把"会调工具"讲透成"会编排工具",看懂真正决定 Agent 上限的执行层设计
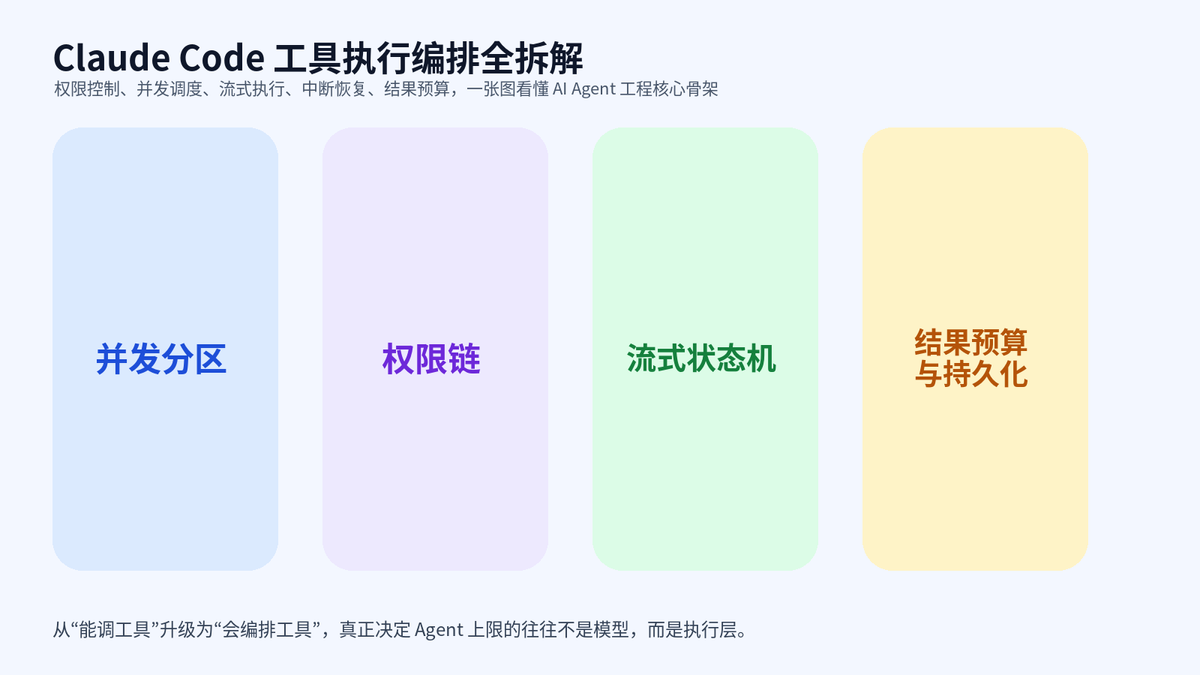
很多人一谈 AI Agent,注意力都会先落在模型本身,关心它会不会规划、会不会推理、会不会自动调用工具。可一旦真正落到工程现场,难点立刻变了味:一次回合里来了多个工具请求,哪些能并发,哪些必须串行;某个动作可能改工作目录、改文件、改会话状态,谁来兜住一致性;工具返回一大坨内容,谁来防止上下文被塞爆;用户按下中断以后,是全停、半停,还是只停一部分。
说白了,执行层就像一座总调度室。模型负责提出动作意图,真正把动作安全地跑出来、把结果干净地喂回去的,是工具执行编排。谁把这一层做扎实,谁的 Agent 才可能从"演示很好看"走到"线上真能跑"。
1、为什么工具执行编排才是 Agent 真正的硬骨头
1.1 一次回合里,工具请求从来不是孤立存在的
模型常常不会只发出一个工具请求,而是一口气抛出一串动作。最典型的情况,就是先读多个文件,再跑一次 Bash,再继续修改内容。表面看,这只是几个工具顺序排队;实际上,每一个动作都可能影响后面的上下文和环境状态。只读动作可以一起跑,写入动作却可能让并行读取看到不同版本的世界。
1.2 执行层必须同时回答四个问题
第一,哪些动作可以并发,哪些必须独占。第二,危险动作到底谁说了算,是工具自己决定,还是规则决定,还是用户决定。第三,结果太大怎么办,不能每次都把几十万字符直接塞给模型。第四,用户中断以后,系统能否做到有边界地停,而不是一刀切把整轮会话打爆。
1.3 这层设计决定的是系统上限,而不是小修小补
没有执行编排,工具系统照样能工作,但只能停留在"能跑"的阶段。真正的产品级 Agent 需要的是"稳定地跑、可重复地跑、出了问题还能收得住"。这也是为什么很多团队模型并不差,却依旧把体验做得忽快忽慢、忽好忽坏。
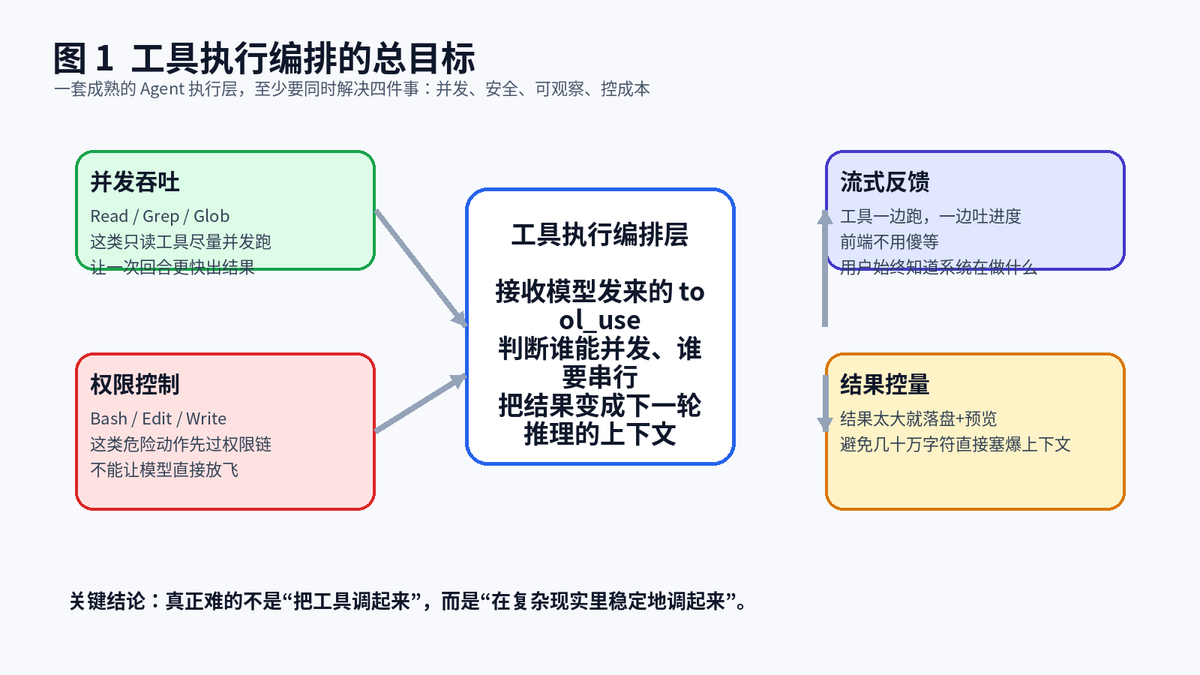
执行层真正关心的四件事:安全并发、权限控制、流式反馈、结果控量。
2、第一步不是执行,而是先把工具请求分区
2.1 分区的本质,是把一串动作切成不同批次
最关键的处理动作,可以概括成一句话:连续的安全调用尽量合并,遇到不安全调用立刻断开。比如连续几个 Read、Grep、Glob,可以组成一个并发批次;一旦出现 Bash、Edit、Write 这种可能改状态的工具,就要单独拿出来独占执行。
2.2 为什么这里采用的是"贪心合并"
因为它足够简单,也足够稳。系统并不追求全局最优调度,而是只做一个非常务实的判断:前后相邻的安全动作,能并就并;只要看到一个不确定因素,就切批。这样既保住相对顺序,又吃到大部分并发收益。工程里很多好设计,恰恰不是数学意义上的最优,而是风险、复杂度、收益三者最平衡。
2.3 真正聪明的地方,在于"拿不准就当不安全"
如果输入没有通过 schema 验证,或者并发安全判断本身抛了异常,系统不是硬着头皮继续猜,而是直接退回串行。这就是典型的失败即关闭思路。宁可少一点并发,也不能把文件状态、目录状态、上下文状态搅乱。
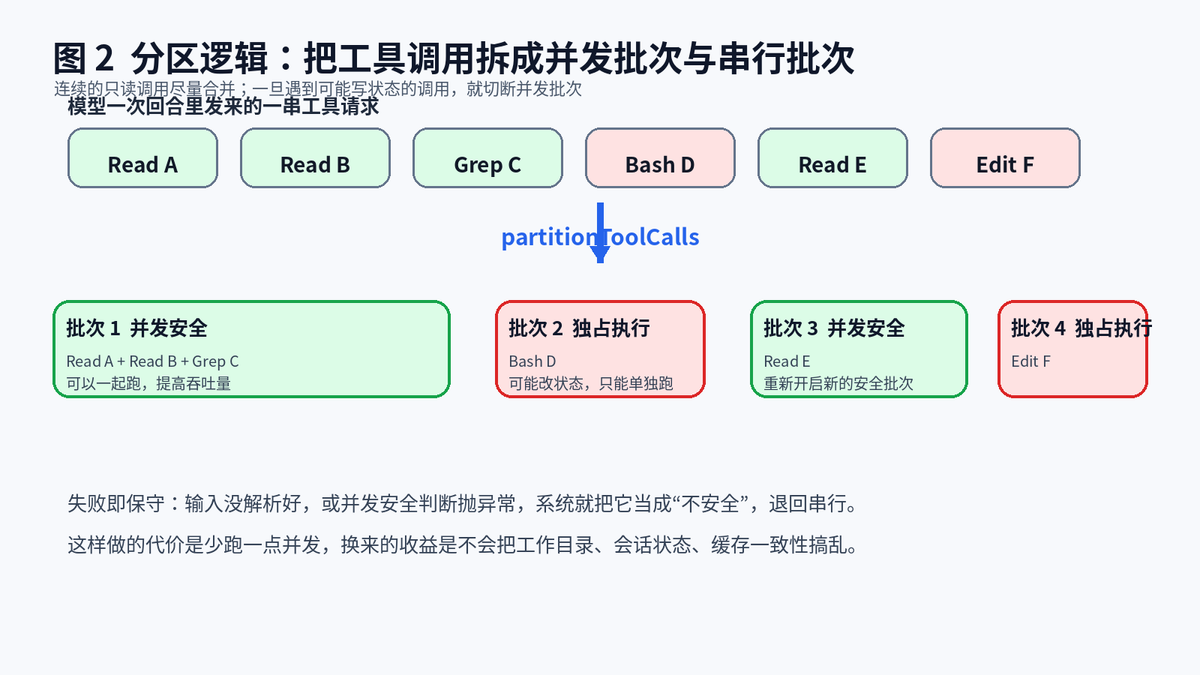
工具分区的核心不是复杂调度,而是连续安全调用的贪心合并。
3、runTools 背后的调度思路:并发追求效率,串行追求顺序语义
3.1 并发批次不是无脑一起跑
安全批次里的多个工具可以同时执行,但它们对上下文的修改不能立刻写回。否则就会出现竞态:Read A 还没结束,Read B 已经把工具列表、上下文提示、运行状态改掉了,后面谁看到的是旧状态,谁看到的是新状态,马上就乱。
3.2 所以并发执行时要"延迟提交上下文修改"
更稳的办法是:并发期间先把每个工具产生的上下文修改器收集起来,等整批都结束以后,再按原始顺序一个个应用。这样既拿到了并行执行的速度,又保住了顺序语义。你可以把它理解成财务里的"先记流水,后统一入账"。
3.3 串行批次的目标完全不同
串行路径里,重点不是效率,而是顺序可见性。一个工具执行完,马上把新的上下文提交进去,下一个工具看到的就是更新后的状态。写入类动作之所以必须串行,不是因为它们慢,而是因为它们会改变世界。
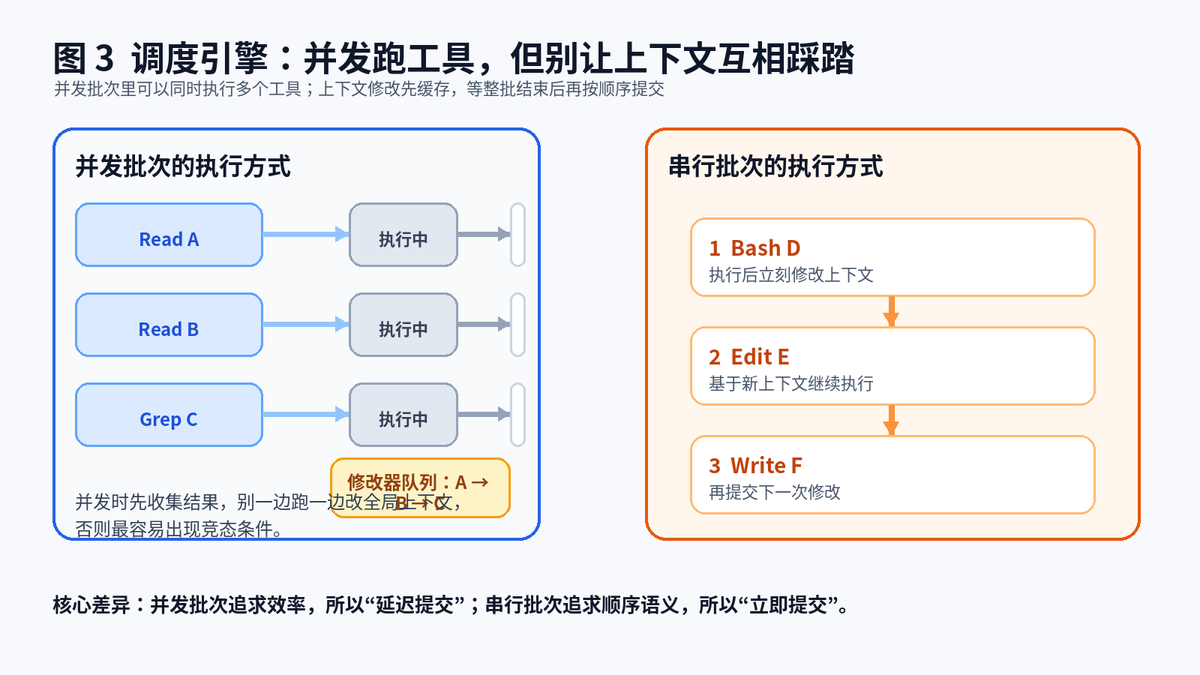
并发批次延迟提交上下文修改,串行批次立即提交上下文修改。
4、单工具生命周期为什么要拆成九段
4.1 不是"找到工具就执行",而是先过一整条检查链
单个工具调用看起来很简单:模型给出名字和参数,系统去执行就行。但真正成熟的执行链会在前面叠很多层:先找工具,再校验参数结构,再做业务语义验证,再跑前置 Hook,再走权限链,通过之后才真正执行。
4.2 Schema 验证和语义验证不是一回事
Schema 验证解决的是"类型对不对"。比如本来应该给数组,结果模型给了字符串,这一层就要拦住。语义验证解决的是"业务上能不能这样干"。比如路径是否存在、目标文件是否允许修改、命令参数有没有越界。前者是格式问题,后者是业务问题,两层都不能少。
4.3 生命周期拆得足够细,系统才有地方插安全钩子
很多团队做工具系统失败,不是因为模型太笨,而是因为整个执行链只有一个黑盒 call。黑盒一旦出事,前面拦不住,后面接不住。阶段拆得足够细以后,每个节点都能插监控、插规则、插 Hook、插审计,这才是真正的工程化。
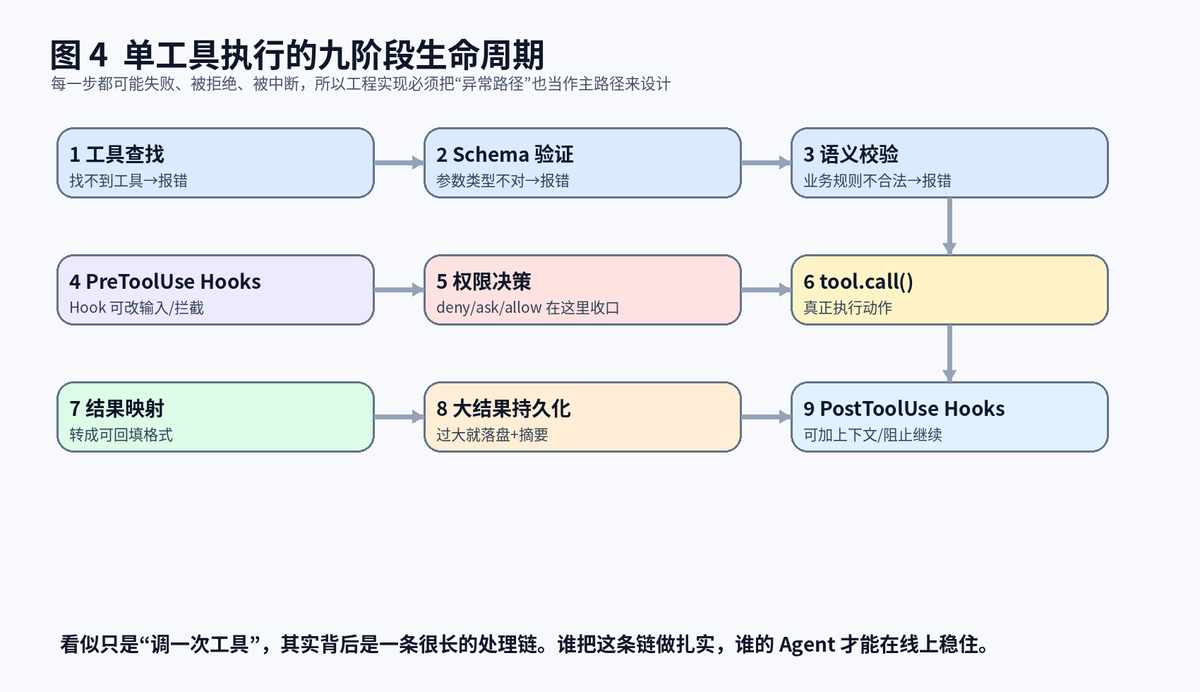
单工具调用从查找到后置 Hook,背后是一条九阶段执行链。
5、权限系统为什么不是一个 if 判断,而是一条决策链
5.1 真正危险的不是"没有权限系统",而是"只有一层权限系统"
如果系统只在工具内部写一个 checkPermissions,看上去也能工作,但只要这一层漏判,危险动作就会直接落地。更稳的做法,是把权限拆成多层:前置 Hook 可以先给出 allow、deny、ask;规则系统再检查 deny/ask;工具自己还有内部校验;分类器能帮忙自动判断;最后实在拿不准,再交给用户确认。
5.2 最重要的原则:低层放行,不能覆盖高层底线
这套设计里最值得学的一点就是,Hook 的 allow 不是通行证。只要更高优先级的规则里写了 deny 或 ask,前面的 allow 也不能硬闯过去。换句话说,系统宁可多问一次,也不能把用户明确配置的安全边界给绕过去。
5.3 这其实就是纵深防御
安全从来不应该押宝在某一层永远正确。模型可能输错参数,Hook 可能误判,分类器可能置信度不足,用户也可能点错确认。多层判断不是浪费,而是在给系统留退路。工程里最危险的,不是决策链太长,而是只有一个决定生死的开关。
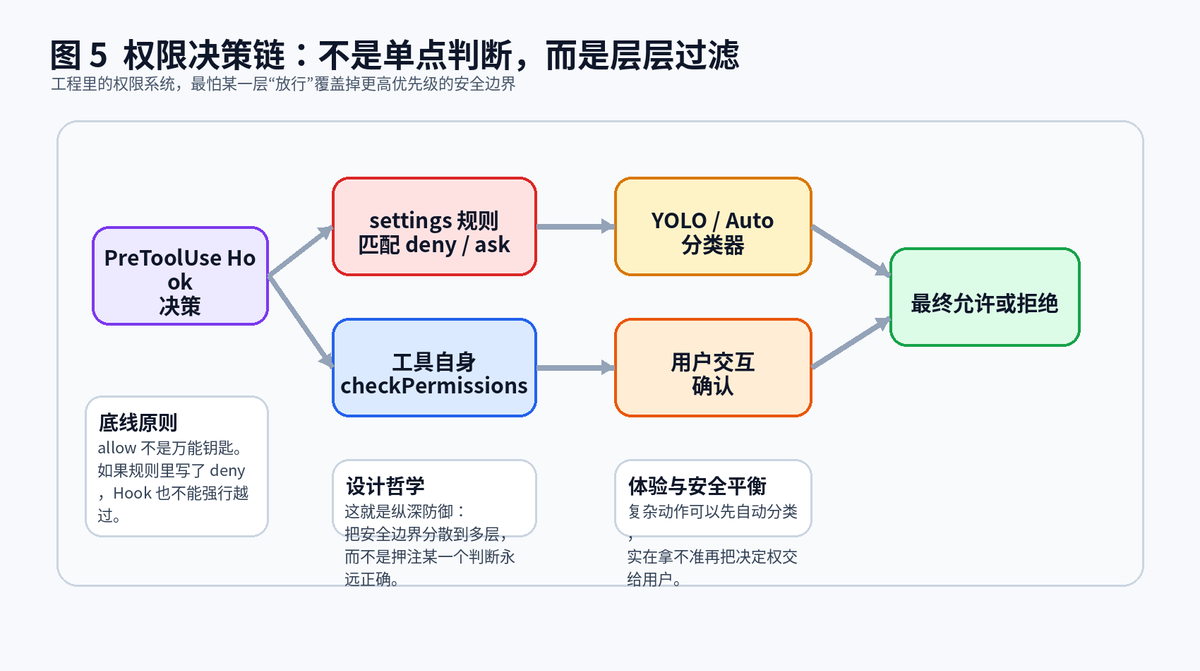
权限系统不是一个开关,而是一条不能越权的多层决策链。
6、流式执行器真正解决了什么问题
6.1 批量模式和流式模式,不是同一件事
批量模式的前提是:模型已经把所有工具请求都吐完了,系统再统一分区、统一执行。可流式模式不同,工具块是一个接一个解析出来的。这个时候,如果还坚持"等所有块都到齐再说",前端就会明显感觉到迟滞。
6.2 更高级的做法,是工具一到就排队,一能跑就启动
流式执行器会给每个工具维护状态:queued、executing、completed、yielded。新工具一来,先进入队列;只要当前并发条件满足,它就可以立即启动,不必等整轮响应结束。这种设计最大的价值,就是把等待时间切碎,让系统看上去始终在向前推进。
6.3 但流式不等于乱序
最终结果仍然要尽量维持顺序语义,否则用户会看得一头雾水。比较巧妙的做法是:最终结果按规则交付,进度消息则允许即时传递。于是用户可以先看到"某工具正在读取""某命令正在运行",而真正的结果块依旧按约定回到消息历史。
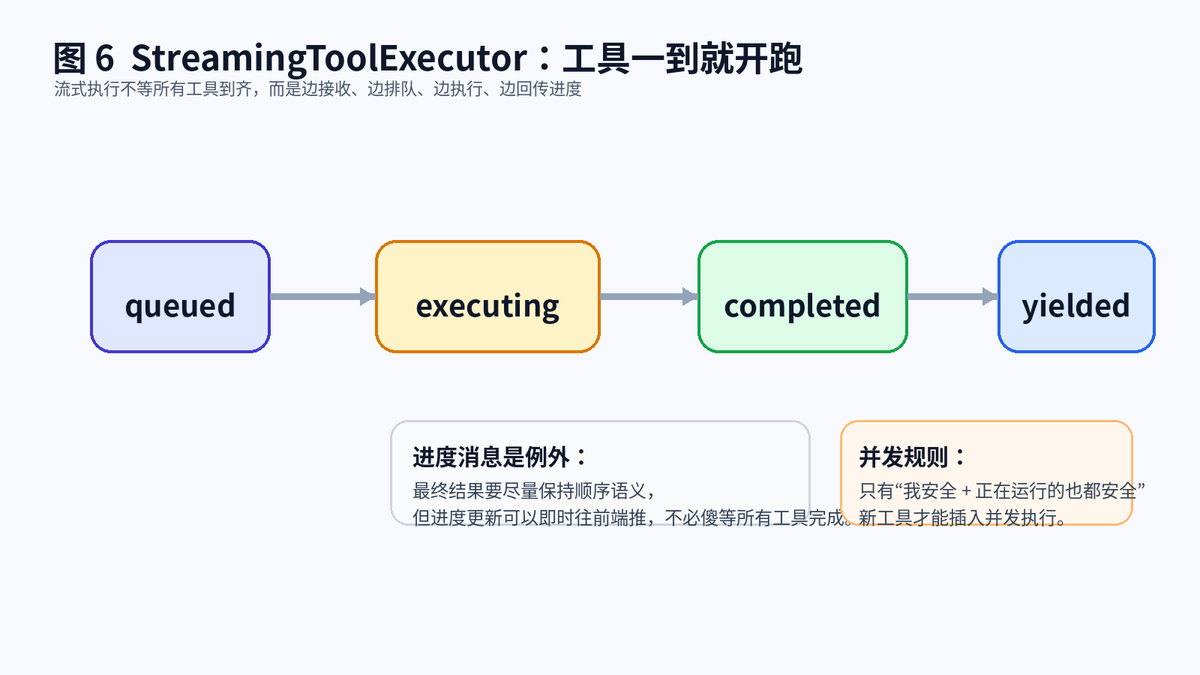
流式执行器让工具到达即排队、能执行即启动、进度先反馈。
7、为什么 Bash 失败以后,会连带取消同级 Bash
7.1 这不是粗暴,而是对真实场景的妥协
Shell 命令之间常常带着隐式依赖。前一步 mkdir 没成功,后面的 cp、tar、deploy 大概率也会失败。如果系统还傻乎乎让后续命令全部跑完,只会制造更多噪音和更多无效报错。
7.2 所以这里采用的是"选择性级联"
只有相关性很强的一组 Bash 同级任务,会发生连带取消。Read、Grep、WebFetch 这种独立性更强的工具,不应该因为某个 Bash 失败就跟着一起死掉。这里的思路非常值得借鉴:错误传播不能太弱,也不能太强,最好的做法是按相关性传播。
7.3 中断控制也遵循同样的边界感
有的工具声明自己是 cancel 型,用户中断以后就立即停;有的工具是 block 型,即便用户发了取消信号,也要跑到自然结束。执行层持续追踪当前有哪些工具可中断,这样前端才知道什么时候适合提示"按 ESC 取消"。
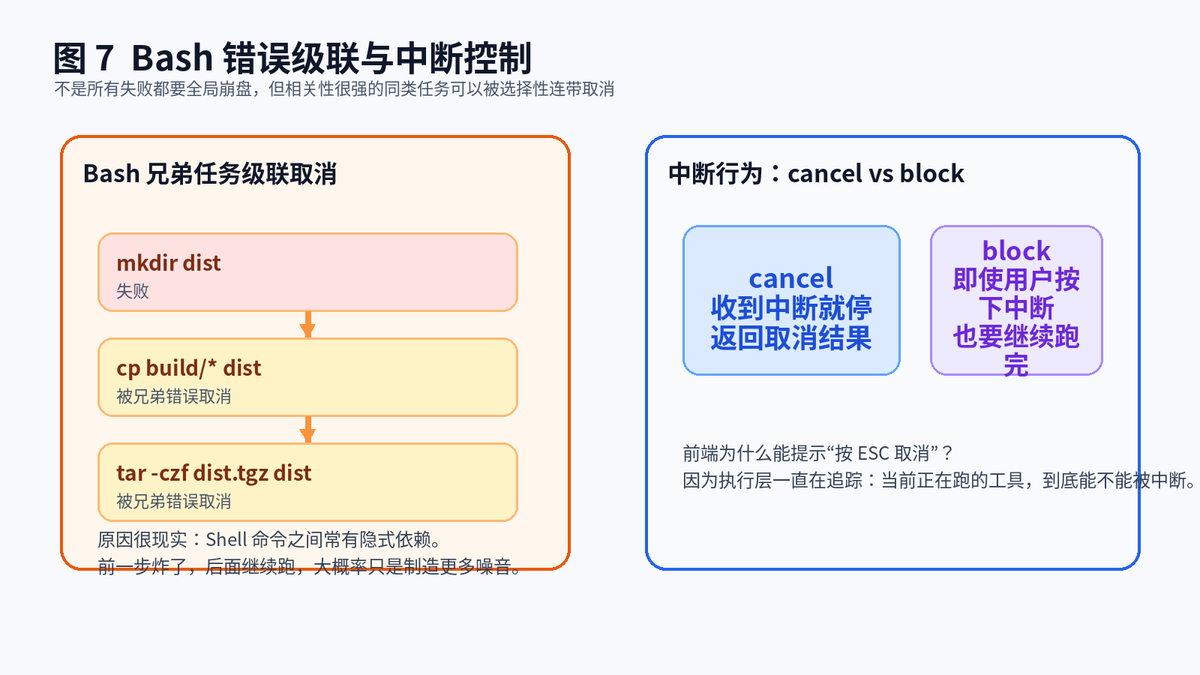
相关性强的 Bash 任务可选择性级联取消,中断行为也要分类型处理。
8、结果管理为什么是很多 Agent 的隐形短板
8.1 大结果不是财富,很多时候反而是负担
一次 Bash 的 cat、一次日志输出、一次大文件读取,很容易就冲出几十万字符。把这类结果完整塞给模型,看起来像"信息给足了",实际上经常是把上下文窗口撑爆,让模型注意力被垃圾细节拖走。
8.2 更成熟的做法,是两级预算控制
第一层看单工具大小,每个工具都有自己的最大结果边界;第二层看一整条消息的聚合预算,防止十个工具各自不算大,但合在一起仍然把上下文吞光。真正超了预算,就把完整结果写入会话目录,再回填一个摘要、预览和路径。
8.3 这里还有一个很高级的细节:替换内容要稳定
如果同一条工具结果今天被截断、下一轮又恢复完整、再下一轮又被截断,提示缓存就会来回抖动。为了让缓存前缀尽量稳定,一旦某个结果在某次评估里被替换,后续通常都沿用同样的替换版本。这看上去有点绕,但对性能收益极大。
8.4 空结果也不能真的留空
有些模型会把空工具结果误判成回合边界,甚至提前结束响应。所以系统会主动给空结果塞一段占位文本,比如"命令执行完成,但没有输出"。别小看这个小动作,很多线上奇怪问题,恰恰就死在这种极小的边角料上。
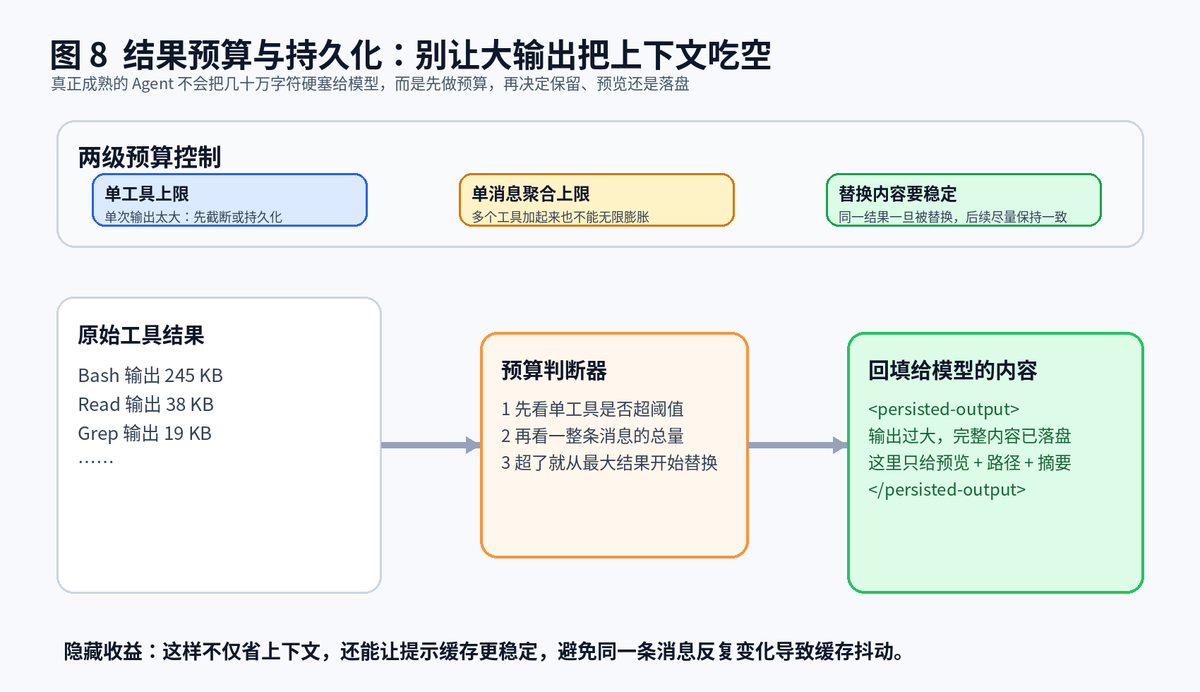
结果预算与持久化,让大输出不再直接吞掉上下文窗口。
9、Stop Hooks 把"停不停下一轮推理"这件事单独拿出来处理
9.1 工具执行成功,不代表下一轮一定该继续
有时候前置 Hook 或后置 Hook 会发现:动作虽然执行了,但结果里已经暴露出危险信号,或者当前轮次应该先停下来让用户看一眼,而不是立刻把结果再塞回模型继续推理。
9.2 所以执行层把"是否继续下一轮"独立成一个开关
这一步非常像生产线上的质检闸门。货已经做出来了,但能不能立刻放进下一道工序,还要再看一次。这样设计以后,工具执行和后续推理就不再绑死在一起,Agent 系统也就有了更细粒度的刹车能力。
9.3 执行层成熟以后,工具系统会自然长出更多角色
当编排层足够完善,工具就不一定全是"执行型工具"。系统甚至可以加入建议型、对齐型、辅助决策型的工具,让 Agent 不只是直接做事,而是先建议、再确认、再执行。这会让整个系统更像一个有边界感的助手,而不是一台一路狂奔的自动机。

这套执行层最终沉淀成 5 条可复用的工程模式。
10、普通团队能直接抄走的 7 条落地建议
10.1 并发安全一定要基于输入判断,不要只基于工具名字判断
同样叫 Bash,有的命令只读,有的命令会改环境。按工具名一刀切,结果要么太保守,要么太危险。
10.2 并发默认值一定要保守
只要解析失败、分类失败、信号不明确,就先退回串行。线上系统最怕"误并发",不怕"少并发"。
10.3 危险动作一定要做多层权限链
不要让某个 Hook、某个分类器、某段提示词单独掌控生杀大权。安全边界要分散部署。
10.4 进度消息和最终结果要区别对待
进度可以快,结果要稳。让用户先看到系统在工作,再看到有序结果,体验会明显提升。
10.5 大结果一定要做预算和持久化
别把模型当日志平台。能摘要就摘要,能预览就预览,完整内容该落盘就落盘。
10.6 错误传播要做相关性分级
相关任务可以一起停,不相关任务不要陪葬。这样既不放任错误扩散,也不轻易把整轮会话干死。
10.7 让替换规则尽量确定,给缓存留活路
上下文越稳定,缓存越容易命中,系统越省钱,也越快。很多性能问题,根源不是模型推理本身,而是上下文内容一直在抖。
总结:优秀的 Agent,不只是会想,还要会收拾现场
把这一整套设计压缩成一句通俗的话,就是:模型负责提要求,执行层负责兜后果。模型说"去读文件、去跑命令、去改内容",执行层不能只是机械照做,而要先想清楚能不能并发、需不需要问权限、结果会不会太大、失败以后该不该级联取消、用户中断后应不应该马上停。
也正因为如此,真正拉开 Agent 差距的,往往不是提示词多花哨,而是执行层是否有边界感。边界感体现在:不确定就保守;危险动作不越权;大结果不硬塞;错误传播有范围;中断控制有规则;缓存内容尽量稳定。谁把这些基础骨架搭好,谁的系统才能在复杂生产环境里跑得又快又稳。
对于做 AI 应用的人来说,这部分最值得借鉴的不是某一个具体函数名,而是背后的工程观:把每一个可能出事故的地方,提前设计成可观测、可拦截、可回退、可恢复的节点。这样一来,Agent 才不是一辆一路狂飙的车,而是一套既能提速,也能踩刹车的完整系统。