负载均衡是一种电子计算机技术.用来在多个计算机(计算机集群) 网络连接 CPU 磁盘驱动器或其他资源中分配负载.以达到优化资源使用 最大化吞吐率 最小化响应时间.同时避免过载的目的.使用带有负载均衡的多个服务组件.取代单一的组件.可以通过冗余提高可靠性.负载均衡服务通常是由专用软件和硬件来完成.主要作用是将大量作业合理的分摊到多个操作单元上进行执行.用于解决互联网架构中的高并发和高可用的问题.
负载均衡构建在原有网络结构之上.它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽 加强网络数据处理能力 增加吞吐量 提高网络的可用性和灵活性.负载主机可以提供很多种负载均衡方法.也就是常说的调度方法或算法.
互联网早期.业务流量比较小并且业务逻辑比较简单.单台服务器便可以满足基本的需求.但随着互联网的发展.业务流量越来越大并且业务逻辑也越来越复杂.单台机器的性能问题以及单点故障问题凸显了出来.因此需要多台机器来进行性能的水平扩展以及避免单点故障.
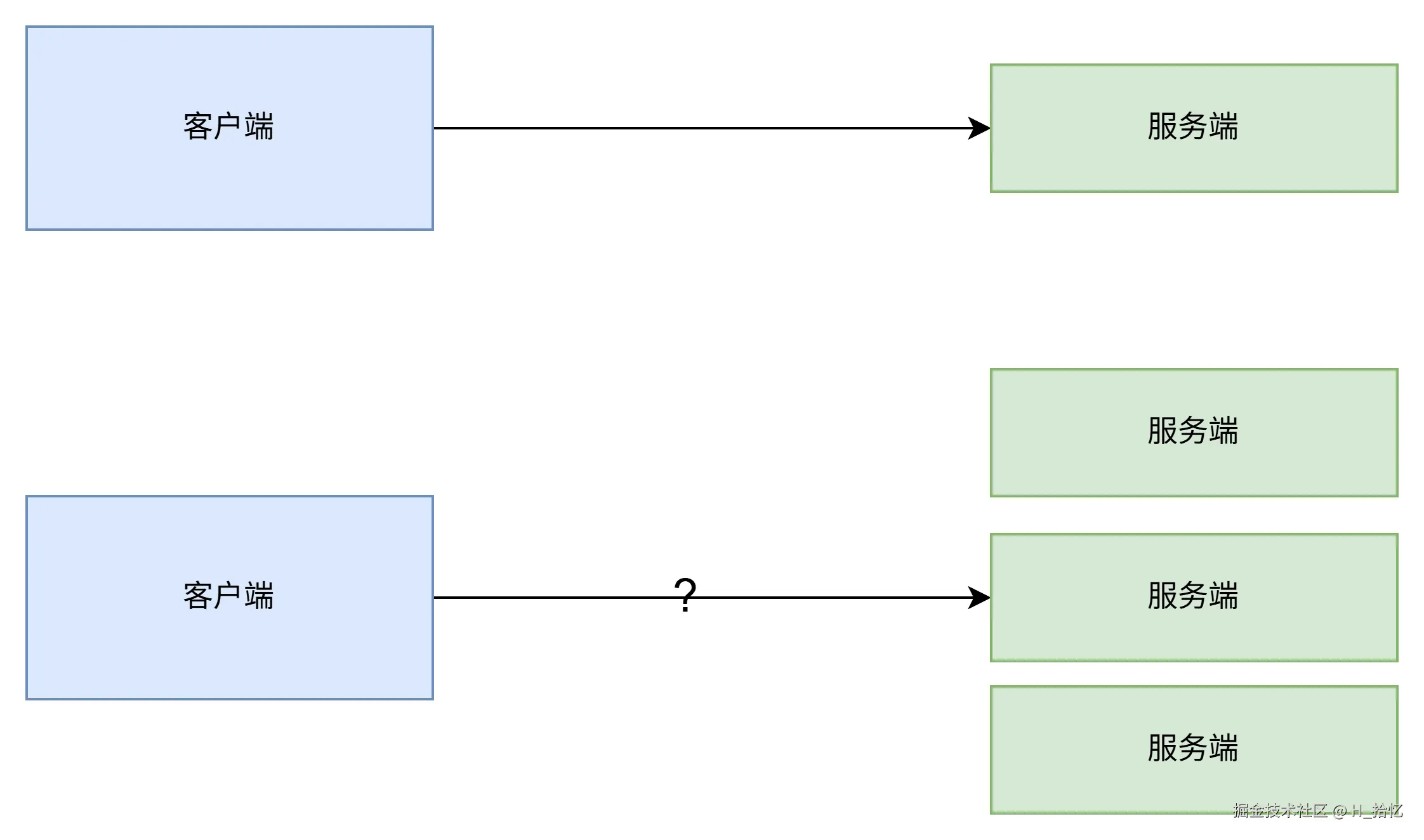
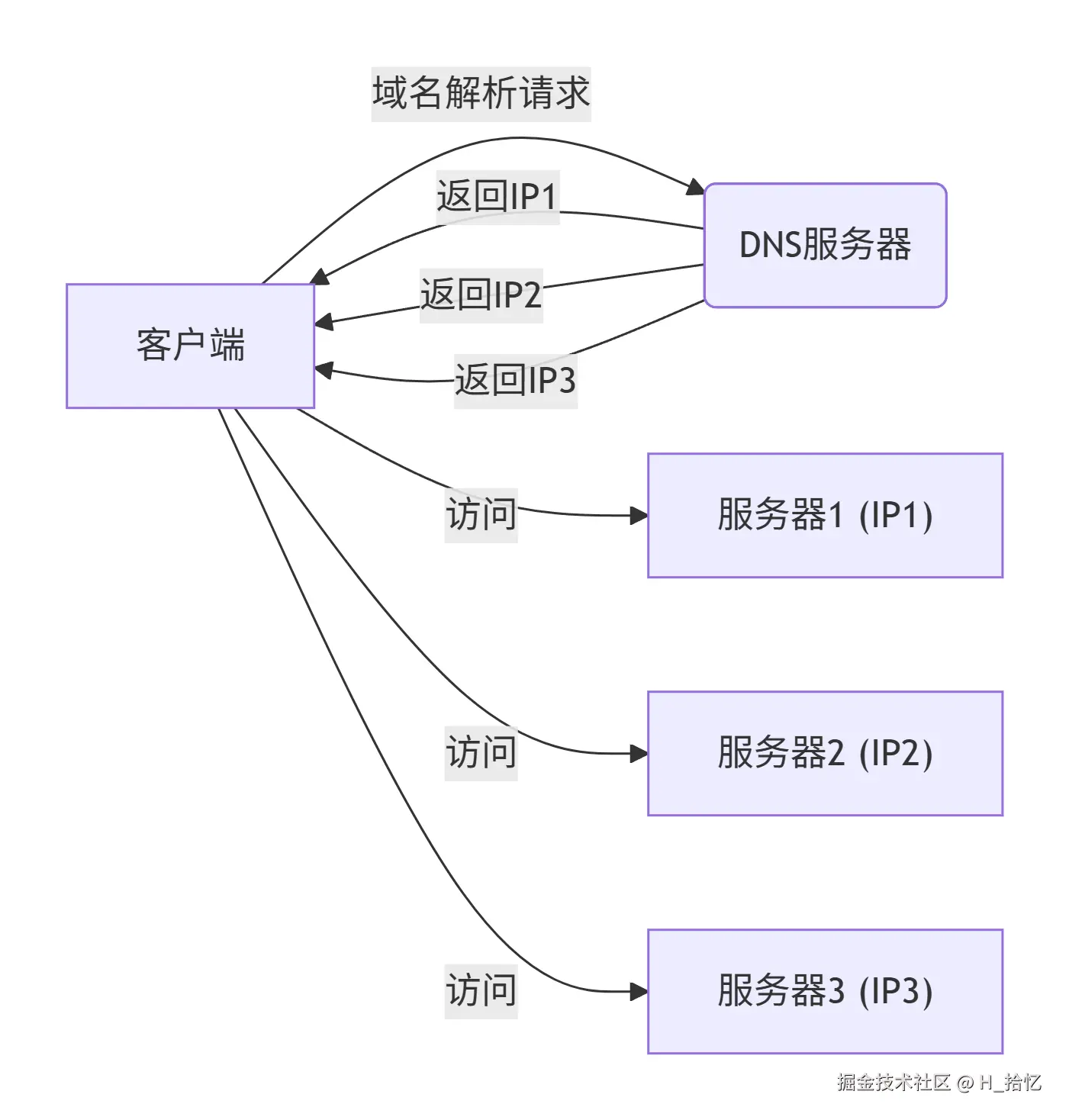
如图所示.早期的方法是使用DNS作负载均衡.通过给客户端解析不同的IP地址.让客户端流量直接到达各服务器端.但是这种方法有一个很大的缺点就是延时性问题.在做出调度策略改变后.由于DNS各级节点的缓存并不会及时的在客户端生效.而且DNS负载的调度策略比较简单.无法满足业务需求.因此出现了负载均衡.
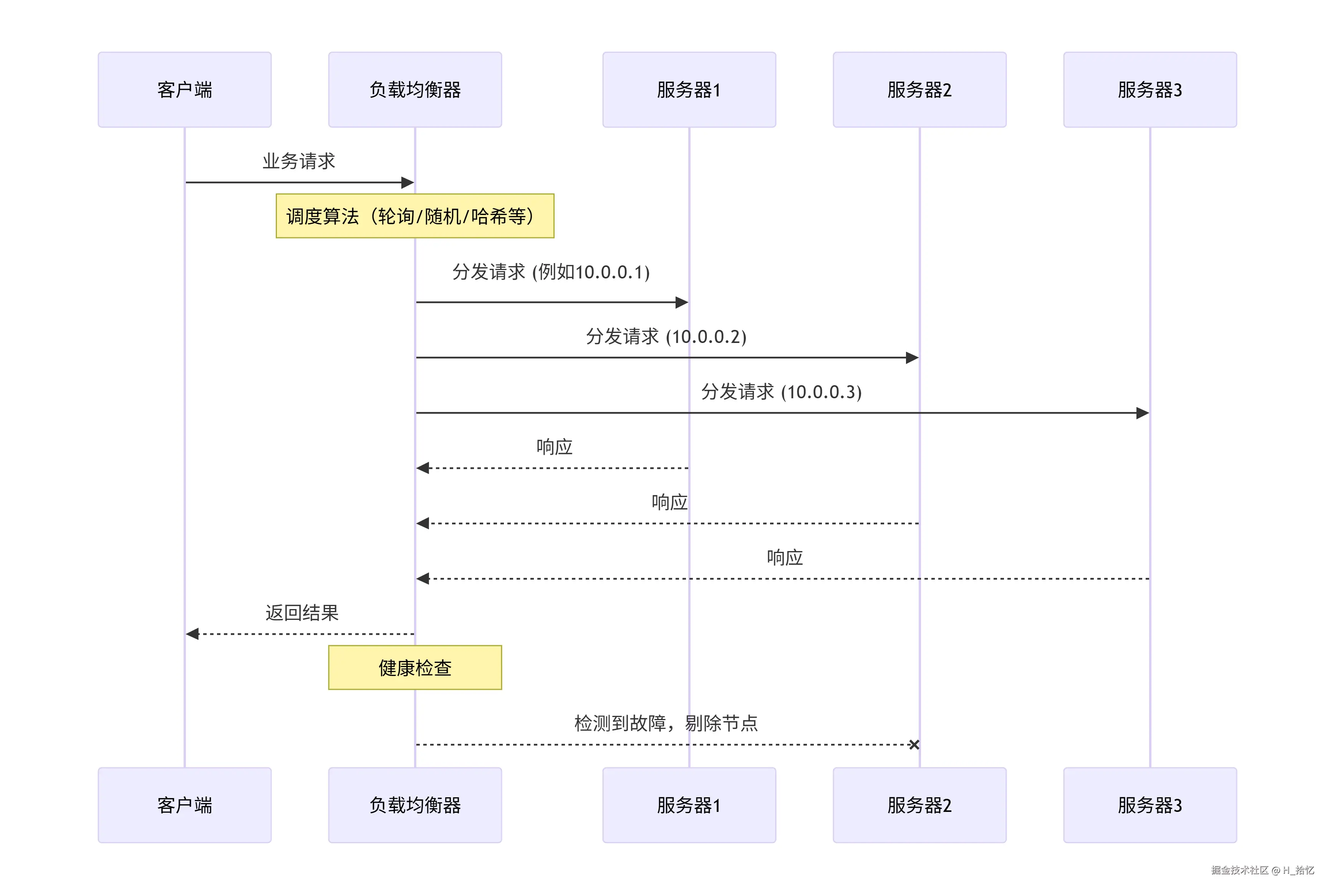
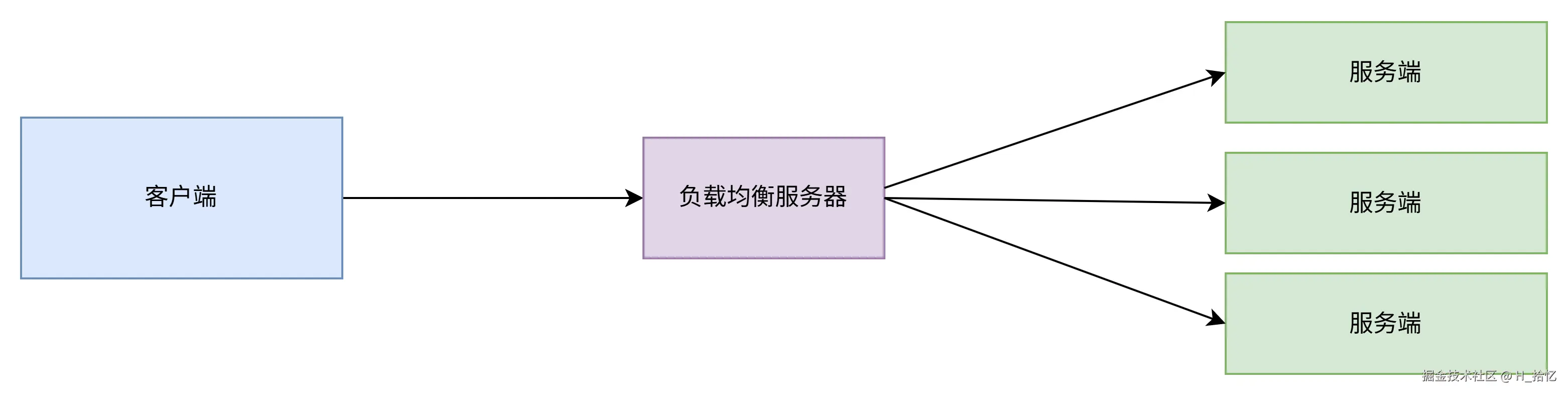
如图所示.客户端的流量首先会达到负载均衡服务器.由负载均衡服务器通过一定的调度算法将流量分发到不同的服务器端.同时负载均衡服务器也会对服务器做出周期性的健康检查.当发现故障节点时.便动态的将节点从服务器端集群中剔除.以此来保证应用的高可用.
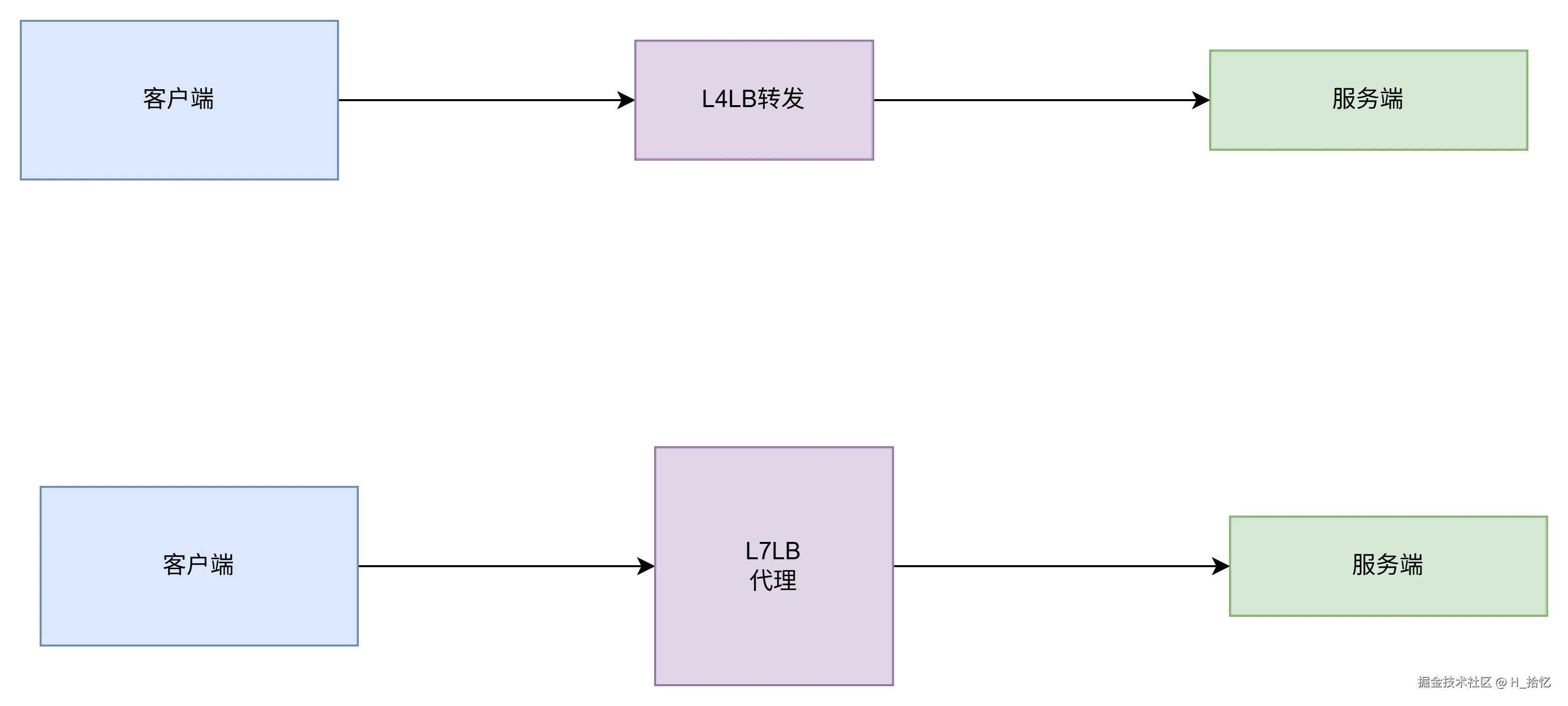
如图所示.负载均衡又分为4层负载均衡和7层负载均衡.4层负载均衡工作在OSI模型的传输层.主要工作是转发.它在接收到客户端的流量后通过修改数据包的地址信息将流量转发到服务端.
7层负载均衡工作在OSI模型的应用层.因为它需要解析应用层流量.所以7层负载均衡会与客户端建立一条完整的连接并将应用层的请求流量解析出来.在按照调度算法选择一个服务端.并与服务器端建立另外一条连接将请求发送过去.因此7层负载均衡的主要工作就是代理.
场景负载均衡技术:
1.基于DNS的负载均衡:
由于在DNS服务器中.可以为多个不同的地址配置相同的名字.最终查询这个名字的客户端将在解析这个名字时得到其中的一个地址.所以这种代理方式是通过DNS服务器中的随机名字解析域名好IP来实现负载均衡.
2.反向代理负载均衡:
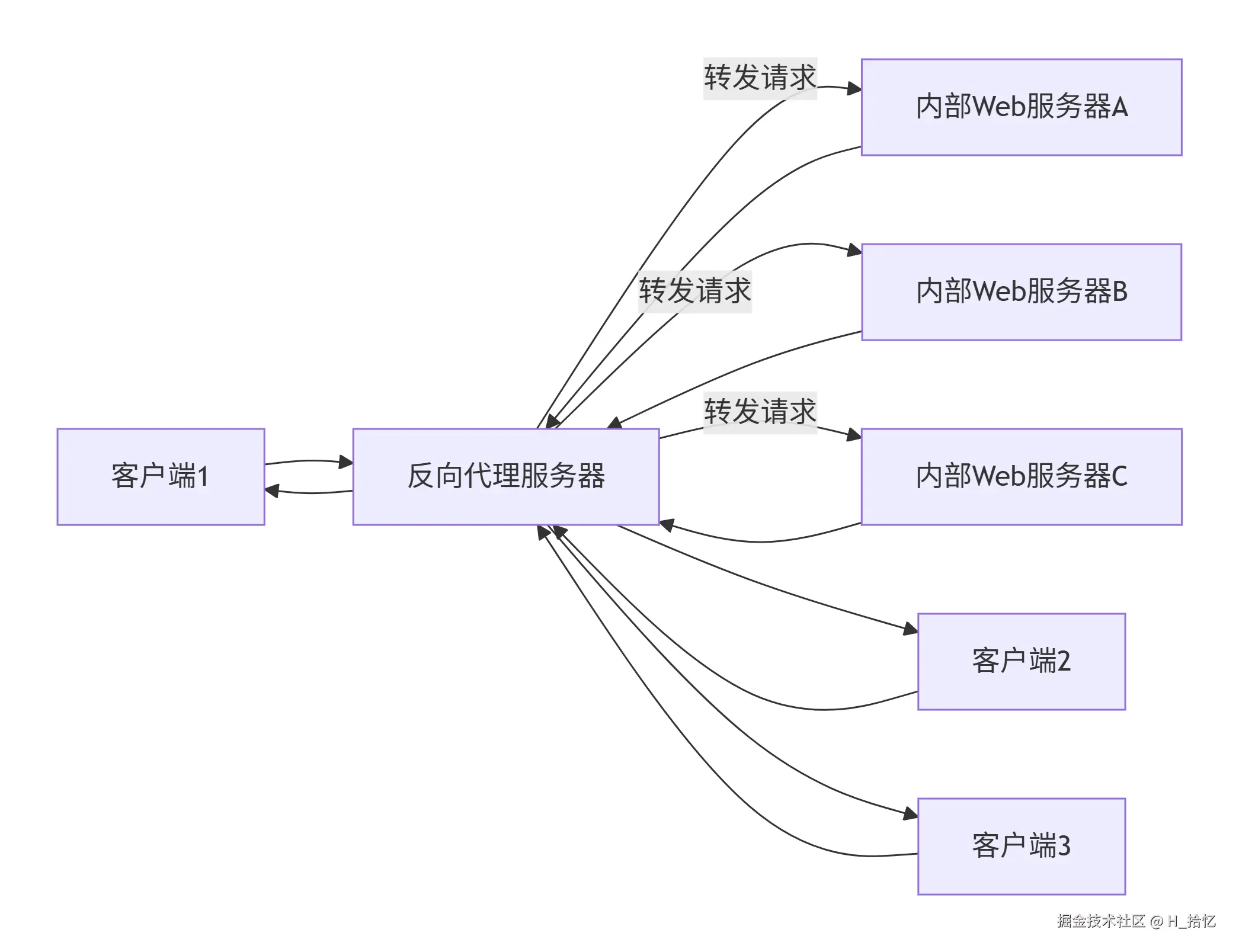
这种代理方式与普通的代理方式不同.标准代理方式是客户使用代理访问多个外部Web服务器.之所以被称为反向代理模式是因为这种代理方式是多个客户使用它访问内部Web服务器.而非访问外部服务器.
3.基于NAT的负载均衡技术: 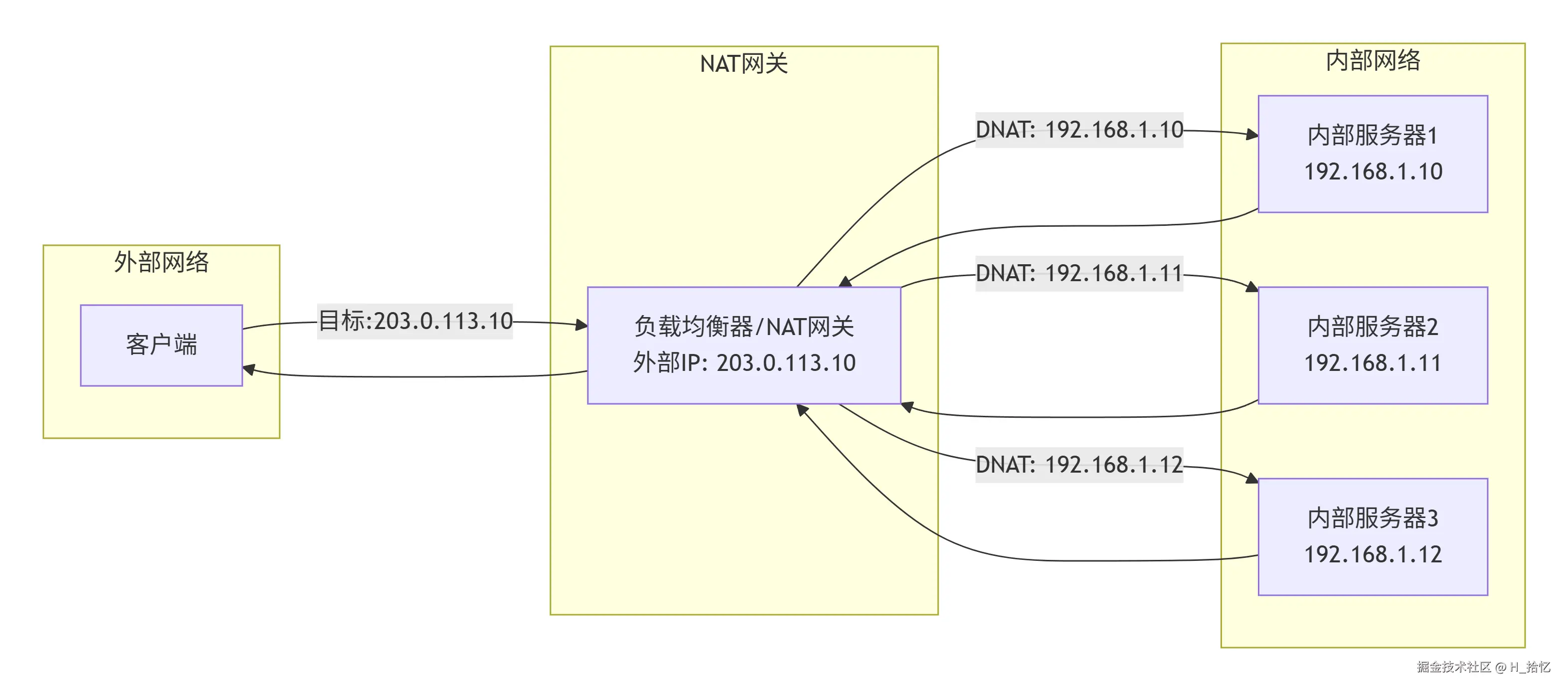
该技术通过一个地址转换网关将每个外部连接均匀转换为不同的内部服务器地址.因此.外部网络中的计算机就各自与自己转换的得到的地址上的服务器进行通信.从而达到负载均衡的目的.其中.网络地址转换网关位于外部地址和内部地址之间.不仅可以实现当外部客户端访问转换网关的某一外部地址时可以转发到某一映射的内部地址上.还可以使内部地址的计算机能访问外部网络.
常见负载均衡算法:
1.轮询调度算法:
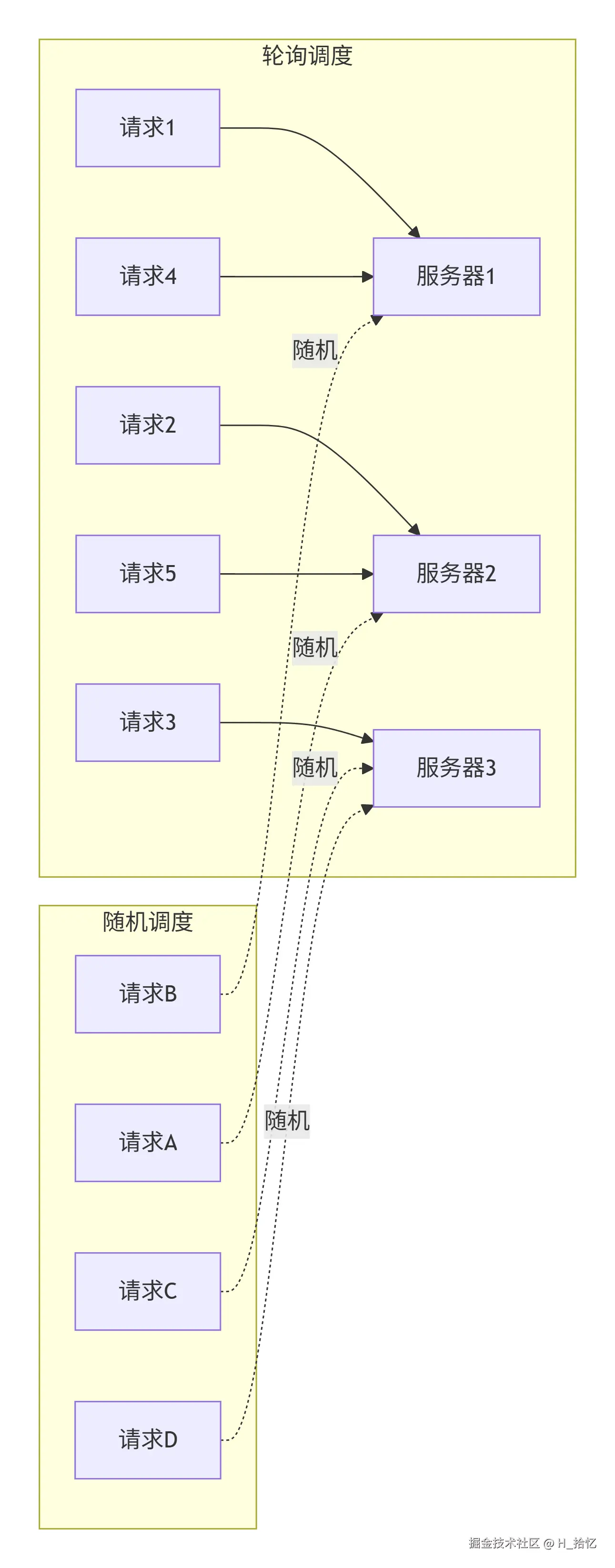
轮询调度算法是一种基础的负载均衡算法.它的原理是把来自用户的请求轮流分配给内部的服务器:从服务器1开始.直到服务器N.然后重新开始循环.轮询算法的优点在于简洁性.它无须记录当前所有连接的状态.所以它是一种无状态的调度.
示例:
go
package main
import (
"errors"
"fmt"
"sync"
)
var (
ErrNoAvailableItem = errors.New("没有可用项")
)
// 调度器实例.
type RoundRobinBalancer struct {
m sync.Mutex
next int
items []interface{}
}
// 实例化负载均衡器.
func New(item []interface{}) *RoundRobinBalancer {
return &RoundRobinBalancer{items: item}
}
// 选择可用项.
func (r *RoundRobinBalancer) Pick() (interface{}, error) {
if len(r.items) == 0 {
return nil, ErrNoAvailableItem
}
r.m.Lock()
defer r.m.Unlock()
i := r.items[r.next]
r.next = (r.next + 1) % len(r.items)
return i, nil
}
func main() {
source := []interface{}{"10.0.0.1", "10.0.0.2", "10.0.0.3"}
balancer := New(source)
wc := sync.WaitGroup{}
for i := 0; i < 10; i++ {
wc.Add(1)
go func() {
v, _ := balancer.Pick()
fmt.Printf("%v\n", v.(string))
wc.Done()
}()
}
wc.Wait()
}轮询调度算法将请求按顺序轮流的分配到每个节点上.不关心每个节点实际的连接数和当前的系统负载.优点是简单高效.易于水平扩展.每个节点都满足均衡.缺点是没有考虑机器的性能问题.根据木桶效益.集群性能瓶颈更多的会受到性能差的服务器的影响.
2.随机算法:
随机算法是指通过算法从服务器列表中随机选取一台服务器进行访问.结合概率论的相关知识可以得知.随着客户端调用服务端的次数增多.其实际效果趋近于平均分配请求到服务器端的每一台服务器.也就是达到轮询的效果.
假设有N台服务器S={S0,S1,S2 ... , Sn}.算法可以描述为.通过随机函数生成0~N之间的任意整数.将该数字做为索引.从S中获取对应的服务器.假定现在有4台服务器.初始化服务列表后.每台服务器对应一个地址.地址分别有相应的权重.
随机算法与权重没有关系.每个服务器会被随机的访问到.由概率论可以得知.当样本量足够大时.每台服务器被访问到的概率近似相等.随机算法的效果就趋近于轮询调度算法.将请求随机分配到各个节点.随着客户端调用服务端次数增多.其实际效果越来越接近于平均分配.也就是轮询的结果.优缺点和轮询相似.
示例:
go
package main
import (
"errors"
"fmt"
"math/rand"
"sync"
)
var (
ErrNoAvailableItem = errors.New("没有可用项")
)
// 调度器实例.
type RoundRobinBalancer struct {
m sync.Mutex
curIndex int
res []string
}
// 实例化负载均衡器.
func New(res []string) *RoundRobinBalancer {
return &RoundRobinBalancer{res: res}
}
// 生成下一个随机字符串.
func (r *RoundRobinBalancer) Next() string {
if len(r.res) == 0 {
return ""
}
r.m.Lock()
defer r.m.Unlock()
r.curIndex = rand.Intn(len(r.res))
return r.res[r.curIndex]
}
func main() {
source := []string{"10.0.0.1", "10.0.0.2", "10.0.0.3", "10.0.0.4"}
balancer := New(source)
wc := sync.WaitGroup{}
for i := 0; i < 4; i++ {
v := balancer.Next()
fmt.Printf("%v \n", v)
}
wc.Wait()
}3.一致性哈希算法:
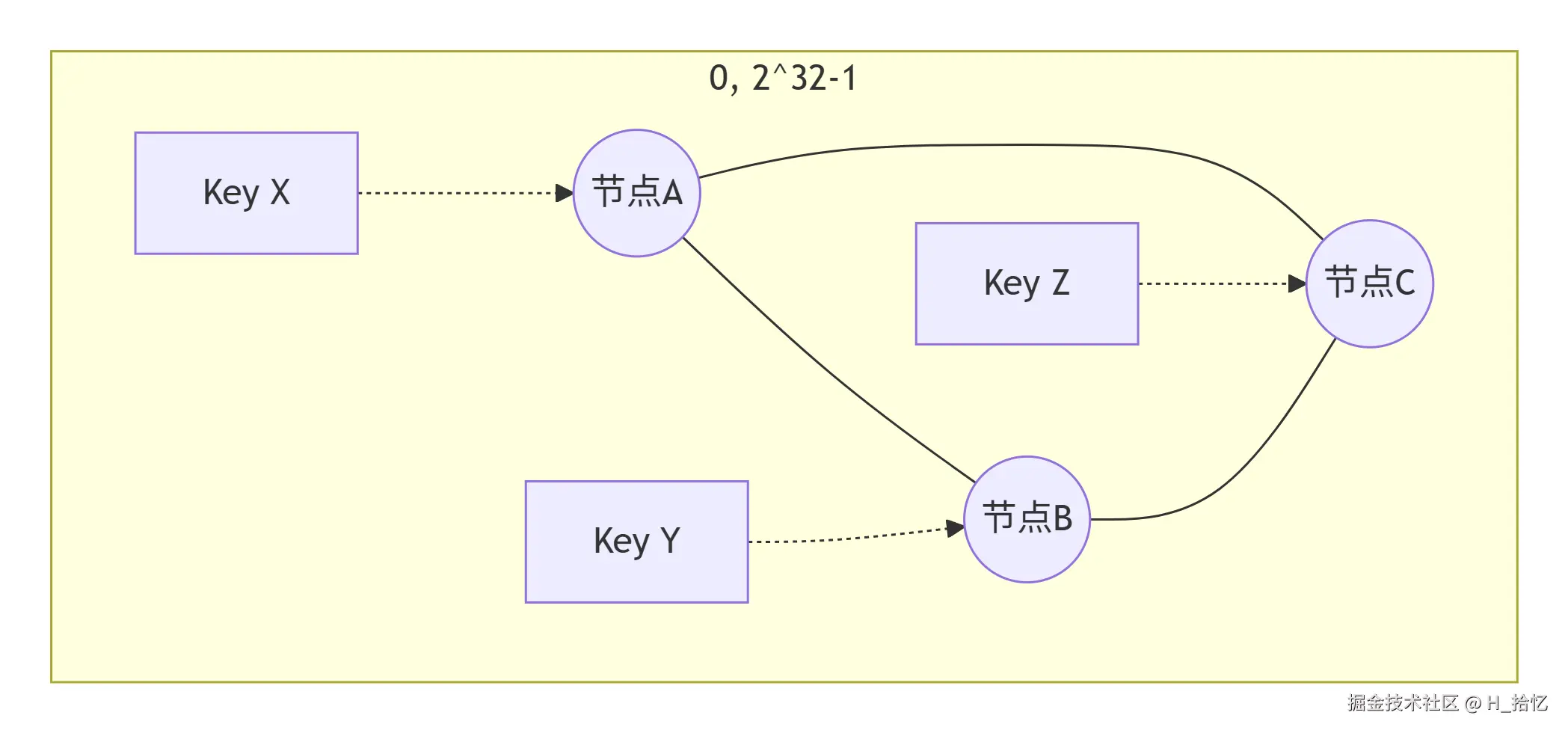
一致性哈希算法是根据请求来源的地址.通过哈希函数计算得到一个数值.用该数值对服务器列表的大小进行求余运算.得到结果便是客户端要访问的服务器的序号.采用一致性哈希算法进行负载均衡.同一源地址的请求.当服务器列表不变时.它每次都会映射到同一台服务器进行访问.
假设有N台服务器S={S0,S1,S2,...,Sn-1}
1).通过指定的哈希函数.计算请求来源地址的哈希值.
2).对哈希值进行求余.底数为N.
3).将余数作为索引值.从S中获取对应的服务器.
一致性哈希算法的优点是相同的地址每次都会落在同一个节点.可以人为干预客户端请求方向.缺点是如果某个节点出现故障.则会导致这个节点上的客户端无法使用.无法保证高可用.当某一用户成为热点用户.则会有巨大的流量涌向这个节点.导致冷热分布不均衡.无法有效利用集群的性能.所以当热点事件出现时.一般会将一致性哈希算法切换成轮询算法.
示例:
go
package main
import (
"fmt"
"github.com/golang/groupcache/consistenthash"
)
func main() {
//构建一个consistenthash对象.每个节点在hash环都有4虚拟节点.
hash := consistenthash.New(4, nil)
//添加节点.
hash.Add(
"10.0.0.1:8080",
"10.0.0.1:8081",
"10.0.0.1:8082",
"10.0.0.1:8083")
//根据key获取其对应的节点.
//Get获取散列(哈希)中与提供的键最接近的项目.
node := hash.Get("10.0.0.1")
fmt.Println(node)
}4.键值范围算法:
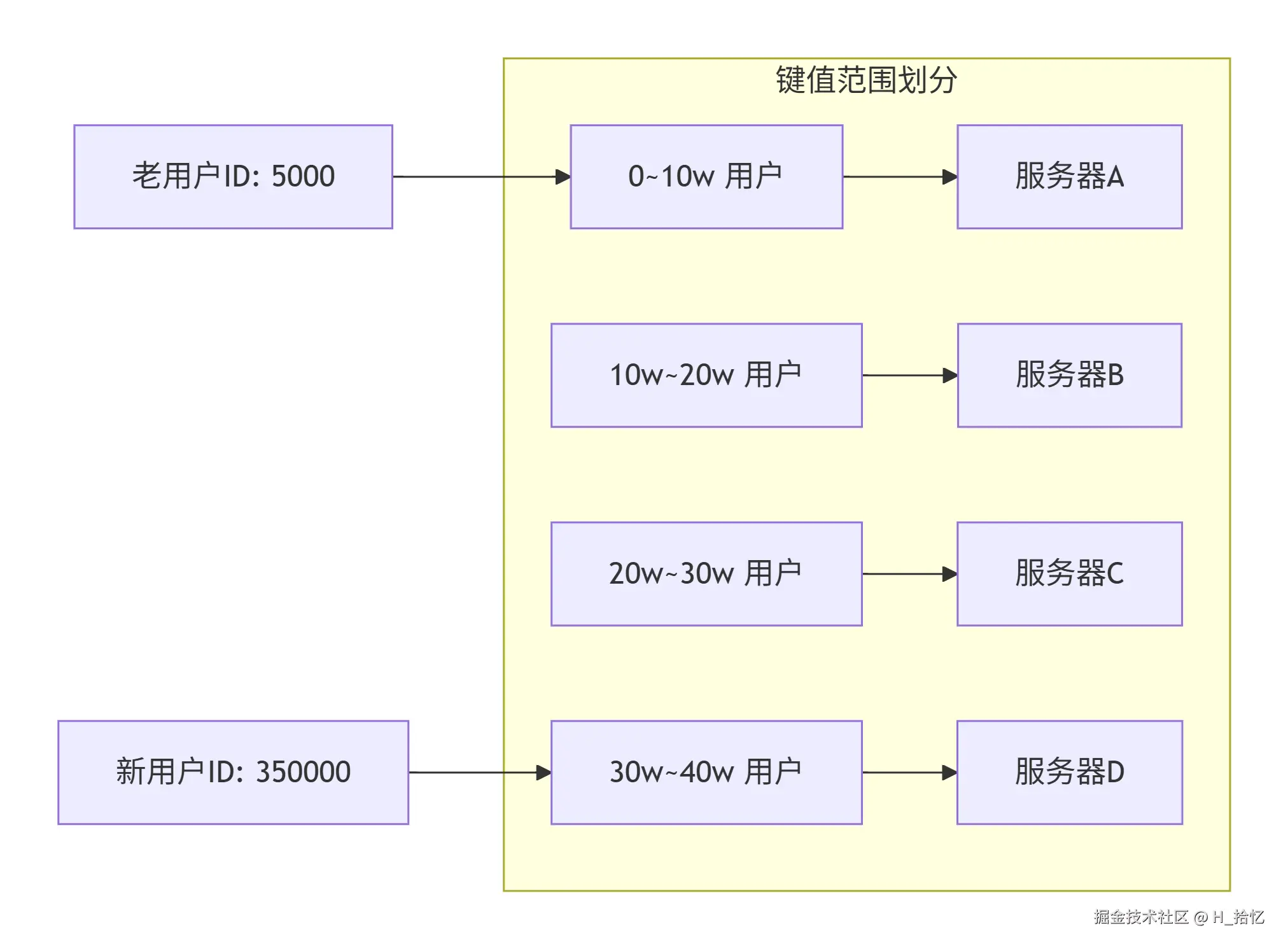
键值范围算法是根据键值的范围进行负载.比如0到10万的用户请求走第一个节点服务器.10万到20万的用户走请求的第二个节点服务器.以此类推.键值范围算法的优点是容易水平扩展.随着用户量增加.可以增加节点而不影响旧数据.缺点是容易负载不均衡.比如新注册的用户活跃度高.旧用户活跃度低.则压力就全在新增的服务器节点上了.旧服务器节点性能浪费.而也容易单点故障.无法满足高可用.
语雀地址www.yuque.com/itbosunmian...?
《Go.》 密码:xbkk 欢迎大家访问.提意见.