一、硬件加速的三条主线:网络、存储、算力
最近一段时间,业界关于 "Kernel Bypass 网卡 + 超融合" 的讨论再度热起来。低延时网卡(Solarflare、Mellanox、Cisco ExaNIC 等)绕开内核协议栈,把网络收发延迟从十几微秒压到个位数,确实是金融极速交易场景的关键突破。
站在云平台厂商的视角,Kernel Bypass 在整套硬件加速体系中只属于单点加速手段 。一个真正能够支撑极速交易、量化策略、AI 训练推理、信创、安全敏感行业场景的智算云平台,需要在网络、存储、算力三条主线上同时具备硬件加速能力,并通过虚拟化层把这些能力以可调度、可迁移、可统一管理的方式交付给业务。
云轴科技ZStack用四大产品线承接这一架构判断:

- ZCF(ZStack Cloud Foundation):
私有云核心平台,承载 SR-IOV、Kernel Bypass、OVS-DPDK、DPU、NVMe-oF 接入等计算侧硬件加速能力,默认搭配 ZBS(ZStack Block Storage) 作为底层分布式存储,提供 RDMA 零拷贝、SPDK 用户态等存储侧加速能力;
- ZVF(ZStack Virtualization Foundation):
虚拟化产品线(含 ZSphere、ZLR),承担 VMware 替代主力,把 ZCF 的硬件加速能力打包给虚拟化场景客户;
- AIOS 智塔:
智算平台,负责 GPU/真武 810E 等异构算力调度、dGPU 弹性切片、智算高性能网络;
- HCI(ZStack Cube 超融合一体机):
把 ZCF + ZVF + AIOS 的能力打包成软硬一体方案,覆盖金融极速交易一体机、信创一体机、智算一体机、阿里云联合一体机。
本文按照"网络、存储、算力"三条主线展开 ZCF / ZBS / AIOS / ZVF / HCI 的能力,拆解 ZStack 在金融极速交易、信创云、VMware 替代、AI Infra 一体机几类典型客户场景中的落地路径。
ZStack 能做到全栈加速的三个前提条件:第一,完整的产品矩阵------从私有云、虚拟化、存储、智算到超融合一体机,所有产品在同一套代码主线下演进;第二,阿里云控股带来的软硬协同------真武 810E、神龙、通义大模型与 ZStack 在产品规划层面拉通;第三,十余年在金融、信创、政企、能源、AI 场景的实际交付沉淀,把零散的加速技术沉淀成可复制的解决方案模板。
下图把 ZStack 的全栈硬件加速能力按"业务层 → 平台加速能力层 → 硬件层"三层 × "网络 / 存储 / 算力"三条主线整理成一张总览图,后续章节按此结构展开。
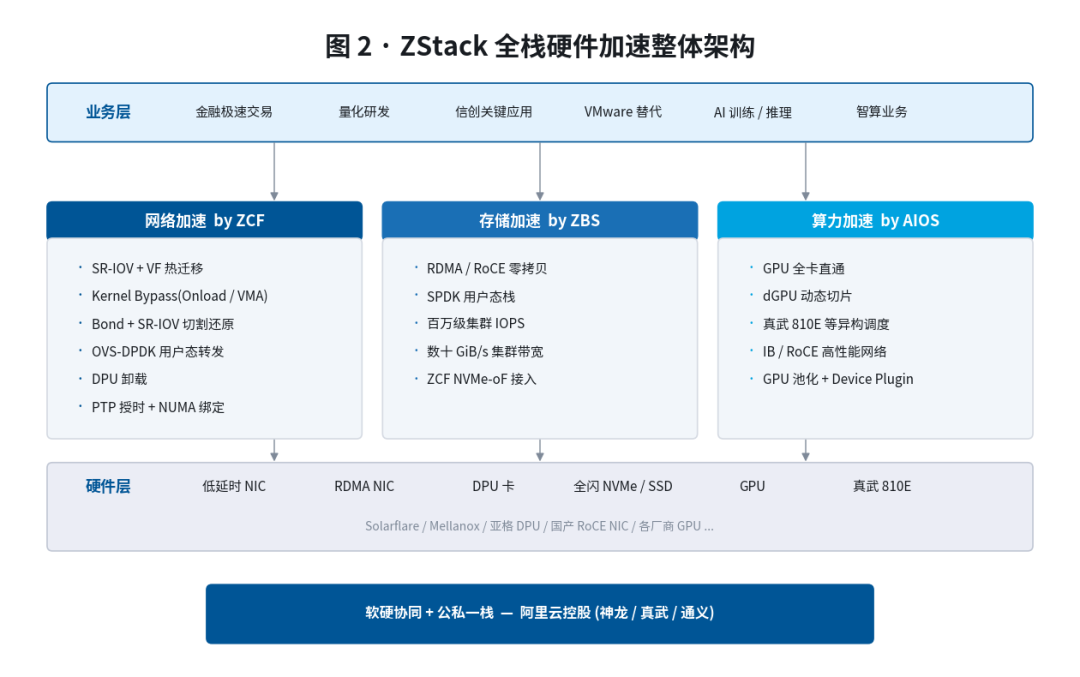
二、ZCF 计算侧:从 SR-IOV 到 DPU 的四级火箭
ZCF 是 ZStack 私有云的核心平台,网络与存储的所有硬件加速能力都首先在 ZCF 上落地,再通过 ZVF、AIOS、HCI 三个产品线下传到对应场景。
ZCF 在网络硬件加速方向规划了四级火箭:
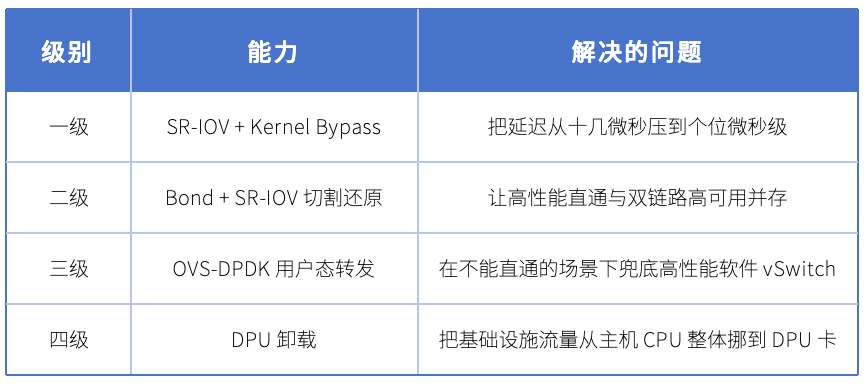
外加 NVMe-oF 接入(存储接入协议)、PTP 授时、NUMA 绑定作为辅助调优能力。
2.1 SR-IOV + PCI 直通:把网卡"切片"给虚拟机
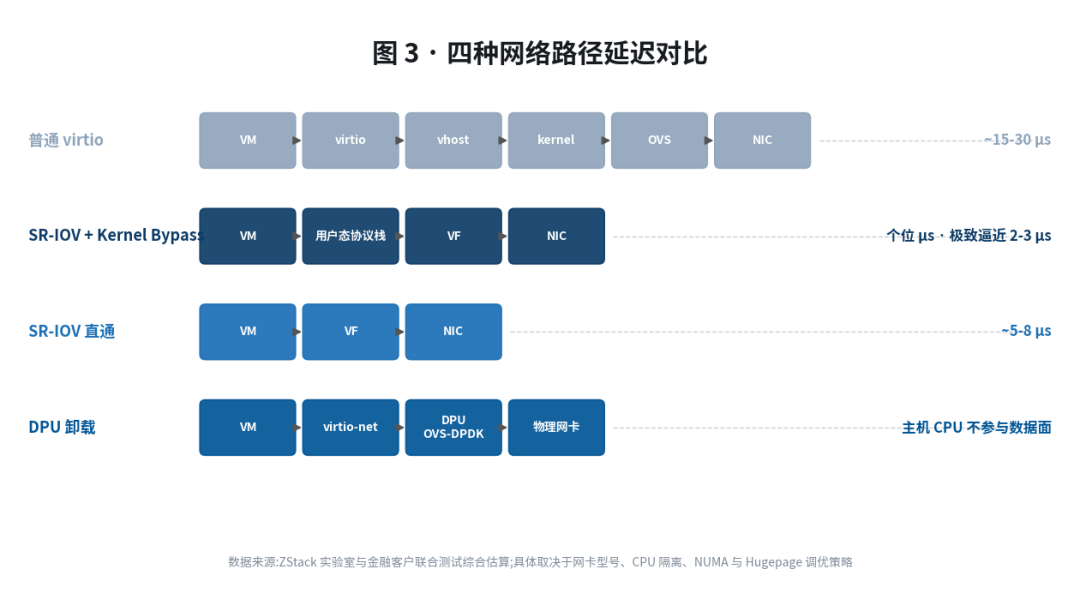
SR-IOV(Single Root I/O Virtualization)是 PCIe 标准定义的硬件虚拟化技术。一块物理网卡可以被划分为多个 VF(Virtual Function),每个 VF 在虚拟机眼中等同于一块独立的物理网卡,绕开了 Hypervisor 的 vSwitch 转发路径。
ZCF 自 4.x 版本起完整支持 SR-IOV:
-
延迟表现:
-
基于 ZStack 内部实验室数据,SR-IOV 虚拟机网卡延迟约为普通虚拟网卡的 1/3,小包转发能力可达 2.5M pps 量级;
-
网卡兼容性:
-
覆盖 Intel、Mellanox、Solarflare 等主流低延时与 RDMA 网卡,以及多款国产 RoCE 网卡,具体认证清单以版本兼容性矩阵为准;
-
配合 Kernel Bypass 用户态协议栈(Onload / VMA / 自研用户态 TCP):
-
在 ZStack 与低延时网卡厂商、金融客户的联合测试中,端到端延迟可达个位微秒级,在极致调优场景下进一步逼近 2--3 微秒区间;具体数值取决于网卡型号、CPU 隔离与 NUMA 调优策略。
2.2 ZCF 差异化能力一:VF 网卡热迁移
行业里大部分超融合平台对 SR-IOV 虚拟机的处理是"绑死在物理机上"------一旦做了 VF 直通,就失去了热迁移能力。这对金融生产环境是不可接受的,因为硬件故障、内核补丁、机房腾挪都需要无中断的迁移窗口。
ZCF 通过VF 热迁移机制(基于 qemu/libvirt 的 VFIO 迁移框架,叠加 ZStack 调度层与网络后备通道的工程化封装),实现 SR-IOV 虚拟机在不停机的前提下跨物理机迁移:
- 源主机上 VF 被动态从虚拟机解绑;
- 网络流量短暂切到 virtio 后备通道;
- 迁移完成后,目标主机上重新绑定新的 VF;
- 整个切换过程对上层应用透明。
这一能力在多家头部券商的 OMS、行情分发、风控引擎场景中已经验证。
2.3 ZCF 差异化能力二:双网卡 Bond + SR-IOV 切割还原
金融生产环境对链路冗余的要求是不可妥协的------单网卡故障必须能秒级切换。但传统 SR-IOV 方案与 Bond 几乎不兼容:VF 直通后,Bond 的活动备援逻辑无法生效。
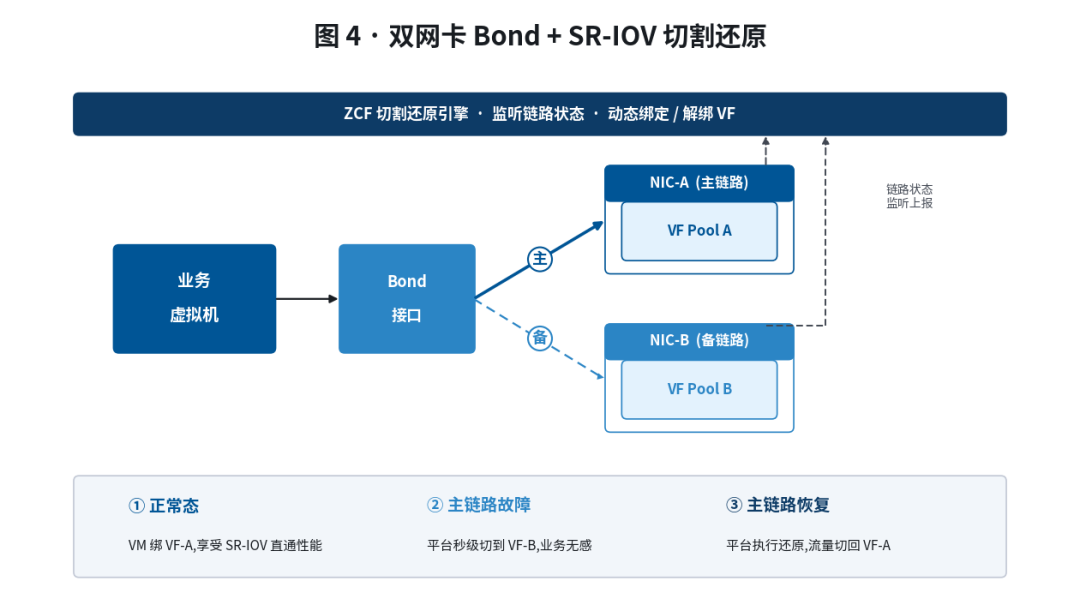
ZCF 较新版本引入 双网卡 Bond 支持 SR-IOV 切割还原机制:
- 平台为每张物理网卡创建 VF 池;
- 业务虚拟机使用 Bond 模式接入,底层映射到主备两张物理网卡的 VF;
- 主链路故障时,平台自动将虚拟机网卡从主 VF 切换到备 VF,业务感知不到中断;
- 故障恢复后,平台执行"还原"动作,把流量切回主链路,保持原有性能基线。
这一能力让 ZCF 第一次在云平台层面把高性能(SR-IOV 直通)和高可用(双链路 Bond)两个看似矛盾的目标同时满足。
2.4 ZCF 差异化能力三:OVS-DPDK 用户态转发兜底
不是所有业务都适合 SR-IOV 直通------VF 数量受网卡硬件限制,大规模租户隔离、复杂 SDN 策略、灵活的安全组规则,这些场景仍然需要软件 vSwitch。
ZCF 近期版本上线 OVS-DPDK 用户态转发:把数据平面从内核态搬到用户态,通过 DPDK 的 PMD(Poll Mode Driver)轮询机制,把 vSwitch 的吞吐和延迟拉到接近硬件直通水平,同时保留完整的 OVS 流表、VXLAN、安全组、QoS 能力。
2.5 ZCF 差异化能力四:DPU 方案 ------ 把基础设施"挪到卡上"
ZCF 已规划DPU 方案 ,与亚格等 DPU 厂商完成深度对接,在客户环境进入联合验证阶段。这是网络硬件加速的第四级火箭:把网络、存储、管理三类基础设施流量,从主机 CPU 卸载到 DPU 卡上。
技术要点:
-
弹性裸金属新形态:
-
ZCF 定义了新的弹性裸金属虚拟化类型,DPU 卡直接接管裸金属节点的上下电、云盘加载/卸载、网络配置、网卡创建等动作,替代传统弹性裸金属架构中的"网卡节点 + 部署网络"角色;
-
DPU 卡上的 OVS-DPDK:
-
网络数据面运行在 DPU 卡上的高性能 OVS-DPDK,主机侧 CPU 不再参与 vSwitch 转发,释放出来的 CPU 全部归业务;
-
存储、管理、业务流量统一收敛:
-
DPU 作为"网关节点"承载多类流量,简化主机网卡数量,降低布线复杂度;
-
商务模式延续:
-
DPU 方案是现有 ZCF 弹性裸金属能力的延伸,沿用同一套授权模式,客户无需重新购买独立产品线。
对客户的直接价值:主机 CPU 利用率提升、网络吞吐与延迟逼近硬件极限、机柜密度提升、整体 TCO 下降 。
2.6 ZCF 计算侧的 NVMe-oF 接入
NVMe-oF 是 ZCF 计算侧的存储接入协议。ZCF 作为 initiator,把后端存储(第三方 NVMe-oF 存储阵列)以块设备的形式直接挂载给虚拟机,跳过传统的 iSCSI / FC SAN 协议栈,获得接近本地 NVMe 盘的延迟与吞吐。
这条路径与 SR-IOV、DPU、ZBS RDMA 在端到端层面叠加,构成 ZCF 计算侧的全用户态、零拷贝存储高速公路。
2.7 PTP 精确授时与 NUMA 绑定
极速交易场景对时钟一致性有微秒级要求。ZCF 配合硬件 PTP(IEEE 1588)网卡,实现虚拟机时钟与主时源的亚微秒到微秒级对齐;配合 CPU 绑核、NUMA 亲和、Hugepage 预分配、中断隔离等一整套调优手段,平台层把硬件性能完整释放给业务。
形成的组合拳是:极致延迟 → SR-IOV + Kernel Bypass + PTP;大规模租户 + 灵活策略 → OVS-DPDK;双高(性能+可用)→ Bond + SR-IOV 切割还原;基础设施卸载 + CPU 释放 → DPU **。**客户可以按业务画像选型,不被单一技术路线绑死。
三、ZBS 存储侧:RDMA 零拷贝与高 IOPS 集群
网络硬件加速只是入口,存储侧的硬件加速同样关键。ZStack 自研分布式存储 **ZBS(ZStack Block Storage)**在这条路径上的工程投入:
3.1 RDMA / RoCE 零拷贝集群网络
ZBS 全面支持 RDMA(RoCE v2),节点间数据传输绕过 CPU 和内核协议栈,实现真正的零拷贝。基于 ZStack 实验室与典型客户环境的实测:
- 单卷随机读 IOPS 可达数十万级别;
- 集群聚合 IOPS 随节点规模线性扩展,可进入百万级以上区间;
- 集群聚合带宽随网络规模线性扩展,可进入数十 GiB/s以上区间;
- 4K 随机读延迟稳定在亚毫秒级 ,在金融极速交易等极致场景可达百微秒级。
3.2 SPDK 用户态存储栈
ZBS 服务端整合 SPDK 用户态存储栈,把存储 IO 路径从内核态搬到用户态轮询模式,与 ZCF 计算侧的 DPDK/SR-IOV/DPU/NVMe-oF 形成端到端的"用户态高速公路"。
3.3 落地场景
ZBS 已经在多个金融、能源、运营商生产环境运行:
- 某全国性期货交易所:核心交易系统底层存储,支撑数万合约实时撮合;
- 某头部量化基金:高频策略回测平台,千万级订单/秒级别压力测试;
- 多家政企信创云:核心业务底层存储,满足国密合规与性能双重要求。
四、AIOS 智算平台:算力 + 高网融合
第三条主线是算力。AI 训练推理、图形渲染、科学计算场景,GPU/异构加速卡是核心生产力。AIOS 智塔是 ZStack 在智算赛道的核心产品。
4.1 GPU 全直通
AIOS 支持 NVIDIA、AMD、寒武纪、海光 DCU、华为昇腾、阿里平头哥真武 810E 等主流加速卡的全卡直通:虚拟机独占整张物理卡,性能损耗趋近于零,适合 LLM 训练、大规模推理。
4.2 dGPU:动态 GPU 虚拟化
ZStack Cloud 发布 动态 GPU 虚拟化(dGPU)方案,并在 AIOS 智塔产品线中作为 GPU 资源管理的能力之一对外提供:
-
显存与算力按需切分:
-
在单张物理 GPU 上创建多个 vGPU 实例,显存粒度可达 GB 级别,算力按比例分配;
-
资源调度统一管理:
-
GPU 资源与 CPU、内存、存储、网络资源池一体化管理,纳入 AIOS 调度面;
-
硬件覆盖范围:
-
不同厂商 GPU 采用各自的切片技术(NVIDIA 基于 vGPU 授权、华为昇腾基于 vNPU、寒武纪基于 SMLU 等),ZStack 在 AIOS 与 Cloud 中对接主流卡型,具体适配清单按版本滚动更新,以最新发布说明为准。
客户价值:推理服务、桌面云、AI 开发平台等多租户场景下,单卡承载的业务密度提升,GPU 投资回报周期缩短。
4.3 智算高性能网络:InfiniBand / RoCE / RDMA 全栈支持
智算集群与传统云平台的最大差异,是网络从"南北向访问"变成"东西向数据洪流"------GPU 节点之间的张量同步、节点与存储之间的数据集加载,任何一个网络瓶颈都会让 GPU 卡变成空转。AIOS 在网络层面提供以下能力:

具体能力:
-
多张物理网络分离部署:
-
AIOS 标配业务、存储、管理、带外四张网络,从硬件层规避不同流量相互干扰,网络架构与 ZStack 在金融、政企超融合场景中的最佳实践对齐;
-
存储网络走 RDMA/RoCE:
-
与 ZBS RDMA 集群对接,大规模数据集以接近本地盘的延迟流入 GPU 节点;容器侧也可通过 RDMA Device Plugin 直接对接高性能 S3 对象存储;
-
训练专用高性能网络:
-
针对大规模分布式训练场景,AIOS 支持额外部署 InfiniBand 或 RoCE 高速网络,用于 GPU 节点间张量同步;具体网卡速率(25G / 100G / 200G / 400G)按客户集群规模与算力规划匹配;
-
GPU 资源调度:
-
AIOS 通过 GPU 池化管理、Device Plugin 把 GPU 资源对外暴露,上层 AI 框架(PyTorch / TensorFlow / vLLM 等)可在此基础上直接调用 NVIDIA NCCL、AMD RCCL 等通信库做集合通信加速,平台不做侵入式封装。
4.4 真武 810E 与阿里云软硬协同
真武 810E 是阿里平头哥 2026 年 1 月 29 日官宣的 GPGPU 处理器,96GB HBM2e 显存,性能对标英伟达 H20,已经支撑阿里云万卡集群与超过 400 家企业的实际负载。
ZStack 作为阿里云控股的云基础软件公司,在 AIOS 智塔产品线中深度集成对真武 810E 的调度与管理能力,联合阿里云推出 AI Infra 一体机 与 ZStack Cube 智算版,把真武 810E 算力、英伟达 GPU 算力、国产 GPU 算力统一纳入调度池,对客户呈现为一个"算力黑盒"。
这套组合让客户获得算力供应链的稳定性------某一种 GPU 缺货时,不用改造整个 AI 平台。
五、ZVF 虚拟化:VMware 替代的主力
ZVF(ZStack Virtualization Foundation)是 ZStack 面向虚拟化场景 的产品线,包含 ZSphere(服务器虚拟化平台)与 ZLR(容灾产品), 核心定位是 VMware 替代。
ZVF 把 ZCF 沉淀下来的硬件加速能力------SR-IOV、Bond+SR-IOV 切割还原、OVS-DPDK 等------以兼容 VMware 操作习惯的方式打包给虚拟化场景客户:
- V2V 工具链:支持从 vCenter / ESXi 批量导入虚拟机,迁移规模从百台到数千台;
- 运维体验对齐:界面、API、操作概念与 VMware 用户的操作习惯兼容;
- 价格体系替代 **:**不绑定昂贵的 Broadcom 订阅模式;
- 容灾联动:ZLR 提供同城双活、异地容灾,部分场景已替代 SRM。
落地案例:多家头部券商、期货公司、制造业、医疗机构已启动或完成 VMware 替代,迁移规模覆盖核心数据库、ERP、桌面云、生产线控制系统。
六、客户实践
以下三个案例均来自 ZStack 已交付的真实生产项目,客户名做匿名化处理,聚焦"硬件加速能力如何在客户场景中落地"这一主线。
6.1 某头部量化私募基金:RDMA 低延迟超融合,4K IOPS 突破物理机基线
-
客户背景:
-
技术驱动的创新型量化投资基金公司,依托高频机器学习模型构建端到端深度学习投研流程,业务对 IO 延迟极度敏感
-
业务挑战:
-
原有业务部署在高性能物理机,Allinone 模式部署量化模型业务与数据库,资源利用率低、硬件投入高;批流引擎需要毫秒级聚合海量原始量价数据,Tick 级特征计算对小块随机 IO 提出极致要求
-
方案组合:
-
ZStack 3 节点超融合 + 25G 存储网络 + RDMA 低延迟 + ZBS 第二代全闪高性能分布式存储
-
硬件加速实测数据:
-
单台云主机 4K 随机读 15 万 IOPS / 随机写 11 万 IOPS,延迟 0.4ms / 0.5ms,远超物理机单机性能基线
-
客户价值:
-
在不牺牲性能的前提下实现云化交付,自服务 + 工单审批简化精简 IT 团队的资源管理成本;弹性扩容能力支撑 AI 投研业务架构的持续迭代
6.2 某全国性期货交易所:存算分离 + 国产 ARM + ZBS 高性能存储底座
-
客户背景:
-
某全国性期货交易所,科技部门为所内及期货会员单位提供交易相关业务的基础设施服务
-
业务挑战:
-
核心及会员业务原以物理机 + 本地 SSD RAID 为主,业务分散、运维复杂;在推进国产化的同时,需要保留低延迟、高 IOPS 的存储能力
-
方案组合 :
-
ZStack Cloud 弹性计算与裸金属服务(覆盖 Intel、鲲鹏、海光集群)+ ZBS 全闪高性能分布式存储 + 存算分离架构
-
硬件加速实测效果 :
-
基于国产 ARM(鲲鹏)与海光芯片集群,叠加 ZBS 全闪存储,在国产化技术路线下保留了核心交易、数据库类业务所需的低延迟、高并发 IO 性能
-
客户价值 :
-
计算与存储互不影响、各自发挥最大性能,故障概率显著下降;帮助客户从传统物理机 + 本地虚拟化平滑迈向"国产化 + 高性能 + 高可靠"的现代云平台架构
6.3 某大型金融公司:DPDK 网络加速 + 全闪存储,核心数据库上云
-
客户背景 :
-
某大型金融公司,推进从传统虚拟化架构向现代混合云架构的转型升级
-
业务挑战:
-
金融核心数据库对网络吞吐、IO 延迟、稳定性的要求极高,原有架构无法同时满足业务性能与混合云演进需要
-
方案组合:
-
ZStack Cloud + DPDK 网络加速 + ZBS 全闪存储的存算分离架构;集群一包含 23+8 计算节点和 3 节点 ZBS,集群二包含 13 计算节点和 3 节点 ZBS
-
硬件加速实测效果:
-
借助 DPDK 用户态网络加速 + ZBS 全闪存储,金融系统核心数据库成功上云,同时承接公有云托管业务向本地私有云的回迁,构建出高性能、高稳定性的混合云体系
-
客户价值:
-
在不牺牲性能的前提下完成混合云架构演进;通过利旧原有硬件资源有效控制建设成本;为后续 CMP 多云统一调度、ZDR 异地容灾、DTS 跨云数据同步预留扩展空间
七、阿里云控股下的软硬协同:一体机 + 公私一栈
ZStack 的另一层差异化,来自股权与产品层面的双重协同:阿里云是 ZStack 的控股股东。这意味着 ZStack 四大产品线与阿里云的公共云、神龙、真武 810E、通义大模型,可以在产品、方案、商务、交付四个层面深度联动。
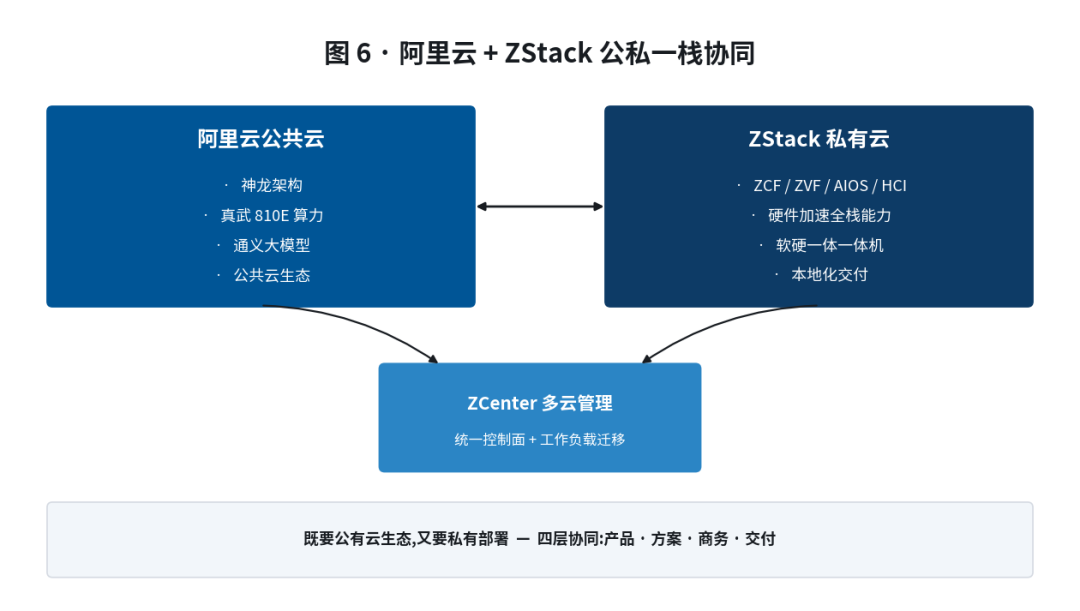

具体表现
-
一体机产品线:
-
ZStack Cube 系列 HCI 一体机、智算一体机,部分型号直接采用阿里云供应链的硬件平台与真武 810E 算力卡;
-
公私一栈:
-
客户在阿里云公共云上的工作负载可以平滑迁移到 ZStack 私有云,反之亦然,ZCenter 提供统一控制面;
-
联合方案:
-
在金融、能源、政企、AI 等垂直行业,ZStack 与阿里云联合 GTM,共享渠道、共享案例、共享专家资源;
-
技术共建:
-
在硬件加速(真武 810E 协同、DPU、RDMA 网络、机密计算)、AI 基础设施、云原生数据库等方向开展技术联合研发。
对客户而言,这是一个"既要公有云生态,又要私有部署"的最优解。