如果有人问我:"在复杂的业务系统中,哪种SQL写法最容易成为系统崩溃的隐形杀手?"我大概率会把票投给------在SELECT列表中滥用标量子查询。
时间来到2026年,,单一的事务处理(OLTP)或分析处理(OLAP)已经无法满足海量数据的即时变现需求。HTAP(混合事务/分析处理)已经成为了当下数据库选型的绝对主流。这意味着,我们经常会在承载着高并发核心交易的数据库上,直接运行极其复杂的报表类查询。在以往,这种操作无疑是"自杀行为",而那些看似逻辑清晰、实则极其消耗算力的标量子查询,往往就是拖垮整个系统的罪魁祸首。
今天,我们就从一个真实的生产痛点出发,结合实操测试,深度剖析金仓数据库Kingbase是如何通过底层优化器的"标量子查询消除"技术,赋予数据库原生HTAP能力的。 
@toc
一、 痛点剖析:为什么你的报表SQL能让CPU瞬间飙红?
在日常的复杂业务系统开发中,SQL往往会写得非常复杂。随着业务复杂度的提升,CTE(公用表表达式)、多层子查询、窗口函数、聚集计算被大量用于组织逻辑。其中,最典型的模式就是在 SELECT 之后挂载多个标量子查询(即只返回单一数据的查询),用来对主查询的数据进行进一步的处理。
我们来看一个典型的业务报表SQL写法:
sql
SELECT s11.id1,
(SELECT SUM(s22.id1) FROM s22 WHERE s22.id3 = s11.id3) AS sum_id1,
(SELECT SUM(s22.id2) FROM s22 WHERE s22.id3 = s11.id3) AS sum_id2
FROM s11;从业务语义上来看,这条SQL无可挑剔,它极大地迎合了开发人员的线性思维:从主表 s11 中取数据,并针对每一行记录,去关联表 s22 中分别计算特定条件下的总和。
然而,从数据库执行引擎的角度来看,这隐藏着极其严重的性能隐患。传统优化器面对这种SQL时,通常会采用"完整执行最外层父查询,对外层查询的每一条执行结果,执行一遍子查询"的策略。
这意味着什么?假设主表 s11 有10万条记录,那么跟在 SELECT 后面的两个标量子查询,将被分别触发执行10万次!总计需要进行20万次的独立查询。随着 s11 记录数的增多,查询耗时将呈指数级上升,产生可怕的嵌套循环效应。更令人遗憾的是,除了输出字段不同,这两个子查询的结构基本相同,分别独立执行造成了极大的算力浪费。
二、 技术深水区:消除标量子查询为什么那么难?
面对上述问题,有经验的研发往往会通过手动改写SQL,利用 JOIN (连接操作)和 GROUP BY 来代替。但如果希望由数据库的"优化器"在底层自动完成这个转换(即标量子查询消除),这个问题远没有想象中简单。
将 SELECT 之后的标量子查询改写为连接操作,其核心技术难点主要体现在语义安全性(Equivalence)的保证上。优化器如果处理不当,很容易偷偷改变SQL原本的语义,尤其是在以下高危场景中:
- 多行返回的掩盖陷阱: 按照SQL标准,当子查询的期望返回值是标量时,如果在运行时查出了多条记录,数据库应该直接抛出错误。但如果优化器盲目地将其改写为连接操作,查询不仅不会报错,反而会因笛卡尔积退化而默默返回多条错误记录。这样,会导致优化前后的语句不等价,业务系统读取到脏数据。
- 聚合函数的空值(NULL)陷阱: 这是一个非常经典的坑。当子查询的返回是聚合函数
COUNT时,如果在子表中匹配不到任何关联数据,原本的标量子查询会返回数字0。但是,如果强制将其转换为外连接进行消除,在没有匹配连接条件的情况下,外连接补齐的记录会补NULL值。这样一来,原本应该显示"0"的地方变成了"NULL",与原始结果产生严重偏差。
因此,业界主流的共识是:不是所有的标量子查询都可以被优化,优化引擎必须有极其严苛的等价性判定机制。
三、 破局与重构:基于等价性判定的精细化消除设计
为了应对HTAP时代愈发苛刻的性能挑战,国内数据库国家队电科金仓在这一领域做出了深度的底层内核探索。在金仓数据库 V009R002C014 及以上版本中 
针对上述痛点,专门引入了一套极其完善的标量子查询消除机制。
作为开发者,我仔细梳理了金仓数据库这套机制的工作流,其整体思路可以概括为极其严谨的三步走战略: 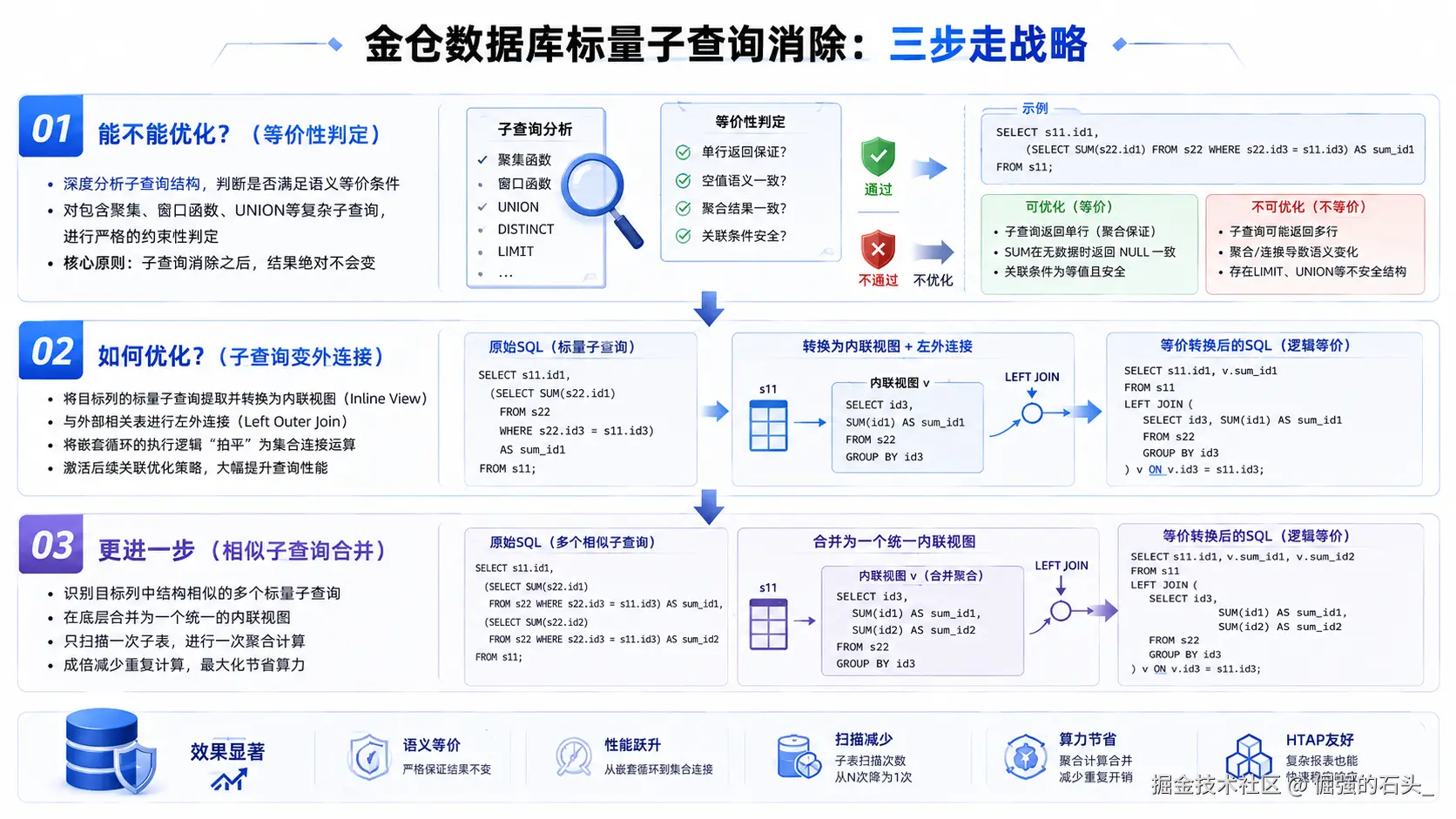
第一步:能不能优化?(等价性判定) 在这个阶段,优化器的目标不再是"尽可能地消除子查询",而是精准识别出那些绝对安全的子查询优化机会。引擎会深度分析子查询的结构,判断是否满足语义等价条件。对于包含聚集、窗口函数、UNION等复杂子查询,会进行严格的约束性判定,核心原则只有一条:"子查询消除之后,结果绝对不会变"。
第二步:如何优化?(子查询变外连接) 对于通过了等价性校验的子查询,便正式进入查询优化阶段。金仓数据库会将目标列的标量子查询提取并转换为内联视图(Inline View) ,随后将这个视图与外部的相关表进行左外连接(Left Outer Join)。通过将嵌套循环的执行逻辑"拍平"为集合间的连接运算,从而彻底激活后续的关联优化策略,大幅提高查询性能。
第三步:更进一步(相似子查询合并) 回想我们在第一节中提到的痛点代码(多个结构相似的子查询)。金仓数据库在这里做了一个非常惊艳的进阶处理:在目标列中,如果存在多个可合并的标量子查询,优化器会在底层将其合并为一个统一的内联视图,然后再与外部查询进行连接。这意味着对子表的扫描和聚合计算被合并到了最低限度,成倍减少了重复的算力消耗。
四、 动手实操:从32秒到24毫秒的真实性能验证
我们直接在金仓数据库环境中构造一个包含全表扫描和聚集函数的极端测试用例,来直观感受这项内核技术带来的震撼。
1. 构建测试环境 我们创建两张带有数值型主键的表 t1 和 t2,并利用 generate_series 函数各自插入1万条连续的数据。
sql
create table t1(id numeric(10,1));
create table t2(id numeric(10,1));
insert into t1 values(generate_series(1,10000));
insert into t2 values(generate_series(1,10000));2. 执行测试SQL 构造一个典型的主表全表扫描,并在 SELECT 列表中带上关联 t2 表的聚合标量子查询:
sql
select (select sum(id) from t2 where t1.id=t2.id) from t1;3. 执行计划与性能对比
系统这边会走 SubPlan 这条执行路径。简单说,就是 t1 表里每拿出一条记录,就要去 t2 表里完整扫一遍。t1 一共有1万条记录,那么 t2 就会被反复扫 1万次。这个开销其实很直接,也很好理解。在测试环境里,这条查询最后跑了 大概 32 秒。如果放到一个要求响应比较快的HTAP系统里,这个时间基本就没法接受了。 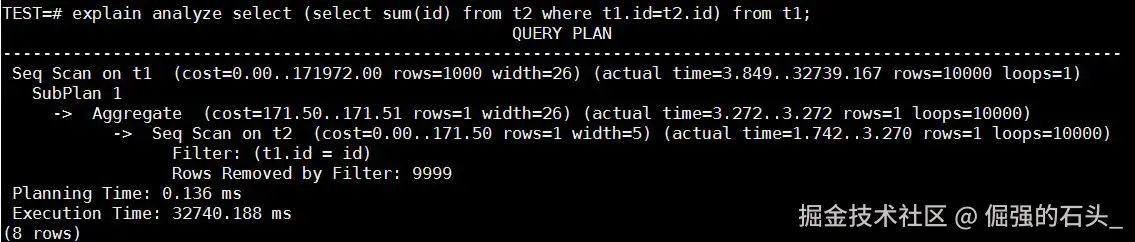
当我们在金仓数据库里依赖子查询消除这个特性再执行一次时:
执行计划就明显不一样了。优化器把原来底层的执行方式,改成了 Hash Left Join 再配合 HashAggregate,也就是哈希聚合。这里最关键的变化其实就一个:t2 表只需要被执行一次扫描。
所以最后的执行时间,也从原来的 32 秒,也就是 32000毫秒左右,降到了大约 24 毫秒。这个差距还是挺明显的。 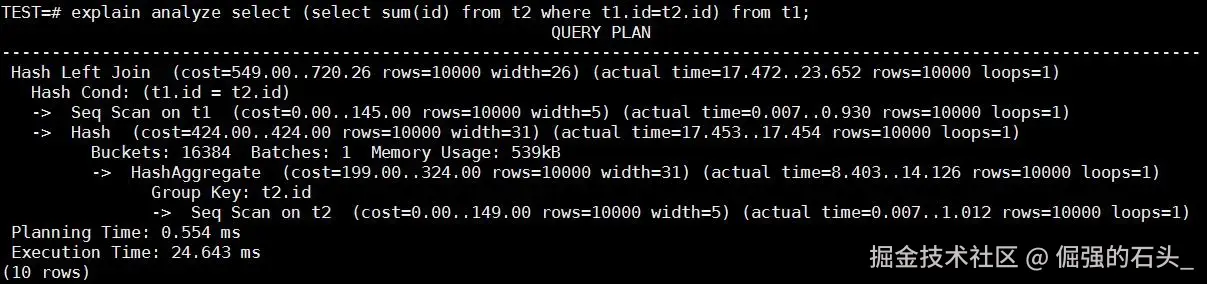
整整三个数量级的性能提升!并且在整个调优过程中,业务开发人员不需要修改哪怕一行前端SQL代码。
五、 总结与展望
在复杂报表,还有交易和分析混在一起跑的场景里,标量子查询消除这个技术,作用就比较实在。它把原本需要反复执行的嵌套操作,改写成只需要执行一次的连接子查询。结构差不多的子查询,也会被合并掉。也就是说,这不只是简单改一下SQL写法的问题。它背后更多考验的是数据库内核对关系代数等价变换的理解,以及能不能把这些转换推得足够准确。
面向2026年的主流HTAP架构,企业应用系统不只是要能把大量数据存下来,还得能把复杂分析算得快。一个现代数据库做得好不好,很大一部分要看优化器能不能把复杂查询处理好。像"标量子查询消除"这类内核层面的优化,表面看起 来不显眼,但对开发人员来说,确实能少操心很多底层执行细节。金仓数据库通过这些具体的优化能力,给企业核心业务提供更稳定的性能支撑。