Unidbg学习笔记(十六):Console Debugger
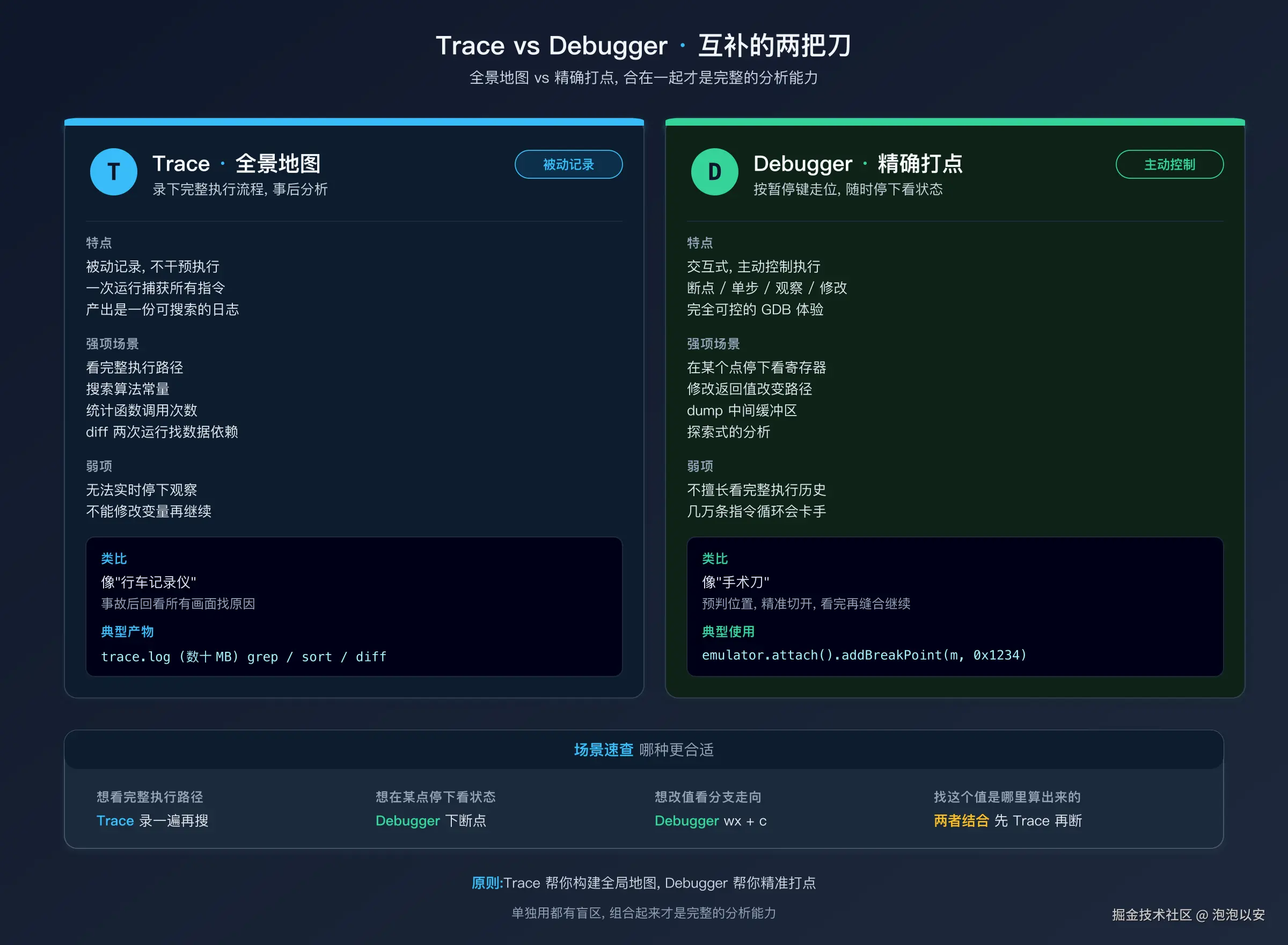
如果 Trace 是"拍电影",Console Debugger 就是"按暂停键走位"。你不再被指令流推着走,而是能随时停下来,看寄存器,看内存,看栈,改个值再继续。这是 Unidbg 最容易被低估的武器,也是算法分析里最重要的武器。
上一篇把你留在了哪里
第十五篇我们站在防守方的视角,理解了六大检测面和叠加防御的打分机制。你学会了"怎么想",但还没学到"怎么动手"。
从这一篇开始,我们回到攻击方的日常,聊具体怎么分析一个 SO 函数。而 Console Debugger,就是这个过程里你每天都会用到的工具。
Trace 和 Debugger 是互补的两个工具:
| 场景 | Trace | Debugger |
|---|---|---|
| 我想看完整执行路径 | 适合 | 不合适 |
| 我想在某个点停下来看状态 | 不合适 | 适合 |
| 我想修改一个值看分支走向 | 不合适 | 适合 |
| 我想知道这段代码执行了多少次 | 适合 | 不合适 |
| 我想找"这个值是哪里算出来的" | 两者结合 | 两者结合 |
简单说:Trace 帮你构建全局地图,Debugger 帮你精准打点。
为什么 Unidbg 的调试器如此好用
在真机上调试一个带反调试的 SO,是世界上最痛苦的事情之一:
ptrace双进程相互附加- 检测
TracerPid字段 - 检测调试器断点(软断点
0xde01/ 硬断点寄存器) - 检测单步执行的时间差
- 检测
ptrace系统调用本身
每一层你都要绕过,然后再接着调试。一次典型的真机调试会话,70% 的时间花在对抗反调试,30% 在看寄存器。
Unidbg 的调试器彻底没有这个问题。因为:
- 它不是"附加进程",而是模拟器内部直接控制 CPU 。没有
ptrace,没有TracerPid. - 没有软/硬断点的概念。断点是 Backend 在执行前检查的一段代码,SO 完全感知不到。
- 没有"调试器进程",检测逻辑找不到攻击者。
- 你在断点里改寄存器,SO 看到的就是改完的值,没人会怀疑。
换句话说:Unidbg 的调试器 = 一个没有任何反调试对手的 GDB。这是真机永远无法提供的体验。
启动调试器
最简单的方式:attach()
java
public class Sample {
public static void main(String[] args) {
AndroidEmulator emulator = AndroidEmulatorBuilder.for64Bit().build();
VM vm = emulator.createDalvikVM();
DalvikModule dm = vm.loadLibrary(new File("libsample.so"), true);
// 开启调试器, 执行到第一条指令就停下
emulator.attach().addBreakPoint(dm.getModule(), 0x1234);
// 调用目标函数, 触发断点
dm.callJNI_OnLoad(emulator);
}
}当执行到 module.base + 0x1234 时,Unidbg 会弹出一个交互式命令行:
python
>>> 这里就是你开始调试的起点。
更灵活的方式:多个断点
java
Debugger debugger = emulator.attach();
debugger.addBreakPoint(module, 0x1234); // 函数入口
debugger.addBreakPoint(module, 0x1280); // 关键分支
debugger.addBreakPoint(module, 0x12A0); // 返回前你可以一口气下好所有感兴趣的位置,然后 c 一路跑过去,每个断点都会停下。
带条件的断点
java
debugger.addBreakPoint(module, 0x1234, new BreakPointCallback() {
@Override
public boolean onHit(Emulator<?> emulator, long address) {
RegisterContext ctx = emulator.getContext();
long x0 = ctx.getLongArg(0);
// 只在参数为特定值时才停下: 不感兴趣 → return true 跳过, 感兴趣 → return false 进入命令行
return x0 != 0x12345678L;
}
});注意 onHit 的返回值语义和直觉相反 ------ 看一眼源码 BreakPointCallback.java 就知道:return false 表示"真的断下,进入命令行",return true 表示"跳过这次,继续执行" 。这就是条件断点 。读者初次看代码常常凭直觉写反,下面所有自动化探针的例子都遵循这一约定,看到 return true 就当成"自动继续"。
核心命令速查

进入调试器命令行后,能用的命令其实不多,但每一个都很好用。下面这张表是最常用的:
⚠️ unidbg console 与 GDB 最大的语法差异 :地址类命令的地址要紧贴前缀,无空格 ------
b0x1234而不是b 0x1234,m0x1234而不是m 0x1234,mx0而不是mr x0。新手最容易踩的坑就是按 GDB 习惯加空格。
| 命令 | 功能 | 场景 |
|---|---|---|
c |
继续执行 | 看完当前状态,跑到下一个断点 |
s / si |
单步执行(step into) | 逐指令分析,遇到函数调用会进入 |
n |
步过(step over) | 跳过不关心的调用,在 bl 后面停下 |
b0x<addr> |
动态加断点(地址紧贴 b,无空格) |
例 b0x1234 在 module.base + 0x1234 设断点 |
b |
在当前 PC 处加断点 | 单字母 b 默认作用于当前 PC |
r |
移除当前 PC 处的断点 | 与 b 配对 |
blr |
在 lr 寄存器位置下断点 | 快速回到调用者(函数返回处) |
nb |
在下一个 basic block 开头断下 | 跨过当前块 |
m0x<addr> [size] |
查看指定地址的内存 | 例 m0x40005000 32;不带 size 默认 0x70 |
mx<n> / mfp / msp |
查看寄存器指向的内存 | 例 mx0 看 x0 指向的内容(不是 mr x0) |
wx<n> <val> |
修改通用寄存器 | 例 wx0 0 让函数返回 0(不是 wx x0 0) |
wx0x<addr> <hex> |
往内存写一段字节 | 例 wx0x40005000 deadbeef |
wb0x<addr> / ws0x<addr> / wi0x<addr> / wl0x<addr> |
按 byte / short / int / long 类型写内存 | 例 wi0x40005000 42 |
d / dis |
在当前 PC 处反汇编 | 不带地址,只看现场 |
d0x<addr> |
反汇编指定地址 | 例 d0x1234;不接受长度参数 |
bt |
查看调用栈 | "我是怎么到这里的?" |
stop |
抛异常退出,不再继续 | 终止当前调用 |
p <assembly> |
在 PC 处打补丁,原地改一条汇编 (不是 Jython 脚本) | 例 p mov x0, #0 |
vbs |
列出当前所有断点 | 排查"为什么没断下来" |
gc |
触发一次 JVM GC | 内存调试用 |
threads |
列出所有模拟线程 | 多线程样本调试 |
quit / exit |
关闭 debugger 并继续执行 | 不是 q,必须完整拼写 |
寄存器查看
每次断下时 Unidbg 会自动打印所有寄存器:
ini
>>> b0x40001234
>>> c
[10:32:15 INFO] [Debugger] >>> break at 0x40001234
x0=0x0000007fffff7a80 x1=0x0000000000000020 x2=0x0000000000000010
x3=0x0000000040005000 x4=0x0000000000000000 x5=0x0000000000000000
...
pc=0x0000000040001234 sp=0x0000007fffff7a00想看单个寄存器指向的内存 : mx0 就够了(注意是 mx0 不是 mr x0,命令名 + 寄存器号紧贴在一起)。
三个最重要的工作流
死记命令没意义,记住几个工作流才有用。下面三个是我每次分析 SO 都会走一遍的。
工作流 1:函数入口断点 + 观察入参
场景:拿到一个 SO,知道某个函数负责签名,想看看它的入参是什么。
-
在 IDA 里打开 SO,找到
Java_com_xxx_signIt的偏移,比如0x1A34 -
Unidbg 代码:
javaDebugger d = emulator.attach(); d.addBreakPoint(module, 0x1A34); // 触发 JNI 调用 (静态方法走 DvmClass; 实例方法走 DvmObject) DvmClass clazz = vm.resolveClass("com/xxx/Sample"); clazz.callStaticJniMethodObject(emulator, "signIt(Ljava/lang/String;)Ljava/lang/String;", str); -
断下后,JNI 函数的参数规则:
x0=JNIEnv*(几乎没用)x1=jobject this或jclass clazzx2= 第一个 Java 参数x3= 第二个 Java 参数
-
看
x2指向的内存:mx2- 但注意:
x2是jstring,是个 handle,不是直接的字符串指针。需要 SO 自己调用GetStringUTFChars才能解开。所以mx2看到的是 handle 结构,不是你期待的字符串。
- 但注意:
-
解决办法:直接在
GetStringUTFChars的返回处下断点 ,那时x0就是解好的 C 字符串指针。
这是一个很实用的小技巧:不要在你想看数据的地方下断点,要在"数据已经被解好"的地方下断点。
JNI 入参提取的完整套路
实际操作里,为了不每次都手动 mr x2 猜 handle 结构,我们一般会写一个小工具把 JNI 参数一键解开。下面这段代码是我分析任何 JNI native 方法时的第一个 Hook,它在函数入口做一次完整的入参提取:
java
d.addBreakPoint(module, 0x1A34, (emu, address) -> {
RegisterContext ctx = emu.getContext();
// x0 = JNIEnv*, 不用看
int thisOrClass = ctx.getIntArg(1); // DVM handle 是 int (hashCode 派生), 不是 long
System.out.println("[entry] this/clazz handle = 0x" + Integer.toHexString(thisOrClass));
// 从 x2 开始是 Java 参数, 按方法签名解码
// 例如 signIt(Ljava/lang/String;[B)Ljava/lang/String;
int jstrHandle = ctx.getIntArg(2);
int byteArrayHandle = ctx.getIntArg(3);
DvmObject<?> strObj = vm.getObject(jstrHandle); // VM.getObject(int)
DvmObject<?> byteObj = vm.getObject(byteArrayHandle);
String str = (String) strObj.getValue();
byte[] bytes = (byte[]) byteObj.getValue();
System.out.println("[entry] arg1 (String) = " + str);
System.out.println("[entry] arg2 (byte[]) = " + Hex.encodeHexString(bytes));
return true; // dump 完直接放行, 不进交互式 REPL
});关键是 vm.getObject(handle) 这一步------它把 JNI handle(在 unidbg 里是一个 int,由 hashCode 派生而来)在 Unidbg 的 DVM 字典里查一下,拿到背后的 Java 对象。注意签名是 getObject(int hash),不是 long,所以从寄存器拿来的值要用 getIntArg 或显式 (int) 截位。对 jstring 就能调 getValue() 拿字符串,对 jbyteArray 就能拿 byte 数组,对 jobject 你还能进一步调 getObjectField 看字段。这比 mr x2 看原始内存直观太多了,也彻底绕开了"要不要调 GetStringUTFChars"的纠结------因为 DVM 字典里早就有解码过的 Java 对象。
函数签名和寄存器的映射规则也值得固化下来,以后拿到任何 JNI 函数都能套用:
| 签名位置 | ARM64 寄存器 | 类型 | 提取方式 |
|---|---|---|---|
| 隐式 0 | x0 |
JNIEnv* |
几乎不用 |
| 隐式 1 | x1 |
jobject(实例方法) / jclass(静态方法) |
vm.getObject(x1) |
| 第 1 个 Java 参数 | x2 |
取决于签名 | 见下 |
| 第 2 个 Java 参数 | x3 |
同上 | 同上 |
| ... | x4-x7 |
... | ... |
| 第 7 个及以后 | 栈上 | ... | sp + offset 读 |
其中"取决于签名"要分清楚:基本类型(int / long / float 等)直接按值传,int 在 w2 的低 32 位,long 填满 x2,float/double 走 v0-v7;对象类型(String / byte[] / 自定义类)都是 handle,需要 vm.getObject 解开。把这张表打印出来贴在屏幕边,以后分析 JNI 入参不再需要试错。
工作流 2:用 blr 快速回到调用者
场景:你进了一个函数,觉得这不是你想看的函数,想立刻回到调用者。
最原始的做法: n n n n n ... 步过所有指令直到 ret.
更快的做法:
python
>>> blr
>>> cblr 会在当前 lr 寄存器指向的地址(也就是调用者的下一条指令)下一个断点,然后 c 继续执行,函数一返回立刻断下。秒回调用者。
这在分析一个很深的调用链时非常省时间。你走错一层, blr + c 就能立刻退出来。
工作流 3:修改返回值绕过检测
场景:你发现一个 anti-hook 函数,它返回 1 表示"检测到 hook",你想让它返回 0.
方法 A:在函数入口 return 0
python
>>> b0x1A34 # 函数入口 (注意 b 和地址紧贴, 没有空格)
>>> c
(断下)
>>> wx0 0 # 设返回值为 0 (wx0 = 写 x0 寄存器, 不是 wx x0)
>>> blr # 在 lr 处下断
>>> c # 执行...但一到函数内部就会改写 x0等等,这样不行 ------ 函数内部会覆盖 x0。我们得在函数返回前改。
方法 B:在函数返回点 wx0 0
python
>>> b0x1A34 # 函数入口
>>> c
>>> blr # 先定位 ret 之前的位置
>>> c
(返回前断下)
>>> wx0 0 # 此时改 x0, 会被当成返回值
>>> c更简洁的:直接在 ret 指令上下断点,然后改 x0:
python
>>> d0x1A34 # 在 0x1A34 处反汇编, 看看有几个 ret (不接受长度参数)
>>> b0x1B08 # ret 位置下断
>>> c
>>> wx0 0
>>> c这就是 Console Debugger 最强的武器:你可以在任意位置改任意值,然后看代码怎么走。
和 IDA/Ghidra 的联动工作流
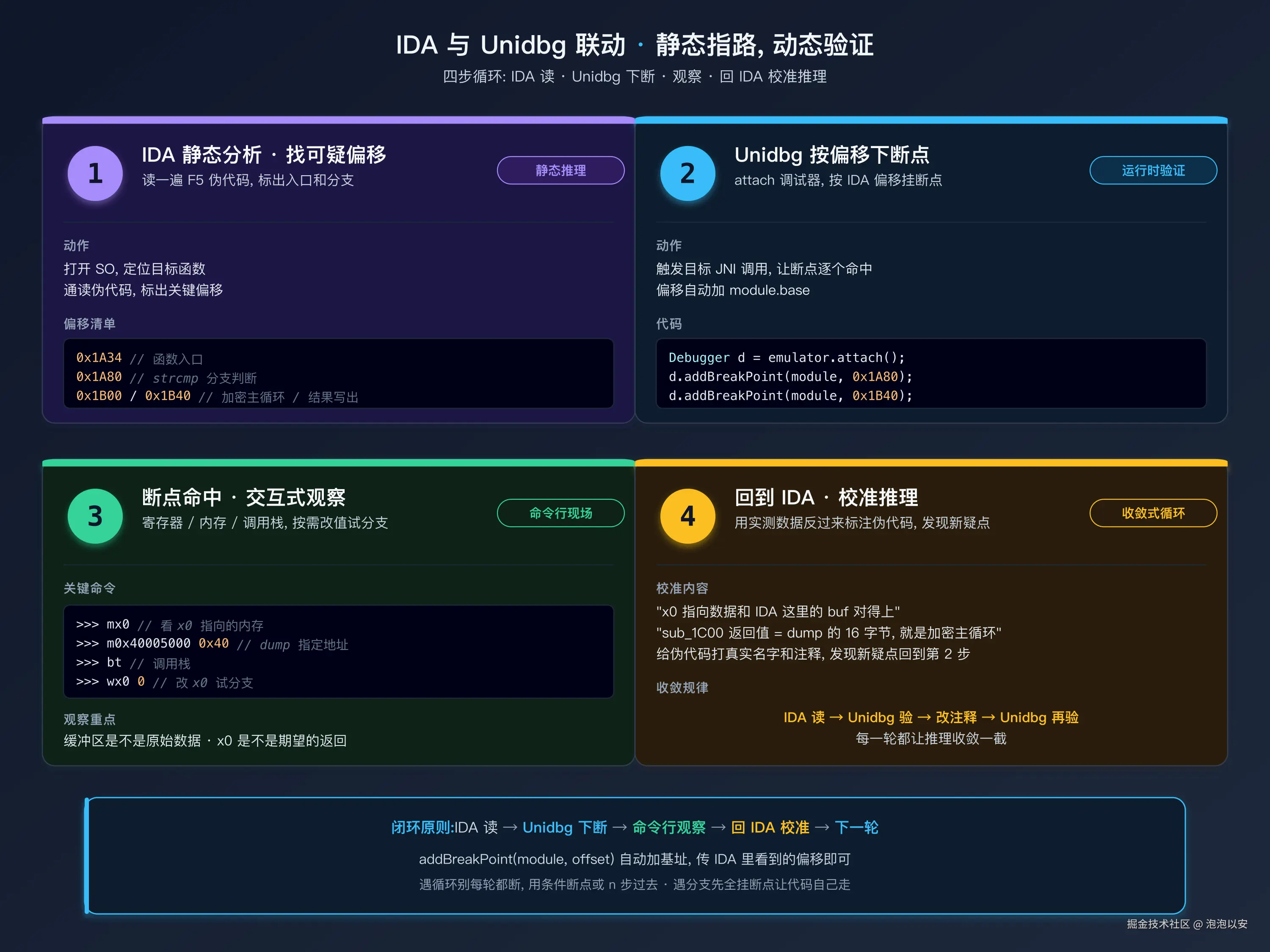
Console Debugger 单独用已经很强,但它真正的威力来自和静态分析工具的联动。
典型工作流
-
IDA 先分析:打开 SO,找到关键函数,读一遍伪代码,在重点位置记下偏移。比如:
0x1A34:函数入口0x1A80:判断strcmp返回值的分支0x1B00:加密循环开始0x1B40:结果写出
-
Unidbg 设好断点:
javaDebugger d = emulator.attach(); d.addBreakPoint(module, 0x1A80); d.addBreakPoint(module, 0x1B00); d.addBreakPoint(module, 0x1B40); -
运行,在每个断点观察:
- 断点 1:看
x0是不是期待的比较结果 - 断点 2:看
x0/x1指向的缓冲区是不是原始数据 - 断点 3:看
x0指向的是不是加密后的数据
- 断点 1:看
-
回 IDA 验证 :"断点 3 时 x0 指向的数据和 IDA 里这个
sub_1C00的返回值对得上,说明它确实是加密函数. " -
循环:IDA 发现新的可疑点 → Unidbg 下断点验证 → IDA 再看。
关键窍门
- IDA 里的偏移是相对 SO 基址的 。Unidbg 的
addBreakPoint(module, offset)会自动加上module.base。你不需要手动算。 - 遇到分支,先在每个分支下一个断点,让代码自己走,看哪个断下。省得你推理半天。
- 遇到循环 ,不要每轮都断。用条件断点:"仅在
x0 == 0x100时断下",或者干脆n步过整个循环。 - 遇到
bl调用 ,先n看看返回值是不是感兴趣。不是就继续。是的话,重新跑一遍,这次用s进去看。
断点回调的高级用法
命令行交互是人力操作,慢。更高效的是用断点回调写死分析逻辑:
场景:每次断点自动 dump 内存
java
d.addBreakPoint(module, 0x1B40, new BreakPointCallback() {
@Override
public boolean onHit(Emulator<?> emulator, long address) {
RegisterContext ctx = emulator.getContext();
long addr = ctx.getXLong(0); // x0 指向结果
byte[] data = emulator.getBackend().mem_read(addr, 16);
System.out.println("result @ 0x" + Long.toHexString(addr) + ": " + Hex.encodeHexString(data));
return true; // 不进入交互, 自动继续
}
});return true 是关键 ------ 它让断点"触发但不停下",执行自动继续。你就得到了一个自动化的数据探针 。(return false 反而是"真的断下进 REPL",前一节解释过这条反直觉的约定。)
场景:条件 dump + 修改寄存器
java
d.addBreakPoint(module, 0x1A80, (emu, addr) -> {
RegisterContext ctx = emu.getContext();
long cmp = ctx.getXLong(0);
if (cmp != 0) {
System.out.println("unexpected cmp result: " + cmp);
emu.getBackend().reg_write(Arm64Const.UC_ARM64_REG_X0, 0);
System.out.println("patched to 0, continuing...");
}
return true; // patch 完自动放行
});这种"断点里改寄存器"的技巧,在绕过检测和打补丁时非常实用 ------ 你不需要修改 SO 二进制,也不需要 Hook 框架,用 Debugger 直接就能 patch.
从"浪费带宽"到"精准打击":怎么选断点地址
把上面所有技巧练熟之后,下一个问题自然浮出水面:一个 SO 动辄几十万条指令,你到底该在哪里下断?随便断下来你看到的也只是一堆不相干的寄存器,真正的功夫不在"会用命令",而在"挑地址"。这里把我分析微信读书 libencrypt.so 时选 7 个断点的心路过程整理成四条可复用的线索。
线索一·JNI 导出函数入口是天然起点 。业务流程一定从某个 Java_com_xxx_xxx 或 module.callFunction(emulator, offset + 1, ...) 进入,这是唯一不需要推理就能确定的地址。第一个断点永远打在这里,目的是看它第一步跳向哪个子函数------这决定了你接下来该追哪一层。
线索二·用 Trace 反推算法候选 。先打开全 SO 范围的 emulator.traceCode(module.base, module.base + module.size) 跑一次,把输出重定向到文件,然后 grep 有特征的常量:AES 的 0x637c777b (S-Box 前 4 字节)、SHA256 的 0x6a09e667 (H0)、SHA1 的 0xC3D2E1F0 (H4,MD5 没有第 5 个 IV,足以唯一识别)、MD5 的 0x67452301+0xefcdab89 同时出现 (注意 SHA1/MD5 的前 4 个 IV 完全一样, 单看 0x67452301 区分不了, 要靠组合)。每命中一次常量,就记下当时 PC 所在的函数入口------这种方式能直接定位到"算法主体函数",省去逐个函数猜。微信读书那个 0x8EB8 就是从 Trace 里命中 SHA256 常量反推出来的,断点里加一句注释 "sha256 arg1/arg3/ret" 就知道它的角色了。
线索三·IDA 交叉引用缩小候选集 。有些函数压根不含标准常量(比如自定义的字节置换表),Trace 反推失效。这时回 IDA,从业务入口追 BL/B 跳转,把所有被直接或间接调用的函数列出来,按函数大小过滤------10 行以下的 utility 函数跳过,50~300 行"有分量"的列入候选。参数数量也能从 IDA 函数签名里看到,这决定你 hook 回调里读几个参数:两个就是可能是对称变换(对称 in/out 缓冲),三个大概率是"key + IV + 明文"结构。
线索四·在断点里用 bt 自己迭代精化 。最容易被忽视的一点:断点集不是一次性设完就跑的,而是迭代出来的。典型流程是"断下业务入口 → bt 看调用栈 → 发现它又调了某个地址 → 加一个新断点 → 继续跑"。每一轮都能让你多看一层。微信读书那 7 个 hook 地址就是这样一轮一轮加出来的,不是第一次静态分析就全部列全------这是人力分析的常态,不必强求一次到位。
把这四条线索并排用,挑出来的断点集会呈现一种"每个点都有理由"的分布:业务入口 1 个、Trace 命中的算法函数 23 个、IDA 推断的中间函数 2 3 个、调用栈追出来的关键节点 12 个。合计 610 个点,足以覆盖一个典型 SO 的关键算法路径。反过来,如果你发现自己下了 20 多个断点还没找到算法主体,基本可以肯定是线索二(Trace 常量命中)没做扎实------回头把 Trace 跑一次比继续乱断效率高得多。
常见问题与陷阱
陷阱 1:断点地址算错
Unidbg 用的是运行时绝对地址 ,IDA 用的是文件内偏移。两者的换算:
arduino
运行时地址 = module.base + IDA 偏移大多数情况直接用 addBreakPoint(module, offset), Unidbg 自动处理。但如果你手动传 long 地址,记得加上 module.base.
陷阱 2:断点在 Thumb 指令上失效
范围说明 :本节仅适用于 ARM32 / AArch32 SO 。AArch64(本章前文示例所用的
x0/x1...寄存器、Arm64Const.UC_ARM64_REG_X0等)没有 Thumb 模式,可以跳过。如果你只分析 64 位 SO,直接看陷阱 3。
Thumb 指令的地址低位是 1 (比如 0x1235 实际是 0x1234 的 Thumb)。 Unidbg 的断点通常对齐到 2 字节,不会因低位出错,但如果你硬传一个带低位 1 的地址,可能不触发。用 IDA 里显示的偏移,不要加低位 1.
这里有一个非常容易踩的坑,值得单独拉一节讲清楚:Thumb 地址、IDA offset、module.base+offset 三者完全不是一回事。它们之间的关系是:
| 概念 | 例子 | 含义 |
|---|---|---|
| IDA 里看到的偏移 | 0x1234 |
文件偏移,低位永远是偶数(2 字节对齐) |
| IDA 里带 Thumb 位的地址 | 0x1235 |
告诉处理器"这是 Thumb 指令",低位 1 是一个 hint 而不是真实地址的一部分 |
Unidbg 的 addBreakPoint(module, offset) |
addBreakPoint(m, 0x1234) |
Unidbg 自动加 module.base,不需要 Thumb 位 |
| 手动构造运行时地址 | module.base + 0x1234 |
完全正确,能断下 |
| 错误的构造 | module.base + 0x1235 |
带了 Thumb 位,可能错过 2 字节,Unicorn 断不下来 |
举个具体例子,假设 IDA 显示一个 Thumb 函数入口是:
arduino
.text:00001235 funcXXX:
.text:00001235 PUSH {R4,R5,LR}这个 0x1235 是 IDA 用来提示你"从这里开始是 Thumb 指令"的视觉约定 ,真实的文件偏移和运行时偏移都是 0x1234。你在 Unidbg 里应该用 0x1234:
java
// 正确
d.addBreakPoint(module, 0x1234);
// 错误: 把 Thumb hint 位当真实地址了
d.addBreakPoint(module, 0x1235); // 可能跑到 0x1236 的中间, 断不下如果你不小心把 0x1235 写进去,最常见的症状是 "断点设了但从来不触发" ------因为 Unicorn 是按 2 字节对齐对比 PC 的,0x1235 永远不可能等于 0x1234 也不可能等于 0x1236,于是永远不命中。排查这类问题,第一步就是把所有断点地址看一遍,凡是奇数的都减 1。
陷阱 3:单步执行太慢
如果函数里有 10000 条指令,你绝对不想一条条 s。正确做法:
- 用 Trace 一次性记录完整流程,看哪里可疑
- 在可疑处下断点,用 Debugger 停下来看状态
- 不要试图"单步走完整个函数"
Trace + Debugger 的混合工作流
单步太慢几乎是新手踩的第一个坑,用一次就知道疼------一个 5000 指令的加密函数,每条 s 要 0.5 秒计算加打印,一次性单步走完要 40 分钟,还没看明白任何东西。正确的混合用法分三段:
第一段:Trace 定范围。先跑一次完整的指令 Trace,输出重定向到文件,然后用 Python 或 grep 做简单的统计分析。比如看函数总指令数、循环次数、调用了哪些子函数------这些能给你一个"骨架"。典型的定范围脚本:
python
# 统计每个 16 字节地址区间被执行的次数, 找到循环
from collections import Counter
c = Counter()
with open("trace.log") as f:
for line in f:
if m := re.match(r"^(0x[0-9a-f]+):", line):
c[int(m.group(1), 16) & ~0xf] += 1
# 打印执行次数最多的前 20 个区间 -> 热点就是加密循环
for addr, cnt in c.most_common(20):
print(f"0x{addr:x}: {cnt}")找到热点区间(假设是 0x1B00 - 0x1B80,被执行了 640 次),就知道这是 AES 的轮循环,每轮 80 条指令、共 10 轮 + 64 步 key schedule。
第二段:Debugger 盯单次迭代 。在轮循环的入口(0x1B00)和出口(0x1B80)各下一个断点,跑到第一次进入循环时停下。此时用 mr x19(假设 x19 是 state 指针)看一次输入 state,然后 c 到循环出口,再 mr x19 看一次输出 state。两次 dump 对比,一轮的变换就彻底清楚了。
python
>>> c # 进入第一次循环
break at 0x1B00
>>> mx19 # 查看进入前的 state (mx19 = m 命令查看 x19 寄存器指向的内存)
0x7fffff_7a80: 00 11 22 33 44 55 66 77 88 99 aa bb cc dd ee ff
>>> c
break at 0x1B80 # 循环出口
>>> mx19 # 查看一轮后的 state
0x7fffff_7a80: 63 7c 77 7b f2 6b 6f c5 30 01 67 2b fe d7 ab 76这两行 dump 就够你对照标准 AES 的 SubBytes + ShiftRows + MixColumns + AddRoundKey 了------00 11 22... 过 S-Box 变成 63 7c 77 7b... 明显是 AES 的 S-Box 输出。
第三段:断点回调批量抓 。搞清一轮后,把断点回调改成 return true 自动化版本("放行不停"),让它把 10 轮的 state 全部 dump 下来,然后用 Python 对比标准 AES 的 10 轮参考实现,一轮对一轮 diff。10 分钟看完 10 轮,而不是 40 分钟单步走完一轮还没看懂。
这就是 Trace + Debugger 的典型搭配:Trace 帮你找到"值得看的地方",Debugger 帮你在那个地方看清楚发生了什么。任何一个用 Debugger 走了一整天还没进度的场景,99% 是因为跳过了第一段的 Trace 定范围。
陷阱 4: Debugger 只能在支持的 Backend 上用
和 Trace 一样,Console Debugger 依赖 Backend 对单步/断点的支持。Dynarmic 不支持 ,必须切回 Unicorn/Unicorn2. 如果你发现 attach() 没反应,先看 Backend 是什么。
陷阱 5:多线程场景下断点混乱
如果目标函数内部开了多线程,Debugger 可能在任意线程断下,寄存器显示的是哪个线程的也不一定。简单 SO 基本不会遇到这问题,但复杂 SDK 会。遇到多线程,考虑用 Trace + 代码审查代替 Debugger.
总结
| 问题 | 答案 |
|---|---|
| Debugger 和 Trace 什么关系 | 互补 ------ Trace 是全景地图,Debugger 是精确打点 |
| Unidbg 的 Debugger 比真机 GDB 强在哪 | 彻底没有反调试对手,完全可控 |
| 最常用的三个命令 | c / blr / mx<n>(不是 mr <reg>) |
| 怎么快速回到调用者 | blr + c |
| 怎么绕过一个检测函数 | 在 ret 指令处 wx0 0 |
| 怎么自动化分析 | 断点回调 + return true(注意是 true 才"放行",false 反而是停下) |
| 和 IDA 怎么联动 | IDA 记偏移 → Unidbg 下断点 → 观察 → 回 IDA 验证 |
记住一句话:Console Debugger 是 Unidbg 给你的手术刀。但手术刀的威力,取决于你提前读过多少解剖学 ------ 也就是 IDA 里的伪代码。光会用 Debugger 没用,你还得会看静态代码。两者合一,才是完整的分析能力。