(一)引言
在前面我们已经实现的ReAct智能体和Plan-and-Solve智能体中,智能体一旦完成了任务,其工作流程就结束了。然而他们在执行过程中的行动轨迹以及最终结果,都可能存在错误或者待改进之处 。
因此,在完成工作后有必要增加一个"反刍机制",引入事后(post-hoc)的自我校正循环,使其能够审视自己的工作,发现不足并进行迭代优化。
(二)Reflection的工作原理
考虑到传统大模型微调所需要成本极高,导致大模型无法快速从环境交互中进行学习提升。2023年提出的Reflexion框架,使得大模型能够从语言反馈中优化动作执行。这就是事后自我校正的例子。
Reflexion框架的工作流程可以概括为三步循环:执行 -> 反思 -> 优化
- 执行(Execution):首先,智能体使用ReAct或者Plan-and-Solve尝试完成任务,生成一个答案的"初稿"或者行动轨迹。
- 反思(Reflection):接着,智能体进入反思阶段。它会调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个评审员的角色。评审员会审视第一步生成的"初稿",并从多个维度进行评估。
- 优化(Refinement):最后,智能体将"初稿"和"反馈"作为新的上下文,再次调用大模型,要求它根据反馈内容对初稿进行修正,生成一个更加完善的"修订版"
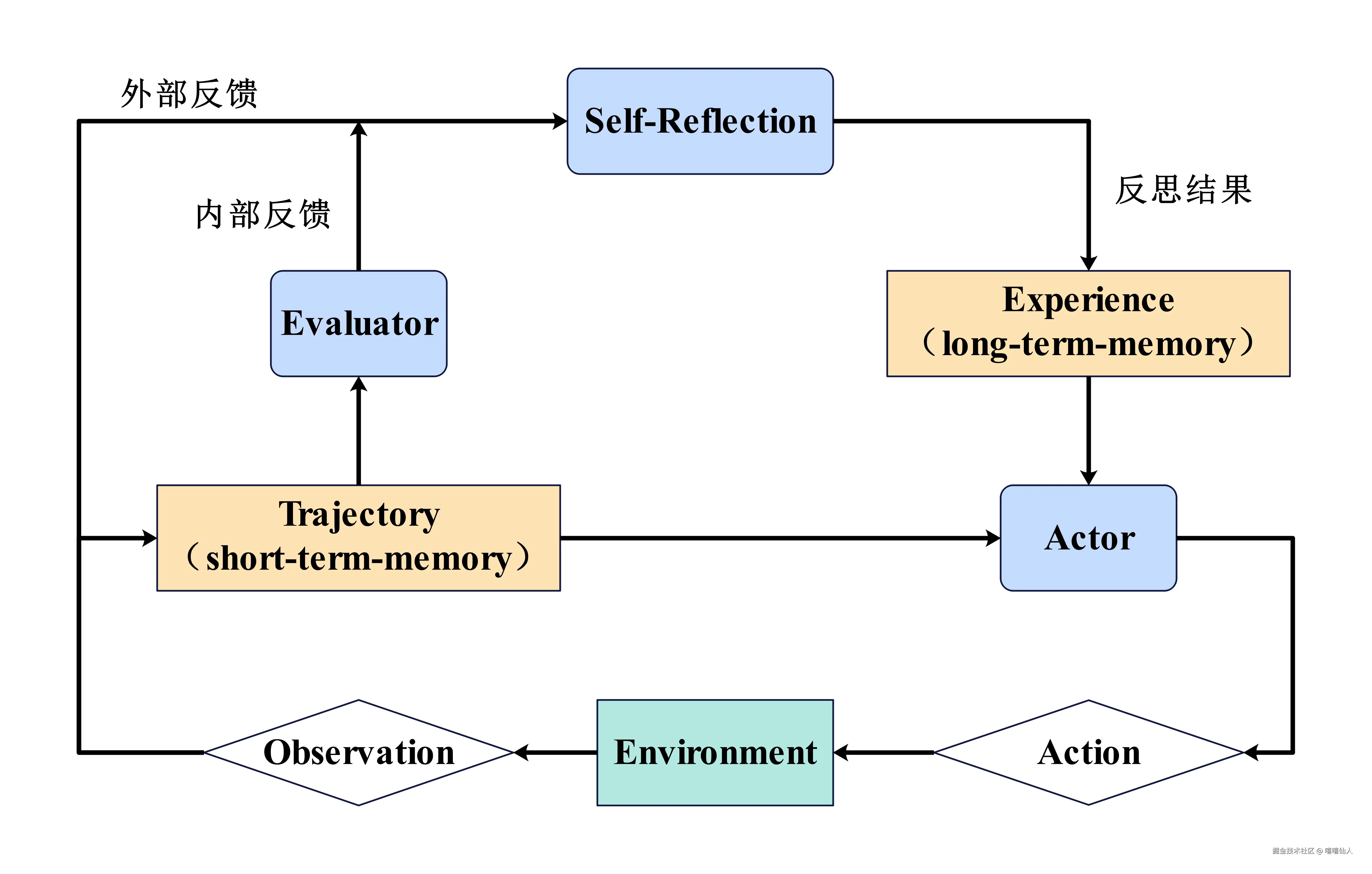
Reflection机制为智能体构建了一个临时的"短期记忆"。整个"执行-反思-优化"的流程形成了一个宝贵的经验记录,智能体不仅仅知道最终的答案,还记得自己是如何从初稿迭代到最终版本的。这样的持续优化过程显著提升了复杂任务的最终成功率和答案质量。
我们可以将这个过程用公式展示出来:
假设 Oi 是第 i 次迭代产生的输出, O0是原始输出,反思模型 πreflect 会生成针对 Oi 的反馈 Fi :
Fi=πreflect(Task,Oi)
随后,优化模型 πrefine 会结合原始任务、上一版输出以及反馈,生成新一版的输出 Oi+1:
Oi+1=πrefine(Task,Oi,Fi)
(三)Reflection的工程实现
我们将从需求开始分析,通过环境准备和构建代码再到最后的测试从零手撕一个 Reflection 范式的智能体。
1. 需求分析
为了凸显Reflection迭代优化的特性,我们设计的目标任务是"编写一个Python函数,找到1到n之间所有的素数。" 这个任务非常适配Reflection范式:
- 优化方向明确:智能体初次生成的代码很可能是一个简单但效率低下的递归实现,可以根据反馈将其优化为更高效的迭代版本。
- 反思点清晰:可以通过反思发现其"时间复杂度过高"或"存在重复计算"的问题。
2. Reflection智能体编码实现
(1)记忆模块
Reflection通常对应着信息的存储和提取,如果上下文足够长的情况,想让"评审员"直接获取所有的信息然后进行反思往往会传入很多冗余信息。因此,一个"短期记忆"模块是实现该范式的必需品。这个记忆模块将负责存储每一次"执行-反思"循环的完整轨迹。
python
from typing import List, Dict, Any, Optional
class Memory:
# 短期记忆模块, 储存智能体的行动和反思轨迹
def __init__(self):
# 初始化一个空列表存储所有记录
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
# 向记忆中添加一条新纪录
# record_type参数:记录的类型------execution或者reflection
self.records.append({"type": record_type, "content": content})
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
# 将所有的记录格式化为一个连贯的字符串文本,用于构建提示词
trajectory = ""
for record in self.records:
if record['type'] == 'execution':
trajectory += f"--- 上一轮尝试 (代码) ---\n{record['content']}\n\n"
elif record['type'] == 'reflection':
trajectory += f"--- 评审员反馈 ---\n{record['content']}\n\n"
return trajectory.strip()
def get_last_execution(self) -> str:
# 获取最近一次的执行结果
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return None- 使用列表
records来按顺序存储每一次的行动和反思。 add_record方法负责向记忆中添加新的记录。- get_trajectory 方法将记忆轨迹格式化一段文本便于后续直接插入到后续的提示词中,为模型的反思和优化提供完整的上下文。
get_last_execution方便我们获取最新的执行结果以供反思。
(2)提示词设计
Reflection需要多个不同角色的提示词来协同工作。
(i)初始执行提示词
这是智能体首次尝试解决问题的提示词,内容相对直接,只要求模型完成指定任务。
python
# 1. 初始执行提示词
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""(ii)反思提示词
它指示模型扮演"评审员"的角色,对上一轮生成的代码进行批判性分析,并提供具体的、可改进的反馈。
python
# 2. 反思提示词
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在**算法效率**上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
```python
{code}
```
请分析该代码的时间复杂度,并思考是否存在一种**算法上更优**的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答"无需改进"。
请直接输出你的反馈,不要包含任何额外的解释。
"""(iii)优化提示词
当收到反馈后,优化提示词将引导模型根据反馈内容对原有代码进行修正和反馈。
python
# 3. 优化提示词
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
# 评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""(3)ReflectionAgent类实现
将(1)中的记忆模块和(2)中的提示词整合到 ReflectionAgent 类中
python
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# 1. 初始执行
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# 2. 迭代循环:反思与优化
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback or "no need for improvement" in feedback.lower():
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_propmt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n{final_code}")
return final_code
def _get_llm_response(self, promt: str) -> str:
# 用于调用LLM并获取完整的流式响应
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
return response_text(4)Reflection智能体完整实现
以Ubuntu22.04系统,Python3.10版本为例进行展示。
首先我们新建一个项目文件夹 Reflection_demo 来存放我们的所有文件。
Reflection_demo/
├── .env
├── llm_client.py
├── Reflection.py
└── README.md
Reflection.py
python
from typing import List, Dict, Any, Optional
from dotenv import load_dotenv
from llm_client import HelloAgentsLLM
try:
load_dotenv()
except FileNotFoundError:
print("警告:未找到 .env 文件,将使用系统环境变量。")
except Exception as e:
print(f"警告:加载 .env 文件时出错: {e}")
class Memory:
"""
一个简单的短期记忆模块,用于存储智能体的行动与反思轨迹。
"""
def __init__(self):
# 初始化一个空列表来存储所有记录
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
"""
向记忆中添加一条新记录。
参数:
- record_type (str): 记录的类型 ('execution' 或 'reflection')。
- content (str): 记录的具体内容 (例如,生成的代码或反思的反馈)。
"""
self.records.append({"type": record_type, "content": content})
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
"""
将所有记忆记录格式化为一个连贯的字符串文本,用于构建提示词。
"""
trajectory = ""
for record in self.records:
if record['type'] == 'execution':
trajectory += f"--- 上一轮尝试 (代码) ---\n{record['content']}\n\n"
elif record['type'] == 'reflection':
trajectory += f"--- 评审员反馈 ---\n{record['content']}\n\n"
return trajectory.strip()
def get_last_execution(self) -> str:
"""
获取最近一次的执行结果 (例如,最新生成的代码)。
"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return None
# --- 模块 2: Reflection 智能体 ---
# 1. 初始执行提示词
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""
# 2. 反思提示词
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在**算法效率**上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
```python
{code}
```
请分析该代码的时间复杂度,并思考是否存在一种**算法上更优**的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答"无需改进"。
请直接输出你的反馈,不要包含任何额外的解释。
"""
# 3. 优化提示词
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
# 评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# --- 1. 初始执行 ---
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# --- 2. 迭代循环:反思与优化 ---
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback or "no need for improvement" in feedback.lower():
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n{final_code}")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""一个辅助方法,用于调用LLM并获取完整的流式响应。"""
messages = [{"role": "user", "content": prompt}]
# 确保能处理生成器可能返回None的情况
response_text = self.llm_client.think(messages=messages) or ""
return response_text
if __name__ == '__main__':
# 1. 初始化LLM客户端 (请确保你的 .env 和 llm_client.py 文件配置正确)
try:
llm_client = HelloAgentsLLM()
except Exception as e:
print(f"初始化LLM客户端时出错: {e}")
exit()
# 2. 初始化 Reflection 智能体,设置最多迭代2轮
agent = ReflectionAgent(llm_client, max_iterations=2)
# 3. 定义任务并运行智能体
task = "编写一个Python函数,找出1到n之间所有的素数 (prime numbers)。"
agent.run(task)llm_client.py
python
# llm_client.py
import os
from openai import OpenAI
from dotenv import load_dotenv # 从.env文件中导入环境变量
from typing import List, Dict
# 导入环境变量
load_dotenv()
class HelloAgentsLLM:
# 调用兼容OpenAI接口的服务, 使用默认的流式响应(将响应内容分为chunks逐个发送给客户端,而不是等待响应完毕一次性发送)
def __init__(self, model: str = None, apiKey: str = None, baseUrl: str = None, timeout: int = None):
# 初始化客户端,优先使用本地传入参数,否则加载环境变量参数
self.model = model or os.getenv("LLM_MODEL_ID")
apiKey = apiKey or os.getenv("LLM_API_KEY")
baseUrl = baseUrl or os.getenv("LLM_BASE_URL")
timeout = timeout or int(os.getenv("LLM_TIMEOUT", 60))
if not all([self.model, apiKey, baseUrl]):
raise ValueError("model ID and apiKey must be provided in .env file")
self.client = OpenAI(api_key=apiKey, base_url=baseUrl, timeout=timeout)
print("✅ 大模型配置成功")
def think(self, messages: List[Dict[str, str]], temperature: float = 0) -> str:
# 调用大模型进行思考,并返回思考结果
print(f"🧠 正在调用 {self.model} 模型...")
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
stream=True, # 开启流式响应
)
# 流式响应逻辑
print("✅ 大语言模型响应成功:")
collected_content = []
for chunk in response:
content = chunk.choices[0].delta.content or "" # 从当前数据块提取刚产生的数据
print(content, end="", flush=True)
collected_content.append(content) # 将每次新产生的数据进行添加
print() # 流式输出结束后换行
return "".join(collected_content) # 将列表元素合成为完整字符串
except Exception as e:
print(f"❌ 调用LLM API时发生错误: {e}")
return None.env
python
# .env 文件
LLM_API_KEY="YOUR-API-KEY"
LLM_MODEL_ID="YOUR-MODEL"
LLM_BASE_URL="YOUR-URL"3. 测试效果
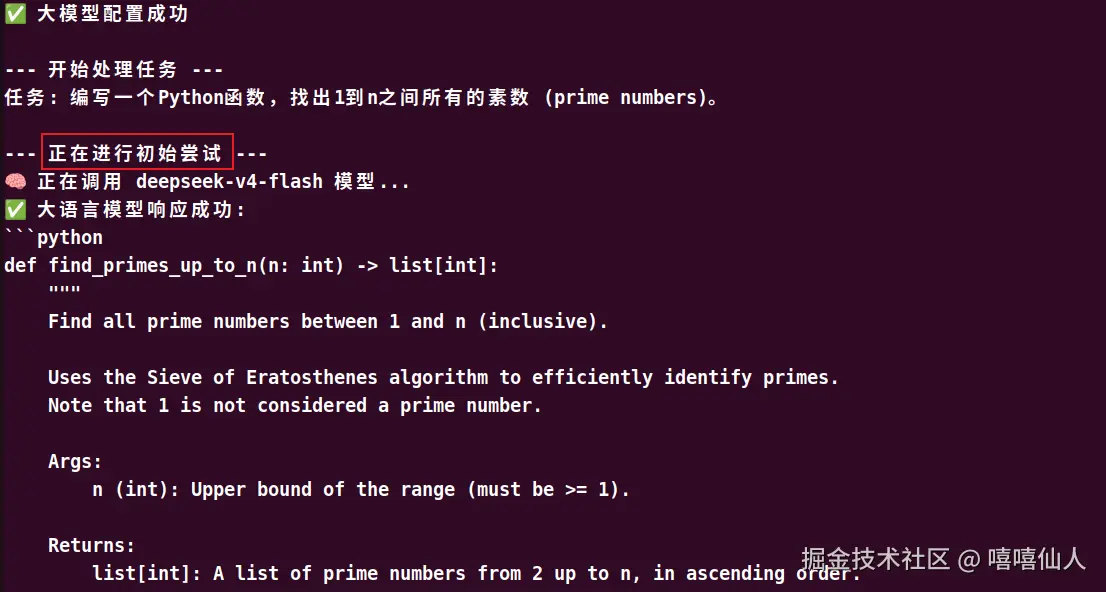
在终端运行 python Reflection.py,观察到以下输出:


(四)Reflection的特点和局限性
(1)特点
- 显著提升了输出的质量与上限:特别适合对准确率、严谨度和专业性要求极高的场景。
- 具备强大的可解释性与经验积累能力:整个的思考过程通过短期和长期记忆模块被完整记录下来。
(2)局限性
- 计算成本与时间开销高:单次任务可能需要调用3-5次甚至更多次大模型,Token消耗呈线性甚至指数级增长,接口响应延迟也会明显增加。
- 高度依赖"评审员"的水平:如果扮演评审员的模型自身存在知识盲区、认知偏差,或者能力弱于生成者,就可能出现"互相放水"或者"瞎指挥"的情况。