AI新手与AI高级用户
差异一:提问的深度
我见过挺多人在使用 AI 之后说很傻,但仔细一想,他们的提示词只有半句话。这就像雇了一个顾问,然后只告诉他"帮我做点什么"------结果当然让人失望。AI 的能力上限远比大多数人体验到的要高,真正的门槛不是技术,而是你愿不愿意认真对待这次"对话"。
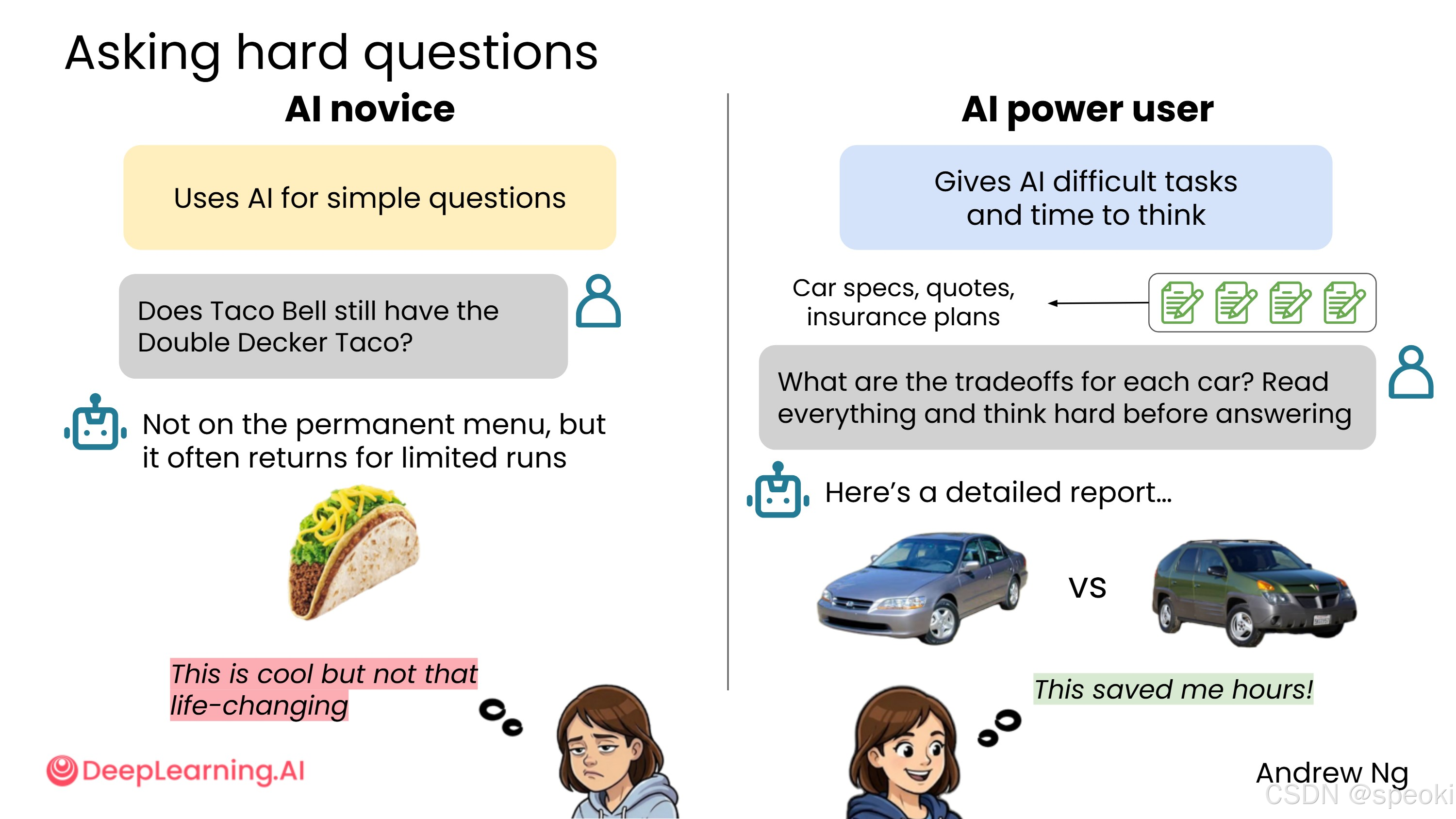
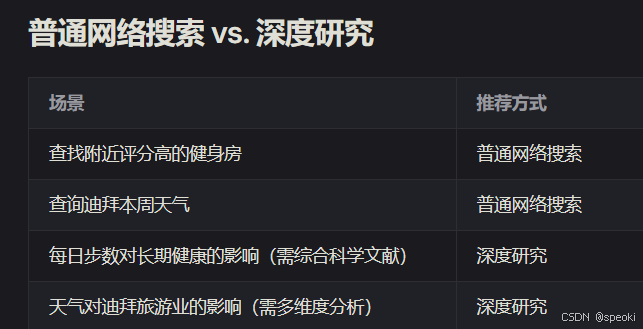
AI 新手 习惯用 AI 回答简单问题,就像在谷歌搜索一样提示它。例如:
塔可钟还有双层塔可吗?
这类问题没什么问题,但如果你有更难的问题,也可以问 AI,并给它时间思考。
AI 高级用户 会把 AI 当作深度分析工具。例如,想买车时,可以上传一组文档(汽车规格、报价、保险计划),然后问:
这些车的权衡是什么?告诉它仔细阅读所有内容,回答前要好好思考。
这可能导致 AI 花费数秒甚至数分钟来思考,并编译出详细的分析报告,大大节省你自己做研究的时间。
我把这种用法叫做"把 AI 当分析师用"。你不是在问它一个问题,而是在委托它完成一项任务。区别在于:问题期待一个答案,任务期待一份交付物。当你开始用"任务思维"来构建提示词,AI 的输出质量会有质的飞跃。买车分析只是一个例子------合同审查、竞品对比、职业规划,都可以用同样的方式来做。
差异二:提供上下文的多少
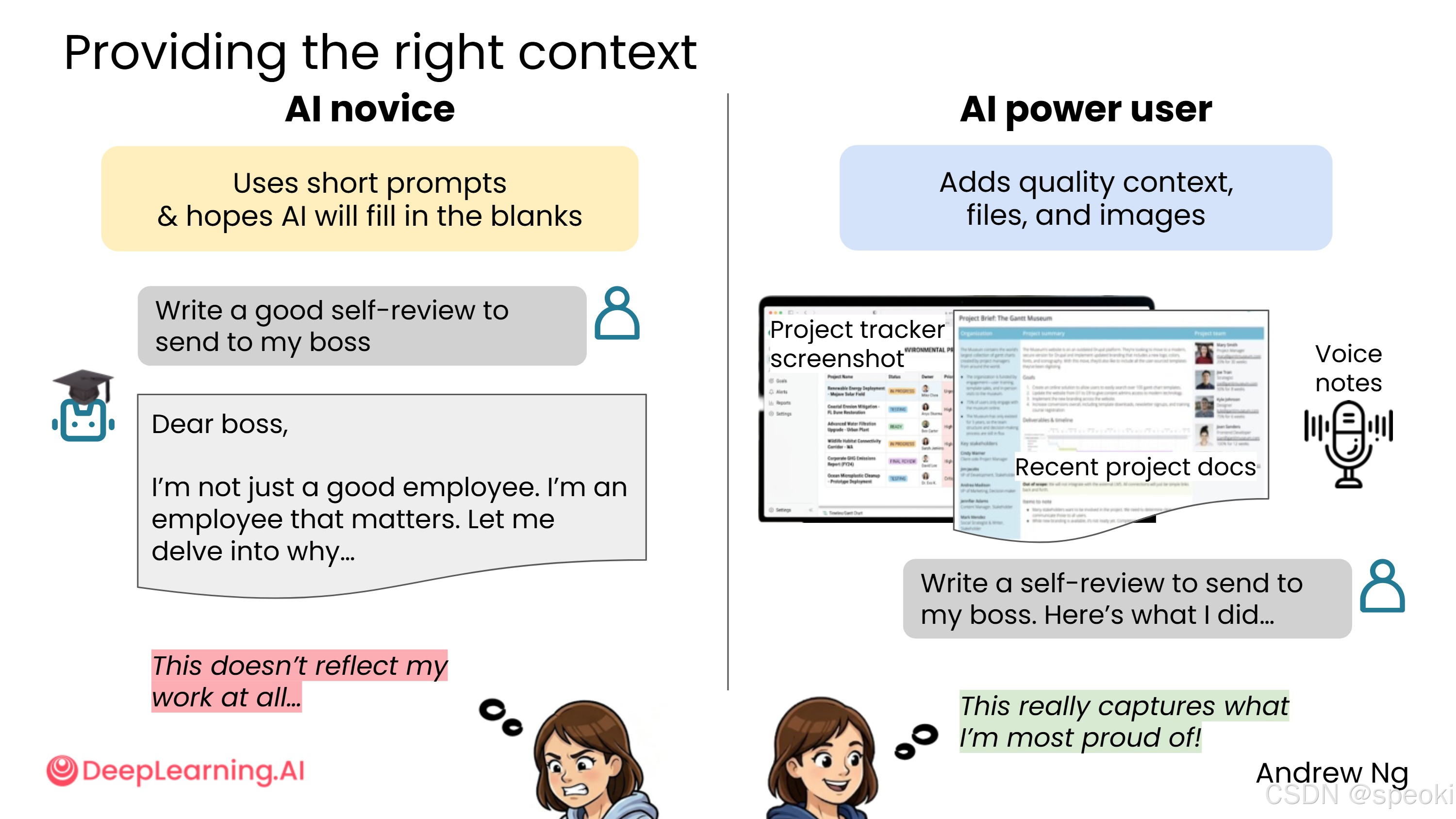
AI 新手 倾向于用简短提示,希望 AI 能帮你填补空白。例如:
请写一篇好的自我评价发给我的老板。
AI 并不知道你过去一年里做过什么,因为你还没告诉它。结果往往是非常普通的自我评价,没什么帮助。
AI 高级用户 几乎对 AI 产生了一种"同理心"------设身处地为 AI 着想:如果你是那个接到任务的人,你真的了解足够多,能做好这项任务吗?
高级用户可能会上传:
- 项目跟踪器的截图(展示你做了什么)
- 最近的项目文档
- 语音备忘录(讲解项目内容)
然后再说:写一篇自我评价发给我的老板。这样能更好地捕捉你最引以为傲的成果。
我喜欢用一个比喻来解释这件事:你不会在第一天上班就让新同事独立完成一份重要报告,你会先给他背景、讲清楚目标、分享相关资料。对 AI 也一样。它不是搜索引擎,不会自动猜测你的处境------你给的信息越完整,它能做的事情就越接近你真正需要的。"上下文"不是可选项,它是质量的基础。
差异三:如何获得诚实反馈
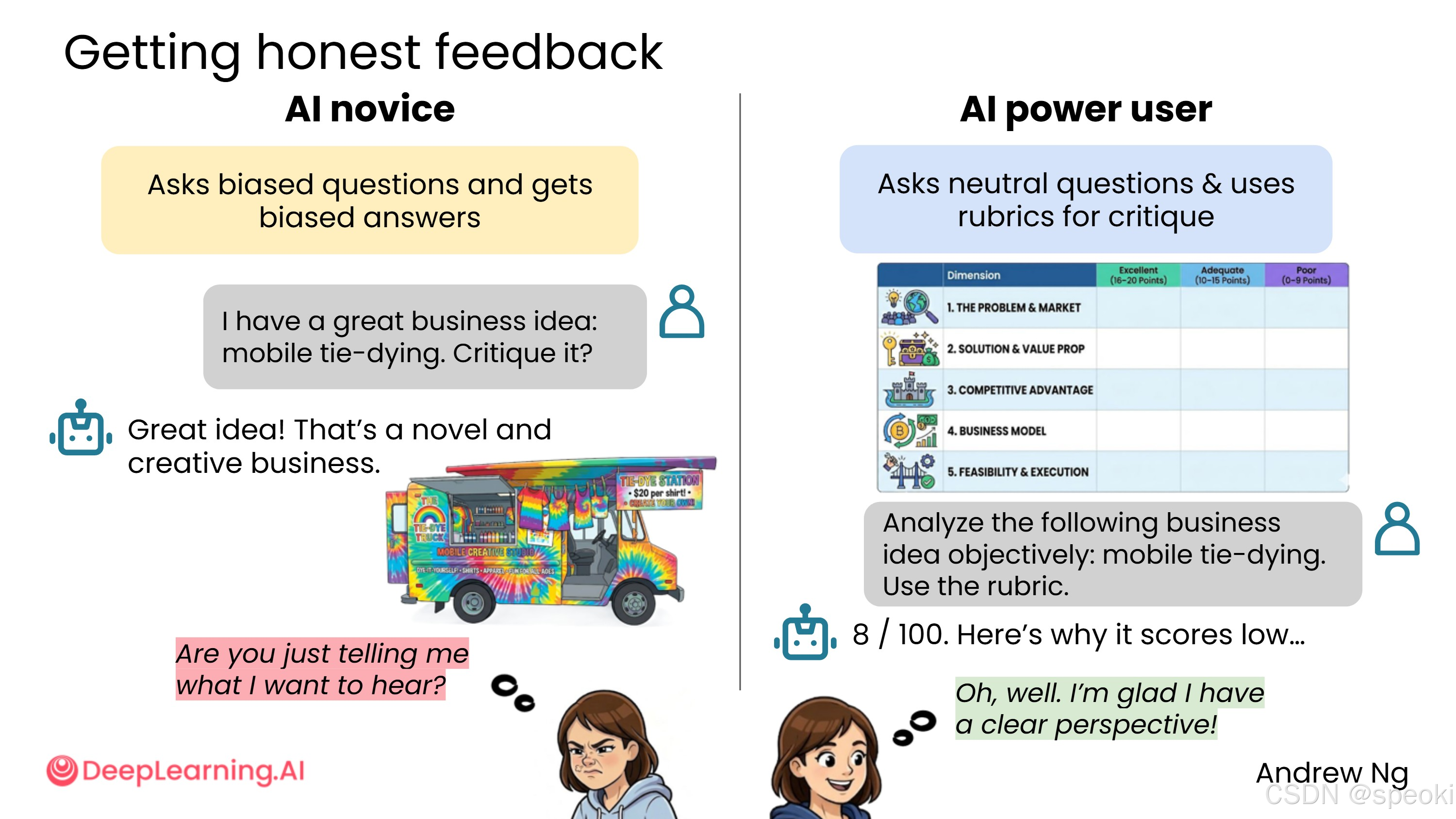
AI 新手 可能会这样问:
我有个很棒的商业点子:移动扎染。批评它。
因为你说了"很棒的商业点子",AI 自然会想取悦你,说"多么棒的主意"。这种现象有时被称为谄媚(Sycophancy)------即使你稍微透露了你希望得到的答案,AI 很可能只是反映并支持你的偏好。
AI 高级用户 倾向于提出中立问题,不给 AI 任何暗示。或者给它一个评分标准,告诉 AI 如何形成答案的基础,迫使它更加客观。例如:
请客观地分析以下商业理念:移动扎染。使用以下评分标准:有问题吗?有市场吗?我有竞争优势吗?
这样 AI 不知道你是希望它告诉你这是个好主意,还是希望它帮你避免在糟糕的点子上浪费时间。结果更可能是客观的评分,比如"这个想法是 8 分(满分 100 分)",并说明原因。
谄媚是 AI 最容易被忽视的缺陷之一。很多人用 AI 验证自己的想法,却不知道 AI 其实在"迎合"他们。我的建议是:每当你想让 AI 评价你自己的东西时,先把"我觉得这很好"这类话从提示词里删掉,换成中立的描述。更进一步,可以明确告诉 AI:"不要顾及我的感受,我需要的是真实的分析,哪怕结论是否定的。"这一句话,往往能让输出质量大幅提升。
差异四:写作工作流程
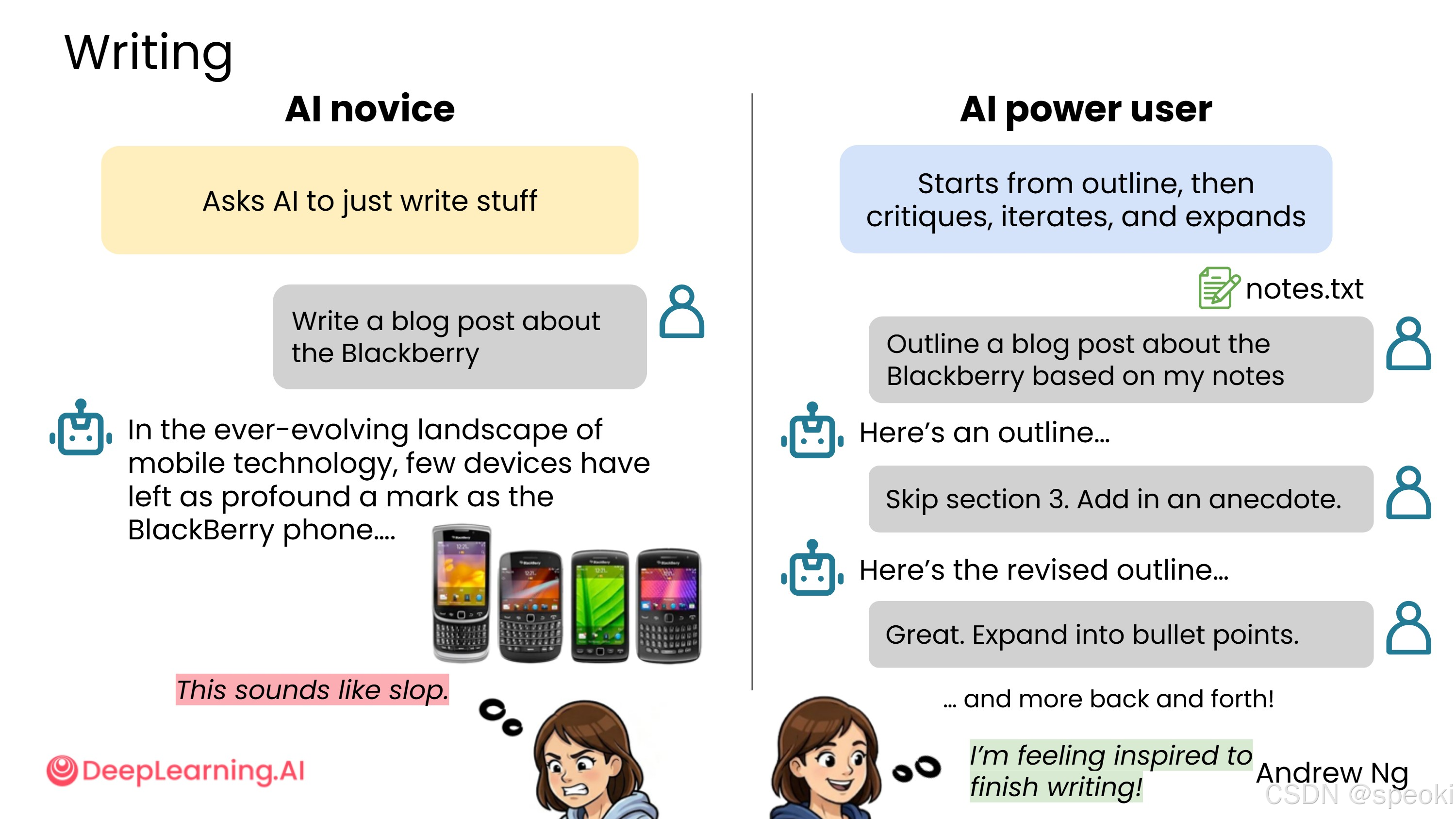
AI 新手 只会让 AI 直接写,例如:
写一篇关于黑莓的博客文章。
AI 会生成一堆普通文本,听起来像 AI 写的,没什么意思,而且占用大量空间。
AI 高级用户 通常不会直接让 AI 写,而是先让 AI 做大纲,批评大纲,迭代几次,只有在大纲满意之后,才让 AI 开始起草最终文章。
典型工作流程如下:
- 上传笔记作为背景,让 AI 根据笔记写博客大纲
- 给 AI 反馈你喜欢和不喜欢大纲的哪些方面
- 经过几轮来回,确认大纲满意
- 将大纲扩展成要点
- 批评要点,再次迭代
- 将要点扩展成最终文本
这个工作流程背后有一个更深的道理:写作的本质是思考,而不是打字。当你让 AI 先出大纲,你其实是在用 AI 帮你"想清楚"------哪些内容值得写,哪些顺序更合理,哪些角度你没想到。很多人跳过这一步,直接要成品,结果拿到一篇结构混乱的文章,再花大量时间修改。倒不如一开始就慢下来,把结构做对,后面反而更快。这个原则不只适用于写作,做方案、做决策、做产品规划,都一样。
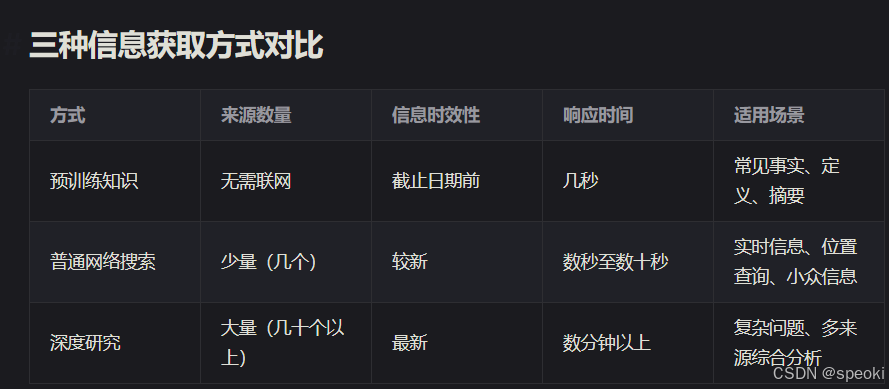
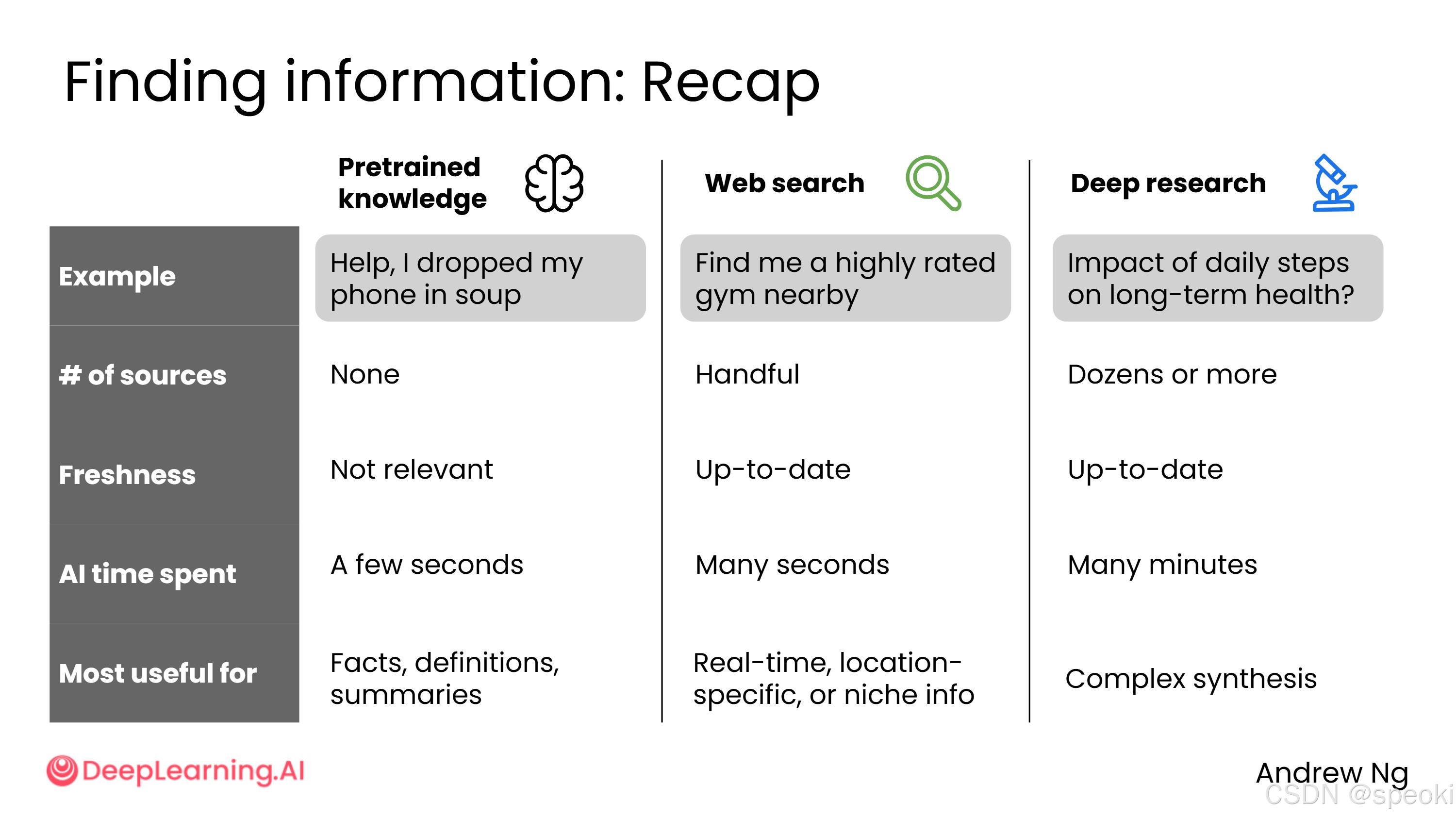
预训练知识
你小时候是怎么学会写作的?大概是通过大量阅读。
AI 也是一样------AI 系统通过阅读来自互联网的海量文本,学习其中的语言模式。理解 AI 读过哪些内容,能帮助你更好地预测它的行为。
AI 模型可以回答各种各样的问题,例如:
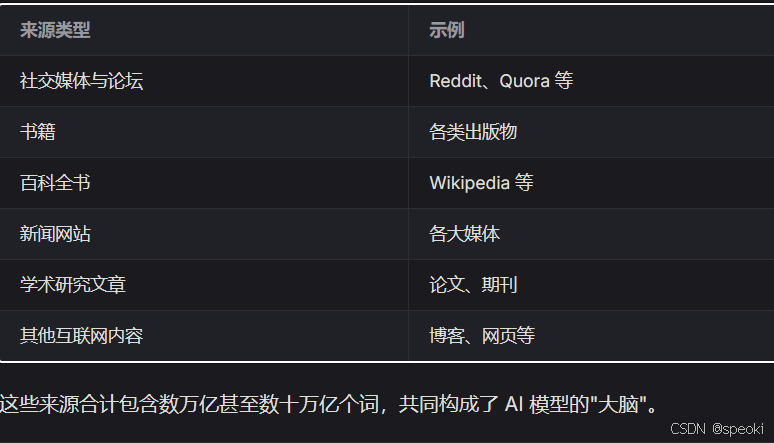
AI 模型从多种多样的来源中学习,主要包括:

知识频率与可靠性
互联网上不同类型的内容出现频率不同,AI 的预训练知识也因此反映了这种分布规律。
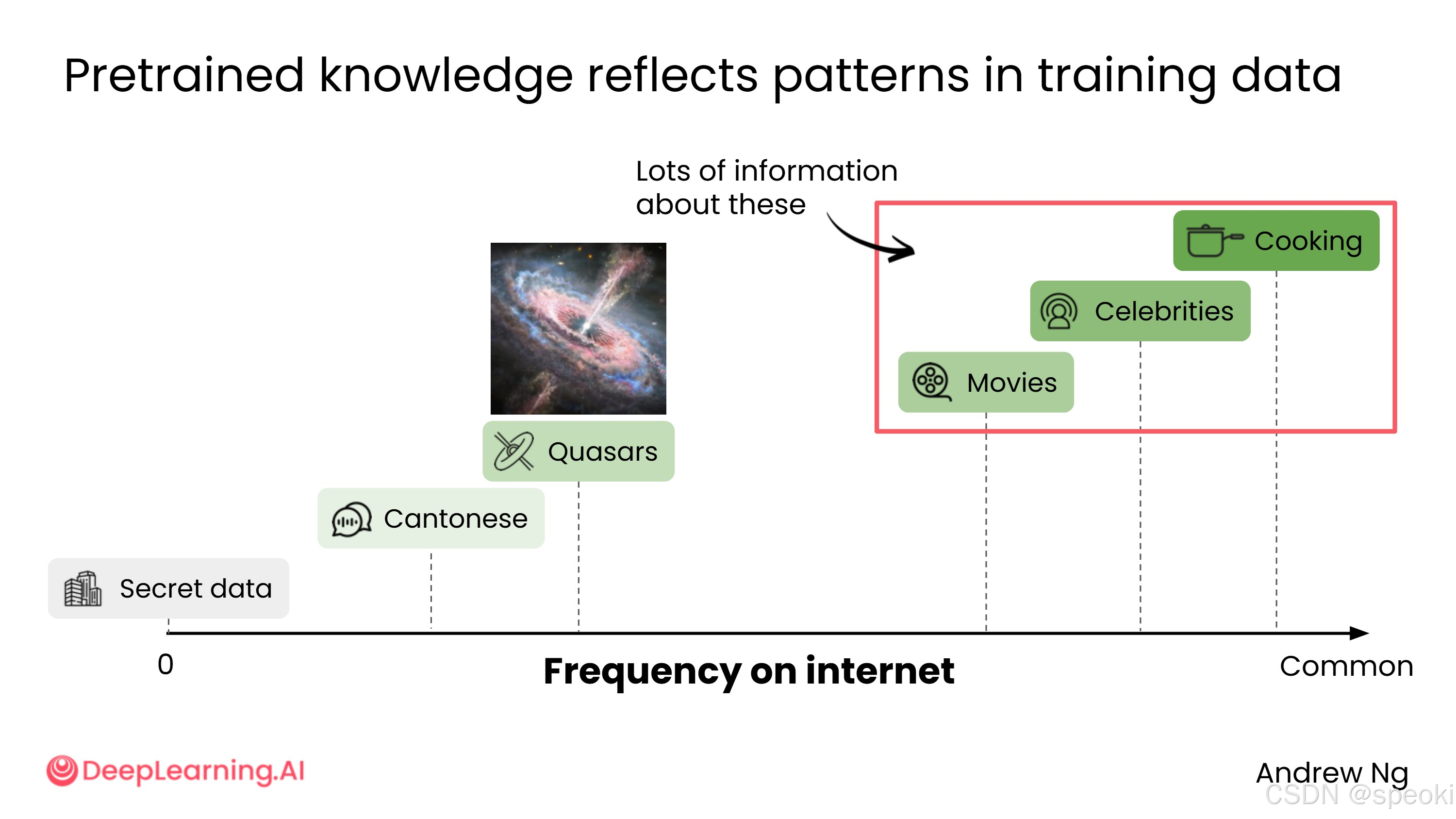
知识丰富的领域(互联网内容多):
- 烹饪(普遍的人类经验,相关文章极多)
- 娱乐、电影、名人
知识相对有限的领域(互联网内容少):
- 专业术语,如"类星体"(quasar)------由超大质量黑洞驱动的极亮天体,相关文章远少于烹饪类内容
语言分布:
- 互联网内容以英语为主
- 其他语言如粤语(全球超过 8000 万人使用)的内容占比不足 0.1%
AI 完全不了解的内容:
- 你公司的私有数据、内部文件等未公开在互联网上的信息
实用规则: 某类信息在互联网上出现的频率越高,AI 对该话题的回答通常越可靠。
AI 对拼写错误的容忍度
由于 AI 从包含大量拼写错误的互联网内容中学习,它对错别字有很强的理解能力。例如:
- can you cook eggs in microwave(有拼写错误)
- can you cook eggs in the microwave(标准写法)
两者对 AI 来说几乎没有区别。因此,使用 AI 时不必花太多时间纠正每一个语法错误,快速输入即可。
预训练知识的局限性
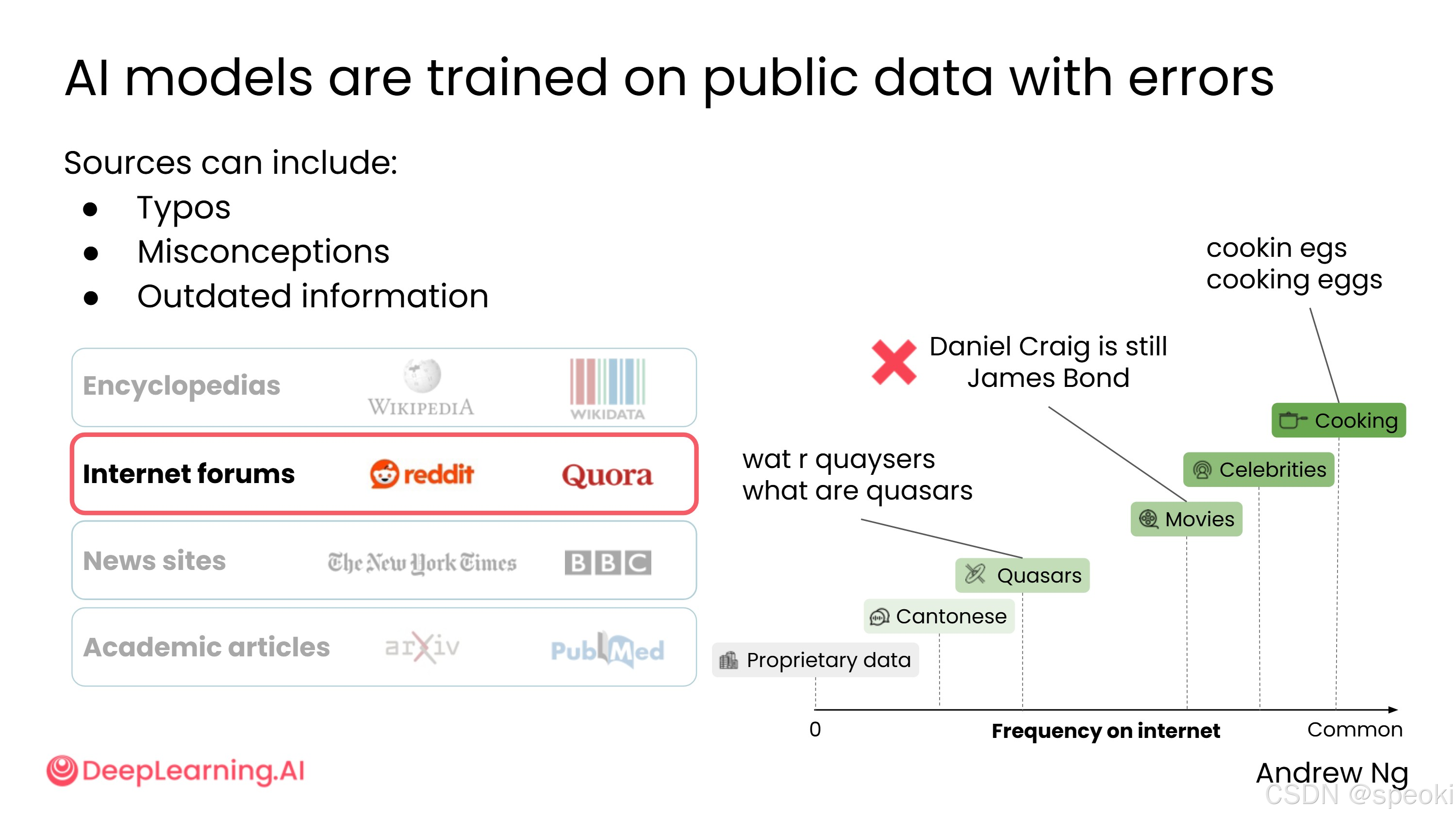
预训练知识并非万能,主要存在以下局限:
- 包含误解和过时信息:互联网上本身存在大量错误内容,AI 也会从中学习
- 缺乏实时信息 :预训练知识有截止日期,无法获取最新动态
掌握如何提示 AI 以减少误解、避免过时信息,是使用 AI 的重要技能之一。
小结
- AI 的预训练知识来自互联网上的海量文本
- 知识的可靠性与该话题在互联网上的内容丰富程度正相关
- AI 对拼写错误有较强容忍度,无需过度纠正
- 预训练知识不包含私有数据,也不具备实时信息能力
- 对于需要实时信息的场景,需要结合网络搜索功能使用
- 下一节将介绍如何通过网络搜索弥补预训练知识的不足。
预训练知识这个概念,让我想到一个很贴切的比喻:AI 就像一个博览群书、见多识广的人,但他在某个时间点之后就与世隔绝了,不再接触新信息。他能流利地谈论历史、科学、文化,但对昨天发生的事一无所知。
有几点值得特别关注:
-
"互联网偏见"问题:AI 的知识分布并不均匀,它更擅长英语、更了解西方文化、更熟悉热门话题。这意味着当你用中文问一个小众的本地问题时,AI 的回答质量可能远不如用英文问一个全球性话题。这不是 AI 的"错",而是训练数据本身的结构性偏差。
-
拼写容忍度的背后逻辑:AI 之所以能理解错别字,是因为它见过无数人犯同样的错误------这其实是一种"群体智慧"的体现。但这也意味着,如果某个错误写法在互联网上极为普遍,AI 可能会把错的当成对的。
-
私有数据的边界:公司内部文档、个人日记、未发布的代码------这些 AI 完全不知道。这既是隐私保护的优点,也是使用 AI 处理专业工作时需要额外补充上下文的原因。在实际工作中,我们往往需要把相关背景信息"喂给"AI,才能得到真正有用的答案。
网络搜索
知识截止日期
AI 模型的训练在某个时间点停止,因此它的知识存在一个"截止日期"------也就是说,AI 只读取了截止日期之前的互联网内容,之后它的知识便被冻结在那个时间点上。
但世界不会停止运转,新的事件不断发生,新的电影上映,新的梗图诞生......
- AI 自动判断:模型识别到问题可能需要实时或小众信息,自动发起搜索
- 用户主动触发:
- 点击 AI 界面中的搜索按钮
- 在提示词中明确写出"请搜索网络"或"请联网查询"
注意:并非所有 AI 模型都支持网络搜索,但目前主流的 AI 产品(如 ChatGPT、Gemini、Claude)大多已具备这一能力。
网络搜索的局限性
网络搜索能让 AI 用更新的信息来补充其预训练知识,从而在许多任务上表现更好。
但和普通网络搜索一样,它也可能返回不可靠的来源。
因此,在使用 AI 进行网络搜索时,需要注意:
- 引导 AI 使用更权威、更可靠的信息来源
- 对搜索结果保持批判性思维
- 必要时核实 AI 给出的信息
网络搜索功能让 AI 从"百科全书"升级成了"实时记者",但这个升级并不是无代价的。
关于"年份触发"的技巧:文中提到在提示词里加上年份(如"2025 年")可以触发网络搜索,这是一个很实用的小技巧。更广泛地说,任何暗示"时效性"的词语都能起到类似效果,比如"最新的"、"现在"、"今年"、"近期"等。养成这个习惯,能让 AI 主动去获取更新的信息,而不是依赖可能已经过时的预训练知识。
AI 搜索 vs. 自己搜索:两者最大的区别在于,AI 会帮你"消化"搜索结果,而不是把一堆链接甩给你。这在需要综合多个来源时特别有价值------但也意味着你看不到原始信息,AI 的"消化"过程可能引入偏差或遗漏细节。
一个反直觉的现象:有时候,不触发网络搜索反而更好。如果你问的是一个经典的、稳定的知识点(比如某个数学定理或历史事件),预训练知识往往比网络搜索更可靠------因为网络上可能充斥着质量参差不齐的二手解读,而 AI 的预训练知识来自大量高质量文本的综合提炼
网络搜索的来源与局限
网络搜索并不完美
网络搜索 是一个非常有价值但并不完美 的工具。就像你自己搜索网络时,不一定总能找到想要的内容------它同样存在找到过时或不准确来源的局限性。
但你可以通过一些方法绕过这些局限,让 AI 给出更准确、更新的答案。

来源质量的问题
以"绿色市场肽类补充剂是否安全"为例,AI 可能会搜索到:
- 社交媒体帖子
- Reddit、Quora 等公共论坛
- 销售肽类产品的商业网站(这类网站有倾向性地声称产品安全)
这些来源的可靠性参差不齐。
更好的做法:引导 AI 使用来自官方机构的来源,例如:
- 世界卫生组织(WHO)
- 美国食品药品监督管理局(FDA)
- 欧洲药品管理局(EMA)
这样更有可能获得可靠、有科学依据的答案。
为什么 AI 倾向于引用热门来源
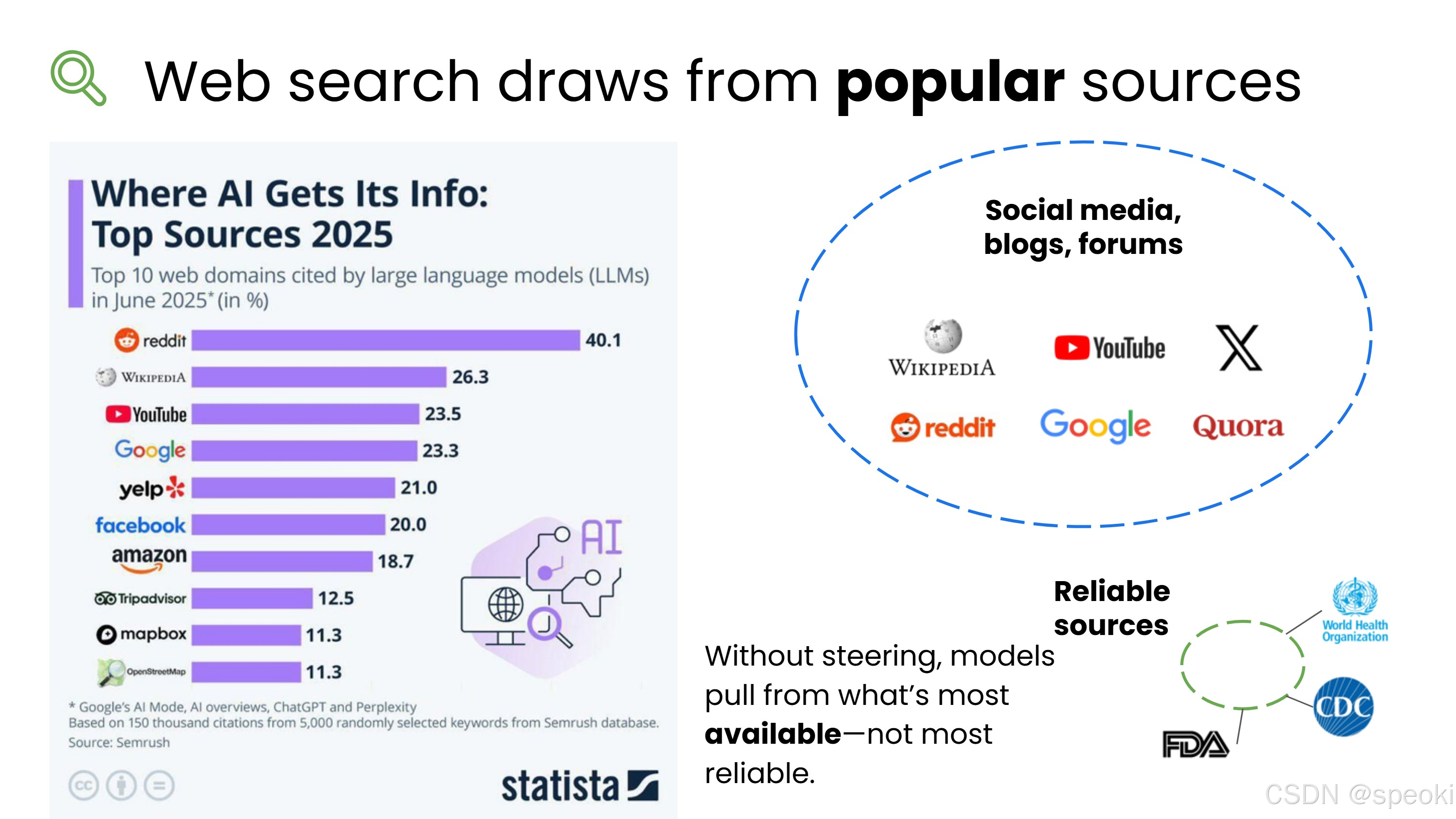
根据一份报告,AI 模型引用最多的网站依次是:
- Wikipedia
- YouTube
- Yelp
互联网上来自社交媒体、博客、论坛的文本数量庞大,而来自高度可靠、经过科学验证的来源的文本相对较少。
如果你不指定偏好的来源类型,AI 往往会倾向于引用数量最多的内容,而不是最可靠的内容。
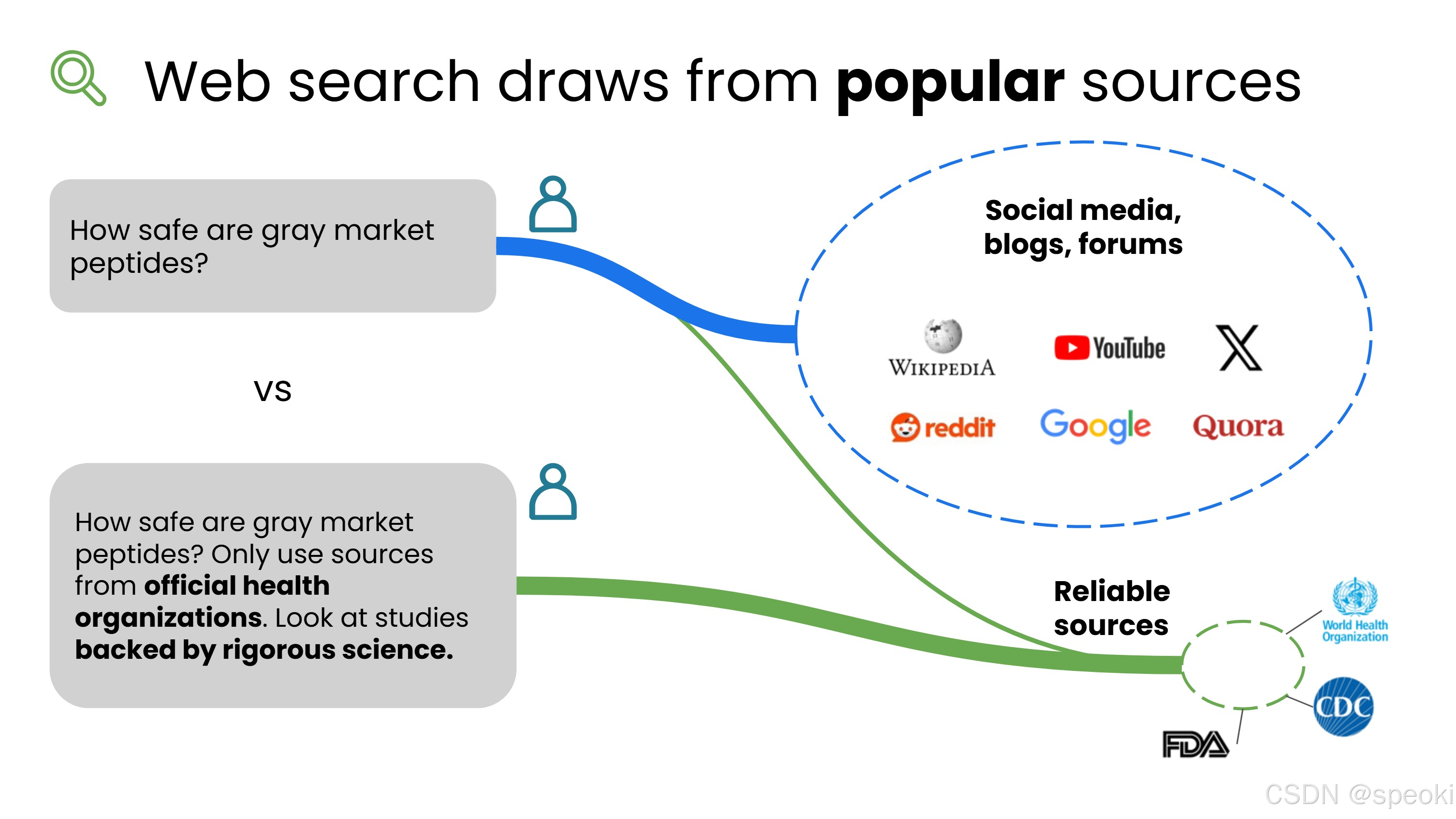 结论:在提示词中明确要求使用权威来源,可以显著提升答案质量。
结论:在提示词中明确要求使用权威来源,可以显著提升答案质量。
网络搜索的另一个局限是:网页内容可能已经过时。
理解 AI 如何进行网络搜索,有助于更好地使用它。整个过程可以类比为一个两人客服团队:
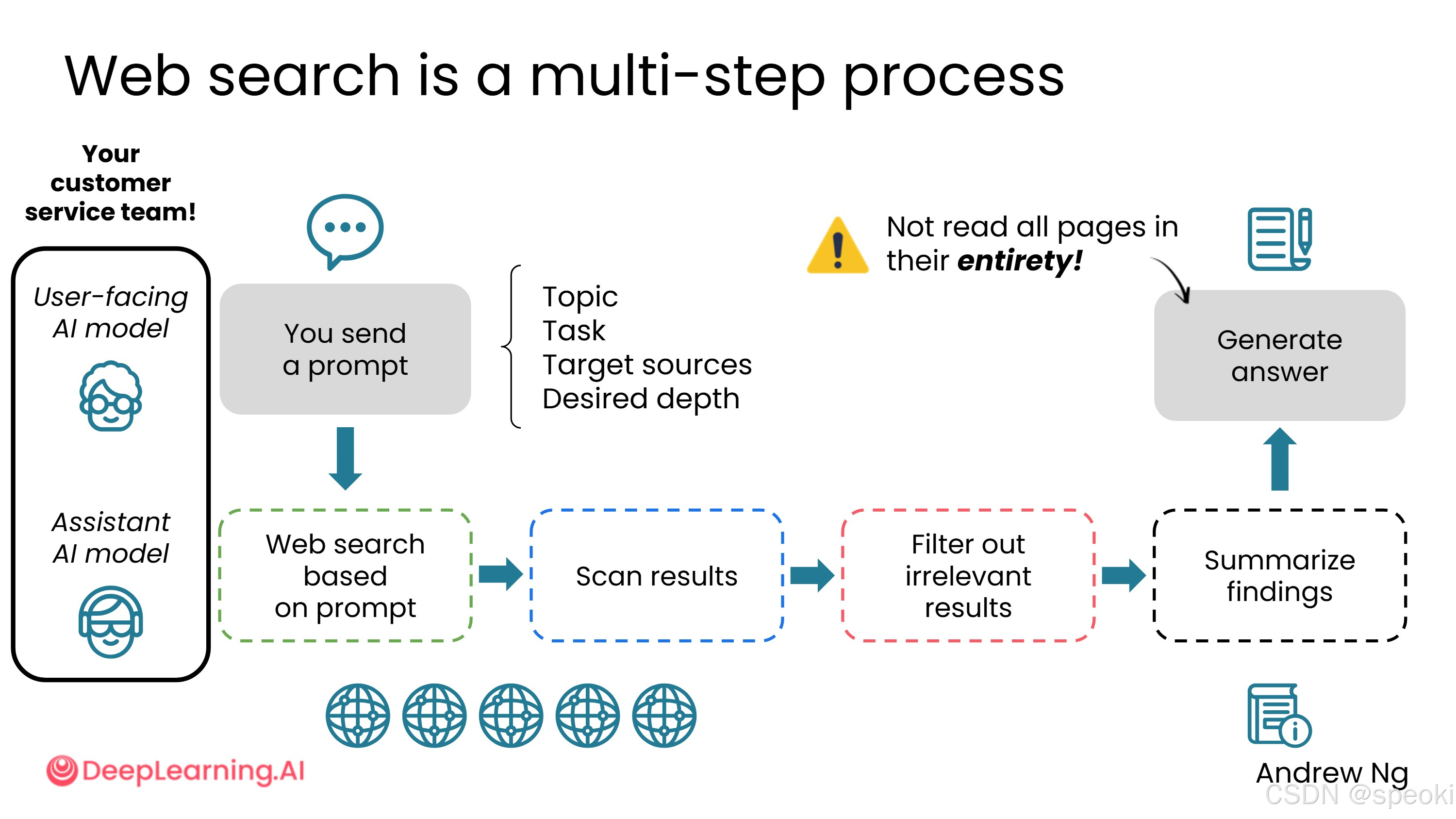
重要提示:用户端 AI 模型并没有完整阅读它所引用的网页,它只看到了这些网页的摘要。这就是为什么有时 AI 引用某个网页作为依据,但你实际去看那个网页,会发现内容并不支持 AI 的结论。
**示例:**如果你问"徒步马丘比丘前需要了解什么",助手模型可能会搜索:
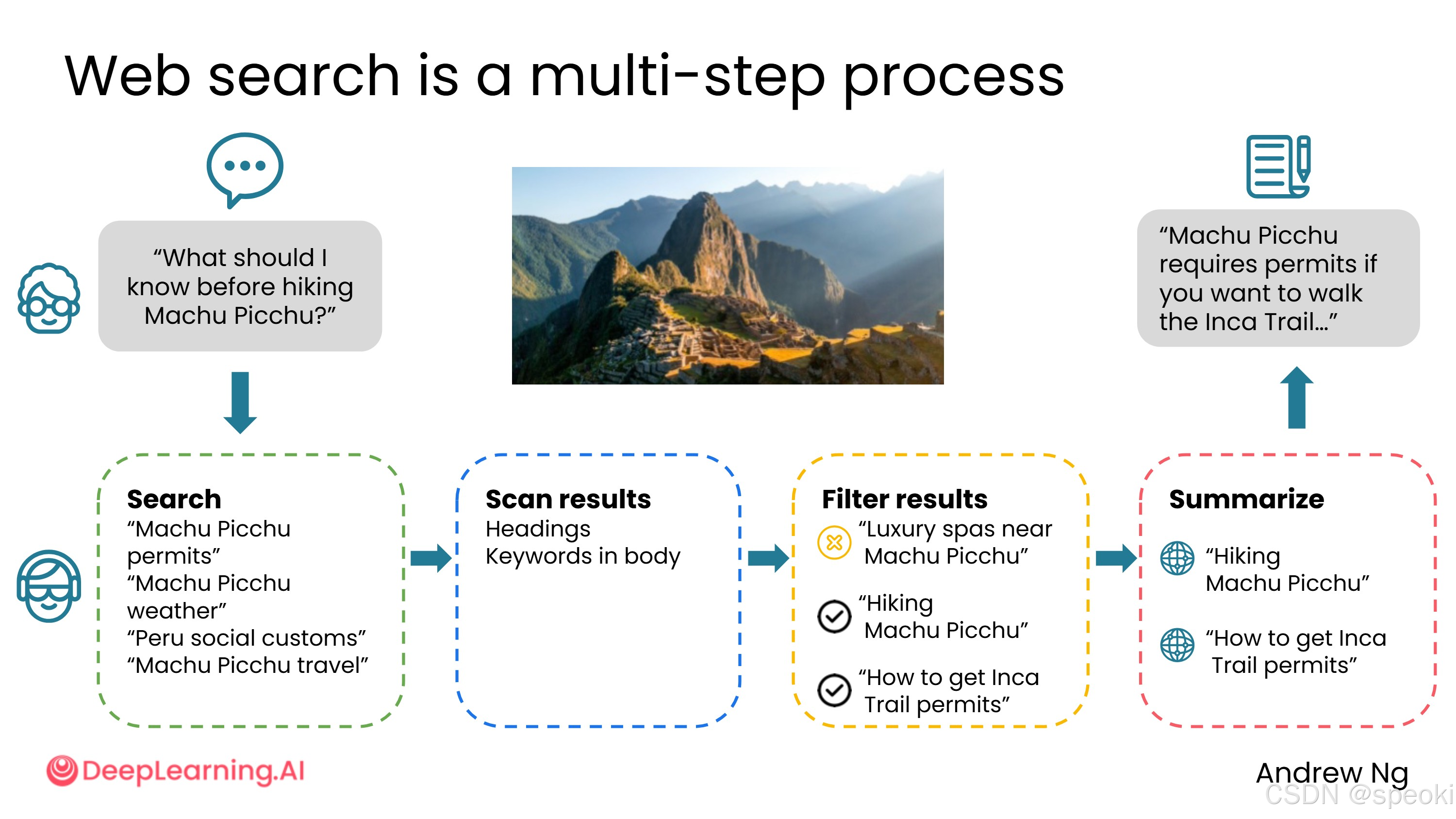
- "马丘比丘许可证"
- "马丘比丘天气"
- "马丘比丘社交礼仪"
然后筛选结果、摘要最相关的网页,再由用户端模型生成最终答案。
AI 模型 vs. 搜索引擎:如何选择?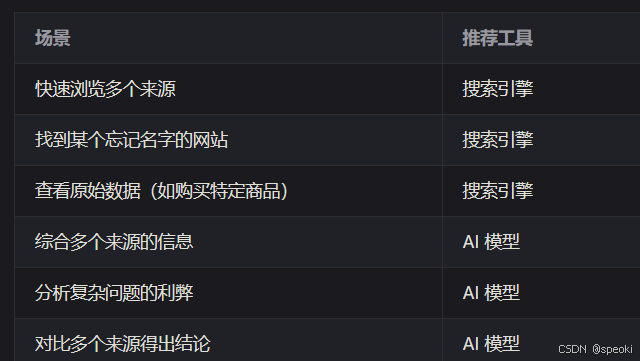
好习惯同样适用
你在使用 Google 等搜索引擎时养成的好习惯,在使用支持网络搜索的 AI 模型时同样有效:
- 关注来源的可靠性
- 对结果进行二次核实
"摘要陷阱":AI 引用了某个网页,但实际上只看了摘要------这就像一个学生引用了一本书,但只读了封底简介。结论可能是对的,也可能完全偏离原文的意思。当 AI 给出的信息对你很重要时,最好点进原始链接自己确认一下。
为什么 Reddit 排第一?:AI 引用最多的是 Reddit,这其实很合理------Reddit 上有大量真实用户的第一手经验,覆盖话题极广,而且内容往往比官方文档更"接地气"。但问题在于,Reddit 上的信息没有经过专业审核,质量差异极大。一个高赞回答不等于正确答案。
主动指定来源是一种"提示词技巧":与其让 AI 自由发挥去找来源,不如直接告诉它"请参考 WHO 或 FDA 的官方信息"。这个小改动能显著提升答案的可信度,尤其是在医疗、法律、金融等高风险领域。把这个习惯固化到你的提示词模板里,是很值得的投资。
搜索引擎和 AI 的分工:两者不是竞争关系,而是互补的。当你需要"找到某个具体的东西"时,搜索引擎更直接;当你需要"理解某个复杂问题"时,AI 更擅长综合和解释。学会在两者之间切换,是现代信息获取的核心技能。
使用深度研究
有时候,你希望 AI 不只是综合几个来源,而是综合几十个来源,并进行大量思考,给出对某个问题最深入、最全面的研究答案。
ChatGPT、Gemini、Claude 等主流 AI 聊天界面都提供了深度研究模式。这是一个非常有价值却常被低估的工具。
Gemini 的特色功能
使用 Google Gemini 进行深度研究时,它可以将研究结果转化为:
例如,Gemini 生成的万圣节鬼屋规划网页包含:
四个内容板块
预算饼图
噪音法规可视化图表
可用于活动规划的检查清单
深度研究的工作原理
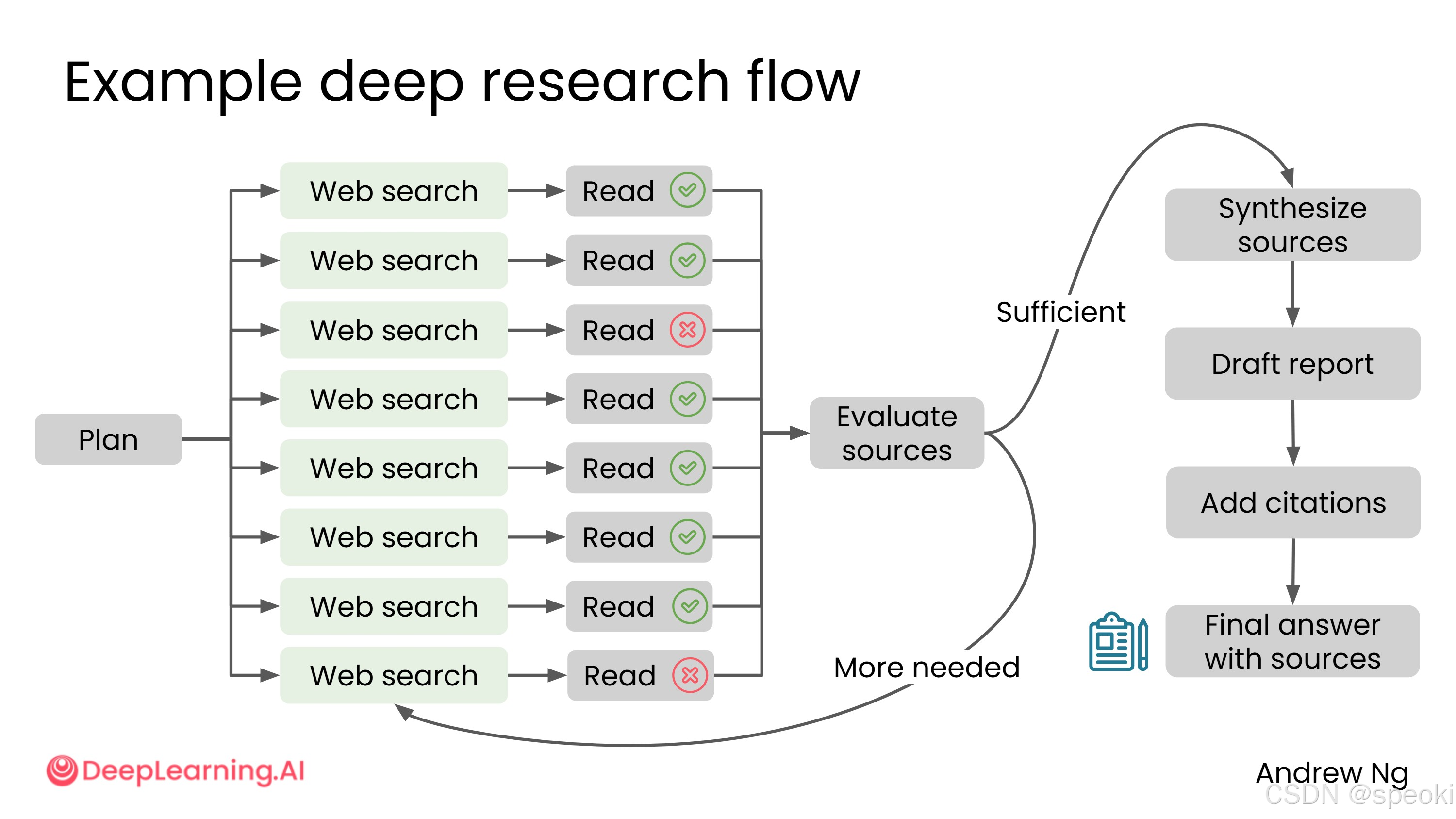
深度研究的一大优势是可以同时发起多个搜索,而不是逐一进行,因此在获取大量网页时效率极高。