写在前面
之前写了一篇关于慢请求排查的实战记录(传送门),本来以为把 Arthas 追调用链、排查 O(n²) 循环什么的讲清楚就差不多了。
但写完之后总觉得少了点什么。
回想自己背面试题的时候,"深分页为什么慢"、"子查询为什么不如 JOIN"、"索引失效的场景有哪些" 这些问题,能说得头头是道。可真要我解释清楚到底慢在哪里、具体慢多少,我发现自己其实也就知道个大概。
所以趁周末,我搭了个测试环境,自己动手跑了一遍 EXPLAIN,把那些背烂了的八股一个个验证了一遍。
纸上得来终觉浅,绝知此事要躬行。 ------古人诚不我欺。
⚠️ 说明:文中所有截图均为本地测试环境数据。因为不同的数据量、不同的机器配置跑出来的结果差异很大
案例一:深分页,到底"深"在哪里?
被问烂了的问题
面试的时候十有八九会问到:"MySQL 分页为什么越往后越慢?怎么优化?"
标准回答人人会背:LIMIT 90000, 10 虽然只要 10 条,但 MySQL 得先捞 90000 行再丢掉,偏移量越大越慢。优化用游标分页。
但说实话,我之前从来没亲眼见过这个过程到底有多慢。于是动手试了一下。
先看看正常的查询是什么样
作为对比基准,先跑一条最普通的全表查询:
sql
SELECT * FROM orders;
此时表里数据量不大,查询很快。下面我们模拟深分页的场景。
写一个"教科书式"的慢 SQL
vbnet
SELECT * FROM orders ORDER BY id LIMIT 90000, 10;
- 执行耗时 :
0.425秒 - 扫描行数:约 90000+ 行
只取 10 条数据,却翻了 9 万行。这个反差确实很直观。
看看 EXPLAIN 怎么说
跑一下 EXPLAIN,看看 MySQL 自己是怎么说的:
vbnet
EXPLAIN SELECT * FROM orders ORDER BY id LIMIT 90000, 10;
| 字段 | 值 |
|---|---|
| type | index |
| rows | 90010 |
| Extra | null |
MySQL 老老实实告诉你它打算扫多少行------跟你想的差不多,是吧?
换成游标分页
vbnet
SELECT * FROM orders WHERE id > 90000 ORDER BY id LIMIT 10;
- 执行耗时 :
0.238 - 扫描行数:仅 10 行
再跑一遍 EXPLAIN:
vbnet
EXPLAIN SELECT * FROM orders WHERE id > 90000 ORDER BY id LIMIT 10;
| 字段 | 值 |
|---|---|
| type | range |
| rows | 99629 |
| Extra | Using where |
一点感想
实际跑完一圈下来,最直观的感受就是:纸上说的"扫描行数"和"执行时间"不是抽象概念,是实打实能看得到的差距。
以前背八股的时候,"LIMIT 90000, 10 需要扫描 90010 行" 这句话对我来说就是个知识点。当我在终端看到 rows 那栏的数字时,才发现------哦,原来这就是"多扫了 9 万行"的感觉。
优化建议:
- 能用游标分页就用游标分页,这也是现在主流业务的做法
- 实在要传统分页,考虑在前端限制最大页数(比如只让翻 100 页)
- 覆盖索引 + 延迟关联也是路,不过不如游标分页直接
案例二:关联子查询 vs JOIN------面试题的"照妖镜"
又一个经典场景
vbnet
SELECT o.*,
(SELECT u.phone FROM users u WHERE u.id = o.user_id) AS phone
FROM orders o
WHERE o.status = 1;这条 SQL 看起来挺"优雅"的------一条语句就搞定了订单和用户的关联,还不用 JOIN。但实际上呢?

- 执行耗时 :
0.608
问题在哪
关联子查询(Correlated Subquery)的特点是:外层查出来多少行,内层子查询就跑多少遍。
假设 orders 表有 1 万条 status = 1 的记录,那这个子查询就被执行 1 万次。就算子查询走了索引,1 万次也是 1 万次开销。
EXPLAIN 看一下:
vbnet
EXPLAIN SELECT o.*,
(SELECT u.phone FROM users u WHERE u.id = o.user_id) AS phone
FROM orders o
WHERE o.status = 1;
| 字段 | 值 |
|---|---|
| type | ALL(orders)/ eq_ref(users) |
| rows | 199258(orders)/ 1(users) |
| Extra | Using where(orders)/ null(users) |
换成 JOIN 试试
ini
SELECT o.*, u.phone
FROM orders o
LEFT JOIN users u ON o.user_id = u.id
WHERE o.status = 1;
- 执行耗时 :
0.546
EXPLAIN:
ini
EXPLAIN SELECT o.*, u.phone
FROM orders o
LEFT JOIN users u ON o.user_id = u.id
WHERE o.status = 1;
| 字段 | 值 |
|---|---|
| type | ALL(orders)/ eq_ref(users) |
| rows | 199258(orders)/ 1(users) |
| Extra | Using where(orders)/ null(users) |
一点感想
这个案例其实是我最"震撼"的。背了无数遍"子查询不如 JOIN",但自己动手验证之前,我一直以为这差别也就一点点。
跑完之后发现,一个 N 次子查询和一个 JOIN,在数据量上去之后完全不是一个量级。
但是这也不是绝对的------我就见过有人把大表 JOIN 连到七八个,结果比子查询还慢。工具是死的,人是活的,具体情况具体分析才是正解。
案例三:IN (1,2,3,...,2000) vs BETWEEN------一个被忽视的细节
场景
sql
SELECT * FROM orders WHERE user_id IN (1,2,3,...,2000);这个写法在某些 ORM 或者代码生成器里很常见------查一批用户的订单,顺手就把 ID 列表拼成 IN 了。
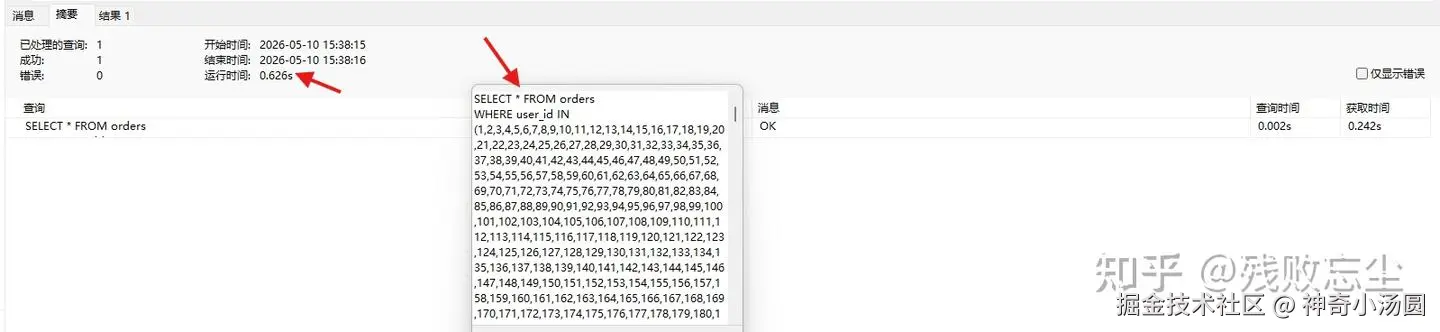
- 执行耗时 :
0.626秒
EXPLAIN 看看
sql
EXPLAIN SELECT * FROM orders WHERE user_id IN (1,2,3,...,2000);
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
换成 BETWEEN
sql
SELECT * FROM orders WHERE user_id BETWEEN 1 AND 2000;
- 执行耗时 :
0.573秒
EXPLAIN:
sql
EXPLAIN SELECT * FROM orders WHERE user_id BETWEEN 1 AND 2000;
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
什么场景有效
IN vs BETWEEN 这个对比有一个前提:你的值得是连续的范围。
如果你要查的是 IN (3, 7, 15, 22, 99) 这种离散值,那 BETWEEN 当然没法用。这时候可以考虑:
- 创建临时表,把目标值塞进去,用 JOIN 取代 IN
- 分批查询,控制每批 IN 列表个数(MySQL 默认
eq_range_index_dive_limit是 200)
案例四:LIKE 模糊匹配------前% vs 后%
场景
sql
SELECT * FROM orders WHERE remark LIKE '%keyword%';很多时候业务需求确实需要"前模糊"查询,但代价是什么呢?

- 执行耗时 :
0.352秒
EXPLAIN 看看
sql
EXPLAIN SELECT * FROM orders WHERE remark LIKE '%keyword%';
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
改用后缀匹配
sql
SELECT * FROM orders WHERE remark LIKE 'keyword%';如果业务上能接受只查"以 keyword 开头"的记录,性能差距可不是一星半点:

- 执行耗时 :
0.326秒
EXPLAIN 对比
sql
EXPLAIN SELECT * FROM orders WHERE remark LIKE 'keyword%';
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
一点感想
这个知识点背八股的时候记得可牢了------"LIKE 前面加 % 会导致索引失效"。但是真的跑完对比一看,差距比我想象中大得多。
但是说实话,很多业务场景就是需要"包含"而非"以什么开头",这时候想用索引只能上**全文索引(FULLTEXT)** 或者ES 搜索引擎了。建议:
- 能用后缀匹配就用后缀匹配(
keyword%),直接走索引 - 非要前模糊且数据量大:考虑引入 ES
- 数据量小的表(百万以内),MySQL 做全表扫描也能接受,看实际场景
- 也可以考虑用覆盖索引减少回表开销
案例五:OR 条件------索引的"隐形杀手"
场景
ini
SELECT * FROM orders WHERE user_id = 100 OR amount > 5000;OR 条件在八股里也是高频考点------OR 两边必须都有索引才可能走索引,否则全表扫描。

- 执行耗时 :
0.490秒
EXPLAIN 看看
ini
EXPLAIN SELECT * FROM orders WHERE user_id = 100 OR amount > 5000;
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
优化思路
OR 的最佳替代方案是 UNION ALL------把两条各自能走索引的查询拆开,再合并结果:
sql
SELECT * FROM orders WHERE user_id = 100
UNION ALL
SELECT * FROM orders WHERE amount > 5000 AND user_id != 100;(这条 SQL 的截图就不放了,大家感兴趣可以在本地试一下)
一点感想
OR 这个 case 说实话在日常开发中见得不算太多,但一旦遇到,如果数据量大就非常头疼。面试也高频,算是八股里的标配题了。
优化建议:
- 优先考虑用
UNION ALL替代 OR - 确保 UNION 中每个子查询都能独立走索引
- 如果 OR 两边的条件能转化为 AND,优先用 AND
案例六:IS NOT NULL------NULL 值的麻烦
场景
sql
SELECT * FROM orders WHERE remark IS NOT NULL;IS NULL 和 IS NOT NULL 能不能走索引?答案是:取决于数据分布和 MySQL 版本。但 IS NOT NULL 在数据比率高的情况下大概率全表扫描。

- 执行耗时 :
0.464秒
EXPLAIN
sql
EXPLAIN SELECT * FROM orders WHERE remark IS NOT NULL;
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
一点感想
NULL 值在 MySQL 里本身就是个"不太干脆"的存在。IS NOT NULL 不走索引的核心原因是:如果大部分行的 remark 都不为 NULL,那优化器认为走索引还不如全表扫描快。
反过来,如果 IS NOT NULL 筛选后只剩很小一部分数据,是有可能走索引的。
优化建议:
- 表设计时尽量避免 NULL,用 NOT NULL + 默认值(空字符串、0 等)
- 如果业务必须用 NULL,考虑缓存其他字段的索引值
- 实际查询中,
IS NOT NULL是最后的选择------能加其他条件就尽量加
案例七:多条件查询------无联合索引 vs 有联合索引
场景
当我们在 WHERE 中写了多个条件时,有没有联合索引差别有多大?我创建了一个 (user_id, status) 的联合索引来做对比。
先看看只用 status 条件查询------无联合索引发挥作用
ini
SELECT * FROM orders WHERE status = 2;只用 status 条件时,联合索引(user_id, status)用不上(违背最左前缀原则),效果很差:

- 执行耗时 :
0.434秒
ini
EXPLAIN SELECT * FROM orders WHERE status = 2;
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
再看看带上 user_id 条件------联合索引生效
ini
SELECT * FROM orders WHERE user_id = 100 AND status = 2;带上 user_id 后,联合索引(user_id, status)就能完美利用,差距非常明显:

- 执行耗时 :
0.232秒
EXPLAIN:
ini
EXPLAIN SELECT * FROM orders WHERE user_id = 100 AND status = 2;
| 字段 | 值 |
|---|---|
| type | ref |
| rows | 80 |
| Extra | null |
一点感想
这个 case 和前面的 OR 形成有趣对比------AND 在一个合适的联合索引下可以高效检索,OR 却很难用好索引。同样是对多个字段做条件筛选,一个 AND 一个 OR,性能天差地别。
而这里更想强调的是最左前缀原则 ------(user_id, status) 联合索引只对包含 user_id 的查询有效,光查 status 是走不上的。建了索引不等于能用上,还得看怎么写的。
联合索引优化建议:
(user_id, status)的联合索引能完美覆盖WHERE user_id = ? AND status = ?这类查询- 联合索引的顺序很重要:高频查询、选择性高的字段放左边
- 不一定要给每个 AND 条件都建联合索引,单列索引 + 索引合并也能解决问题
- 但索引合并有额外开销,数据量大时联合索引更优
案例八:类型转换导致的索引失效
场景
有时候表里明明有索引,查询还是慢------别急着怀疑索引坏了,先看看类型匹不匹配。
假设 order_no 字段是 VARCHAR 类型,也建了索引。跑两个看起来差不多的查询,结果天差地别。
正确写法:带上引号
ini
SELECT * FROM orders WHERE order_no = '4';字符串查字符串,类型匹配,索引正常生效:

- 执行耗时 :
0.216秒
EXPLAIN:
ini
EXPLAIN SELECT * FROM orders WHERE order_no = '4';
| 字段 | 值 |
|---|---|
| type | ref |
| rows | 1 |
| Extra | null |
错误写法:没加引号(隐式类型转换)
ini
SELECT * FROM orders WHERE order_no = 4;整数比较 VARCHAR------MySQL 会对字段做隐式类型转换,索引直接失效:

- 执行耗时 :
0.399秒
EXPLAIN:
ini
EXPLAIN SELECT * FROM orders WHERE order_no = 4;
| 字段 | 值 |
|---|---|
| type | ALL |
| rows | 199258 |
| Extra | Using where |
同样有索引,只是一个引号的区别,执行计划就完全不同了。
一点感想
这个 case 其实比"缺少索引"更隐蔽------少了索引你一眼就能看出来 EXPLAIN 的 type 是 ALL,但类型不匹配的时候,你以为索引已经建了应该没问题,结果 MySQL 默默地做了类型转换,索引形同虚设。
优化建议:
- 写 SQL 时注意字段类型,VARCHAR 字段一定要加引号
- 代码中用 ORM 的话,参数类型要和数据库字段类型对齐
- 排查慢 SQL 时,如果发现索引建了但没走,先看有没有类型不匹配的问题
八个案例放在一起看
| 场景 | 问题 | 优化方向 | 关键点 |
|---|---|---|---|
| LIMIT 深分页 | LIMIT 90000, 10 扫了再丢 | 游标分页 WHERE id > xxx | 利用主键索引精准定位 |
| 关联子查询 | 外层每行执行一次子查询 | 改为 JOIN | JOIN 一次搞定 |
| IN 大量值 | 2000 个值逐个索引查找 | BETWEEN 或临时表 JOIN | 连续值用范围查询 |
| LIKE 模糊 | %keyword% 前模糊不能走索引 | keyword% 后缀匹配 / 全文索引 | 前 % 无解,只能换方案 |
| OR 条件 | OR 两边都有索引才可能走 | UNION ALL 拆开 | 拆成多条独立走索引的查询 |
| IS NOT NULL | 数据占比高时优化器选全表扫 | 避免 NULL 设计 | NOT NULL + 默认值 |
| 多条件查询 | 无联合索引时用不上最左前缀 | 建联合索引 | 最左前缀原则 |
| 隐式类型转换 | 索引建了但类型不匹配导致失效 | VARCHAR 带引号 | 类型匹配比加索引更隐蔽 |
通(ren)用(sheng)建议
- 背了要动手:八股可以在面试的时候帮你过关,但只有亲手跑一遍 EXPLAIN,那些结论才会变成你自己的经验
- EXPLAIN 是基本功:排查慢 SQL 的时候,第一件事就是 EXPLAIN。先看 type(至少要 range)、rows(估算扫描行数)和 Extra(出现 filesort、temporary 要警惕)
- 索引不是银弹:索引能解决很多问题,但不是所有问题都能靠加索引解决。深分页、LIKE 前模糊这些问题,加再多索引也没用
- 先检查有没有索引:很多慢 SQL 其实没有高深的原理------看看 WHERE 条件的列有没有对应索引就行
- 具体情况具体分析:没有放之四海皆准的优化方案,写 SQL 的时候要多想想数据量级和业务场景
写在最后
这篇文章更像是我自己的一个学习笔记------把那些背过的、似懂非懂的八股,亲手在 MySQL 里验证了一遍,然后记录下自己的感受和发现。
如果你也是那种"背了好多但总觉得不踏实"的人,强烈建议你花一个周末,搭个测试环境,把常见的问题 SQL 都跑一遍 Explain。真的会有种"原来如此"的感觉。
文章里的耗时和 Explain 字段我留了空,因为不同的数据量级和机器配置跑出来差异很大。后续我会补上几组不同量级(10 万、100 万、1000 万行)的对比数据,让它更有参考价值。
另外,关于慢 SQL,你还有什么亲身经历或者踩过的坑吗?欢迎在评论区分享,说不定能帮到更多人 🙏
有问题或者觉得我哪里写错了,也欢迎指正。我只是个在学习路上挣扎的后端开发,大家互相交流,一起进步。