一、Qwen3-TTS语音克隆三合一工作流
1.三合一工作流包含三个子工作流:
1) 声音设计
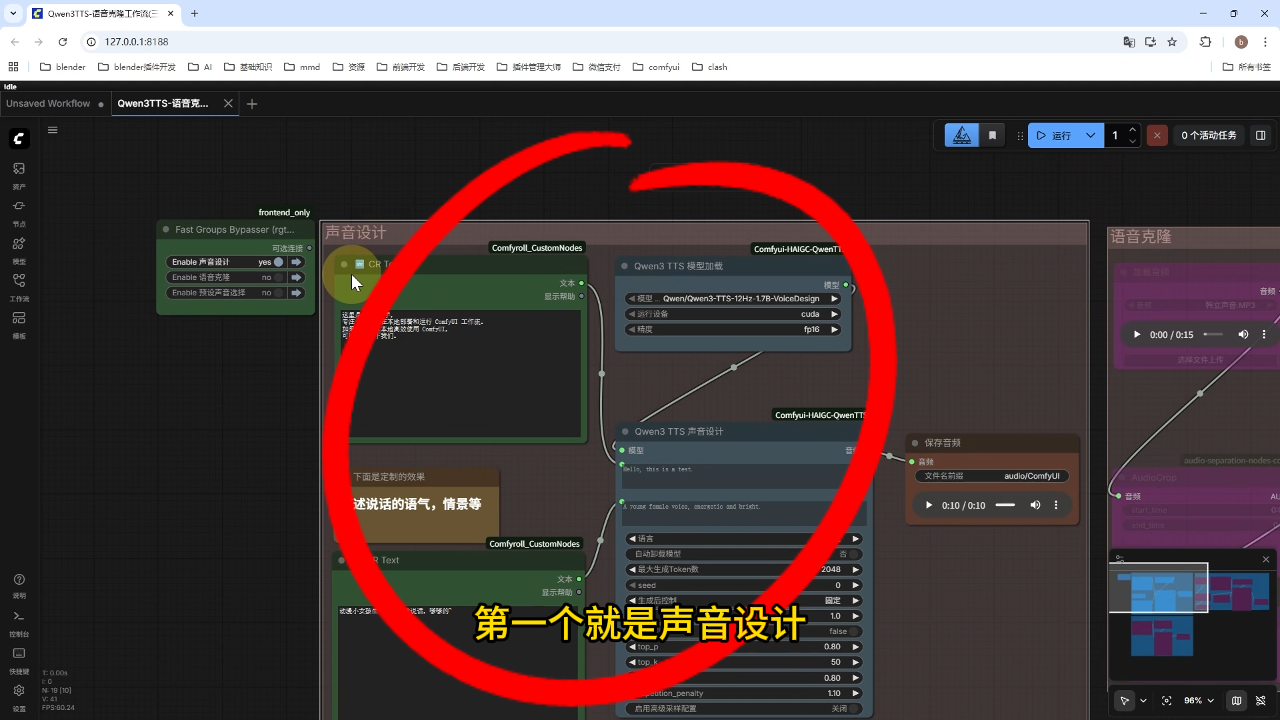
声音设计功能可通过自定义描述生成音色,输入文案即可生成对应音色的音频
2) 语音克隆
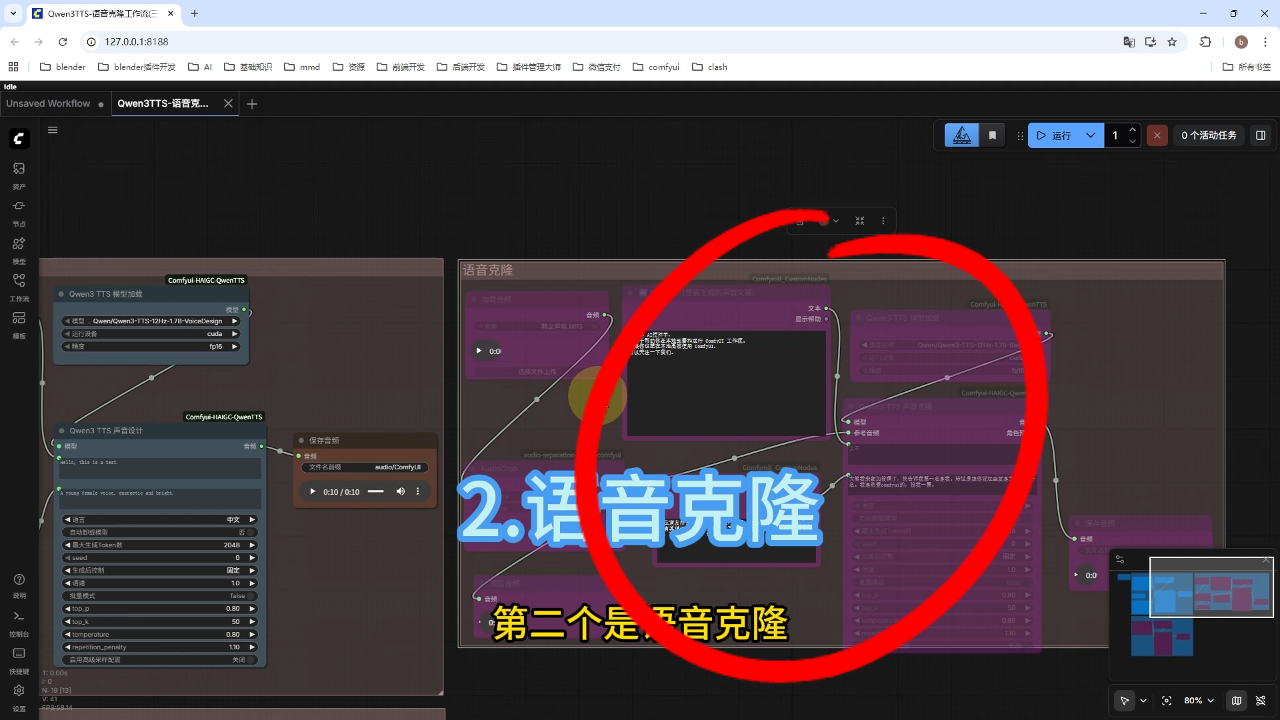
语音克隆功能需提供原始音频,系统将基于该音色生成新文案的音频
3) 预设声音
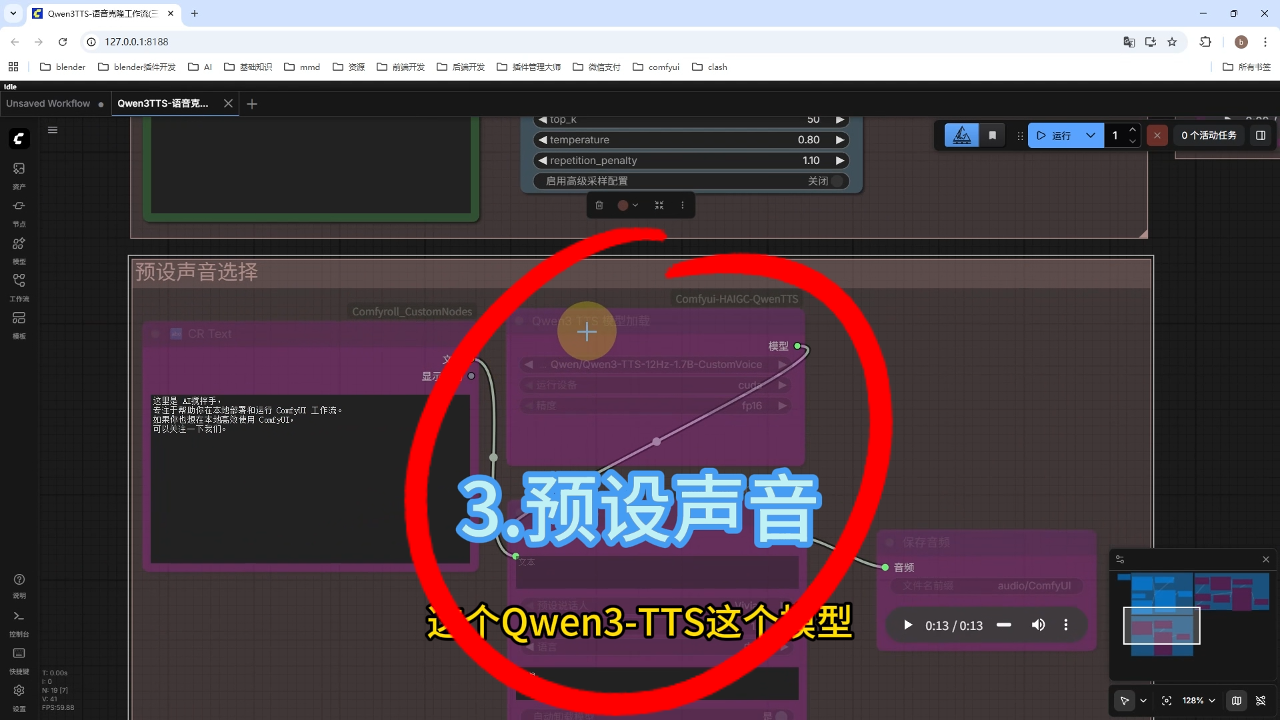
预设声音功能包含9种预置音色,可直接选择音色生成文案音频
2.详细演示
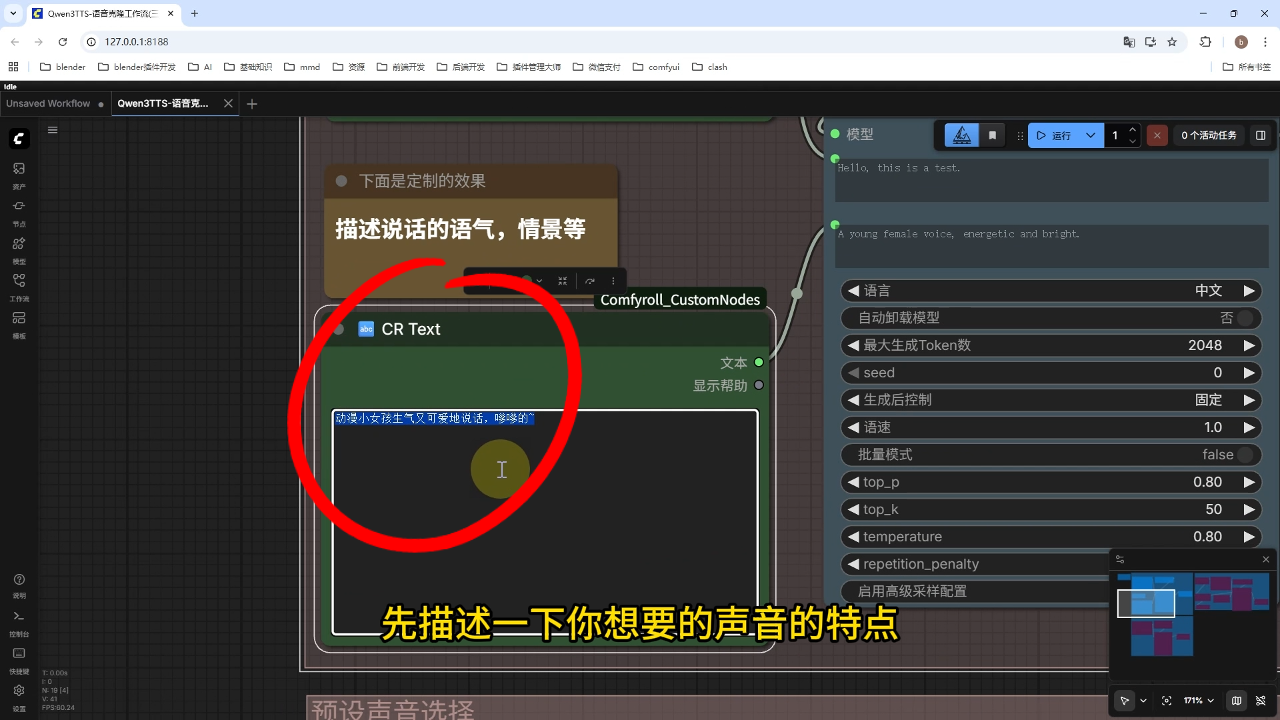
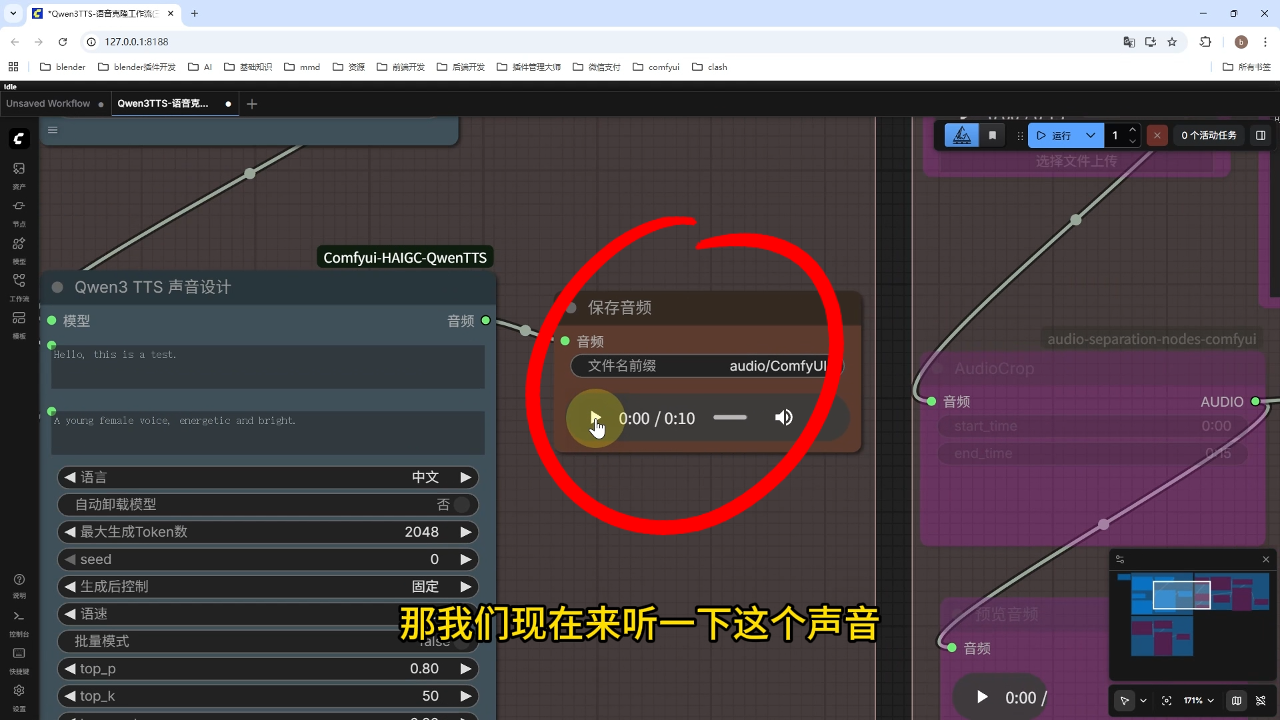
1) 声音设计
操作流程:在描述框输入声音特征(如"动漫小女孩生气又可爱的说话"),填写生成文案后点击运行
输出示例:生成音频内容为"这里是AI搅拌手,专注于帮助你在本地部署和运行comfyui工作流..."
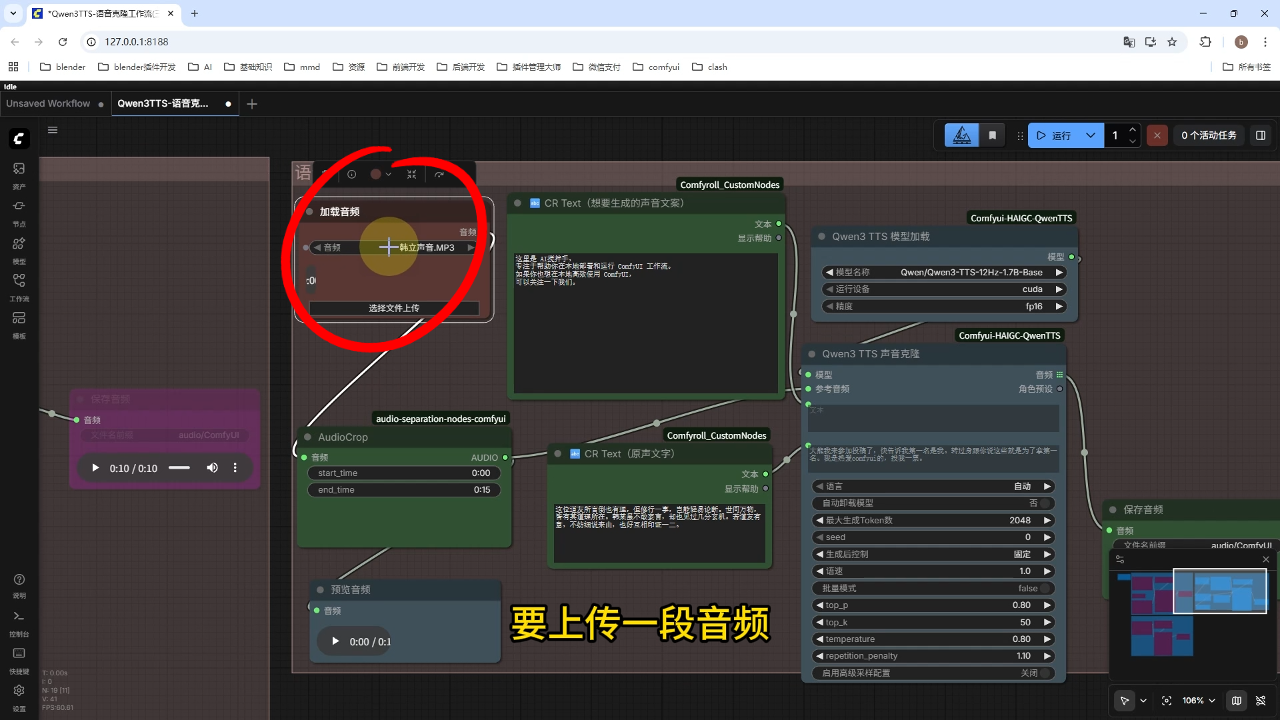
2) 语音克隆
操作流程:上传原始音频文件,输入目标文案内容后点击运行
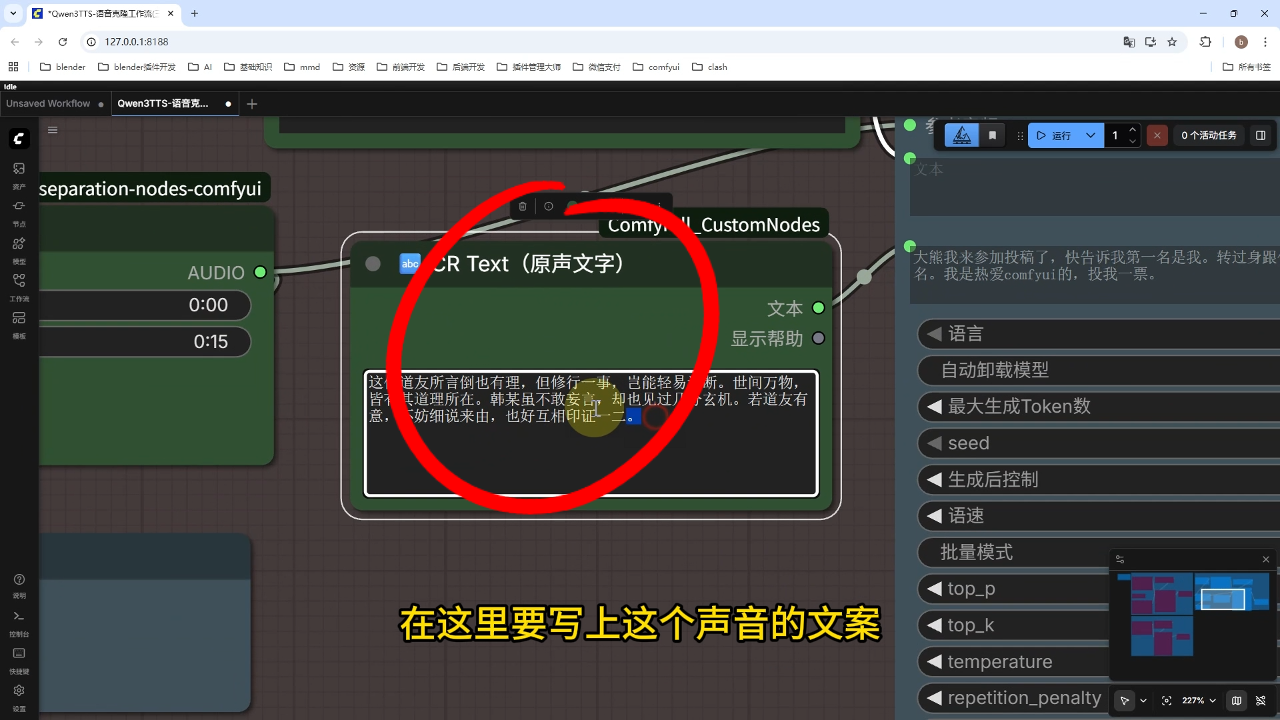
输出示例:生成音频内容为"这位道友所言倒也有理,但修行一事岂能轻易论断..."
3) 预设声音
操作流程:选择9种预设音色之一,设置生成token数和时长参数后运行
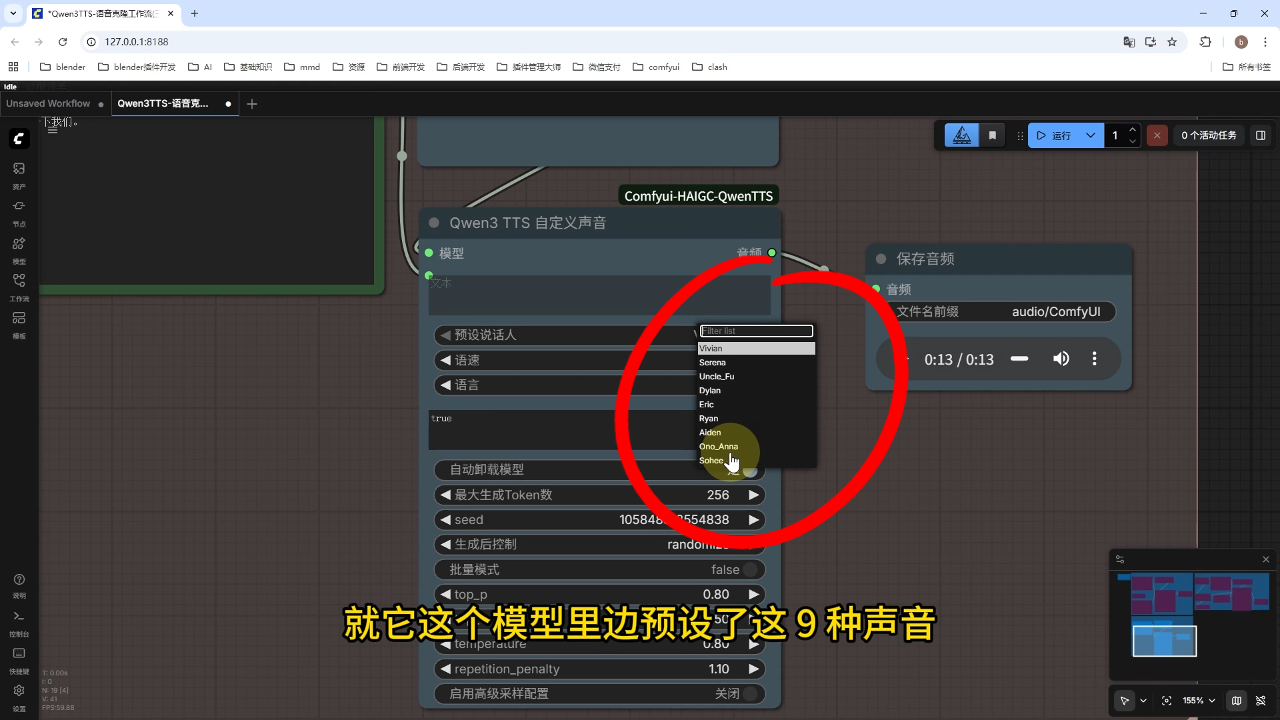
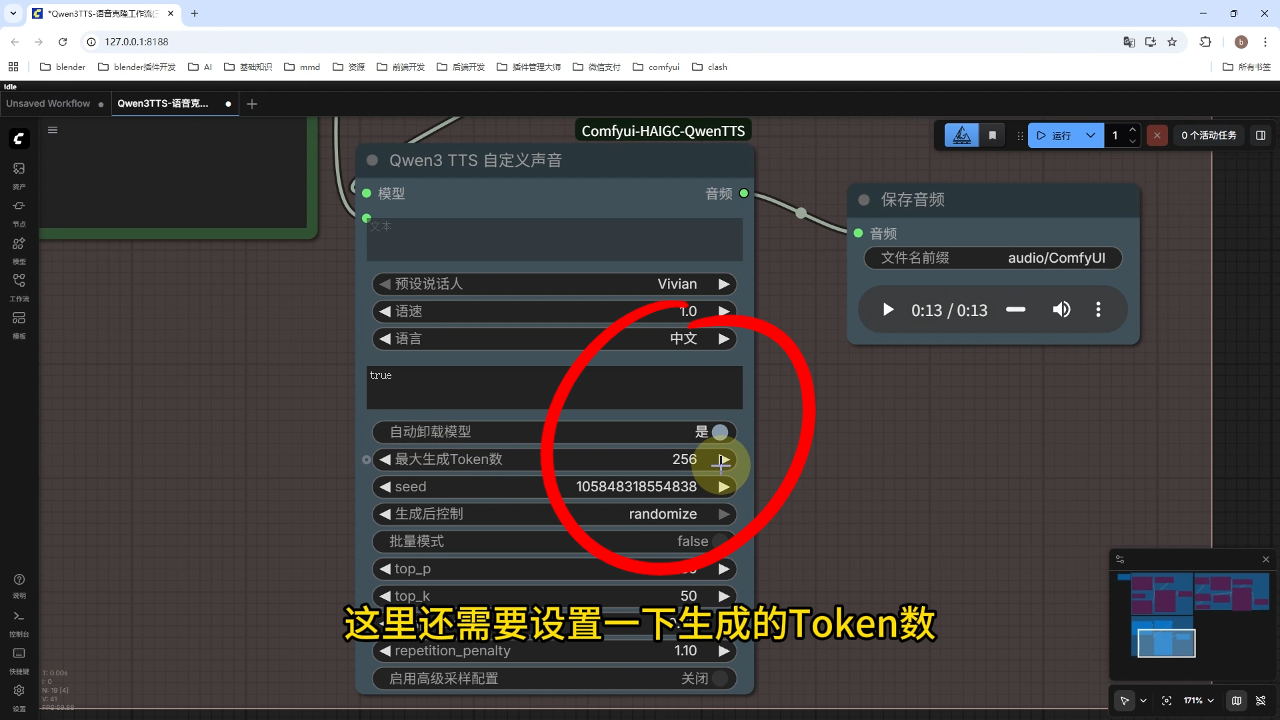
附加功能:可调节语速和语言选项(支持英文或自动识别)
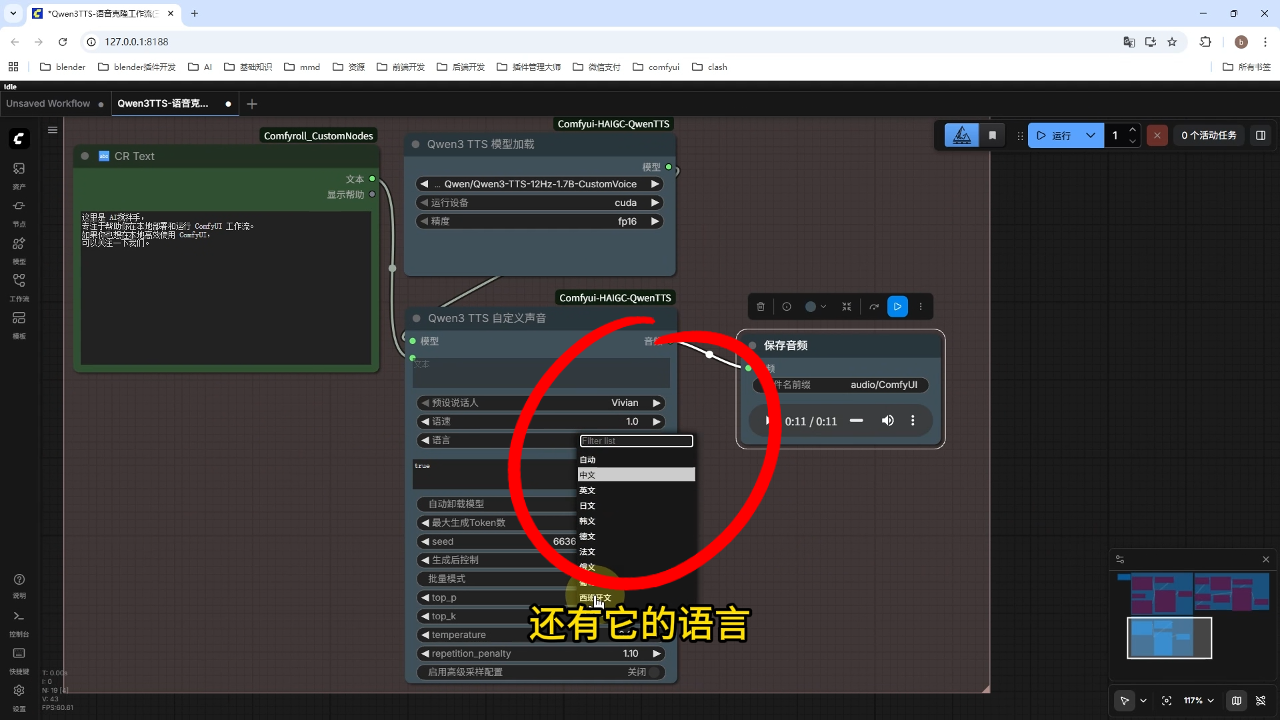
输出示例:生成音频内容为"这里是AI搅拌手,专注于帮助你在本地部署和运行comfyui工作流..."
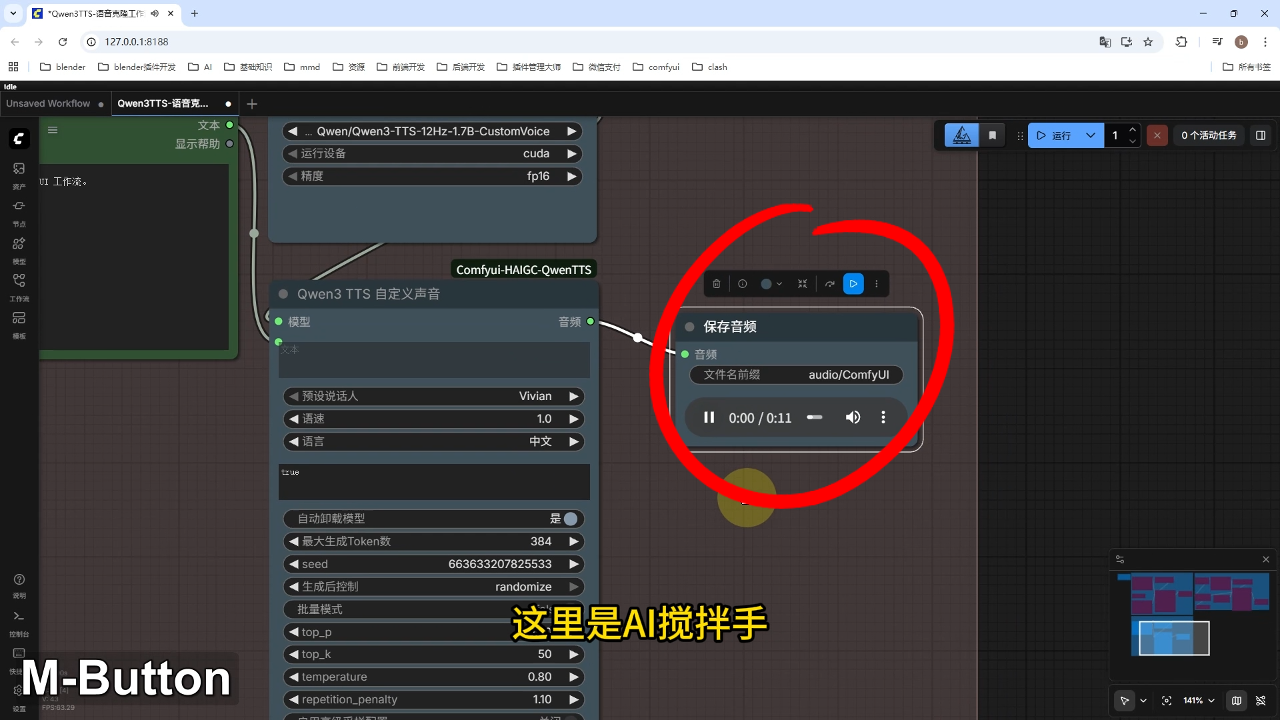
3.安装方式
需事先准备好纯净包
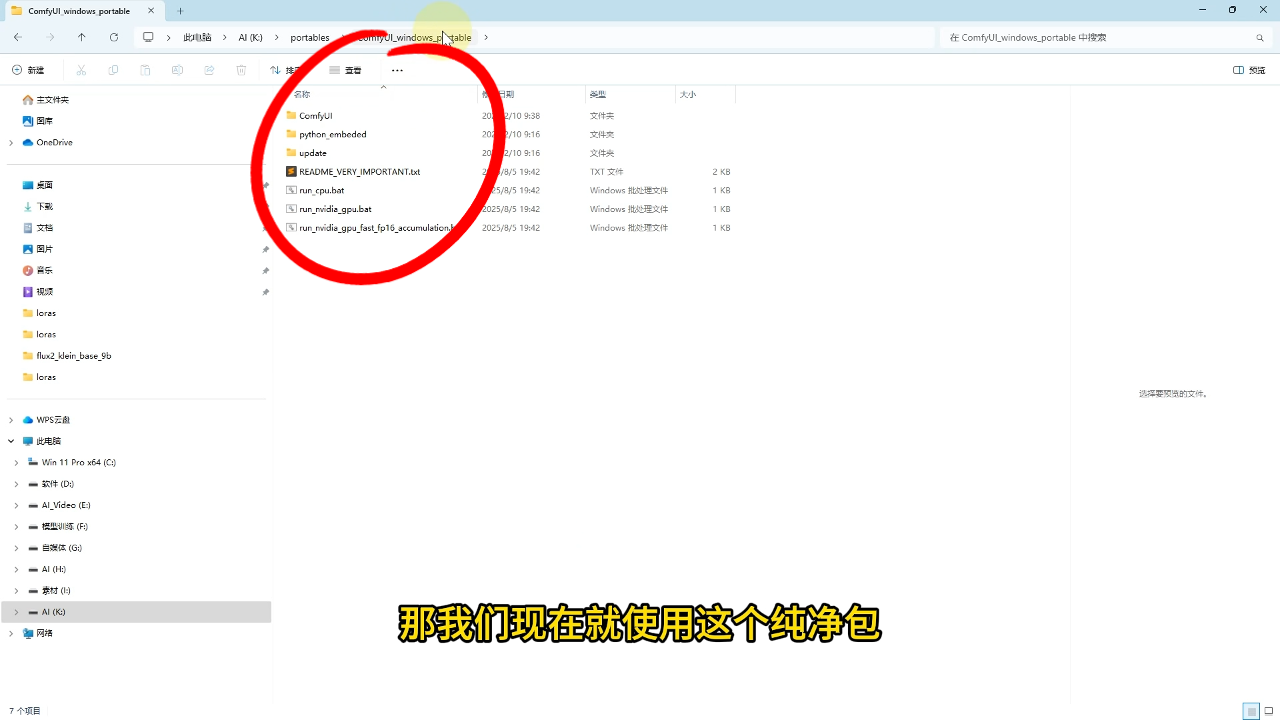
1) 一键安装
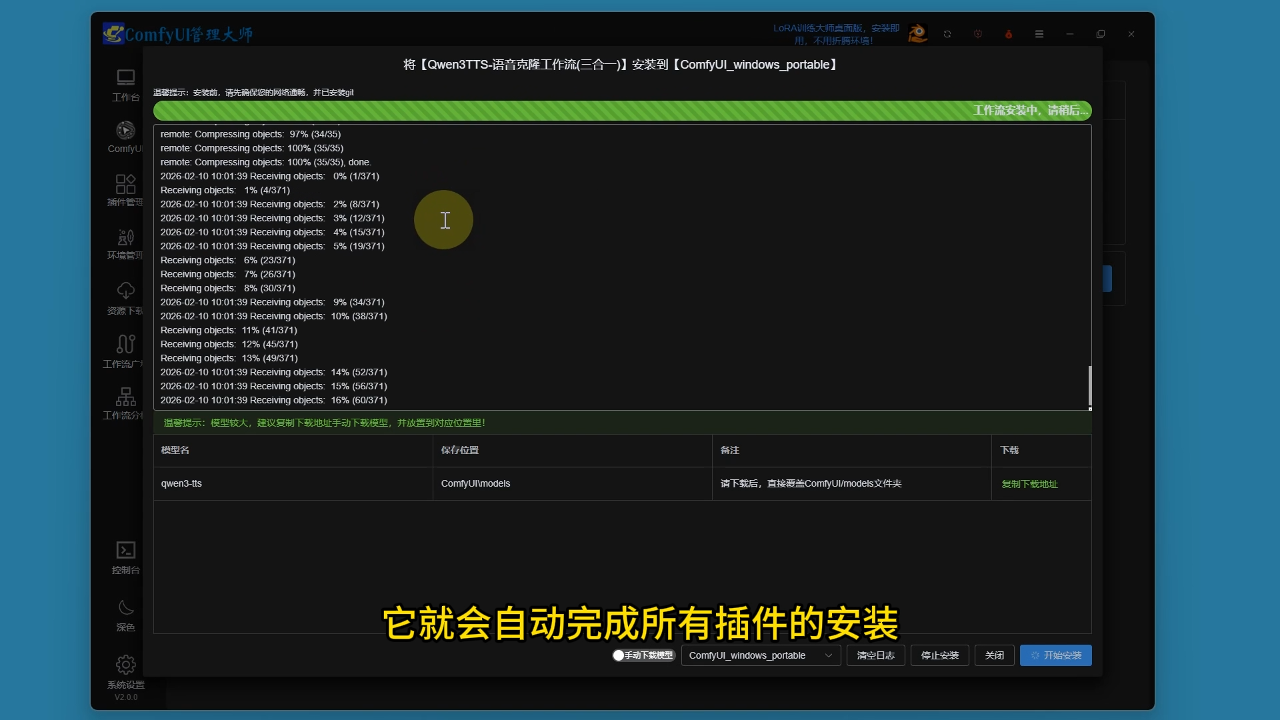
安装步骤:通过comfyui管理大师选择Qwen3 tts语音克隆工作流,点击一键安装
安装效果:自动完成所有插件、依赖和工作流的完整安装
验证方法:重启后工作流节点均可正常使用,测试音频生成功能
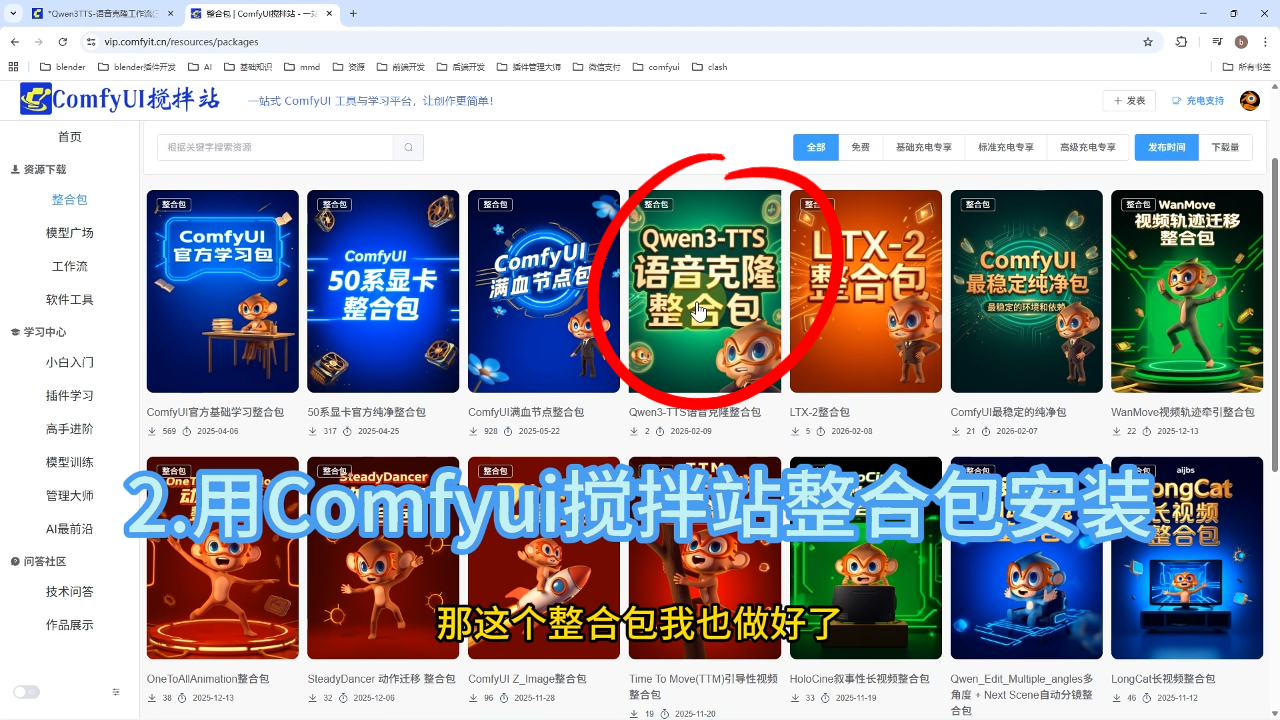
2) ComfyUI搅拌站整合包
安装方式:下载整合包后解压即可使用,内置三合一工作流
3) 手动安装:Qwen3-TTS音克隆模型和工作流
安装步骤:分别下载模型文件和工作流文件,模型文件需覆盖原models目录
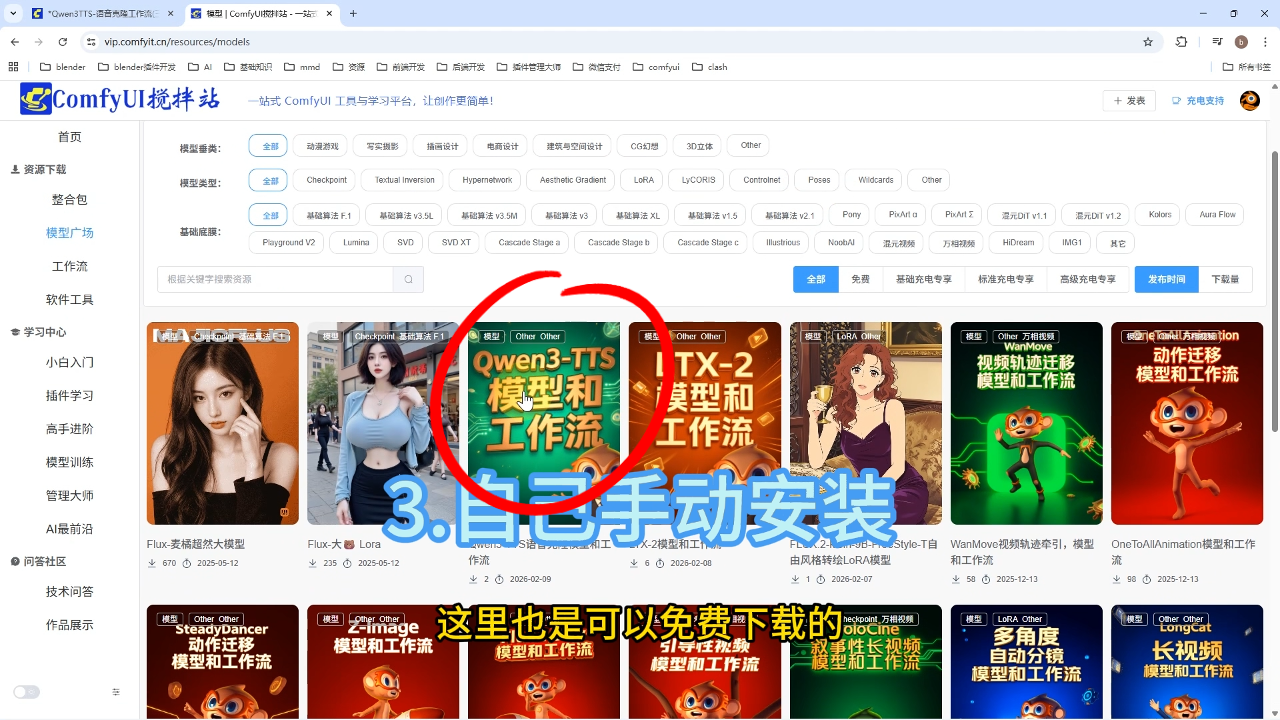
资源获取:支持免费下载模型和工作流组合包
二、知识小结
|------|--------------|---------|--------------|
| 功能模块 | 核心特点 | 技术实现 | 应用场景 |
| 声音设计 | 通过文字描述生成定制音色 | AI音色建模 | 动漫配音/虚拟角色创作 |
| 语音克隆 | 基于样本音频克隆音色 | 声纹特征提取 | 有声书/个性化语音助手 |
| 预设音库 | 9种预置音色直接调用 | TTS模型优化 | 快速内容生产/多语言播报 |
可点击下方原文链接观看视频教程👇