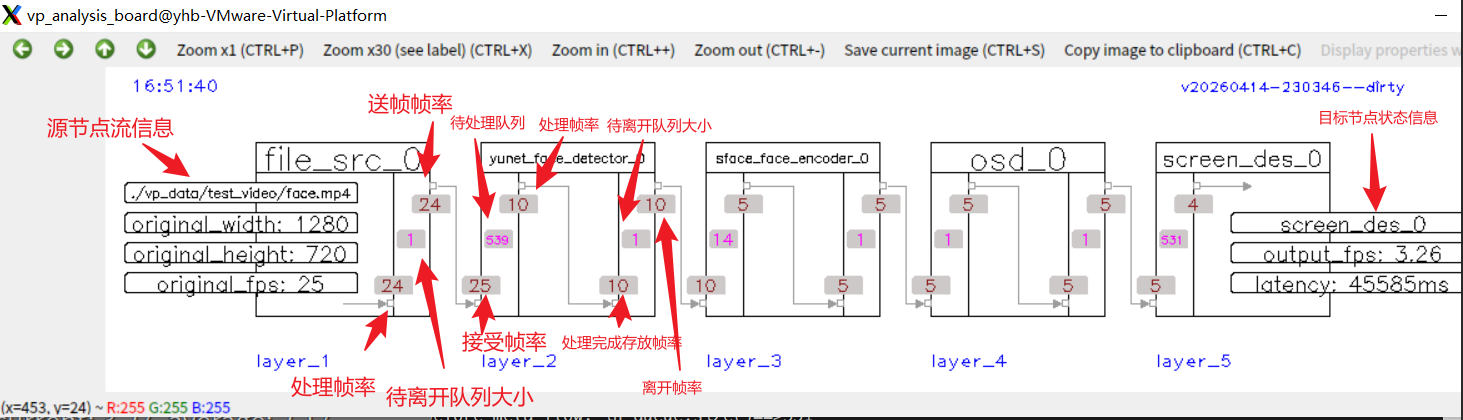
《videopipe学习之从运行面板开始》分析了VideoPipe如何通过观察者模式实现状态监控。我们看到面板上的数字实时跳动,节点状态通过钩子机制自动报告。但这里还有一个有趣的问题:监控的是状态变化,那状态变化所反映的"数据"本身,又是如何在节点间流转的呢?
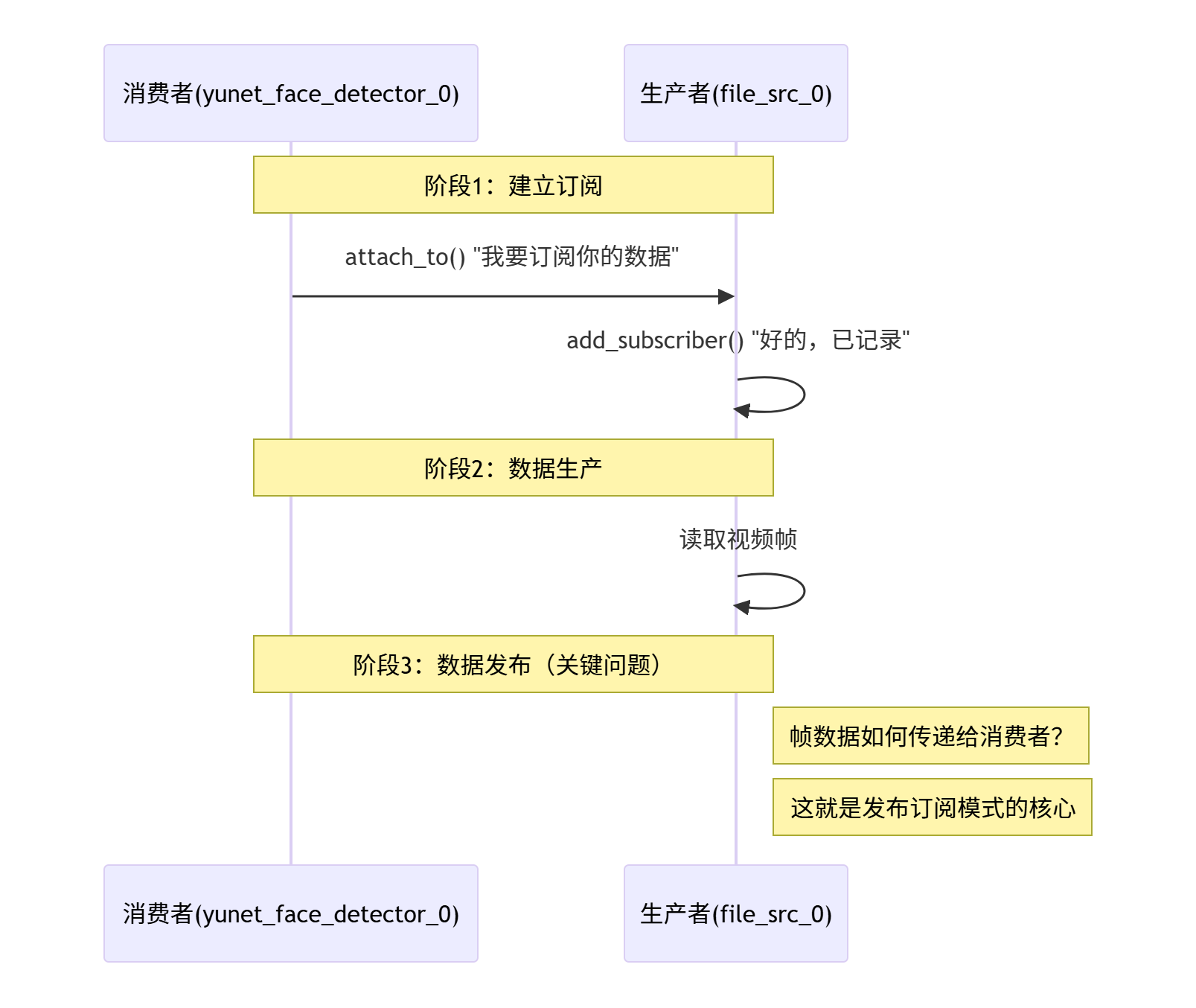
1 从attach_to出发------发布订阅模式的登场
1.1 重新审视attach_to
回想1-1-1_sample.cpp中的attach_to调用:
cpp
// 1-1-1_sample.cpp中的连接代码
yunet_face_detector_0->attach_to({file_src_0});
// attach_to的实际实现
void vp_node::attach_to(std::vector<std::shared_ptr<vp_node>> pre_nodes) {
for (auto &pre_node: pre_nodes) {
pre_node->add_subscriber(this->shared_from_this()); // 关键:向生产者注册
}
}attach_to实际上是消费者向生产者注册自己。yunet_face_detector_0对file_src_0说:"我是你的订阅者,有数据请通知我。"
1.2 订阅者列表的管理
add_subscriber做了什么?数据如何从生产者流向消费者?
cpp
// vp_meta_publisher.cpp
void vp_meta_publisher::add_subscriber(std::shared_ptr<vp_meta_subscriber> subscriber) {
std::lock_guard<std::mutex> guard(subscribers_lock);
// 将订阅者加入列表
subscribers.push_back(subscriber);
}线程安全:通过subscribers_lock保护订阅者列表。
维护订阅关系:将订阅者指针存入subscribers向量。
建立映射:生产者知道"谁订阅了我的数据"。
1.3 数据如何传递
现在订阅关系建立了,但数据如何传递?这就是发布订阅模式要解决的问题:
2 发布订阅架构------装饰器模式的双重体现
2.1 节点也是多重"装饰"的结果
在分析add_subscriber时,我们发现一个有趣的问题:add_subscriber方法是vp_meta_publisher类的成员函数。但节点类vp_node为什么会有这个方法?
让我们看vp_node的定义:
cpp
// 来自vp_node.h的实际继承关系
class vp_node: public vp_meta_publisher, // ← 关键:继承了发布者接口
public vp_meta_subscriber, // ← 也继承了订阅者接口
public vp_meta_hookable, // ← 还有监控钩子接口
public std::enable_shared_from_this<vp_node> {
// ...
};vp_meta_publisher接口赋予节点发布者能力。
vp_meta_subscriber接口赋予节点订阅者能力。
vp_meta_hookable接口赋予节点监控报告能力------上篇文章主要探索的核心。
这不正是装饰器模式的典型应用吗?节点通过继承不同的接口,被"装饰"上了不同的能力。
在这些装饰的接口中,vp_meta_publisher和vp_meta_subscriber一起构成了发布订阅模式的实现基础。
2.2 完整的装饰器视图
让我们看看VideoPipe如何通过装饰器模式为节点装配能力:
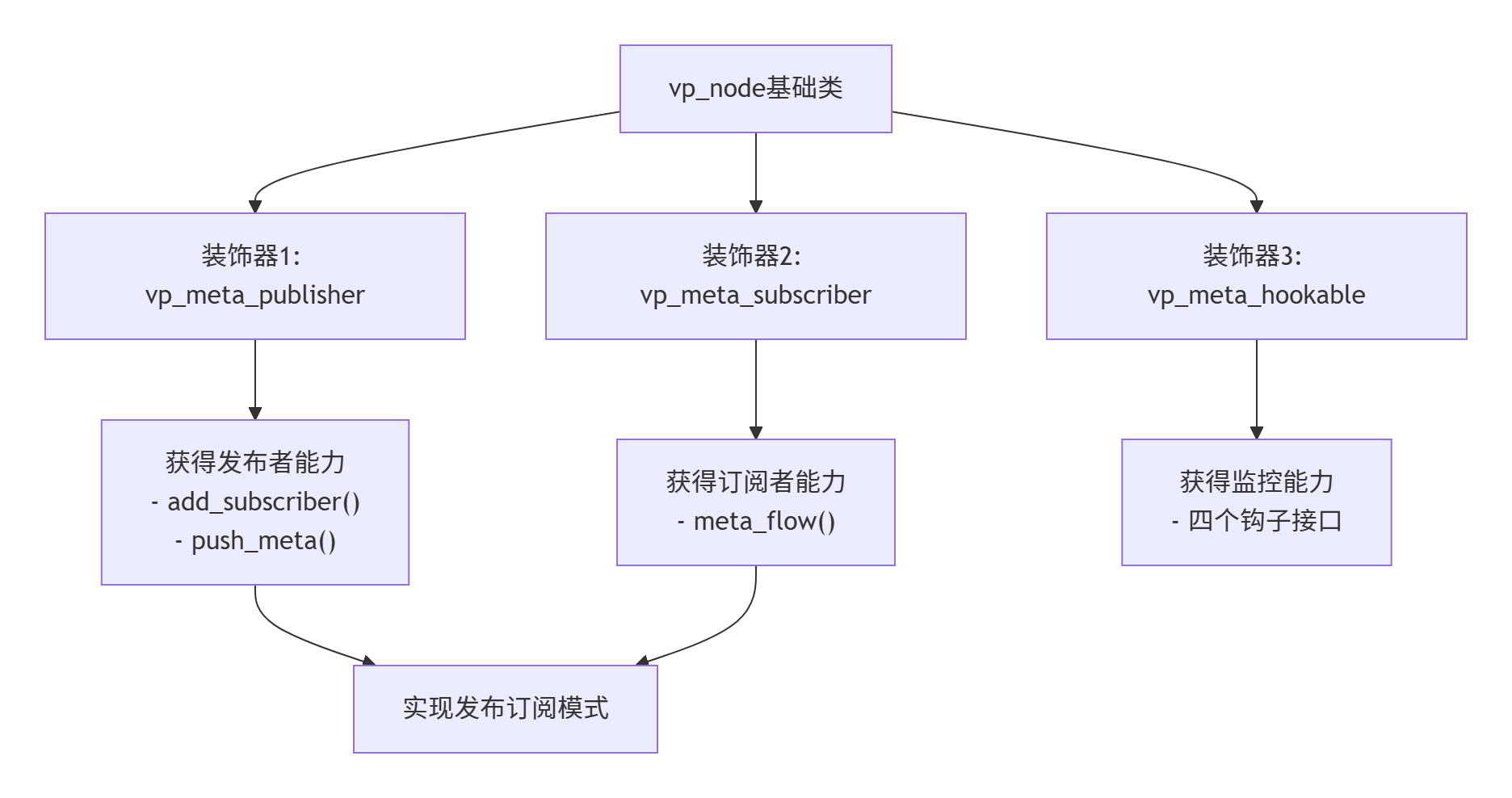
关键洞察:发布订阅模式在VideoPipe中是通过装饰器模式实现的:
装饰器模式:为节点动态添加能力(发布、订阅、监控)。
发布订阅模式:利用这些装饰的能力实现数据流转。
观察者模式:利用监控装饰实现状态报告。
2.3 发布订阅模式的完整实现
现在让我们看看发布订阅模式如何工作:
在vp_meta_publisher.h中:
cpp
class vp_meta_publisher {
public:
virtual void add_subscriber(std::shared_ptr<vp_meta_subscriber> subscriber) = 0;
virtual void push_meta(std::shared_ptr<vp_objects::vp_meta> meta) = 0; // 关键:发布方法
protected:
std::vector<std::shared_ptr<vp_meta_subscriber>> subscribers; // 订阅者列表
std::mutex subscribers_lock; // 线程安全保护
};在vp_meta_subscriber.h中:
cpp
class vp_meta_subscriber {
public:
virtual void meta_flow(std::shared_ptr<vp_objects::vp_meta> meta) = 0; // 关键:接收方法
};数据流转过程:
生产者通过add_subscriber收集订阅者。
生产者通过push_meta发布数据。
订阅者通过meta_flow接收数据。
2.4 完整的故事线
现在我们可以完整理解attach_to建立的连接:`
cpp
用户代码:yunet_face_detector_0->attach_to({file_src_0})
实际含义:
1. yunet_face_detector_0(装饰了vp_meta_subscriber)
2. 向file_src_0(装饰了vp_meta_publisher)注册
3. 建立file_src_0.subscribers列表包含yunet_face_detector_0
4. 当file_src_0有数据时,通过push_meta()推送给所有订阅者
5. 订阅者通过meta_flow()接收数据2.5 节点的双重身份:发布者与订阅者
基于前面的分析,我们发现VideoPipe中的节点有一个关键特征:一个节点可以同时是发布者和订阅者。
这种双重身份体现在:
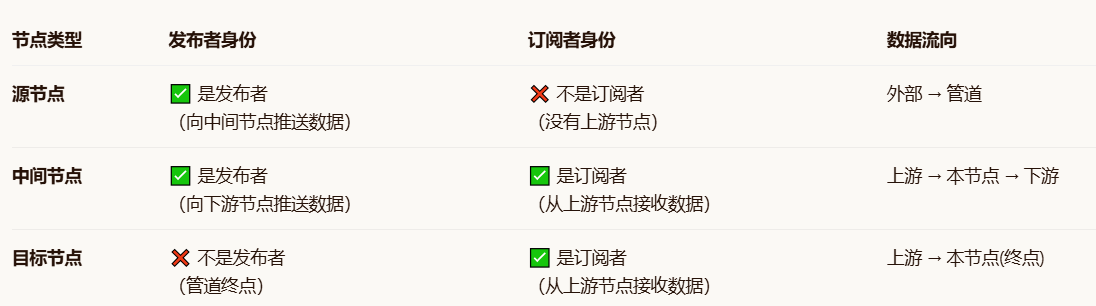
发布订阅模式与生产者-消费者模式的对应:
发布者 = 生产者
订阅者 = 消费者
中间节点:既是生产者又是消费者
源节点:只是生产者
目标节点:只是消费者
这种设计使得VideoPipe的管道可以灵活组合,每个节点只需要关注自己的处理逻辑,上下游关系通过发布订阅模式自动管理。
3 发布订阅的线程生命周期
理解了节点的双重身份,我们面临一个关键问题:订阅关系建立了,发布者和订阅者的能力也通过装饰器赋予了节点,但数据如何开始流动?
发布者接口(push_meta)和订阅者接口(meta_flow)只是静态的能力定义,需要有执行引擎来让这些接口真正工作。这就是VideoPipe线程模型的作用。
线程是发布订阅模式的执行引擎:
处理线程:执行订阅者能力,消费数据。
分发线程:执行发布者能力,推送数据。
没有线程,接口只是纸上谈兵。
让我们看看这些执行引擎如何创建、运行和销毁。
3.1 线程的初始化创建
从vp_node.h中我们可以看到,vp_node类包含两个线程成员:
cpp
// 处理线程
std::thread handle_thread;
// 分发线程
std::thread dispatch_thread;线程的创建发生在initialized()方法中。从vp_node.cpp可以看到:
cpp
void vp_node::initialized() {
// 在所有资源初始化后启动线程
this->handle_thread = std::thread(&vp_node::handle_run, this);
this->dispatch_thread = std::thread(&vp_node::dispatch_run, this);
}关键点:
线程在initialized()方法中创建。
处理线程执行handle_run方法。
分发线程执行dispatch_run方法。
这两个方法都是vp_node类的成员函数。
至于initialized方法谁来调用,一般是vp_node的子类构造函数里调用它,比如vp_file_src_node的构造函数里调用。
3.2 源节点的特殊处理
从vp_src_node.h中我们看到,源节点重写了handle_run方法:
cpp
// 强制在子类中重新实现
virtual void handle_run() override;在vp_src_node.cpp中,源节点的handle_run方法抛出异常:
cpp
void vp_src_node::handle_run() {
throw vp_excepts::vp_not_implemented_error("必须为源节点重新实现'handle_run'方法!");
}设计意图:这是防护设计,确保源节点不能直接使用,必须派生子类实现自己的handle_run逻辑,因为源节点是管道的起点,需要主动生成数据而不是等待输入。
3.3 目标节点的特殊处理
从vp_des_node.h中我们看到,目标节点重写了dispatch_run方法:
cpp
// 在目标节点中什么都不做
virtual void dispatch_run() override final;在vp_des_node.cpp中,目标节点的dispatch_run方法为空:
cpp
// 在所有目标节点中,分发线程立即终止
void vp_des_node::dispatch_run() {
// dispatch thread terminates immediately in all des nodes
}设计原因:目标节点是管道的终点,不需要将数据分发给下游节点,因此分发线程可以立即终止。
3.4 线程的销毁
从vp_node.cpp中,我们看到deinitialized()方法的实现:
cpp
void vp_node::deinitialized() {
// 发送死亡标志
alive = false;
{
std::lock_guard<std::mutex> guard(this->in_queue_lock);
this->in_queue.push(nullptr);
this->in_queue_semaphore.signal();
}
// 在vp_node中等待线程退出
if (handle_thread.joinable()) {
handle_thread.join();
}
if (dispatch_thread.joinable()) {
dispatch_thread.join();
}
}线程销毁的关键步骤:
(1)设置alive = false,停止线程循环
(2)向输入队列推送nullptr作为死亡标志
(3)激活输入信号量,唤醒等待的处理线程
(4)使用join()等待线程自然结束
(5)检查线程是否可加入(joinable()),避免重复join()
3.5 源节点的销毁
从vp_src_node.cpp中,我们看到源节点的deinitialized()方法:
cpp
void vp_src_node::deinitialized() {
alive = false;
gate.open();
vp_node::deinitialized();
}源节点特殊处理:
除了调用基类的deinitialized()方法。
还需要打开gate,确保源节点停止工作。
gate是源节点特有的控制机制(从vp_src_node.h可以看到vp_utils::vp_gate gate;)。
3.6 线程与装饰器的关系
回顾第2章的分析,vp_node通过装饰器模式获得能力:
cpp
class vp_node: public vp_meta_publisher, // 发布者能力
public vp_meta_subscriber, // 订阅者能力
public vp_meta_hookable { // 监控能力线程是装饰器能力的执行引擎:
处理线程(handle_thread):执行装饰的订阅者能力。
分发线程(dispatch_thread):执行装饰的发布者能力。
没有线程,装饰器接口只是静态能力定义,无法实际工作。
4 线程执行的数据流转
线程创建后,如何体现节点的双重身份?不同类型的节点(源节点、中间节点、目标节点)通过不同的线程行为来体现它们的发布者/订阅者身份:

让我们具体看看这三种节点的线程实现差异。
4.1 处理线程:订阅者的执行引擎
因为不同类节点子类处理线程处理不同,所以分开查看,如下。
4.1.1 源节点处理线程:主动生产数据
基于vp_file_src_node.cpp,源节点的处理线程实现与中间节点完全不同。源节点是管道的起点,需要主动生成数据:
cpp
void vp_file_src_node::handle_run() {
cv::Mat frame;
int video_width = 0;
int video_height = 0;
int fps = 0;
std::chrono::milliseconds delta;
int skip = 0;
while(alive) {
// 检查是否需要工作
gate.knock();
auto last_time = std::chrono::system_clock::now();
// 尝试打开视频捕获
if (!file_capture.isOpened()) {
if(!file_capture.open(this->gst_template, cv::CAP_GSTREAMER)) {
VP_WARN(vp_utils::string_format("[%s] open file failed, try again...", node_name.c_str()));
continue;
}
}
// 创建帧元数据
auto out_meta =
std::make_shared<vp_objects::vp_frame_meta>(resize_frame, this->frame_index, this->channel_index, video_width, video_height, fps);
if (out_meta != nullptr) {
this->out_queue.push(out_meta);
// 如果需要,激活handled钩子
if (this->meta_handled_hooker) {
meta_handled_hooker(node_name, out_queue.size(), out_meta);
}
// 重要!通知out_queue的消费者
this->out_queue_semaphore.signal();
}源节点处理线程的特点:
(1)主动生成数据:不需要等待输入信号量,主动读取视频文件。
(2)控制工作状态:通过gate.knock()检查是否需要继续工作。
(3)流信息报告:视频打开后触发流信息监控钩子。
(4)帧率控制:通过睡眠时间控制输出帧率。
(5)直接放入输出队列:处理结果直接放入out_queue。
4.1.2 中间节点处理线程:标准消费-生产模式
基于vp_node.cpp,中间节点的处理线程遵循标准的消费者-生产者模式:
cpp
void vp_node::handle_run() {
// 缓存用于批处理(如果需要)
std::vector<std::shared_ptr<vp_objects::vp_frame_meta>> frame_meta_batch_cache;
while (alive) {
// 等待生产者,确保in_queue不为空
this->in_queue_semaphore.wait();
VP_DEBUG(vp_utils::string_format("[%s] 处理前,in_queue大小==>%d", node_name.c_str(), in_queue.size()));
auto in_meta = this->in_queue.front();
// 死亡标志
if (in_meta == nullptr) {
continue;
}
// 激活处理钩子
invoke_meta_handling_hooker(node_name, in_queue.size(), in_meta);
if (out_meta != nullptr && node_type() != p_node_type::DES)
{
VP_DEBUG(vp_utils::string_format("[%s] 放入out_queue前,out_queue大小==>%d", node_name.c_str(), out_queue.size()));
this->out_queue.push(out_meta);
// 激活已处理钩子
invoke_meta_handled_hooker(node_name, out_queue.size(), out_meta);
// 通知out_queue的消费者
this->out_queue_semaphore.signal();
}中间节点处理线程的特点:
(1)等待输入:in_queue_semaphore.wait()- 等待上游节点推送数据。
(2)获取数据:in_queue.front()- 从输入队列获取元数据。
(3)触发监控钩子:invoke_meta_handling_hooker()- 装饰的监控能力。
(4)调用处理方法:根据元数据类型调用相应的处理方法。
(5)放入输出队列:处理结果放入输出队列。
(6)触发完成钩子:invoke_meta_handled_hooker()- 装饰的监控能力。
(7)通知分发线程:out_queue_semaphore.signal()。
4.1.3 目标节点处理:终点消费模式
基于vp_screen_des_node.cpp,目标节点是管道的终点,其处理逻辑特殊:
cpp
std::shared_ptr<vp_objects::vp_meta>
vp_screen_des_node::handle_frame_meta(std::shared_ptr<vp_objects::vp_frame_meta> meta) {
VP_DEBUG(vp_utils::string_format("[%s] received frame meta, channel_index=>%d, frame_index=>%d", node_name.c_str(), meta->channel_index, meta->frame_index));
cv::Mat resize_frame;
if (this->display_w_h.width != 0 && this->display_w_h.height != 0) {
cv::resize((osd && !meta->osd_frame.empty()) ? meta->osd_frame : meta->frame, resize_frame, cv::Size(display_w_h.width, display_w_h.height));
}
else {
resize_frame = (osd && !meta->osd_frame.empty()) ? meta->osd_frame : meta->frame;
}
if (!screen_writer.isOpened()) {
assert(screen_writer.open(this->gst_template, cv::CAP_GSTREAMER, 0, meta->fps, {resize_frame.cols, resize_frame.rows}));
}
screen_writer.write(resize_frame);
// 调用基类中定义的一般工作
return vp_des_node::handle_frame_meta(meta);
}目标节点处理的特点:
(1)显示结果:处理结果显示在屏幕上。
(2)计算性能:在基类vp_des_node::handle_frame_meta中计算性能指标。
(3)返回nullptr:是管道终点,不返回数据给下游。
(4)分发线程立即终止:不需要推送数据。
4.2 分发线程的统一实现
4.2.1 分发线程的标准工作流程
基于vp_node.cpp,分发线程dispatch_run是所有非目标节点的发布者执行引擎:
cpp
void vp_node::dispatch_run() {
while (alive) {
// 等待生产者,确保out_queue不为空
this->out_queue_semaphore.wait();
VP_DEBUG(vp_utils::string_format("[%s] 分发前,out_queue大小==>%d", node_name.c_str(), out_queue.size()));
auto out_meta = this->out_queue.front();
// 死亡标志
if (out_meta == nullptr) {
continue;
}
// 激活离开钩子
invoke_meta_leaving_hooker(node_name, out_queue.size(), out_meta);
// 执行推送操作
this->push_meta(out_meta);
this->out_queue.pop();
VP_DEBUG(vp_utils::string_format("[%s] 分发后,out_queue大小==>%d", node_name.c_str(), out_queue.size()));
}
}分发线程的关键流程:
(1)等待输出:out_queue_semaphore.wait()- 等待处理线程完成
(2)获取数据:out_queue.front()- 从输出队列获取元数据
(3)触发离开钩子:invoke_meta_leaving_hooker()- 装饰的监控能力
(4)执行推送:push_meta()- 装饰的发布者能力
(5)清理队列:out_queue.pop()
4.2.2 发布者的核心实现
分发线程通过调用push_meta方法实现数据发布,该方法遍历订阅者列表并调用每个订阅者的meta_flow方法:
cpp
void vp_meta_publisher::push_meta(std::shared_ptr<vp_objects::vp_meta> meta) {
std::lock_guard<std::mutex> guard(subscribers_lock);
// 遍历所有订阅者(通过add_subscriber注册的)
for (auto& subscriber: subscribers) {
// 通过订阅者的装饰接口推送
subscriber->meta_flow(meta);
}
}发布订阅的核心:
(1)一对一或多对一的订阅关系。
(2)线程安全的订阅者管理。
(3)遍历订阅者列表,调用每个订阅者的meta_flow方法。
(4)线程安全保护。
4.2.3 目标节点的特殊处理
基于vp_des_node.cpp,目标节点的分发线程立即终止:
cpp
// 在所有目标节点中,分发线程立即终止
void vp_des_node::dispatch_run() {
// dispatch thread terminates immediately in all des nodes
}设计原因:目标节点是管道的终点,不需要将数据分发给下游节点。
4.4 订阅者的数据接收
从vp_node.cpp中,meta_flow方法的实现展示了订阅者如何接收数据:
cpp
void vp_node::meta_flow(std::shared_ptr<vp_objects::vp_meta> meta) {
if (meta == nullptr) {
return;
}
std::lock_guard<std::mutex> guard(this->in_queue_lock);
VP_DEBUG(vp_utils::string_format("[%s] meta_flow前,in_queue大小==>%d", node_name.c_str(), in_queue.size()));
this->in_queue.push(meta);
// 激活到达钩子(装饰的监控能力)
invoke_meta_arriving_hooker(node_name, in_queue.size(), meta);
// 通知in_queue的消费者
this->in_queue_semaphore.signal();
VP_DEBUG(vp_utils::string_format("[%s] meta_flow后,in_queue大小==>%d", node_name.c_str(), in_queue.size()));
}订阅者接收流程:
(1)放入队列:in_queue.push(meta)- 将接收的数据放入输入队列。
(2)触发到达钩子:invoke_meta_arriving_hooker()- 装饰的监控能力。
(3)通知处理线程:in_queue_semaphore.signal()- 唤醒等待的处理线程。
4.5 完整的流转链条
结合装饰器模式和线程模型,完整的流转链条如下:
cpp
装饰器提供能力接口 → 线程作为执行引擎 → 数据流转
├─ 订阅者能力(vp_meta_subscriber)
│ └─ 处理线程(handle_thread)执行
│ ├─ 通过meta_flow接收数据
│ ├─ 放入输入队列
│ ├─ 调用handle_frame_meta处理
│ └─ 放入输出队列
│
├─ 发布者能力(vp_meta_publisher)
│ └─ 分发线程(dispatch_thread)执行
│ ├─ 从输出队列取出数据
│ ├─ 调用push_meta推送
│ └─ 遍历订阅者列表
│
└─ 监控能力(vp_meta_hookable)
└─ 四个钩子在关键位置触发
├─ 到达钩子:meta_flow中
├─ 处理钩子:handle_run中
├─ 完成钩子:handle_run中
└─ 离开钩子:dispatch_run中5 生产者-消费者模式与线程安全
前面我们提到节点的双重身份:发布者=生产者,订阅者=消费者。在节点内部,这种双重身份通过生产者-消费者模式实现线程间的数据传递。
节点内部的生产者-消费者链条:
cpp
上游节点(生产者) → meta_flow() → 本节点in_queue → 处理线程(消费者)
↓
本节点out_queue ← 处理结果(生产者) ← handle_frame_meta()
↓
分发线程(消费者) → out_queue → push_meta() → 下游节点(订阅者)双重角色的同步协调:
当节点作为消费者时:等待上游节点的push_meta()调用。
当节点作为生产者时:通过out_queue_semaphore.signal()通知分发线程。
这种设计确保了数据在节点间的平滑流转。
5.1 生产者-消费者模式
从vp_node.h可以看到队列和信号量的定义:
cpp
// 缓存从先前节点接收的输入元数据
std::queue<std::shared_ptr<vp_objects::vp_meta>> in_queue;
// 缓存输出元数据到下一个节点
std::queue<std::shared_ptr<vp_objects::vp_meta>> out_queue;
// 用于in_queue的同步
vp_utils::vp_semaphore in_queue_semaphore;
// 用于out_queue的同步
vp_utils::vp_semaphore out_queue_semaphore;生产者-消费者模型:
上游节点是生产者:通过meta_flow向in_queue生产数据。
本节点处理线程是消费者:从in_queue消费数据。
本节点处理线程是生产者:向out_queue生产数据。
本节点分发线程是消费者:从out_queue消费数据。
下游节点是消费者:接收通过push_meta推送的数据。
5.2 线程安全的队列管理
从vp_node.cpp可以看到队列操作的线程安全设计:
cpp
// meta_flow中的入队操作
void vp_node::meta_flow(std::shared_ptr<vp_objects::vp_meta> meta) {
std::lock_guard<std::mutex> guard(this->in_queue_lock);
this->in_queue.push(meta);
// ...
}
// handle_run中的出队操作
void vp_node::handle_run() {
// 在while循环内部,但没有额外的锁保护pop操作
// 因为注释说明:"there is only one thread poping data from the in_queue, we don't use lock here when poping."
auto in_meta = this->in_queue.front();
this->in_queue.pop();
// ...
}线程安全策略:
入队时加锁:多个上游节点可能同时调用meta_flow。
出队时不加锁:只有处理线程从in_queue弹出数据。
类似地:只有分发线程从out_queue弹出数据。
5.3 信号量同步机制
信号量的作用:
in_queue_semaphore:控制处理线程的等待/唤醒。
out_queue_semaphore:控制分发线程的等待/唤醒。
同步流程:
cpp
// 生产者(上游节点)激活信号量
void vp_node::meta_flow(...) {
this->in_queue.push(meta);
this->in_queue_semaphore.signal(); // 通知消费者
}
// 消费者(处理线程)等待信号量
void vp_node::handle_run() {
this->in_queue_semaphore.wait(); // 等待生产者
// ... 处理数据
this->out_queue_semaphore.signal(); // 通知下一个消费者
}5.4 背压处理机制
背压(Backpressure)是流处理系统中的一种流量控制机制。当生产者(上游)生产数据的速度 > 消费者(下游)处理数据的速度时,系统需要处理这种速度不匹配的问题,避免内存溢出(队列无限增长)、系统崩溃和数据丢失。
很显然,videpipe没有背压处理机制。
5.5 线程安全的订阅者管理
从之前的分析可知,发布者的线程安全设计:
cpp
class vp_meta_publisher {
protected:
std::vector<std::shared_ptr<vp_meta_subscriber>> subscribers;
std::mutex subscribers_lock; // 保护订阅者列表
void add_subscriber(...) {
std::lock_guard<std::mutex> guard(subscribers_lock);
subscribers.push_back(...);
}
void push_meta(...) {
std::lock_guard<std::mutex> guard(subscribers_lock);
for (auto& sub: subscribers) {
sub->meta_flow(...);
}
}
};线程安全保证:
添加订阅者和遍历订阅者使用同一把锁。
避免在遍历过程中订阅者列表被修改。
确保发布数据时订阅者列表的一致性和完整性。
6 完整的数据流转时序
6.1 从attach_to到数据流的完整过程
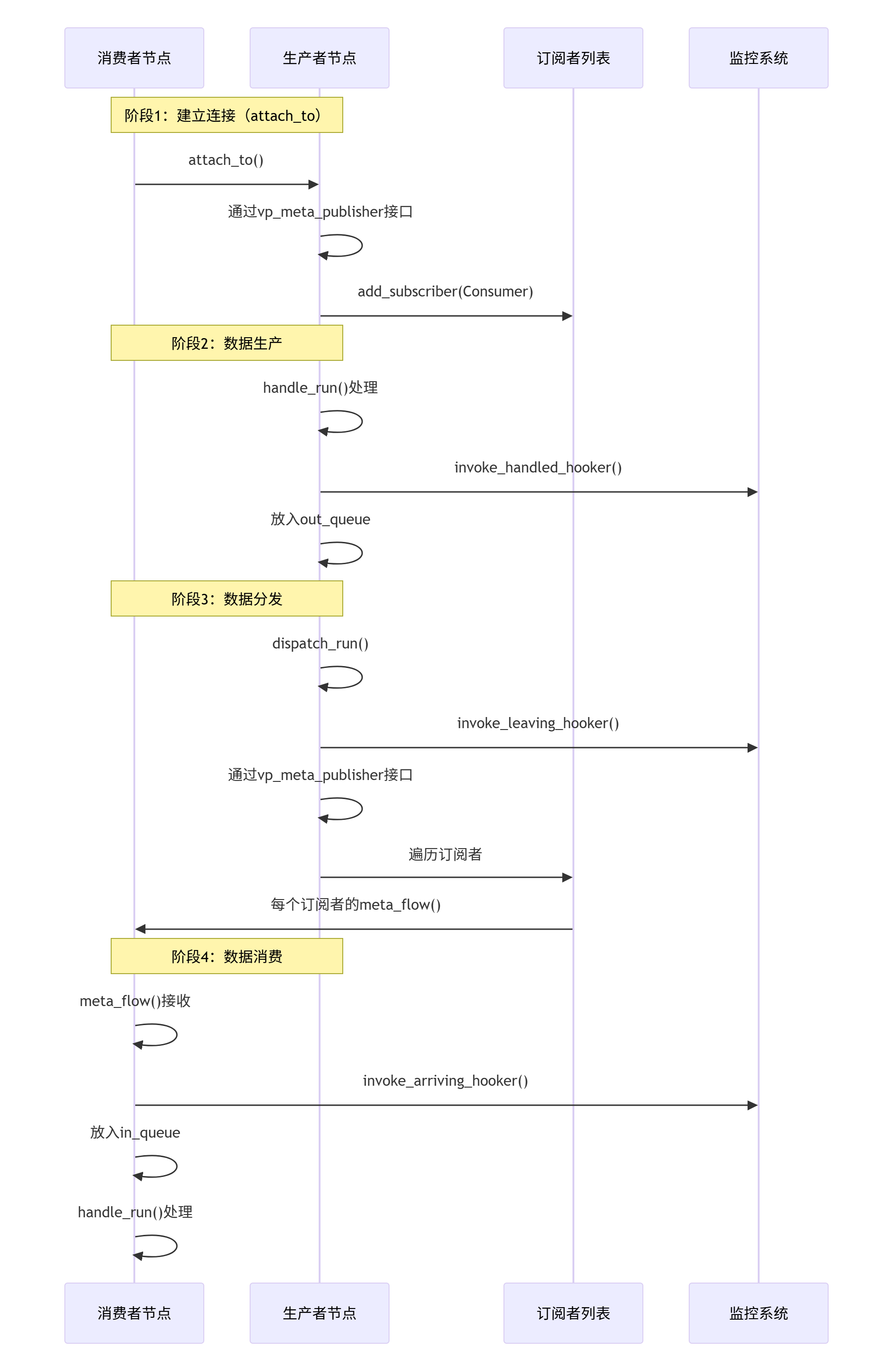
6.2 线程模型的完整视图
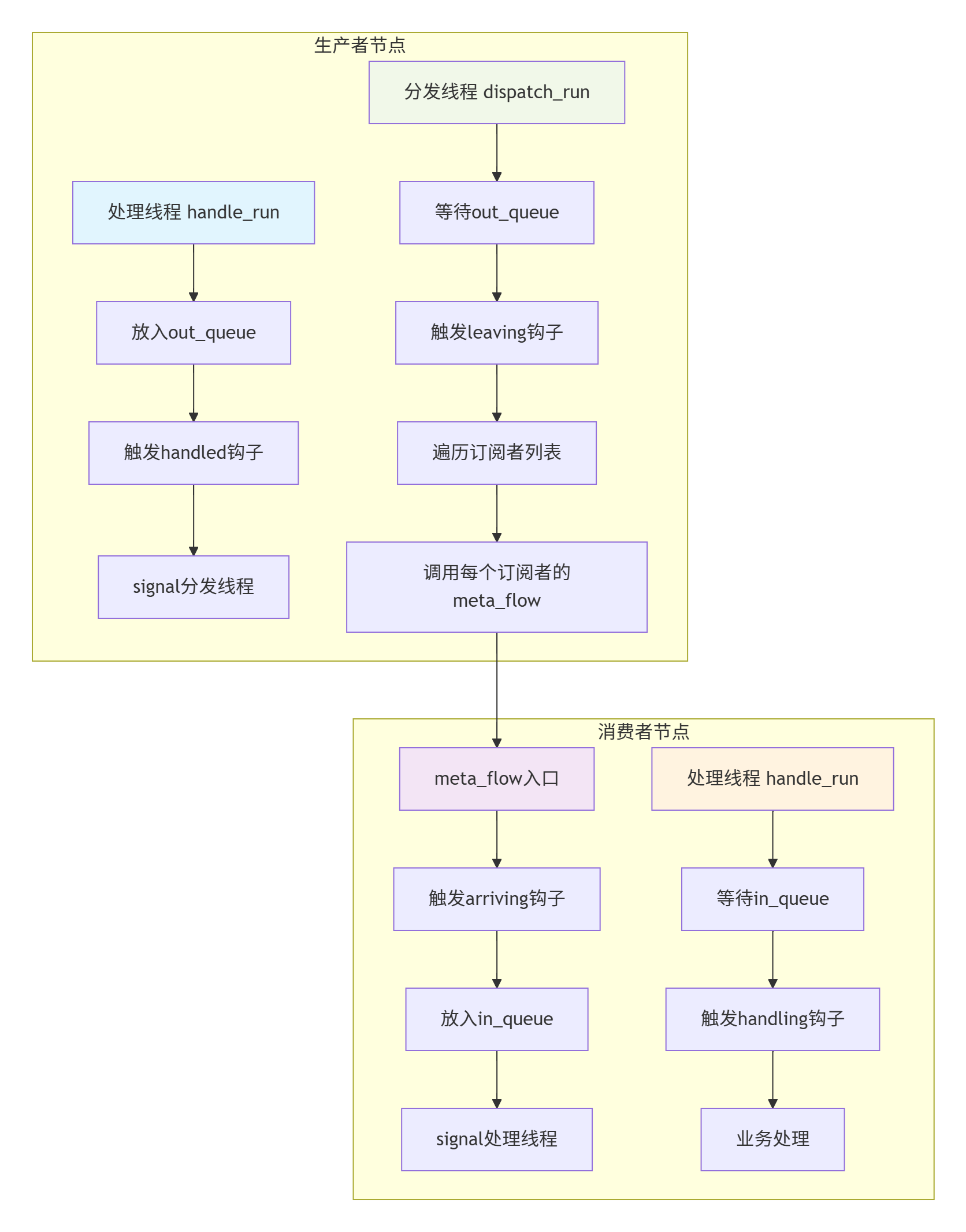
6.3 数据流转的关键路径
端到端数据流:
cpp
file_src_0 (生产者)
├─ 读取帧 → handle_run处理 → 放入out_queue
├─ dispatch_run分发 → push_meta推送
└─ 遍历订阅者 → 调用meta_flow
yunet_face_detector_0 (消费者)
├─ meta_flow接收 → 放入in_queue
├─ handle_run处理 → 放入out_queue
├─ dispatch_run分发 → push_meta推送
└─ 遍历订阅者 → 调用meta_flow
sface_face_encoder_0 (消费者)
├─ meta_flow接收 → 放入in_queue
├─ handle_run处理 → 放入out_queue
└─ ... 继续传递7 设计模式协同全景
7.1 完整的装饰器层次
通过两篇文章的分析,我们现在可以看到VideoPipe完整的装饰器层次:
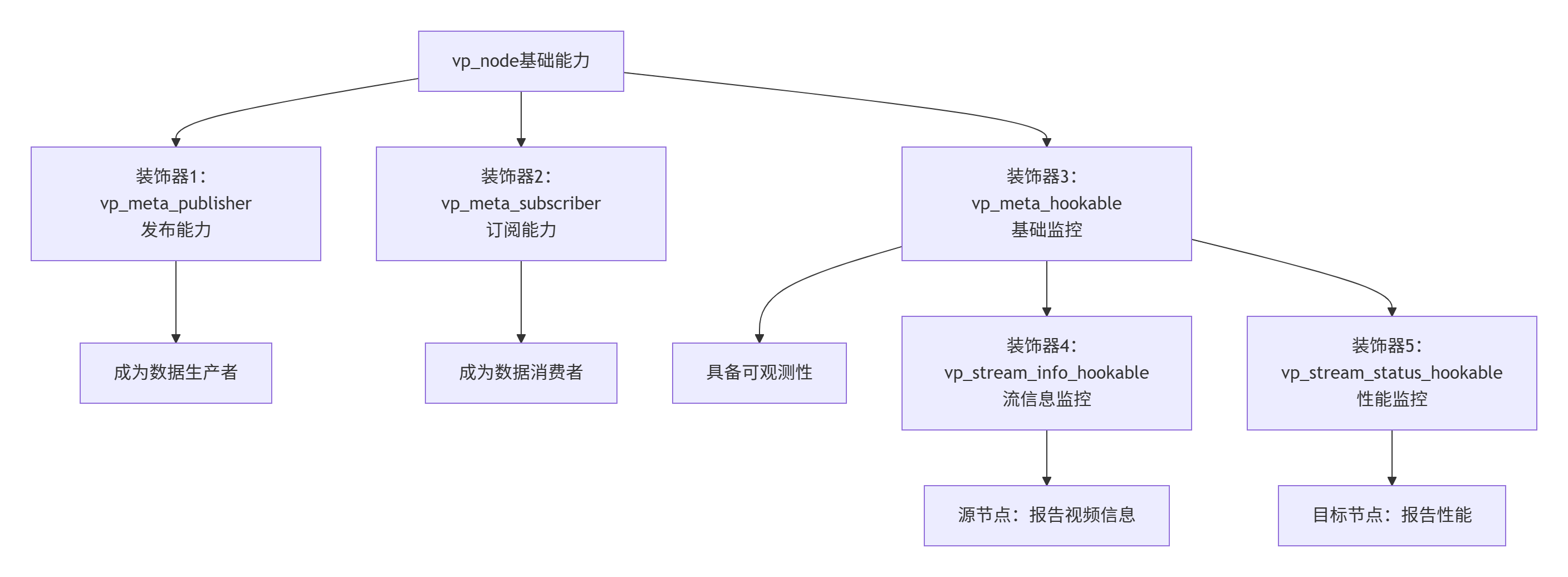
7.2 与上一篇的装饰器模式对比

上一篇重点分析了监控装饰器,本篇重点分析数据流转装饰器,但它们都通过多重继承装饰在同一个vp_node上。
7.3 五种设计模式的协同
设计模式的完整协同视图:
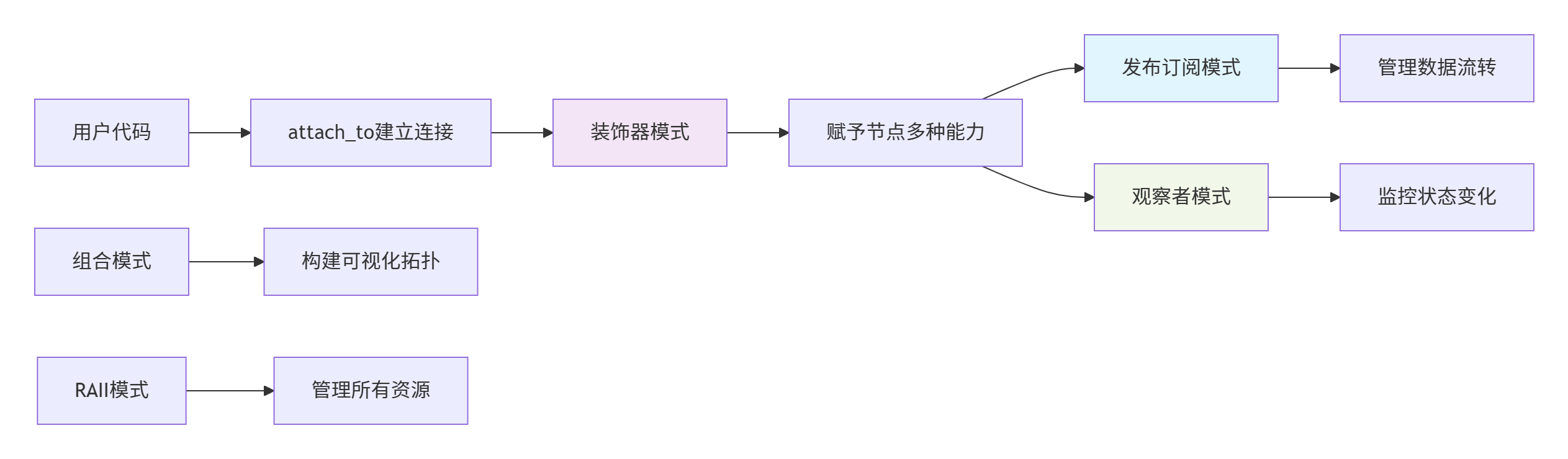
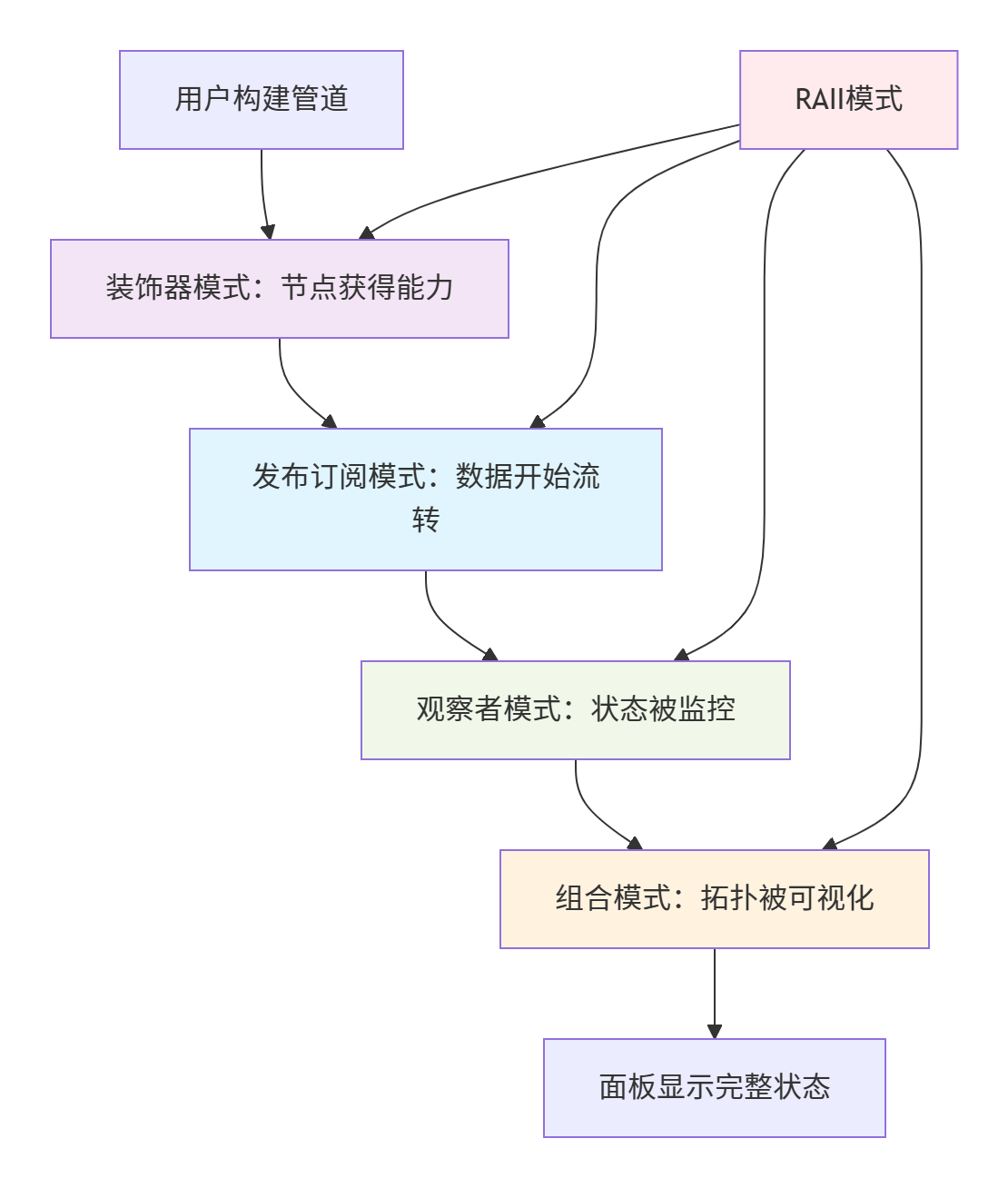
VideoPipe通过五种设计模式的精妙协同,构建了完整的流处理系统:
(1)装饰器模式:为节点动态添加能力。
(2)发布订阅模式:管理节点间数据流转。
(3)观察者模式:实现状态监控和报告。
(4)组合模式:构建可视化拓扑结构。
(5)RAII模式:确保资源安全管理。
7.4 设计模式如何支持节点的双重身份
五种设计模式协同工作,完美支持了节点的双重身份:
7.4.1 装饰器模式:为节点动态添加发布者和订阅者能力
中间节点:获得两种能力接口
源节点:主要获得发布者能力
目标节点:主要获得订阅者能力
7.4.2 发布订阅模式:管理节点间的数据流转
发布者推送数据给所有订阅者
支持一对多的通信模式
松耦合的节点连接
7.4.3 线程模型:执行装饰器接口能力
处理线程执行订阅者逻辑
分发线程执行发布者逻辑
不同节点类型有不同线程行为
7.4.4 生产者-消费者模式:节点内部的数据缓冲
输入队列:上游生产者,本节点消费者
输出队列:本节点生产者,下游消费者
信号量控制生产消费速度
7.4.5 观察者模式:监控节点状态变化
监控数据到达、处理、完成、离开
实时反馈节点的双重角色工作状态
7.4.6 模式协同支持的双重身份:
装饰器模式定义"能做什么"(发布/订阅能力)。
发布订阅模式定义"如何交互"(节点间通信)。
线程模型定义"如何执行"(能力执行引擎)。
生产者-消费者模式定义"如何缓冲"(内部数据流)。
观察者模式定义"如何监控"(状态可观测性)。
7.5 模式协同的工作流