一、研究背景
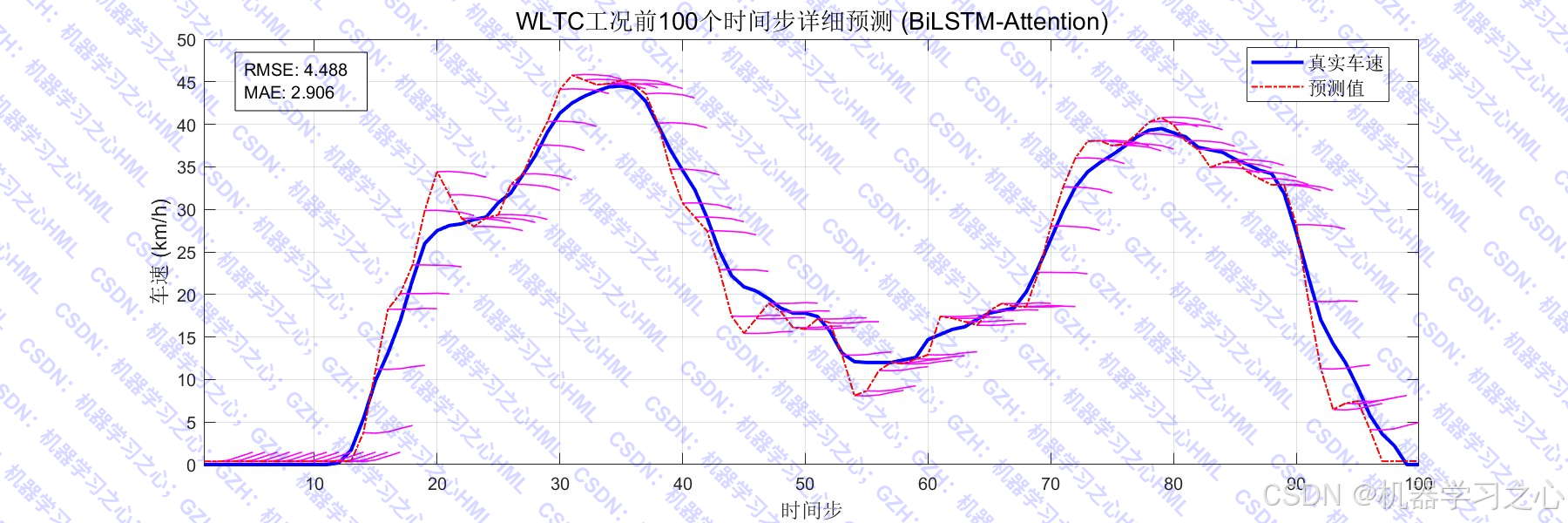
车辆速度预测是智能交通系统、新能源汽车能量管理、驾驶辅助系统等领域的关键技术。传统方法(如马尔可夫链、ARIMA)难以捕捉复杂的时间依赖性和非线性特征。近年来,深度学习模型(如LSTM、BiLSTM、Attention机制)在时间序列预测中表现优异。本代码基于 BiLSTM + 自注意力机制,实现对不同驾驶工况(如NEDC、UDDS、WLTC)下车速的多步预测。
二、主要功能
- 多工况数据加载:支持多个标准驾驶循环(中国城市、HWFET、LA92、US06、JC08、CLTCP、UDDS、NEDC、WLTC)。
- BiLSTM-Attention网络构建与训练:自动构建深度学习网络并进行训练。
- 车速多步预测 :使用历史
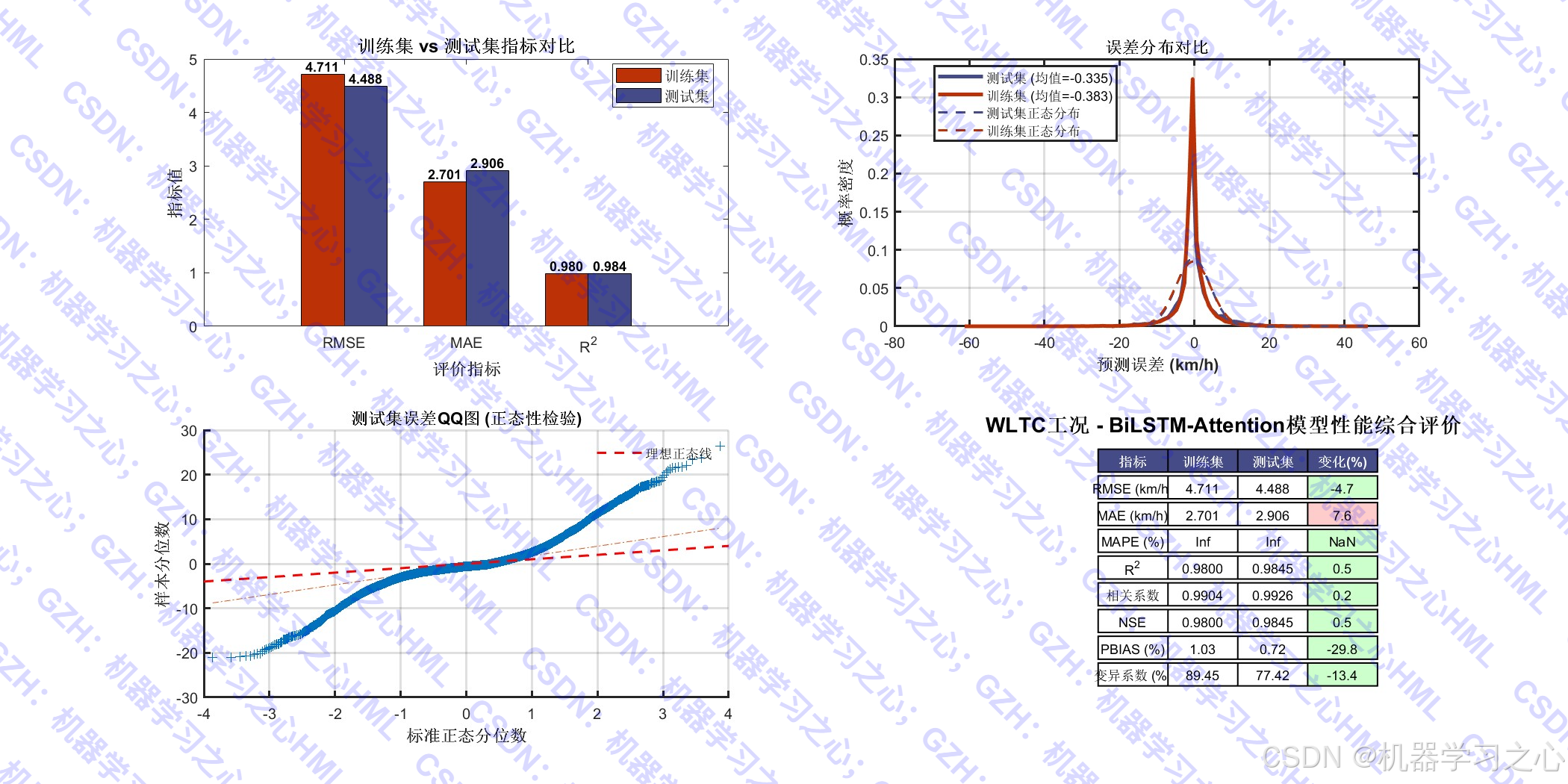
d个时间步的车速,预测未来p个时间步的车速。 - 模型评估:计算多种评价指标(RMSE、MAE、MAPE、R²、NSE、PBIAS、sMAPE、NRMSE等)。
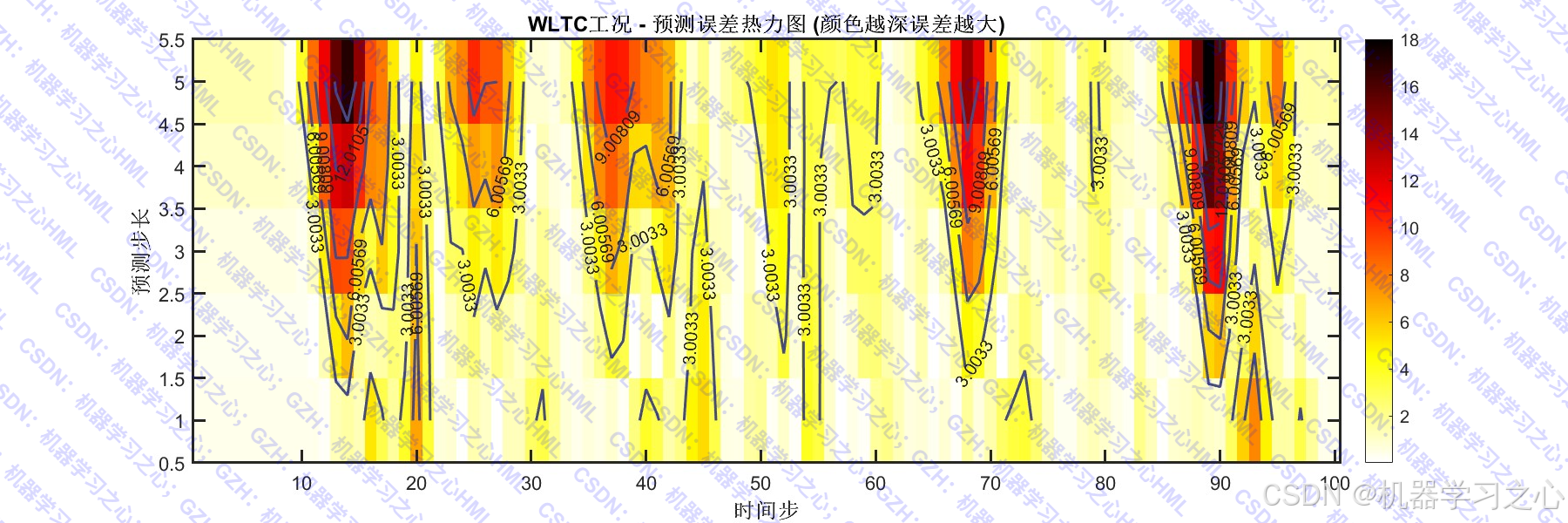
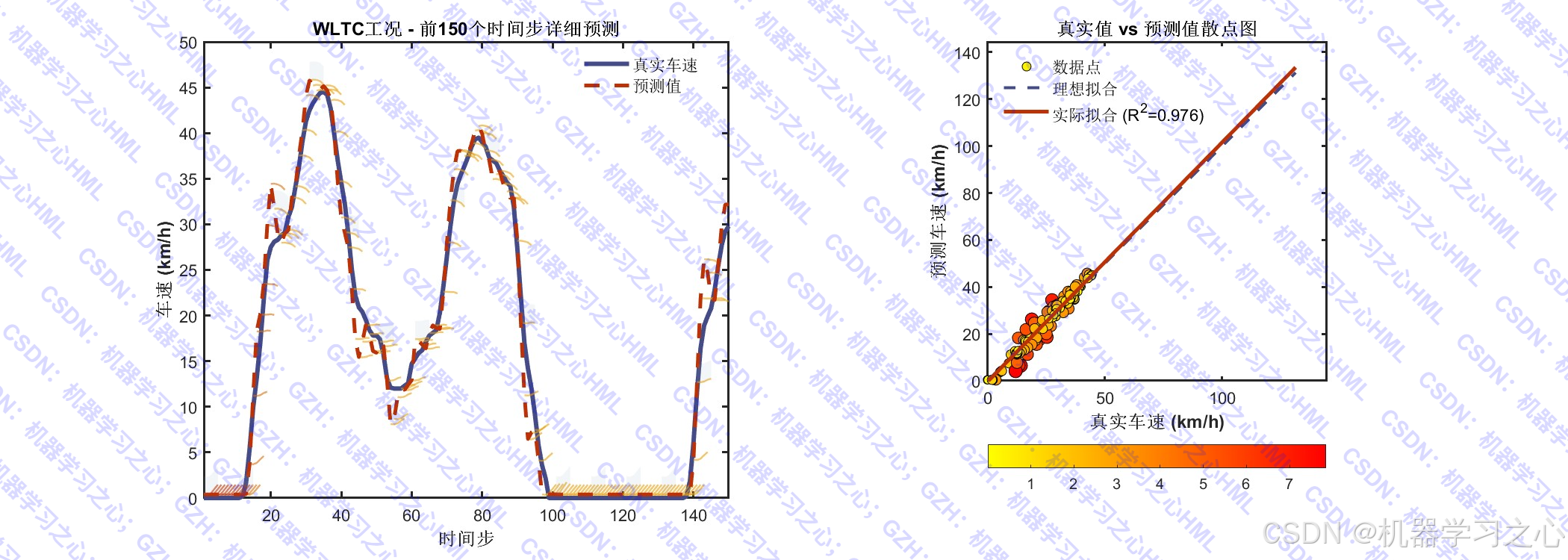
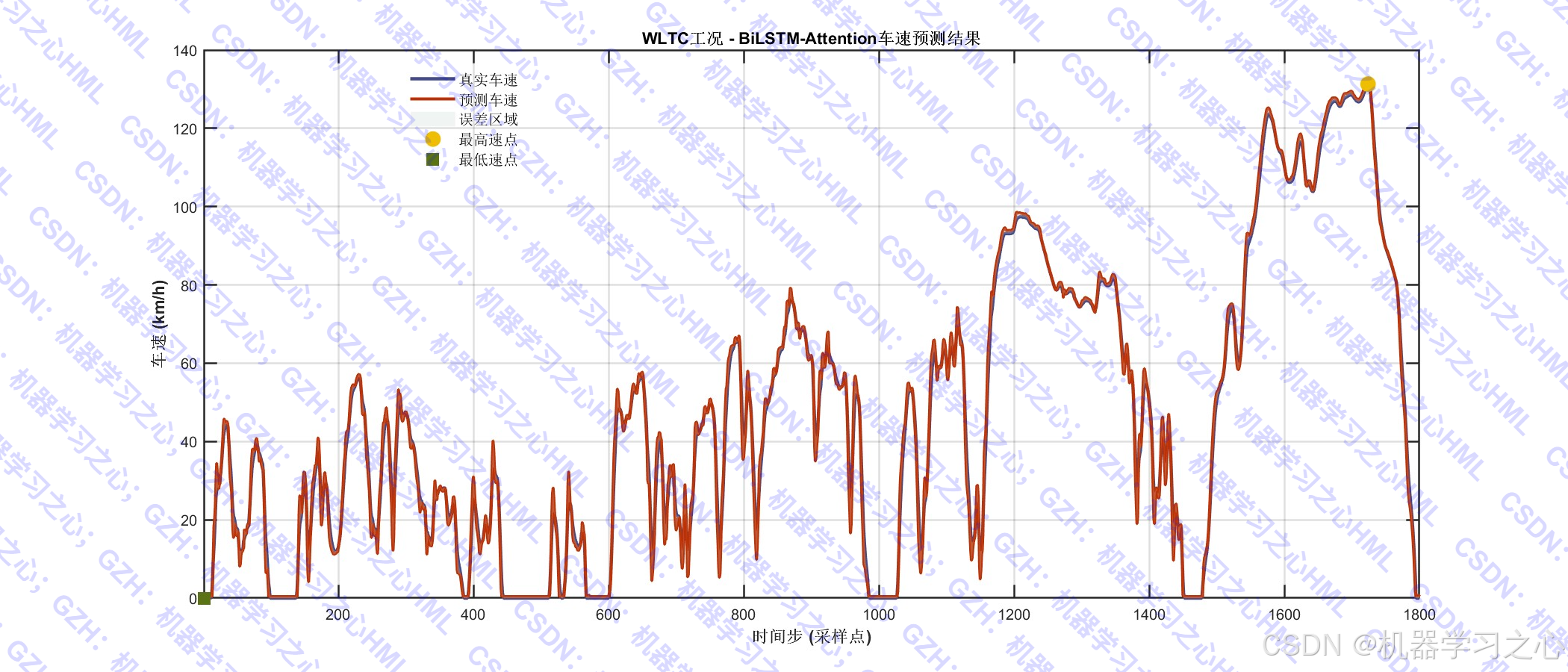
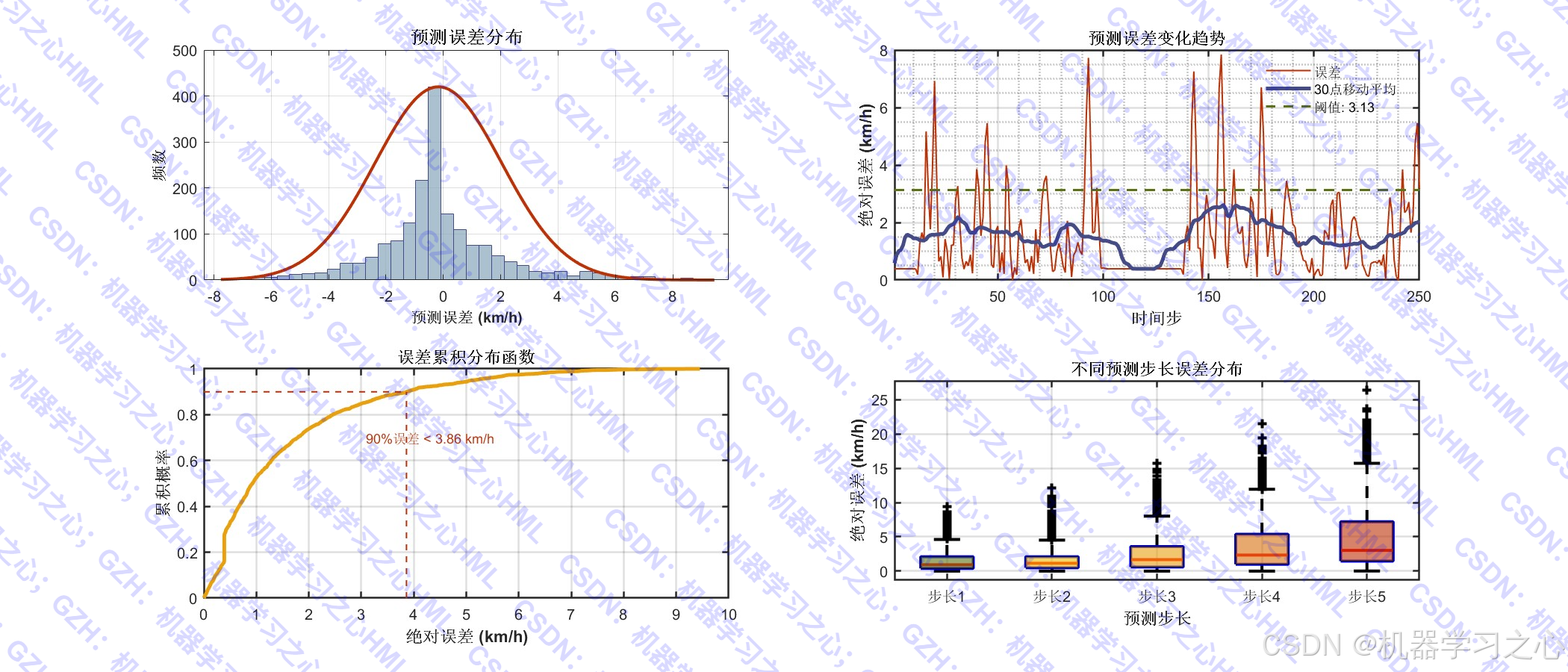
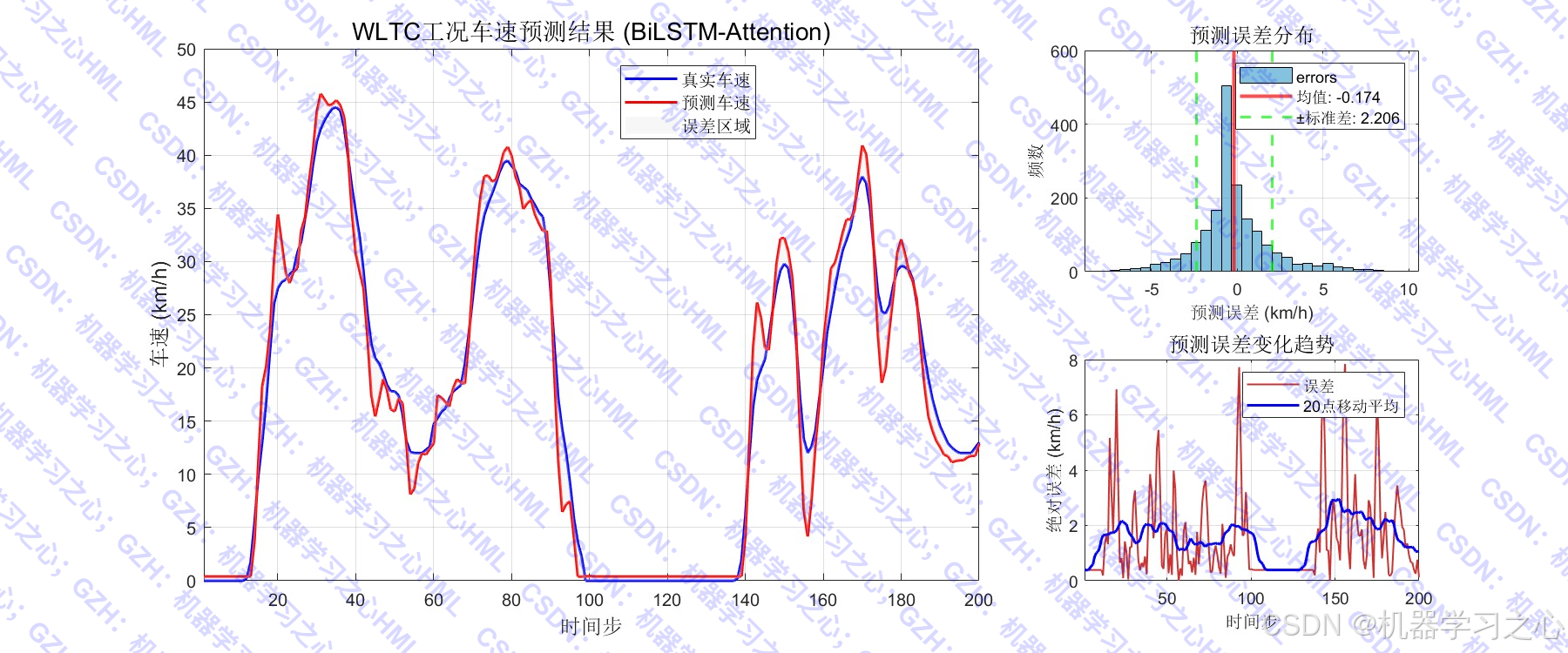
- 可视化分析:绘制预测结果、误差分布、散点图、热力图、QQ图、残差自相关图、指标对比表格等。
- 防止过拟合分析:训练集与测试集指标对比,评估模型泛化能力。
三、算法步骤
- 数据准备 :
- 加载多个工况数据,拼接成训练集。
- 根据
work_condition选择测试工况(NEDC / UDDS / WLTC)。
- 构造输入输出样本 :
- 使用滑动窗口生成训练样本:输入为
d个历史车速,输出为p个未来车速。
- 使用滑动窗口生成训练样本:输入为
- 数据归一化 :
- 使用
mapminmax将输入输出归一化到 0, 1。
- 使用
- 构建BiLSTM-Attention网络 :
- 输入层 → BiLSTM层 → 自注意力层 → 全连接层 → ReLU → 全连接层 → 回归层。
- 训练网络 :
- 使用 Adam 优化器,训练 100 个 epoch,学习率衰减策略。
- 预测 :
- 对测试集进行多步预测。
- 反归一化与误差计算 :
- 恢复原始量纲,计算多项误差指标。
- 可视化与结果保存 :
- 绘制多个对比图,保存模型评估结果。
四、技术路线
text
数据加载 → 滑动窗口构造样本 → 归一化 → BiLSTM-Attention网络构建 → 训练 → 预测 → 反归一化 → 评估 → 可视化- BiLSTM:捕捉前后向时序依赖。
- Self-Attention:关注关键时间步的特征。
- Adam优化:自适应学习率,加速收敛。
- Mini-batch训练:提高训练效率。
五、公式原理
1. BiLSTM单元(前向+后向)
- 前向LSTM:
ht(f)=LSTM(xt,ht−1(f)) h_t^{(f)} = \text{LSTM}(x_t, h_{t-1}^{(f)}) ht(f)=LSTM(xt,ht−1(f)) - 后向LSTM:
ht(b)=LSTM(xt,ht+1(b)) h_t^{(b)} = \text{LSTM}(x_t, h_{t+1}^{(b)}) ht(b)=LSTM(xt,ht+1(b)) - 输出:
Ht=ht(f);ht(b) H_t = h_t\^{(f)}; h_t\^{(b)} Ht=ht(f);ht(b)
2. 自注意力机制(Self-Attention)
- 输入:BiLSTM输出序列 H∈RT×dH \in \mathbb{R}^{T \times d}H∈RT×d
- 计算查询、键、值:
Q=HWQ,K=HWK,V=HWV Q = H W_Q, \quad K = H W_K, \quad V = H W_V Q=HWQ,K=HWK,V=HWV - 注意力权重:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dk QKT)V
3. 损失函数(回归层)
- 均方误差(MSE):
Loss=1N∑i=1N(yi−y^i)2 \text{Loss} = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 Loss=N1i=1∑N(yi−y^i)2
4. 评价指标示例
- RMSE :
RMSE=1N∑i=1N(yi−y^i)2 \text{RMSE} = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2} RMSE=N1i=1∑N(yi−y^i)2 - MAPE :
MAPE=100%N∑i=1N∣yi−y^iyi∣ \text{MAPE} = \frac{100\%}{N} \sum_{i=1}^{N} \left| \frac{y_i - \hat{y}_i}{y_i} \right| MAPE=N100%i=1∑N yiyi−y^i
六、参数设定
| 参数 | 值 | 说明 |
|---|---|---|
d |
5 | 输入序列长度(历史车速点数) |
p |
5 | 输出序列长度(预测步数) |
numHiddenUnits |
100 | BiLSTM隐藏单元数 |
numHeads |
4 | 自注意力头数 |
numKeyChannels |
128 | 注意力键通道数 |
MiniBatchSize |
64 | 批量大小 |
MaxEpochs |
100 | 最大训练轮数 |
InitialLearnRate |
0.01 | 初始学习率 |
LearnRateSchedule |
piecewise | 分段衰减策略 |
LearnRateDropPeriod |
50 | 每50轮衰减一次 |
LearnRateDropFactor |
0.5 | 学习率衰减因子 |
七、运行环境
- 软件:MATLAB2020
- 数据集 :需包含
.mat文件(如China_urban.mat,UDDS.mat等)
八、应用场景
| 场景 | 说明 |
|---|---|
| 新能源汽车能量管理 | 预测未来车速,优化电池/发动机功率分配 |
| 智能驾驶辅助系统 | 预测前车速度变化,提前调整本车速度 |
| 交通流预测 | 用于城市或高速路段的车速预测,辅助交通调度 |
| 驾驶行为分析 | 分析不同工况下的驾驶模式,用于驾驶员行为评估 |
| 仿真测试 | 在虚拟环境中预测车辆速度,用于控制器测试与验证 |