Redis7 底层数据结构解析
Redis 版本:7.2
目录
- [一、整体理解 Redis 底层数据结构](#一、整体理解 Redis 底层数据结构 "#%E4%B8%80%E6%95%B4%E4%BD%93%E7%90%86%E8%A7%A3-redis-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84")
- [1. Redis 数据在底层是什么样的?](#1. Redis 数据在底层是什么样的? "#1redis-%E6%95%B0%E6%8D%AE%E5%9C%A8%E5%BA%95%E5%B1%82%E6%98%AF%E4%BB%80%E4%B9%88%E6%A0%B7%E7%9A%84")
- [2. Redis 常见数据类型的底层数据结构总结](#2. Redis 常见数据类型的底层数据结构总结 "#2redis-%E5%B8%B8%E8%A7%81%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%E7%9A%84%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93")
- [二、String 数据结构详解](#二、String 数据结构详解 "#%E4%BA%8Cstring-%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [1. string 数据是如何存储的?](#1. string 数据是如何存储的? "#1string-%E6%95%B0%E6%8D%AE%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E7%9A%84")
- [2. string 类型对应的 int / embstr / raw 有什么区别?](#2. string 类型对应的 int / embstr / raw 有什么区别? "#2string-%E7%B1%BB%E5%9E%8B%E5%AF%B9%E5%BA%94%E7%9A%84-int--embstr--raw-%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB")
- [3. string 底层数据结构总结](#3. string 底层数据结构总结 "#3string-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93")
- [三、HASH 类型数据结构详解](#三、HASH 类型数据结构详解 "#%E4%B8%89hash-%E7%B1%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [1. hash 数据是如何存储的](#1. hash 数据是如何存储的 "#1hash-%E6%95%B0%E6%8D%AE%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E7%9A%84")
- [2. hash 底层数据结构详解](#2. hash 底层数据结构详解 "#2hash-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [3. hash 底层数据结构总结](#3. hash 底层数据结构总结 "#3hash-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93")
- [四、List 类型数据结构详解](#四、List 类型数据结构详解 "#%E5%9B%9Blist-%E7%B1%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [1. list 数据是如何存储的](#1. list 数据是如何存储的 "#1list-%E6%95%B0%E6%8D%AE%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E7%9A%84")
- [2. list 底层数据结构详解](#2. list 底层数据结构详解 "#2list-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [3. quicklist 简介](#3. quicklist 简介 "#3quicklist-%E7%AE%80%E4%BB%8B")
- [4. list 底层数据结构总结](#4. list 底层数据结构总结 "#4list-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93")
- [五、SET 类型数据结构详解](#五、SET 类型数据结构详解 "#%E4%BA%94set-%E7%B1%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [1. set 数据是如何存储的](#1. set 数据是如何存储的 "#1set-%E6%95%B0%E6%8D%AE%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E7%9A%84")
- [2. set 底层数据结构详解](#2. set 底层数据结构详解 "#2set-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [六、ZSET 类型数据结构详解](#六、ZSET 类型数据结构详解 "#%E5%85%ADzset-%E7%B1%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [1. zset 数据是如何存储的](#1. zset 数据是如何存储的 "#1zset-%E6%95%B0%E6%8D%AE%E6%98%AF%E5%A6%82%E4%BD%95%E5%AD%98%E5%82%A8%E7%9A%84")
- [2. zset 底层数据结构详解](#2. zset 底层数据结构详解 "#2zset-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [3. zset 底层数据结构总结](#3. zset 底层数据结构总结 "#3zset-%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93")
- [七、Redis 总结](#七、Redis 总结 "#%E4%B8%83redis-%E6%80%BB%E7%BB%93")
前言
这一章节将深入理解 Redis 底层数据结构,尝试真正了解 SET k1 v1 这样的指令是怎么执行的、数据是怎么保存的。 源码:自己在官网下载,解压进入src文件
一、整体理解 Redis 底层数据结构
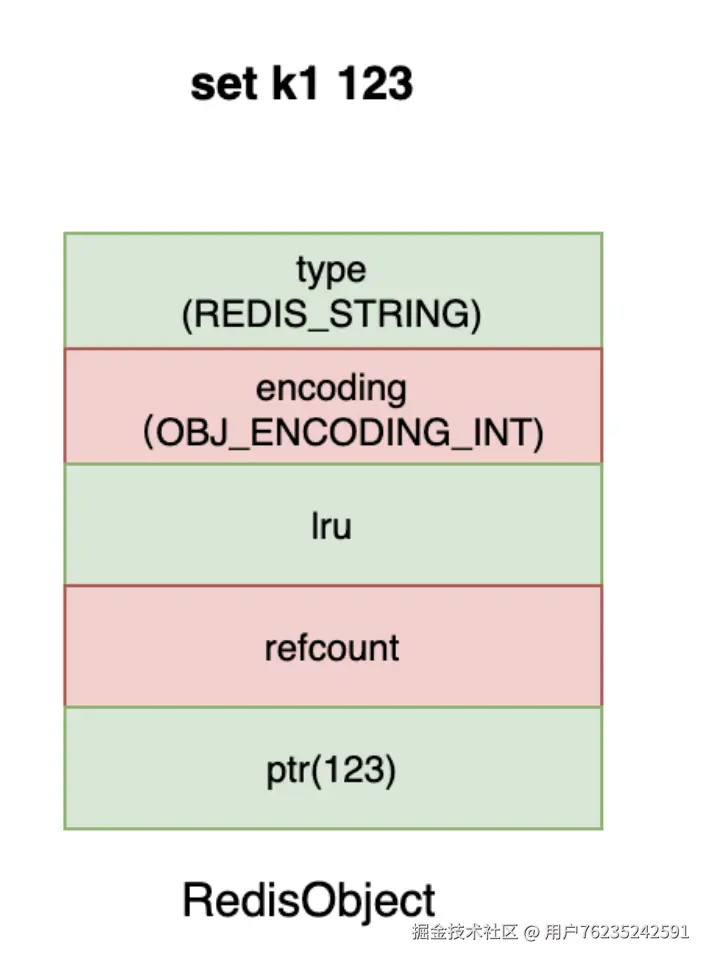
1、Redis 数据在底层是什么样的?
在应用层面,我们熟悉 Redis 有多种不同的数据类型,比如 string、hash、list、set、zset 等。但是这些数据在 Redis 的底层是什么样子呢?实际上 Redis 提供了一个指令 OBJECT 可以用来查看数据的底层类型。
bash
127.0.0.1:6379> OBJECT HELP
1) OBJECT [ [value] [opt] ...]. Subcommands are:
2) ENCODING
3) Return the kind of internal representation used in order to store
4) the value associated with a <key>.
5) FREQ
6) Return the access frequency index of the <key>. The returned integer is
7) proportional to the logarithm of the recent access frequency of the key.
8) IDLETIME
9) Return the idle time of the <key>, that is the approximated number of
10) seconds elapsed since the last access to the key.
11) REFCOUNT
12) Return the number of references of the value associated with the specified <key>.
14) HELP
15) Print this help.
127.0.0.1:6379> SET k1 v1
OK
127.0.0.1:6379> OBJECT ENCODING k1
"embstr"可以看到,k1 v1 这个键值对,在底层的数据类型就是 embstr。Redis 在底层,是这样描述这些数据类型的:
server.h 880 行:
c
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */注意:可以看到有些类型已经不再使用了。比如 ZIPLIST ,在 Redis6 中是非常重要的数据类型,但现在已经不再使用了。在 Redis7 中,基本已经使用 listpack 替代了 ziplist。
这些编码方式都是使用在 Object 的 encoding 字段里的。这个 Object 是什么呢?
server.h 900 行:
c
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
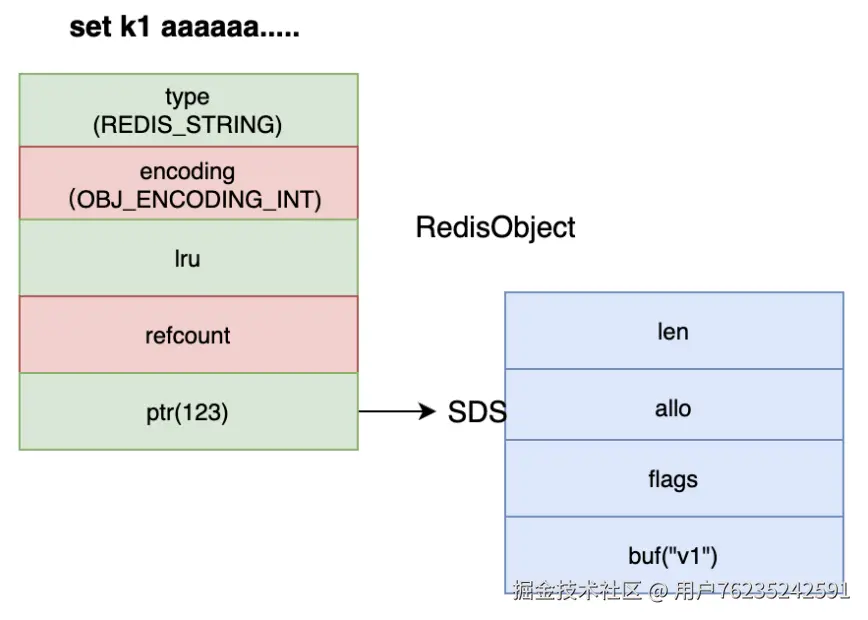
};Redis 是一个 k,v 型的数据库,其中 key 通常都是 string 类型的字符串对象,而 value 在底层就统一是 redisObject 对象。
这个 redisObject 结构,实际上就是 Redis 内部抽象出来的一个封装所有底层数据结构的统一对象。这类似于 Java 的面向对象设计方式。
几个核心字段含义:
| 字段 | 说明 |
|---|---|
type |
Redis 的上层数据类型,如 string、hash、set 等,可用 TYPE key 指令查看 |
encoding |
Redis 内部的底层数据类型 |
lru |
当内存超限时会采用 LRU 算法清除内存中的对象(也支持 LFU 模式) |
refcount |
对象的引用次数,可用 OBJECT REFCOUNT key 指令查看 |
*ptr |
指针,指向真正底层的数据结构。encoding 只是类型描述,实际数据保存在 ptr 指向的具体结构里 |
2、Redis 常见数据类型的底层数据结构总结
每一种上层数据类型对应底层多种不同的数据结构,也就是说同样的一个数据类型,Redis 底层的处理方式是不同的:
bash
127.0.0.1:6379> SET k1 v1
OK
127.0.0.1:6379> TYPE k1
string
127.0.0.1:6379> OBJECT ENCODING k1
"embstr"
127.0.0.1:6379> SET k2 1
OK
127.0.0.1:6379> TYPE k2
string
127.0.0.1:6379> OBJECT ENCODING k2
"int"
127.0.0.1:6379> SET k3 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> TYPE k3
string
127.0.0.1:6379> OBJECT ENCODING k3
"raw"下面是 Redis 中上层数据类型和底层真正存储数据的数据结构的对应关系:
| Redis 版本 | string | set | zset | list | hash |
|---|---|---|---|---|---|
| Redis 6 | SDS(动态字符串) | intset + hashtable | skiplist + ziplist | quicklist + ziplist | hashtable + ziplist |
| Redis 7 | SDS | intset + listpack + hashtable | skiplist + listpack | quicklist + listpack | hashtable + listpack |
Redis6 和 Redis7 最大的区别 就在于 Redis7 已经用 listpack 替代了 ziplist。只不过为了保证兼容性,Redis7 中并没有移除 ziplist 的代码以及配置。listpack 与 ziplist 的区别也是一个高频的面试题,后面会逐步介绍。
二、String 数据结构详解
1、string 数据是如何存储的?
string 数据的类型,会根据 value 的类型不同,有以下几种处理方式:
- int :如果 value 可以转换成一个
long类型的数字,那么就用 int 保存 value。只有整数才会使用 int,如果是浮点数,Redis 内部其实是先将浮点数转化成字符串,然后保存。 - embstr :如果 value 是一个字符串类型,并且长度小于 44 字节,那么 Redis 就会用 embstr 保存。embstr 的底层数据结构是 SDS(Simple Dynamic String,简单动态字符串)。
- raw :如果 value 是一个字符串类型,并且长度大于 44 字节,就会用 raw 保存。
源码验证: <t_string.c 295⾏> 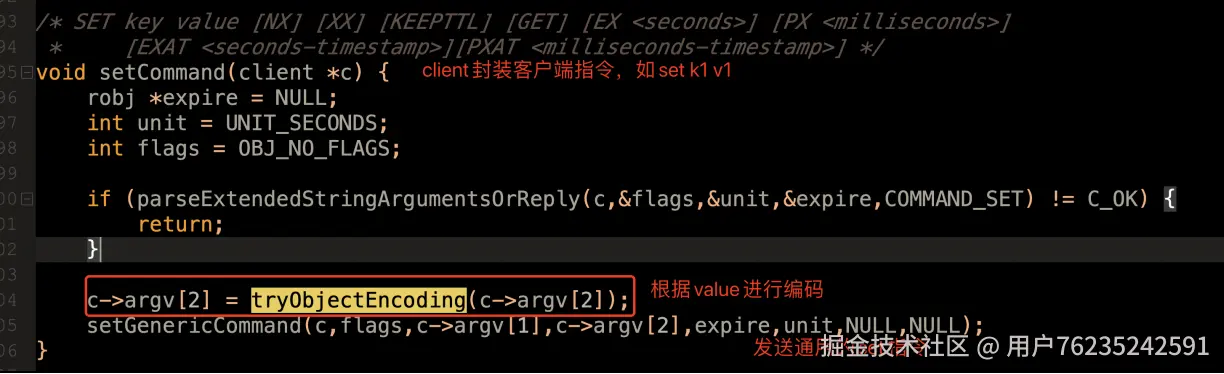 在客户端执行
在客户端执行 SET k1 v1 这样的指令,会进入 t_string.c 的 setCommand 方法处理,最终调用 tryObjectEncoding 方法(在 object.c 614 行的 *tryObjectEncodingEx 方法中):
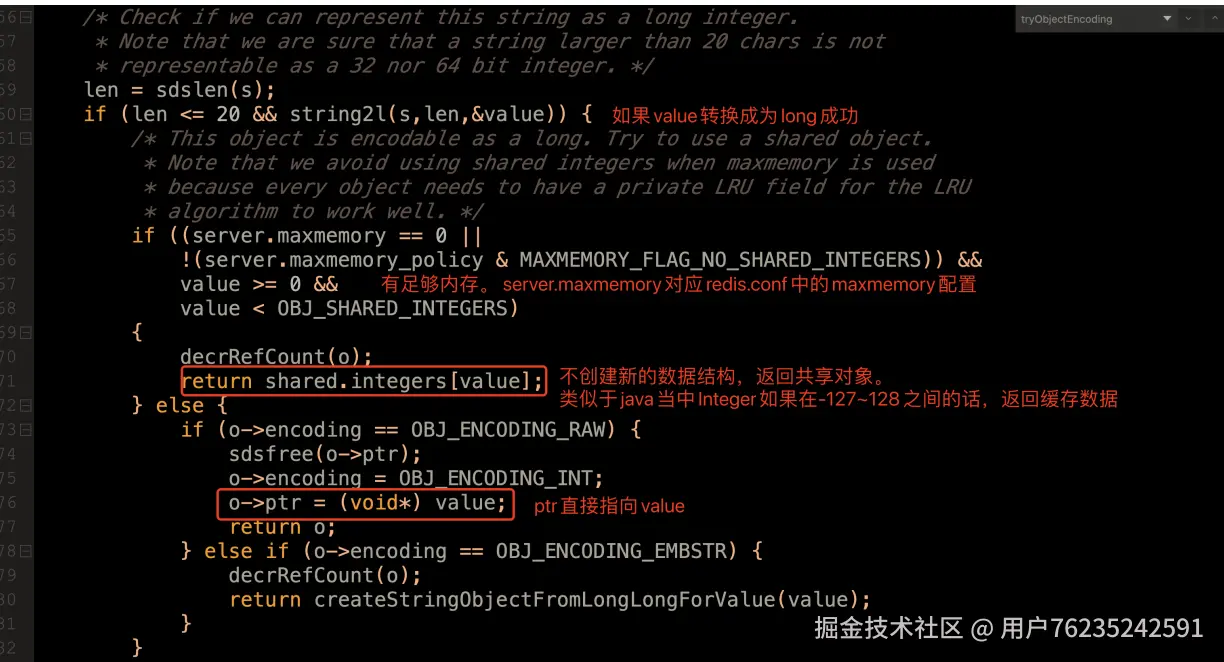
- 对于数字长度超过 20 的大数字,Redis 是不会用 int 保存的
OBJ_SHARED_INTEGER = 1000,对于 1000 以内的数字,直接指向内存(共享对象)
2、string 类型对应的 int / embstr / raw 有什么区别?
① int 类型
尽量在对应的 robj 中的 ptr 指向一个缓存数据对象。对于小于 1000 的整数,直接使用预先创建的共享对象,节省了对象创建的内存开销。
 ② embstr 类型
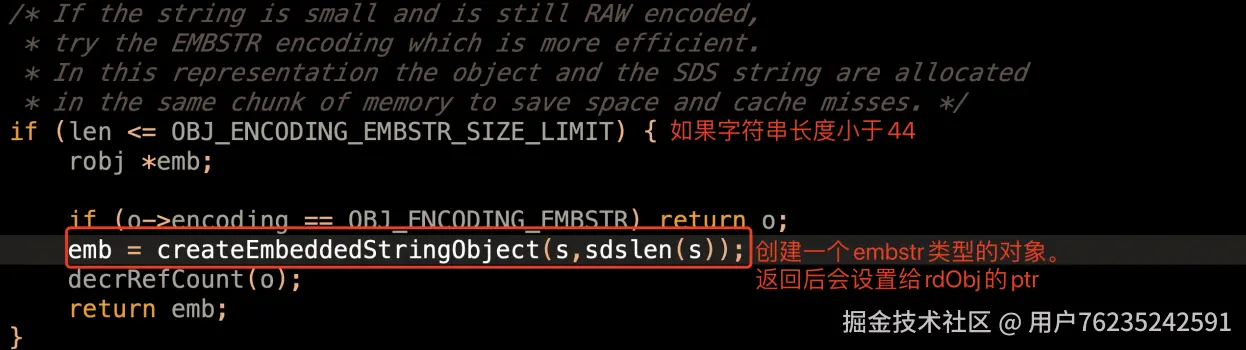
② embstr 类型
如果字符串类型长度小于 44,就会创建一个 embstr 对象(object.c 92 行)。
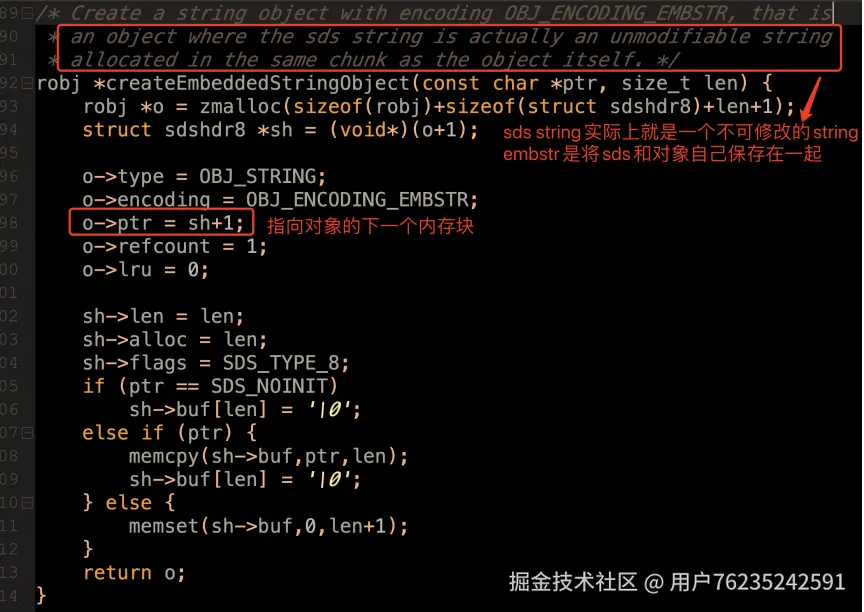
embstr 字面意思就是内嵌字符串。所谓内嵌的核心,就是将新创建的 SDS 对象直接分配在对象自己的内存后面,这样内存读取效率明显更高。
注意:SDS 其实是一段不可修改的字符串。这意味着如果使用
APPEND之类的指令尝试修改一个 key 的值,那么就算 value 的长度没有超过 44,Redis 也会使用一个新创建的 raw 类型,而不再使用原来的 SDS。
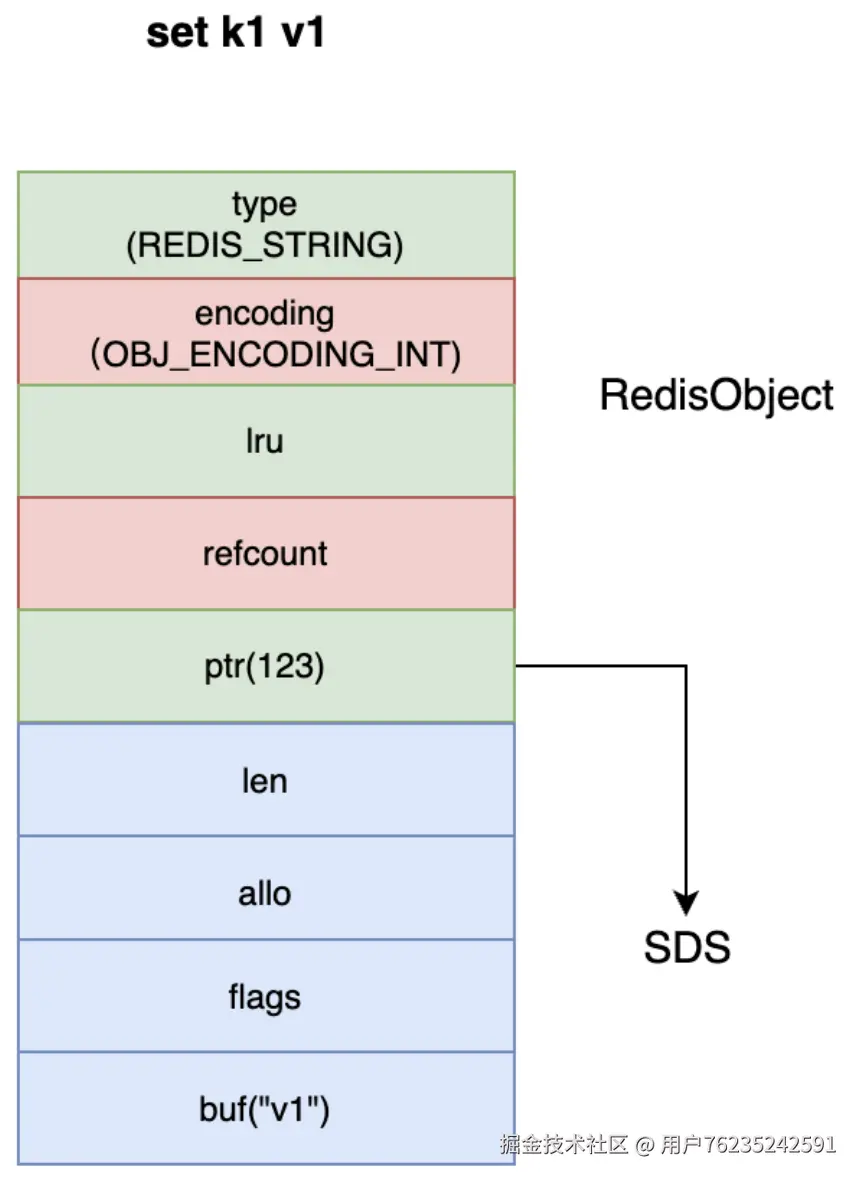
SDS 结构(sds.h 45 行):
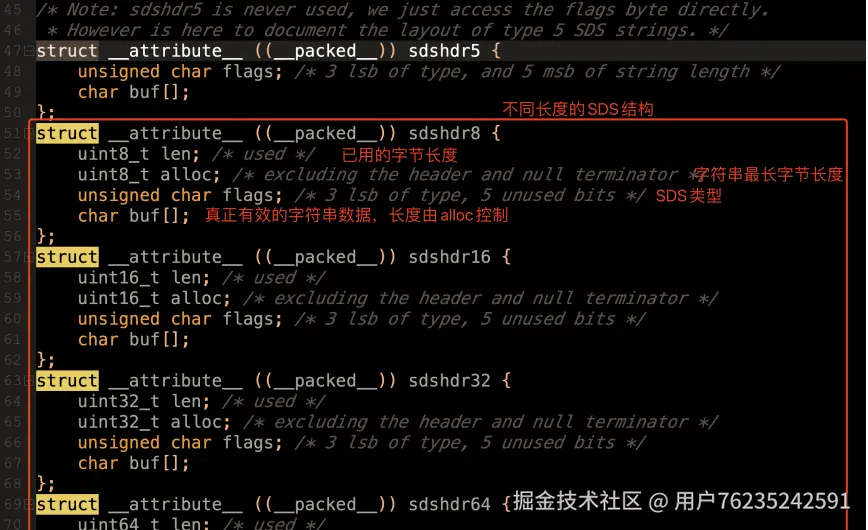 Redis 根据字符串长度不同,封装了多种不同的 SDS 结构。通常保存字符串用一个
Redis 根据字符串长度不同,封装了多种不同的 SDS 结构。通常保存字符串用一个 buf[] 就够了,但是 Redis 在这个数组的基础上封装成了 SDS 结构,通过添加的这些参数可以更方便解析字符串。
- 如果用数组方式保存字符串,读取完整字符串需遍历数组,时间复杂度 O(N);但 SDS 中预先记录了
len,可以直接读取一定长度的字节,时间复杂度 O(1),效率更高。 - C 语言中通常用
\0表示字符串结束,但如果 value 中就包含\0这样的字符就会产生歧义。有了 SDS 后,直接读取完整字节,不用管这些歧义了。
③ raw 类型
raw 类型相当于是兜底的一种类型。特殊的数字类型和小字符串类型处理完了后,就是 raw 类型了。raw 类型的处理方式就是单独创建一个 SDS,然后将 robj 的 ptr 指向这个 SDS。
3、string 底层数据结构总结
对于 string 类型的一系列操作,Redis 内部会根据用户给的不同键值使用不同的编码方式,自适应地选择最优化的内部编码方式。这些逻辑对用户是完全隔离的。
| 编码类型 | 条件 | 特点 |
|---|---|---|
| int | value 可转换为数字 | ptr 直接存整数值,无需额外指针;小于 1000 时使用共享对象,极省内存 |
| embstr | 字符串且长度 ≤ 44 字节 | 连续内存分配,读取速度快,避免内存碎片 |
| raw | 字符串且长度 > 44 字节 | RedisObject 和 SDS 分开申请内存,ptr 指针指向新创建的 SDS |
三、HASH 类型数据结构详解
1、hash 数据是如何存储的
hash 类型的数据,底层存储时,有两种存储格式:hashtable 和 listpack。
bash
127.0.0.1:6379> HSET user:1 id 1 name roy
(integer) 2
127.0.0.1:6379> TYPE user:1
hash
127.0.0.1:6379> OBJECT ENCODING user:1
"listpack"
# 修改阈值参数
127.0.0.1:6379> CONFIG SET hash-max-listpack-entries 3
OK
127.0.0.1:6379> CONFIG SET hash-max-listpack-value 8
OK
# value 超过 8 字节,升级为 hashtable
127.0.0.1:6379> HSET user:1 name royaaaaaaaaaaaaaaaa
(integer) 0
127.0.0.1:6379> OBJECT ENCODING user:1
"hashtable"
# 键值对个数超过 3,升级为 hashtable
127.0.0.1:6379> HSET user:2 id 1 name roy score 100 age 18
(integer) 4
127.0.0.1:6379> OBJECT ENCODING user:2
"hashtable"判断逻辑:hash 型的数据,如果 value 里的数据比较少,就用 listpack;如果数据比较多,就用 hashtable。涉及两个参数:
hash-max-listpack-entries:限制 value 里键值对的个数(默认 512)hash-max-listpack-value:限制 value 里值的数据大小(默认 64 字节)
正常情况下,hash 类型数据大部分都是使用 listpack。对于 hash 类型数据,主要需要理解 listpack 是如何存储的。
2、hash 底层数据结构详解
基础数据结构:
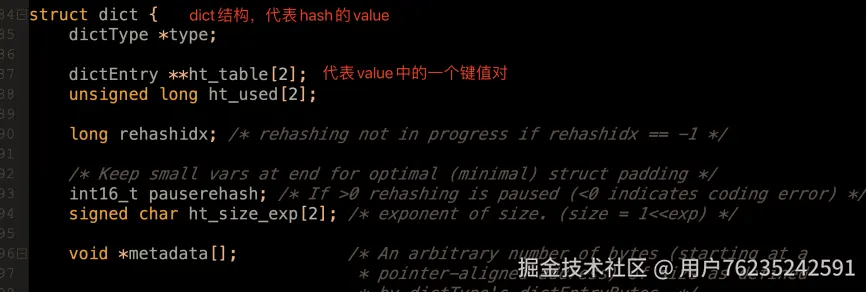
hash 数据的 value 是一系列的键值对。这些 k,v 键值对底层封装成了一个 dictEntry 结构,然后整个这些键值对又会被封装成一个 dict 结构,这个 dict 结构就构成了 hash 的整个 value(dict.h 84 行,dict.c 63 行)。

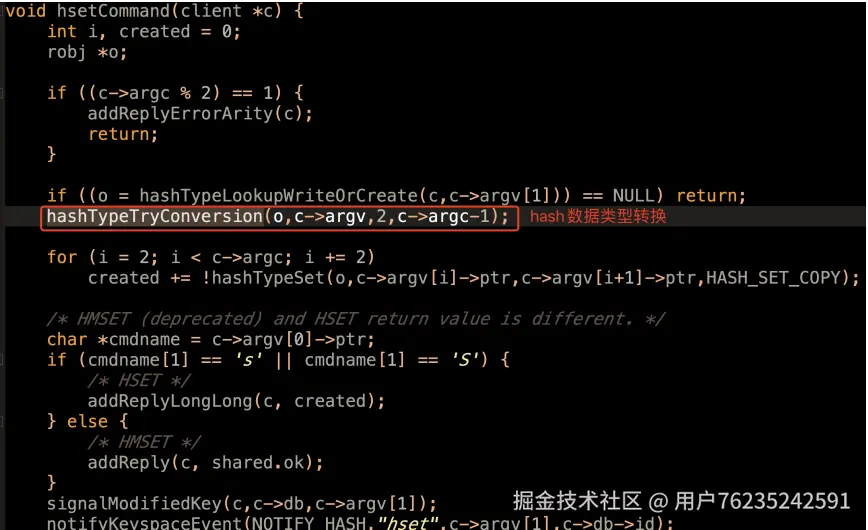
然后,来看redis底层是如何执⾏⼀个hset key field1 value1 field2 value2 这样的指令的 Redis底层处理hset指令的⽅法在 <t_hash.c 606⾏>
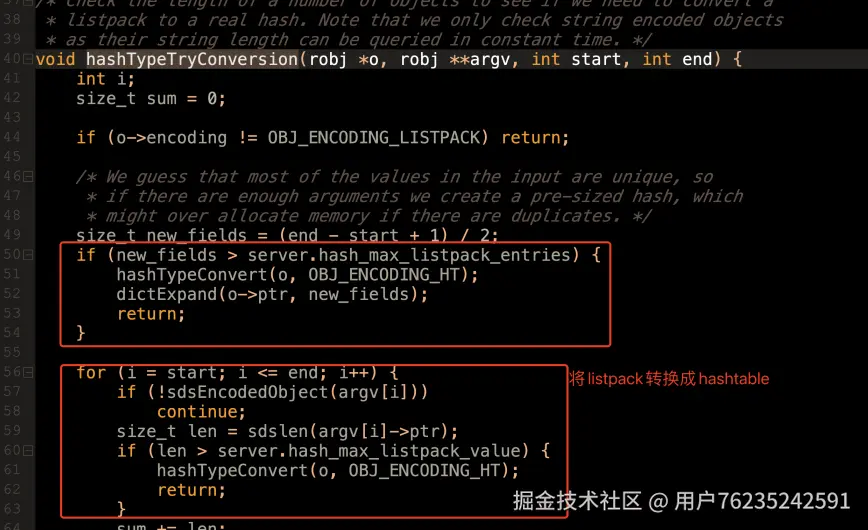
 接下来这个hashTypeTryConversion⽅法就会尝试进⾏编码转换。 这就验证了hash类型数 据根据那两个参数选择⽤listpack还是hashtable的。
接下来这个hashTypeTryConversion⽅法就会尝试进⾏编码转换。 这就验证了hash类型数 据根据那两个参数选择⽤listpack还是hashtable的。
 listpack 与 ziplist:
listpack 与 ziplist:
listpack是ziplist的升级版,所以,谈到listpack就不得不谈ziplist。ziplist字⾯意义是压缩 列表。怎么压缩呢? ziplist最⼤的特点,就是他被设计成⼀种内存紧凑型的数据结构,占⽤⼀块连续的内存空 间,不仅可以利⽤CPU缓存,⽽且会针对不同⻓度的数据,进⾏响应的编码。这种⽅法可 以及有效的节省内存开销。 在redis6中,ziplist是Redis底层⾮常重要的⼀种数据结构,不⽌⽀持hash,还⽀持list等其 他数据类型 ziplist是由连续内存块组成的顺序性数据结构,整个结构有点类似于数组。可以在任意⼀端 进⾏push/pop操作,时间复杂度都是O(1)。整体结构如下:
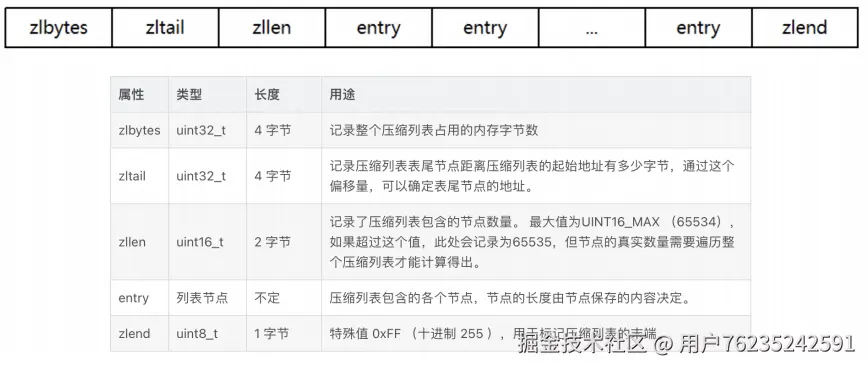
每一个 entry 结构又分为三个部分:
| 字段 | 说明 |
|---|---|
previous_entry_length |
记录前一个节点的长度,占 1 个或 5 个字节。前一个节点长度 < 254 字节用 1 字节;≥ 254 字节用 5 字节(第一个字节是 0xfe,后四个字节才是真实长度) |
encoding |
编码属性,记录 content 的数据类型(字符串还是整数)及 content 的长度 |
contents |
负责保存节点的数据,可以是字符串或整数 |
ziplist后⾯的list通常是指链表数据结构。⽽典型的双向链表是在每个节点上通过两个指针指向前和后的相邻节点。⽽ziplist这种数据结构,就不再保存指针,只保留⻓ 度。极致压缩内存空间。这也是关于ziplist紧凑的⼀种表现。 在这种结构下,对于⼀个ziplist,要找到对列的第⼀个元素和最后⼀个元素,都是⽐较容易的,可以通过头部的三个字段直接找到。但是,如果想要找到中间某⼀些元素(⽐如Redis的list数据类型的LRANGE指令),那么就只能依次遍历(从前往后单向遍历)。所以,ziplist不太适合存储太多的元素。
为什么要用 listpack 替换 ziplist?------连锁更新问题
redis的作者antirez的github上提供了listpack的实现。⾥⾯有⼀个md⽂档介绍了 listpack。⽂章地址: github.com/antirez/lis... listpack的整体结构跟ziplist是差不多的,只是做了⼀些⼩调整。最核⼼的原因是要解决ziplist的连锁更新问题。
连锁更新问题的核心在于 entry 的 previous_entry_length 记录方式。假设我们有一个 ziplist,每个 entry 的长度都在 250~253 字节之间,previous_entry_length 都只需要 1 个字节。
 这时,如果将一个长度 ≥ 254 字节的新节点加入到压缩列表的表头:
这时,如果将一个长度 ≥ 254 字节的新节点加入到压缩列表的表头:

- e1 的
previous_entry_length只有 1 个字节,无法保存新节点的长度,需要扩充到 5 个字节 - 这样 e1 的整体长度就会超过 254 字节
- e1 长度扩展 → e2 的
previous_entry_length也需要从 1 扩展到 5 字节 - 接下来后续每一个 entry 都需要重新调整空间
这种连续多次空间扩展操作称为连锁更新,效率极低且不安全。正是因为这个问题,Redis7 中使用新的 listpack 结构替代 ziplist。
**listpack 整体结构
 核⼼是entry中原本记录前⼀个entry的⻓度,现在改为记录⾃⼰的⻓度。这样,就不 会再因为前⼀个entry变化⽽影响⾃⼰的⻓度。这样也就没有了连锁更新的问题。
核⼼是entry中原本记录前⼀个entry的⻓度,现在改为记录⾃⼰的⻓度。这样,就不 会再因为前⼀个entry变化⽽影响⾃⼰的⻓度。这样也就没有了连锁更新的问题。
listpack在源码中的体现如下:(listpack.h 49 行):**

3、hash 底层数据结构总结
- hash 底层更多的是使用 listpack 来存储 value
- 如果 hash 对象保存的键值对超过 512 个,或者所有键值对的字符串长度超过 64 字节,底层的数据结构就会由 listpack 升级成为 hashtable
- 对于同一个 hash 数据,listpack 结构可以升级为 hashtable 结构,但是 hashtable 结构不会降级成为 listpack
四、List 类型数据结构详解
1、list 数据是如何存储的
list 类型的数据,在 Redis 中以 listpack + quicklist 为基础保存。
bash
127.0.0.1:6379> LPUSH l1 a1
(integer) 1
127.0.0.1:6379> RPUSH l1 a2
(integer) 2
127.0.0.1:6379> TYPE l1
list
127.0.0.1:6379> OBJECT ENCODING l1
"listpack"
# 调整参数后,数据量大的 list 使用 quicklist
127.0.0.1:6379> CONFIG SET list-max-listpack-size 2
OK
127.0.0.1:6379> LPUSH l3 a1 a2 a3
(integer) 3
127.0.0.1:6379> OBJECT ENCODING l3
"quicklist"关于 list-max-listpack-size 参数(redis.conf 中的说明):
bash
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb
# -4: max size: 32 Kb
# -3: max size: 16 Kb
# -2: max size: 8 Kb (default, highest performing)
# -1: max size: 4 Kb
# Positive numbers mean store up to exactly that number of elements per list node.
list-max-listpack-size -2总结:对于 list 数据类型,Redis 根据 value 中数据的大小判断底层数据结构。数据比较"小"的 list 类型,底层用 listpack 保存;数据量比较"大"的 list 类型,底层用 quicklist 保存。
2、list 底层数据结构详解
处理 LPUSH、RPUSH 这些指令时(t_list.c 484 行),
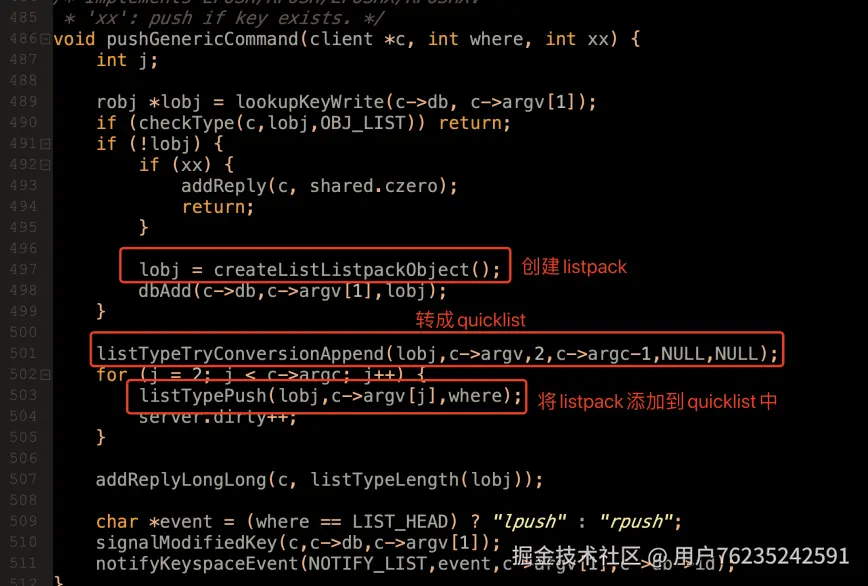
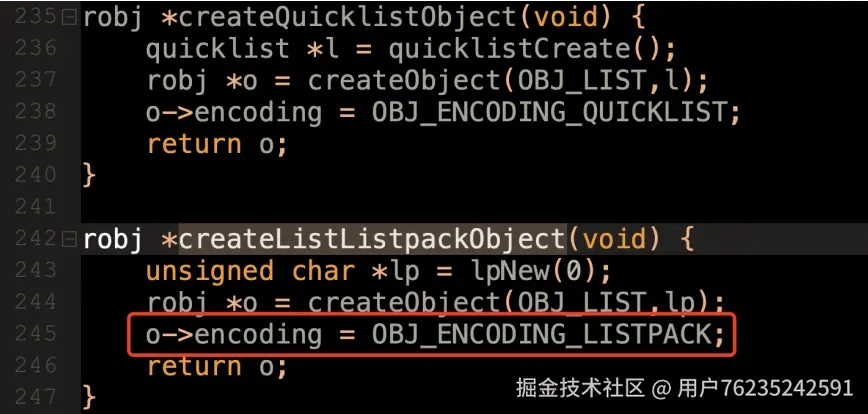
会先创建 listpack 结构(object.c 242 行),
 然后通过
然后通过 listTypeTryConversionAppend 方法(t_list.c 132 行)
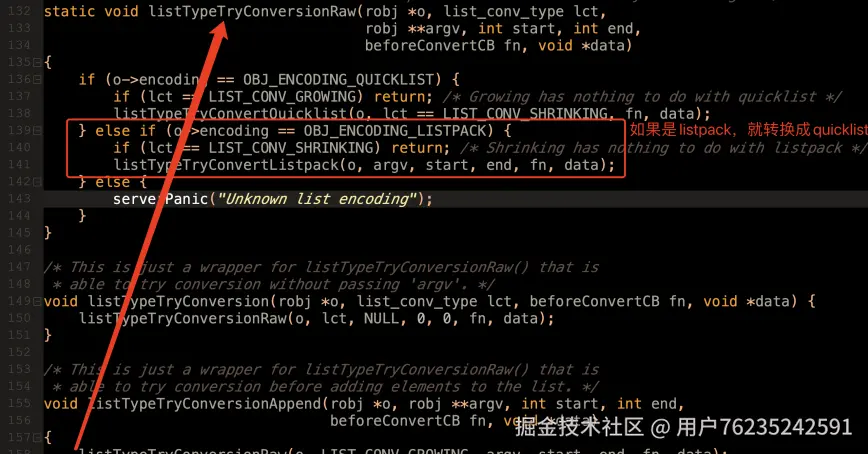 尝试对 listpack 进行转换,在
尝试对 listpack 进行转换,在 listTypeTryConvertListpack 方法(t_list.c 32 行)中可以看到转换为 quicklist 的逻辑。
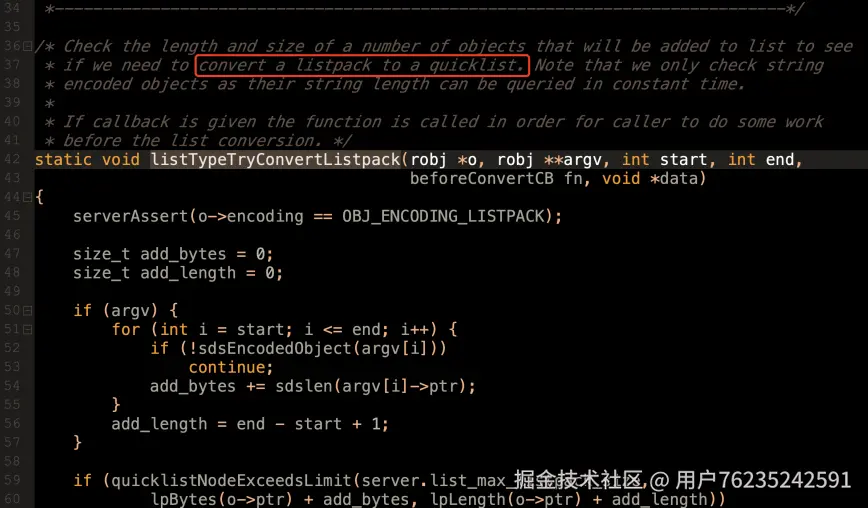 另外,还涉及到另一个配置参数
另外,还涉及到另一个配置参数 list-compress-depth,表示 list 的数据压缩级别,可以去配置⽂件中了解⼀下。
bash
# Lists may also be compressed.
# Compress depth is the number of quicklist ziplist nodes from *each*
side of
# the list to *exclude* from compression. The head and tail of the
list
# are always uncompressed for fast push/pop operations. Settings
are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into
the list,
# going from either the head or tail"
# So: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will
compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or
tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->
[tail]
# etc.
list-compress-depth 03、quicklist 简介
要理解quicklist是什么,⾸先要尝试去理解Redis为什么有了listpack后,还需要设计⼀个quicklist。也就是listpack结构有什么不⾜的地⽅。
为什么需要 quicklist?
-
listpack(类 Array 结构)的优缺点:
- 优点:存储数据连续,通过偏移量可以快速定位,非常适合
LRANGE这样的检索操作 - 缺点:每次新增或删除节点,都需要调整大量节点的位置,对
LPUSH这样的操作非常不友好,数据节点越多,要移动的内存越多
- 优点:存储数据连续,通过偏移量可以快速定位,非常适合
-
纯链表(List)结构的优缺点:
- 优点:增删节点非常方便,只需调整指针,很好地支持
LPUSH、LPOP这样的操作 - 缺点:检索数据只能依次遍历节点,时间复杂度 O(N)
- 优点:增删节点非常方便,只需调整指针,很好地支持
quicklist = Array + 链表的结合体,尽可能综合这两种数据结构的优点。
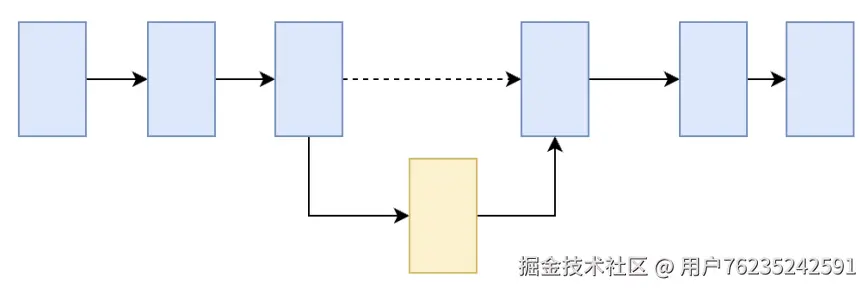
quicklist 大体上可以认为是一个链表结构,里面的每个节点是一个 quicklistNode(quick.h 98 36 行)。
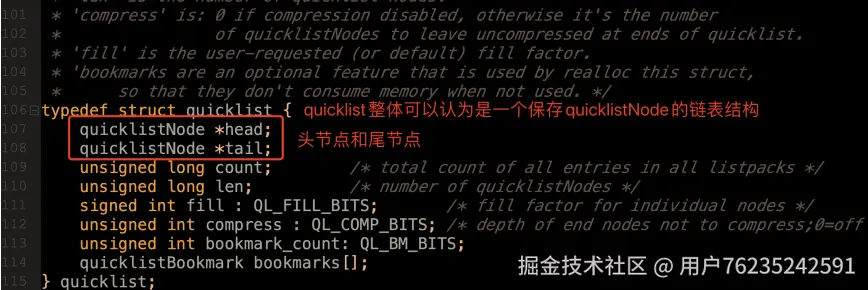
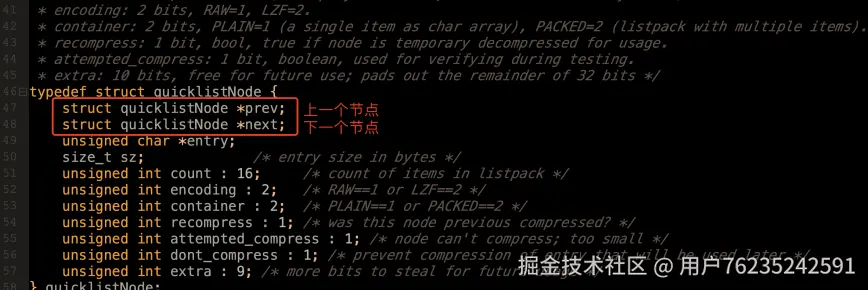
每个 quicklistNode 会保存前后节点的指针(典型的链表结构),而 *entry 实际上就是指向具体保存数据的 listpack 结构。
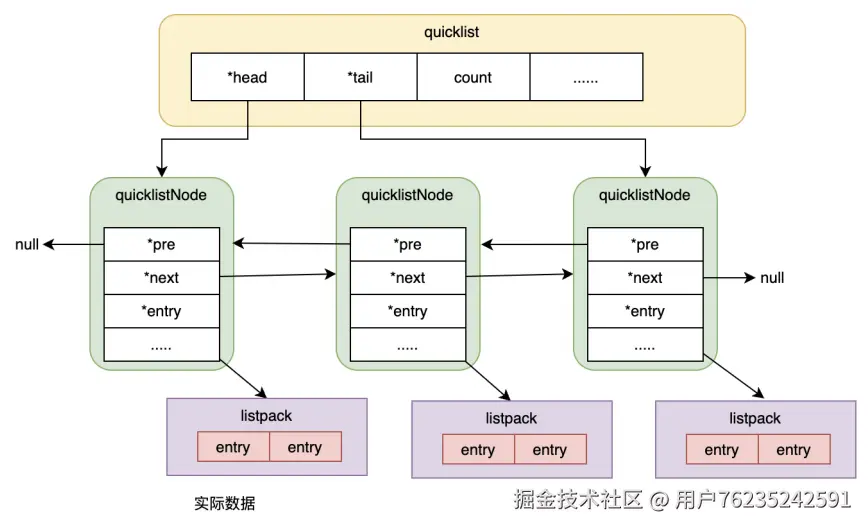 这样就形成了quicklist的整体结构。这个quicklist结构,就相当于是数组Array和链表List的结合体。这就能尽可能的结合这两种数据结构的优点。
这样就形成了quicklist的整体结构。这个quicklist结构,就相当于是数组Array和链表List的结合体。这就能尽可能的结合这两种数据结构的优点。
Redis6 vs Redis7: quicklist 的整体结构在 Redis 很早的版本中就已经成型,区别在于 quicklistNode 中间保存的数据结构。Redis6 以前是 ziplist,到 Redis7 中改为了 listpack。
4、list 底层数据结构总结
- 如果 list 的底层数据量比较小 时,Redis 底层用 listpack 结构保存
- 当 list 的底层数据量比较大 时,Redis 底层用 quicklist 结构保存
- 数据量大小的判断标准由参数
list-max-listpack-size决定:正数表示按 list 结构的数据节点个数判断,负数(-1 到 -5)表示按数据节点的大小判断
五、SET 类型数据结构详解
1、set 数据是如何存储的
Redis 底层综合使用 intset + listpack + hashtable 存储 set 数据。set 数据的子元素也是 k,v 形式的 entry,其中 key 就是元素的值,value 是 null。
bash
# 纯数字 → intset
127.0.0.1:6379> SADD s1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> OBJECT ENCODING s1
"intset"
# 非数字,少量 → listpack
127.0.0.1:6379> SADD s2 a b c d e
(integer) 5
127.0.0.1:6379> OBJECT ENCODING s2
"listpack"
# 超过阈值 → hashtable
127.0.0.1:6379> CONFIG SET set-max-listpack-entries 2
OK
127.0.0.1:6379> SADD s3 a b c d e
(integer) 5
127.0.0.1:6379> OBJECT ENCODING s3
"hashtable"区分底层结构的相关参数:
bash
# 如果 set 的数据都是不超过 64 位的数字(一个 long 数字),就使用 intset 存储
set-max-intset-entries 512
# 如果 set 的数据不是数字,并且数据的大小没有超过下面设定的阈值,就用 listpack 存储
# 如果数据大小超过了其中一个阈值,就改为使用 hashtable 存储
set-max-listpack-entries 128
set-max-listpack-value 642、set 底层数据结构详解
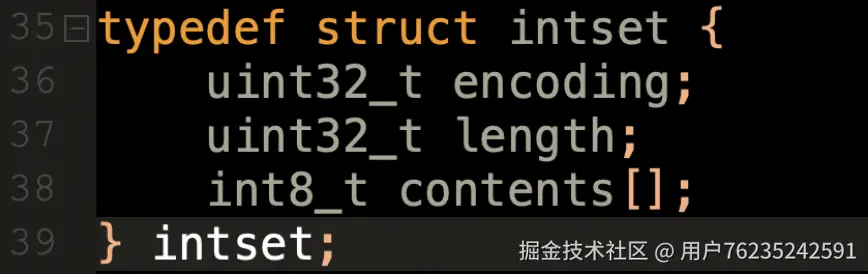
- intset :比较简单的数据结构,就是保存一组整数(
intset.h35 行)
- listpack:之前已经介绍过
- hashtable:我把它理解为redis兜底类型
三种数据结构之间的转换,以 SADD 指令为例(t_set.c 605 行),
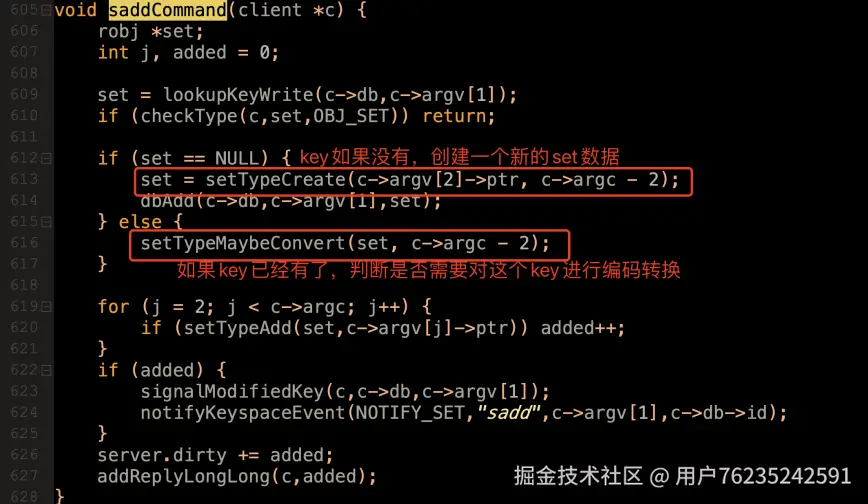 在创建 set 元素时根据子元素的类型判断是用 intset 还是 listpack(
在创建 set 元素时根据子元素的类型判断是用 intset 还是 listpack(t_set.c 40 行)。 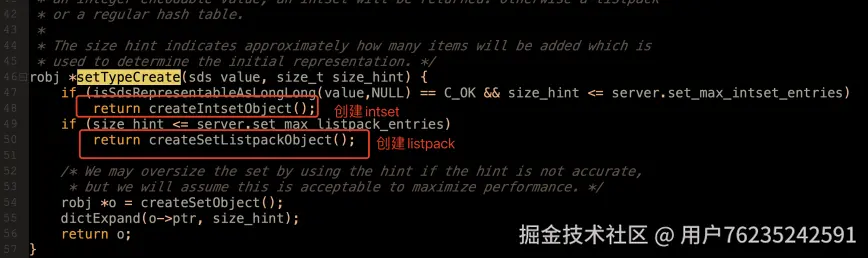 在添加元素时,也会根据参数判断是否需要转换底层编码(
在添加元素时,也会根据参数判断是否需要转换底层编码(t_set.c 59 行)。

六、ZSET 类型数据结构详解
1、zset 数据是如何存储的
Redis 底层综合使用 listpack + skiplist 两种结构来保存 zset 类型的数据。
bash
127.0.0.1:6379> CONFIG GET zset*
1) "zset-max-ziplist-value" 2) "64"
3) "zset-max-listpack-entries" 4) "128"
5) "zset-max-ziplist-entries" 6) "128"
7) "zset-max-listpack-value" 8) "64"
127.0.0.1:6379> ZADD z1 80 a
(integer) 1
127.0.0.1:6379> OBJECT ENCODING z1
"listpack"
# 超过阈值 → skiplist
127.0.0.1:6379> CONFIG SET zset-max-listpack-entries 3
OK
127.0.0.1:6379> ZADD z2 80 a 90 b 91 c 95 d
(integer) 4
127.0.0.1:6379> OBJECT ENCODING z2
"skiplist"区分底层数据结构的参数有两个:
bash
# 类似于 hash 和 list,从 value 的元素数量和数据大小两方面进行区分
zset-max-listpack-entries 128
zset-max-listpack-value 642、zset 底层数据结构详解
zset 类型底层数据结构有 skiplist 和 listpack 两种。listpack 之前已经介绍过。
为什么需要 skiplist?
zset 类型的数据,底层需要先按照 score 进行排序,排序过程中是需要移动内存的:
- 如果节点数据不是太多,将这些内存移动完后重新整理成一个类似 Array 的 listpack 结果是可以接受的
- 如果数据量太大,频繁移动内存开销就比较大。这时以链表这种零散的数据结构是比较合适的
但对于一个单链表结构来说,要检索链表中的某一个数据,只能从头到尾遍历链表,时间复杂度是 O(N),性能比较低。

skiplist(跳表)的优化思路:
构建多层逐级缩减的子索引,用更多的索引来提升搜索的性能。
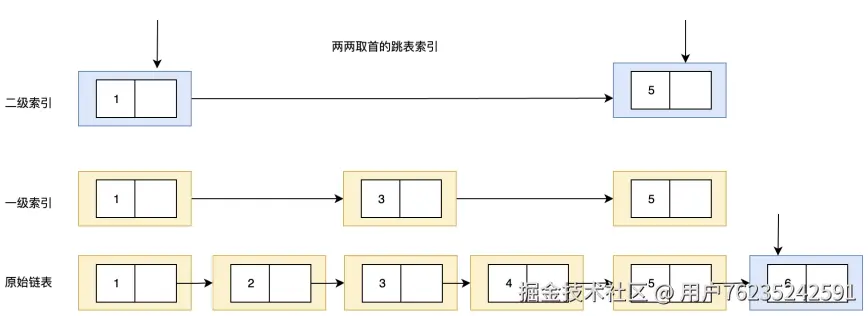
skiplist 是一种典型的用空间换时间的解决方案:
- 优点:数据检索性能比较高,时间复杂度 O(logN),空间复杂度 O(N)
- 缺点:更新链表时,维护索引的成本相对更高
- 适用场景:数据量比较大,且读多写少的应用场景
Redis 天生就是针对读多写少的应用场景,而数据量的大小通过之前看到的两个参数从数据条目数和数据大小两个方面来进行区别。
底层数据结构转换的逻辑,从 ZADD 操作入手(t_zset.c 1838 行),
 往下跟踪
往下跟踪 zaddGenericCommand 方法(t_zset.c 1169 行)可以看到转换逻辑。
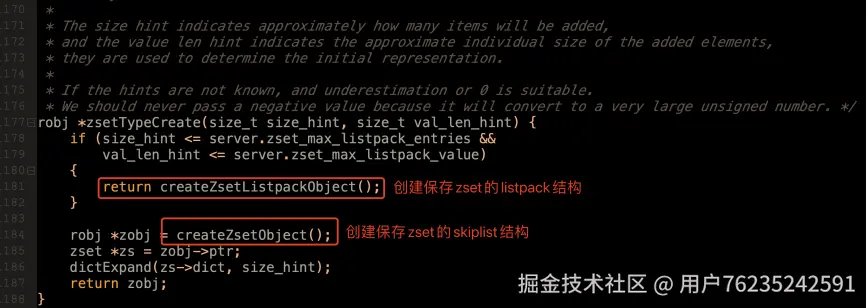
3、zset 底层数据结构总结
Redis 底层综合使用 listpack + skiplist 两种数据结构来保存 zset 类型的数据:
- 当 zset 数据的 value 数据量比较小 时,使用 listpack 结构保存
- value 数据量比较大 时,使用 skiplist 结构保存
Redis 中衡量 zset 的 value 数据大小的参数有两个:
zset-max-listpack-entries:从 value 的元素数量方面进行区分zset-max-listpack-value:从数据大小方面进行区分
七、Redis总结
Redis 中几种常见数据结构的底层结构汇总:
| Redis 版本 | string | set | zset | list | hash |
|---|---|---|---|---|---|
| Redis 6 | SDS(动态字符串) | intset + hashtable | skiplist + ziplist | quicklist + ziplist | hashtable + ziplist |
| Redis 7 | SDS | intset + listpack + hashtable | skiplist + listpack | quicklist + listpack | hashtable + listpack |
Redis 为什么这么快?
这是一个没有标准答案的问题。Redis 为了提升整体的运行速度,在各个方面都做了非常极致的优化:
- 无锁化的线程模型
- 层层递进的集群架构
- 灵活定制的底层数据结构(本文重点)
- 极致优化的算法实现
但是,Redis 的价值并不仅仅是一个"快"。在快的同时,Redis 也在不断扩展新的业务功能和应用场景:
- 集中式缓存
- 分布式锁
- 分布式主键生成
- NoSQL 数据库
- 向量搜索
作为 Java 程序员,如何在复杂的业务场景中最大程度用好 Redis,发挥 Redis 的强大性能,是一个绕不开的基本功。
附:关键知识点总结
| 知识点 | 说明 |
|---|---|
| redisObject | Redis 所有数据的统一封装对象,包含 type、encoding、lru、refcount、*ptr 字段 |
| SDS | Simple Dynamic String,Redis 对 C 字符串的封装,添加 len 等字段,O(1) 获取长度,支持二进制安全 |
| ziplist | Redis6 核心数据结构,内存紧凑,但存在连锁更新问题,Redis7 中已被 listpack 取代 |
| listpack | ziplist 的升级版,entry 记录自身长度(而非前一个 entry 的长度),解决了连锁更新问题 |
| quicklist | 链表 + listpack 的结合体,兼顾检索效率和增删效率 |
| skiplist | 跳表,多层索引链表,时间复杂度 O(logN),空间换时间,适合读多写少场景 |
| intset | 整数集合,用于存储纯整数的 set |