从云端数据分析平台数据图实验报告
班级 物联网2303
姓名 杜子健
学号 231040700302
一、云端数据分析平台ModelWhale设置
1.1 平台注册与登录
通过浏览器访问 ModelWhale 云端平台官网(https://www.modelwhale.com/),使用学校邮箱完成注册后,输入账号密码登录个人工作台。登录后系统自动跳转至「项目管理」页面,支持创建新项目、导入数据集、在线编写代码等核心功能。
1.2 项目创建与环境配置
- 点击工作台右上角「+ 新建项目」,选择「空白项目」,项目名称设置为「泰坦尼克号生存预测 KDD 实验」,项目描述填写「基于泰坦尼克号数据集的知识发现过程,含数据探索、预处理、可视化分析」,点击确认创建。
- 环境配置:进入项目后,系统默认提供 Python 3.8 运行环境,已预装 pandas、numpy、matplotlib、seaborn 等数据分析必备库。通过「环境设置」可查看已安装库版本,若需补充依赖,可通过「终端」执行pip install 库名命令安装(本次实验默认环境已满足需求)。
1.3 数据集导入
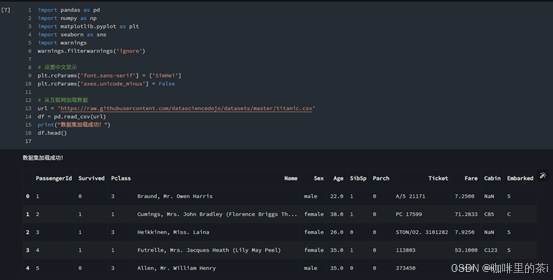
- 进入项目后,点击左侧「数据集」→「+ 导入」,选择「公开数据集」,在搜索框输入「泰坦尼克号生存预测」,选择经典数据集(包含 train.csv 和 test.csv 文件,train.csv 含 891 条样本,12 个特征)。
- 导入完成后,数据集自动存储在项目「data」目录下,可通过pd.read_csv('./data/train.csv')直接读取使用。
二、知识发现(KDD) -- 泰坦尼克号生存预测数据集
2.1 数据取得(取得数据集)
本次实验使用泰坦尼克号经典公开数据集,核心数据文件为train.csv,包含 891 名乘客的生存状态及个人信息,用于后续 KDD 全流程分析。数据集核心特征说明如下:
| 特征名称 | 特征含义 | 数据类型 |
|---|---|---|
| PassengerId | 乘客唯一 ID | 整数(无实际预测意义) |
| Survived | 生存状态(1 = 生存,0 = 遇难) | 二进制(目标变量) |
| Pclass | 客舱等级(1 = 一等舱,2 = 二等舱,3 = 三等舱) | 分类变量 |
| Name | 乘客姓名 | 字符串 |
| Sex | 性别 | 分类变量(male/female) |
| Age | 年龄 | 连续变量(含缺失值) |
| SibSp | 船上兄弟姐妹 / 配偶数量 | 整数 |
| Parch | 船上父母 / 子女数量 | 整数 |
| Ticket | 船票编号 | 字符串 |
| Fare | 票价 | 连续变量 |
| Cabin | 客舱号 | 字符串(含缺失值) |
| Embarked | 登船港口(C = 瑟堡,Q = 皇后镇,S = 南安普顿) | 分类变量 |
数据读取代码:
python
运行
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
设置中文显示
plt.rcParams'font.sans-serif' = 'SimHei'
plt.rcParams'axes.unicode_minus' = False
读取数据集
df = pd.read_csv('./data/train.csv')
print("数据集形状:", df.shape) # 输出(891, 12),验证数据读取成功
df.head() # 查看前5条数据
2.2 数据探索(描述性统计)
通过描述性统计分析数据集的基本特征,包括数据分布、数值特征统计量、分类特征分布等,为后续预处理提供依据。
(1 )数值特征统计分析
python
运行
数值特征描述性统计
numeric_stats = df.describe()
print("数值特征描述性统计:")
print(numeric_stats)
核心结论:
- 年龄(Age)均值约 29.7 岁,最小值 0.42 岁(婴儿),最大值 80 岁,标准差 14.5 岁,说明乘客年龄分布较广。
- 生存比例:Survived 均值为 0.38,即约 38% 的乘客存活。
- 客舱等级(Pclass)均值约 2.3,说明三等舱乘客占比最高。
- 票价(Fare)均值约 32.3 美元,标准差较大(49.7),存在高票价异常值。
(2 )分类特征分布分析
python
运行
分类特征分布统计
categorical_features = 'Sex', 'Pclass', 'Embarked', 'Survived'
for feat in categorical_features:
print(f"\n{feat}特征分布:")
print(dffeat.value_counts(normalize=True).round(3) * 100) # 输出占比(%)
核心结论:
- 性别(Sex):男性占 64.8%,女性占 35.2%,男性乘客数量显著多于女性。
- 客舱等级(Pclass):三等舱占 55.1%,二等舱占 24.2%,一等舱占 20.7%,三等舱乘客占比最高。
- 登船港口(Embarked):南安普顿(S)占 72.4%,瑟堡(C)占 18.9%,皇后镇(Q)占 8.7%,多数乘客从南安普顿登船。
2.3 数据缺失值处理
通过数据探索发现数据集存在缺失值,需针对性处理以避免影响后续分析结果。
(1 )缺失值检测
python
运行
检测各特征缺失值数量及占比
missing_info = pd.DataFrame({
'缺失值数量': df.isnull().sum(),
'缺失值占比(%)': (df.isnull().sum() / len(df) * 100).round(2)
})
print("缺失值统计:")
print(missing_infomissing_info\['缺失值数量' > 0])
缺失值结果:
- Age(年龄):缺失 177 条,占比 19.87%
- Cabin(客舱号):缺失 687 条,占比 77.10%
- Embarked(登船港口):缺失 2 条,占比 0.22%
(2 )缺失值处理策略与实现
- Age (年龄):缺失占比约 20%,采用「中位数填充」(受异常值影响小):
python
运行
df'Age'.fillna(df'Age'.median(), inplace=True)
- Cabin (客舱号):缺失占比超 77%,直接填充无意义,新增「是否有客舱」二进制特征(1 = 有客舱,0 = 无客舱):
python
运行
df'Has_Cabin' = df'Cabin'.apply(lambda x: 0 if pd.isnull(x) else 1)
- Embarked (登船港口):缺失占比极低(0.22%),采用「众数填充」(使用出现频率最高的港口 S):
python
运行
df'Embarked'.fillna(df'Embarked'.mode()0, inplace=True)
处理后验证:print("处理后缺失值数量:", df.isnull().sum().sum()),输出 0,说明缺失值已完全处理。
2.4 数据呈现与分析(分析数据图)
通过可视化图表呈现数据特征与生存状态的关联,挖掘潜在规律,核心图表如下:
(1 )生存状态总体分布
python
运行
plt.figure(figsize=(8, 5))
survived_count = df'Survived'.value_counts()
sns.countplot(x='Survived', data=df, palette='#FF6B6B', '#4ECDC4')
plt.title('泰坦尼克号乘客生存状态分布', fontsize=14)
plt.xlabel('生存状态(0=遇难,1=生存)', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
添加数值标签
for i, v in enumerate(survived_count):
plt.text(i, v + 10, str(v), ha='center', fontsize=11)
plt.savefig('./survived_distribution.png', dpi=300, bbox_inches='tight')
plt.show()
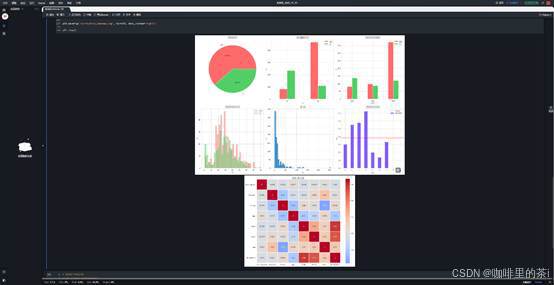
分析结论:891 名乘客中,遇难 549 人(占 61.6%),生存 342 人(占 38.4%),整体存活率较低。
(2 )性别与生存状态的关系
python
运行
plt.figure(figsize=(8, 5))
sns.countplot(x='Sex', hue='Survived', data=df, palette='#FF6B6B', '#4ECDC4')
plt.title('不同性别的生存状态分布', fontsize=14)
plt.xlabel('性别', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.legend('遇难', '生存', fontsize=11)
计算存活率
survived_by_sex = df.groupby('Sex')'Survived'.mean() * 100
for i, sex in enumerate(survived_by_sex.index):
plt.text(i, dfdf\['Sex'==sex].shape0 + 10, f'存活率:{survived_by_sexsex:.1f}%', ha='center', fontsize=11)
plt.savefig('./sex_survived.png', dpi=300, bbox_inches='tight')
plt.show()
分析结论:女性存活率(74.2%)远高于男性(18.9%),体现了 "女士优先" 的救援原则。
(3 )客舱等级与生存状态的关系
python
运行
plt.figure(figsize=(8, 5))
sns.countplot(x='Pclass', hue='Survived', data=df, palette='#FF6B6B', '#4ECDC4')
plt.title('不同客舱等级的生存状态分布', fontsize=14)
plt.xlabel('客舱等级(1=一等舱,2=二等舱,3=三等舱)', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.legend('遇难', '生存', fontsize=11)
计算存活率
survived_by_pclass = df.groupby('Pclass')'Survived'.mean() * 100
for i, pclass in enumerate(survived_by_pclass.index):
plt.text(i, dfdf\['Pclass'==pclass].shape0 + 10, f'存活率:{survived_by_pclasspclass:.1f}%', ha='center', fontsize=11)
plt.savefig('./pclass_survived.png', dpi=300, bbox_inches='tight')
plt.show()
分析结论:客舱等级越高,存活率越高 ------ 一等舱存活率(62.9%)> 二等舱(47.3%)> 三等舱(24.2%),反映了社会阶层对救援优先级的影响。
(4 )年龄分布与生存状态的关系
python
运行
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='Age', hue='Survived', multiple='dodge', bins=20, palette='#FF6B6B', '#4ECDC4')
plt.title('不同年龄的生存状态分布', fontsize=14)
plt.xlabel('年龄', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.legend('遇难', '生存', fontsize=11)
plt.savefig('./age_survived.png', dpi=300, bbox_inches='tight')
plt.show()
分析结论:儿童(0-10 岁)存活率较高,老年乘客(60 岁以上)存活率较低,体现了 "优先救援老弱妇孺" 的原则;20-40 岁成年乘客数量最多,但遇难比例较高。
(5 )登船港口与生存状态的关系
python
运行
plt.figure(figsize=(8, 5))
sns.countplot(x='Embarked', hue='Survived', data=df, palette='#FF6B6B', '#4ECDC4')
plt.title('不同登船港口的生存状态分布', fontsize=14)
plt.xlabel('登船港口(C=瑟堡,Q=皇后镇,S=南安普顿)', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.legend('遇难', '生存', fontsize=11)
计算存活率
survived_by_embarked = df.groupby('Embarked')'Survived'.mean() * 100
for i, port in enumerate(survived_by_embarked.index):
plt.text(i, dfdf\['Embarked'==port].shape0 + 10, f'存活率:{survived_by_embarkedport:.1f}%', ha='center', fontsize=11)
plt.savefig('./embarked_survived.png', dpi=300, bbox_inches='tight')
plt.show()
三、过程出现那些问题? 如何解决?
1. 问题 1 :中文显示乱码
- 现象:使用 matplotlib 绘制图表时,中文标题和标签显示为方框(乱码)。
- 解决方法:在代码开头设置中文显示参数,指定支持中文的字体(如 SimHei、Microsoft YaHei):
python
运行
plt.rcParams'font.sans-serif' = 'SimHei' # 设置中文显示字体
plt.rcParams'axes.unicode_minus' = False # 解决负号显示异常问题
2. 问题 2 :Cabin 特征缺失值过多,处理方式纠结
- 现象:Cabin(客舱号)缺失占比达 77.1%,直接填充或删除特征均不合理。
- 解决方法:放弃直接使用 Cabin 原始值,转换为衍生特征 ------"是否有客舱"(Has_Cabin),用 1 表示有客舱信息,0 表示无,既保留了部分信息,又避免了缺失值的影响。
3. 问题 3 :图表保存后部分内容被截断
- 现象:使用plt.savefig()保存图表时,标题或坐标轴标签的边缘部分被截断,显示不完整。
- 解决方法:在savefig()中添加bbox_inches='tight'参数,自动调整图表边界,确保所有内容完整显示:
python
运行
plt.savefig('./age_survived.png', dpi=300, bbox_inches='tight')
4. 问题 4 :数据探索时无法直观发现特征与生存状态的关联
- 现象:仅通过描述性统计数值,难以快速判断哪些特征对生存状态影响显著。
- 解决方法:采用可视化分析,通过 countplot、histplot 等图表,将特征与生存状态的关联可视化,直观呈现规律(如性别、客舱等级的影响)。
四、对使用python语言进行KDD实验有甚么看法,以后它可以帮你做哪些事情?
1. 对 Python 进行 KDD 实验的看法
Python 语言是 KDD(知识发现)实验的理想工具,其优势主要体现在以下方面:
- 生态丰富:拥有 pandas(数据处理)、matplotlib/seaborn(可视化)、scikit-learn(建模)等一站式数据分析库,无需切换工具即可完成 KDD 全流程(数据获取→预处理→探索→建模→评估)。
- 易用性强:语法简洁直观,代码可读性高,即使是物联网专业等非计算机背景学生,也能快速上手实现复杂的数据分析逻辑。
- 兼容性好:支持本地运行与云端平台(如 ModelWhale)无缝衔接,无需担心环境配置问题,可专注于数据本身的探索。
- 可视化能力强:通过少量代码即可生成高质量图表,将抽象数据转化为直观规律,助力知识发现。
同时,Python 也存在一定局限性:大规模数据集处理速度略逊于 C++ 等编译型语言,但对于教学实验、中小规模数据挖掘场景,完全能满足需求。
2. 未来应用场景
结合物联网专业背景,Python 的 KDD 能力未来可帮我完成以下事情:
- 物联网设备数据分析:处理传感器采集的温度、湿度、设备运行状态等时序数据,通过 KDD 发现设备故障预警规律、能耗优化空间。
- 环境监测数据分析:对空气质量、水质等监测数据进行预处理与可视化,挖掘污染来源、变化趋势等知识,为环保决策提供支持。
- 智能家居场景应用:分析用户行为数据(如家电使用时间、偏好设置),通过 KDD 构建用户画像,实现设备智能联动与个性化服务。
- 毕业设计与科研:基于 Python 实现物联网相关的数据分析类课题,如 "基于 KDD 的智慧农业作物生长状态预测""工业物联网设备故障诊断模型" 等。
五、心得与感受
本次在 ModelWhale 云端平台完成泰坦尼克号数据集的 KDD 实验,让我深刻体会到 Python 数据分析的魅力,也收获了扎实的实践技能与思维提升。
实验初期,我对数据预处理中的缺失值处理感到困惑,尤其是 Cabin 特征高达 77% 的缺失率,让我一度不知如何下手。通过查阅资料和尝试不同方案,最终选择将其转化为衍生特征,这让我明白:数据预处理不是简单填充或删除,而是要结合业务逻辑和数据特点,保留有价值的信息。
在数据可视化环节,当通过图表直观看到 "女性存活率远高于男性""一等舱乘客存活率最高" 等规律时,我切实感受到了 "数据说话" 的力量 ------ 原本抽象的数字,通过可视化转化为清晰的结论,这正是 KDD 的核心价值所在。同时,ModelWhale 平台的便捷性也让我印象深刻,无需本地配置复杂环境,即可快速导入数据集、编写代码并生成图表,极大提升了实验效率。
作为物联网专业学生,本次实验让我意识到:物联网的核心不仅是设备互联,更在于数据的价值挖掘。Python 的 KDD 能力为我打开了新的视野,未来我将尝试将数据分析与专业知识结合,比如用 Python 处理传感器数据、构建预测模型,让物联网设备产生的海量数据转化为有价值的决策支持。
此外,实验中遇到的中文乱码、图表截断等问题,也让我学会了独立排查和解决问题的方法,培养了严谨的实验态度。这次实验不仅提升了我的 Python 编程能力,更塑造了 "数据驱动" 的思维方式 ------ 在未来的学习和工作中,我会更注重用数据说话,用科学的分析方法解决实际问题。