
让 Agent 写万字方案或代码审查报告,结果打开文件看到满屏的 ### 和用特殊字符硬凑的"颜色标注",瞬间失去阅读欲望?
随着 Agent 处理的任务日益复杂,作者在代码审查与架构规划等场景中已感受到 Markdown 格式的局限 。此时,输出格式的瓶颈早已不是"机器能否生成",而是**"人类能否高效消化"**。
最近,一线工程师 Thariq 在社区分享了一个反直觉的实践:在 Claude Code 工作流中,他几乎全面停用 Markdown,改用 HTML 作为 Agent 的主要输出格式。这个看似复古的前端技术,正在成为部分开发者的"信息带宽倍增器"。
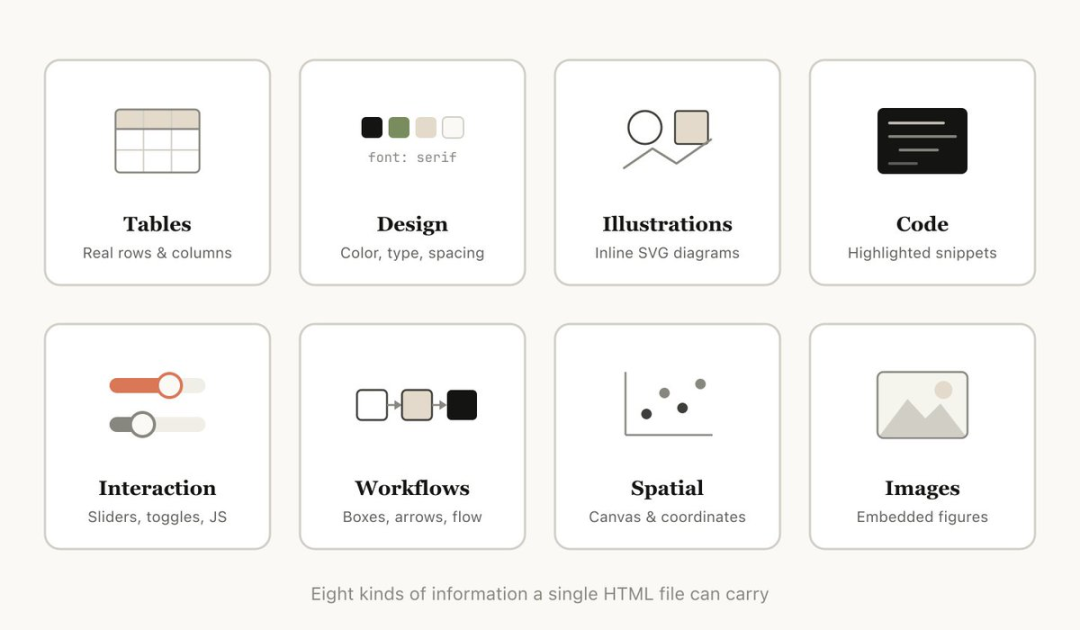
这听起来很美好,但工程上的账还是要算的。HTML 到底解决了什么真实痛点?延迟、成本和版本控制会付出什么代价?我们结合原文与社区反馈,拆解这次格式迁移的底层逻辑。
当长文超过 100 行:Markdown 为什么开始"催眠"?
Markdown 能统治开发者工作流,靠的是轻量、易读、易同步。但在 Agent 时代,它的优势正在变成短板。
当 Agent 输出的 PR 审查、架构规划或跨源报告超过百行时,纯文本的线性排版会让视觉疲劳呈指数级上升。更麻烦的是,模型为了在 Markdown 里做高亮或画流程图,经常被迫使用 ASCII 字符或 Unicode 符号硬凑排版。
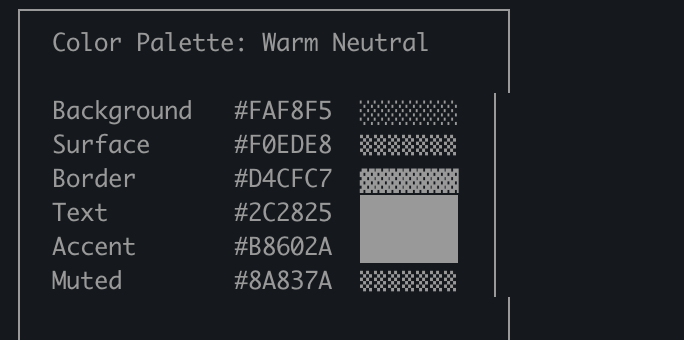
Markdown 的轻量优势在超百行长文档中正转变为可读性瓶颈与排版局限。
读这张截图时,重点看左侧:为了模拟颜色高亮和区块分割,Markdown 被迫堆砌了大量杂乱的控制字符;而右侧则是 HTML 原生的结构化呈现。这种对比直观展示了纯文本在复杂信息可视化时的表达瓶颈。
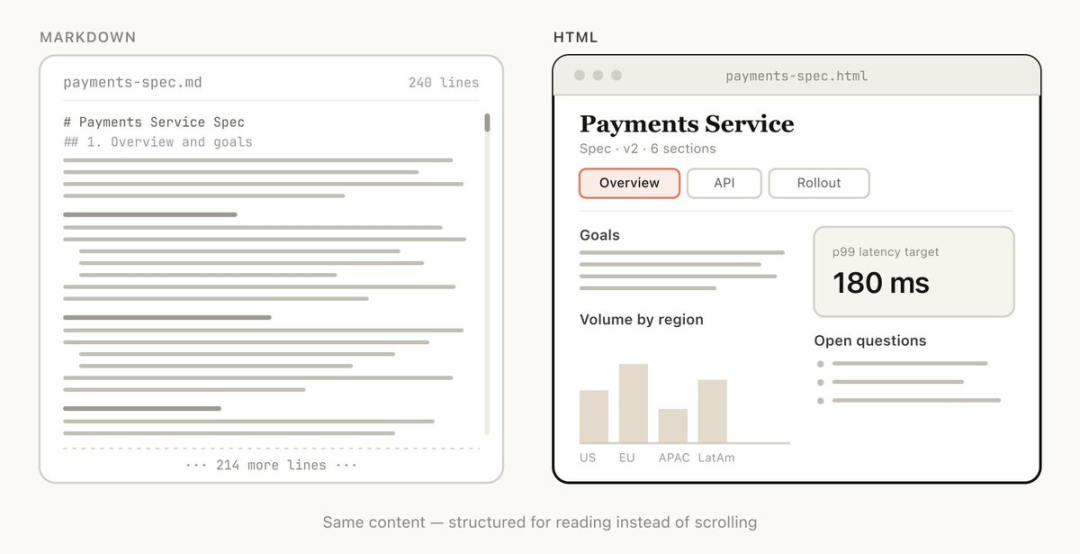
该素材支撑了原文的核心观察:作者认为,纯文本格式在长文档中的可读性下降会降低实际阅读与协作效率。但它仅展示了视觉维度,不能证明 HTML 在纯逻辑推理或轻量代码片段传递中同样占优。
降维打击:HTML 如何成为 Agent 的"富文本画布"?
如果把 Markdown 比作电报,HTML 就是一个自带控制台和仪表盘的网页。
作者指出,HTML 几乎能无损表达 Agent 能读取的任何信息集合。原生支持表格、CSS 网格布局、SVG 矢量图,甚至直接嵌入交互脚本。这意味着 Agent 不再只能"写文字",而是可以直接"排版"。
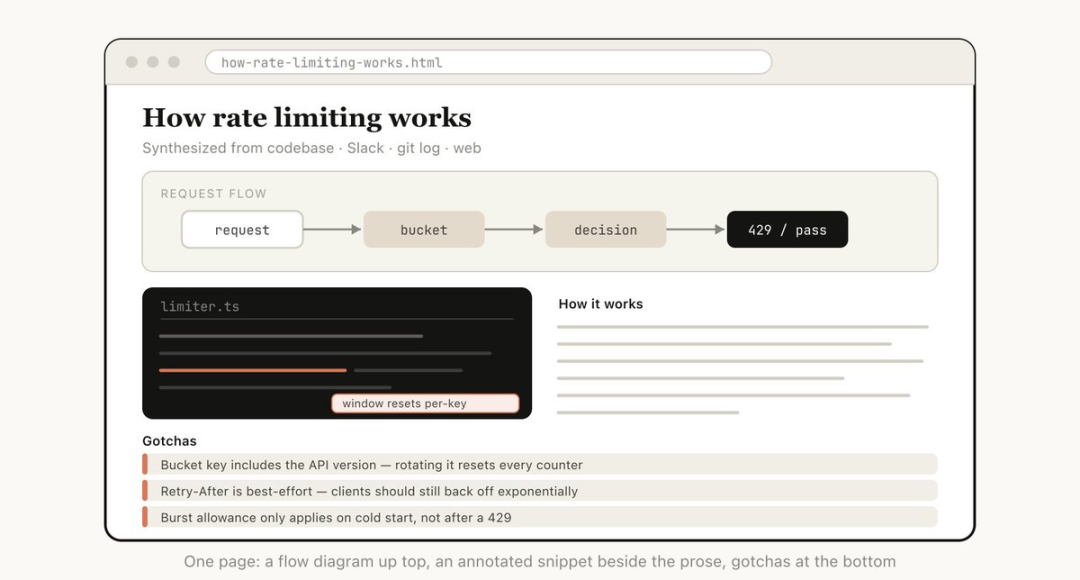
HTML 提供了远超 Markdown 的信息承载维度,且无需依赖特定解析器即可在任意浏览器中渲染。
更重要的是分享链路。Markdown 文件通常需要挂载到 Git 平台或专用编辑器才能良好预览;而 HTML 只需丢到 S3 或本地服务器,扔一个链接,团队内任何人打开即看。作者指出,相比附件 Markdown,通过链接分享 HTML 能提升团队的实际阅读意愿,但该结论目前为个人工作流经验,尚无跨团队量化数据支撑。
从单向输出到双向交互:让 UI 控件反哺 Prompt
HTML 最大的增量价值,不在于更好看,而在于能交互。
在传统的 Agent 工作流中,人类只能单向阅读输出,然后手动改 Prompt 重新生成。但在 HTML 里,Agent 可以生成滑块、表单、参数调节面板。你可以在网页上点选选项、拖拽排序,然后将最终配置"一键复制回 Prompt"。
这种"人类调整参数 -> 反馈配置 -> Agent 迭代"的闭环,将静态报告升级为可操作仪表盘。
注意这张图里的数据流向:UI 控件的输入结果被序列化为 JSON 或 Markdown 字符串,直接回填给 Claude Code。这背后依赖的是模型对前端代码的精准生成能力,以及本地文件系统或 MCP(模型上下文协议,让 AI 直接读取你的本地工具链)的上下文注入。
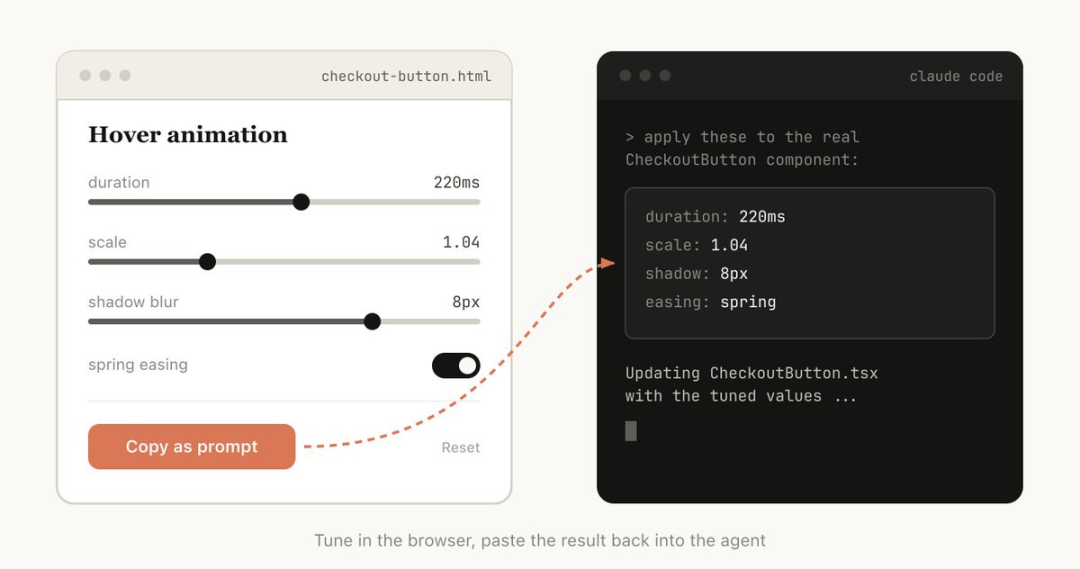
该截图验证了"HTML 支持双向人机协作"的工程可行性。但必须明确:交互功能并非 HTML 标签自动具备的魔法,而是高度依赖 Prompt 约束与模型的前端代码生成质量。
算一笔工程账:更快的渲染速度,更慢的生成延迟
切换格式必然伴随隐性成本。作者没有回避这些 trade-off。
首先,作者实测表明:HTML 的生成耗时约为 Markdown 的 2-4 倍。多出的标签、样式和脚本会拉长模型的推理时间,对实时性要求高的流水线并不友好。
其次,Token 开销。虽然 HTML 标签确实更费字,但在 Claude Opus 4.7(1M 上下文窗口)的尺度下,作者声称这部分额外 Token 占用"并不明显",其带来的表达力收益覆盖了边际成本。
最后,也是工程师最头疼的一点:HTML 在 Git 版本控制中会产生大量结构性标签噪声。 哪怕只改了一个段落,Diff 中会出现大量结构性标签变动,增加历史回溯与代码审查成本,体验远不如 Markdown 干净。
这把"尺子"不适合量什么?HTML 的适用边界
尽管作者在个人工作流中已全面转向 HTML,但将单一偏好泛化为工程最佳实践是危险的。 Markdown 在以下场景仍不可替代:
-
none !importantnone !importantCLI 环境与纯文本同步:在终端里
cat或vim查看时,Markdown 依然最高效。none !importantnone !important
-
none !importantnone !important轻量级代码审查与逻辑推理:当核心交付物是代码块而非排版文档时,Markdown 的专注度更高。none !important
none !important
-
none !importantnone !important非技术角色的源码审查:让产品或运营直接阅读 HTML 结构,可能会增加协作摩擦。none !important
none !important
-
none !importantnone !important模型能力边界:强依赖大模型的前端生成能力。若在能力较弱的开源小模型上直接输出 HTML,极易产生破碎的 DOM 结构。none !important
none !important
此外,HTML 方案高度依赖本地运行环境与预览工具链。在非标准开发终端、断网环境或弱提示词约束下,极易出现渲染失效或布局错乱。 读者需结合自身工程环境评估 ROI。
对开发者与 AI 协议的启发:下一步该期待什么?
这一实践迅速引起了社区关注。AI 研究者 Andrej Karpathy 公开附议,并提出了一个更具前瞻性的演进路径。
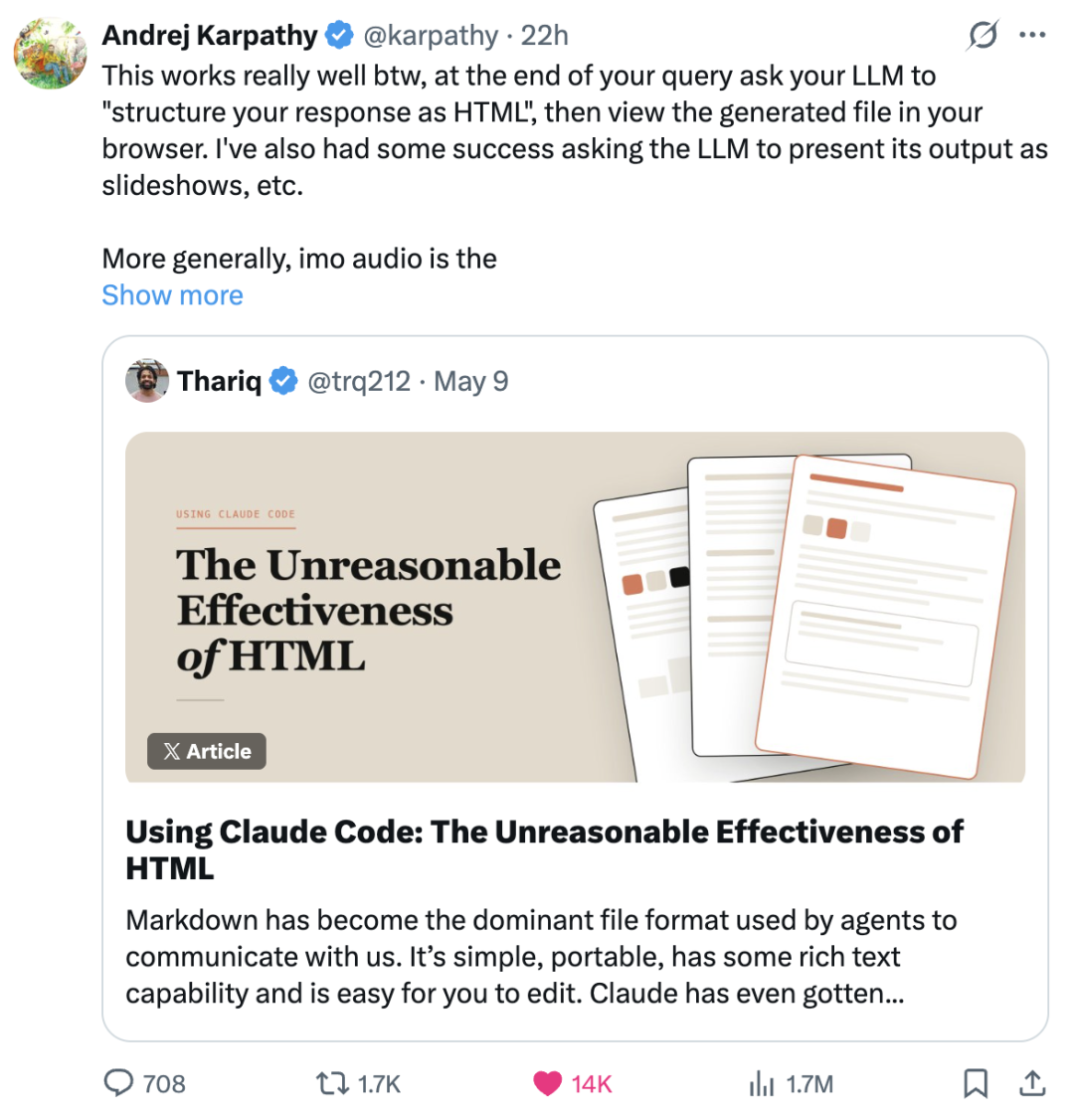
读这张引文卡片时,重点关注 Karpathy 对 AI 输出形态的阶段划分,以及他对 HTML 作为"早期但正在形成的新默认选项(new good default)"的定性判断。
该推文反映了社区对"富文本输出协议"的共识趋势。该评价属于对 AI 输出协议演进的阶段性观察,强调 HTML 正成为探索方向之一,并非已落地的工业标准或性能基准。
对研发者的直接启发在于:输出格式约束(Output Format Constraint)正在成为影响信息保真度的关键变量。 未来的模型微调或评估基准,可能需要专门针对结构化标记(HTML/XML)的语法正确率、上下文开销压缩以及富文本渲染一致性进行优化。
对一线开发者而言,不必急于重构现有工作流。更合理的做法是:在需要跨源汇总、参数调优或高层汇报的复杂场景中,尝试通过 Prompt 指定 output format: HTML;而在日常代码迭代与 Git 协作中,继续保留 Markdown 的轻量优势。
格式没有绝对的好坏,只有与当前人机协作带宽的匹配度。当 Agent 的输出越来越像一份"产品",用人类更熟悉的方式去交付,或许才是工程演进的下一步。
参考链接
标题:Using Claude Code: The Unreasonable Effectiveness of HTML