内容回顾
1、MyISAM引擎
2、索引创建规则
3、单表查询优化
4、多表(关联)查询优化
5、explain性能分析工具和指标字段
6、数据库优化方式?
今天内容
1、主从复制原理(背)
简单描述
-
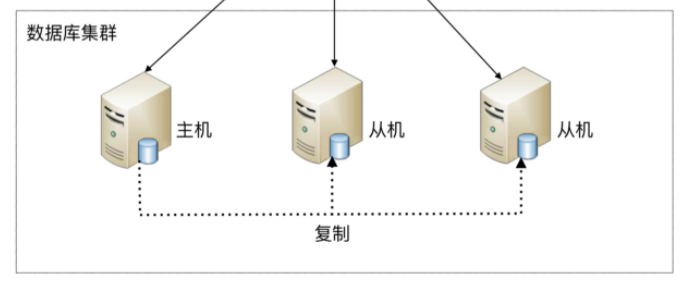
搭建数据库集群时候,只能有一台主机,可以有多台从机,也就是一主多从
-
在主机里面进行写操作,主机完成操作之后,同步到集群里面其他从机里面去
-
主从复制有缺点:数据延迟问题,主机里面写完操作之后,马上在从机读,可能读取不到
-
解决:在主机里面写在主机里面读
底层原理(☆)
-
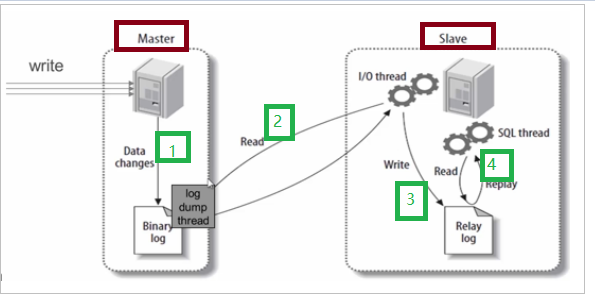
要实现主从复制,主机里面需要使用二进制日志,从机需要使用中继日志
-
当主机数据发生变化,在主机二进制日志里面记录变化数据
-
当从机开始主从同步之后,从机创建线程,线程连接主机,读取主机里面二进制日志变化数据
-
当从机线程读取主机二进制日志变化数据之后,把数据存储从机中继日志中
-
从机把中继日志存储数据同步从机服务里面
2、搭建主从复制环境
搭建主机
-
使用docker创建mysql服务器,端口号3306
-
创建mysql配置文件,配置服务器id和二进制日志格式
-
重启docker容器
-
修改mysql密码加密规则
-
创建新用户,专门做主从复制使用
-
查看主机里面二进制日志名称和位置
binlog.000003 | 1357
搭建从机
-
使用docker创建mysql服务器,端口号3307
-
创建mysql配置文件,配置服务器id和中继日志信息
-
重启docker容器
-
修改mysql密码加密规则
-
在从机 上配置主从关系(特别注意,相关数据一定修改正确)
-
在从机启动主从复制
-
在从机查看是否配置成功 SHOW SLAVE STATUS\G

测试
- 首先在主机里面创建数据库,创建表,在表添加数据
CREATE DATABASE db_user;
USE db_user;
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30),
PRIMARY KEY (id)
);
INSERT INTO t_user(uname) VALUES('zhang3');
INSERT INTO t_user(uname) VALUES(@@hostname);- 之后,到从机进行查看
3、ShardingSphere-JDBC读写分离
-
ShardingSphere可以方便实现读写分离和数据分片
-
ShardingSphere分为两个产品 ShardingSphere-JDBC和ShardingSphere-Proxy
搭建SpringBoot工程
- 引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.5</version>
</parent>
<groupId>com.atguigu</groupId>
<artifactId>sharding-jdbc-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.4.0</version>
</dependency>
<!--兼容jdk17和spring boot3-->
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
</project>- 创建实体类
@TableName("t_order")
@Data
public class Order {
@TableId(type = IdType.AUTO)
//@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String orderNo;
private Long userId;
}@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}- 创建mapper
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}@Mapper
public interface UserMapper extends BaseMapper<User> {
}- 创建配置文件
application.properties
spring.datasource.driver-class-name=org.apache.shardingsphere.driver.ShardingSphereDriver
spring.datasource.url=jdbc:shardingsphere:classpath:shardingsphere.yamlshardingsphere.yaml(后面修改这个配置文件)
- 测试类
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
}ShardingSphere实现读写分离
-
首先,搭建好主从复制环境(完成)
-
在shardingSphere.yaml文件添加
mode:
type: Standalone
repository:
type: JDBC
dataSources:
write_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3306/db_user
username: root
password: 123456
read_ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3307/db_user
username: root
password: 123456
# read_ds_1:
# dataSourceClassName: com.zaxxer.hikari.HikariDataSource
# driverClassName: com.mysql.cj.jdbc.Driver
# jdbcUrl: jdbc:mysql://192.168.200.130:3308/db_user
# username: root
# password: 123456
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
# - read_ds_1
transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMIC
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
props:
sql-show: true测试
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
@Autowired
private UserMapper userMapper;
/**
* 写入数据的测试
*/
@Test
public void testInsert(){
User user = new User();
user.setUname("张三丰");
userMapper.insert(user);
}
@Test
public void testSelect(){
User user1 = userMapper.selectById(1);
}
}主机读写
/**
* 事务测试
*/
@Transactional//开启事务
@Test
public void testTrans(){
User user = new User();
user.setUname("铁锤");
userMapper.insert(user);
List<User> users = userMapper.selectList(null);
}4、ShardingSphere-JDBC垂直分片
准备服务器
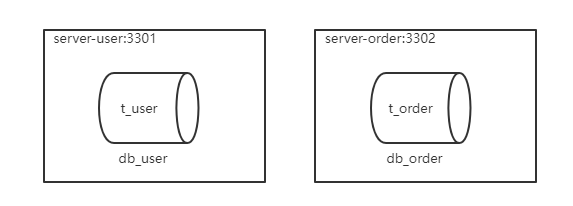

ShardingSphere-JDBC操作
mode:
type: Standalone
repository:
type: JDBC
dataSources:
user_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3301/db_user
username: root
password: 123456
order_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3302/db_order
username: root
password: 123456
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: user_ds.t_user
t_order:
actualDataNodes: order_ds.t_order
props:
sql-show: true测试
/**
* 垂直分片:插入数据测试
*/
@Test
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("强哥");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("ATGUIGU001");
order.setUserId(user.getId());
orderMapper.insert(order);
}
/**
* 垂直分片:查询数据测试
*/
@Test
public void testSelectFromOrderAndUser(){
User user = userMapper.selectById(1L);
Order order = orderMapper.selectById(1L);
}5、ShardingSphere-JDBC水平分片
准备服务器
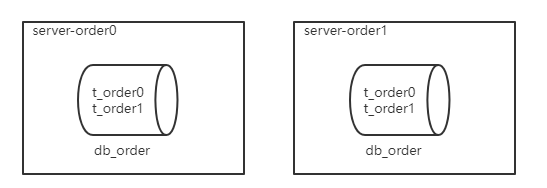
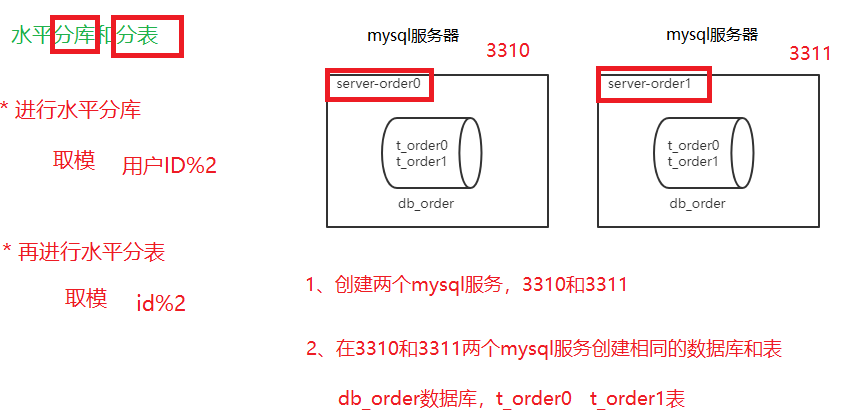
ShardingSphere-JDBC操作
- 修改Order类id生成策略,分布式id
@TableName("t_order")
@Data
public class Order {
//@TableId(type = IdType.AUTO)
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String orderNo;
private Long userId;
}- shardingsphere.yaml
mode:
type: Standalone
repository:
type: JDBC
dataSources:
user_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3301/db_user
username: root
password: 123456
order_ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3310/db_order
username: root
password: 123456
order_ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.200.130:3311/db_order
username: root
password: 123456
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: user_ds.t_user
t_order:
actualDataNodes: order_ds_${0..1}.t_order${0..1}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: userid_inline
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orderid_inline
shardingAlgorithms:
userid_inline:
type: INLINE
props:
algorithm-expression: order_ds_${user_id % 2}
orderid_inline:
type: INLINE
props:
algorithm-expression: t_order${id % 2}
props:
sql-show: true- 测试
@Test
public void testInsertOrderTableStrategy(){
for (long i = 0; i < 4; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + System.currentTimeMillis());
order.setUserId(1L);
orderMapper.insert(order);
}
for (long i = 0; i < 4; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + System.currentTimeMillis());
order.setUserId(2L);
orderMapper.insert(order);
}
}分库分表原则
1、单表达到500w行或者单表容量达到2GB,考虑分库分表
2、能不分进行不分,如果分越少越好
3、有关联数据库表 放到同一个数据库里面,避免跨库操作
6、补充MySQL其他概念
补充-MVCC
MVCC 就是数据库的 "时光机",让多个用户同时读写数据时,互不干扰,还能看到自己操作时的 "数据快照",不用一直加锁排队。
MVCC多版本并发控制
简单说,它给每条数据的每次修改都拍个 "快照" 并标上时间戳,你查数据时,数据库会根据你的 "时间",找到你该看的那个快照版本,这样别人改了新数据,也不会影响你看到的内容。
用一个具体的用户操作场景,比如"转账时的读写冲突",来拆解MVCC是怎么工作的。
咱们用 "用户 A 给用户 B 转账 100 元" 的场景,拆解 MVCC 如何解决读写冲突,核心是让 "转账的写操作" 和 "查余额的读操作" 互不干扰。
场景初始状态
假设数据库里有两条记录,初始时都有一个唯一的 "版本号"(类似时间戳,每次修改会递增):
-
用户 A 余额:1000 元,版本号 = 1
-
用户 B 余额:500 元,版本号 = 1
步骤 1:用户 C 开始查询 A 和 B 的余额(读操作)
此时用户 C 发起查询,数据库会给 C 的查询也分配一个 "查询版本号",比如版本号 = 2。
数据库会根据这个版本号,找到所有 "版本号≤2" 且未被删除的最新数据:
- 找到 A 的版本 1(1000 元)、B 的版本 1(500 元),返回给 C,C 看到的总余额是 1500 元。
步骤 2:用户 A 发起转账(写操作,此时 C 还没查完)
转账本质是两个修改操作,MVCC 不会直接改原数据,而是生成新的版本:
-
扣 A 的 100 元:生成 A 的新版本,余额 = 900 元,版本号 = 3(递增),同时标记旧版本 1 "未删除"。
-
加 B 的 100 元:生成 B 的新版本,余额 = 600 元,版本号 = 4(再递增),同时标记旧版本 1 "未删除"。
此时数据库里 A 和 B 各有两个版本,但旧版本并未消失。
步骤 3:C 的查询继续,完全不受转账影响
因为 C 的查询版本号是 2,数据库只会认 "版本号≤2" 的数据:
-
A 的版本 3(900 元)、B 的版本 4(600 元)版本号都大于 2,所以 C 看不到。
-
C 依然读取 A 的版本 1(1000 元)和 B 的版本 1(500 元),最终结果不变。
步骤 4:转账完成后,新用户 D 查询(读操作)
D 的查询会分配到版本号 = 5,此时数据库找 "版本号≤5" 的最新数据:
- A 的最新版本是 3(900 元),B 的最新版本是 4(600 元),D 看到的总余额还是 1500 元(数据一致)。
MySQL日志
-
**二进制日志:**数据库里面数据变化,在二进制日志进行记录
-
**中继日志:**主从复制里面,从机读取主机二进制日志内容,存储中继日志
-
**redo日志:**保证事务提交的
-
**undo日志:**保证事务回滚的,使用MVCC机制多版本并发控制
MySQL锁
-
事务的隔离性底层使用锁机制
-
如果不考虑事务隔离性,产生四个问题
-- 脏读:两个未提交事务互相读取对方数据
-- 不可重复读:一个提交事务,读取另外一个未提交事务修改数据
-- 幻读:一个提交事务,读取另外一个未提交事务添加数据
-- 丢失修改:多个事务同时修改同一个记录,最后提交的把之前覆盖
- 解决
-- 脏读、不可重复读、幻读通过设置事务隔离级别解决
-- 丢失修改使用乐观锁解决(版本)
- 事务隔离级别
MySQL默认级别 REPEATABLE READ(可重复读)
- 并发问题
1、采用 MVCC 方式的话, 读-写 操作彼此并不冲突, 性能更高 。
2、采用 加锁 方式的话, 读-写 操作彼此需要 排队执行 ,影响性能。
一般情况下我们当然愿意采用 MVCC 来解决 读-写 操作并发执行的问题,但是业务在某些特殊情况 下,要求必须采用 加锁 的方式执行。