ITIL体系的配置管理基石,开源CMDB领域的标杆之作,腾讯蓝鲸生态的数据底座。
一、引言:痛点与场景
随着企业IT架构日趋复杂,服务器、数据库、中间件、网络设备数量持续膨胀,运维团队面临的核心困境是:看不清自己管了什么。配置信息散落在表格、文档、记忆里,变更靠吼、故障时资产信息对不上,是大多数运维团队的真实写照。
CMDB(Configuration Management Database,配置管理数据库)正是为解决这一痛点而生。它是企业IT管理体系的核心,记录所有IT资产(服务器、网络设备、应用组件)之间的关联关系和属性信息,是构建运维自动化、监控、故障定位乃至AIOps的数据基石。
腾讯蓝鲸团队开源的 bk-CMDB(BlueKing CMDB) 是国内最成熟的CMDB实现之一。它不仅服务于腾讯内部数万量级的主机规模,也在数千家企业落地,被视为开源CMDB领域的标杆作品。
▲ 图1:蓝鲸配置平台首页界面,包含主机搜索、导航菜单(首页/业务/资源/模型/运营分析)
二、项目简介
bk-CMDB是腾讯蓝鲸智云体系的核心组件,定位为面向应用的配置管理平台。它与业界传统CMDB最大的区别在于:以应用视角组织IT资源,将主机、进程、模块、业务之间的拓扑关系纳入统一管理,而非简单做一个资产清单库。
核心信息一览:
| 属性 | 内容 |
|---|---|
| 开源协议 | MIT,商用无限制 |
| 编程语言 | Go(后端)+ Vue.js(前端) |
| 架构风格 | 四层微服务架构 |
| 最新版本 | v3.2.19 |
| 源码仓库 | github.com/Tencent/bk-cmdb |
| 官方文档 | bk.tencent.com/docs |
| 在线体验 | https://cmdb-exp.bktencent.com/start(账号:admin 密码:admin) |
bk-CMDB与蓝鲸体系其他产品(bk-PaaS、bk-CI、bk-BCS等)深度集成,是蓝鲸生态的数据基础设施------其他平台需要查询主机归属、应用拓扑、进程配置时,都从CMDB获取数据。同时bk-CMDB也完全可以独立部署使用,不依赖蓝鲸其他组件。
三、系统架构
bk-CMDB采用四层微服务架构,从上到下依次为:Web层、接口层、服务层(场景层+资源管理层)、资源层(存储)。这种分层设计是CMDB领域少有的将"资源抽象"和"业务场景"明确分离的架构实践。
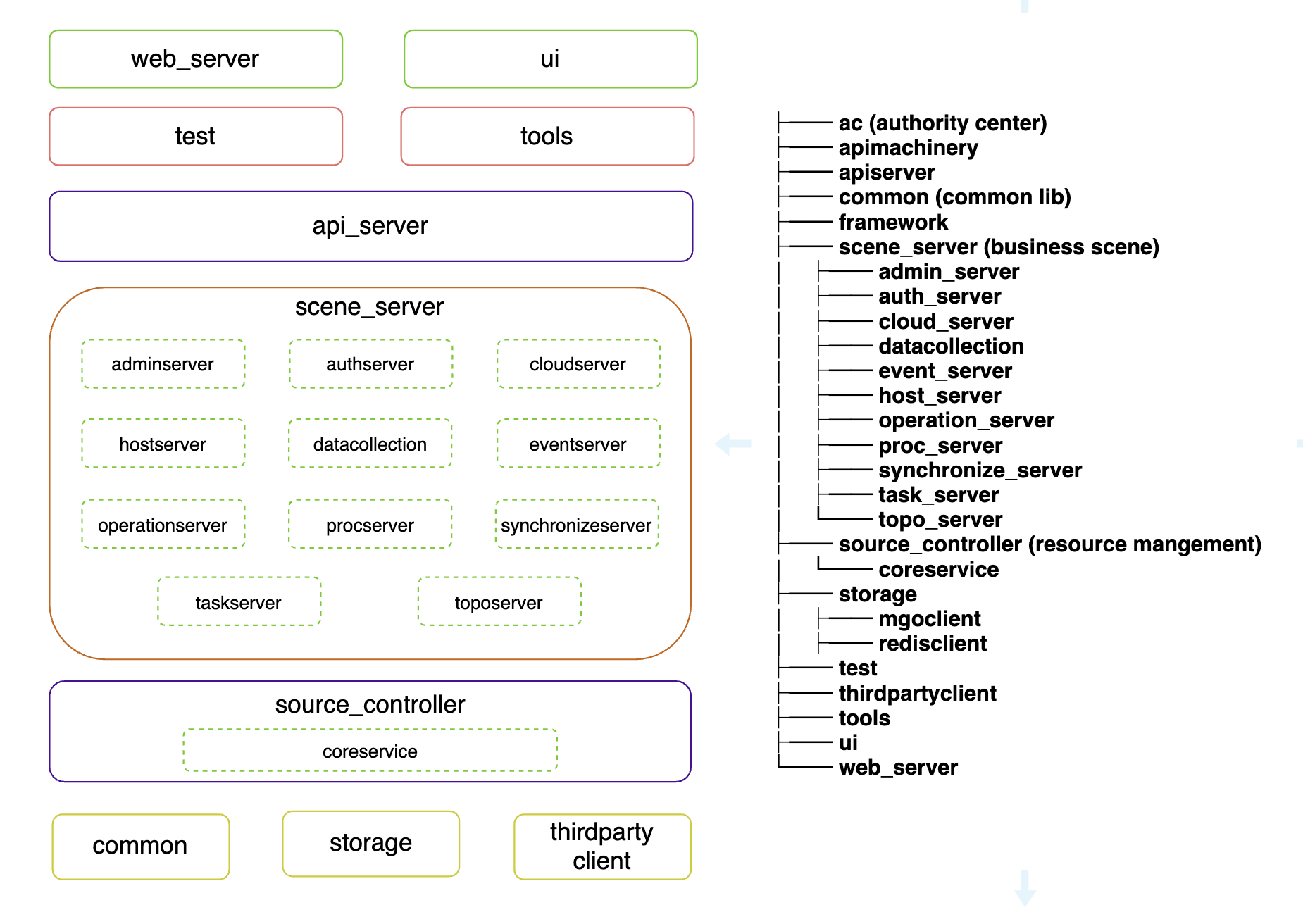
▲ 图2:bk-CMDB 微服务架构图与源码目录结构对照
第一层:Web层。 由 Web Server(Gin框架提供REST接口)和 Vue.js 前端组成,为用户提供可视化的配置管理界面。Web Server同时处理前端请求的路由和聚合,将请求转发给下游的场景服务。
第二层:接口层(API Server)。 基于Go-Restful框架构建,是整个系统的API网关。所有外部请求(Web前端、CLI工具、第三方系统集成)均通过API Server进入系统,接口层负责请求路由、参数校验、鉴权等通用处理。
第三层:服务层。 这是bk-CMDB最核心的设计亮点,分为两大模块:
场景服务(Scene Server) 是对业务操作场景的封装,每个场景服务职责单一、无状态、可独立部署。包括:host(主机管理)、topo(拓扑管理)、process(进程管理)、auth(权限认证)、event(事件订阅与推送)、cloud(云区域管理)、synchronize(数据同步)、operation(运营统计)等。场景服务之间无直接耦合,完全依赖资源层的原子接口。
资源管理服务(Resource Layer) 是架构的核心抽象层。bk-CMDB将所有管理的实体抽象为三类原子资源:主机(Host)、进程(Process)、通用对象(Common Object)。每个原子资源由独立的微服务(Source Controller)管理,提供增删改查的标准化原子接口。这种设计的精妙之处在于:场景服务中的任何业务操作,最终都是对若干原子资源的组合操作,当需要扩展新功能时,只需要开发新的场景服务,复用已有的资源管理接口即可。
第四层:资源层(Store)。 MongoDB作为主存储,保存所有配置数据;Redis提供缓存;ZooKeeper承担两项关键职责------作为配置中心 ,由Admin服务将配置推送至ZooKeeper,各微服务从本地读取;作为服务注册中心,各服务启动时自上报地址,ZooKeeper的Node Watch机制实时同步服务地址变化,保证系统高可用。
四、核心特性解析
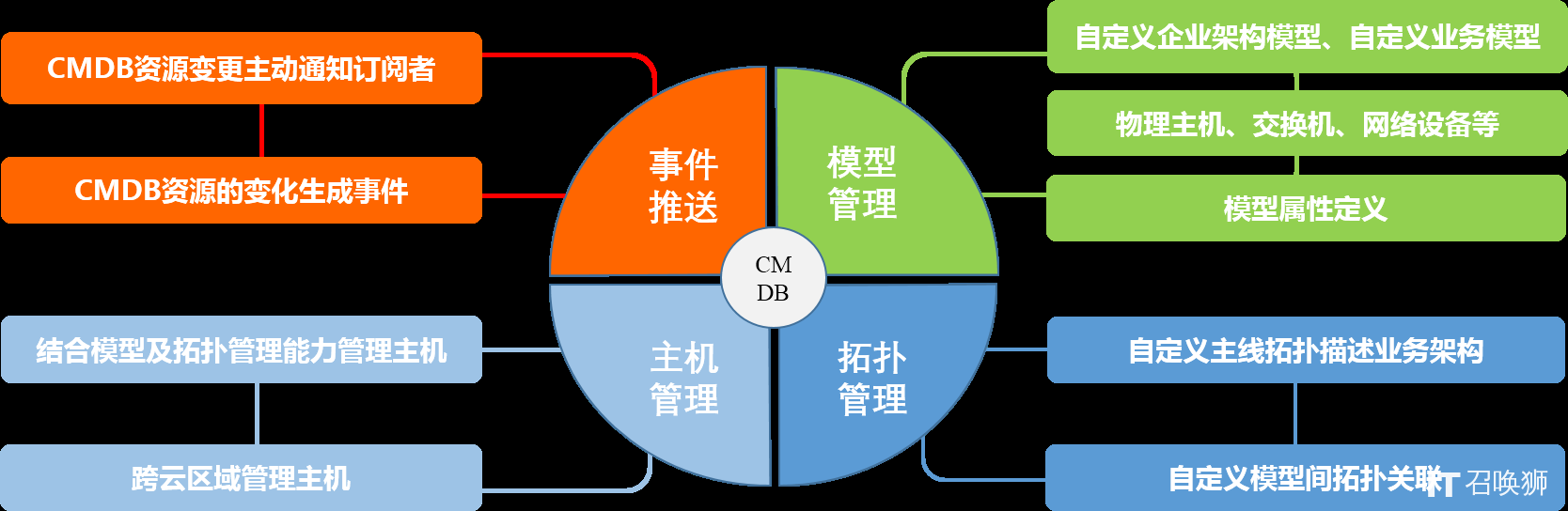
▲ 图3:bk-CMDB 四大核心功能模块:模型管理、拓扑管理、主机管理、事件推送
1. 拓扑化业务视图
bk-CMDB的核心差异化能力是以业务为中心的拓扑管理。传统的CMDB往往以资产为核心录入数据,而bk-CMDB将业务(Business)放在最顶层,其下是集群(Set),再下是模块(Module),模块与主机通过进程(Process)关联。这种层级关系天然映射了真实的应用架构:业务就是一个完整的对外服务,集群对应一个环境(如生产/测试),模块对应一个具体的服务组件,组件运行在哪些机器上、监听哪些端口,一目了然。
运维人员在故障定位时,可以从业务拓扑快速定位到具体是哪台主机、哪个进程出了问题,而不需要在资产表格里来回查找。拓扑视图也让容量规划、扩缩容决策变得直观可控。
2. 自定义模型:灵活扩展不设限
传统CMDB最被诟病的地方是"买来什么样就什么样",无法适应企业的个性化需求。bk-CMDB实现了完整的自定义模型管理能力:内置模型(主机、进程、业务、集群、模块)可以拓展属性;企业也可以新建完全自定义的对象类型,比如将"负载均衡器"、"证书"、"DNS记录"纳入CMDB管理,并定义这些对象与主机、进程之间的关联关系。
这种设计让CMDB从"厂商定义的资产清单"转变为"企业自己的配置数据库",真正解决了CMDB"建不起来"或"建起来没人用"的核心矛盾。
3. 主机快照:配置变更可追溯
主机快照(Host Snapshot)是bk-CMDB的一个实用功能,自动采集主机的实时运行状态(CPU核数、内存大小、磁盘挂载情况、网卡信息等)并存入数据库。每次变更(如虚拟机迁移、硬件升级)都会生成新的快照,历史变化轨迹可查。快照数据同时作为监控、作业平台的数据来源,实现CMDB与运维工具的联动。
4. 事件注册与推送
bk-CMDB提供了基于回调方式的事件订阅机制。下游系统(如监控平台、自动化运维平台)可以注册对特定数据变更事件的监听------例如"当某台主机的状态变为不可用时,触发告警"。数据变更通过事件服务(Event Server)主动推送给订阅方,无需轮询。这为构建CMDB驱动的自动化运维闭环提供了原生支持。
5. 精细化权限管理
bk-CMDB的权限体系基于用户组进行设计,管理员可以定义不同用户组对不同业务、主机、模型的访问和操作权限。权限控制粒度可以达到"某个用户组只能查看某几台主机的信息"级别,满足中大型企业的合规审计需求。
五、快速上手
bk-CMDB提供多种部署方式,从轻量到生产均可覆盖。
方式一:在线体验(推荐先体验)
无需部署,直接访问在线体验环境:
体验地址:https://cmdb-exp.bktencent.com/start
账号:admin
密码:admin方式二:Docker Compose 快速部署(开发测试用)
bash
# 克隆代码
git clone https://github.com/Tencent/bk-cmdb.git
cd bk-cmdb
# 使用容器化部署脚本(推荐 Ubuntu 20.04)
# 参考文档:docs/wiki/container-support.md方式三:标准安装部署(生产环境)
详细步骤参考官方文档,以下为核心依赖说明:
| 组件 | 版本要求 |
|---|---|
| Go | ≥ 1.21 |
| MongoDB | ≥ 3.6 |
| Redis | ≥ 3.2 |
| ZooKeeper | ≥ 3.4 |
编译源码后,通过官方安装脚本完成各微服务的配置和启动。生产环境建议使用Kubernetes Helm Chart部署,支持服务横向扩展。
官方部署文档:https://bk.tencent.com/docs/document/6.0/152/8128
六、实战演示:建立业务拓扑
以一个典型场景为例,说明bk-CMDB的核心操作流程:纳管一个包含Web集群和数据库集群的业务。
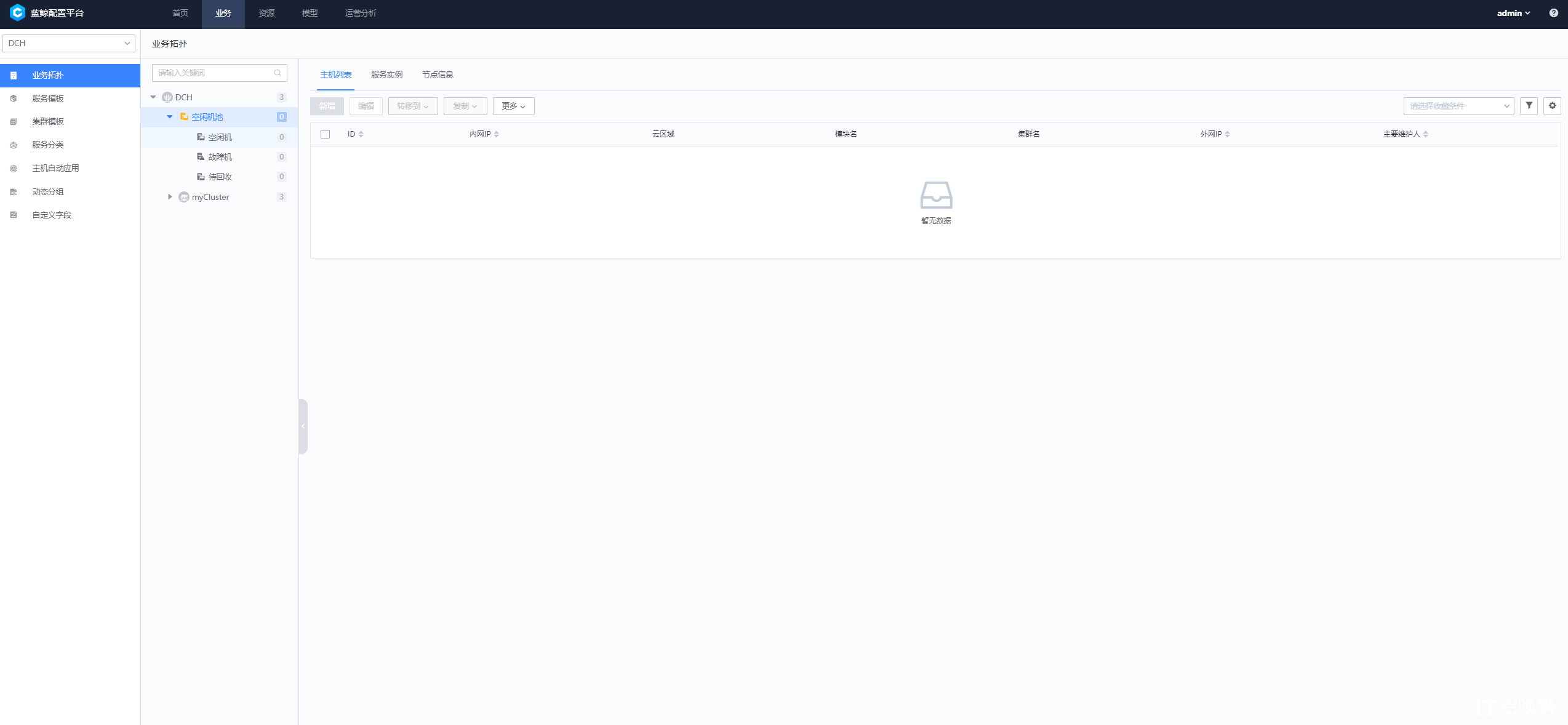
▲ 图4:bk-CMDB 业务拓扑管理界面,左侧为层级树状结构,右侧为主机列表
第一步:创建业务。 在CMDB中新建一个业务"电商平台",定义其运维负责人和所属部门。
第二步:创建集群和模块。 在"电商平台"下创建两个集群:生产集群(Set)和数据库集群(DB-Set)。在生产集群下创建两个模块:Nginx模块和App模块;在数据库集群下创建DB模块。
第三步:纳管主机。 将运行Nginx的3台机器和运行App的5台机器录入CMDB,填写主机IP、操作系统、所属云区域等信息。每台主机可关联一个或多个模块。
第四步:纳管进程。 在各主机上注册进程信息,如Nginx进程(监听80端口)、Java App进程(监听8080端口)。进程必须同时绑定主机和模块。
第五步:查看拓扑。 进入拓扑视图,可以清晰看到:电商平台 → 生产集群 → Nginx模块(3台主机) → 承载的Nginx进程,以及电商平台 → 数据库集群 → DB模块(X台主机) → DB进程。运维人员可以在此视图上直接操作------点击主机即可进入详情,点击进程即可查看端口和绑定关系。
七、技术亮点深度解析
基于资源抽象的分层架构
bk-CMDB的设计哲学可以概括为一句话:复杂业务场景皆可拆解为对简单资源的组合操作 。场景层服务(host、topo、process等)不直接操作数据库,而是调用资源层的原子接口;资源层服务(Source Controller)只负责对单一资源类型的标准化CRUD,不了解任何业务上下文。这种分层带来的最大好处是系统热更新:新增一个业务场景不需要修改资源层代码,只需要新增一个场景服务;新增一种资源类型只需要新增一个资源管理微服务,不影响现有服务。
这对运维系统的长期演进尤为重要------随着企业业务复杂度增加,CMDB需要不断适配新的资源类型和管理场景,架构的可扩展性直接决定了系统的生命力。
从腾讯内部走出来的工程实践
bk-CMDB不是实验室产物,它在腾讯内部经历了数万量级主机的实际验证。代码中随处可见对大规模场景的考虑:ZooKeeper的服务发现机制解决了一致性问题;MongoDB的文档模型天然适合配置数据的树状结构;各服务无状态设计支持蓝绿发布和金丝雀灰度。这些工程取舍不是教科书上的最优解,但是在腾讯的实际场景中被证明足够稳定、足够好用。
开源与蓝鲸生态的协同价值
虽然bk-CMDB可以独立使用,但它真正发挥威力是在蓝鲸生态中。蓝鲸PaaS提供统一的用户登录和权限体系,bk-CMDB作为数据底座向上游的监控、作业平台、标准运维提供配置查询和变更推送;蓝鲸CI/CD系统在发布时自动更新CMDB中的版本信息;蓝鲸SOPS在执行自动化流程时从CMDB读取目标主机列表。这种生态协同让CMDB从"建起来"变成"真正被用起来",而非沦为又一个"看起来很美但没人填数据"的系统。
八、相关资源
bk-CMDB 官方网站:
bk-CMDB 官方文档:
https://bk.tencent.com/docs/document/6.0/152/6945
bk-CMDB 在线体验:
https://cmdb-exp.bktencent.com/start
默认账号:admin 默认密码:admin
bk-CMDB GitHub 源码仓库:
https://github.com/Tencent/bk-cmdb
bk-CMDB 部署指南:
https://github.com/Tencent/bk-cmdb/blob/master/docs/overview/installation.md
本文由「IT召唤狮」整理发布,图片已添加版权水印,转载需授权。