文章目录
- 一、数据类型
-
- 总览
- 五大基本类型
- 特殊类型
- 底层数据结构
-
- 总览
- 键值对数据库如何实现?
- SDS
-
- [C 语言字符串缺陷](#C 语言字符串缺陷)
- 数据结构
- [链表 list](#链表 list)
- [压缩链表 ziplist](#压缩链表 ziplist)
- [哈希表 hash](#哈希表 hash)
- [整数集合 inset](#整数集合 inset)
- [跳表 zskiplist](#跳表 zskiplist)
-
- [结构 & 查找](#结构 & 查找)
- 节点结构
- 跳表节点层数设置
- 为什么用跳表不用平衡树(红黑树)?
- quicklist
- listpack
-
- [对比 ziplist 的改动](#对比 ziplist 的改动)
- 总结
- 面试
- 二、持久化
- 三、缓存
- 四、分布式锁
- 五、高可用
-
-
- 高可用的三个层次
- 主从复制
- 哨兵(Sentinel)
- [Cluster 集群](#Cluster 集群)
-
- 是什么
- [数据分片:哈希槽(Hash Slot)](#数据分片:哈希槽(Hash Slot))
- 客户端是怎么知道该访问哪台机器的?
-
- [客户端自行缓存「槽 → 节点」的地图](#客户端自行缓存「槽 → 节点」的地图)
- [地图过期:MOVED 重定向](#地图过期:MOVED 重定向)
- [槽迁移:ASK 重定向](#槽迁移:ASK 重定向)
- [节点之间同步信息:Gossip 协议](#节点之间同步信息:Gossip 协议)
- [集群的故障转移 failover](#集群的故障转移 failover)
- [Cluster 的限制](#Cluster 的限制)
- 三种方案对比
- 面试
- 总结
-
- 六、原理
-
-
- [Redis 为什么这么快?](#Redis 为什么这么快?)
- 单线程模型
-
- [Redis 到底哪里是单线程?](#Redis 到底哪里是单线程?)
- 为什么命令执行用单线程?
- 单线程的执行流程
- [Redis 6.0 为什么引入多线程网络 IO?](#Redis 6.0 为什么引入多线程网络 IO?)
- [IO 多路复用](#IO 多路复用)
-
- [先理解网络 IO 的问题](#先理解网络 IO 的问题)
- [三种 IO 多路复用机制](#三种 IO 多路复用机制)
-
- select(最古老)
- [poll(改进版 select)](#poll(改进版 select))
- [epoll(Linux 主流,Redis 使用)](#epoll(Linux 主流,Redis 使用))
- [epoll 的两种触发模式](#epoll 的两种触发模式)
- [Redis 的事件驱动模型](#Redis 的事件驱动模型)
- [Redis 事务](#Redis 事务)
- 面试
- 总结
-
一、数据类型
总览
| 数据结构 | 底层实现 | 典型使用场景 |
|---|---|---|
| String | SDS动态字符串 | 缓存、计数器、分布式锁 |
| Hash | ziplist / hashtable | 存对象、购物车 |
| List | quicklist | 消息队列、最新列表 |
| Set | hashtable / intset | 去重、共同好友、抽奖 |
| ZSet | ziplist / skiplist | 排行榜、延迟队列 |
| BitMap | String扩展 | 签到、用户在线状态 |
| HyperLogLog | 概率算法 | UV统计 |
| GEO | ZSet(GeoHash 编码) | 附近的人、打车计算距离 |
| Stream | Radix Tree(基数树) + listpack | 消息队列(支持多消费族、消息持久化、ACK) |
五大基本类型
String
最大 512 MB
-
内部实现:int + SDS
- SDS 不仅可以保存文本数据,还可以保存二进制数据,如图片、音频等
- SDS 获取字符串长度的时间复杂度是 O(1),用
len属性 - Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出
字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr,可以把 Redis 存储数据想象成搬家包装
- int(极简装),整数类型直接用
redisObject里的指针位置存储,省略 SDS - embstr(一体化礼盒),小件物品,如 44 字节内的短字符串(Redis 5.0),使用
redisObject + SDS存储并放在一块连续的内存中 - raw(普通快递),大件,如长字符串,使用
SDS存储并且用redisObject记录存储位置,找的时候先去后者找位置再顺着位置找物品
embstr 实际上是只读的,一旦修改会暴力升级为 raw,因为其设计初衷就是为了极致的查询性能,分配的是固定大小的连续空间,一旦修改就有可能装不下,必须重新分配内存,即写时升级
-
常用命令
redis# 设置 key-value 类型的值(可带过期时间) SET name abc [EX seconds] # 根据 key 获得对应的 value GET name # 原子自增 +1 INCR key # 原子自增 +N INCRBY key 10 # 不存在才设置(not exists)(分布式锁的基础) SETNX name abc -
应用场景
# ① 缓存用户信息(JSON序列化存入) SET user:1001 '{"name":"xmon","age":21}' EX 3600 # 直接缓存整个对象的JSON # 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值 MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20 # ② 计数器(文章阅读数、点赞数) INCR article:read:8888 # 原子操作,不用担心并发问题 # ③ 分布式锁 SET lock:order:1001 uuid NX EX 30 # NX = 不存在才设置,保证只有一个人能拿到锁 # EX = 自动过期,防止死锁 # 释放锁时,先比较 uuid 是否相等,避免锁的误释放 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del" ,KEYS[1]) else return 0 end
List
有序、可重复的链表,支持两端操作,按照插入顺序排序
-
内部实现:双向链表或压缩列表
- 元素小于 512 个,值小于 64 字节,使用压缩列表
- 否则使用双向链表
在 Redis 3.2 之后,List 只由
quicklist实现,替代上面两者,从 Redis7.0 +,quicklist 节点内部用来保存元素的压缩列表也被listpack替代现在的 Quicklist 是一个双向链表,但每一个节点都是一个 Listpack,保证了插入删除的效率并且极大压缩了空间
-
常用命令
LPUSH list a b c # 从左边推入:c b a RPUSH list x # 从右边推入:c b a x LPOP list # 从左边弹出 RPOP list # 从右边弹出 LRANGE list 0 -1 # 查看全部元素 LLEN list # 长度 BLPOP list 10 # 阻塞式弹出,最多等10秒 -
应用场景
# ① 最新消息列表(只保留最新100条) LPUSH news:feed article:9999 LTRIM news:feed 0 99 # 只保留前100条 # ② 简单消息队列 # 生产者 RPUSH queue:email task_001 # 消费者(BLPOP 没消息时阻塞等待,不用轮询) BLPOP queue:email 0消息队列存取消息时的三个需求:消息保序(顺序性)、处理重复的消息(幂等性)和保证消息的可靠性(不丢失)
-
如何满足消息保序需求?
Redis List 本身就是天然保序的,实现时保证单进单出,发送方使用
LPUSH将消息按顺序放入队列,接收方使用RPOP/BRPOP按顺序取出并发问题:如果有多个消费者同时从 List 里拿消息,由于执行速度不同顺序会乱
解决:将需要保序的消息通过 Hash 取模,发往同一个特定的 List,并保证一个 List 只由一个消费者处理
-
如何处理重复的消息?
核心思想:做操作前先检查
解决方案:全局唯一 ID + 去重表
- 生成 ID:生产者发送消息时,给每条消息报一个全局唯一ID(雪花算法ID/订单号)
- 去重判断:消费者拿到消息时,先去 Redis 的
SET或String查一下这个 ID 是否存在- 没查到:新消息,处理业务,将 ID 存入 Redis
- 查到:重复消息,直接丢弃,不执行业务逻辑
-
如何保证消息可靠性?
消费者拿走消息后突然宕机,消息在内存中消失了
解决:使用
RPOPLPUSH指令(备份队列模式),让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存
⚠️ List 作消息队列有缺陷:不支持重复消费、无 ACK 机制。 生产环境消息队列建议用 Stream 或 RocketMQ/Kafka。
-
Hash
压缩列表或哈希表,适合存结构化对象
-
内部实现:压缩列表或哈希表
- 元素个数小于 512 个且所有值小于 64 字节,使用压缩列表
- 否则使用哈希表
Redis 7.0 ,压缩列表已废弃,交由 Listpack 实现
-
常用命令
HSET user:1001 name xmon age 21 city beijing # 存储一个哈希表key的键值 HGET user:1001 name # 取单个字段 HMGET user:1001 name age # 取多个字段 HGETALL user:1001 # 取全部 HDEL user:1001 name age # 删除字段 HLEN user:1001 # 返回filed数量 HINCRBY user:1001 age 1 # 某字段自增 -
应用场景
# ① 缓存对象 # 存储一个哈希表uid:1的键值 HMSET uid:1 name Tom age 152 # 存储一个哈希表uid:2的键值 HMSET uid:2 name Jerry age 13 # 获取哈希表用户id为1中所有的键值 HGETALL uid:1 # ② 购物车:key=cart:uid,field=商品id,value=数量 HSET cart:1001 item:5001 2 # 商品5001加2个 HINCRBY cart:1001 item:5001 1 # 再加1个 HGETALL cart:1001 # 获取完整购物车 HDEL cart:1001 item:5001 # 删除某商品
和 String 存 JSON 的对比:
| Hash | String+JSON | |
|---|---|---|
| 修改单字段 | ✅ 直接 HSET | ❌ 需要整个反序列化再序列化 |
| 内存 | 字段少时用 ziplist,省内存 | 相对多 |
| 适合场景 | 字段经常单独更新 | 整存整取 |
存储对象时,一般用String + Json,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储
Set
无序、不重复的集合,支持集合运算
-
内部实现:哈希表或整数集合
- 如果元素为整数且个数小于 512,使用整数集合
- 否则使用哈希表
-
常用命令
SADD set a b c # 添加元素 SREM set a # 删除元素 SISMEMBER set b # 判断是否存在 SMEMBERS set # 获取所有元素 SCARD set # 元素数量 # 集合运算 SINTER set1 set2 # 交集(共同好友) SUNION set1 set2 # 并集 SDIFF set1 set2 # 差集 SRANDMEMBER set 3 # 随机取3个(不删除) SPOP set 1 # 随机弹出1个(删除) -
应用场景
# ① 共同好友 SADD friends:A user1 user2 user3 SADD friends:B user2 user3 user4 SINTER friends:A friends:B # → user2, user3 # ② 抽奖(不重复中奖用SPOP,可重复用SRANDMEMBER) SADD lottery uid1 uid2 uid3 uid4 uid5 SPOP lottery 3 # 随机抽3个中奖用户 # ③ 文章标签 SADD article:8888:tags java backend redis SMEMBERS article:8888:tags
ZSet(Sorted Set)
有序、不重复 ,每个元素带一个 score 分数,按 score 自动排序,最强大的数据结构
-
内部实现:压缩列表或跳表
- 有序集合的元素小于128个,且值小于64字节,使用压缩列表
- 否则使用条表
Redis 7.0 压缩列表 -> Listpack
-
常用命令
ZADD rank 100 user1 200 user2 150 user3 ZRANGE rank 0 -1 WITHSCORES # 升序 ZREVRANGE rank 0 -1 WITHSCORES # 降序 ZRANK rank user1 # 升序排名 ZREVRANK rank user1 # 降序排名(排行榜用这个) ZSCORE rank user1 # 获取分数 ZINCRBY rank 50 user1 # 加分 ZRANGEBYSCORE rank 100 200 # 按分数范围查 -
应用场景
# ① 实时排行榜 ZINCRBY game:score 10 user1001 # 用户得了10分 ZREVRANGE game:score 0 9 WITHSCORES # 取前10名 # ② 延迟队列(score 存执行时间戳) ZADD delay:queue 1735000000 task_001 # 定时执行的任务 # 定时轮询:取 score <= 当前时间 的任务执行 ZRANGEBYSCORE delay:queue 0 [current_time]
特殊类型
BitMap
把每个 bit 位当作一个 boolean 用,极省内存 ,适合一些数据量大且使用二值统计的场景
-
内部实现:String
-
常用命令
SETBIT key offset value # 设置值,value只能为0/1 GETBIT key offset # 获取值 BITCOUNT key start end # 获取指定范围内为1的个数 -
应用场景
# ① 签到统计,1亿用户的签到,只需 ~12MB SETBIT sign:user:1001 20250101 1 # 1号签到 GETBIT sign:user:1001 20250101 # 查询某天 BITCOUNT sign:user:1001 # 统计签到总天数 # ② 连续签到用户总数 # 与操作:统计三天连续打卡的用户数 BITOP AND sign:user 20250101 20250102 20250103 # 统计 bit 位= 1 的个数 BITCOUNT sign:user
HyperLogLog
提供不精确的去重计数 :用极小内存(固定 12KB )估算集合的基数(不重复元素个数),误差约 0.81%
-
常用命令
PFADD uv:page:home user1 user2 user3 # 添加元素 PFCOUNT uv:page:home # 估算UV数量 PFMERGE uv:total uv:page:home uv:page:about # 合并 -
应用场景
# 每次用户访问,记录 uid PFADD uv:2025:0101 user_001 PFADD uv:2025:0101 user_002 PFADD uv:2025:0101 user_001 # 重复访问,不计入 PFCOUNT uv:2025:0101 # → 2
UV 不需要精确值,允许少量误差,HyperLogLog 是最优解 如果用 Set 存 uid,1000万用户要几百MB;HyperLogLog 永远只用 12KB
GEO
-
内部实现:没有设计新的底层数据结构,而是直接使用ZSet 集合
-
应用场景
# 滴滴打车 # ID号为33的车辆的当前经纬度位置存入 GEO 集合中 GEOADD cars: locations 116.034579 39.03045233 # 查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用 GEORADIUS cars: locations 116.05457939.030452 5 km ASC COUNT10
Stream
Redis5.0 新增,是专门为消息队列设计的数据类型,它支持消息的持久化、支持自动生成全局唯一ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
-
常用命令
-
XADD:向流中添加消息(自动生成唯一 ID) -
XLEN:查询消息长度 -
XREAD:直接读取消息(支持阻塞模式) -
XDEL:根据 ID 删除消息 -
DEL:删除整个 stream -
XGROUP CREATE:创建消费组 -
XREADGROUP:组内成员读取消息(读取后消息进入 PEL 列表) -
XPENDING和XACK-
XPENDING:查询每个消费组内所有消费者「已读取、但尚未确认」的消息 -
XACK:确认消息处理完成,将其从 PEL(未确认列表)中移除
-
-
-
应用场景
# 消息队列 XADD mymq * name xiaolin # 生产者通过 XADD 命令插入一条消息 XREAD STREAMS mymq 1654254953807-0 # 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息 XREAD BLOCK 10000 STREAMS mymq $ # 阻塞读,命令最后的"$"符号表示读取最新的消息 # 特有功能 # 1.XGROUP 创建消费组 XGROUP CREATE mymq group1 0-0 # 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取 XREADGROUP GROUP group1 consumer1 STREAMS mymq > # 命令最后的参数">",表示从第一条尚未被消费的消息开始读取基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处
理完的消息?
消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息
小结
- 消息保序:XADD/XREAD
- 阻塞读取:XREAD block
- 重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一ID;
- 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING命令查看消费组已经读取但是
未被确认的消息,消费者使用 XACK确认消息; - 支持消费组形式消费数据
Redis 基于 Stream 消息队列与专业的消息队列有哪些差距?
1、Redis Stream 消息会丢失吗?
Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
2、Redis Stream 消息可堆积吗?
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧
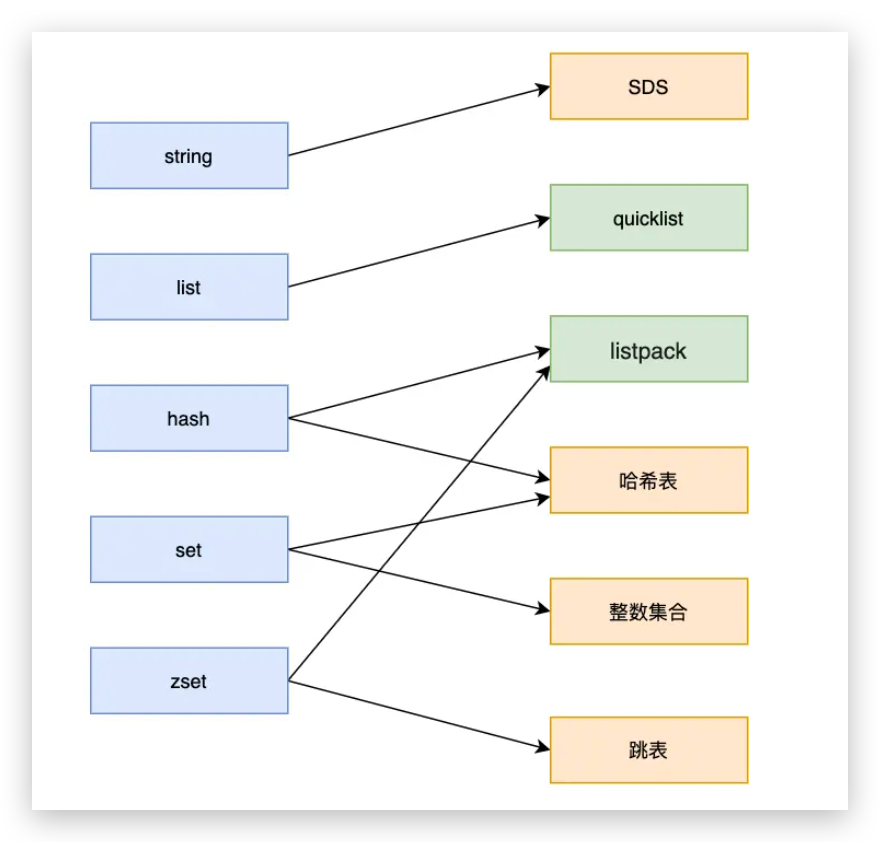
底层数据结构
指的并不是 String, List, Hash, Set, ZSet 等数据类型(数据的保存形式),这些对象底层实现就用到了数据结构,它们的对应关系如下
总览

键值对数据库如何实现?
实现:一个全局的哈希表(Dict)加上多态的底层数据结构(redisObject)
核心机制:
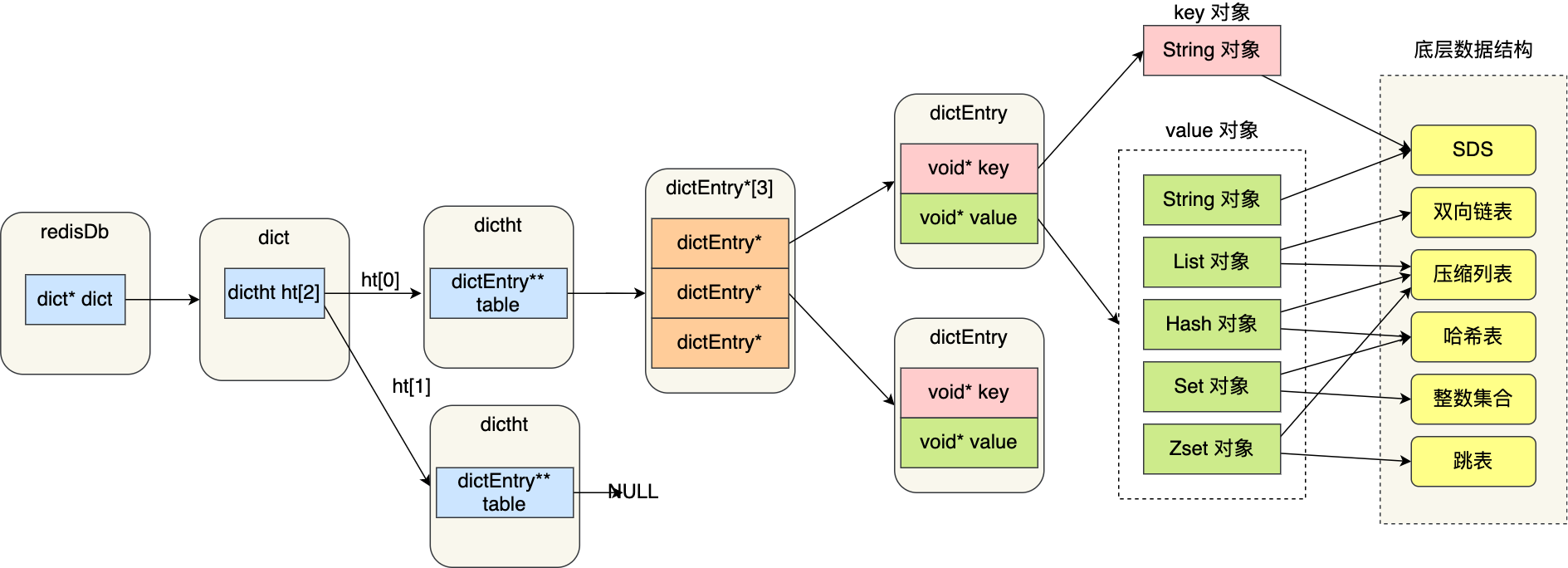
-
全局哈希表 Global Hash Table
每个数据库的底层都是一个
redisDb结构体,其中有最重要的dict字典结构- 全局哈希表由一个一维数组组成,数组的每个元素指向一个哈希桶 Bucket
- 当执行 GET/SET 时,Redis 会计算哈希值,然后对数组长度取模定位到对应的哈希桶(O(1))
-
万物皆可 redisObject
全局哈希表中,Key 为固定字符串,由 SDS 实现,目的是解决获取长度为 O(N) + 杜绝缓冲区溢出 + 实现二进制安全,Value 则被统一包装成 redisObject
ctypedef struct redisObject { unsigned type:4; // 逻辑类型:String, List, Hash, Set, Zset 等 unsigned encoding:4; // 物理编码:如 int, embstr, raw, hashtable, skiplist 等 // 通过 type 和 encoding 的解藕,Redis 可以在不同场景下无缝切换底层结构 unsigned lru:LRU_BITS; // 记录最后一次被访问的时间(用于内存淘汰策略) int refcount; // 引用计数(用于内存回收) void *ptr; // 指向底层实际数据结构的指针 } robj; -
哈希冲突与链式哈希 Chained Hashing
链地址法解决哈希冲突:当多个 Key 被映射到同一个哈希桶时,它们会被组织成一个单向链表,新插入的节点采用头插法,因为 Redis 认为新插入的数据更容易被再次访问
-
渐进式 Rehash Progressive Rehash
数据不断写入 -> 哈希冲突增多 -> 链表加长 -> 查询性能下降 -> 哈希表扩容(Rehash)
考虑到一次性完成数据迁移引起线程阻塞问题,因此设计Rehash:
- 双表机制:
dict结构包含两个哈希表数组ht[0](default) &ht[1] - 分配空间:扩容时,先为
ht[1]分配两倍于ht[0]的空间 - 分批迁移:维护一个索引计数器
rehashidx,在 Rehash 期间,每次处理 CRUD 时 Redis 会顺手将ht[0]在rehashidx索引上的所有键值对迁移到ht[1],然后rehashidx ++ - 无缝切换:当数据迁移完毕后,将
ht[1]设置为ht[0],并释放原来的ht[0]
Rehash 期间,先查
ht[0]再查ht[1],SET 操作一律写入ht[1],保证ht[0]只减不增 - 双表机制:
SDS
C 语言字符串缺陷
- 获取字符串长度时间复杂度为 O(N)
- 字符串不能含有 "\0" 字符,因此其不能保存像图片、音频、视频文化这样的二进制数据
- 字符串不会记录自身缓冲区大小,操作函数不高效不安全,有缓冲区溢出的风险,可能导致程序终止
数据结构
c
struct sdshdr {
int len; // 已使用长度
int alloc; // 分配的总长度
char flags; // 类型标识
char buf[]; // 实际数据
};-
len,记录字符串长度:时间复杂度 O(1)(使得字符串能含有 \0 字符,能保存图片、音频等)
-
alloc,分配给字符数组的空间长度 :修改字符串->
alloc - Len计算剩余空间 -> 不满足,扩容(解决缓冲区溢出和)修改后长度 < 1MB → 额外分配同等大小(len * 2) 修改后长度 ≥ 1MB → 额外分配 1MB惰性空间释放:字符串缩短时不立即释放内存,len 减小但 alloc 不变,下次增长直接用
-
flags,用来表示不同类型的SDS :5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、
sdshdr32 和 sdshdr64,它们数据结构中的 len 和 alloc 成员变量的数据类型不同,目的是为了能灵活保存不同大小的字符串,从而有效节省内存空间
-
buf\[\],字节数组,保存实际数据:不仅可以保存字符串,也可以保存二进制数据
链表 list
Redis 实现了一个经典的双向链表
结构
c
// 节点
typedef struct listNode {
struct listNode *prev; // 前置节点
struct listNode *next; // 后置节点
void *value; // 节点的值,void* 可以存任意类型
} listNode;
// 链表
typedef struct list {
listNode *head; // 链表头节点
listNode *tail; // 链表尾节点
unsigned long len; // 链表节点数量
void *(*dup)(void *ptr); // 复制函数
void (*free)(void *ptr); // 释放函数
int (*match)(void *ptr, void *key); // 比较函数
} list;优点:
- 双向:每个节点有 prev/next,方便从两端操作
- 带头尾指针:获取头尾节点 O(1)
- 带长度:获取长度 O(1)
- 无环:头的 prev 和尾的 next 都是 NULL
- 多态 :通过
void*+ 函数指针支持存储任意类型
缺点(也是为什么后来被取代的原因)
- 每个节点单独分配内存,内存不连续,碎片多,缓存命中率低,CPU 缓存不友好
- 每个节点有 prev/next 两个指针,额外内存开销大
Redis 3.2 之后 List 类型的底层已经不用 linkedlist,改用 quicklist
压缩链表 ziplist
为了节省内存设计的紧凑型连续内存结构,没有指针,所有数据挨在一起
内存布局

- zlbytes:整个 ziplist 占用字节数
- zltail :尾部节点距离起始地址有多少字节,即最后一个 entry 的偏移量(方便从尾部操作)
- zllen :entry 数量
- zlend :结束标志,固定 0xFF(十进制255)
每个 entry 的结构
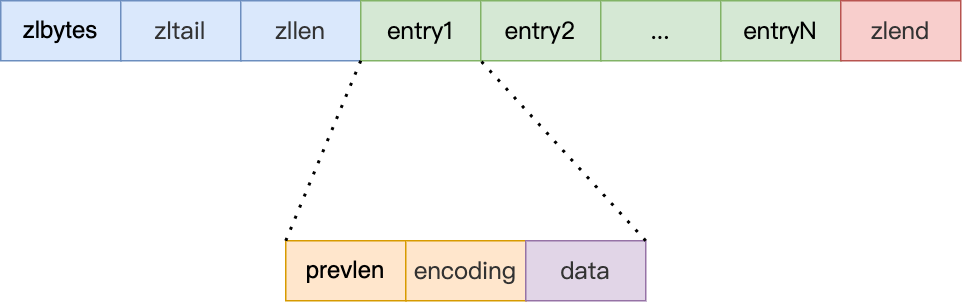
- previous_entry_length:前一个entry的长度(用于从后往前遍历)
- encoding:数据类型(字符串和整数)和长度
- data:实际数据(整数或字节数组)
插入数据时,会根据数据大小和类型会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息(节省内存)
优点
- 内存连续紧凑,没有指针开销
- 小整数用特殊 encoding 直接编码,极省内存
致命缺点:连锁更新
ziplist 中,每个节点都会记录前一个节点的长度(prevlen):
-
如果前一个节点长度 < 254 字节 ,
prevlen占用 1 字节 -
如果前一个节点长度 ≥ 254 字节 ,
prevlen占用 5 字节假设有 N 个 entry,每个 previous_entry_length 都是 1 字节(前一个entry长度<254)且长度都在 250-253 字节之间
现在在头部插入一个大 entry(长度≥254)
→ 第1个entry的 previous_entry_length 需要从1字节扩为5字节
→ 第1个entry变大了,第2个entry的 previous_entry_length 也要扩
→ 第2个entry变大了,第3个entry也要扩...
→ 最坏情况 O(n) 次内存重分配!
这就是连锁更新(cascade update),是 ziplist 被 listpack 取代的直接原因
哈希表 hash
Redis 的哈希表实现,也是 HashMap 的经典实现思路。
数据结构
c
typedef struct dict {
dictht ht[2]; // 两个哈希表!用于渐进式 rehash
int rehashidx; // -1 表示未在 rehash
} dict;
typedef struct dictht {
dictEntry **table; // 数组,每个槽是链表头
unsigned long size; // 数组大小(2的幂次)
unsigned long sizemask; // size-1,用于取模
unsigned long used; // 已有节点数
} dictht;
typedef struct dictEntry {
void *key; // 键值对中的键
union { // 键值对中的值
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,形成链表
} dictEntry;
哈希表的优点在于,它能以 O(1) 的速度快速查询速度(将 key 通过 hash 函数计算),但随着数据的不断增多,哈希冲突的可能性也会越高
哈希冲突
哈希表是一个数组,数组中每一个元素就是一个哈希桶
**什么是哈希冲突?**当有两个以上数量的 kay 被分配到了哈希表中同一个哈希桶上时,此时称这些 key 发生了冲突
有一个可以存放8个哈希桶的哈希表,key1 经过哈希函数计算后并取模,结果值为 1,那么就对应哈希桶1,类似的,key9和 key10分别对应哈希桶 1 和桶 6,此时,key1 和 key9 对应到了相同的哈希桶中,这就发生了哈希冲突
链地址法 :冲突时新节点插入链表头部(O(1))
table[0] → entry_A → entry_B → NULL
table[1] → NULL
table[2] → entry_C → NULL链式哈希的局限性也很明显,随着链表长度增加,查询这一位置上的数据的耗时就会增加(O(n)),此时需要对哈希表的大小进行扩展(rehash)。
渐进式 rehash
负载因子 = 哈希表已保存节点数量 / 哈希表大小(used/size)
为什么需要 rehash? 负载因子(load factor)过高时查询退化,需要扩容。
为什么是渐进式? 如果一次性把几百万个 key 全部迁移,Redis 会卡住很长时间,影响服务。
渐进式 rehash 过程:
1. 分配 ht[1],大小为 ht[0] 的 2 倍
2. 设置 rehashidx = 0,表示从第 0 个桶开始迁移
3. 每次对 dict 的增删改查操作,顺带迁移 rehashidx 对应桶的数据
4. 同时查询时,ht[0] 和 ht[1] 都查
新写入只写 ht[1]
5. rehashidx 逐渐递增,直到 ht[0] 全部迁移完
6. ht[0] = ht[1],rehashidx = -1,完成
时间线:
[操作1] 迁移 bucket[0],rehashidx=1
[操作2] 迁移 bucket[1],rehashidx=2
...
[操作n] 迁移完所有桶,rehash 结束渐进式的代价: rehash 期间同时存在两张表,内存占用翻倍。
触发条件
- load factor >= 1 && 未执行 RDB 快照(bgsave)或 AOF 重写(bgrewriteaof)
- load factor >= 5
整数集合 inset
Set 里全是整数且数量少时使用,比 hashtable 省内存。
结构
c
typedef struct intset {
uint32_t encoding; // 编码方式:int16 / int32 / int64
uint32_t length; // 元素数量
int8_t contents[]; // 元素数组(有序!)
} intset;特性
- 元素有序存储 ,查找用二分查找 O(log n)
- 内存连续紧凑,无指针开销
升级机制
当新插入的整数超出当前 encoding 范围时,自动升级:
原来全是 int16(−32768~32767)
插入 100000(超出int16范围)
→ 整体升级为 int32,所有元素重新编码
→ 升级是不可逆的,不会因为删了大数就降级升级的好处: 平时用小类型省内存,需要时才扩,灵活节约。
跳表 zskiplist
ZSet 的核心底层结构,是有序链表的多级索引版本。
结构 & 查找
level 3: 1 ──────────────────── 50 ──────────────── 100
level 2: 1 ──────── 20 ──────── 50 ──────── 80 ──── 100
level 1: 1 ── 10 ── 20 ── 30 ── 50 ── 60 ── 80 ──── 100图中头节点有LO~L2三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
-
L0层级共有 5个节点,分别是节点1、2、3、4、5;
-
L1 层级共有3个节点,分别是节点 2、3、5;
-
L2 层级只有1个节点,也就是节点3。
查找节点4,从最高层开始:
L2: 3,4>3,下降到 L1
L1: 3 → 5,5>4,下降到 L0
L0: 3 → 4,找到!
时间复杂度期望 O(log n)。
节点结构
c
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 分数,用于排序
struct zskiplistNode *backward; // 后退指针(只有第1层有)
// 节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨越的节点数(用于计算排名)
} level[];
} zskiplistNode;span(跨度)的作用: 每个指针记录跨越了多少节点,累加即可得到节点的排名,ZRANK 因此是 O(log n)。
层高怎么决定?:随机决定,每个节点的层高 = 1 的概率是 1/2,每多一层概率减半(最高 32 层)。这保证了整体的概率平衡,期望效果接近平衡树。
跳表节点层数设置
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN),那么如何维持这个比例?
跳表在创建节点的时候,随机生成每个节点的层数:
创建节点时,会生成范围为[0-1]的一个随机数,如果这个随机数小于0.25,那么层数就增加1层,然后继续生成下一个随机数,直到随机数的结果大于 0.25结束,最终确定该节点的层数。
如果层高最大限制是 64,那么在创建跳表「头节点」的时候,就会直接创建 64 层高的头节点
为什么用跳表不用平衡树(红黑树)?
| 维度 | 跳表 | 红黑树 |
|---|---|---|
| 底层结构 | 多级有序链表 | 自平衡二叉搜索树 |
| 逻辑核心 | 随机性(抛硬币决定层数) | 确定性(旋转和变色) |
| 范围查询能力 | 极强,天然支持顺序遍历 | 一般,需要中序遍历 |
| 代码复杂度 | 低(几百行搞定) | 高(需要处理复杂的删除情况) |
| 内存开销 | 略高(平均每个节点 1.33 ∼ 2 1.33 \sim 2 1.33∼2 个指针) | 略低(每个节点固定 3 指针 + 颜色位) |
- 实现简单:跳表代码非常直观,更容易调试和维护,而平衡树的插入和删除操作可能引发子树的调整,逻辑复杂。对于注重底层性能和代码质量的项目来说,简单往往意味着更少的 Bug。
- 范围查询效率:在跳表中,找到范围的起点后,只需在最底层链表顺序遍历即可。红黑树做范围查询则需要进行繁琐的中序遍历。
- 内存占用灵活:平衡树每个节点包含 2个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数p 的大小。如果像 Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
quicklist
linkedlist + ziplist 的结合体,List 类型的实际底层实现(Redis 3.2+)。
内存结构
c
typedef struct quicklist {
quicklistNode *head; // quicklist 的链表头
quicklistNode *tail; // quicklist 的链表尾
unsigned long count; // 所有压缩列表中的总元素个数
unsigned long len; // quicklistNodes 的个数
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev; // 前一个 quicklistNode
struct quicklistNode *next; // 后一个 quicklistNode
unsigned char *zl; // quicklistNode 指向的压缩列表
unsigned int sz; // 压缩列表的的字节大小
unsigned int count : 16; // ziplist 中的元素个数
} quicklistNode;设计思路
linkedlist:内存分散,指针开销大
ziplist:内存紧凑,但连锁更新风险大、不能太长
折中方案:
用链表把多个 ziplist 串起来
每个链表节点是一个 ziplist(控制在一定大小内)-
每个 ziplist 节点最多存多少个 entry
list-max-ziplist-size 128 # 默认128个
-
两端各压缩几个节点(0=不压缩,中间节点访问少,压缩省内存)
list-compress-depth 0
优点
- 链表部分解决了 ziplist 不能太长(连锁更新)的问题
- ziplist 部分解决了 linkedlist 内存分散的问题
- 两端操作 O(1),整体内存比 linkedlist 小很多
listpack
Redis 5.0 引入,ziplist 的改进版,目标是彻底解决连锁更新问题。
对比 ziplist 的改动
ziplist 的 entry:
| previous_entry_length | encoding | data |
↑ 存前一个entry的长度,是连锁更新的根源listpack 的 entry:
| encoding | data | element-total-len |
↑ 存的是当前entry自己的长度改动的意义: 每个 entry 只记录自己的长度,和前一个 entry 完全解耦。 修改任意 entry,不会影响其他 entry,彻底消除连锁更新。
从后往前遍历:读当前 entry 尾部的 element-total-len,直接跳到前一个 entry 的起始位置。
现状:Redis 7.0 之后 ziplist 已全面被 listpack 替代:
- Hash、ZSet 的小数据底层:ziplist → listpack
- quicklist 的每个节点:ziplist → listpack
总结
| 结构 | 内存 | 查询 | 核心问题 | 现状 |
|---|---|---|---|---|
| linkedlist | 大(指针开销) | O(n) | 内存碎片 | 已废弃 |
| ziplist | 小(连续) | O(n) | 连锁更新 | 被listpack替代 |
| hashtable | 中 | O(1) | rehash期间内存翻倍 | 在用 |
| skiplist | 中 | O(log n) | 实现略复杂 | 在用 |
| intset | 最小 | O(log n) | 只能存整数 | 在用 |
| quicklist | 中 | O(n) | --- | 在用(List底层) |
| listpack | 小(连续) | O(n) | --- | 当前最新 |
面试
Q:Redis 数据类型以及使用场景分别是什么?
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2版新增)、HyperLogLog (2.8版新增)、GEO(3.2版新增)、Stream(5.0版新增)。
Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session信息等。
- List 类型的应用场景:消息队列、最新动态/时间轴(用户最新的 10 条浏览记录)等
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。形式消费数据)等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生
成全局唯一消息ID,支持以消费组形式消费数据。
Q:五种常见的 Redis 数据类型如何实现?
String
String 类型的底层的数据结构实现主要是SDS(简单动态字符串)。SDS和我们认识的C字符串不太一样,之所以没有使用C语言的字符串表示,因为 SDS 相比于 C的原生字符串:
- SDS 不仅可以保存文本数据,还可以保存二进制数据。
- SDS 获取字符串长度的时间复杂度是 O(1) 。
- Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。
List
List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于 512个(默认值,可由 list-max-ziplist-entries 配置),且列表每个元素的值都小于64字节(默认值,可由 list-max-ziplist-value 配置),使用压缩列表;
- 如果列表的元素不满足上面的条件,使用双向链表;
Redis 3.2 +,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。
Hash
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希类型元素个数小于 512个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于64 字
节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作 Hash 类型的底层数
据结构;- 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
Set
Set 类型的底层数据结构是由哈希表或整数集合实现的:
- 如果集合中的元素都是整数且元素个数小于 512(默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
ZSet
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于128个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为
Zset 类型的底层数据结构;- 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由listpack 数据结构来实现了。
二、持久化
为什么需要持久化?
Redis 数据全在内存,进程崩溃或服务器重启,数据全丢。持久化就是把内存数据写到磁盘,重启后能恢复。
Redis 提供三种方案:
持久化方案
├── RDB(快照)
├── AOF(日志)
└── RDB + AOF 混合(推荐)RDB(Redis Database Backup)
把某一时刻内存中全量数据 以二进制快照的形式写入磁盘(全量快照 ),文件名默认 dump.rdb。
触发方式
-
手动触发
bashSAVE # 同步,直接在主线程执行,期间阻塞所有命令(生产不用) BGSAVE # 异步,fork 子进程写 RDB,主线程继续服务 -
自动触发(配置文件)
bash# 满足任意一条就触发 BGSAVE save 900 1 # 900秒内有 1 次写操作 save 300 10 # 300秒内有 10 次写操作 save 60 10000 # 60秒内有 10000 次写操作 -
其他自动触发场景
-
执行
SHUTDOWN命令时 -
主从复制时,主节点自动 BGSAVE 发给从节点
-
BGSAVE 核心原理:fork + COW
主进程
│
├── fork() ──→ 子进程(复制主进程的页表,极快)
│ │
│ └── 遍历内存,写 RDB 文件
│
└── 继续处理客户端请求Copy-On-Write(写时复制):
fork 出来的子进程和主进程共享同一块物理内存,并不是真的复制所有数据。
fork 后:
主进程页表 ──┐
├──→ 同一块物理内存
子进程页表 ──┘
主进程收到写请求,要修改某个 key:
→ 操作系统把该内存页复制一份
→ 主进程修改自己的副本
→ 子进程继续读原始页,写 RDB
最终子进程写的是 fork 那一刻的内存快照COW 的代价: 如果 fork 期间写操作非常多,大量内存页被复制,内存占用可能接近 2 倍,需要注意预留内存。
RDB 文件格式
| REDIS魔数 | 版本号 | 数据库数据 | EOF标志 | CRC64校验 |重启时 Redis 读取 RDB 文件,把数据全量加载回内存。
优缺点
优点:
- 文件紧凑,体积小,恢复速度快
- BGSAVE 对主线程影响小
- 适合全量备份和灾难恢复
缺点:
- 两次快照之间的数据会丢失(最多丢几分钟数据)
- fork 子进程本身有开销,数据量大时 fork 耗时可能达到秒级,期间主线程卡顿
AOF(Append Only File)
把每条写命令 以文本形式追加到 AOF 文件(默认 appendonly.aof),恢复时重放所有命令。
bash
# 开启 AOF
appendonly yesAOF 写入流程
客户端写命令
↓
执行命令(先写内存)
↓
写入 AOF 缓冲区(aof_buf)
↓
根据刷盘策略 → 写入磁盘注意:Redis 先执行命令,再写 AOF(和 MySQL WAL 先写日志相反) 好处:不会因为命令语法错误污染 AOF;坏处:执行后崩溃来不及写日志,会丢当前命令
三种刷盘策略
bash
appendfsync always # 每条命令都 fsync → 最安全,性能最差
appendfsync everysec # 每秒 fsync 一次 → 最多丢1秒数据(推荐)
appendfsync no # 由操作系统决定何时 fsync → 最快,最不安全| 策略 | 丢数据风险 | 性能 | 适用场景 |
|---|---|---|---|
| always | 几乎不丢 | 最差 | 金融,不允许丢数据 |
| everysec | 最多丢1秒 | 好 | 绝大多数业务 |
| no | 可能丢较多 | 最好 | 可以接受丢数据 |
AOF 重写(Rewrite)
Q: AOF 只追加,文件越来越大。同一个 key 被修改100次,AOF 里有100条记录,但实际只需要最后一条。
A:AOF 重写 ------ 对当前内存数据生成等价的最小命令集,替换旧 AOF 文件。
bash
# 手动触发
BGREWRITEAOF
# 自动触发配置
auto-aof-rewrite-percentage 100 # 文件比上次重写后大 100% 时触发
auto-aof-rewrite-min-size 64mb # 且文件大小至少 64MBBGREWRITEAOF 流程:
主进程 子进程
│ │
触发重写 │──── fork() ──────────────────→│
│ (短暂阻塞,复制页表) │
│ │ 遍历内存
继续处理 │ │ 生成等价命令
写命令 │ │ 写入新AOF
│ │
写命令A ──→ ① 旧AOF │
│ ② 重写缓冲区[A] │
写命令B ──→ ① 旧AOF │
│ ② 重写缓冲区[A,B] │
│ │ 写完,发信号
│←────────────────────────────── │
│
把缓冲区 ──→ 追加[A,B]到新AOF
(短暂阻塞)
│
rename ──→ 新AOF替换旧AOF
│
完成 ✅Redis 7.0 引入的 Multi Part AOF(MP-AOF)
Redis 7.0 + ,重构了 AOF 重写机制,引入了 Multi Part AOF(MP-AOF),它把 AOF 拆分成了多个文件进行管理:
- 一个清单文件 manifest :记录当前 AOF 由哪些文件组成;
- 一个基础文件 base:使用 RDB 格式保存重写开始那一刻内存中的全量数据;
- 若干个增量文件 incr :使用 AOF格式记录重写开始之后新产生的写命令。
重写过程:
- 重写开始时,主进程先打开一个新的
incr文件,之后新的写命令会直接追加到这个新的incr里,而
不再写入「AOF 重写缓冲区」;- 子进程负责把当前内存状态以 RDB 格式写入到一个新的
base文件;- 重写完成后,Redis 只需原子地更新
manifest文件,让它指向新的base和新的 incr 即可,旧的
base和旧的incr可以安全删除。
优缺点
优点:
- 数据安全性高,最多丢1秒(everysec 策略)
- AOF 文件是可读的文本,误操作可以手动编辑恢复
误删恢复例子:
bash
# 手抖执行了 FLUSHALL
# 立刻停 Redis,找到 AOF 文件
# 删掉最后一行 FLUSHALL 命令
# 重启 Redis,数据恢复缺点:
- 文件比 RDB 大得多
- 重放命令恢复速度比 RDB 慢
- 高并发写时 always 策略性能瓶颈明显
RDB + AOF 混合持久化
Redis 4.0 引入,解决 AOF 恢复慢的问题。
开启方式
bash
aof-use-rdb-preamble yes # 开启混合持久化
appendonly yes # 同时要开启 AOF原理
AOF 重写时不再全写命令,而是:
新 AOF 文件结构:
┌─────────────────────────────────────────┐
│ RDB 部分(fork那一刻的全量二进制快照) │ ← 快,紧凑
├─────────────────────────────────────────┤
│ AOF 部分(重写期间新产生的写命令) │ ← 增量日志
└─────────────────────────────────────────┘恢复流程
读 AOF 文件
→ 前半段是 RDB 格式 → 快速加载全量数据
→ 后半段是 AOF 格式 → 重放增量命令
→ 完成恢复好处:
- 恢复速度接近 RDB(主体是二进制快照)
- 数据完整性接近 AOF(增量部分补全快照后的数据)
对比
| RDB | AOF | 混合 | |
|---|---|---|---|
| 数据安全 | 差(可能丢分钟级) | 好(最多丢1秒) | 好 |
| 恢复速度 | 快 | 慢 | 快 |
| 文件大小 | 小 | 大 | 中 |
| 系统开销 | 中(fork) | 中(fsync) | 中 |
| 适用场景 | 备份/可接受丢数据 | 不允许丢数据 | 生产推荐 |
RDB 是快照 ,恢复快但可能丢数据;AOF 是日志 ,安全但恢复慢;混合持久化结合两者优点,是生产环境首选。RDB + AOF 混合持久化
Redis 大 Key 对持久化有什么影响?
什么是大 Key?
String → value 超过 10KB 算大,超过 1MB 算非常大
List/Hash/Set/ZSet → 元素数量超过 10000,或总大小超过 10MB
对 RDB 快照的影响
-
fork 时内存占用翻倍风险更高
大 Key 意味着内存占用大,fork 子进程后如果主线程继续写这个大 Key,COW 会复制整个内存页。
普通情况:修改小 key → 只复制一个内存页(4KB) 大 Key: 修改一个 100MB 的 value → 复制大量内存页 → 内存峰值可能暴涨,OOM 风险 -
RDB 文件变大,写磁盘时间变长
一个大 Key 可能占 RDB 文件很大比例,导致:
- 子进程写磁盘时间变长
- 主从全量同步时传输 RDB 耗时增加,同步变慢
对 AOF 日志的影响
-
AOF 写入放大
大 Key 每次修改,AOF 追加的命令体积就很大。
bash# 比如一个 100MB 的 String,每次 SET 都往 AOF 追加 100MB SET big_key <100MB数据> -
AOF 重写时间变长
BGREWRITEAOF子进程遍历内存生成新 AOF,遇到大 Key 需要写大量数据,重写期间:- 子进程写磁盘时间拉长
- 重写缓冲区积压更多命令(因为重写时间长)
- 最后把缓冲区追加到新 AOF 时,主线程阻塞时间变长
对混合持久化的影响
两者的问题都有,RDB 阶段大 Key 导致快照写入慢,AOF 阶段增量命令体积大。
主线程阻塞
大 Key 删除时才是最危险的:
DEL big_key(value 是 100MB 的 Hash)
→ 主线程同步释放内存
→ 阻塞几百毫秒甚至几秒
→ 期间所有命令全部等待
→ 如果正好在 RDB/AOF 重写窗口期,雪上加霜解决:用 UNLINK 代替 DEL
bash
UNLINK big_key # 异步删除,把释放内存的工作交给后台线程,主线程不阻塞如何排查大 Key
bash
# 官方工具,扫描 RDB 文件,不影响线上服务
redis-cli --bigkeys
# 或者用 SCAN 遍历 + MEMORY USAGE 查大小
MEMORY USAGE key_name大 Key 让 RDB fork 的内存复制代价更高、让 AOF 写入和重写更慢,本质都是大内存操作拖慢 IO 和阻塞主线程 。根本解决办法是拆分大 Key ,删除时用 UNLINK 异步释放。
面试
Q:Redis 如何实现数据不丢失?
Redis 读写操作都是在内存中,性能高,但是当其重启之后数据会丢失,为了保证内存中数据不丢失,Redis 实现了数据持久化的机制(将数据存放至磁盘,然后从磁盘中恢复),共有三种数据持久化的方式:
- RDB 快照:将某一时刻的内存数据以二进制的方式写入磁盘
- AOF 日志:每执行一条写操作命令,就将该命令以追加的方式写入一个文件
- 混合持久化:Redis 4.0 新增,集成 RDB & AOF 的优点
Q:AOF 日志如何实现?
执行完一条写操作命令后,将该命令以追加的方式写入文件,重启后 Redis 会读该文件,然后逐一执行以进行数据恢复
为什么先执行命令再将命令写入日志?
避免额外的检查开销
不会阻塞 当前的写命令
AOF 写回策略有几种?(appendfsync)Always,命令执行后,同步将 AOF 日志数据写回硬盘
Everysec,命令执行后,先写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区内容写回硬盘
No,Redis 不控制写回硬盘的时机,命令执行后先写入内核缓冲区,再由 OS 决定何时将缓冲区内容写回硬盘
AOF 日志过大会触发什么机制?AOF 重写机制( 对当前内存数据生成等价的最小命令集,替换旧 AOF 文件)
重写 AOF 日志的过程是怎样的?(bgrewriteaof)
- fork 子进程(短暂阻塞,复制页表)
- 子进程 和 主进程 并行进行,子进程先生成命令并写入新 AOF,主进程写入旧 AOF (保证旧文件完整)并重写缓冲区(记录重写期间产生的新命令以便写入新 AOF)
- 子进程通知主进程写完了(发信号)
- 主进程将重写缓冲区的命令追加到新 AOF(短暂阻塞)
- 原子替换旧 AOF(rename系统调用)
fork 子进程遍历内存生成新 AOF,期间主进程的新写命令存入重写缓冲区,子进程写完后主进程把缓冲区追加进去,最后原子替换旧文件。两次短暂阻塞:fork 时复制页表、最后追加缓冲区时。
Q:RDB 快照如何实现?
记录某一个瞬间的内存数据到 dump.rdb(default),恢复时直接将 RDB 文件读入内存
RDB 做快照会阻塞线程吗?(save | bgsave)
save,会在主线程生成 RDB 文件,由于和写命令在同一个线程,如果写入文件的时间太长,会阻塞主线程;bgsave,创建子进程生成 RDB 文件,避免主线程的阻塞
RDB 在执行快照时,数据能修改吗?可以修改,这正是 fork + COW(写时复制) 机制解决的核心问题。BGSAVE 触发后,主线程 fork 出子进程,子进程负责写 RDB,与此同时如果主进程执行读操作,则主线程与 bgsave 子进程相互不影响,如果主进程执行写操作,则 COW 开始工作(将被修改数据所在的内存页复制一份)bgsave 在副本上操作,主线程仍然可以修改原数据,代价是写操作越多,内存复制越多。
Q:为什么会有混合持久化?
为了解决 RDB 和 AOF 各自的短板
RDB 的问题:丢数据
快照是定时触发的,两次快照之间如果 Redis 宕机,这段时间的数据全丢。
09:00 RDB快照 09:01 ~ 09:14 写了大量数据 09:15 宕机 09:15 RDB快照还没触发 → 丢了 15 分钟的数据AOF 的问题:恢复慢
AOF 记录的是每一条写命令,数据量大时 AOF 文件可能有几十 GB,恢复时需要逐条重放命令,可能需要几十分钟甚至几小时。
AOF 文件 50GB → Redis 重启 → 逐条执行命令重建内存 → 恢复完成需要 1 小时 → 这 1 小时服务不可用混合持久化怎么解决的:AOF 重写时,新文件不再全写命令,而是:
┌──────────────────────────────┐ │ RDB 二进制快照(全量,快) │ ← 解决恢复慢 ├──────────────────────────────┤ │ AOF 增量命令(重写期间新产生)│ ← 解决丢数据 └──────────────────────────────┘恢复时先加载 RDB 部分(秒级),再重放少量 AOF 增量命令,恢复速度接近 RDB,数据完整性接近 AOF。
Q:RDB 和 AOF 同时存在,Redis 重启用哪个?
优先用 AOF,因为 AOF 数据更完整。只有 AOF 关闭时才用 RDB。
Q:fork 子进程期间主进程会阻塞吗?
fork 系统调用本身会短暂阻塞主线程(复制页表),但通常只有几毫秒。fork 完成后主线程立刻恢复服务,子进程独立写磁盘。数据量越大,fork 越慢。
Q:AOF 重写期间新来的写命令怎么处理?
同时写入旧 AOF 和重写缓冲区。子进程写完新 AOF 后,把重写缓冲区的内容追加进去,保证数据不丢。
Q:Redis 能保证强一致吗?
不能。即使 AOF everysec,也可能丢最近1秒数据。Redis 定位是高性能缓存,不是强一致存储,强一致场景用 MySQL。
三、缓存
减少数据库压力 + 提升响应速度
- 穿透 → 布隆过滤器拦截非法请求
- 击穿 → 互斥锁保证只有一个线程重建缓存
- 雪崩 → TTL 随机化 + Redis 高可用
- 一致性 → 先更新DB再删缓存,允许短暂不一致
- 淘汰 → 一般选 allkeys-lru 或 allkeys-lfu
缓存三兄弟
缓存穿透
指当查询一个不存在的 key 时,请求直接透过 Redis 打到数据库(缓存未命中),原因如下:
- 业务误操作,缓存和数据库中的数据均被误删
- 恶意攻击,故意访问不存在的 key
解决
-
缓存空值:将查询过的不存在 key 缓存起来,如果重复查询这个 key 就可以直接返回无需打数据库
javaObject result = db.query(id); if (result == null) { // 缓存一个空值,设置较短过期时间 redis.set(key, "NULL", 60); } -
布隆过滤器:查询前加一层布隆过滤(询问这个 key 是否存在)
请求 id=9999 ↓ 布隆过滤器:不存在 → 直接返回,不查数据库 存在 → 查 Redis → 查 MySQLjava// 初始化:把数据库所有合法 id 加入布隆过滤器 bloomFilter.add(id); // 请求时先检查 if (!bloomFilter.contains(id)) { return null; // 直接拦截 }工作原理是利用多个哈希函数将一个元素映射到一个位数组中(BitMap),其工作流程如下:
- Init:BitMap(长度m,值为 0) & 哈希函数集(k 个相互独立的哈希函数,将输入映射到 BitMap 中)
- Add:添加元素时,使用函数集对该元素计算,得到 k 个哈希值,将这 k 个哈希值在 BitMap 中对应位置设置为1
- Query:查询元素时,先计算得到哈希值,查询它们是否为全为1,如果有一个位置是 0,那么绝对不存在,如果全为 1 可能存在
特性:
- 说不存在 → 一定不存在
- 说存在 → 可能存在(有误判率,约 1%)
- 不支持删除(变种 Counting Bloom Filter 支持),会影响其他元素判断
缓存击穿
某个热点 key 过期的一瞬间,大量并发请求同时未命中,全部打到数据库
击穿是热点 key,雪崩是大量 key
解决
-
互斥锁(Mutex):缓存未命中时只让一个线程去查数据库重建缓存,其他线程等待(数据一致性强但性能稍差)
javaString value = redis.get(key); if (value == null) { // 尝试拿分布式锁 if (redis.setnx(lockKey, "1", 10)) { try { value = db.query(id); redis.set(key, value, 3600); } finally { redis.del(lockKey); // 释放锁 } } else { // 没抢到锁,等一会重试 Thread.sleep(50); return get(id); // 递归重试 } } return value; -
逻辑过期:在 value 中存放一个字段判断是否逻辑过期(性能好但数据一致性稍差)
java// value 结构 { "data": {...}, "expireTime": 1735000000 } // 读取逻辑 RedisData redisData = redis.get(key); if (redisData.expireTime > now()) { return redisData.data; // 未过期,直接返回 } // 逻辑过期了,异步重建缓存 if (tryLock(lockKey)) { asyncRebuildCache(key); // 后台线程重建 } // 先返回旧值,不阻塞 return redisData.data;
缓存雪崩
大量 key 在同一时间集中过期(TTL 设置成一样的) or Redis 宕机,导致大量请求同时打到数据库
大量 key 同时过期
-
TTL 加随机值
javaint ttl = 3600 + RandomUtil.nextInt(0, 300); // 加0~5分钟随机 redis.set(key, value, ttl); -
互斥锁:如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(记得设置超时时间)
-
后台更新缓存(缓存预热):由于系统内存紧张时会淘汰掉一些缓存数据,因此我们想让缓存"永久有效",并将更新缓存的工作交由后台线程定时更新
- 定时更新缓存并频繁检测缓存是否有效
- 发现缓存失效时,通过 MQ 通知后台线程更新缓存
Redis 故障宕机
-
构建 Redis 缓存高可靠集群:靠架构解决 Redis 本身宕机导致的雪崩
- 主从 + 哨兵:主节点宕机自动切换从节点
- Redis Cluster:分片集群,部分节点宕机不影响整体
-
服务熔断(暂停业务应用对缓存服务的访问,直接返回错误)或请求限流机制(只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务):防止 Redis 崩溃之后数据库被打垮
java// 请求限流机制示例 // 限流:超过阈值直接返回降级结果 if (requestCount > threshold) { return "服务繁忙,请稍后再试"; } // 降级:查数据库失败时返回兜底数据 try { return db.query(id); } catch (Exception e) { return defaultValue; }
缓存更新策略
-
Cache Aside(旁路缓存)
读流程:
查 Redis → 命中 → 返回 → 未命中 → 查 MySQL → 写入 Redis → 返回写流程:
更新 MySQL → 删除 Redis 缓存为什么是删除缓存,而不是更新缓存? 更新缓存在并发下可能写入旧值(两个线程先后更新,顺序不一致);删除是幂等操作(无论执行多少次,系统的最终状态和执行一次的结果都是一样的),更安全。下次读时自然重建缓存。
-
Read/Write Through(穿透读写)
应用只和缓存交互,由缓存层负责同步数据库,应用无感知。实现复杂,一般用成熟的缓存中间件才会考虑,业务开发少用。
-
Write Behind(异步写回)
只写缓存,由后台异步批量写数据库。性能最高,但有丢数据风险,适合日志、点赞计数等允许少量丢失的场景。
缓存一致性
Cache Aside 写流程有一个经典问题:先删缓存还是先更新数据库?
先删缓存,再更新数据库
线程A:删除缓存
线程B:查缓存未命中 → 查数据库(旧值)→ 写入缓存(旧值)
线程A:更新数据库(新值)
结果:缓存里是旧值,数据库是新值 → 不一致!❌先更新数据库,再删缓存
线程A:更新数据库(新值)→ 删除缓存
线程B 读请求:缓存未命中 → 查数据库(新值)→ 写入缓存(新值)
结果:一致 ✅延迟双删(并发)
还有一个极小概率的问题:
缓存恰好过期
线程B:查缓存未命中 → 查数据库(旧值,还没更新完)
线程A:更新数据库 → 删除缓存
线程B:把旧值写入缓存
结果:缓存是旧值 → 不一致这个窗口极小(需要缓存恰好在那一刻过期),且下次缓存过期后会自动修正,一般业务上可以接受 ,但对一致性要求高时,可以用延迟双删兜底:
java
// 第一次删缓存
redis.del(key);
// 更新数据库
db.update(data);
// 延迟一段时间,再删一次(清除期间可能写入的旧值)
Thread.sleep(500);
redis.del(key);延迟时间要大于一次数据库读写的时间,确保把"读旧值写缓存"的窗口覆盖掉。
如何保证两个操作都能执行成功?
数据库和缓存是两个独立的系统,没有原生的事务保证。
失败场景分析
① 更新数据库成功 → 删除缓存失败
结果:数据库是新值,缓存是旧值 → 不一致
② 更新数据库失败 → 删除缓存成功
结果:数据库是旧值,缓存为空 → 下次读数据库,重建旧值
这种影响不大,数据库失败本身就该回滚麻烦的是删除缓存失败导致的不一致,解决方案如下:
-
重试机制:删缓存失败时,捕获异常,重试几次。
javaboolean success = false; int retries = 3; while (retries-- > 0) { try { redis.del(key); success = true; break; } catch (Exception e) { // 稍等再试 Thread.sleep(50); } } if (!success) { // 重试全失败,写入消息队列,后续补偿 mq.send(new DeleteCacheMessage(key)); }重试是同步的,失败次数多时会阻塞请求,影响接口响应时间。
-
消息队列异步重试:删缓存失败后,把 key 发到消息队列,由消费者异步重试删除,主流程不阻塞。
更新数据库 ↓ 删除缓存 ↓ 失败 发送消息到 MQ(key) ↓ 消费者拉取消息 → 重试删除缓存 ↓ 还是失败 消息重新入队(设置最大重试次数)java// 生产者 db.update(data); try { redis.del(key); } catch (Exception e) { // 删缓存失败,丢消息队列 mq.send("cache_delete", key); } // 消费者 @MQListener("cache_delete") public void onMessage(String key) { redis.del(key); }优点:解耦,异步,重试有保障
缺点:引入 MQ,架构复杂度增加;消费者消费前有短暂不一致窗口
-
Canal 订阅 MySQL binlog (最终一致性方案):完全不在业务代码里处理缓存,而是监听数据库的变更日志,自动删除对应缓存。
业务代码 只管更新 MySQL ↓ MySQL 写 binlog ↓ Canal 订阅 binlog,解析变更 ↓ Canal 发消息到 MQ ↓ ↑ACK(删除缓存成功) 消费者:删除 Redis 对应 key优点:
- 业务代码和缓存完全解耦,不需要写任何缓存删除逻辑
- binlog 是 MySQL 内部机制,只要数据库写成功,删缓存一定会被触发
缺点:
- 引入 Canal + MQ,运维成本高
- 有一定延迟(binlog → Canal → MQ → 消费者)
这是大厂处理缓存一致性的主流方案,延迟通常在毫秒到秒级,绝大多数业务可以接受。
| 同步重试 | MQ异步重试 | Canal+binlog | |
|---|---|---|---|
| 实现复杂度 | 低 | 中 | 高 |
| 对业务侵入 | 有 | 有 | 无 |
| 可靠性 | 一般 | 好 | 最好 |
| 一致性延迟 | 最低 | 低 | 略高 |
| 适用场景 | 小项目 | 中型项目 | 大型项目 |
本质上是分布式环境下两个系统的原子性问题 ,无法做到真正的强一致,只能做最终一致性。小项目用重试兜底,大项目用 Canal 监听 binlog 自动补偿,把缓存删除从业务逻辑中彻底剥离出去。
过期删除策略 vs 内存淘汰策略
- 过期删除策略:针对设置了 TTL 的 key,到期了怎么删
- 内存淘汰策略:Redis 内存不够用了,怎么腾空间
过期删除策略
相关命令
bash
# 对 key 设置过期时间
expire/expireat <key> <n>
pexpire/pexpireat <key> <n>
# 设置字符串时对 key 设置过期时间
set <key> <value> ex/px <n>
setex <key> <n> <valule>
# 查看剩余的存活时间
ttl key
# 取消过期时间
persist key如何判定 key 已过期了?
Redis 每个数据库(redisDb)内部维护两个字典:
c
typedef struct redisDb {
dict *dict; // 存所有 key-value
dict *expires; // 单独存 key 的过期时间(绝对时间戳,毫秒)
} redisDb;设置过期时间时,只往 expires 字典里写一条记录:
bash
SET name "xmon"
EXPIRE name 300
# expires 字典里:
# "name" → 1735000000000(当前时间戳 + 300000ms)判断逻辑:用当前时间戳和 expires 字典里存的过期时间戳比大小,超过了就是过期。
c
int keyIsExpired(redisDb *db, robj *key) {
// 1. 去 expires 字典查这个 key 有没有过期时间
mstime_t when = getExpire(db, key);
// 2. 没有过期时间,永不过期
if (when < 0) return 0;
// 3. 获取当前时间戳(毫秒)
mstime_t now = mstime();
// 4. 当前时间 > 过期时间 → 已过期
return now > when;
}流程示意
访问 key "name"
↓
去 expires 字典查 → 没有记录 → 永不过期,正常返回
→ 有记录(timestamp = T)
↓
now > T ?
→ 是:已过期,删除,返回 null
→ 否:未过期,正常返回过期删除策略有哪些?
Redis 有三种删除策略,实际上同时使用了两种。
-
定时删除(Redis 没用这个):给每个 key 创建一个定时器,到期立即删除。
优点:内存释放最及时
缺点:大量定时器占用 CPU,key 多时性能极差
-
惰性删除:不主动删,等到被访问时再检查
客户端访问 key ↓ Redis 检查该 key 是否过期 ↓ 过期 删除,返回 null ↓ 未过期 正常返回c// Redis 源码中每次访问 key 都会调用这个 int expireIfNeeded(redisDb *db, robj *key) { if (!keyIsExpired(db, key)) return 0; // 未过期,放行 deleteExpiredKeyAndPropagate(db, key); // 过期,删除 return 1; }优点: 对 CPU 友好,不主动消耗资源
缺点: 如果 key 一直不被访问,永远不会删,内存泄漏
-
定期删除:每隔一段时间,随机抽查一批设置了 TTL 的 key,删除其中过期的。
每隔 100ms 执行一次: 从 expires 字典中随机抽取 20 个 key 删除其中已过期的 如果过期比例 > 25%,再抽一批继续删 直到过期比例 < 25% 或执行时间超过阈值(默认25ms)才停止模式 触发 执行时间 场景 SLOW 定时任务,100ms一次 最长 25ms 常规清理 FAST 每次事件循环前执行 最长 1ms 快速补充清理 优点: 兼顾 CPU 和内存,折中方案
缺点: 随机抽样,不能保证所有过期 key 及时删除
Redis 实际的组合策略
惰性删除 + 定期删除 配合使用
定期删除:后台主动清理,释放内存
惰性删除:访问时兜底,保证不返回过期数据
两者互补,但仍然无法保证所有过期 key 都被删除
→ 这就是为什么还需要内存淘汰策略内存淘汰策略
当 Redis 内存达到 maxmemory 上限时,新写入请求触发淘汰。
bash
# 配置最大内存
maxmemory 4gb
# 配置淘汰策略
maxmemory-policy allkeys-lruRedis 内存淘汰策略有哪些?
8 种策略 ,按作用范围分两类:
- allkeys 系列:对所有 key 生效
- volatile 系列:只对设置了过期时间的 key 生效
| 策略 | 范围 | 算法 | 含义 |
|---|---|---|---|
noeviction |
全部 | 无 | 不淘汰,内存满直接报错(默认) |
allkeys-lru |
所有key | LRU | 淘汰最久未使用的 |
allkeys-lfu |
所有key | LFU | 淘汰访问频率最低的 |
allkeys-random |
所有key | 随机 | 随机淘汰 |
volatile-lru |
有TTL的key | LRU | 有TTL的key中淘汰最久未使用的 |
volatile-lfu |
有TTL的key | LFU | 有TTL的key中淘汰频率最低的 |
volatile-random |
有TTL的key | 随机 | 有TTL的key中随机淘汰 |
volatile-ttl |
有TTL的key | TTL | 淘汰剩余过期时间最短的 |
LRU vs LFU
-
LRU (Least Recently Used,最近最少使用),淘汰最久没被访问的 key,适合热点数据随时间变化的场景。
传统的 LRU 是基于链表的,链表元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,删除表尾元素即可,Redis 并未使用该方式实现 LRU,原因如下:
- 链表管理缓存数据,带来额外开销
- 链表移动操作很耗时,进而降低 Redis 缓存性能
Redis 的 LRU 是近似的,不是精确的:
Redis 的做法: 每个 key 记录最后一次访问时间(lru 字段,24bit) 淘汰时随机采样 N 个 key(默认 maxmemory-samples=5) 淘汰其中 lru 时间最老的那个 多次采样近似达到 LRU 效果,牺牲少量精确度换取性能但 LRU 算法无法解决缓存污染问题,比如应用有且仅读取一次的数据,那么这些数据会留存在缓存中很长一段时间,造成缓存污染。因此,Redis 4.0 后引入 LFU 解决该问题
-
LFU (Least Frequently Used, 最不常用),淘汰访问次数最少的 key,更能反映长期热度,适合热点相对固定的场景。
但直接记录真实访问次数有两个问题:
- 计数器可能非常大,占用内存多
- 历史遗留问题:一个 key 以前访问很频繁,最近完全没人用,但计数还是很高,永远不会被淘汰
Redis 的 LFU 针对这两个问题都做了处理。
复用 lru 字段
Redis 没有新增字段,而是把
redisObject里原来存 LRU 时间戳的 24 bit 字段拆成两部分:cunsigned lru:24; // LRU 模式:24bit 全部存最后访问时间戳 // LFU 模式:拆成两段 // 高 16 bit → ldt(last decrement time,上次衰减时间,分钟级) // 低 8 bit → counter(访问频率计数器,Morris Counter) | 16 bit (ldt) | 8 bit (counter) |8 bit 最大值 255,不直接存真实访问次数,而是用Morris Counter(概率计数器)
Morris Counter:对数级近似计数
每次访问 key,counter 不是直接 +1,而是按概率递增:
c// 伪代码 double r = random(); // 0~1 之间的随机数 double p = 1.0 / (counter * lfu_log_factor + 1); if (r < p) counter++; // 概率越来越小效果:
counter 越小 → 概率越大 → 容易涨(冷数据快速区分) counter 越大 → 概率越小 → 很难涨(热数据增长平缓) counter = 0 → 每次必然 +1 counter = 10 → 约 1/10 概率 +1 counter = 100 → 约 1/100 概率 +1 counter 上限 → 255(8bit 最大值) 实际映射关系(lfu_log_factor=10,默认值): counter = 10 → 约 100 次访问 counter = 18 → 约 1000 次访问 counter = 255 → 约 100万次访问用 255 以内的数字就能表示从几次到百万次的访问量差异,极省内存。
LFU 还有衰减机制:
光有计数还不够,如果一个 key 以前很热现在没人用,counter 一直高,永远不会被淘汰。
Redis 引入时间衰减:每隔一段时间,counter 自动减小。
c// 计算衰减量 unsigned long LFUDecrAndReturn(robj *o) { // ldt:上次衰减时间(分钟) unsigned long ldt = o->lru >> 8; unsigned long counter = o->lru & 255; // 距离上次衰减过了多少分钟 unsigned long num_periods = (now_in_minutes - ldt) / lfu_decay_time; // 衰减:过了多少个周期,counter 减多少 if (num_periods > 0) { counter = (num_periods > counter) ? 0 : counter - num_periods; } return counter; }bash# 衰减速度配置(默认1,即每分钟衰减1点) lfu-decay-time 1 一个 key counter = 50,lfu-decay-time = 1 10 分钟没被访问 → counter = 50 - 10 = 40 100 分钟没被访问 → counter = 50 - 50 = 0(最小到0) → 下次内存满,优先被淘汰完整流程
每次访问 key: ↓ ① 计算衰减:距上次衰减多久了 → counter 减去对应值 ↓ ② 概率递增:按 Morris Counter 概率 counter +1 ↓ ③ 更新 ldt 为当前时间 内存满,需要淘汰: ↓ 随机采样 N 个 key(同 LRU,也用淘汰池) ↓ 比较各 key 的 counter(先做衰减计算) ↓ 淘汰 counter 最小的 -
对比
LRU LFU 判断依据 最后访问时间 访问频率(计数) 24bit 用法 全部存时间戳 16bit时间 + 8bit计数 冷热区分 看最近 看长期 新 key 保护 刚加入就是最热 counter 从0开始,容易被淘汰 适合场景 热点随时间变化 热点长期稳定
两套策略配合
key 设置了 TTL,到期了
↓
惰性删除:被访问时检查,删除
定期删除:后台随机抽查,删除
↓ 但是有漏网之鱼(还没被访问也没被抽到)
内存快满了
↓
内存淘汰策略介入
根据配置的策略,强制淘汰 key 腾出内存缓存预热
系统刚启动时缓存是空的,如果直接上线,所有请求都会打到数据库。
java
// 项目启动时,主动把热点数据加载进 Redis
@PostConstruct
public void initCache() {
List<Product> hotProducts = db.queryHotProducts();
hotProducts.forEach(p -> redis.set("product:" + p.getId(), p, 3600));
}面试
| 问题 | 关键词 |
|---|---|
| 穿透 | 不存在的key → 布隆过滤器 |
| 击穿 | 热点key过期 → 互斥锁/逻辑过期 |
| 雪崩 | 大量key同时过期 → TTL随机+高可用 |
| 一致性 | 先更新DB再删缓存 → Canal兜底 |
| 淘汰 | 生产用allkeys-lru/lfu |
| 热key | 本地缓存+key分片 |
| 大key | 拆分+UNLINK异步删除 |
| 分布式锁 | SET NX EX + Lua释放 + Redisson看门狗 |
Q:什么是缓存穿透、击穿、雪崩?分别怎么解决?
穿透:查询数据库不存在的 key,缓存永远未命中,每次都打数据库。 解决:布隆过滤器拦截非法请求;或缓存空值(TTL 设短)。
击穿:单个热点 key 过期瞬间,大量并发全部打到数据库。 解决:互斥锁保证只有一个线程重建缓存;或逻辑过期(key 不设物理过期,异步重建,先返回旧值)。
雪崩:大量 key 同时过期,或 Redis 宕机,数据库被打垮。 解决:TTL 加随机值错开过期时间;Redis 主从+哨兵保证高可用;服务层限流降级兜底。
Q:布隆过滤器的原理?有什么缺陷?
本质是一个 bit 数组 + 多个哈希函数。插入元素时,使用哈希函数集计算出多个位置,将这些位置上的 bit 全置为1。查询时,同样算出多个位置,如果有一个不为1则一定不存在,全为1则有可能存在
缺陷:
- 有误判:bit 位可能被其他元素设置,导致实际不存在而显示存在(假阳性)
- 不支持删除:删除一个元素会影响共享 bit 位,影响其他元素的判断
Q:如何保证缓存和数据库一致性?
使用旁路缓存(Cache Aside),先更新数据库再删除缓存
为什么是删而不是更新?
- 并发下两个线程同时更新缓存,顺序不保证会写入旧值;
- 删除是幂等操作更安全;
- 不是每次缓存都会被读,惰性重建更合理。
删除缓存失败怎么办?两种方案:
- MQ 异步重试删除
- Canal 监听 MySQL binlog,自动触发删缓存,业务代码零侵入,大厂主流方案。
Q:为什么先更新数据库,再删缓存?反过来有什么问题?
先删缓存再更新数据库,有较大概率出现不一致:
线程A:删缓存 线程B:读缓存未命中 → 查数据库(旧值)→ 写入缓存(旧值) 线程A:更新数据库(新值) 结果:数据库新值,缓存旧值 → 不一致,且会一直保持到缓存过期先更新数据库再删缓存,不一致的窗口极小(需要缓存恰好在那一刻过期且并发读),且下次缓存过期后自动修正。
Q:什么是延迟双删?解决了什么问题?
先删缓存,更新数据库,延迟一段时间再删一次缓存:
解决"先删缓存再更新数据库"方案中,并发读写将旧值写入缓存的问题。延迟时间要覆盖一次完整的数据库读写耗时,确保把期间写入的旧值清掉。 缺点:延迟删除期间仍有短暂不一致;sleep 阻塞线程,一般放异步执行。
Q:Redis 的内存淘汰策略有哪些?生产怎么选?
8 种策略,按范围分两类:
- allkeys 系列:对所有 key 生效
- volatile 系列:只对设置了过期时间的 key 生效
按算法分:lru(最近最少使用)、lfu(最不常用)、random(随机)、ttl(最快过期)
生产选择:
- 通用场景:
allkeys-lru,淘汰最久未访问的- 热点相对固定:
allkeys-lfu,更能反映长期热度- 缓存和持久数据混用:
volatile-lru,只淘汰有过期时间的- 不淘汰(
noeviction)默认值,内存满直接报错,生产一般不用
Q:LRU 和 LFU 的区别?Redis 的 LRU 是精确的吗?
LRU (Least Recently Used):淘汰最久没被访问的,适合热点随时间变化的场景。 LFU(Least Frequently Used):淘汰访问次数最少的,适合热点相对固定的场景。
Redis 的 LRU 不是精确的 ,是近似 LRU。精确 LRU 需要维护一个全局链表,内存和性能开销大。Redis 的做法是:随机采样 N 个 key(默认5个),淘汰其中最久未访问的那个,多次采样近似达到 LRU 效果。可通过
maxmemory-samples调大采样数量提高精确度,但相应增加 CPU 开销。
Q:热 key 问题是什么?怎么解决?
某个 key 访问频率极高(比如明星突发新闻、秒杀商品),导致该 key 所在的 Redis 节点压力过大,甚至打垮单节点。
解决方案:
- 本地缓存:在 JVM 内存(Caffeine/Guava Cache)缓存一份,请求先走本地缓存,不到 Redis
- key 分片 :把热 key 复制成多份,
hot_key_0、hot_key_1...hot_key_N,请求随机打到其中一个,分散压力- 读写分离:从节点分担读压力
Q:大 key 问题是什么?怎么排查和解决?
什么是大 key:String value 超过 10KB,或集合类型元素超过 10000 个/总大小超过 10MB。
危害:
- 读写大 key 阻塞主线程
- 删除大 key(DEL)同步释放内存,可能阻塞几百毫秒
- RDB/AOF 持久化耗时增加,内存峰值高
- 主从同步传输慢
排查:
bash
bashredis-cli --bigkeys # 扫描找大 key MEMORY USAGE key_name # 查某个 key 内存占用解决:
- 拆分大 key:Hash 拆成多个小 Hash,List 分页存储
- 删除用
UNLINK代替DEL(异步释放内存)- 压缩 value(gzip 压缩后存入)
Q:缓存预热怎么做?
服务启动时主动把热点数据加载进 Redis,避免冷启动时所有请求都打数据库。
常见做法:
- 项目启动时用
@PostConstruct加载热点数据- 发布前手动跑脚本提前预热
- 根据历史访问日志,定时任务预热次日热点数据
Q:如何实现一个简单的分布式锁?有哪些坑?
基础实现:
bashSET lock:key uuid NX EX 30 # NX:不存在才设置(互斥) # EX:自动过期(防死锁) # uuid:标识锁的持有者(防误删)释放锁时必须用 Lua 脚本保证原子性:
luaif redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end主要坑:
- 锁超时业务没执行完:用 Redisson 的看门狗(watchdog)自动续期
- 主从切换锁丢失:主节点宕机,锁还没同步到从节点,另一个线程在新主上能拿到锁 → 用 RedLock(但有争议)
- 不可重入:同一线程重复加锁会死锁 → Redisson 实现了可重入锁
四、分布式锁
基础用
SET NX EX+ Lua 释放;生产用 Redisson,自带看门狗续期、可重入、发布订阅等待;主从安全问题用 RedLock 有争议,大多数业务单节点 Redisson 足够。
为什么需要分布式锁
单机环境用 JVM 的 synchronized / ReentrantLock 就够了,但分布式环境下多个服务实例各自的 JVM 锁互不感知:
用户下单,扣减库存
实例A ────┐
├──→ 同时读到 stock=1,同时扣减 → stock=-1(超卖!)
实例B ────┘
JVM锁锁不住跨进程的并发,需要一个所有实例都认可的第三方来协调
→ Redis 分布式锁单节点锁 SETNX
适用于业务不是支付、下单这种核心场景的简单场景
加锁
bash
SET lock:key uuid NX EX 30
# NX = Not Exists,key 不存在才设置(互斥的关键)
# EX = 过期时间,防止宕机后锁永不释放(死锁)
# uuid = 唯一标识,标记锁的持有者(防误删)
- uuid 唯一
- EX 合理预留缓冲
- 加锁后别做无效等待,重试/抛异常
释放锁(必须用 Lua 脚本)
将判断和删除这两个操作封装成一个原子操作
lua
-- 先判断是不是自己的锁,再删除,两步必须原子执行
-- KEYS[1]对应传入的锁的key(比如lock_key)
-- ARGV[1]对应传入的锁的唯一标识(比如unique_value)
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end为什么释放锁必须用 Lua?
线程A:GET lock → 值是自己的 uuid ✅
(此时锁恰好过期,被线程B拿到)
线程A:DEL lock → 把线程B的锁删了!❌
GET + DEL 不是原子操作,中间可能被打断
Lua 脚本在 Redis 中原子执行,不会被打断Java 代码实现
java
public class SimpleRedisLock {
private StringRedisTemplate redisTemplate;
private String lockKey;
private String uuid;
public boolean tryLock(long expireTime) {
uuid = UUID.randomUUID().toString();
Boolean success = redisTemplate.opsForValue()
.setIfAbsent(lockKey, uuid, expireTime, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
public void unlock() {
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
redisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
List.of(lockKey),
uuid
);
}
}单节点锁的问题
问题1:锁超时,业务没执行完
线程A 拿到锁,设置过期时间 30s
业务执行到第 25s,还没完成
第 30s 锁自动过期,线程B 拿到锁
线程A 和线程B 同时在临界区执行!❌解决:看门狗(Watchdog)自动续期
问题2:不可重入
java
// 同一个线程,加锁两次
lock(); // 成功
doSomething();
lock(); // 失败!key 已存在,自己把自己锁死了解决:可重入锁(记录持有线程 + 重入次数)
问题3:主从切换锁丢失
线程A 在主节点写入锁
主节点还没来得及同步给从节点,主节点宕机
从节点升级为新主节点,锁数据丢失
线程B 在新主节点拿到同一把锁
两个线程同时持有锁!❌解决:RedLock(有争议)或业务层容忍
高可用锁 RedLock
针对主从切换锁丢失问题,Redis 作者 antirez 提出了 RedLock 算法。
适用于支付、下单等核心业务场景,并部署至少 3 个独立的 Redis 锁节点。具体部署建议如下:
- 节点数量选择奇数:如 3、5、7 等,便于快速计算成功条件,确保锁机制的有效性
- 保证节点独立性:节点之间不能有主从复制关系
- 合理设置请求超时:向节点发送加锁请求时,建议设置 50-100ms 的超时时间,避免单个节点相应缓慢拖流程
原理
部署 N 个(一般5个)完全独立的 Redis 主节点(无主从关系)
加锁:向所有 N 个节点发送 SET NX EX 请求
超过半数(>=3)成功,且总耗时 < 锁过期时间
→ 加锁成功
释放:向所有 N 个节点发送释放命令
即使一个节点宕机,锁数据还存在其他多数节点上
新的加锁请求无法获得多数同意,保证互斥RedLock 的争议
Martin Kleppmann(《DDIA》作者)和 antirez 有过著名的公开论战:
Martin 的质疑:
线程A 在5个节点都加锁成功
线程A 发生 GC Stop-The-World 停顿(比如几秒)
期间锁在所有节点自动过期
线程B 加锁成功
GC 结束,线程A 认为自己还持有锁,继续执行
两个线程同时在临界区!RedLock 没有解决这个问题结论:
| RedLock | |
|---|---|
| 解决主从切换问题 | ✅ |
| 解决 GC 停顿问题 | ❌ |
| 实现复杂度 | 高(需要5个独立Redis) |
| 生产使用 | 争议较大 |
实际生产怎么选?
- 大多数业务:单节点 Redisson + 看门狗 足够
- 对锁要求极高(金融核心链路):用数据库做分布式锁(悲观锁 FOR UPDATE),或 ZooKeeper
Redlock 切勿滥用,性能开销大
生产级分布式锁 Redisson
Redisson 解决了单节点锁的所有问题,是生产环境的标准选择。
基本使用
java
RLock lock = redissonClient.getLock("lock:order:1001");
// 尝试加锁,最多等3秒,锁自动过期30秒
boolean success = lock.tryLock(3, 30, TimeUnit.SECONDS);
if (success) {
try {
// 业务逻辑
deductStock();
} finally {
lock.unlock();
}
}核心一:看门狗自动续期
线程A 拿到锁,leaseTime 默认 30s(watchdog 超时时间)
后台 watchdog 线程每隔 10s(leaseTime/3)检查一次:
线程A 还持有锁吗?
→ 是:重置过期时间为 30s
→ 否(线程A崩溃):不续期,锁自然过期释放
只有调用 unlock() 或线程崩溃,锁才会真正释放
java
// 不指定 leaseTime,watchdog 自动续期
lock.lock(); // 默认启动看门狗
// 指定 leaseTime,不启动看门狗(自己管过期时间)
lock.lock(30, TimeUnit.SECONDS);但是它并非绝对可靠,如果服务器宕机,其线程会随之终止,锁释放。
核心二:可重入锁
Redisson 用 Hash 结构存锁信息:
bash
# key = 锁名,field = 线程标识,value = 重入次数
HSET lock:order:1001 thread_A_uuid 1
# 同一线程再次加锁
HSET lock:order:1001 thread_A_uuid 2 # 重入次数 +1
# 释放一次
HSET lock:order:1001 thread_A_uuid 1 # 重入次数 -1
# 再释放一次,重入次数=0,删除 key
DEL lock:order:1001加锁 Lua 脚本:
lua
-- 锁不存在,直接加锁
if redis.call('exists', KEYS[1]) == 0 then
redis.call('hset', KEYS[1], ARGV[2], 1)
redis.call('pexpire', KEYS[1], ARGV[1])
return nil
end
-- 锁存在,判断是不是自己的
if redis.call('hexists', KEYS[1], ARGV[2]) == 1 then
redis.call('hincrby', KEYS[1], ARGV[2], 1) -- 重入次数+1
redis.call('pexpire', KEYS[1], ARGV[1])
return nil
end
-- 是别人的锁,返回剩余过期时间(告诉调用方等多久)
return redis.call('pttl', KEYS[1])核心三:加锁失败时的等待机制
tryLock(waitTime, ...) 失败后不是无脑轮询,而是用 Redis 的发布订阅:
线程B 尝试加锁失败
→ 订阅 lock:order:1001 的释放消息频道
→ 进入等待(不占用 CPU)
线程A 释放锁
→ 发布释放消息到频道
线程B 收到消息
→ 重新尝试加锁比无脑 while(true) 轮询更高效,减少 CPU 和 Redis 压力。
各实现方案对比
| SETNX 手写 | Redisson | RedLock | |
|---|---|---|---|
| 可重入 | ❌ | ✅ | ✅ |
| 自动续期 | ❌ | ✅ 看门狗 | ✅ |
| 主从安全 | ❌ | ❌ | ✅ |
| 实现复杂度 | 低 | 低(开箱即用) | 高 |
| 生产推荐 | ❌ | ✅ | 看场景 |
面试
Q:为什么需要分布式锁?和 JVM 锁有什么区别?
JVM 锁只在单机环境生效,分布式环境下多个服务实例各自的 JVM 锁互不感知,无法解决这种跨进程的并发问题,因此我们才有了分布式锁
分布式锁借助第三方存储(Redis / ZooKeeper / 数据库),让所有实例都认可同一个锁,才能协调跨进程的互斥访问
场景:秒杀扣减库存、定时任务防止重复执行,幂等控制
Q:分布式锁需要满足哪些条件?
- 互斥性:同一时刻只有一个客户端持有锁
- 防死锁:持有锁的客户端崩溃后,锁能自动释放
- 防误删:只能由持有者释放自己的锁,不能删别人的
- 原子性:加锁和释放锁的操作必须是原子的
- 可重入:同一线程可以多次加锁不死锁
- 高可用:锁服务本身不能是单点
Q:Redis 分布式锁的基本实现是什么?
SET lock:key uuid NX EX 30释放时使用 Lua 脚本保证原子性
Q:为什么加锁要用 SET NX EX 一条命令,而不是 SETNX + EXPIRE 两条?
两条命令不是原子操作,SETNX 成功后进程崩溃,EXPIRE 没有执行,锁永远不会过期,造成死锁。
Redis 2.6.12 之后支持
SET key value NX EX seconds一条命令原子完成,必须用这个。
Q:为什么释放锁要用 Lua 脚本?直接 DEL 有什么问题?
GET + DEL 两步不是原子操作,中间锁可能过期被别人拿走,导致误删别人的锁。Lua 在 Redis 中原子执行,整个过程不会被其他命令插入,彻底避免这个问题。
Q:锁过期了但业务还没执行完怎么办?
- 评估业务最大执行时间,设置比它更长的 TTL。
- Redisson 的看门狗机制自动续期,不指定
leastTime(default = 30s)时,每隔leastTime/3检查一次,如果业务还未执行完成就重置过期时间为 30s 直至业务完成主动释放
Q:加锁的 value 为什么要用 UUID?用线程 ID 不行吗?
线程 ID 在单机内唯一,而在分布式环境下可能存在相同的线程 ID,会导致锁会被其他线程误删
而 UUID 是全局唯一的,可以精确标识哪台机器的哪个线程,并且 Redisson 的实现是
UUID + 线程ID,更严谨。
Q:Redisson 的看门狗原理是什么?什么时候不生效?
原理:Redisson 加锁时如果不指定 leastTime,后台会启动一个定时任务 WatchDog,并且每隔 leastTime / 3 检查当前线程是否还持有锁,是的话重置过期时间为 leastTime。线程崩溃后 watchdog 也会停,锁自动在 30s 后过期
不生效情况:显式调用 lock.lock(leaseTime, unit)手动设置过期时间,Redisson 认为你自己管理过期时间
Q:Redisson 如何实现可重入锁(Reentrant Lock)?
用 Hash 结构存锁信息,field 是线程标识,value 是重入次数:
bashHSET lock:key "uuid:threadId" 1 # 第一次加锁 HSET lock:key "uuid:threadId" 2 # 同一线程重入 # 释放一次 → 2-1=1 # 再释放 → 1-1=0 → DEL lock:key加锁和释放都用 Lua 脚本保证原子性,重入次数归零才真正删除 key。
Q:tryLock 等待时用的是轮询吗?
不是,用的是 发布订阅机制,避免无效轮询浪费 CPU:
线程B tryLock 失败 ↓ 订阅锁释放的频道(不占 CPU,进入等待) ↓ 线程A 释放锁,发布释放消息 ↓ 线程B 收到消息,重新尝试加锁比
while(true) { sleep; tryLock }更高效,减少 Redis 压力。
Q:主从切换会导致锁丢失吗?怎么解决?
会。Redis 主从是异步复制,主节点加锁成功但还没同步到从节点时主节点宕机,从节点升为新主,锁数据丢失,另一个线程可以在新主上加同一把锁,导致两个线程同时持有锁。
解决方案一:RedLock 向 N 个(通常5个)独立 Redis 主节点同时加锁,超过半数成功才算加锁成功,单个节点宕机不影响锁的有效性。
解决方案二:业务层容忍 大多数业务接受极小概率的锁失效,用幂等 + 补偿机制兜底,不上 RedLock。
Q:RedLock 有什么争议?
Martin Kleppmann(《DDIA》作者)指出 RedLock 无法解决 GC Stop-The-World 问题:
线程A 在5个节点加锁成功 线程A 发生长时间 GC 停顿(几秒) 期间锁在所有节点过期 线程B 加锁成功 GC 结束,线程A 认为自己还持有锁,继续执行 → 两个线程同时在临界区!antirez 认为这是极端情况,实际概率极低,RedLock 已经够用。
结论: 真正需要强一致的场景(金融核心链路),用 ZooKeeper 或数据库锁,Redis 分布式锁定位是高性能,不是强一致。
Q:分布式锁有哪些实现方式?怎么选?
| Redis | ZooKeeper | 数据库 | |
|---|---|---|---|
| 性能 | 最高 | 中 | 最低 |
| 可靠性 | 中(异步复制) | 高(强一致) | 高 |
| 实现复杂度 | 低 | 中 | 低 |
| 死锁风险 | 有过期时间兜底 | 临时节点自动删除 | 需手动处理 |
| 适用场景 | 高并发,允许极小概率失效 | 强一致要求 | 并发量低 |
日常业务首选 Redisson ;强一致场景用 ZooKeeper (Curator 封装);并发量极低的简单场景可以用数据库
SELECT FOR UPDATE。
Q:如何用数据库实现分布式锁?
sql-- 加锁(利用唯一索引) INSERT INTO distributed_lock(lock_key, holder, expire_time) VALUES ('order:1001', 'uuid', NOW() + 30s); -- 插入成功 = 加锁成功,失败 = 锁被占用 -- 释放锁 DELETE FROM distributed_lock WHERE lock_key = 'order:1001' AND holder = 'uuid';缺点:性能差(磁盘 IO)、需要定时清理过期锁、没有阻塞等待机制。
总结
| 问题 | 关键词 |
|---|---|
| 基础实现 | SET NX EX + Lua 释放 |
| 防死锁 | EX 过期时间 |
| 防误删 | UUID 标识持有者 |
| 锁超时 | Redisson 看门狗续期 |
| 可重入 | Hash 存重入次数 |
| 等待机制 | 发布订阅,非轮询 |
| 主从安全 | RedLock(有争议) |
| 生产选型 | Redisson,强一致用 ZK |
五、高可用
高可用的三个层次
主从复制
└── 解决:单点故障读压力,提供数据备份
但:主节点宕机需要手动切换
哨兵(Sentinel)
└── 解决:主从基础上实现自动故障转移
但:写操作只有一个主节点,存储容量有限
集群(Cluster)
└── 解决:数据分片,突破单机容量和写性能瓶颈主从复制
三种模式:全量复制、基于长连接的命令传播、增量复制。
是什么
一个主节点(master)+ 多个从节点(slave),主节点负责读写,从节点只读,主节点的数据自动同步到从节点。
写
客户端 ──→ Master ──┬──→ Slave1(只读)
读 └──→ Slave2(只读)
└──→ Slave3(只读)配置
bash
# 从节点配置文件里加一行
replicaof 192.168.1.1 6379
# 或运行时动态配置
REPLICAOF 192.168.1.1 6379第一次同步:全量复制
从节点第一次连接主节点,触发全量同步(主服务器会把所有的数据都同步给从服务器):
Slave Master
│ │
├── 发送 PSYNC ? -1 ─────────→ │ (我是新节点,不知道runID和offset)
│ │
│ ← 返回 FULLRESYNC │ (给你我的 runID 和当前 offset)
│ runID offset ──────────────┤
│ ├── 执行 BGSAVE,生成 RDB
│ ├── 期间新写命令存入 replication buffer
│ ← 发送 RDB 文件 ─────────────┤
│ │
├── 加载 RDB │
│ │
│ ← 发送 replication buffer ───┤ (补发 RDB 期间的增量命令)
│ │
├── 执行增量命令 │
│ │
└── 同步完成 │- 建立连接:执行
psync拿主服务器的runID和复制进度offset,主服务器收到后响应FULLRESYNC(全量复制) 以携带 runID 和 offset。- runID:每个 Redis 服务器启动时产生的随机 ID 用于标识自己,第一次同步被设置为 ?
- offset:复制进度,第一次同步设置为 -1
- 开始同步:Master 执行
bgsave异步生成 RDB 文件后发给 Slave,Slave 收到后清空当前数据并载入 RDB 文件,该过程中的写命令存入replication buffer(主从一致):- Master 生成 RDB 文件期间
- Master 发送 RDB 文件给 Slave 期间
- Slave 加载 RDB 文件期间
- 发送命令:Slave 完成载入后回复一个 ACK,接着 Master 将
replication buffer缓冲区的命令发送出去,然后 Slave 执行,此时主从一致。
我们还可以通过将 Slave 作为 Master 继续
replicaof,从而减轻主服务器的压力
日常同步:基于长连接的命令传播
完成第一次同步后,为保证后续主从一致,双方之间会维护一个 TCP 连接,并且是长连接(避免频繁的 TCP 连接和断开带来的性能开销)。主节点每执行一条写命令,实时通过这条长连接发给从节点,从节点同步执行。
主节点执行:SET name xmon
↓
通过长连接实时发送给所有从节点
↓
从节点执行:SET name xmon
↓
数据保持一致这是正常运行期间持续同步的核心机制。
注意:主从同步是异步的,主节点不等从节点确认就返回客户端,所以极端情况下(主节点宕机)可能丢失少量数据。
心跳检测:
长连接期间主从之间有心跳机制互相检测对方是否存活:
从节点每秒发送:REPLCONF ACK offset
→ 告诉主节点自己当前同步到哪个 offset
→ 主节点借此判断从节点是否存活、同步是否有延迟
主节点每 10s 发送:PING
→ 检测从节点是否存活断线重连:增量复制
从节点断线重连后触发,不重新做全量复制,只补同步断线期间缺失的数据。
Slave Master
│ │
├── 断线重连 │
├── 发送 PSYNC runID offset ───────→ │
│ (我记得你的 runID,我同步到 offset X)
│ │
│ Master 检查:
│ ① runID 是我吗? ✅
│ ② offset 还在 repl_backlog_buffer 范围内吗?
│ ✅ → 增量复制
│ ❌ → 重新全量复制
│ │
│ ← 发送 offset 之后的命令 ──────── │
│ │
└── 执行增量命令,同步完成 │增量复制时,主服务器怎么知道要将哪些增量数据发送给从服务器呢?
repl_backlog_buffer:环形缓冲区,用于主从断练后找寻差异数据replication offset:标记上面缓冲区的同步进度,主从都有各自的偏移量
repl_backlog_buffer 缓冲区何时写入?
重连后,Slave 会发送 psync 将自己的复制偏移量 slave_repl_offset 发送给 Master,Master 则根据自己和 Slave 的复制偏移量决定从服务器执行哪种同步操作:
- offset 还在缓冲区内 → 增量复制
- offset 已被覆盖 → 只能全量复制
断线时间越长、写流量越大,越容易触发全量复制,建议适当调大:
bash
repl-backlog-size 10mb主从复制的问题
主节点宕机
↓
从节点有数据,但无法自动升为主节点
↓
需要人工介入,修改配置,重启
↓
期间服务不可用→ 这就是哨兵要解决的问题
哨兵(Sentinel)
是什么
哨兵是一组独立的 Redis 进程(通常 3 个,设定为奇数),专门负责监控主从节点,自动完成故障转移。
Sentinel1 Sentinel2 Sentinel3
│ │ │
└───────────┼───────────┘
│ 监控
┌──────┴──────┐
Master Slave1
Slave2哨兵的三大职责
-
监控(Monitoring)
每个哨兵每隔 1 秒向主从节点发送
PING,检查是否在线。节点回复 PONG → 正常 节点超时无响应 → 该哨兵标记为【主观下线(SDOWN)】 -
仲裁(Quorum)
单个哨兵说宕机了不算,需要多数哨兵达成共识才能确认:
Sentinel1:Master 没响应,我认为它主观下线 ↓ Sentinel1 询问 Sentinel2、Sentinel3:你们觉得 Master 还活着吗? ↓ 超过 quorum 数量(默认2,默认哨兵/2+1)的哨兵都认为下线 ↓ 确认【客观下线(ODOWN)】,触发故障转移为什么需要多数仲裁? 防止网络抖动导致的误判,一个哨兵网络隔离了,不代表主节点真的宕机。
-
故障转移(Failover)
确认主节点客观下线后,哨兵们先选出一个 Leader 哨兵来执行故障转移:
Leader 哨兵选举(Raft 算法): 每个哨兵给自己投票,同时拉票 第一个获得超过半数票的哨兵成为 LeaderLeader 哨兵执行故障转移:
- 从所有 Slave 中选出新 Master(选举规则见下)
- 让选出的 Slave 执行 SLAVEOF NO ONE(脱离从节点身份)
- 让其他 Slave 执行 SLAVEOF 从而指向新 Master 地址
- 通知客户端新 Master 地址(通过 pub/sub 频道)
- 原 Master 恢复后,作为新 Master 的 Slave 加入
新 Master 的选举规则
按优先级依次判断:
① slave-priority(replica-priority)配置值,越小越优先
→ 可以手动指定哪个从节点优先升主
② 与原 Master 数据最接近的(offset 最大的)
→ 数据最全,丢失最少
③ runID 最小的
→ 前两条都一样时的最终决策哨兵的问题
哨兵解决了高可用,但写操作仍然只有一个 Master
→ 写性能无法水平扩展
→ 单机内存上限就是存储上限(比如最多 64GB)
→ 数据量很大时,单机撑不住→ 这就是 Cluster 要解决的问题
Cluster 集群
是什么
Redis Cluster 把数据分散存储到多个主节点,每个主节点负责一部分数据,同时每个主节点有自己的从节点做高可用。
Master1(slot 0~5460) + Slave1
Master2(slot 5461~10922) + Slave2
Master3(slot 10923~16383)+ Slave3数据分片:哈希槽(Hash Slot)
Redis Cluster 使用 CRC16 哈希算法把所有数据映射到 16384 个 slot(哈希槽):
key 属于哪个 slot:
slot = CRC16(key) % 16384
slot 属于哪个节点:
由集群配置决定,比如 0~5460 在 Master1为什么是 16384 个槽? 16384 = 2^14,用 bitmap 表示每个节点负责的槽,每个节点只需要 2KB 就能存完整的槽位图,节点间心跳包传输成本低。
一致性哈希 vs 哈希槽:
| 一致性哈希 | 哈希槽 | |
|---|---|---|
| 扩容影响 | 只影响相邻节点 | 需要手动迁移槽 |
| 数据倾斜 | 可能不均匀 | 可以精确控制 |
| 实现复杂度 | 高 | 简单直观 |
由上我们可以知道数据是如何分的了,那么,客户端是怎么知道该访问哪台 Redis 的?
客户端是怎么知道该访问哪台机器的?
客户端自行缓存「槽 → 节点」的地图
客户端可以连接任意节点,在启动的时候,会主动去任意一个节点拉一份「哪个槽归哪台节点管」的映射表,把它缓存在自己本地,节点会计算 key 应该在哪个槽,如:0 ~ 5460 号槽在 A 节点等。
客户端访问 key 的流程如下:
- CRC16 计算 key 所属的槽位
- 查看地图,查看这个槽归哪个节点
- 向节点发请求
整个过程都是本地计算,并且一次请求就能命中,效率高,这种带本地缓存地图的客户端被称为Smart Client(智能客户端)。Java的Jedis、Lettuce,Go 的 go-redis,甚至你用 redis-cli -c 加了-c 参数后,都是 Smart Client的行为。
地图过期:MOVED 重定向
由于该地图是客户端一次性拉取下来的,有一定的时效性,后续的集群的扩缩容会导致其过期,因此 Redis 的解决方案称为 MOVED 重定向,过程如下:
客户端 → 访问 key="name" → 连接 Master1(地图上显示,但是已过期,槽已被迁移到 Master2)
Master1 计算:slot = CRC16("name") % 16384 = 5798
5798 不在我的范围(0~5460),在 Master2
Master1 返回:(error)MOVED 5798 192.168.1.2:6379(通知客户端)
客户端 → 立即更新本地地图 → 重新连接 Master2 → 访问成功槽迁移:ASK 重定向
新增节点(扩缩容)时,把部分槽从旧节点迁移到新节点:
原来:Master1(0~5460),Master2(5461~10922),Master3(10923~16383)
新增:Master4
迁移:从 Master1、Master2、Master3 各拿出一部分槽给 Master4
之后:每个节点负责约 4096 个槽迁移过程中,槽处于 MIGRATING(迁出) 和 IMPORTING(迁入) 状态,期间的请求用 ASK 重定向处理,不影响正常访问,错误消息如下:
(error) ASK 100 192.168.1.2:6379
意思是:这个 key 这一次你去 Master2 问问看,但这只是临时的,不要更新你的地图客户端(不更新本地地图) → 发送 ASKING 给 Master2 → 重新连接 Master2 → 访问成功
MOVED 和 ASK 核心区别:
MOVED 是永久搬家通知 ,客户端要更新地图;ASK是临时借道通知,客户端这一次跳过去,地图不动。
节点之间同步信息:Gossip 协议
总结:Gossip 协议让每个节点定期随机找几个邻居互换信息,像流言一样扩散,最终整个集群达成一致。优点是去中心化、扩展性强、容错好;缺点是只能做到最终一致,有传播延迟。Redis Cluster 用它来同步节点状态和槽位信息,故障检测用 PFAIL/FAIL 两阶段仲裁防止误判。
Gossip 是一种去中心化的信息传播协议,灵感来自现实中的流言传播:
你告诉两个朋友一个消息
这两个朋友各自再告诉两个朋友
...
最终所有人都知道了这个消息集群总线端口(cluster bus)不是 6379(业务端口),而是 16379(业务端口 + 10000),注意:部署 Cluster 时,两个端口都要放行
核心思想
每个节点周期性地随机选几个邻居节点,互相交换自己知道的信息,经过若干轮传播后,整个集群的所有节点都能获得一致的状态。
集群有 A B C D E 五个节点
第1轮:
A 随机选 B、C → 把自己的状态发给 B、C
B 随机选 A、D → 把自己的状态发给 A、D
...
第2轮:
B 已经知道了 A 的状态,再传播给 D、E
...
几轮之后:所有节点都知道整个集群的状态Gossip 消息类型
Redis Cluster 中节点间交换四种消息:
-
PING
节点 A 定期向随机选取的几个节点发送 PING 携带信息: - 自己的状态(地址、负责的槽位、主从关系) - 自己知道的部分其他节点状态 -
PONG
收到 PING 的节点回复 PONG 携带信息:同 PING,也会带上自己知道的节点状态 双向交换信息,一次通信两个节点都能更新状态 -
MEET
新节点加入集群时发送 MEET 消息 告诉已有节点:我来了,把我加入集群 收到 MEET 的节点回复 PONG,建立连接 之后新节点的信息通过 Gossip 扩散到整个集群 -
FAIL
某节点被判定为故障时,立即向所有节点广播 FAIL 消息 (这里不用 Gossip 随机传播,而是直接广播,加快故障感知速度)
Gossip 的特性
-
优点
-
去中心化:
没有中心节点,任何节点都对等 不存在单点故障,一个节点宕机不影响协议运行 -
扩展性强:
新节点加入只需要发送 MEET 给任意一个节点 信息自动扩散到整个集群,不需要通知所有节点 -
容错性强:
消息会通过多条路径传播 即使部分节点宕机或消息丢失,信息仍能最终传达 -
实现简单:
每个节点逻辑相同,只需要随机选邻居互换信息 不需要复杂的全局协调机制
-
-
缺点
-
最终一致性,不是强一致:
信息传播需要时间(几轮 Gossip 后才能扩散完) 在信息完全扩散前,不同节点看到的集群状态可能不同 -
消息冗余:
同一条信息会被多个节点重复传播 节点越多,冗余消息越多 -
传播延迟:
信息扩散速度 = O(log N)(N 为节点数) 不适合对实时性要求极高的场景 (这也是 FAIL 消息改用广播而非 Gossip 的原因)
-
对比其他一致性协议
| Gossip | Raft | Paxos | |
|---|---|---|---|
| 一致性 | 最终一致 | 强一致 | 强一致 |
| 中心节点 | 无 | 有 Leader | 有 |
| 实现复杂度 | 低 | 中 | 高 |
| 扩展性 | 强 | 一般 | 一般 |
| 适用场景 | 状态同步、成员发现 | 日志复制、选举 | 分布式事务 |
| 典型应用 | Redis Cluster、Cassandra | etcd、Raft Redis | ZooKeeper |
集群的故障转移 failover
主从关系
Redis Cluster 里的每个主节点,都可以配一个或多个从节点(默认 3 主 3 从),但从节点默认不对外提供读写服务,如果连上从节点去 GET 一个 key,从节点会返回 MOVED 让你回去找主节点(READONLY 可更改)
节点故障检测
-
主观下线(PFAIL, Probably FAILed)
节点 A 向节点 B 发送 PING 超过 cluster-node-timeout(默认15s)没有收到 PONG → 节点 A 将节点 B 标记为 PFAIL(主观下线) → 只是 A 自己认为,可能是网络抖动 -
客观下线(FAIL)
节点 A 在 Gossip 消息里传播"B 可能挂了" 其他节点也陆续反馈对 B 的 PFAIL 当超过集群半数的主节点都认为 B 是 PFAIL → 将 B 标记为 FAIL(客观下线) → 广播 FAIL 消息,触发故障转移
Cluster 的选举机制
类似 Raft 的投票机制,流程大概如下:
- 资格检查:
cluster-replica-validity-factor参数判断从节点与节点是否失联太久,如果失联很久则没资格。 - 排队发起选举:Slave 按照与 Master 的数据同步进度排队,复制的越新的 Slave 等待时间越短。
- 发起选举,请求投票:Slave 开始拉票(只有持有槽的主节点才有投票权)。
- 收集选票
- 成为新主:半数以上主节点的票当选新主
Cluster 的限制
① 不支持多 key 事务(key 可能在不同节点)
解决:用 hash tag 强制同类 key 落在同一个槽
{user}:name 和 {user}:age → CRC16 只算 {} 里的内容 → 同一个槽
② 只有 db0(不支持 SELECT 切换数据库)
③ 批量操作(MSET/MGET)要求所有 key 在同一个槽
④ 最少需要 3 主 3 从,共 6 个节点三种方案对比
| 主从复制 | 哨兵 | Cluster | |
|---|---|---|---|
| 高可用 | ❌ 需手动切换 | ✅ 自动故障转移 | ✅ 自动故障转移 |
| 读扩展 | ✅ 从节点分担读 | ✅ | ✅ |
| 写扩展 | ❌ 只有一个主 | ❌ 只有一个主 | ✅ 多主分片 |
| 容量扩展 | ❌ | ❌ | ✅ |
| 复杂度 | 低 | 中 | 高 |
| 适用场景 | 读多写少,数据量小 | 需要自动故障转移 | 数据量大,高并发写 |
面试
Q:主从复制是同步还是异步?会丢数据吗?
异步复制,主节点不等从节点确认就返回给客户端。主节点宕机时,未同步到从节点的数据会丢失。可以用
min-replicas-to-write要求至少 N 个从节点同步成功才返回,降低丢数据风险,但影响写性能。
Q:哨兵为什么至少要部署 3 个?
需要多数仲裁,2 个哨兵时一个挂了,剩下 1 个无法达成多数(需要 >=2),集群失去故障转移能力。3 个哨兵允许 1 个挂掉还能正常工作。同理,哨兵数量建议是奇数。
Q:Cluster 为什么是 16384 个槽而不是 65536 个?
节点间心跳包里包含槽位图,16384 个槽用 bitmap 表示只需 2KB;65536 个槽需要 8KB,心跳包太大,网络开销高。且一般 Redis Cluster 不超过 1000 个节点,16384 个槽完全够用。
Q:脑裂问题是什么?如何解决?
网络分区导致集群中出现两个 Master,各自接受写入,网络恢复后数据冲突。 解决:设置
min-replicas-to-write 1,要求至少 1 个从节点在线才接受写入,孤立的 Master 自动停止写服务,避免脑裂期间产生脏数据。
总结
主从 解决读扩展和数据备份,哨兵 在主从基础上加了自动故障转移,Cluster 在哨兵基础上加了数据分片突破单机容量瓶颈。三者层层递进,根据数据量和可用性要求选型:小项目主从够了,中型项目上哨兵,大规模高并发上 Cluster。
六、原理
Redis 为什么这么快?
① 纯内存操作(最核心)
② 单线程模型,避免线程切换和锁竞争
③ IO 多路复用,单线程处理大量并发连接
④ 高效的数据结构(SDS、跳表、ziplist...)
⑤ 渐进式 rehash、惰性删除等机制避免集中阻塞之所以 Redis 采用单线程(网络 I/O 和执行命令)那么快,有如下几个原因:
- Redis 大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- 采用单线程模型可以避免多线程之间的竞争,省去多线程切换带来的时间和性能上的开销,而且也不会导致死锁
- 采用 I/O 多路复用机制处理大量的客户端 Socket 请求
单线程模型
Redis 到底哪里是单线程?
这个问题要说清楚,Redis 并不是所有地方都单线程:
单线程的部分:
命令处理(网络读写 + 命令执行)← 核心,这里是单线程
多线程的部分(Redis 4.0+):
AOF 刷盘
RDB 持久化(fork 子进程)
大 key 异步删除(UNLINK)
多线程的部分(Redis 6.0+):
网络 IO 读写(多线程解析请求、写回响应)
但命令执行本身仍然是单线程所以准确的说法是:命令执行是单线程的,网络 IO 在 6.0 后引入了多线程。
为什么命令执行用单线程?
多线程的代价:
① 线程切换(上下文切换)消耗 CPU
② 共享数据需要加锁(synchronized / mutex)
③ 锁竞争、死锁问题
④ 代码复杂度高
Redis 的命令执行是纯内存操作,本身极快(微秒级)
瓶颈不在 CPU,而在网络 IO
→ 多线程带来的收益远小于它的开销
→ 单线程反而更简单、更快单线程的执行流程
Redis 启动
↓
初始化 server,创建 epoll 实例
↓
监听端口,注册 accept 事件
↓
进入事件循环(死循环):
├── epoll_wait 等待事件(可读/可写)
├── 处理文件事件(客户端请求)
│ ├── 新连接:accept,注册读事件
│ ├── 可读:读取命令,解析,执行,写响应到缓冲区
│ └── 可写:把缓冲区响应发给客户端
└── 处理时间事件(定时任务,如定期删除过期key)整个过程在一个线程里完成,没有锁,没有切换。
Redis 6.0 为什么引入多线程网络 IO?
随着网络带宽提升,瓶颈从内存操作转移到了网络 IO:
读取客户端请求(read syscall)
解析请求协议(RESP 协议)
把响应写回客户端(write syscall)
这些 IO 操作比命令执行慢得多,单线程处理成了瓶颈
Redis 6.0 方案:
多个 IO 线程并行读取请求、解析协议、写回响应
但命令执行仍然由主线程串行处理(保证线程安全)
IO 线程1 ──→ 读取并解析请求 ──┐
IO 线程2 ──→ 读取并解析请求 ──┼──→ 主线程串行执行命令 ──→ IO 线程并行写响应
IO 线程3 ──→ 读取并解析请求 ──┘IO 多路复用
先理解网络 IO 的问题
假设 Redis 要同时处理 10000 个客户端连接,朴素的做法:
方案一:每个连接一个线程
10000 个连接 = 10000 个线程
→ 内存爆炸(每个线程约 1MB 栈)
→ 线程切换开销极大
方案二:单线程轮询
while(true) {
for each connection:
if has data: read and process
}
→ 大量无效轮询,CPU 空转
→ 延迟高IO 多路复用 是正确解法:用一个线程监听多个连接,哪个连接有事件就处理哪个,没有事件就阻塞等待,不浪费 CPU。
三种 IO 多路复用机制
select(最古老)
c
int select(int nfds, fd_set *readfds, fd_set *writefds, ...);
// 原理:
// 把所有 fd(文件描述符)复制到内核
// 内核遍历所有 fd,检查哪些有事件
// 返回有事件的 fd 数量,用户再遍历找出哪些有事件
缺点:
① fd 数量上限 1024(FD_SETSIZE)
② 每次调用都要把全部 fd 从用户态复制到内核态
③ 内核遍历所有 fd,O(n) 复杂度
④ 返回后用户还要遍历一遍找出就绪的 fdpoll(改进版 select)
c
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
改进:用链表存 fd,去掉了 1024 上限
仍然存在:
① 每次调用复制全部 fd 到内核
② O(n) 遍历
③ 返回后用户还要轮询epoll(Linux 主流,Redis 使用)
c
// 三个核心函数
int epoll_create(int size); // 创建 epoll 实例
int epoll_ctl(int epfd, int op, int fd, ...); // 注册/修改/删除 fd
int epoll_wait(int epfd, epoll_event *events, ...); // 等待事件核心改进:
① 内核维护一棵红黑树存所有监听的 fd
→ 增删 fd 是 O(log n),不需要每次复制全部 fd
② 内核维护一个就绪链表
fd 有事件时,硬件中断回调把该 fd 加入就绪链表
→ epoll_wait 只返回就绪的 fd,不用遍历全部
③ 返回的就是就绪事件列表
→ 用户不需要再轮询一遍
性能对比:
select / poll epoll
fd 复制 每次全部复制 只注册一次
时间复杂度 O(n) O(1)(就绪事件数)
fd 上限 1024 / 无限 无限
返回结果 需要用户轮询 直接返回就绪 fdepoll 的两种触发模式
水平触发(LT,Level Triggered)默认
fd 有数据未读完 → 每次 epoll_wait 都会通知
→ 不容易漏事件,编程简单边缘触发(ET,Edge Triggered)
fd 状态变化时只通知一次 → 必须一次性读完所有数据
→ 减少系统调用次数,性能更高
→ 编程复杂,必须配合非阻塞 IORedis 使用的是水平触发,编程简单,不容易丢事件。
Redis 的事件驱动模型
Redis 自己封装了一套事件驱动框架(ae),屏蔽了底层 select/epoll 的差异:
┌─────────────────────────────────────┐
│ Redis ae 事件库 │
├─────────────────────────────────────┤
│ epoll(Linux) │
│ kqueue(macOS/BSD) │
│ select(Windows/兜底) │
└─────────────────────────────────────┘两类事件:
文件事件(File Event):网络 IO 相关
├── 连接事件:新客户端连接(acceptTcpHandler)
├── 读事件:客户端发来命令(readQueryFromClient)
└── 写事件:把响应写回客户端(sendReplyToClient)
时间事件(Time Event):定时任务
└── serverCron:每 100ms 执行一次
├── 定期删除过期 key
├── 持久化检查
├── 主从同步
└── 统计信息更新...完整处理流程:
epoll_wait(阻塞等待事件,超时时间 = 最近时间事件的剩余时间)
↓ 有事件
处理所有就绪的文件事件(网络读写)
↓
检查时间事件是否到期,到期则执行
↓
回到 epoll_waitRedis 事务
基本命令
bash
MULTI # 开启事务,后续命令进入队列
SET key1 val1 # 入队(不立即执行)
SET key2 val2 # 入队
INCR counter # 入队
EXEC # 提交,按顺序执行队列里的命令
DISCARD # 放弃事务,清空队列
bash
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET name xmon
QUEUED ← 注意是 QUEUED,不是执行结果
127.0.0.1:6379> INCR age
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) (integer) 22WATCH:乐观锁
bash
WATCH key1 key2 # 监听 key,事务执行前如果被修改,事务自动失败
MULTI
SET key1 newval
EXEC # 如果 key1 在 WATCH 之后被其他客户端修改 → 返回 nil(事务取消)
经典用法(类似 CAS):
WATCH balance # 监听余额
val = GET balance # 读取当前值
MULTI
SET balance val-100 # 扣款
EXEC # 如果期间 balance 被改了,返回 nil
# 应用层重试Redis 事务和 MySQL 事务的区别
| Redis 事务 | MySQL 事务 | |
|---|---|---|
| 原子性 | 弱(命令运行时错误不回滚) | 强(任何错误全部回滚) |
| 隔离性 | 执行期间不被打断 | 多种隔离级别 |
| 回滚 | ❌ 不支持 | ✅ 支持 |
| 持久性 | 依赖持久化配置 | WAL 保证 |
Redis 事务的两种错误
-
语法错误(入队时报错)
整个事务不执行:
MULTI SET name xmon # QUEUED WRONGCMD # ERROR:未知命令 SET age 21 # QUEUED EXEC # 返回错误,整个事务取消 -
运行时错误(执行时出错)
只有出错的命令失败,其他命令正常执行,不回滚:
MULTI SET name xmon # QUEUED(正确命令) INCR name # QUEUED(name是字符串,INCR会出错,但入队成功) SET age 21 # QUEUED(正确命令) EXEC 1) OK # SET name 成功 2) ERR # INCR name 失败,但不影响其他 3) OK # SET age 成功这是 Redis 事务最大的局限:不支持运行时回滚。 Redis 认为运行时错误是编程错误,不需要回滚机制。
Q:事务为什么不支持回滚?
A:Redis 官方的解释:
- Redis 命令只有在语法正确且数据类型匹配时才会失败,这类错误是编程失误,应该在开发阶段发现
- 不支持回滚让 Redis 内部实现更简单、更快
面试
Q:Redis 单线程为什么还这么快?
纯内存操作本身极快;单线程避免了线程切换和锁竞争开销;IO 多路复用(epoll)用一个线程高效处理大量并发连接;命令执行是 O(1) 或 O(log n);数据结构针对性优化(SDS、跳表、ziplist)。
Q:Redis 6.0 的多线程和之前有什么区别?
之前完全单线程;6.0 对网络 IO 部分(读请求、解析协议、写响应)引入多线程提高吞吐量,但命令执行本身仍是单线程串行,保证数据安全,不需要加锁。
Q:epoll 比 select 好在哪里?
select 每次调用需要把全部 fd 复制到内核,O(n) 遍历,fd 上限 1024;epoll 用红黑树维护 fd,只在注册时复制一次,内核通过回调维护就绪链表,epoll_wait 直接返回就绪 fd,O(1) 复杂度,无 fd 数量限制。
Q:Redis 事务能保证原子性吗?
不完全能。语法错误(入队时报错)会导致整个事务取消;但运行时错误(执行时出错)不会回滚,其他命令照常执行,这点和 MySQL 的原子性不同。严格来说 Redis 事务只保证命令按顺序执行且不被打断,不保证要么全成功要么全失败。
总结
单线程模型:
命令执行单线程,避免锁竞争,简单高效
6.0+ 网络IO多线程,命令执行仍单线程
IO 多路复用:
epoll 监听大量连接,有事件才处理,不空转
文件事件(网络IO)+ 时间事件(定时任务)构成事件循环
过期删除:
惰性删除 + 定期删除配合,expires 字典存过期时间戳
内存淘汰:
8种策略,生产推荐 allkeys-lru/lfu
事务:
MULTI/EXEC 保证命令顺序执行不被打断
不支持运行时回滚,不是真正的强原子性
WATCH 实现乐观锁,应对并发冲突