在教育数字化转型的浪潮中,课堂实录的智能化分析成为提升教学质量的关键环节。传统的课堂视频分析依赖人工转录和标注,效率低、成本高且易出错。本文将分享一套基于讯飞语音识别 API 与大语言模型(LLM)的完整解决方案,实现从课堂视频自动提取音频、语音转写、文本优化到结构化数据输出的全流程自动化,为教学分析提供精准、高效的数据支撑。
一、方案背景与核心目标
课堂视频中蕴含着丰富的教学互动信息,但原始视频无法直接用于结构化分析。我们的核心目标是:
- 将课堂 MP4 视频自动转换为 WAV 音频格式,解决语音识别的数据源问题;
- 利用讯飞语音识别 API 完成音频转写,精准识别师生对话及时间戳;
- 通过 LLM 优化转写文本,修正识别噪声、纠正角色分配错误;
- 自动识别课堂教学活动(如小组讨论、独立练习等),并输出 CSV/JSON 结构化数据,适配教学分析场景。
二、技术架构与核心模块
整个方案的技术架构围绕audio_to_data类展开,核心模块包括视频转音频、语音识别、LLM 文本优化、活动识别、结构化数据输出五大环节,整体流程如下:
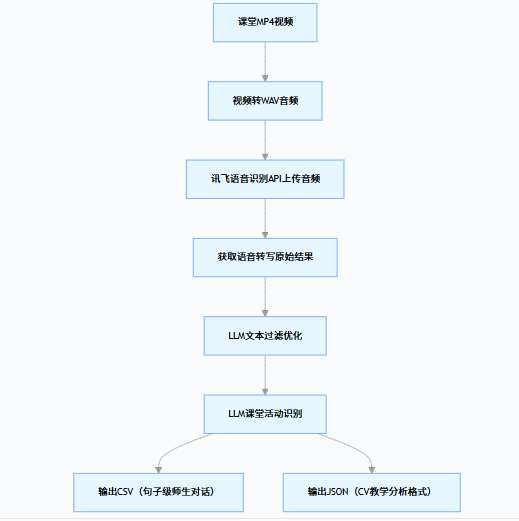
1. 视频转音频:打通数据源第一步
课堂视频通常为 MP4 格式,而语音识别 API 需要音频输入。我们基于 MoviePy 库实现视频到 WAV 音频的自动转换,支持可选时长截取(便于测试),并自动创建音频存储目录:
def movie_to_audio(self, mp4_file, wav_file, duration_seconds=None):
"""
使用 MoviePy 将 MP4 文件转换为 WAV 文件,处理音频轨道检测、目录自动创建等异常场景
"""
try:
if not os.path.exists(mp4_file):
print(f"错误: 输入文件不存在: {mp4_file}")
return False
# 确保输出目录存在
output_dir = os.path.dirname(wav_file)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
# 加载视频并提取音频
video_clip = VideoFileClip(mp4_file)
if duration_seconds:
video_clip = video_clip.subclipped(0, min(duration_seconds, video_clip.duration))
if video_clip.audio is None:
print("错误: 视频文件不包含音频轨道")
return False
audio_clip = video_clip.audio
audio_clip.write_audiofile(wav_file, codec='pcm_s16le')
# 释放资源
audio_clip.close()
video_clip.close()
return True
except Exception as e:
print(f"转换失败: {e}")
return False该模块解决了视频格式兼容问题,同时做了完善的异常处理(如文件不存在、无音频轨道等),保证流程稳定性。
2. 讯飞语音识别:精准转写师生对话
讯飞语音识别 API 支持教育领域(pd="edu")的语音转写,可识别多角色(师生)、返回精准的时间戳。核心步骤包括:
-
生成签名:基于 APPID、时间戳、秘钥生成 API 调用签名,保证请求安全;
-
上传音频:将 WAV 音频文件上传至讯飞服务器,获取任务 ID;
-
轮询获取结果:根据任务 ID 轮询查询转写状态,直到返回最终结果。
def get_signa(self, ts):
"""生成讯飞API调用签名"""
m2 = hashlib.md5()
m2.update((self.appid + ts).encode('utf-8'))
md5 = m2.hexdigest()
signa = hmac.new(self.secret_key.encode('utf-8'), md5.encode(), hashlib.sha1).digest()
return base64.b64encode(signa).decode('utf-8')def upload_file(self, ts, signa):
"""上传音频文件至讯飞服务器"""
file_len = os.path.getsize(self.upload_file_path)
file_name = os.path.basename(self.upload_file_path)
param_dict = {
'appId': self.appid,
'signa': signa,
'ts': ts,
"fileSize": file_len,
"fileName": file_name,
"pd": "edu", # 教育领域适配
"roleType": "1",
"roleNum": "2" # 识别师生两个角色
}
with open(self.upload_file_path, 'rb') as f:
data = f.read(file_len)
response = requests.post(
url=lfasr_host + api_upload + "?" + urllib.parse.urlencode(param_dict),
headers={"Content-type": "application/json"},
data=data
)
result = json.loads(response.text)
if result['code'] != '000000':
print(f"上传失败! 错误信息: {result.get('descInfo')}")
return None
return result
3. LLM 文本优化:修正识别噪声与角色错误
语音转写结果常存在识别噪声(如 "噢没""嗯嗯嗯")、角色分配错误(老师的话标记为学生)等问题。我们基于阿里云通义千问(兼容 OpenAI 接口)的 DeepSeek-V3 模型,分两步优化:
-
文本修复:识别并删除无意义词汇、补全缺失内容、修正错误词汇;
-
角色修正:根据上下文逻辑,纠正师生角色分配错误。
def llm_filter(self, text):
"""LLM过滤优化转写文本,修复噪声并修正角色"""
prompt_content = """
你的任务是修复课堂录音转文本的CSV中的识别噪声,步骤:
1. 识别内容错误、缺失、多余内容;
2. 谨慎修正,不改变原意;
3. 修正角色分配错误(老师/学生);
4. 保持CSV格式:说话人,开始时间,结束时间,"文本内容"
"""
response = self.llm.chat.completions.create(
model="deepseek-v3",
messages=[
{"role": "system", "content": "你是专业的文本修复助手"},
{"role": "user", "content": prompt_content + text}
],
temperature=0.5,
)
return response.choices[0].message.content
为提升效率,我们还实现了批量处理逻辑(batch_llm_filter),按 50 句 / 批处理,降低 API 调用次数,同时处理解析异常(失败时保留原始文本)。
4. 课堂活动识别:挖掘隐藏的教学环节
原始转写仅包含师生对话,我们通过 LLM 分析对话上下文,识别未被记录的教学活动(如 "独立思考""小组讨论"):
- 识别 "触发指令":老师发出的任务指令(如 "请大家独立思考三分钟");
- 识别 "结束信号":老师终止活动的发言(如 "时间到了,谁来分享一下");
- 生成活动标签:在对话间隙插入活动描述,补充时间戳和角色。
5. 结构化数据输出:适配多场景分析
最终输出两种结构化数据:
-
CSV 文件:句子级师生对话,包含 "时间(MM:SS)、角色、内容",便于人工查看和 NLP 分析;
-
JSON 文件:适配 CV 教学分析的格式,包含开始 / 结束秒数、角色编号、内容,便于程序调用。
def json_to_sentences_csv(self, json_file_path, output_csv_path=None):
"""生成句子级CSV文件"""
if output_csv_path is None:
base_name = os.path.splitext(json_file_path)[0]
output_csv_path = base_name + '_sentences.csv'
with open(output_csv_path, 'w', newline='', encoding='utf-8-sig') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['时间', '角色', '内容'])
for sentence in self.sentences_activity:
writer.writerow([
self.ms_to_mmss(sentence['start_ms']),
sentence['spk'],
sentence['text']
])
return output_csv_path
三、使用指南
1. 环境准备
安装依赖库:
pip install httpx requests moviepy openai python-dotenv2. 配置 API 密钥
- 讯飞开放平台申请 APPID 和 Secret Key(语音识别);
- 阿里云通义千问申请 API Key(LLM 调用)。
3. 运行代码
if __name__ == '__main__':
# 配置参数
APPID = "你的讯飞APPID"
SECRET_KEY = "你的讯飞Secret Key"
LLM_API_KEY = "你的阿里云API Key"
VIDEO_FILE_PATH = "test.mp4" # 课堂视频路径
# 初始化处理器
audio_processor = audio_to_data(APPID, SECRET_KEY, VIDEO_FILE_PATH, LLM_API_KEY)
# 执行全流程处理
processed_result = audio_processor.process_audio_file()
print("CSV文件路径:", processed_result[1])
print("JSON文件路径:", processed_result[2])
四、方案优势与拓展方向
优势
- 全自动化:从视频到结构化数据,无需人工干预;
- 高精准度:结合教育领域语音识别和 LLM 优化,转写准确率大幅提升;
- 场景适配:输出的 CSV/JSON 格式直接适配教学分析场景,可无缝对接后续的教学行为分析、师生互动统计等应用。
拓展方向
- 多语种支持:适配双语课堂,增加英文语音识别和优化;
- 实时处理:结合流媒体技术,实现课堂视频的实时转写和分析;
- 可视化展示:开发前端页面,展示结构化数据和课堂活动时间轴;
- 教学指标提取:基于结构化数据,自动计算师生互动时长、活动类型占比等教学指标。
五、总结
本文提出的方案将语音识别、大语言模型与教育场景深度结合,解决了课堂视频分析的自动化、精准化问题。该方案不仅能降低教学分析的人力成本,还能挖掘课堂中隐藏的教学活动信息,为教师教学反思、教研团队分析提供数据支撑。未来,随着大模型能力的提升,我们还可进一步实现教学质量的智能评估,助力教育数字化升级。
代码开源提示:本文核心代码已做脱敏处理,可根据实际需求调整 API 参数、LLM 提示词和数据输出格式,适配不同的课堂场景和分析需求。