痛点:大模型前端系统验证有哪些难题
让大模型(Agent)做前端系统验证,听起来很自然------用自然语言告诉它"帮我测一下这个页面",它自己去操作浏览器、检查元素、确认接口。但实际落地时,有几个反复出现的难题:
问题一:一次性自动化,经验不沉淀
大多数 SKILL 是 Playwright 操作的包装------打开页面、点几个按钮、截张图。这些操作能跑通一次,但下次换个页面、换个环境,SKILL 就失效了。Agent 每次跑通一个复杂页面后,过程中踩的坑、试出来的规避方案、查到的 URL 映射,执行完就丢了。Agent 没有记忆,每次都是"从零开始"。
问题二:环境入口靠猜
端口号写死在提示词里、host 假设是本机、入口应用选错------这些在本地开发时没问题,但一旦切换到远程开发机、CloudIDE 或者多人共用一台机器,SKILL 就找不到正确的页面。
问题三:验证停留在表面
页面能打开、HTTP 200、元素存在------这些都是"看起来正常"的证据,但不代表业务成功。接口可能返回空数据、schema 可能不匹配、业务码可能是失败,页面只是没有崩溃而已。
问题四:每次都要重新登录
没有登录态管理机制,每次验收都要从头走一遍登录流程。账号密码可能写死在代码里、Cookie 过期后没有自动刷新机制、多环境共用同一个登录态导致串号------登录成了验收链路中最不稳定的环节。
这些问题叠加起来,大模型就很难进行端到端验证。
为了解决这些痛点,针对我的系统写了一个前端系统端到端验证 SKILL。它的核心思路是"进化"------SKILL 每执行一次,都能把新经验沉淀为可检索的知识,下一次执行时优先复用已有经验,越用越准、越用越稳。下面拆解我是怎么写的。
一、全景图:进化 SKILL 长什么样
一个可以进化的验收 SKILL 由三部分组成:
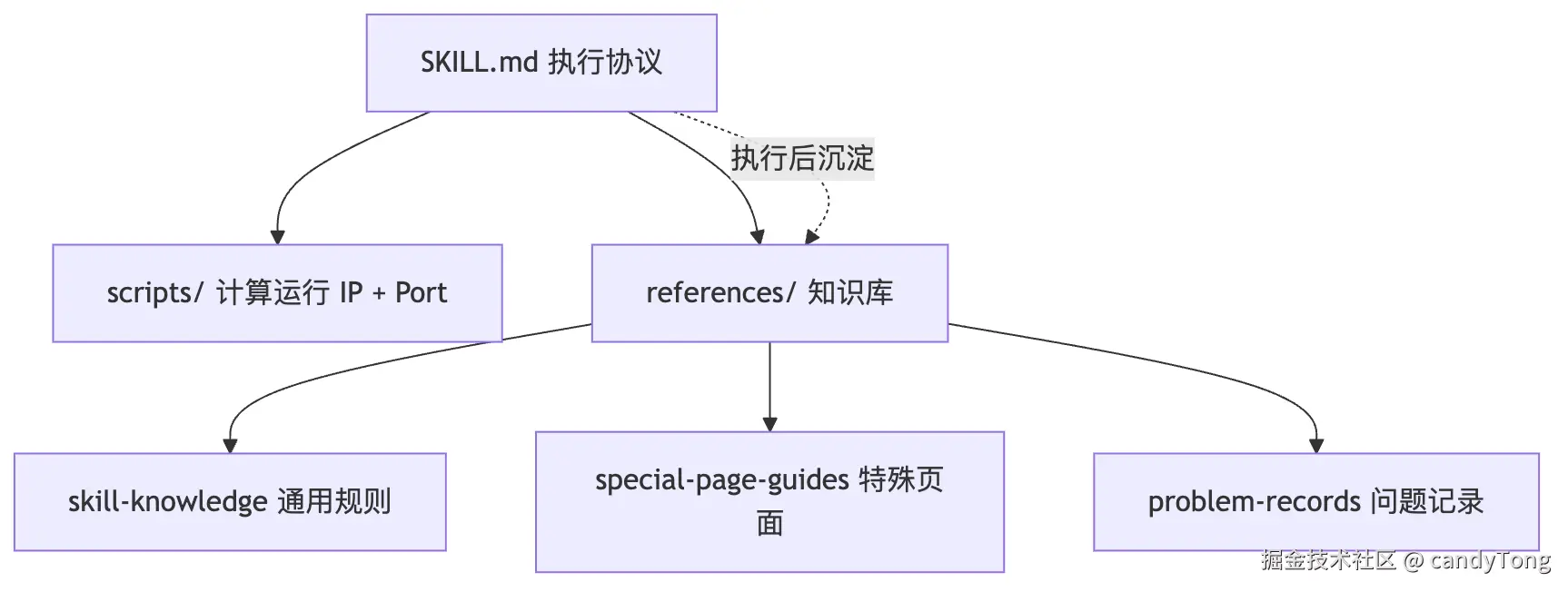
SKILL.md 是主脑,定义 6 阶段执行协议:
rust
计算运行 IP + Port -> 登录态处理 -> 计算页面 URL -> 计算泳道 -> 页面与接口验证 -> 知识沉淀scripts/ 是手脚,用脚本把环境事实(端口、host、入口应用)变成可执行查询,而不是让 Agent 猜测。
references/ 是记忆,分三层:
| 目录 | 存放内容 | 类比 |
|---|---|---|
skill-knowledge/ |
通用规则、固定操作知识 | 常识 |
special-page-guides/ |
特殊页面的专用测试方法 | 专项经验 |
problem-records/ |
稳定复现问题与规避方案 | 踩坑记录 |
进化的核心在于最后一步------知识沉淀 。Agent 每次执行完后,把新发现的问题和已验证方案写回 references/。下一次执行时,这些新沉淀的知识就成了优先检索的输入。SKILL 从"静态提示词"变成了"可学习工作流"。
下面展开每个部分的具体写法。
二、SKILL 拆解
SKILL.md 执行流程
SKILL.md 是 SKILL 的主流程定义,我把它拆成 6 个阶段:
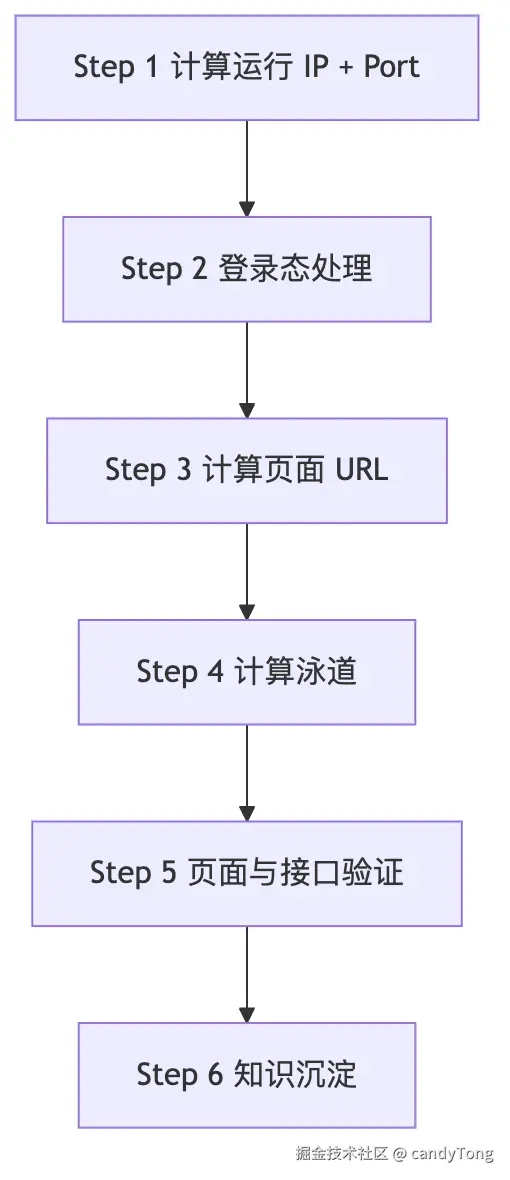
Step 1:计算运行 IP + Port------用脚本代替猜测
页面验收的第一个输入不是页面名称,而是当前可访问的根地址。page-test 不让 Agent 猜端口,而是执行脚本:
text
.agents/skills/page-test/scripts/get-base-url.sh脚本查找目标 dev server 进程,读取进程工作目录,筛选监听端口,再根据本机、SSH、CloudIDE 等场景决定使用 127.0.0.1 还是局域网 IP。这样可以避免本地开了多个 dev Server 时选错端口。
text
http://<host>:<port>/app设计原则:把"当前环境应该访问哪个地址"变成事实查询,避免本地开了多个 dev Server 时选错端口。
| 错误类型 | 表现 | SKILL 的处理方式 |
|---|---|---|
| 端口错误 | 打开了另一个 dev server | 根据进程 cwd 精确匹配目标应用 |
| host 错误 | 本机可访问,远程浏览器不可访问 | 根据环境选择 IP |
Step 2:登录态优先复用,必要时再登录
验收不应该每次都重新登录。page-test 的登录态处理分为三层:
- 复用层:加载本地保存的 Cookie,避免重复登录。
- 验证层:访问首页并检查是否存在用户态。
- 刷新层:登录成功后重新保存当前上下文 Cookie。
设计原则:登录态是一种可验证、可刷新、可持久化的运行前置条件。
Step 3:计算页面 URL------分层检索,不是全仓搜索
用户通常给出功能名称,例如"考试运营管理""任务管理"。page-test 的分层 URL 查找策略:
- 先列
references/special-page-guides/文件名,判断是否命中特殊页面。 - 未命中时,读取默认 URL 映射文档。
- 默认映射未命中时,再搜索路由配置文件或
router目录。 - 路由配置仍不够时,搜索页面目录。
- 一旦通过代码搜索确认新 URL,就回写到默认 URL 映射文档。
设计原则:先复用已沉淀知识,再做昂贵探索。URL 计算从一次性查找变成可累积的缓存。
有些页面知道 URL 还不够,还需要额外的参数才能进入有效状态。例如详情页需要记录 ID、新建页需要指定类型参数、带弹窗的页面需要拼接 query 参数。这类特殊页面不能靠代码搜索自动拼出参数,而是应该提前沉淀到 special-page-guides/ 中,明确标注需要的参数格式和示例。
Step 4:计算泳道(用于指定后端实例)------只在用户明确提供时追加
通过在 url 上拼接 cgi-env-map query 参数传递泳道信息。规则是:只有用户明确提供服务名和泳道名时,才追加参数;没有提供时不主动猜测。
设计原则:业务环境选择属于用户的决策,不是 Agent 可以凭空发明的技术细节。
Step 5:页面与接口验证------业务成功才是成功
页面验收需要区分三个层次:
| 层级 | 验证对象 | 通过标准 |
|---|---|---|
| 页面层 | DOM 是否加载、目标元素是否存在 | 使用 browser_snapshot 读取页面结构 |
| 网络层 | 请求是否发出、是否命中目标接口 | 检查 URL、method、环境头、请求体 |
| 业务层 | 响应是否真实成功 | 检查响应体、业务 Code、目标字段 |
要求页面验证使用 browser_snapshot 而不是常规截图。对 Agent 来说,DOM 快照比图片更能提供可操作证据。
关键接口验证的边界更严格。HTTP 200 只代表传输层成功,不代表业务成功。GraphQL 场景下还需要检查:
- 顶层是否存在
errors。 - 网关包装错误是否出现。
data.<Method>是否存在。- 业务字段
Code是否为成功码。 - 目标字段是否真实返回。
设计原则:页面没崩、HTTP 200、接口业务成功是三个不同结论。验收标准必须覆盖到业务层。
Step 6:知识沉淀------任务结束不是终点
要求任务结束前检查是否产生新的可复用知识。满足以下条件时需要更新 reference:
- 出现新的稳定可复现问题。
- 找到了已验证有效的规避方案。
- 该经验对后续任务有复用价值。
写入位置由知识类型决定:
| 知识类型 | 写入目录 |
|---|---|
| 通用规则、流程更新、分类规范 | skill-knowledge/ |
| 某个特殊页面独有测试方法 | special-page-guides/ |
| 稳定复现问题与规避方案 | problem-records/ |
新增 reference 时必须补全 frontmatter;如果检索方式或执行流程因此改变,还要同步更新 SKILL.md。
设计原则:Agent 每完成一次验收,都有机会把经验转化为下一次可检索的上下文资产。
SKILL 知识体系设计
SKILL 把知识库拆成三层,而不是一把塞进一个长文档:

skill-knowledge/:通用规则
保存执行协议会直接依赖的基础知识,例如验收入口应用选择、泳道信息拼接、网络响应体验证、reference 分类规范等。
special-page-guides/:特殊页面优先
特殊页面往往有专用前置条件、参数格式或验证方式。SKILL 要求先列目录文件名,再根据 frontmatter 的 title、page、tags 检索。命中后才读取具体文档。
这种方式避免了两个极端:既不会完全忽略特殊页面经验,也不会每次都加载所有特殊页面说明。
problem-records/:一问题一文档
页面交互问题不是抽象知识,而是具体症状和规避方案。每篇问题记录都包含 frontmatter,例如 component、symptom、tags。查询时先看文件名,再 grep 元数据,最后只读取必要文档。
这是一种面向 Agent 上下文窗口的知识组织方式:信息足够细,检索入口足够明确,读取成本足够低。
知识搜索策略
知识检索不是一上来就全量读取,而是分层递进:
- 先列目录 :列出
special-page-guides/或problem-records/文件名,判断是否命中目标。 - 查元数据 :未命中时,通过
grepfrontmatter 中的title、page、tags、component、symptom等字段做精确匹配。 - 读单篇文档:命中后只读取必要的单个文件,不加载整个目录。
三类知识的检索方式各有侧重:
special-page-guides/(特殊页面) :先列文件名判断是否命中目标页面,再通过title、page、tags等元数据确认,命中后按文档中的专用方法执行。未命中特殊页面时,先读取default_url_lookup.md查默认映射,最后才搜索路由配置和页面目录。problem-records/(问题记录) :遇到异常交互时先列文件名做粗筛,再通过component、symptom、tags搜索已知症状,最后读取匹配的单篇文档获取规避方案。skill-knowledge/(通用规则) :这类知识相对固定,SKILL 在执行协议中明确知道该读哪个文件,直接按需读取即可,不需要做模糊搜索。这类知识的查找,先看文件名 → 再 grep frontmatter 元数据 → 最后读单篇文档。不直接全量读取,避免上下文膨胀。
知识沉淀规范
SKILL 的进化能力依赖于一套明确的沉淀规则:
- 沉淀时机:出现新的稳定可复现问题、找到已验证有效的规避方案、遇到需要专用测试方法的特殊页面、现有分类/命名/元数据规范不足以支持后续检索。
- 写入位置 :通用规则写进
skill-knowledge/,特殊页面方法写进special-page-guides/,问题与规避方案写进problem-records/。 - 质量门槛:只在问题可复现且方案已验证有效时才做沉淀,不记录偶发噪音。
- 格式要求:新增 reference 必须补全 frontmatter,确保后续可通过元数据检索。
总结
这套 SKILL 的核心价值不在于某个单独的 Playwright 操作,而在于它把页面验收拆成了一条有状态、有边界、有知识沉淀的执行链。
它先用脚本确定入口,再复用登录态;先查特殊页面与默认 URL,再必要时搜索代码;先用 DOM 快照确认页面,再用响应体确认业务成功;最后把稳定问题沉淀回 reference。每一步都减少了 Agent 的不确定性,也让下一次验收更接近"复用已有经验"而不是"重新探索一遍"。
对 SKILL 设计者来说,关键启发是:好的验收 SKILL 不只是指挥 Agent 做事,还要把环境事实、业务边界、验证口径和经验积累写进系统。这样,SKILL 才能从一次性自动化脚本变成可持续进化的工程资产。
更多 AI 工程、Agent 和技术实践相关内容,欢迎关注公众号。
