本文档详细介绍了在 Kubernetes v1.27.16 集群上使用 Helm 快速部署企业级监控体系(Prometheus + Grafana + Alertmanager)的完整实践指南,涵盖持久化存储配置、自定义告警规则、钉钉机器人集成等核心功能,重点解决了 Helm HTTP/2 兼容性、Alertmanager receiver 配置、钉钉关键词匹配等常见问题,并推荐使用稳定的 v0.3.0 Webhook 版本,适用于 K8s 集群监控建设、生产环境告警集成及离线部署场景。
1. 环境准备
1.1 检查集群状态
bash
# 修复 kubeconfig 权限警告(重要!)
chmod 600 /root/.kube/config
# 检查节点状态
kubectl get nodes
# 检查核心组件状态
kubectl get pods -n kube-system
# 检查存储类(StorageClass)
kubectl get storageclass1.2 创建命名空间
bash
kubectl create namespace monitoring1.3 系统要求
- Kubernetes v1.27.16(三主三从)
- 每个节点至少 2GB 可用内存
- 建议配置持久化存储(NFS/Ceph/Local PV)
2. 安装 Helm
2.1 下载 Helm
bash
# 下载 Helm v3.12.0 或更高版本(推荐,修复 HTTP/2 兼容性问题)
wget https://get.helm.sh/helm-v3.12.0-linux-amd64.tar.gz
# 解压
tar -zxvf helm-v3.12.0-linux-amd64.tar.gz
# 移动到 PATH
mv linux-amd64/helm /usr/local/bin/helm
# 验证安装(如果看到权限警告,先执行:chmod 600 /root/.kube/config)
helm version注意:
- Helm v3.9.0 及更早版本与 GitHub 的 HTTP/2 协议存在兼容性问题
- 如果遇到
PROTOCOL_ERROR,请升级到 v3.12.0 或更高版本 - 或者使用下面的国内镜像源
2.2 添加 Prometheus 仓库
bash
# 重要:kube-prometheus-stack 只在 prometheus-community 仓库中
# 不要使用通用的 kubernetes 镜像源
# 方式1: 使用官方源(推荐,需要 Helm v3.12.0+)
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
# 方式2: 如果官方源有 HTTP/2 问题,先升级 Helm
wget https://get.helm.sh/helm-v3.12.0-linux-amd64.tar.gz
tar -zxvf helm-v3.12.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 更新仓库
helm repo update
# 验证仓库
helm repo list
# 搜索 chart(应该能看到结果)
helm search repo kube-prometheus-stack
helm search repo grafana常见问题解决:
-
遇到
PROTOCOL_ERROR错误:- 原因:Helm v3.9.0 与 GitHub HTTP/2 协议不兼容
- 解决:升级 Helm 到 v3.12.0+ 或使用下面的临时方案
-
遇到
context deadline exceeded错误:- 原因:网络连接超时
- 解决:检查网络或使用代理
-
搜索不到
kube-prometheus-stack:- 原因:使用了错误的仓库源(如阿里云通用 k8s 镜像)
- 解决:必须使用 prometheus-community 专用仓库
bash# 错误的做法(不包含 kube-prometheus-stack) helm repo add prometheus-community https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts # 正确的做法 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts -
临时禁用 HTTP/2:
bashexport GODEBUG=http2client=0 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update unset GODEBUG
3. 部署 Prometheus Stack
推荐使用kube-prometheus-stack部署,也可以每个组件单独部署,我这里采用kube-prometheus-stack部署
kube-prometheus-stack 包含了 Prometheus、Grafana、Alertmanager 和常用的 exporters。
3.1在线安装(需要访问 GitHub)
创建自定义 values 文件
yaml
# prometheus-values.yaml
# Prometheus Stack 完整配置
# 全局配置 - 设置默认镜像仓库
global:
imageRegistry: "" # 留空,各组件单独指定
prometheusOperator:
admissionWebhooks:
enabled: true
patch:
enabled: true
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/kube-webhook-certgen
tag: "1.8.2"
pullPolicy: IfNotPresent
createSecretJob:
resources: {}
patchWebhookJob:
resources: {}
prometheus:
prometheusSpec:
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/prometheus
tag: v3.11.3
retention: 15d
resources:
requests:
memory: 2Gi
cpu: 500m
limits:
memory: 4Gi
cpu: 1000m
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: managed-nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
service:
type: NodePort
nodePort: 30090
alertmanager:
alertmanagerSpec:
# 引用已存在的 Secret 作为 Alertmanager 配置
configSecret: prometheus-alertmanager-config
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/alertmanager
tag: v0.32.1
storage:
volumeClaimTemplate:
spec:
storageClassName: managed-nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
resources:
requests:
memory: 200Mi
cpu: 100m
limits:
memory: 400Mi
cpu: 200m
service:
type: NodePort
nodePort: 30093
grafana:
adminPassword: "admin123"
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/grafana
tag: 13.0.1
persistence:
enabled: true
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
size: 1Gi
resources:
requests:
memory: 200Mi
cpu: 100m
limits:
memory: 400Mi
cpu: 200m
service:
type: NodePort
nodePort: 30300
nodeExporter:
enabled: true
kube-state-metrics:
enabled: true
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/kube-state-metrics
tag: v2.18.0安装 Prometheus Stack(在线)
bash
# 重要:先更新仓库索引
helm repo update
# 查看可用的 kube-prometheus-stack 版本
helm search repo kube-prometheus-stack --versions | head -20
# 注意:不同版本对 Kubernetes 版本有要求
# - kube-prometheus-stack >= 80.x 需要 K8s >= 1.25(推荐最新稳定版)
# - kube-prometheus-stack 57.x - 79.x 需要 K8s >= 1.25
# - kube-prometheus-stack 50.x - 56.x 需要 K8s >= 1.25
# - kube-prometheus-stack 45.x - 49.x 需要 K8s >= 1.23
# - kube-prometheus-stack 40.x - 44.x 需要 K8s >= 1.19
# 根据您的 K8s 版本选择合适的 chart 版本:
# K8s v1.27.16 用户(推荐使用 55.x+ 或最新版 84.x+)
# 选项1:使用稳定版本 55.0.0(经过长期验证)
helm install prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--values prometheus-values.yaml \
--version 55.0.0
# 选项2:使用最新版本 84.5.0(功能最全,bug修复最多)
# helm install prometheus prometheus-community/kube-prometheus-stack \
# --namespace monitoring \
# --create-namespace \
# --values prometheus-values.yaml \
# --version 84.5.0
# 查看安装状态
helm status prometheus -n monitoring
# 查看所有 Pod
kubectl get pods -n monitoring3.2 离线安装(国内网络环境推荐)
步骤 1:在有网络的机器上下载 Chart 包
bash
# 在可以访问 GitHub 的机器上执行
# 添加仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 搜索合适的版本(K8s v1.27.16 推荐 55.x+ 或最新版 84.x+)
helm search repo kube-prometheus-stack --versions | grep "8[0-9]\." # 查看最新版
helm search repo kube-prometheus-stack --versions | grep "5[5-9]\." # 查看稳定版
# 下载 Chart 包(以 84.5.0 为例,最新版)
helm pull prometheus-community/kube-prometheus-stack --version 84.5.0
#或者直接网页下载
https://github.com/prometheus-community/helm-charts/releases/download/kube-prometheus-stack-84.5.0/kube-prometheus-stack-84.5.0.tgz
# 会生成文件:kube-prometheus-stack-84.5.0.tgz
ls -lh kube-prometheus-stack-84.5.0.tgz
# 或者下载稳定版 55.0.0
# helm pull prometheus-community/kube-prometheus-stack --version 55.0.0步骤 2:传输到目标服务器
bash
# 将下载的 .tgz 文件传输到 master-1 节点
scp kube-prometheus-stack-84.5.0.tgz root@master-1:/root/步骤 3:在目标服务器上离线安装
bash
# 在 master-1 上执行
# 确认文件已上传
ls -lh /root/kube-prometheus-stack-84.5.0.tgz
ls -lh /root/prometheus-values.yaml
# 创建命名空间
kubectl create namespace monitoring
# 使用本地 Chart 包安装(不需要网络连接)
helm install prometheus /root/kube-prometheus-stack-84.5.0.tgz \
--namespace monitoring \
--values /root/prometheus-values.yaml
# 查看安装状态
helm status prometheus -n monitoring
# 查看所有 Pod
kubectl get pods -n monitoring步骤 4:预拉取所需镜像(可选但推荐)
由于 Chart 中引用的镜像可能也需要从国外拉取,建议提前准备:
bash
# 查看 Chart 需要的镜像列表
helm show values /root/kube-prometheus-stack-84.5.0.tgz | grep -A 2 "repository:"
# 或者解压 Chart 查看
mkdir -p /tmp/chart
tar -zxvf /root/kube-prometheus-stack-84.5.0.tgz -C /tmp/chart
cat /tmp/chart/kube-prometheus-stack/values.yaml | grep repository
# 常见需要的镜像:
# - quay.io/prometheus/prometheus
# - quay.io/prometheus/alertmanager
# - grafana/grafana
# - quay.io/prometheus/node-exporter
# - registry.k8s.io/kube-state-metrics/kube-state-metrics
# 在国内环境下,建议使用国内镜像源或私有仓库
# 可以在 values.yaml 中修改镜像地址为国内源修改 values.yaml 使用国内镜像(如果需要)
yaml
# prometheus-values.yaml
# 全局配置 - 设置默认镜像仓库
global:
imageRegistry: "" # 留空,各组件单独指定
prometheusOperator:
admissionWebhooks:
enabled: true
patch:
enabled: true
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
# 关键:repository 不包含 registry,tag 单独指定
repository: liuxing666/kube-webhook-certgen
tag: "1.8.2"
pullPolicy: IfNotPresent
# 在全局或这里指定 registry
createSecretJob:
resources: {}
patchWebhookJob:
resources: {}
prometheus:
prometheusSpec:
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/prometheus
tag: v3.11.3
alertmanager:
alertmanagerSpec:
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/alertmanager
tag: v0.32.1
grafana:
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/grafana
tag: 13.0.1
nodeExporter:
enabled: true
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/node-exporter
tag: v1.11.1
#kubeStateMetrics:
kube-state-metrics:
enabled: true
image:
registry: "registry.cn-hangzhou.aliyuncs.com"
repository: liuxing666/kube-state-metrics
tag: v2.18.0
#创建阿里云ImagePullSecrets
kubectl create secret docker-registry aliyun-registry-secret \
--docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=liuxing5928 \
--docker-password=xxx \
--docker-email=1573374330@qq.com \
-n monitoring
#为了让该命名空间下所有 Pod 都能自动使用这个凭据,将其添加到默认的 ServiceAccount 中:
kubectl patch serviceaccount default \
-p '{"imagePullSecrets": [{"name": "aliyun-registry-secret"}]}' \
-n monitoring然后使用修改后的 values 文件安装:
bash
helm install prometheus /root/kube-prometheus-stack-84.5.0.tgz \
--namespace monitoring \
--values /root/prometheus-values.yaml版本兼容性参考:
| Kubernetes 版本 | 推荐的 kube-prometheus-stack 版本 | 说明 |
|---|---|---|
| v1.16 - v1.18 | 20.x - 30.x | 较旧版本 |
| v1.19 - v1.24 | 35.x - 44.x | 稳定版本 |
| v1.25 - v1.27 | 50.x - 84.x (推荐 55.x+ 或 84.x+) | 当前适用 |
| v1.28 - v1.31 | 57.x - 84.x (推荐最新版) | 最新版本 |
重要说明:
- K8s v1.27.16 完全兼容 kube-prometheus-stack 84.5.0(最低要求 K8s v1.25+)
- 推荐使用 84.5.0:包含最新功能、bug 修复和安全更新
- 或使用 55.0.0:经过长期验证的稳定版本
- 不要直接使用文档中的版本号,先通过
helm search确认可用版本 - 不同 Helm 仓库的版本号可能不同
- 安装前检查版本兼容性:
helm show chart prometheus-community/kube-prometheus-stack --version <VERSION> | grep kubeVersion
针对 K8s v1.27.16 的安装示例:
bash
# 查看可用的兼容版本(84.x 最新版)
helm search repo kube-prometheus-stack --versions | grep "8[0-9]\."
# 安装最新版 84.5.0(推荐)
helm install prometheus /root/kube-prometheus-stack-84.5.0.tgz \
--namespace monitoring \
--values /root/prometheus-values.yaml
#查看是否部署成功
helm list -n monitoring
kubectl get pods -n monitoring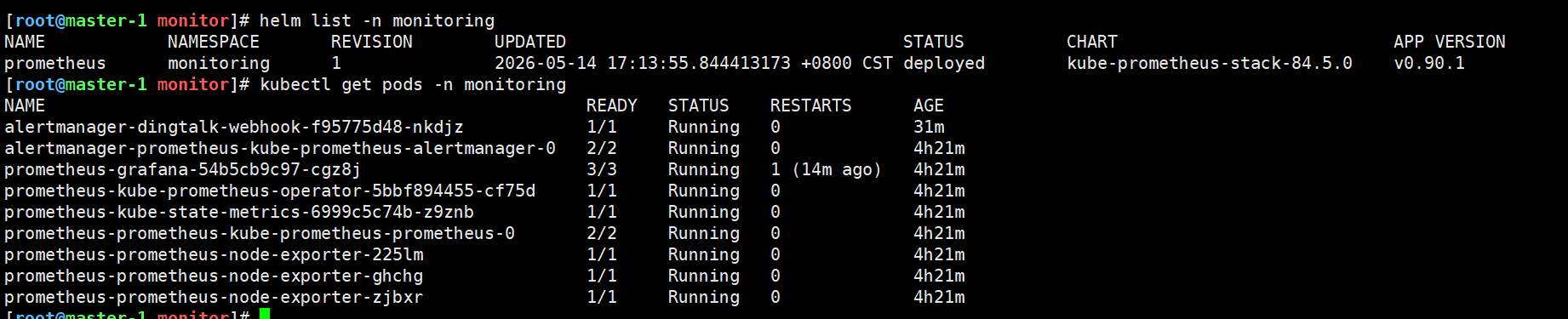
4. 访问监控界面
4.1 获取访问信息
bash
# 查看服务
kubectl get svc -n monitoring
# 获取 Grafana 密码
kubectl get secret -n monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo4.2 通过 NodePort 访问
如果使用 NodePort,访问地址:
- Grafana: http://<任意节点IP>:30300
- Prometheus: http://<任意节点IP>:30090
- Alertmanager: http://<任意节点IP>:30093
4.3 通过 Ingress 访问(推荐生产使用)
编写ingress访问规则
yaml
# ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: monitoring-ingress
namespace: monitoring
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: grafana.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-grafana
port:
number: 80
- host: prometheus.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-kube-prometheus-prometheus
port:
number: 9090
- host: alertmanager.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-kube-prometheus-alertmanager
port:
number: 9093部署ingress规则
bash
kubectl apply -f ingress.yaml
kubectl get svc -n ingress-nginx
配置hosts测试
sh
192.168.91.22 grafana.example.com prometheus.example.com alertmanager.example.com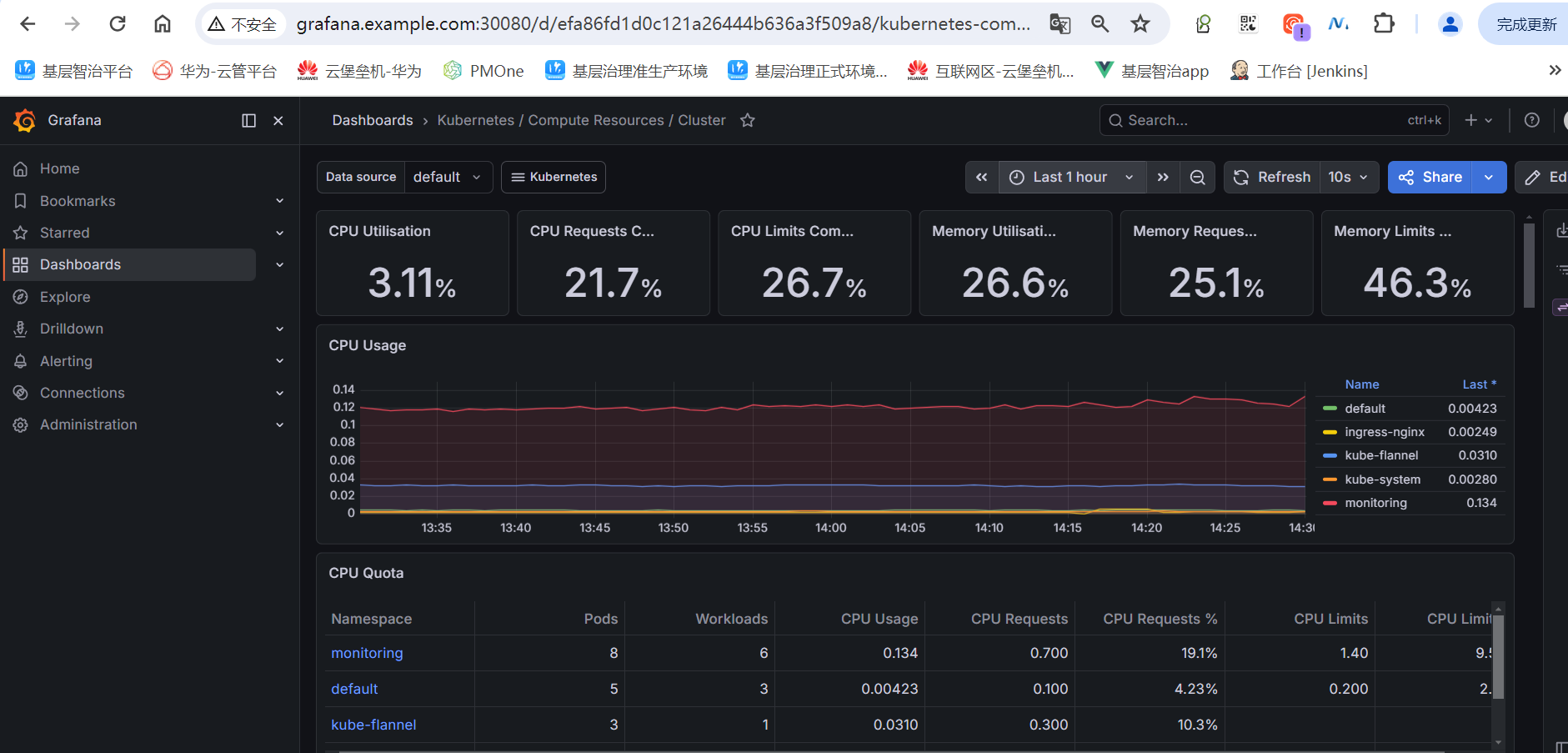
5. 配置告警规则
5.1 创建自定义告警规则
yaml
# custom-alert-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: custom-alert-rules
namespace: monitoring
labels:
release: prometheus
spec:
groups:
- name: node.rules
rules:
- alert: HighCpuUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 50
for: 1m
labels:
severity: warning
annotations:
summary: "[注意]节点 {{ $labels.instance }} CPU 使用率过高"
description: "[注意]CPU 使用率超过 80%,当前值: {{ $value }}%"
- alert: HighMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "[注意]节点 {{ $labels.instance }} 内存使用率过高"
description: "[注意]内存使用率超过 85%,当前值: {{ $value }}%"
- alert: DiskSpaceLow
expr: (1 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"})) * 100 > 85
for: 10m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.instance }} 磁盘空间不足"
description: "根分区使用率超过 85%,当前值: {{ $value }}%"
- name: k8s.rules
rules:
- alert: PodCrashLooping
expr: rate(kube_pod_container_status_restarts_total[15m]) * 60 * 5 > 0
for: 15m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 频繁重启"
description: "Pod 在 15 分钟内重启次数过多"
- alert: PodNotReady
expr: kube_pod_status_ready{condition="true"} == 0
for: 1m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 未就绪"
description: "Pod 已经 10 分钟未处于 Ready 状态"
- alert: NodeNotReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.node }} 不可用"
description: "节点已经 5 分钟处于 NotReady 状态"
bash
kubectl apply -f custom-alert-rules.yaml5.2 查看现有告警规则
bash
# 查看所有告警规则
kubectl get prometheusrules -n monitoring
# 在 Prometheus UI 中查看
# 访问 http://<prometheus-ip>:9090/rules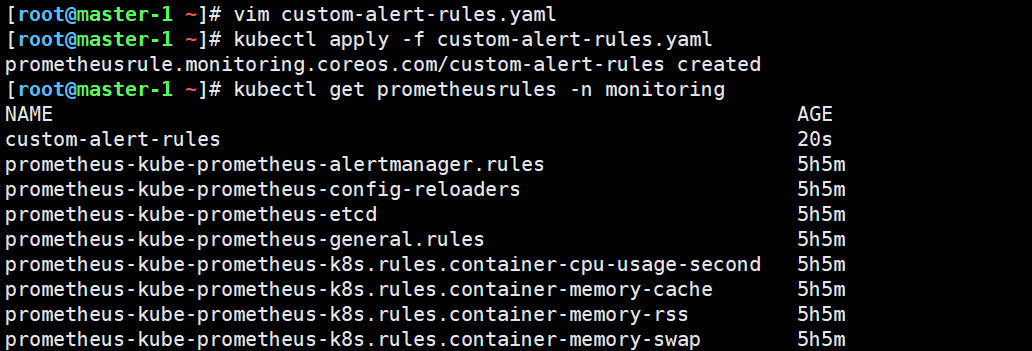
6. 配置钉钉/企业微信告警
6.1 配置 Alertmanager 接收器
yaml
# alertmanager-config.yaml
apiVersion: v1
kind: Secret
metadata:
name: prometheus-alertmanager-config
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'dingtalk'
routes:
- match:
severity: critical
receiver: 'dingtalk'
repeat_interval: 1h
- match:
severity: warning
receiver: 'dingtalk'
repeat_interval: 4h
receivers:
- name: 'dingtalk'
webhook_configs:
- url: 'http://alertmanager-dingtalk-webhook:8060/dingtalk/webhook/send'
send_resolved: true6.2 部署钉钉 Webhook 适配器
yaml
#cat dingtalk-webhook.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: dingtalk-webhook-config
namespace: monitoring
data:
config.yml: |
## Request timeout
# timeout: 5s
## Customizable templates
templates:
- /etc/prometheus-webhook-dingtalk/templates/*.tmpl
## Targets, previously was known as "profiles"
targets:
webhook:
url: https://oapi.dingtalk.com/robot/send?access_token=e23acb6955b2acefca12a64665197f8044843b8f29090538d5f0195fed36ce11
message:
text: '{{ template "dingtalk.default.message" . }}'
# secret for signature
# secret: SECxxxxxx
---
apiVersion: v1
kind: ConfigMap
metadata:
name: dingtalk-templates
namespace: monitoring
data:
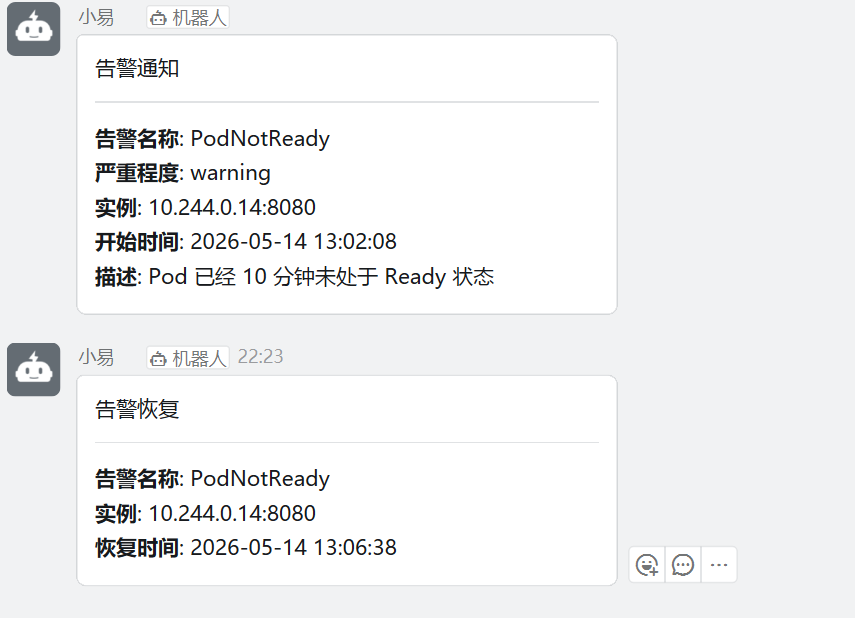
default.tmpl: |
{{ define "dingtalk.default.message" }}
{{ if gt (len .Alerts.Firing) 0 -}}
告警通知
{{ range .Alerts.Firing }}
---
**告警名称**: {{ .Labels.alertname }}
**严重程度**: {{ .Labels.severity }}
**实例**: {{ .Labels.instance }}
**开始时间**: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
**描述**: {{ .Annotations.description }}
{{ end }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
告警恢复
{{ range .Alerts.Resolved }}
---
**告警名称**: {{ .Labels.alertname }}
**实例**: {{ .Labels.instance }}
**恢复时间**: {{ .EndsAt.Format "2006-01-02 15:04:05" }}
{{ end }}
{{- end }}
{{ end }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager-dingtalk-webhook
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: dingtalk-webhook
template:
metadata:
labels:
app: dingtalk-webhook
spec:
containers:
- name: webhook
image: timonwong/prometheus-webhook-dingtalk:v2.1.0
args:
- --config.file=/etc/prometheus-webhook-dingtalk/config.yml
- --web.listen-address=:8060
ports:
- containerPort: 8060
volumeMounts:
- name: config
mountPath: /etc/prometheus-webhook-dingtalk
readOnly: true
- name: templates # 添加模板卷挂载
mountPath: /etc/prometheus-webhook-dingtalk/templates
readOnly: true
volumes:
- name: config
configMap:
name: dingtalk-webhook-config
- name: templates
configMap:
name: dingtalk-templates
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager-dingtalk-webhook
namespace: monitoring
spec:
selector:
app: dingtalk-webhook
ports:
- port: 8060
targetPort: 8060注意 : 将 access_token 写您的钉钉机器人 Token。
bash
kubectl apply -f dingtalk-webhook.yaml
kubectl apply -f alertmanager-config.yaml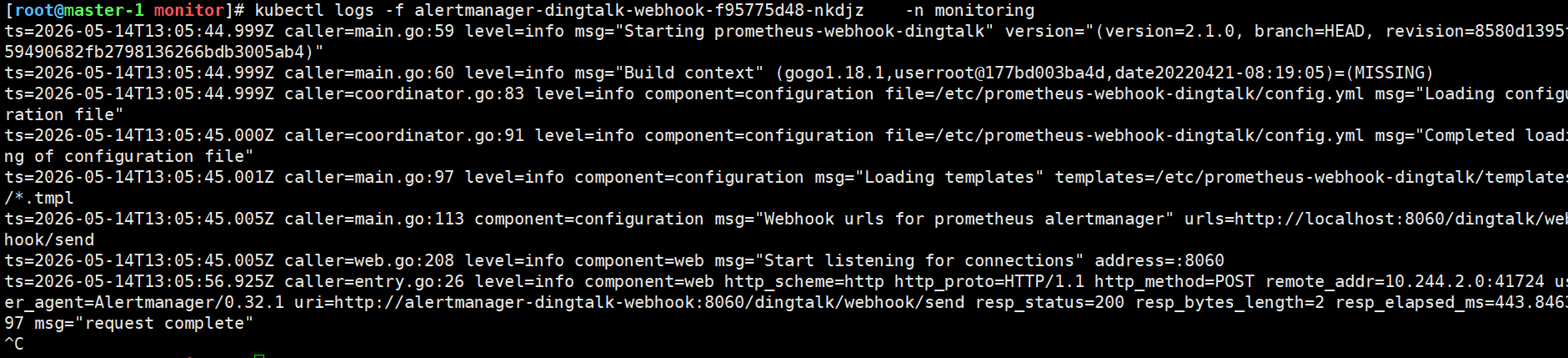
7. 常见问题排查
7.1 Pod 无法启动
bash
# 查看 Pod 状态
kubectl get pods -n monitoring -o wide
# 查看 Pod 详情
kubectl describe pod <pod-name> -n monitoring
# 查看日志
kubectl logs <pod-name> -n monitoring
# 查看 PVC 状态
kubectl get pvc -n monitoring7.2 持久化存储问题
bash
# 检查 PV/PVC 绑定
kubectl get pv,pvc -n monitoring
# 检查 StorageClass
kubectl get storageclass
# 手动创建目录并设置权限
mkdir -p /data/prometheus
chown -R 65534:65534 /data/prometheus # nobody 用户7.3 Prometheus 数据采集问题
bash
# 检查 serviceMonitor
kubectl get servicemonitor -n monitoring
# 重新加载配置
kubectl rollout restart deployment/prometheus-kube-prometheus-operator -n monitoring7.4 Grafana 数据源问题
bash
# 检查 Grafana 数据源
# 访问 Grafana -> Configuration -> Data Sources
# 手动添加 Prometheus 数据源
# URL: http://prometheus-kube-prometheus-prometheus.monitoring.svc:90907.5 资源不足
bash
# 查看资源使用情况
kubectl top pods -n monitoring
# 调整资源限制
helm upgrade prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--set prometheus.prometheusSpec.resources.requests.memory=4Gi \
--set prometheus.prometheusSpec.resources.limits.memory=8Gi7.6 卸载重装
bash
# 卸载
helm uninstall prometheus -n monitoring
# 删除命名空间
kubectl delete namespace monitoring8. 常用监控面板导入
8.1 可以去grafana官网面板导入
在 Grafana 中导入以下面板:
Node Exporter Full - ID: 1860
8.2 导入步骤
- 登录 Grafana
- 左侧菜单 -> Dashboards -> Import
- 输入面板 ID
- 选择 Prometheus 数据源
- 点击 Import
9. 备份与恢复
9.1 备份 Grafana 仪表板
bash
# 导出所有仪表板
kubectl get configmap -n monitoring -l grafana_dashboard -o yaml > grafana-dashboards-backup.yaml9.2 备份 Prometheus 数据
bash
# 进入 Prometheus Pod
kubectl exec -it -n monitoring <prometheus-pod> -- /bin/sh
# 压缩数据目录
tar czf /tmp/prometheus-data.tar.gz /prometheus
# 复制到本地
kubectl cp monitoring/<prometheus-pod>:/tmp/prometheus-data.tar.gz ./prometheus-backup.tar.gz总结
本手册提供了在 Kubernetes v1.27.16 集群上部署完整监控体系的详细步骤:
✅ Helm 安装和管理
✅ Prometheus + Grafana + Alertmanager 一体化部署
✅ 持久化存储配置
✅ 自定义告警规则
✅ 钉钉/企业微信告警集成
✅ 常见问题排查