告别内网模型接入烦恼!ModelStandardization:让 Dify、Open WebUI 无缝对接私有大模型
🚀 开源推荐 | 仅 3.8MB 的轻量级代理,一行命令解决内网大模型非标准 API 格式问题
📌 前言
大家好,我是爱学习的鱼佬 。今天给大家分享一个我开源的小工具------ModelStandardization。
项目地址: https://github.com/kingxzq/ModelStandardization
下载地址: https://github.com/kingxzq/ModelStandardization/releases/tag/v0.1.0
相信很多同学在企业内网部署大模型时都遇到过这样的问题:
内网模型返回的响应格式不标准,导致 Dify、Open WebUI 等工具无法正常接入!
比如内网模型会返回 system_fingerprint、service_tier、usage.completion_tokens_details 等非标准字段,这些字段会让严格的 OpenAI 客户端解析失败。
为了解决这个问题,我开发了 ModelStandardization------一个轻量级的 OpenAI API 格式标准化代理。
🎯 解决的问题
痛点场景
- Dify 接入内网模型失败:Dify 要求严格的 OpenAI 格式,非标准字段会导致 JSON 解析错误
- Open WebUI 无法连接:私有部署的模型接口返回多余字段,客户端不识别
- 多客户端兼容性差:每个客户端对格式的要求不同,适配成本高
ModelStandardization 的解决方案
┌──────────────┐ 标准 OpenAI 请求 ┌───────────────────────┐ 非标准请求 ┌──────────────┐
│ │ ──────────────────────────▶│ │ ────────────────▶│ │
│ Dify / │ │ ModelStandardization │ │ 内网大模型 │
│ Open WebUI │ ◀──────────────────────────│ (端口 8819) │ ◀────────────────│ │
│ │ 标准 OpenAI 响应 │ │ 非标准响应 │ │
└──────────────┘ └───────────────────────┘ └──────────────┘
自动剥离多余字段 ↑↓核心原理:在客户端和内网模型之间加一层代理,自动剥离非标准字段,对外暴露标准的 OpenAI API 接口。
✨ 功能特性
| 特性 | 说明 |
|---|---|
| ✅ 字段剥离 | 支持从请求和响应中剥离任意配置的字段 |
| ✅ 嵌套路径 | 支持点分隔的嵌套字段路径,如 usage.prompt_tokens_details |
| ✅ 流式支持 | 完整支持 SSE 流式响应的字段剥离 |
| ✅ 透明代理 | 对客户端完全透明,无需修改客户端代码 |
| 🚀 高性能 | 基于 Rust + Tokio,延迟 < 1ms |
| 📦 轻量级 | 二进制仅 3.8MB,完全静态链接 |
| 🔒 零依赖 | 不需要任何系统库,下载即用 |
🚀 快速开始
1. 下载
从 GitHub Releases 下载对应平台的二进制文件:
下载地址: https://github.com/kingxzq/ModelStandardization/releases/tag/v0.1.0
- Windows:
model-standardization-v0.1.0-windows-x64.zip(1.7MB) - Linux:
model-standardization-v0.1.0-linux-x64-musl.tar.gz(1.8MB)
2. 配置
编辑 config.toml:
toml
[server]
listen_address = "0.0.0.0"
listen_port = 8819
[upstream]
base_url = "http://192.168.1.100:8000" # 你的内网模型地址
api_key = "sk-xxx" # API Key(可选)
timeout = 300
[response]
# 需要从响应中剥离的字段
strip_fields = [
"system_fingerprint",
"service_tier",
"usage.completion_tokens_details",
"usage.prompt_tokens_details",
]
[request]
# 需要从请求中剥离的字段(可选)
strip_fields = []3. 启动
Linux/macOS:
bash
chmod +x model-standardization
./model-standardizationWindows:
cmd
model-standardization.exe启动成功输出示例:
[2026-06-03T04:36:21.439Z INFO model_standardization] ModelStandardization v0.1.0
[2026-06-03T04:36:21.439Z INFO model_standardization::config] Loaded config from C:\model-standardization-v0.1.0-windows-x64\config.toml
[2026-06-03T04:36:21.440Z INFO model_standardization] Upstream: http://127.0.0.1:8000
[2026-06-03T04:36:21.440Z INFO model_standardization] Response strip fields: ["system_fingerprint", "service_tier", "usage.completion_tokens_details", "usage.prompt_tokens_details"]
[2026-06-03T04:36:21.440Z INFO model_standardization] Request strip fields: []
[2026-06-03T04:36:21.440Z INFO model_standardization::server] ModelStandardization listening on 0.0.0.0:8819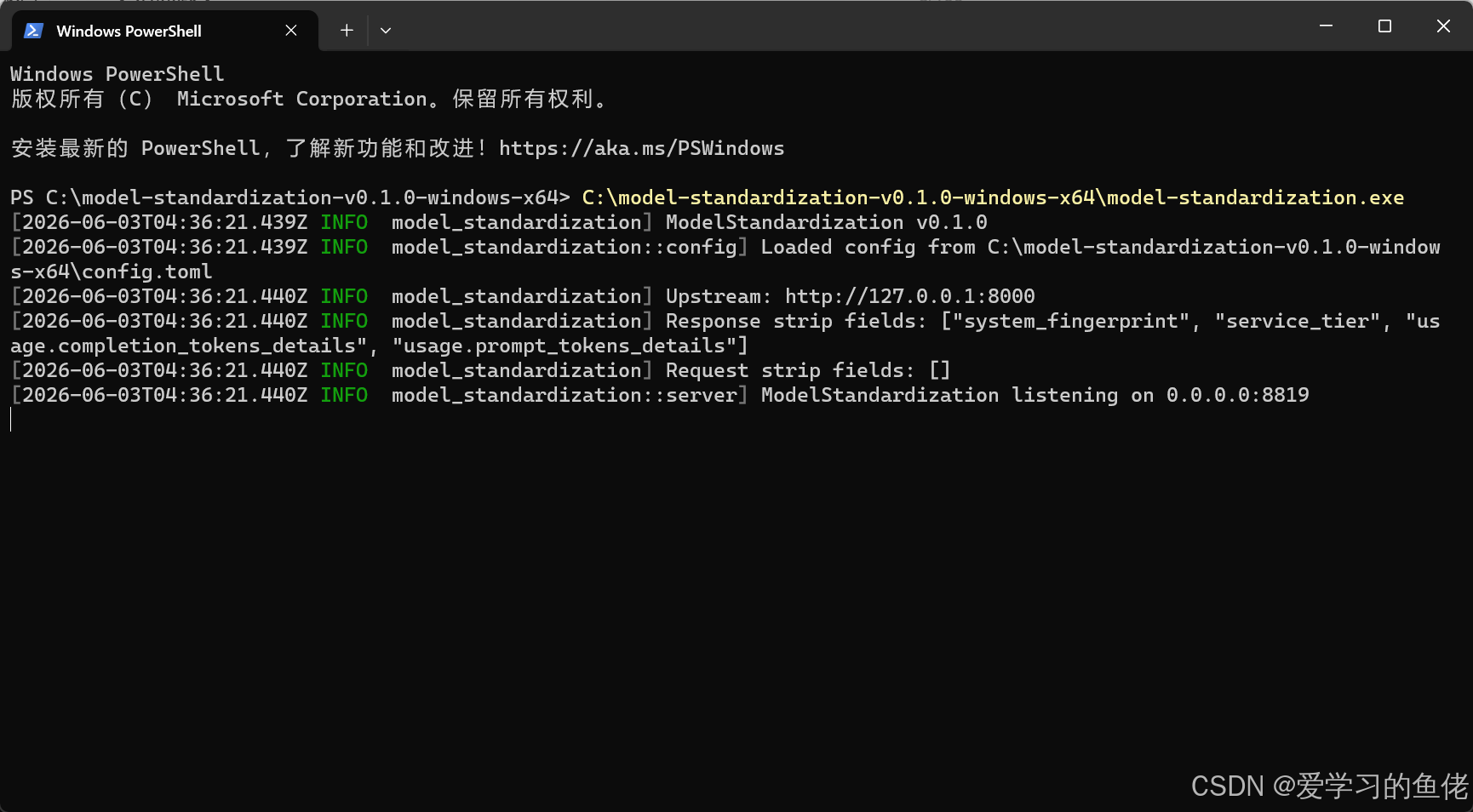
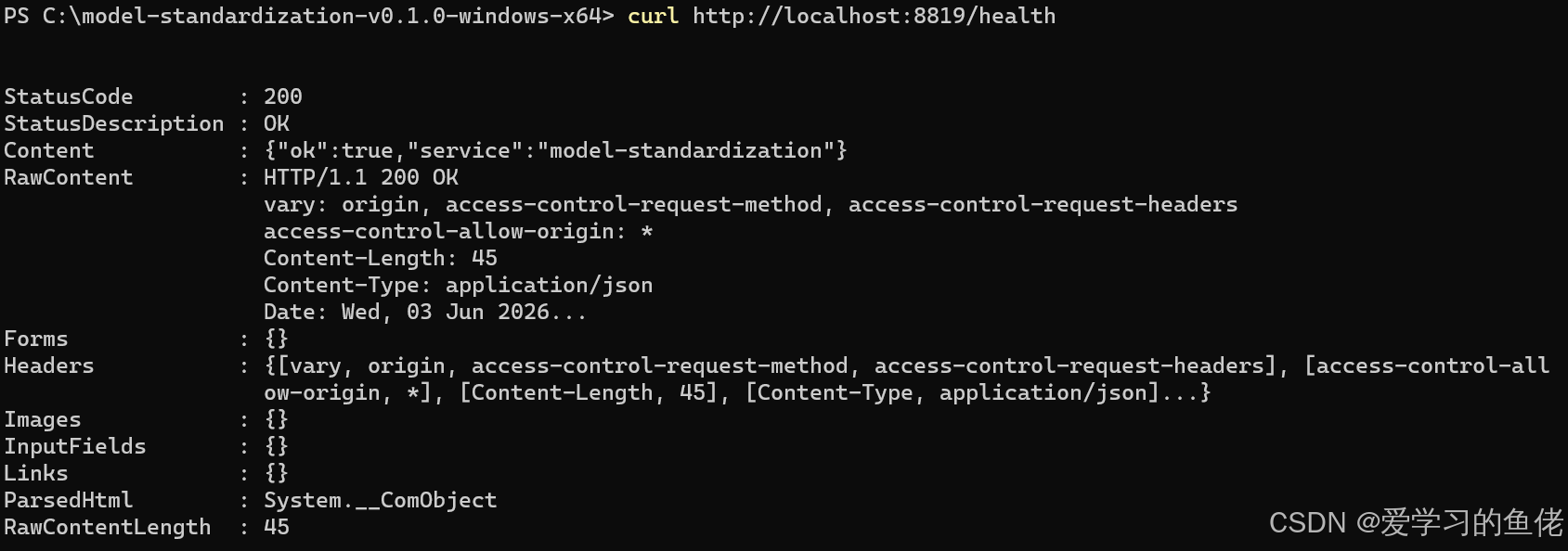
4. 验证
bash
# 健康检查
curl http://localhost:8819/health
# 返回: {"ok":true,"service":"model-standardization"}
# 测试请求
curl http://localhost:8819/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "your-model-name",
"messages": [{"role": "user", "content": "hello"}],
"stream": false
}'
🔧 实战:接入 Dify
步骤 1:启动 ModelStandardization
确保代理已经启动并运行在 http://your-server:8819
步骤 2:配置 Dify
在 Dify 的模型配置中:
- API Base URL :
http://your-server:8819/v1 - API Key: 填写你的内网模型 Key
- Model Name: 填写内网模型支持的模型名
步骤 3:测试对话
配置完成后,就可以在 Dify 中正常使用内网模型了!
📋 常见非标准字段
如果你不确定需要剥离哪些字段,可以参考下表:
| 字段路径 | 说明 | 常见于 |
|---|---|---|
system_fingerprint |
系统指纹标识 | OpenAI 兼容 API |
service_tier |
服务层级 | OpenAI 兼容 API |
usage.completion_tokens_details |
补全 token 详情 | OpenAI 兼容 API |
usage.prompt_tokens_details |
提示 token 详情 | OpenAI 兼容 API |
choices[].logprobs |
对数概率 | 部分模型 |
metadata |
自定义元数据 | 私有部署 |
request_id |
自定义请求 ID | 私有部署 |
如何确定需要剥离哪些字段?
- 直接请求你的内网模型,保存完整响应
- 对比 OpenAI 标准响应格式
- 找出多余的字段,添加到配置文件的
strip_fields中
🐳 Docker 部署
如果你喜欢使用 Docker,也可以快速部署:
Dockerfile:
dockerfile
FROM debian:bookworm-slim
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/lib/apt/lists/*
COPY model-standardization /usr/local/bin/
COPY config.toml /etc/model-standardization/
ENV CONFIG_PATH=/etc/model-standardization/config.toml
EXPOSE 8819
CMD ["model-standardization"]运行:
bash
docker build -t model-standardization .
docker run -d \
--name model-standardization \
-p 8819:8819 \
-v /path/to/config.toml:/etc/model-standardization/config.toml:ro \
model-standardizationDocker Compose:
yaml
version: '3.8'
services:
model-standardization:
image: model-standardization:latest
ports:
- "8819:8819"
volumes:
- ./config.toml:/etc/model-standardization/config.toml:ro
environment:
- RUST_LOG=info
restart: unless-stopped⚡ 性能表现
作为一个 Rust 编写的代理,性能表现非常优秀:
- 额外延迟: < 1ms(纯字段剥离操作)
- 内存占用: 启动约 2-5MB
- CPU 占用: 正常负载下 < 1%
- 并发支持: 基于 Tokio 异步运行时,支持数千并发连接
- 二进制大小: 仅 3.8MB,完全静态链接
🔍 技术实现
项目结构
ModelStandardization/
├── Cargo.toml # Rust 项目配置
├── config.toml # 配置文件
├── src/
│ ├── main.rs # 程序入口
│ ├── config.rs # 配置加载
│ ├── server.rs # HTTP 服务器
│ ├── handlers.rs # 请求处理
│ ├── transform.rs # 字段剥离
│ └── error.rs # 错误处理核心依赖
- Axum: Web 框架
- Tokio: 异步运行时
- Reqwest: HTTP 客户端
- Serde: 序列化框架
流式处理
对于流式请求(stream: true),使用 SSE 逐块处理:
- Channel-based 架构正确缓冲跨 TCP 块的不完整 SSE 行
- 逐行解析
data:前缀的 JSON 数据 - 对每个流式块独立执行字段剥离
- 正确处理
[DONE]终止信号
📖 更多文档
项目提供了完整的中英文文档:
- 中文文档: https://github.com/kingxzq/ModelStandardization/blob/main/README_CN.md
- English Docs: https://github.com/kingxzq/ModelStandardization/blob/main/README_EN.md
🤝 参与贡献
欢迎提交 Issue 和 Pull Request!
- Fork 项目: https://github.com/kingxzq/ModelStandardization/fork
- 创建功能分支
- 提交更改
- 推送到分支
- 创建 Pull Request
💬 常见问题
Q: 支持 HTTPS 吗?
当前仅支持 HTTP。如需 HTTPS,建议使用 Nginx 或 Caddy 作为反向代理。
Q: 如何查看详细日志?
bash
RUST_LOG=debug ./model-standardization # 调试日志
RUST_LOG=trace ./model-standardization # 完整请求/响应Q: 性能如何?
纯 Rust 实现,字段剥离操作在微秒级别完成,额外延迟 < 1ms。
Q: 支持哪些 OpenAI API 端点?
当前支持:
/v1/chat/completions- 聊天补全/v1/models- 模型列表/health- 健康检查
🎉 总结
ModelStandardization 是一个简单但实用的工具,专门解决内网大模型 API 格式不标准的问题。
核心优势:
- ✅ 轻量级:仅 3.8MB,下载即用
- ✅ 高性能:Rust 实现,延迟 < 1ms
- ✅ 易使用:一行命令启动
- ✅ 功能完整:支持流式、嵌套字段等
如果你也在为内网模型接入问题烦恼,不妨试试这个工具!
项目地址: https://github.com/kingxzq/ModelStandardization
下载地址: https://github.com/kingxzq/ModelStandardization/releases/tag/v0.1.0
如果觉得有用,欢迎 ⭐ Star 支持一下!
📝 关于作者
我是爱学习的鱼佬,一个热爱开源的开发者。
欢迎关注我的其他项目!
标签: 开源, 大模型, Dify, OpenAI, Rust, API代理, 内网部署, OpenWebUI