目录
[1.0 简介](#1.0 简介)
[2.0 ETL概述](#2.0 ETL概述)
[(2)ETL API概述](#(2)ETL API概述)
[3.0 Doucument](#3.0 Doucument)
[4.0 Writers](#4.0 Writers)
[5.0 Redis Vector Store](#5.0 Redis Vector Store)
[6.0 Pinecone Vector Store](#6.0 Pinecone Vector Store)
[7.0 重排序:(Re-Ranking)](#7.0 重排序:(Re-Ranking))
[(2) RAG的应用场景](#(2) RAG的应用场景)
[1.0 简介](#1.0 简介)
[2.0 五种模式](#2.0 五种模式)
[(1) Chain Workflow 链式工作流](#(1) Chain Workflow 链式工作流)
[(2) Parallelization Workflow 并行化工作流](#(2) Parallelization Workflow 并行化工作流)
[(3) Routing Workflow 路由工作流](#(3) Routing Workflow 路由工作流)
[(4) Orchestrator-Worker 编排器工作者模式](#(4) Orchestrator-Worker 编排器工作者模式)
[(5) Evaluator-Optimizer 评估-优化循环](#(5) Evaluator-Optimizer 评估-优化循环)
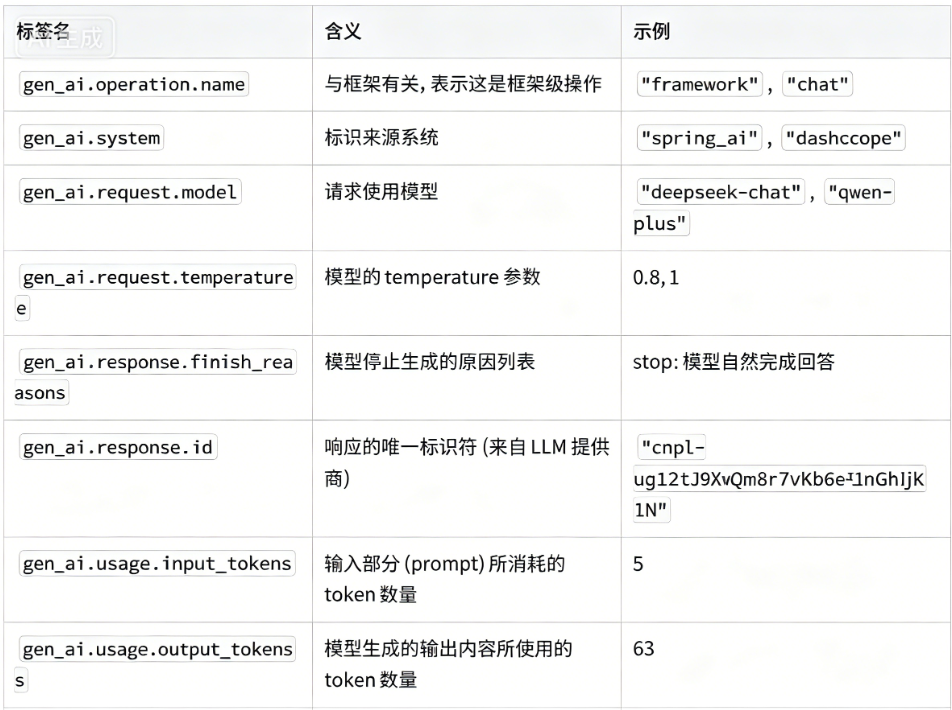
[3.0 Observability 可观测性](#3.0 Observability 可观测性)
[(1) 引入](#(1) 引入)
[(3) 观察监控指标](#(3) 观察监控指标)
一、RAG
1.0 简介
(1)简介
RAG:Retrieval AugmentedGeneration 检索增强生成 是一种结合信息检索和文本生成的混合架构
RAG 就像给AI装上了"外挂⼤脑", 让它在回答问题时, 先从外部知识库 (如⽂档、数据库) 中检索相关⽚段, 再将这些⽚段作为上下⽂, 输⼊给模型. 这样, AI的回答就基于真实、最新数据, ⼤幅减少"幻觉", 同时⽀持动态知识更新. //传统大模型依赖训练数据中的知识,但无法获取最新的信息以及一些非公开信息。
RAG让AI从背书机器升级成为 会查资料的专家 ,适合需要高准确性的场景。
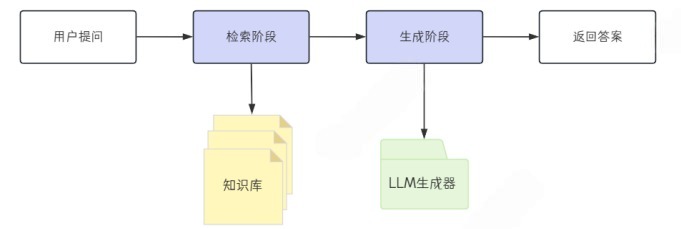
核心是:先查资料,再回答
工作流程:
概念解释:
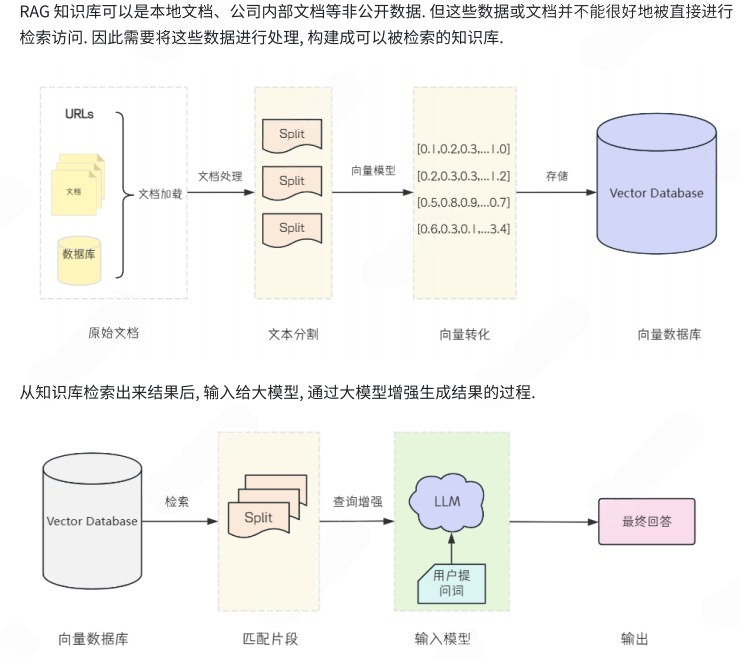
文档加载:springAI提供了多种不同的文档加载器,可以加载包括PDF在内的非结构化数据 或者包括SQL在内的结构化数据
存储:文档转换成向量的方式 将Embedding后的向量数据,存储到向量数据库中
(2)相关技术
向量: 向量常被用来将文本、图像、音频等复杂对象映射到高维空间中的点
每一个维度代表某种潜在的语气特征或属性 它们共同编码了对象的意义和特性
当我们把词语输入给同一模型时,它们会被转成中各自的向量表示 //和Langchain那里的知识类
机器可以通过计算向量间的距离或者角度来判断两个对象是否相似
常见的相似度量方法包括:余弦相似度 欧式距离
Ebedding是将文本映射为向量的技术 计算机擅长处理数字,Embedding的核心思想就是将人类世界的符合转换为计算机能够理解的数值形式,并且要求这种转换能够保留原始符号的语义和关系。
向量数据库:以向量作为最基本存储单元,支持对非结构化数据进行语义级相似性搜索
向量数据库的优点是快速查找 普通的数据库也能存储向量
(3)RAG快速入门
RAG是一套流水线,SpringAI框架为我们提供了RAG全流程的支持
文档加载 文档拆分 向量转换 向量存储 相似检索 查询增强
作为第一个RAG程序,省略掉文档加载和拆分 分为文本向量化向量存储相似性检索查询增强
创建Module : rag-demo
完善pom.xml: spring-boot-starter-web 和 spring-boot-starter-test
添加启动类:
文本向量化:目前常见的大语言模型(如deepseek)并不具备文本向量化的能力 因此需要引入专门的模型来完成这项工作
百炼平台提供的向量模型来学习 ollama也可以
添加依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>配置文件:
java
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}测试文本向量化:
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class TextEmbedTest {
@Autowired
private DashScopeEmbeddingModel embeddingModel;
@Test
void testTextEmbed() {
float[] embedded = embeddingModel.embed("嘟嘟嘟");
System.out.println(embedded.length);
System.out.println(Arrays.toString(embedded));
}
}输出结果:
这样就是把"嘟嘟嘟"转成了一个1534的向量
向量存储:

SimpleVectorStore 翻译:简单的向量存储
是SpringAI内置的一个"内存版"向量数据库,无需外部依赖,开箱即用,特别适合本地测试和快速原型开发。
快速上手:
定义VectroStore
java
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.dashscope.embedding.DashScopeEmbeddingModel;
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}//@TestConfiguration注解:会被SpringTest框架加载,但不会被组件扫描,所以比较适合用于覆盖主配置中的Bean 如果想要在测试中替换某个生产环境中的Bean,可以使用
存储文档到VectrorStore:
java
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.Arrays;
@Test
public void init(@Autowired VectorStore vectorStore) {
// 1. 声明内容文档
Document doc = Document.builder()
.text("2025年夏季奥运会将于巴黎举行, 预计吸引全球数百万观众")
.build();
Document doc2 = Document.builder()
.text("对比学习框架下多语言BERT模型的语义表示分析")
.build();
Document doc3 = Document.builder()
.text("暮色中的老槐树在风中摇曳, 枯枝划破绯红的晚霞")
.build();
Document doc4 = Document.builder()
.text("基于Transformer的预训练模型在机器翻译中的迁移学习研究")
.build();
// 2. 将文本进行向量化, 并且存入向量数据库
vectorStore.add(Arrays.asList(doc, doc2, doc3, doc4));
System.out.println("向量数据库初始化完成");
}代码讲解: vectorStore.add(Arrays.asList(doc, doc2, doc3, doc4));
调用add方法 会用embeddingModel把文本转成向量 把原始文本和向量一起存进内存列表
可以查看源码理解一下
观察向量数据库:
通过debug 观察向量数据库存储内容

相似性检索:
向量存储到向量数据库之后,就可以来查找了,把上述代码进行修改:
java
@Test
void similaritySearchTest(@Autowired VectorStore vectorStore) {
// 3. 相似性查询
SearchRequest searchRequest = SearchRequest
.builder()
.query("机器学习")
.topK(5)
.similarityThreshold(0.3)
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 4.输出
System.out.println(results);
}query是要查询的文本 topk返回相似度最高的5个结果 similarityThreshold(0.3):过滤掉相似度低于0.3的结果,避免返回完全不想关的内容 调用SimpleVectorStore的similaritySearchg方法,把库中所有文档向量与机器学习的向量做余弦相似度的计算,返回符合条件的Document列表 SearchRequest这个类是SpringAI中用于封装相似性搜索查询参数的一个对象
//这个测试模拟了一个典型的RAG流程中的检索步骤
Advisor:
翻译:顾问 增强器
Advisior让数据预处理,RAG检索,日志记录,安全过滤等操作可以像插件一样灵活挂载到AI交互流程中。
QuestionAnswerAdvisor RetrievalAugementationAdvidsor是SpringAI中实现RAG的两个核心组件 分别适用于不同的场景
QuestionAnswerAdvisor:是专门为问答系统设计的Advisor实现 当你希望快速构建一个基于知识库的智能客服或FAQ助手时,它是首选方案 在用户提问时,它会自动将问题转换为Embedding向量,并在配置好的向量存储中进行相似性搜索,找出最相关的文档片段
适用场景:企业内部制度查询,产品帮助文档问答,标准化流程咨询结构化程度较高的问答任务
RetrievalAgugementationAdvisor:灵活可控的通用RAG增强层 它提供了更高级别的可定制能力,它不局限于问答场景,而是作为一个通用的增强层,适用于任何需要引入外部知识的生成任务。 开发者可以通过自定义的Retriever接口来控制检索逻辑
java
@Bean
public RetrievalAugmentationAdvisor retrievalAugmentationAdvisor(ChatModel chatModel, VectorStore vectorStore) {
var retriever = new VectorStoreRetriever(vectorStore, 3); // 检索 top-3 结果
// 自定义 Prompt 模板
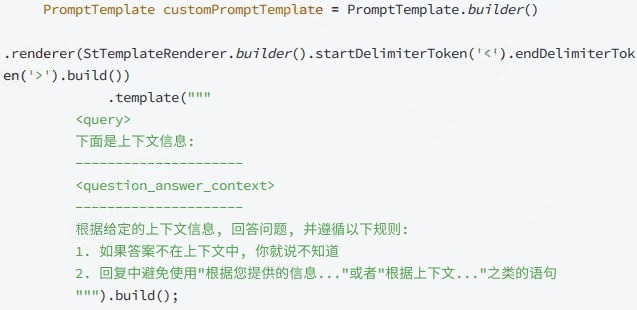
String promptTemplate = """
你是一个企业智能助手, 请根据以下【参考资料】回答问题.
如果资料中没有相关信息, 请回答"抱歉, 我无法找到相关信息. "
【参考资料】:
{documents}
【问题】:
{question}
【回答】:
""";
PromptTemplate template = new PromptTemplate(promptTemplate);
return RetrievalAugmentationAdvisor.builder()
.retriever(retriever) // 使用自定义检索器
.chatModel(chatModel) // 使用 LLM 生成回答
.promptTemplate(template) // 使用自定义模板
.build();
}就是相当于智能问答顾问 这个顾问接到问题之后,不会直接让AI瞎猜,在向量库里面找到相似的资料 然后把这3篇资料塞进一个你写好的提示模板里面 让大模型ChatModel根据这些资料来回答,如果资料找不到就说不知道
promptTemplate 是一个提示词模板
代码案例:
添加依赖: 要使用QuestionAnswerAdvisor 需要添加spring-ai-advisors-vector-store依赖项
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>检索增强生成:
AI模型并不知道向量数据库存储的数据, 当⽤⼾问题发送到 AI 模型时, QuestionAnswerAdvisor会向向量数据库查询与⽤⼾问题相关的⽂档, 检索出来的⽂档, 会被附加到⽤⼾⽂本, 为AI模型响应提供 上下⽂。
java
@Test
void chatRagTest(@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel) {
ChatClient chatClient = ChatClient.builder(chatModel)
.build();
String message = "奥运会什么时候举行";
String content = chatClient.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(message)
.call()
.content();
System.out.println(content);
}为了更好的搜索文档 我们可以在创建QuestionAnswerAdviosr时,配置SearchRequest(一个类似SQL的过滤器表达式) //其实就是缩小范围 向量相似度决定内容上相关,过滤器决定条件上必须满足 它们两个一配合 搜索文档就像点菜一样精准
java
@Test
void chatRagTest2(@Autowired VectorStore vectorStore, @Autowired DashScopeChatModel chatModel) {
ChatClient chatClient = ChatClient.builder(chatModel)
.build();
String message = "奥运会什么时候举行";
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest
.builder()
.query(message)
.topK(5)
.similarityThreshold(0.3)
.build()
)
.build();
String content = chatClient.prompt()
.advisors(advisor)
.user(message)
.call()
.content();
System.out.println(content);
}使用QuestionAnswerAdvisor完成问答场景时,有一个默认的模板,来使用检索到的文档来补充用户问题
java
PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate("""
{query}
Context information is below, surrounded by ---------------------
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
""");query : 先把用户原封不动的问题放上去
Context information is below:相当于直接告诉AI 参考资料在下面 我用虚线给你框起来了 你注意
question_answer_context:这里自动填入从向量库搜出来的相关文档内容
give the context: 这个是最后的指令 你就只凭 刚才给你的那些资料和对话历史来回答,别用你自己以前学过的知识。如果资料里找不到答案,就老实告诉用户你不知道,别硬编。"
整体效果:向量库检索 搜到的文档塞进去 放到query位置 这道模板拼出一个完整的prompt 交给AI模型去生成问答
开发⼈员也可以通过 .promptTemplate() 提供⾃⼰的 PromptTemplate 对象来⾃定义此⾏为.
修改提示词,改为知识库中不存在的信息,比如1是质数吗 在观察返回结果
"1返回质数"是 AI 在没找到参考资料时,偷偷用了自己模糊的记忆犯下的常识错误。这说明光靠 RAG 还不能百分百杜绝幻觉,得从提示词和知识库覆盖两方面一起下手才行。
2.0 ETL概述
(1)简介
前面介绍了RAG的基本操作之后 深入 聊聊RAG中一个非常关键的环节------ETL
RAG的核⼼理念是通过从⼤量数据中检索相关信息来增强⽣成式AI模型的能⼒, 从⽽提⾼⽣成内容的质量和相关性. ⽽ETL过程正是实现这⼀⽬标的关键环节⸺它将原始⽂档转化为可以被⾼效检索和使⽤的结构化数据, 为后续的检索和⽣成过程奠定基础.
E: extract 提取 T: transform 转换 L:load 加载
就像是一家餐厅的 食材处理流程啊
ETL是数据的准备阶段 负责构建和维护这个知识库 没有高质量的RAG,后面的检索和生成都会成为 巧妇难为无米之炊
提取 转换 加载具体过程就不介绍了
(2)ETL API概述
SpringAI框架也提供了支持 ETL管道负责将原始 、 非结构化的数据源转换为结构化向量存储格式 确保数据处于最合适AI模型检索的优化状态
Spring AI的ETL API设计简洁⽽强⼤, 主要由三个核⼼组件构成, 每个组件都对应着ETL过程中的⼀个关键阶段
形象化解释一下: //就是怎么把一堆烂七八糟的原始资料,自动整理好,然后存进AI能懂的知识库

3.0 Doucument
Document数据模型
是ETL API的核心数据模型 它构成了整个数据处理流程的基本单元
一个Document实例包含文本,元数据和其他可选的媒体类型(如图像和音频和视频)
Document就像是这个ETL流水线上的标准快递盒 后续的工序只认这个盒子,不看原料长啥样
Document里面装了 文本 和 元数据(这个文案的那个的说明 作者啦 第几页了 部门啦 什么时候创建的 等等 像是快递单)
DocumentReader文档阅读器
DocumentReader接口实现了Supplier<List<Document>>函数式接口,负责从各种原始数据源中提取内容
是一个具体干活的人,例如 能读PDF 并把每一页转成一个Document对象
DocumentReader是供货商的标准合同,PagePdfDocumentReader就是其中一个签了合同的pdf搬运工
DocumentTransformer ⽂档转换器
流水线中间的加工师傅 你给它一筐处理前的文档,它给你一筐处理后的文档
文档切块 清洗:去掉HTML或者符号等多余的部分 加料:贴标签 自动提取关键词等
向量化:顺手把文档转换为向量
如: TokenTextSplitter 实现类可以根据token数量智能分割⽂本
DocumentWriter ⽂档编写器
流水线的末端 ,专门负责把处理好的文档存进最终仓库
VectorStore本身就是DocumentWrite的一个具体实现 接受文档 转成向量 存进数据库
VectorStore就是它手下最能干的员工,专门负责把文档变成向量存进AI能快速查到的知识库里
DocumentReader 文档阅读器
1JSON
JsonReader 是一个用于将JSON数据转换为Document对象的工具类
主要用于从JSON文件中提取结构化内容并生成文档对象
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import java.util.List;
@Test
void testJsonReader(@Value("classpath:/file/web.json") Resource resource) {
JsonReader jsonReader = new JsonReader(resource);
List<Document> documents = jsonReader.get();
System.out.printf("documents: %d%n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}
@Test
void testJsonArrayReader(@Value("classpath:/file/webArray.json") Resource resource) {
JsonReader jsonReader = new JsonReader(resource);
List<Document> documents = jsonReader.get();
System.out.printf("documents: %d%n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}代码解析:
参数介绍:resource指向JSON文件的SpringResource对象 jsonKeyToUse:指定提取作为文档内容的JSON键(可多个) jsonMetadataGenerator:可选 用于生成文档元数据
上面这段代码就是在测试JsonReader能不能正确的把两种JSON格式(单对象和数组)拆成标准的Document列表,方便后续扔进ETL流水线继续处理
2Text
TextReader用于将纯文本文件转换为Document对象列表(实际仅生成单个Document对象)
代码就不展示了
TextReader提供了两种构造方式:一种是通过资源URL路径初始化 一种是通过Spring的Resource对象初始化
自定义元数据:可以通过getCustomMetadata()方法,获取一个可修改的Map 添加键值对会全局注入到生成的Document中
//就是给你要存进知识库的文档,手动贴上一些额外的小标签 方便你以后快速筛选和认领
textReader.getCustomMetadata().put("author", "bit"); 例如这句代码就是给文档的档案袋用记号笔额外加了一句:这个文档的作者是bit
文档生成规则:
内容处理方式是TextReader将整个文件内容被读入单个Document的content字段
自动元数据:charset source 还有自己添加的元数据
//因为是整个文件读入内存,所以不适合非常大的文件 无法内置分块,需要配合别的分块工具
3 HTML
JsoupDocumentReader 是⼀个使⽤ JSoup 库处理 HTML ⽂档的⼯具, 能够将 HTML 内容转换为结构化的 Document 对象列表. 通过依赖引入:
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>文件读取:
java
@Test
void testJSOUPReader(@Value("classpath:/file/my-page.html") Resource resource) {
JsoupDocumentReader reader = new JsoupDocumentReader(resource);
List<Document> documents = reader.get();
System.out.printf("documents: %d%n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}代码就不一一解释了
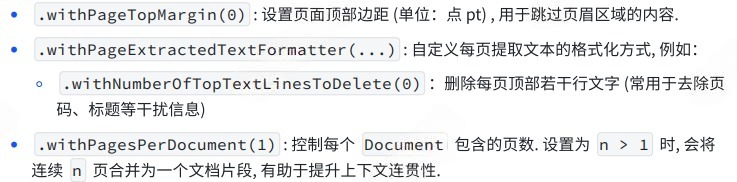
配置选项:在文件读取时,我们可以通过JsoupDocumentReaderConfig自定义JsoupDocumentReader的行为

4Markdown
MarkdownDocumentReader是一个用于处理Markdown文档并将其转化为Document对象列表工具
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>//代码就不放了 文章字数有点多了

MarkdownDocumentReader也支持配置选项,可以通过MarkdownDocumentReaderConfig自定义MarkdownDocumentReader的行为
//当你用工具读取Markdown文件时,怎么设置切莱规则
4 PDF Page
SpringAI提供了两个用于读取PDF文档的工具类,均基于ApachePDFBox库实现
能够将PDF文件解析为结构化的文本内容 适用于后续的AI处理,文本向量化 RAG检索等
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>/代码就不放了有点多
5 Tika(DOCX PPTX HTML)
tika: 可以理解为一个 文档界的万能翻译官
能从各种格式的文件中提取内容 然后统一转换成SpringAI认识的Document对象列表
对于咱们现在学的 RAG(检索增强生成)来说,Tika 帮了大忙。它能把你电脑里各种格式的文档内容提取出来,变成 ETL 流水线中标准的 Document,为后面的知识库或问答系统做准备
各种格式:包括常⻅的 Office ⽂档 (如 DOCX、XLSX、PPTX) 、PDF、HTML、⾳频、视频和图像⽂件.
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>Tika特别适合在AI应用中作为前置文档清洗模块 xxxxxxxxxx
完整的支持列表清参考官方:Apache Tika -- 支持的文档格式
6 SpringAI Alibaba读取器
除了上述讲的DocumentReader SpringAI Alibaba官方社区提供了很多DocumentReader插件扩展实现,在RAG场景中,需要集成不同来源、不同格式的私域数据时,这些插件会非常的有用,它可以帮助开发者快速读取数据,避免重复开发带来的麻烦
DocumentReader RAG 数据源集成-阿里云Spring AI Alibaba官网官网
java
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-document-reader-mysql</artifactId>
</dependency>以下面的MySQL为例,读取MySQL数据库中的内容
//代码实例不加了
7 Transformers 文档转换器
它们就像是一个智能流水线 把原始文档一步步加成适合向量化,检索和生成的高质量片段
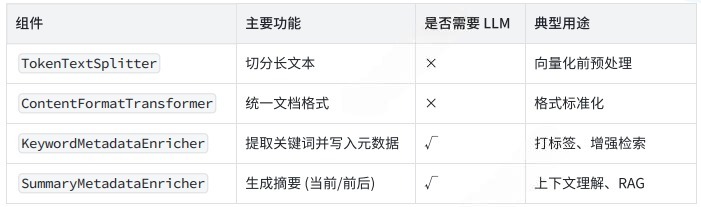
主要包含4个组件
TextSplitter(文本切分器):把长文本切分成小块
-
TextSplitter(文本切分器):将长文本切分为小块内容
-
ContentFormatTransformer(内容格式转换器):统一格式、清洗文本冗余信息
-
KeywordMetadataEnricher(关键词提取器):依托 AI 模型自动提取文档关键词,为文档打标签
-
SummaryMetadataEnricher(摘要生成器):依托 AI 模型自动生成文档内容摘要
TokenTextSplitter ⽂本切分器
这个是TextSplitter的一个实现,它基于OpenAI推荐的xxx分词编码方案,用于将长文本按照token数量切分为多个较小的Document实例
TokenTextSplitter 提供了两种构造函数选项.
-
TokenTextSplitter() : Creates a splitter with default settings.
-
TokenTextSplitter(int defaultChunkSize, int minChunkSizeChars, int
minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator) .
参数说明:
defaultChunkSize:默认值是 800 每块目标 token 数 (尽量不超过)
minChunkSizeChars:默认值是 350 每块最少字符数 (防止内容过短)
minChunkLengthToEmbed:默认值是 5 小于该长度的分块会被直接丢弃
maxNumChunks:默认值是 10000 单个文档最大分块数量 (防止分块过多)
keepSeparator:默认值是 TRUE 是否保留换行等分隔符
TokenTextSplitter 就是像⼀个"懂语法的裁缝", 它先按 AI 能理解的单位 (token) 数好⻓度, 然 后尽量在句号、问号这些⾃然停顿的地⽅下剪⼑, 剪出⼀段段既不过⻓⼜能独⽴成意的⼩段落, 最后还把边⻆料检查⼀遍, 确保没有漏掉重要内容
java
TokenTextSplitter splitter = new TokenTextSplitter(
2000, // defaultChunkSize:每块目标token数(尽量不超过)
800, // minChunkSizeChars:每块最少字符数
10, // minChunkLengthToEmbed:小于该长度的块会被丢弃
1000, // maxNumChunks:单文档最大分块数
true // keepSeparator:保留分隔符(换行符等)
);
List<Document> chunks = splitter.apply(documents);ContentFormatTransformer 内容格式转化器
是SpringAI框架中用于统一管理和调整文档内容格式的处理器
常用于处理从文件中读取的文档,确保它们以整洁、安全的方式被AI看到和使用,简单说就是让杂乱的文档变得整齐划一 该露的露,该藏的藏 常用于RAG系统中对加载文档进行标准化预处理,从而提升后续检索与生成的质量和可控性
KeywordMetadataEnricher(关键词提取器)
是一个基于大模型的元数据增强器 利用ChatModel分析文档内容 生成关键词列表,并作为字符串添加至文档元数据中
可以看作一个 自动打标签的机器人
⽐如: 你有⼀批⽂章要归档, ⼈⼯标注主题太慢了这个组件就像请了个实习⽣, 快速扫⼀眼就说:"这篇讲的是 ⼈⼯智能、机器学习、深度神经⽹络. "然后把这些词贴在⽂件夹上, ⽅便以后搜索查找.
KeywordMetadataEnricher 提供了两种构造函数选项.
- KeywordMetadataEnricher(ChatModel chatModel, int keywordCount) : 指定关
键词数量(使⽤默认提⽰词模版)
- KeywordMetadataEnricher(ChatModel chatModel, PromptTemplate
keywordsTemplate) : ⾃定义提⽰词模版
上面三个的代码实例:
java
@Test
public void testKeywordMetadataEnricher(@Value("classpath:file/会员卡办理规则.txt") Resource resource) {
// 文本读取
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
// 文件分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> apply = splitter.apply(documents);
// 关键词提取
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordCount(5)
.build();
apply = enricher.apply(apply);
apply.forEach(document -> {
System.out.println(document.getMetadata().get("excerpt_keywords"));
System.out.println(document.getText());
});
}SummaryMetadataEnricher 摘要⽣成器
它是利用ChatModel为每个文档生成摘要信息,并将其作为元数据的一部分添加到文档中
业可以根据需要 指定为当前文档或相邻文档生成摘要 添加到元数据当中
CURRENT:当前文档摘要 PREVIOUS:前一个文档摘要 NEXT:下一个文档摘要
SummaryMetadataEnricher 提供了2个构造函数
- SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType>
summaryTypes)
- SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType>
summaryTypes, String summaryTemplate, MetadataMode metadataMode)
支持自定义模板:
java
String customPrompt = "根据给定的⽂本: {context_str}, ⽣成⽂档摘要, 限制在
50字以内, 只返回摘要, 其他信息不返回";总结:
4.0 Writers
FileDocumentWriter 是⼀个实现了 DocumentWriter 接⼝的类, ⽤于将⼀组 Document 对
象的内容写⼊到指定的⽂本⽂件中. 适⽤于调试、⽇志记录或⽣成⼈类可读的⽂档输出.
java
FileDocumentWriter writer = new FileDocumentWriter("output.txt",
true, MetadataMode.ALL, false);
writer.accept(apply);提供了三个构造函数 便于灵活配置
-
FileDocumentWriter(String fileName) :写⼊指定⽂件, 不带标记、⽆元数据、覆盖写
-
⼊FileDocumentWriter(String fileName, boolean withDocumentMarkers) :指定
是否在输出中包含⽂档标记
- FileDocumentWriter(String fileName, boolean withDocumentMarkers,
MetadataMode metadataMode, boolean append) :完整配置
withDocumentMarkers : 是否写⼊⽂档分隔标记
metadataMode : 控制写⼊哪些内容 (正⽂、元数据等)
append : 是否追加到⽂件末尾 ( true ) 还是覆盖 ( false)
5.0 Redis Vector Store
我们还可以使用Redis来存储向量 Redis是一个开源内存数据结构存储
Redis Search扩展了Redis OSS的核心特性 通过加载RedisSearch 可以将Redis用作向量数据库,支持向量存储和相似性搜索
环境准备:
一个Redis实例 Redis客户端 Embedding模型接入
Embedding模型接入:需要一个实现了EmbeddingModel接口的服务来生成向量
比如:DashScopeEmbeddingModel OpenAiEmbeddingModel都可以
SpringAI为RedisVectorStore提供了SpringBoot自动配置 添加对应依赖即可
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>配置属性
要连接到Redis 并使用RedisVectorStore进行向量存储 需要提供实例的访问信息
java
spring:
ai:
vectorstore:
redis:
initialize-schema: true # 是否自动创建索引结构
index-name: spring-ai-index # 向量索引名称
prefix: "embedding:" # Redis Key 前缀
data:
redis:
url: redis://localhost:6379配置Embedding模型:
java
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
embedding:
options:
model: text-embedding-v4向量存储:
使用VectorStore进行向量操作
SpringAI抽象了通用接口VectorStore我们可以直接注入并使用
java
@Autowired
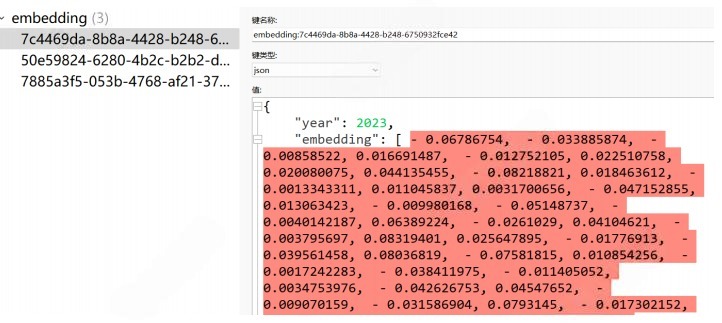
VectorStore vectorStore;观察存储内容:
观察文档在Redis中存储的内容,embedding字段为对应文档经过Embedding后的向量
相似性检索:
java
List<Document> result = vectorStore.similaritySearch(
SearchRequest.builder()
.query("机器学习")
.topK(2)
.similarityThreshold(0.5)
.build()
);
System.out.println(result);6.0 Pinecone Vector Store
Pinecone是为机器学习应用量身打造的xxxxxxxxx
适用于高维向量数据的高效存储,索引与查询 它屏蔽了基础设施管理,提供无缝扩展,试试数据写入和强大安全保障 让开发者和数据科学家能够以极低的运维成本 构建高效的相似度搜索 推荐系统和AI应用
Pinecone是一个全托管的向量数据库平台,即负责所有后端维护,扩展,更新和监控 让用户专注于应用开发 无需担心数据库管理
Pinecone:The vector database to build knowledgeable AI | Pinecone
环境准备:
首次使用无需注册新用户,选择个人免费版
The vector database to build knowledgeable AI | Pinecone
继续创建账户相关信息,或者直接跳过
注册成功会生成一个默认的API Key 注意保存好你的key 也可以创建新的key
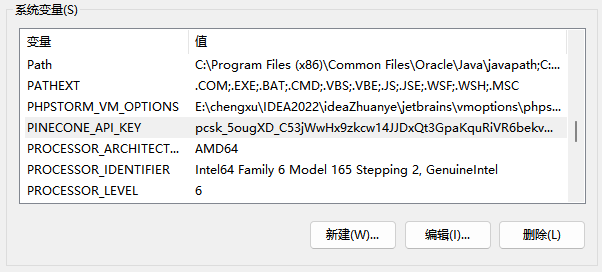
设置PINECONE_API_KEY,将Key添加进环境变量
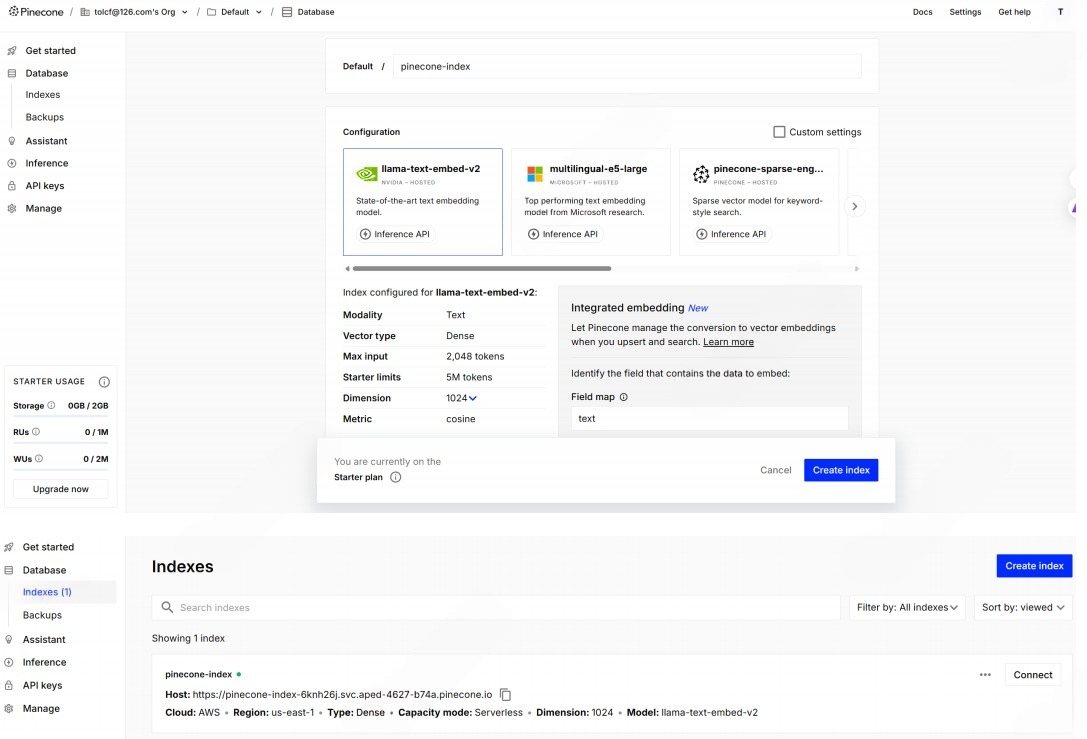
创建索引 索引名字和项目中配置保持一致
快速使用:
添加依赖:
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pinecone</artifactId>
</dependency>Spring AI 为PineconeVectorStore 提供SpringBoot自动配置 添加对应的依赖即可
配置属性:
要连接到Pinecone 需提供Pinecone的访问信息 以及Embedding模型
java
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
embedding:
options:
model: text-embedding-v4
vectorstore:
pinecone:
api-key: ${PINECONE_API_KEY}
index-name: pinecone-index # 上面创建的索引名称向量存储:
使用VectorStroe进行向量操作
SpringAI抽象了通用接口VectorStore 我们可以直接注入并使用
观察存储内容 //这里不展示了
7.0 重排序:(Re-Ranking)
(1)简介
引入:
当前xxx背景下,向量数据库已经成为连接大模型与外部知识的核心桥梁
通过将文本转化为高维向量,并基于余弦相似度等度量方式进行相似搜索,我们可以快速从海量文档中 找到看起来相关的片段。但是在实际应用中,我们发现其排序结果并不总是最优
最相似的向量 ≠ 最相关的答案
所以 重排序正在成为高质量RAG系统不可或缺的一环
真正相关的⽂档被排在后⾯, 会导致送⼊给LLM的上下⽂质量⼤打折扣, 导致检索的结果不准备.
为解决这个问题, 业界普遍采⽤重排序的模式来提升检索质量.
概念: Re-Ranking (重排序) 是指在初步检索出⼀批候选⽂档后, 使⽤⼀个更加精细、专精于相关性判断的模 型, 重新评估每个⽂档与查询之间的匹配程度, 并按新得分重新排序.
工作流程如下:
-
粗排阶段(Retrieve):使⽤向量数据库进⾏快速ANN搜索, 召回⼀批候选⽂档 (如 top-50)
-
精排阶段(Rerank):调⽤更精细的排序模型(如 Cross-Encoder 类重排序模型), 计算每个⽂档与原始查询之间的细粒度语义匹配分数;3. 根据重排序后的得分重新排列⽂档顺序, 选取 top-k ⾼质量上下⽂;
-
将优化后的上下⽂注⼊ Prompt, 交由 LLM ⽣成最终回答.
SpringAI中的实现方式:
提供了开箱即用的支持组件:RetrievalRerankAdvisor 极大简化了集成流程
java
RetrievalRerankAdvisor retrievalRerankAdvisor =
new RetrievalRerankAdvisor(vectorStore, rerankModel,
SearchRequest.builder().topK(200).build());可以通过Debug观察精排前后Document的顺序变化
//EmbeddingModel效果越差,结果越明显
(2) RAG的应用场景
RAG不是取代LLM,而是给它装上知识雷达
当答案需要基于特定文档时,RAG会让AI准确率明显提升 //下面是一些RAG的落地场景
-
智能客服:实时关联企业产品⽂档、⽤⼾⼿册、历史⼯单等, 让客服回答动态匹配最新产品信息
-
企业知识库:将公司Wiki、SOP⽂档、会议纪要等⽂档导⼊RAG知识库, 员⼯快速检索获得精准 答案
-
法律咨询服务: 构建法律条⽂+历史判例知识库, 让AI当"临时律师"
二、Agent
1.0 简介
(1)简介
Agent:智能体, 是一个能够感知环境输入,自主决策,规划行动路径,并调用工具或执行操作以目标的自主软件实体
其核心在于:由大语言模型LLM动态控制流程走向
Agents:指的是多个Agent组成的协作系统,通过分工,通信,竞争或协同完成复杂任务,也称为智能体(Multi-Agent)系统
这里的核心思想不是让一个全能AI完成所有事,而是像人类社会一样 分工合作,各司其职,有领导有执行者 可辩论 评审 优化
就像是一支足球队,这不是一个人的表演,而是一群智能体的协同作战
和工作流(workflow)区别:
从概念上讲,工作流的流程固定,步骤预设,适合明确流程的任务;智能体是由大模型LLM动态控制流程走向,灵活度高
一个是炒菜机器人 一个是米其林主厨 ,它具备主动性、适应性和学习能力
2.0 五种模式
接下来我们学习SpringAI如何通过五种基础模式实现这个概念
(1) Chain Workflow 链式工作流
链式⼯作流模式是⼀种将复杂的任务分解为多个"有序, 依赖性强"的⼦任务, 每个步骤由⼀个独⽴的处理单元 (如 LLM 调⽤) 完成, 前⼀步的输出作为下⼀步的输⼊, 最终形成⼀条"数据流动的链条".
就像工厂里面的流水线:原料 切割 打磨 喷漆 成品 每道工序只专注自己的任务 但真题协同完成最终产品
springAI中的链式实现:https://github.com/spring-projects/spring-ai-examples/tree/main/agentic-patterns
java
for (String prompt : systemPrompts) {
String input = String.format("%s\n--- 输⼊内容 ---\n%s", prompt, response);
response = chatClient.prompt(input).call().content();
}例如:代码块 经过四步链式处理
java
userInput = "The latest report shows 87% employee satisfaction, "
+ "revenue grew by 45 points, "
+ "and customer satisfaction was at 92.";
(2) Parallelization Workflow 并行化工作流
并行化工作流模式是一种通过并发执行多个独立的LLM调用,并在完成后自动聚合结果的处理模式
并行:多个LLM调用 同时进行 而不是一个接着一个地串行
每个任务输入不同,但使用相同的指令模板。 例如:分别让LLM分析市场变化对 客户 员工等的影响,这些可以同时发起请求。
java
ExecutorService executor = Executors.newFixedThreadPool(nWorkers);
List<CompletableFuture<String>> futures = inputs.stream()
.map(input -> CompletableFuture.supplyAsync(() -> {
return chatClient.prompt(prompt + "\nInput: " + input).call().content();
}, executor))
.collect(Collectors.toList());
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
futures.toArray(CompletableFuture[]::new));
allFutures.join();
return futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());技术原理:
使用多线程(Java的ExecutorService)或异步调用(CompletableFuture)等
每个任务封装为一个LLM请求(Prompt+Input)
结果统一归集后返回
总结:并行化工作流就是把一个大任务拆分成小任务,让多个LLM调用同时运行,最后由程序自动把结果合并起来,从而实现高效、智能、可扩展的批量处理机制。
(3) Routing Workflow 路由工作流
路由模式实现了智能任务分发,能够根据不同类型的输入进行专业化处理,核心思想是:
根据输入的内容的类型或特征,自动将任务"路由"到最适合处理它的子系统,模型或处理流程
可以把它想象为一个智能分诊台,就像医院的导诊护士会根据病人症状,决定去内科还是外科,路由模式会判断用户请求的类型,并将其发送给最合适的 专家模块 去处理
java
// 初始化路由表
Map<String, String> routes = new LinkedHashMap<>();
routes.put("财报分析", "[CHAIN] 请提取并整理关键财务指标");
routes.put("员工调查", "你是一位人力资源专家,请分析以下员工反馈...");
routes.put("竞品对比", "请对比以下产品的优劣势...");
// 创建整合工作流
IntegratedWorkflow workflow = new IntegratedWorkflow(chatClient, routes);
// 场景1:输入触发链式工作流
String input1 = "今年Q2客户满意度92分,收入增长45%,员工满意度87%";
String result1 = workflow.execute(input1);
// 路由 → 财报分析 (含[CHAIN]) → 自动执行 ChainWorkflow
// 场景2:并行分析多个独立问题
String input2 = "[PARALLEL] 分析新品对销量的影响 || 分析新品对客户留存的影响 || 分析新品对市场份额的影响";
String result2 = workflow.execute(input2);
// 路由 → 竞品对比(或其他) → 拆分并行 → 聚合结果适用场景:
输入任务具有明显不同的类别
不同类别的任务需要不同的处理逻辑或工具
分类过程可靠且延迟可控
这些任务差异很大,如果让同一个LLM盲目处理,容易出错,而通过路由模式,可以让每个任务由最擅长的模块来完成,提升准确性和效率
(4) Orchestrator-Worker 编排器工作者模式
是一种用于处理复杂 动态任务的AI系统架构,其核思想是:
orchestrator编排器: 负责分析任务,动态分解为多个子任务
workers工作者:并行处理各自的子任务,每个Worker专注于特定领域或视角
结果聚合:将所有Worker的整合为最终响应

//该模式适合无法预先确定子任务、需要多角度解决方案或自适应问题解决的场景
这个模式本质上就是一个最简单的Multi-Agent架构:
Orchestrator是一个Agent负责规划 每个Worker也可以看作一个小型Agent 负责执行特定任务
它们之间通过消息传递协作
它通过先规划 再分工 最后整合的方式,实现了对复杂任务的智能处理
(5) Evaluator-Optimizer 评估-优化循环
简称EO模式 是一种再大模型系统中实现 迭代式质量提升 的闭环加购设计模式
该模式通过两个组件协同⼯作
• Evaluator(评估器): 对当前输出进⾏多维度的质量评估, ⽐如是否准确, 完整, 表达清晰
• Optimizer(优化器): 根据评估结果提出改进建议, 并重新⽣成更好的内容
不同于传统的单词推理流程,EO模式引入了自我反思与迭代优化能力,形成一个:
生成 -- 评估 -- 优化 -- 再生成
的循环,像人写稿时的 初稿-检查-修改过程,比一次性生成结果更智能 更可靠
总之就是:一次生成不够好 那就边评边改
应用场景:高质量文案生成 对话系统自检 报告生成与校验
让AI从一次作答,走向精益求精,它不是一个回答者,更是一个会自我反反思的学习者和改进者。但在使用时座椅,可能会陷入 死循环 所以要设置最大迭代次数,而且多次调用LLM,成本也会较高
Evaluator-Optimizer 是⼀个典型的Multi-Agent(多智能体) 协同模式
• Generator 是⼀个 Agent
• Evaluator 是另⼀个 Agent
• 它们形成⼀个"批评-改进"循环, 共同提升结果质量
3.0 Observability 可观测性
(1) 引入
是指系统通过其外部输出,推断内部运行状态的能力,尤其适用于分布式、依赖外部服务的复杂系统 SpringAI 抽象集成 对主流大模型平台的访问能力,但这些AI服务通常是按流量计费,且调用链路涉及多个环节,所以生产环境中面临一系列挑战,需要可观测性支持。
用量统计 性能监控 优化决策
Spring AI 借助 Spring ⽣态已有的可观测性能⼒, 为 AI 相关的操作提供了指标监控. 它对核⼼组件 (如ChatClient、ChatModel、EmbeddingModel、ImageModel 和 VectorStore) 内置了指标监控 (metrics) 和链路追踪 (tracing) 功能, 帮助开发者监控性能、排查问题。
(2)Zipkin安装
为了更直观,我们选择使用Zipkin作为分布式追踪工具,与SpringAI深度集成,实现从用户请求到模型推理的全链路追踪
Zipkin是一个开源的分布式实时数据追踪系统,基于GoogleDapper的论文xxxxxxxxxxxxxx
用docker安装:
java
docker run -d --name zipkin-spring-ai -p 9411:9411 -e STORAGE_TYPE=mem
openzipkin/zipkin:latest验证安装结果:
访问Zikpin可视化界面:http://192.168.100.236:9411/zipkin/
(3) 观察监控指标
搭建项目 :创建Module spring-observability-demo
添加依赖:
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--阿里百炼-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>配置文件:
java
spring:
application:
name: spring-observability-demo
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}启动类:
测试接口:
java
@RestController
public class TestController {
public ChatClient chatClient;
@Autowired
private DashScopeEmbeddingModel embeddingModel;
public TestController(DashScopeChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@RequestMapping("/callByClient")
public String callByClient(String prompt) {
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
@RequestMapping("/embedding")
public String embedding(@RequestParam(defaultValue = "比特就业课") String text) {
float[] embedded = embeddingModel.embed(text);
return "Embedding长度为:" + embedded.length;
}
}//还有一些redis相关的知识 要在配置文件里面加的那些东西 之后学了再写吧
(4)添加指标监控
添加监控相应的依赖:
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>添加监控配置:
java
management:
tracing:
sampling:
# trace 采样信息, 记录每个请求
probability: 1.0
zipkin:
tracing:
endpoint: http://192.168.100.236:9411/api/v2/spans(5)观察指标
添加项目 访问zikpin可视化界面: http://192.168.100.236:9411/zipkin/
添加项目后,就可以观察到相应的指标了
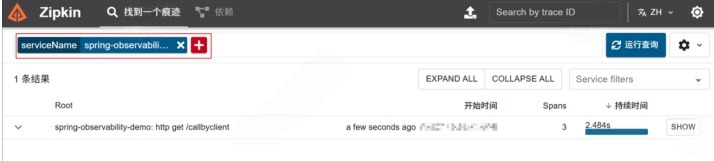
观察指标:
访问callByClient接口,观察ChatClient的监控指标
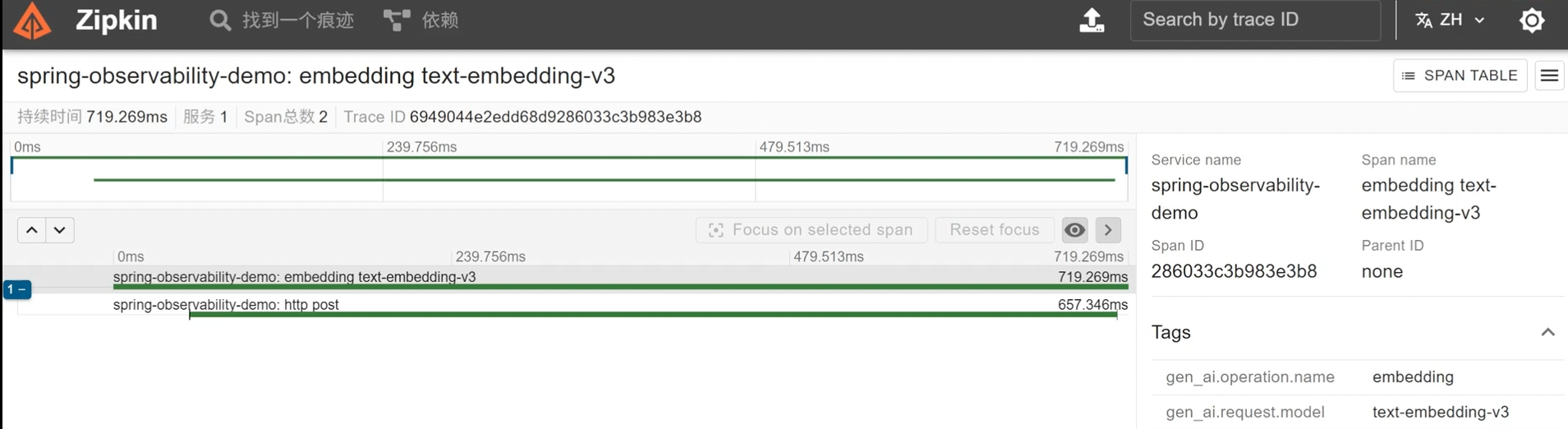
左侧会显示整个调用链路,以及每个链路的耗时,点击左侧的span,右侧会显示对应span的详情
常见的标签: