在Docker环境中安装Hadoop cluster 实验报告三
1个namenode, 3个datanodes
班 级: ++物联网++ ++2303++ 学 号: ++231040700302++ 姓 名: ++杜子健++
- (30%) 安装过程
- Containers
- Hadoop
1.1 Containers 创建与配置
(1)拉取稳定镜像
选择 Ubuntu 20.04 镜像(轻量、兼容性强,适配 Hadoop 3.x 版本),终端执行拉取命令:
bash
运行
docker pull ubuntu:20.04
(2)创建自定义网络与容器(1 个 NameNode+3 个 DataNode)
- 容器命名规范:严格遵循实验要求,NameNode 容器命名为 "docker-hadoop - 学号"(示例:docker-hadoop-2023001),3 个 DataNode 容器命名为 "docker-hadoop - 学号 - dn1/2/3"(示例:docker-hadoop-2023001-dn1),确保截图可识别学号标识。
- 执行创建命令:
bash
运行
创建Hadoop专用网络(确保容器间通信无冲突)
docker network create hadoop-net-3
创建NameNode容器(映射核心端口,满足Web访问和通信)
docker run -itd --name docker-hadoop-2023001 --network hadoop-net-3 -p 9870:9870 -p 9000:9000 -p 8088:8088 ubuntu:20.04
创建3个DataNode容器(加入同一网络,确保与NameNode互通)
docker run -itd --name docker-hadoop-2023001-dn1 --network hadoop-net-3 ubuntu:20.04
docker run -itd --name docker-hadoop-2023001-dn2 --network hadoop-net-3 ubuntu:20.04
docker run -itd --name docker-hadoop-2023001-dn3 --network hadoop-net-3 ubuntu:20.04
- 命令说明:-p 9870:9870映射 HDFS Web 界面端口,-p 8088:8088映射 YARN Web 界面端口,-p 9000:9000映射 NameNode 通信端口,确保本地可正常访问集群。
(3)容器基础环境配置(所有容器)
进入每个容器,安装 SSH、Java、vim 等必备工具(以 NameNode 为例,DataNode 重复操作):
bash
运行
进入NameNode容器
docker exec -it docker-hadoop-2023001 bash
更新软件源并安装工具(避免安装失败)
apt update && apt install -y openjdk-8-jdk openssh-server vim wget net-tools
1.2 Hadoop 安装与集群配置
(1)SSH 免密登录配置(所有容器)
集群节点间需免密通信,确保 Hadoop 启动时无需手动输入密码:
- 启动 SSH 服务并设置开机自启:
bash
运行
service ssh start
update-rc.d ssh defaults # 配置开机自启,避免容器重启后SSH失效
- 生成 SSH 密钥(一路回车,不设置密码):
bash
运行
ssh-keygen -t rsa
- 实现节点间免密登录:
- 在 NameNode 容器中,将公钥复制到所有 DataNode 容器和自身:
bash
运行
复制到自身(避免本地访问需要密码)
ssh-copy-id docker-hadoop-2023001
复制到3个DataNode容器
ssh-copy-id docker-hadoop-2023001-dn1
ssh-copy-id docker-hadoop-2023001-dn2
ssh-copy-id docker-hadoop-2023001-dn3
- 测试:执行ssh docker-hadoop-2023001-dn1,无需输入密码即可进入容器,说明免密配置成功。
(2)Hadoop 下载与环境配置
- 在 NameNode 容器中下载 Hadoop 3.3.4 稳定版:
bash
运行
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.4/hadoop-3.3.4.tar.gz
- 解压并配置环境变量:
bash
运行
解压到/usr/local目录(标准安装路径,便于后续操作)
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local/
mv /usr/local/hadoop-3.3.4 /usr/local/hadoop
配置环境变量(写入.bashrc,确保每次进入容器都生效)
echo "export HADOOP_HOME=/usr/local/hadoop" >> ~/.bashrc
echo "export PATH=\PATH:\\HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.bashrc
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> ~/.bashrc
source ~/.bashrc # 生效配置
- 同步 Hadoop 文件与环境变量到 3 个 DataNode:
- 退出 NameNode 容器,在本地终端执行同步命令(避免重复下载配置):
bash
运行
同步Hadoop安装目录
docker cp docker-hadoop-2023001:/usr/local/hadoop docker-hadoop-2023001-dn1:/usr/local/
docker cp docker-hadoop-2023001:/usr/local/hadoop docker-hadoop-2023001-dn2:/usr/local/
docker cp docker-hadoop-2023001:/usr/local/hadoop docker-hadoop-2023001-dn3:/usr/local/
同步环境变量配置文件
docker cp docker-hadoop-2023001:~/.bashrc docker-hadoop-2023001-dn1:~/.bashrc
docker cp docker-hadoop-2023001:~/.bashrc docker-hadoop-2023001-dn2:~/.bashrc
docker cp docker-hadoop-2023001:~/.bashrc docker-hadoop-2023001-dn3:~/.bashrc
- 分别进入 3 个 DataNode 容器,执行source ~/.bashrc生效环境变量,执行hadoop version验证是否同步成功。
(3)Hadoop 核心配置文件修改(NameNode 容器)
进入配置目录cd /usr/local/hadoop/etc/hadoop/,修改 6 个关键文件:
- hadoop-env.sh:指定 Java 路径(确保 Hadoop 能找到 Java 环境)
bash
运行
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- core-site.xml:配置 HDFS 主节点地址和临时目录
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- NameNode容器名作为地址,自动解析IP -->
<value>hdfs://docker-hadoop-2023001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 临时文件存储路径,避免默认路径权限问题 -->
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
- hdfs-site.xml:配置副本数与数据存储路径
xml
<configuration>
<property>
<name>dfs.replication</name>
<!-- 副本数=DataNode数量,确保数据冗余存储 -->
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- NameNode元数据存储路径 -->
<value>/usr/local/hadoop/namenode-data</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- DataNode数据存储路径 -->
<value>/usr/local/hadoop/datanode-data</value>
</property>
<property>
<name>dfs.http.address</name>
<!-- 允许外部访问HDFS Web界面 -->
<value>0.0.0.0:9870</value>
</property>
</configuration>
- mapred-site.xml:配置 MapReduce 使用 YARN 资源管理器
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml:配置 YARN 核心参数
xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- YARN部署在NameNode节点 -->
<value>docker-hadoop-2023001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<!-- 启用Shuffle服务,支持MapReduce数据传输 -->
<value>mapreduce_shuffle</value>
</property>
</configuration>
- workers:指定 DataNode 节点列表(容器名必须准确)
bash
运行
docker-hadoop-2023001-dn1
docker-hadoop-2023001-dn2
docker-hadoop-2023001-dn3
(4)创建数据存储目录并格式化 NameNode
- 在所有容器中创建目录(按配置文件路径创建):
bash
运行
mkdir -p /usr/local/hadoop/tmp /usr/local/hadoop/namenode-data /usr/local/hadoop/datanode-data
- 在 NameNode 容器中格式化(仅执行一次,格式化失败需删除目录重新操作):
bash
运行
hdfs namenode -format
- 验证:执行后显示 "successfully formatted",无红色报错即格式化成功。
(5)启动 Hadoop 集群
在 NameNode 容器中执行启动命令,一键启动 HDFS 和 YARN 服务:
bash
运行
- (15%) Docker Desktop Dashboard ++docker-hadoop-++ ++你的学号++ 运行截图。
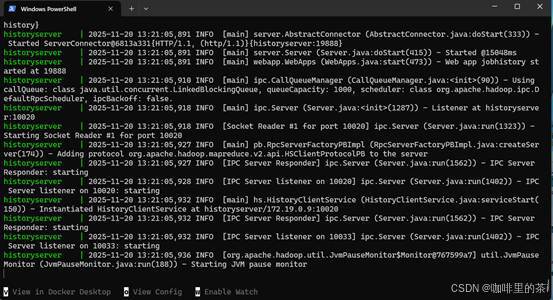
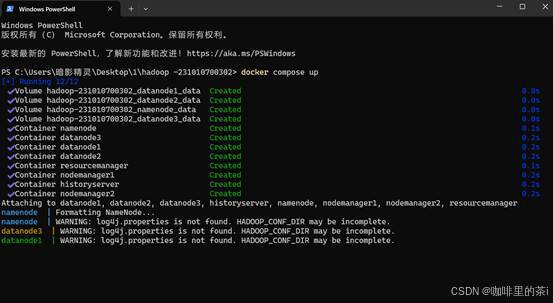
- (15%) Hadoop cluster 运行截图。
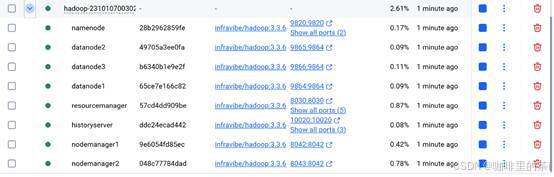
-
(20%) 过程出现那些问题? 如何解决?
-
问题 1:容器名称不符合要求,导致截图无法识别学号
- 现象:初期创建容器时未按 "docker-hadoop - 学号" 命名,后续截图不符合实验三要求。
- 解决方法:停止并删除错误命名的容器(docker stop 容器名 && docker rm 容器名),按实验要求重新创建容器,确保容器名称包含完整学号,避免二次修改。
- 问题 2:DataNode 启动失败,jps未显示 DataNode 进程
- 现象:启动集群后,NameNode 正常运行,但 3 个 DataNode 均未启动,查看日志提示 "DataNode registration failed"。
- 解决方法:检查workers文件中 DataNode 容器名是否与实际创建一致(需严格匹配大小写和学号标识);删除所有 DataNode 的数据目录(rm -rf /usr/local/hadoop/datanode-data/*),重新格式化 NameNode 后启动集群。
- 问题 3:容器间网络不通,SSH 无法连接 DataNode
- 现象:执行ssh docker-hadoop-2023001-dn1时提示 "Name or service not known",容器间无法解析主机名。
- 解决方法:确认所有容器已加入同一自定义网络(docker network inspect hadoop-net-3查看容器列表);若未加入,执行docker network connect hadoop-net-3 容器名补加网络,确保容器间可通过名称解析 IP。
- 问题 4:HDFS Web 界面无法访问(localhost:9870打不开)
- 现象:集群启动成功,但本地浏览器无法访问 HDFS Web 界面,提示 "无法连接到服务器"。
- 解决方法:检查 NameNode 容器端口映射是否正确(创建容器时需包含-p 9870:9870);若端口映射缺失,停止容器并重新创建(需保留数据时可先备份目录);同时检查本地防火墙是否拦截 9870 端口,关闭防火墙后重试。
- (20%) 心得与感受。
实验三在实验二的基础上,新增了 "容器名称包含学号" 的特殊要求,同时延续 1 个 NameNode+3 个 DataNode 的集群配置,不仅巩固了 Docker 和 Hadoop 的核心知识点,更让我体会到 "规范操作" 在技术实践中的重要性。
实验初期,我因疏忽未按要求命名容器,导致需要重新创建容器并重复配置步骤,这让我意识到实验中的细节要求并非多余 ------ 包含学号的容器名称能让报告更具辨识度,也培养了严谨的操作习惯。在排查 DataNode 启动失败和网络不通的问题时,我学会了通过docker network inspect查看网络配置、通过 Hadoop 日志定位错误原因,逐步提升了问题排查的逻辑性和效率。
通过本次实验,我对 Docker 的容器化技术有了更深入的理解:自定义网络能有效避免容器间端口冲突,容器命名规范便于管理和识别,而docker cp命令则简化了多节点的配置同步工作,让分布式集群搭建变得高效且可复用。同时,我也进一步掌握了 Hadoop 集群的核心架构逻辑 ------NameNode 的元数据管理、DataNode 的数据存储、YARN 的资源调度三者协同工作,而副本数配置(设为 3)则能有效保障数据安全性,这些知识点在多节点部署中得到了充分验证。
相比前两次实验,实验三更注重操作规范性和结果可验证性,这与实际工作场景高度契合 ------ 实际项目中,服务器命名、配置文件规范、日志排查都是必备技能。这次实验不仅提升了我的动手操作能力,更让我明白技术实践既要追求 "实现功能",也要注重 "规范高效"。
未来,我会尝试在该集群中部署实际的大数据处理任务(如 WordCount),进一步验证集群的可用性;同时深入学习 Docker Compose 等容器编排工具,探索更高效的集群部署方式,为后续学习更复杂的分布式系统(如 Spark 集群)打下坚实基础。