1.ananconda的安装
(1)群里面先下载安装包
安装链接如下
https://blog.csdn.net/qq_55106902/article/details/147308606?ops_request_misc=elastic_search_misc&request_id=f043e7a7539bb0b3247e2e4fd7497467&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-147308606-null-null.142^v102^pc_search_result_base9&utm_term=anaconda%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
(2)创建虚拟环境
python
conda create -n yolo513 python=3.10 -y(3)虚拟环境的激活
python
conda activate yolo5132.pycharm的安装
(1)下载安装包
Other Versions - PyCharm
(2)pycharm破解
#######可以私信我,看见给发 2元######
3.下载yolo官方的代码
(1)下载代码
ultralytics/ultralytics: Ultralytics YOLO 🚀
4.torch配置环境
(1)查看自己电脑适合哪个版本的torch
python
nvidia-smi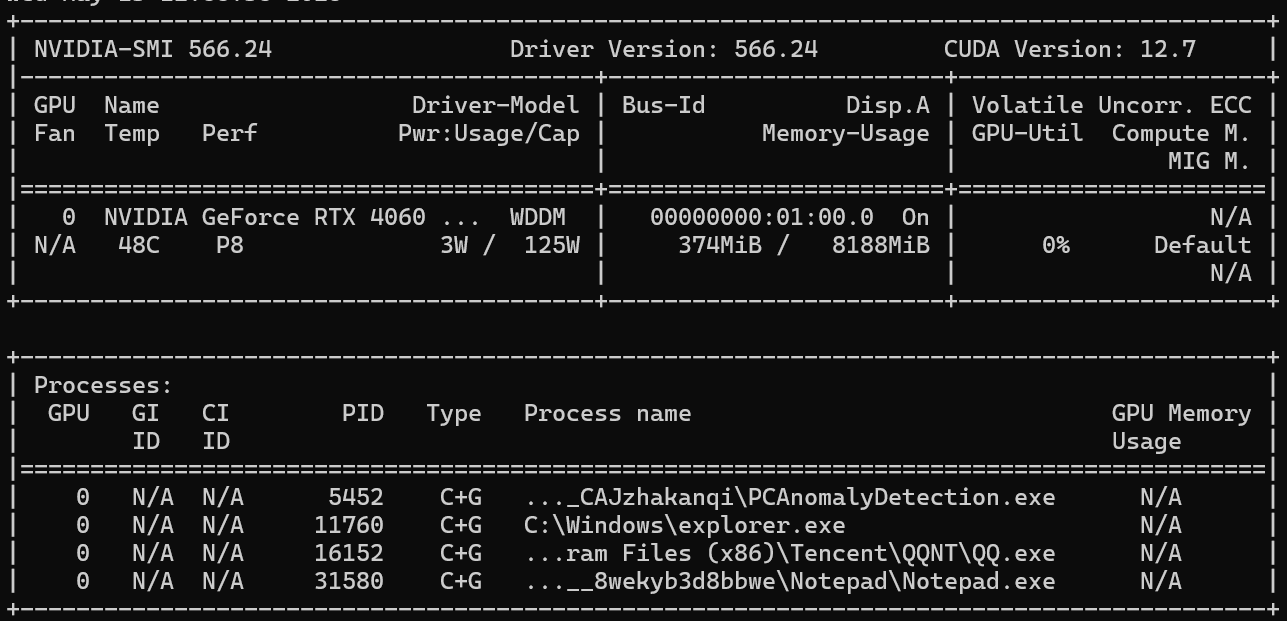
(2)到torch官网找到对应版本的torch下载
有独立显卡的话可以去官网下载GPU版本
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia 或者 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
没有独立显卡的话CPU版本的也是可以的
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 cpuonly -c pytorch
验证GPU是否可用
python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'CPU')"
安装其他库
python
pip install -U ultralytics
pip install tqdm
pip install pandas
pip install seaborn5. 数据集准备

测试集、训练集、验证集
我这有个动物的数据集都可以打包发你,
数据标注工具:ROboflow
6.train文件
python
from ultralytics import YOLO, RTDETR
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
# 加载模型
# model = YOLO('E:/ultralytics/ultralytics/cfg/models/11/yolo11-IAT.yaml')
# model.load('E:/ultralytics/ultralytics/cfg/models/11/best.pt')
#
# # 训练模型
# model.train(
# # data="data/data.yaml", # 数据集 YAML 路径
# # epochs=100, # 训练轮次
# # imgsz=640, # 训练图像尺寸
# # device="cpu", # 运行设备,例如 device=0 或 device=0,1,2,3 或 device=cpu
# data='data/data.yaml', epochs=400, imgsz=640, batch=4, workers=2
# )
#中断后接着运行
# model = YOLO("runs/detect/train3/weights/last.pt")
# model.train(resume=True)
# 评估模型在验证集上的性能
# metrics = model.val()
# 在图像上执行对象检测
# results = model("path/to/image.jpg")
# results[0].show()
model = YOLO(model=r'D:\ultralytics-main\ultralytics\cfg\models\11\yolo11.yaml')
#model.load('yolo11n.pt')
model.train(data='E:/ultralytics/data/data.yaml', epochs=300, batch=8, imgsz=640, workers=1, cache=False,
optimizer='SGD', amp=True, project='runs/train', name='yolo12')主要参数
| 参数 | 含义 | 备注 |
|---|---|---|
| train | 数据集配置文件路径,通常是 .yaml 文件 |
|
| epochs | 训练轮数 | 200 |
| batch | 每次送入模型训练的图片数量,也叫批大小 | 2 |
| imgsz | 输入图片尺寸,训练前图片会被缩放到该尺寸附近 | 640 |
| workers | 数据加载线程/进程数量 | 1 |
| cache | 是否缓存数据集,加快后续读取 | False 表示不缓存,节省内存/硬盘,但训练读取可能慢一些 |
| optimizer | 优化器,决定模型参数如何更新 | 'SGD' 表示使用随机梯度下降优化器 |
| amp | 自动混合精度训练,使用 FP16/FP32 混合计算 | True 表示开启,通常能加快训练并减少显存占用 |
| project | 训练结果保存的根目录 | 'runs/train' 表示结果保存在 runs/train 下 |
| name | 本次实验的文件夹名 | 'yolo12'表示结果目录大概率是runs/train/yolo12 |
主要文件说明
data.yaml
path: . #表示当前目录 train: data/train/images val: data/valid/images test: data/test/images nc: 10 names: ['cat', 'chicken', 'cow', 'dog', 'fox', 'goat', 'horse', 'person', 'racoon', 'skunk']
这两种yaml结构都可以
# dataset path train: E:\fuxian\ultralytics\data\images\train val: E:\fuxian\ultralytics\data\images\val test: E:\fuxian\ultralytics\data\images\test # number of classes nc: 10 # class names names: ['cat', 'chicken', 'cow', 'dog', 'fox', 'goat', 'horse', 'person', 'racoon', 'skunk']
yolo11.yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license # Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs # Model docs: https://docs.ultralytics.com/models/yolo11 # Task docs: https://docs.ultralytics.com/tasks/detect # Parameters nc: 80 # number of classes scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs # YOLO11n backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10 # YOLO11n head head: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 13], 1, Concat, [1]] # cat head P4 - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 10], 1, Concat, [1]] # cat head P5 - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large) - [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)