工作用途
|--------|----------------------------------|
| 验证码 | 存缓存--> 利用 Redis 自动过期特性 |
| 有顺序的数据 | 列表 List--> 有序队列、任务排队、消息通知 |
| 去重 | 集合 Set--> 数据去重、黑白名单、用户状态判断、点赞去重 |
| 排行榜 | 有序集合 ZSet--> 排行榜、优先级排序、有序数据展示 |
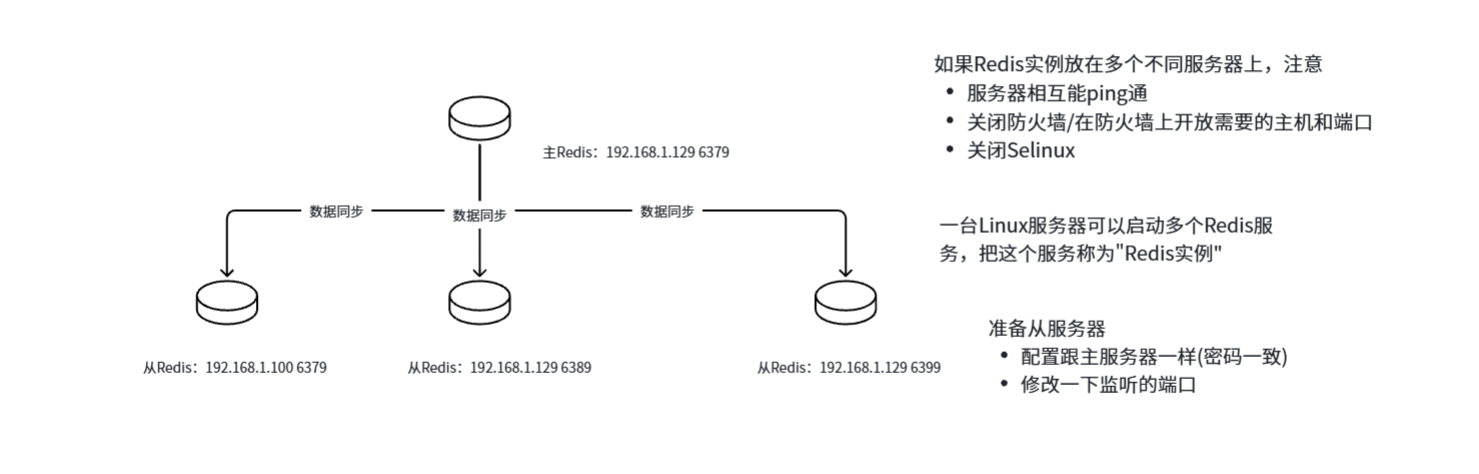
多台Redis
为什么需要多台Redis?
业务量太大=>一台服务器无法高效提供服务
单点故障=>一台服务器挂了,没有其他的备份服务
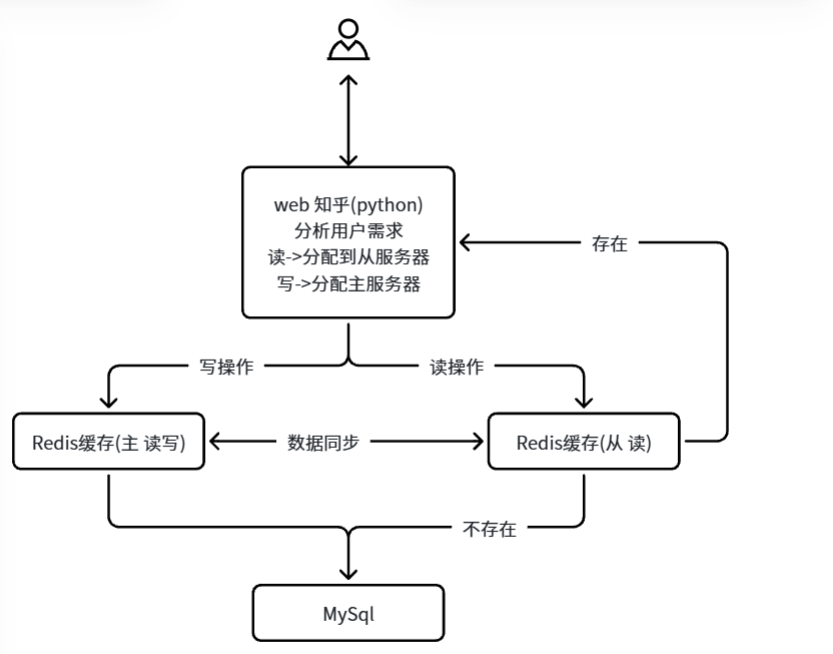
访问Redis过程:
- 获取用户的需求
- 访问Redis数据库
- 如果Redis数据库中有数据->直接返回
- 如果Redis数据库中没有数据->去MySql取数据->存到Redis中->返回
Redis主从
- 容灾恢复->一台挂了,还能使用
- 数据备份
- 水平扩容,支持高并发
- 实现读写分离
主从切换
#主从Redis配置
[root@localhost ~]# cp /etc/redis.conf /etc/redis6379.conf
[root@localhost ~]# cp /etc/redis.conf /etc/redis6389.conf
[root@localhost ~]# cp /etc/redis.conf /etc/redis6399.conf
#主配置文件
[root@localhost ~]# >/etc/redis6379.conf #清空
[root@localhost ~]# cat /etc/redis6379.conf
daemonize yes #表示一个后台程序
bind 127.0.0.1 192.168.100.172
port 6379
protected-mode no #保护模式
requirepass 12345678
dir /redisdata
dbfilename dump.rdb
appendonly no
loglevel notice #日志文件
logfile /redisdata/6379.log
pidfile /var/run/redis_6379.pid
masterauth 12345678
[root@localhost ~]# redis-server /etc/redis6379.conf
[root@localhost ~]# netstat -tulnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.1.129:6379 0.0.0.0:* LISTEN 1540/redis-server 1
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 1540/redis-server 1
#从配置文件-->改6379端口就好->6389/6399
[root@localhost ~]# cp /etc/redis6379.conf /etc/redis6389.conf
:%s/6379/6389/g vim中的查找替换
[root@localhost ~]# cp /etc/redis6379.conf /etc/redis6399.conf
:%s/6379/6399/g
只需在从配置文件中添加
replicaof 192.168.1.129 6379 #指定Redis主服务器
[root@localhost redis-8.6]# mkdir /redisdata
#启动服务
先启动主
[root@localhost ~]# redis-server /etc/redis6379.conf
再启动从
[root@localhost ~]# redis-server /etc/redis6389.conf
[root@localhost ~]# redis-server /etc/redis6399.conf
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> ping
PONG
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 6389 -a 123456
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 6399 -a 123456
#测试
主:能读能写
127.0.0.1:6379> get k1
"a100"
127.0.0.1:6379> set k1 a200
OK
从:只能读
127.0.0.1:6389> get k1
"a200"
127.0.0.1:6389> set k1 a300
(error) READONLY You can't write against a read only replica.
在主上做修改之后,查看从是否同步数据了*常见问题
- 启动报错:数据目录/redisdata6399不存在 =>需创建目录
- 启动不报错,服务没起来:
- 看日志/redisdata/6379.log
root@localhost \~# less /redisdata/6379.log
- 配置文件错误
==========================
主从复制数据同步原理
全量同步
主从复制模式第一次建立连接时,会执行全量同步(全量复制)。什么是全量同步呢?将master节点的所有数据都拷贝给slave节点,slave接收到数据文件后,存盘并加载到内存中
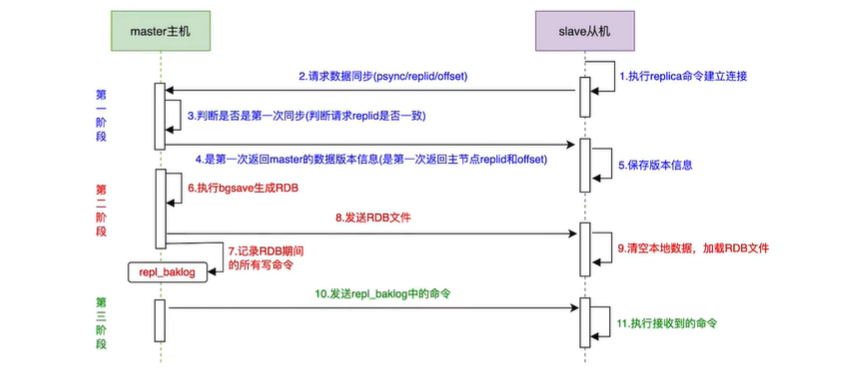
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量。随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新
∴slave做数据同步,必须向master声明自己的replid和offset,master才可以判断到底需要同步哪些数据
完整流程描述:
-
slave节点请求增量备份
-
master节点判断replid,发现不一致,拒绝增量同步
-
master将完整内存数据生成RDB,发送RDB到slave
-
slave清空本地数据,加载master的RDB
-
master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
-
slave执行接收到的命令,保持与master之间的同步
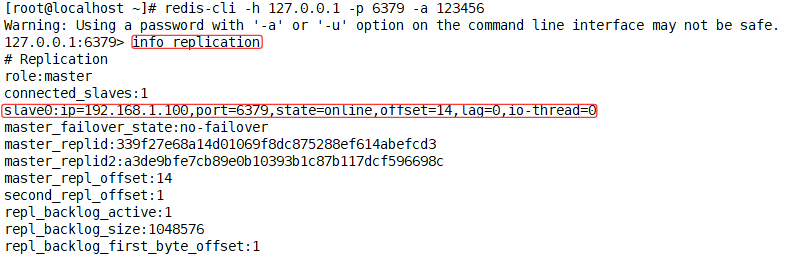
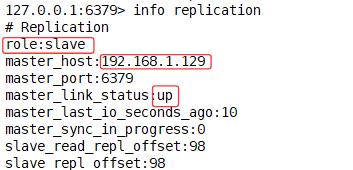
#查看主从关系
127.0.0.1:6399> info replicationReplication
role:slave #角色是从
master_host:192.168.1.129
master_port:6379
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_read_repl_offset:3596
slave_repl_offset:3596
replica_full_sync_buffer_size:0
replica_full_sync_buffer_peak:0
master_current_sync_attempts:1
master_total_sync_attempts:1
master_link_up_since_seconds:2531127.0.0.1:6379> info replication
Replication
role:master
connected_slaves:2
slave0:ip=192.168.1.129,port=6389,state=online,offset=3806,lag=0,io-thread=0
slave1:ip=192.168.1.129,port=6399,state=online,offset=3806,lag=0,io-thread=0
master_failover_state:no-failover
master_replid:732331b1e869e2d885e24e1ca863b25bb43e8109
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:3806
second_repl_offset:-1
新增一台虚拟从主机
scp = 跨服务器远程拷贝文件 / 文件夹基于 SSH 安全加密传输,相当于 Linux 之间的远程复制粘贴
[root@web-server ~]# scp root@192.168.1.129:/package/redis-8.6.zip ./
root@192.168.1.129's password:
redis-8.6.zip 100% 4952KB 44.6MB/s 00:00
[root@web-server ~]# unzip redis-8.6.zip
Archive: redis-8.6.zip
[root@web-server ~]# cd redis-8.6
[root@web-server redis-8.6]# ls
[root@web-server redis-8.6]# make && make install
[root@web-server redis-8.6]# vim /etc/redis6379.conf
[root@web-server redis-8.6]# mkdir /redisdata
[root@web-server redis-8.6]# redis-server /etc/redis6379.conf主Redis-->192.168.1.129
从Redis-->192.168.1.100
==========================
*当主机down之后,从机会不会变成主?
主:shutdown/kill
root@localhost \~# redis-cli -h 127.0.0.1 -p 6379 -a 123456 shutdown
从:观察(info replication)
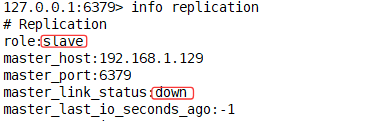
==>从机不会变成主机
*主机恢复后,主从关系是否恢复
主:
root@localhost \~# redis-server /etc/redis6379.conf
root@localhost \~# redis-cli -h 127.0.0.1 -p 6379 -a 123456
从:
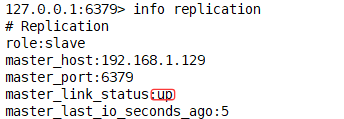
==>会恢复主从关系
*从机down之后,重新上线还会继续同步数据吗
从机down-->主机写数据-->从机启
==>会继续同步数据
==========================
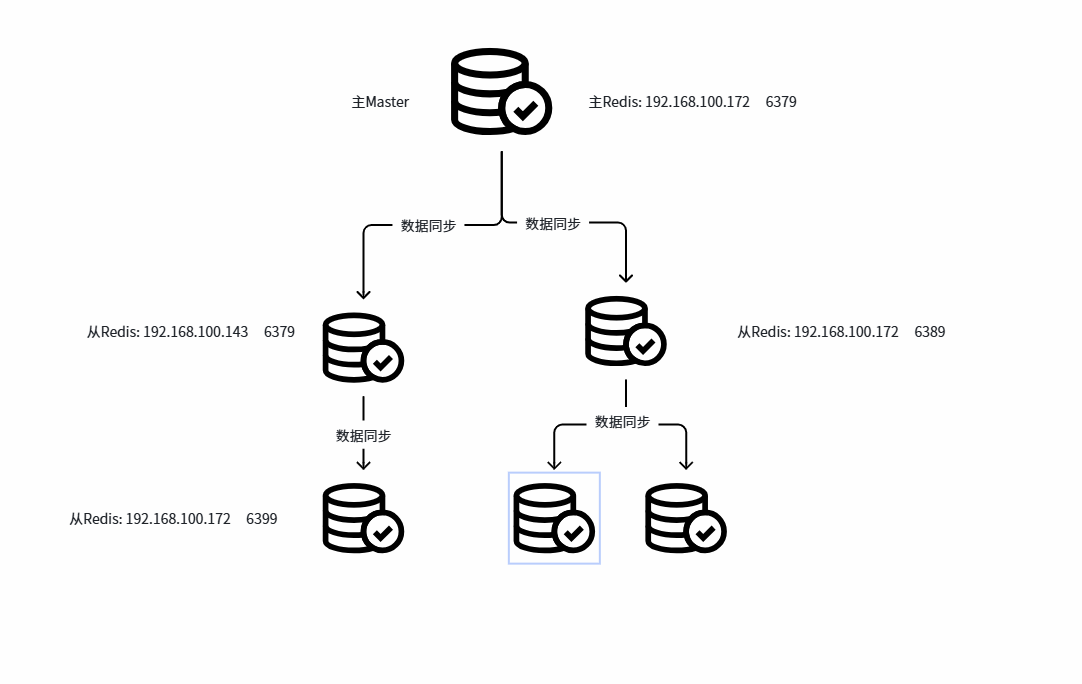
主从从模式
解决主同步压力太大了
操作方法:在二级从节点上,切换主
直接更改主
127.0.0.1:6379> slaveof 192.168.100.143 6379
127.0.0.1:6379> info replication
==========================
关闭主从
127.0.0.1:6379> slaveof no one
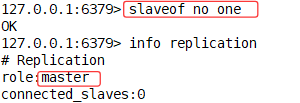
恢复--> slaveof 主IP 主端口
127.0.0.1:6379> slaveof 192.168.1.129 6379
==========================
主从复制的缺点:
1、主挂了,不会有从接盘 =>没有写功能
2、主同步压力会比较大,主从从复制有延迟
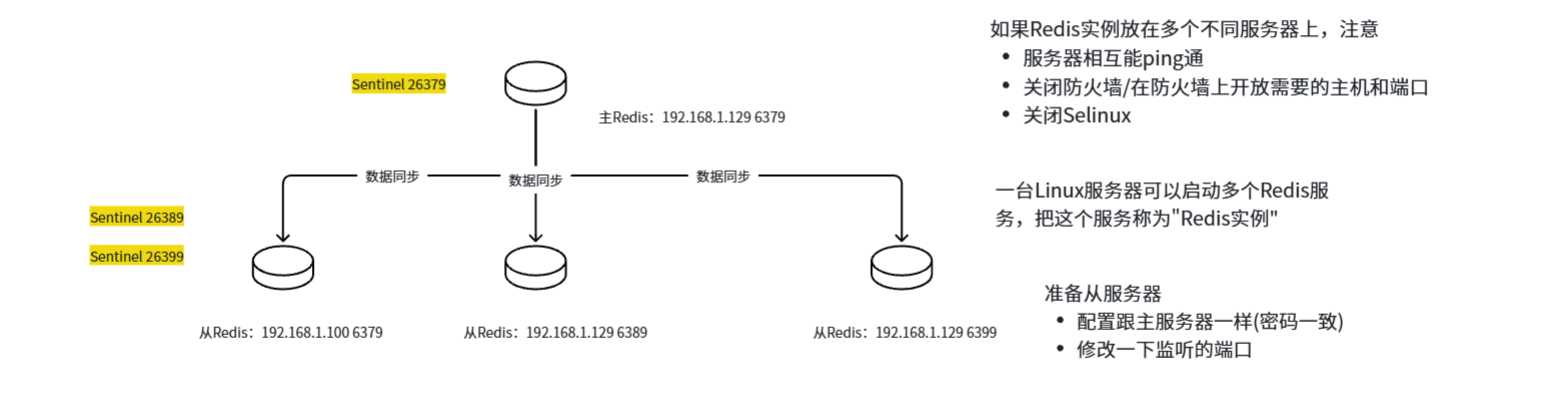
Redis哨兵
当主节点挂掉时,自动从 从节点里选出新主 ,完成故障转移
吹哨人(3个以上-奇数)=>监控主节点状态=>异常
=>发起投票(确定是否下线)
=>选举从为新主节点=>完成切换操作
实现功能:
主从监控
故障转移:主故障,将其他从切换为主
配置中心:客户端连接哨兵,获取主节点
消息通知:将故障转移结果发送给从节点
哨兵配置文件
默认:root@localhost \~# vim /package/redis-8.6/sentinel.conf
/etc/sentinel26379.conf
[root@localhost ~]# cat /etc/sentinel26379.conf
bind 0.0.0.0
port 26379
protected-mode no
daemonize yes
pidfile "/var/run/redis-sentinel26379.pid"
loglevel notice
logfile "/redisdata/sentinel26379.log"
dir "/redisdata"
sentinel monitor mymaster 192.168.1.129 6379 2
sentinel auth-pass mymaster 123456
#启动哨兵
[root@localhost ~]# redis-sentinel /etc/sentinel26379.conf
[root@localhost ~]# redis-server /etc/sentinel26389.conf --sentinel验证哨兵
将主down掉
root@localhost \~# redis-cli -h 127.0.0.1 -p 6379 -a 123456 shutdown
看进展
看配置文件
在从机,观察是否有新主Redis产生


常见问题:哨兵没法正常工作
启服务:查看服务是否正常启动(ps,netstat.lsof......)
写配置文件:配置文件是否写正确(bind,master......)
有延迟查看日志文件,看日志是否更新-->在工作
root@localhost \~# less /redisdata/sentinel26389.log
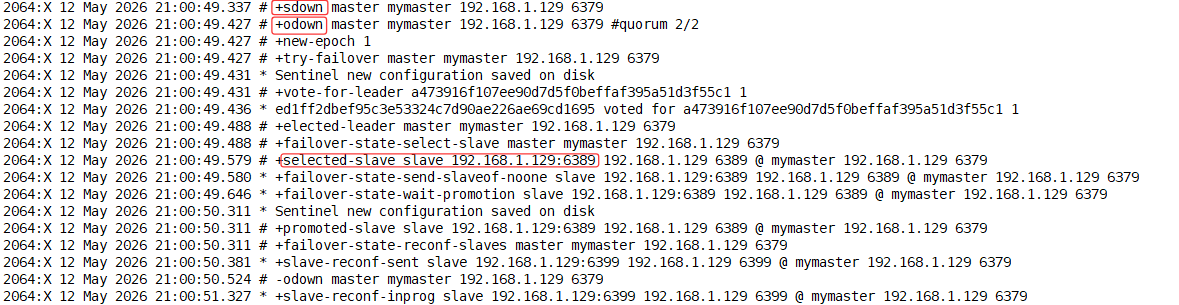
哨兵工作原理(↑上图所示)
*SDOWN:主观下线(一个哨兵自己确认Master Down)
+sdown master mymaster
*ODOWN:客观下线(多个哨兵确认Master Down)
+odown master mymaster 进行投票达到票数2
*新定哨兵王:+vote-for-leader
各个哨兵选举出一个领导者->做故障迁移(将从变成主)的工作
采用RAFT:先到先得机制
*确认新的主节点:+selected-slave
*权限->高->slave_priority:100/replica-priority 100(数字越小优先级越高)
*偏移量->offset->越大优先级越高(slave_repl_offset:133259)
*进行故障迁移
*将新Master:slaveof no one =>主
*再向从发送命令,修改配置文件
==========================
老Master上线后,会继续变成主吗?

==> 不会重新变回主
延迟比较大
哨兵主要解决的问题:主从切换,没有解决主压力大的问题
==========================
Redis集群
集群:(多台机器组合在一起提供服务),提供服务高并发
*高可用:一台down了,还有其他的主机可提供服务(服务不间断)
*分布式:服务的数据分布在多台不同的主机上(更强可扩展性)
*水平扩展:可以无限加机器扩容
*海量存储
集群实现的功能
读写分离
支持数据高可用
支持水平扩展(扩容和缩容)
集群内置了sentinel的故障转移机制,不需要单独使用哨兵功能
核心架构:数据分片和哈希槽
1、数据分片:把所有数据分成16384个哈希槽(slot),每个主节点负责一部分槽
2、哈希槽:客户端写入key-->Redis计算CRC16(key)%16384得到槽号-->根据槽号找到对应的主节点-->数据存在该节点上
节点角色和通信
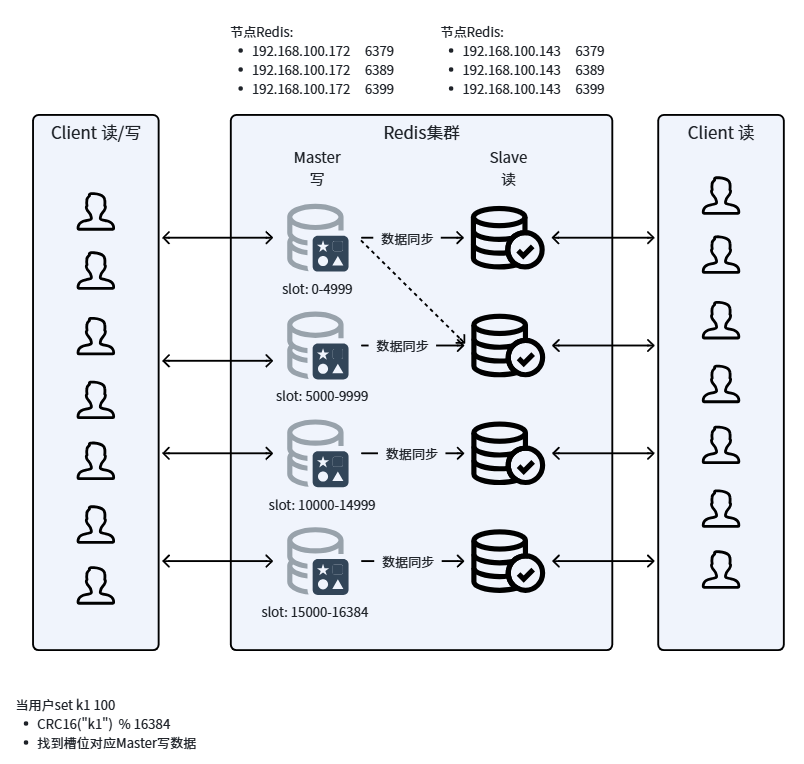
节点类型
*主节点:写->存储数据
*从节点:通过异步复制,同步主节点的数据
当主节点Down掉,升级为主节点
去中心化
*集群中没有中心管理节点,每个节点Gossip协议与其他节点进行通信
*每个节点都维护一份完整的群集元数据(节点信息,每个槽位在哪个节点......)
*节点定期通过PING/PONG消息检测节点状态
客户端请求路由
*重定向模式:
客户端随便连某一台节点->GET/SET/......->CRC16(key)%16384
如果槽位归当前节点=>直接执行命令
如果不归当前节点=>向客户端返回MOVE ->告知正确的节点->切换到正确节点
*代理模式:
客户工具在初始化从集群获取一份槽位映射表缓存到本地,当执行时,根据映射表获取正确连接节点
准备工作:6台Redis服务器=>单独主
[root@localhost redisdata]# cat /etc/redis-cluster-6379.conf
daemonize yes
bind 127.0.0.1 192.168.1.129
port 6379
protected-mode no
requirepass "123456"
dir "/redisdata/cluster6379"
dbfilename "dump.rdb"
appendonly no
loglevel notice
logfile "/redisdata/cluster6379/6379.log"
pidfile "/var/run/redis_cluster_6379.pid"
masterauth "123456"
#开启集群配置
cluster-enabled yes
#集群配置文件
cluster-config-file nodes-6379.conf
#节点超时时间
cluster-node-timeout 5000
#构建命令
[root@localhost redisdata]# redis-cli -a 123456 -p 6379 --cluster create 192.168.1.129:6349 192.168.1.129:6359 192.168.1.129:6369 192.168.1.129:6379 192.168.1.129:6389 192.168.1.129:6399 --cluster-replicas 1
如构建失败
1、kill掉当前进程
2、删除node节点配置
3、重启进程
4、构建
#连接集群
*任意选择一个节点:
[root@localhost redisdata]# redis-cli -a 123456 -p 6349 -c#查看同步情况
127.0.0.1:6349> info replication
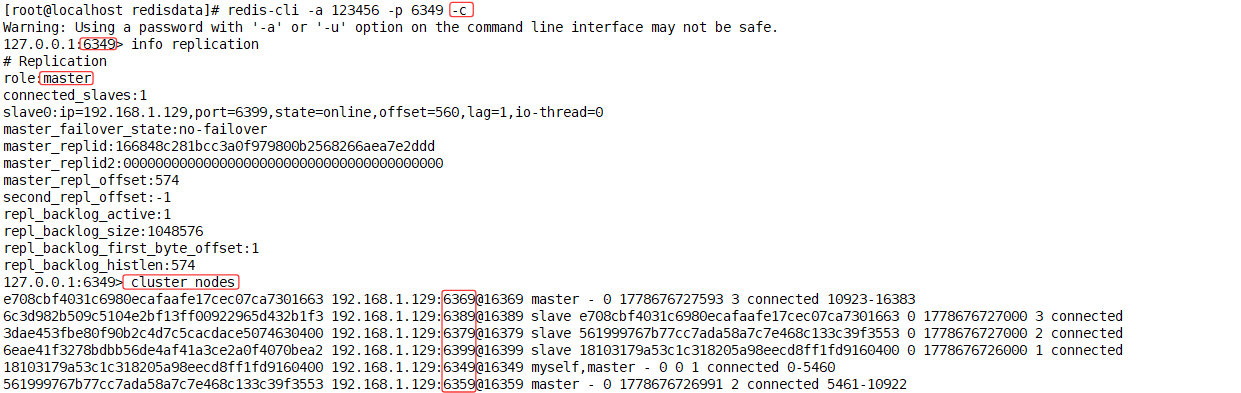
#查看集群节点
127.0.0.1:6349> cluster info
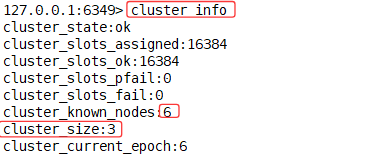
#查看不同槽位号-->对应不同节点
127.0.0.1:6349> cluster keyslot k1
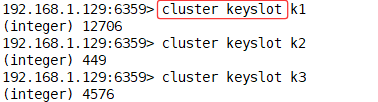
#读写操作(-c 自动路由,跳转)
root@localhost redisdata# redis-cli -a 123456 -p 6349 -c
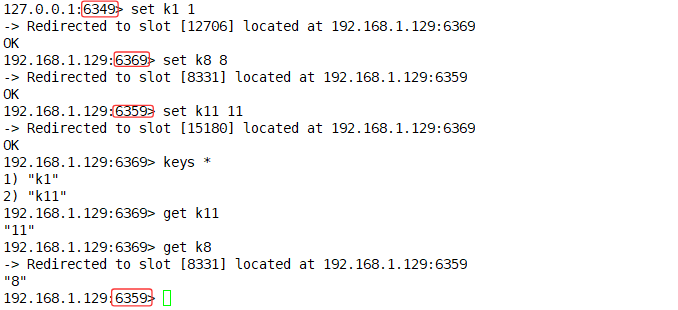
#槽位
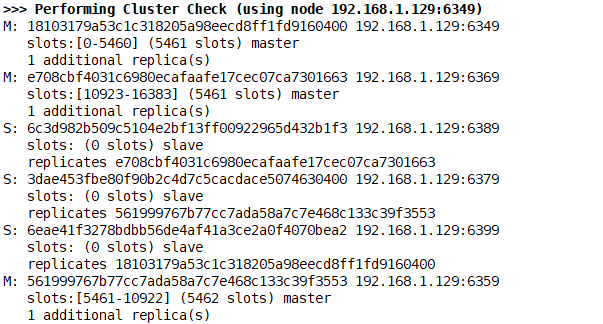
高可用与故障转移
故障迁移
M: 192.168.1.129:6349-->192.168.1.129:6399 slots:0-5460
M: 192.168.1.129:6369-->192.168.1.129:6389 slots:10923-16383
M: 192.168.1.129:6359-->192.168.1.129:6379 slots:5461-10922
主Down=>自动进行了故障迁移
192.168.1.129:6359> shutdown
not connected>
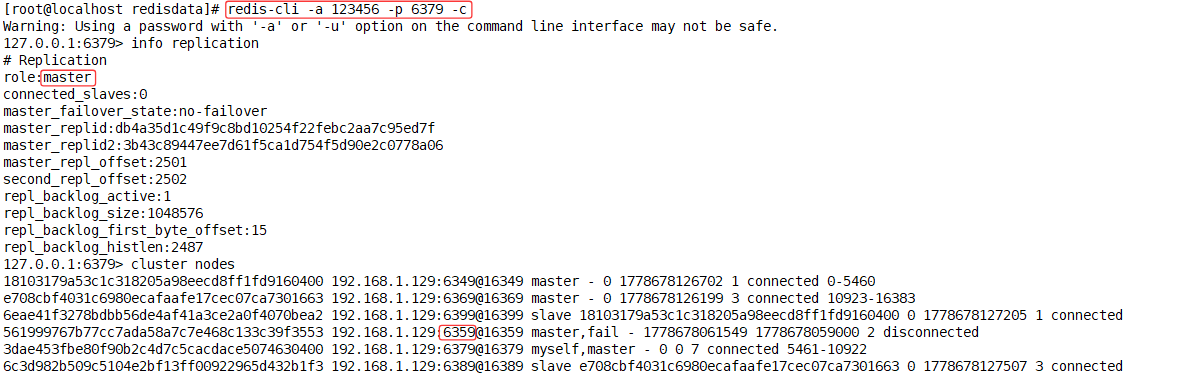
旧主UP-->变slave

集群扩容与缩容
扩容
1、写两个配置文件 :分别在两台机器上创建--> 新加 1 主 + 1 从
(从):192.168.1.129:6300.conf (主): 192.168.1.100:6300.conf
[root@localhost ~]# cp /etc/redis-cluster-6379.conf /etc/redis-cluster-6300.conf
[root@localhost ~]# sed -i 's/6379/6300/g' /etc/redis-cluster-6300.conf
[root@localhost ~]# cat /etc/redis-cluster-6300.conf
daemonize yes #后台运行 Redis 进程
bind 127.0.0.1 192.168.1.129
port 6300
protected-mode no #关闭保护模式 允许外部IP连接Redis
requirepass "123456"
dir "/redisdata/cluster6300" #指定数据目录 每个节点的数据独立存放,避免冲突
dbfilename "dump.rdb"
appendonly no
loglevel notice
logfile "/redisdata/cluster6300/6300.log"
pidfile "/var/run/redis_cluster_6300.pid"
masterauth "123456" #集群节点间认证密码 必须和requirepass一致
#开启集群配置
cluster-enabled yes
#集群配置文件
cluster-config-file nodes-6300.conf
#节点超时时间
cluster-node-timeout 5000 #超过5秒未响应,哨兵会认为节点故障
[root@localhost ~]# mkdir /redisdata/cluster63002、服务启动(此时各自都是一个独立的Master)
[root@localhost ~]# redis-server /etc/redis-cluster-6300.conf
[root@localhost ~]# ps aux|grep redis
*命令扩容-->在线完成,无需停服务
3、新Master加入集群
redis-cli -a 123456 --cluster add-node <新节点:port> <集群节点IP:port>
查看最新集群信息(新主没有slot,不能存数据)
root@localhost \~# redis-cli -a 123456 -p 6349 --cluster check 192.168.1.129:6349
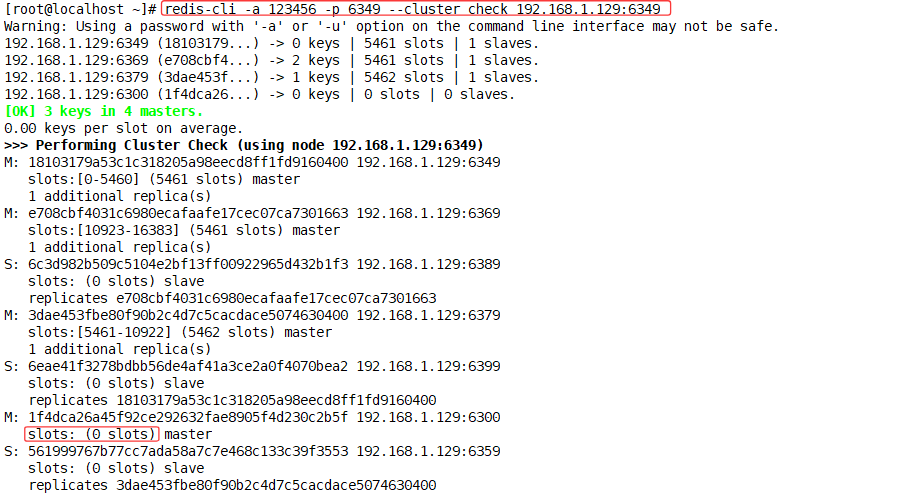
4、重新分配slots
[root@localhost ~]# redis-cli -a 123456 -p 6349 --cluster reshard 192.168.1.129:6349
M: 1f4dca26a45f92ce292632fae8905f4d230c2b5f 192.168.1.129:6300
slots: (0 slots) master
How many slots do you want to move (from 1 to 16384)? 3000 #输入需要多少个
What is the receiving node ID? 1f4dca26a45f92ce292632fae8905f4d230c2b5f #输入接收目标6300的hash串
Source node #1: all #从哪里接收slots
是否执行:yes
[root@localhost ~]# redis-cli -a 123456 -p 6349 --cluster check 192.168.1.129:6349
M: 1f4dca26a45f92ce292632fae8905f4d230c2b5f 192.168.1.129:6300
slots:[0-998],[5461-6461],[10923-11921] (2999 slots) master5、为新主6300分配新的从
redis-cli --cluster add-node <从节点:port> < 集群里任意一个已存在节点IP:port> --cluster-slave --cluster-master-id <主节点ID> -a 密码
root@localhost \~# redis-cli -a 123456 -p 6349 --cluster add-node 192.168.1.100:6300 192.168.1.129:6300 --cluster-slave --cluster-master-id 1f4dca26a45f92ce292632fae8905f4d230c2b5f
6、检查状态
redis-cli -a 123456 cluster nodes
缩容
*清除从节点:192.168.1.100:6300
获取从节点的id:6eae41f3278bdbb56de4af41a3ce2a0f4070bea2
删除
redis-cli -a 123456 --cluster del-node <集群任意节点IP:端口> <要删除的从节点ID>
root@localhost \~# redis-cli -a 123456 -p 6349 --cluster del-node 192.168.1.129:6399 6eae41f3278bdbb56de4af41a3ce2a0f4070bea2
*清除主节点:192.168.1.129:6349
清空主节点slots
redis-cli -a 123456 --cluster reshard < 集群任意节点IP:端口 >
root@localhost \~# redis-cli -a 123456 -p 6349 --cluster reshard 192.168.1.129:6349
输入需要多少个:3000
输入接收目标:hash串(不是6349的)
从哪里接收slots:6349的id
是否执行
删除
- 先删从节点 → 2. 再把主节点槽移走 → 3. 最后删主节点
redis-cli -a 123456 -p <集群任意节点> --cluster del-node <要删除的节点地址> <要删除的节点ID>
#第一步:看 6300 有多少槽
redis-cli -a 123456 -p 6349 --cluster check 192.168.1.129:6349
#第二步:开始迁移槽位
redis-cli -a 123456 -p 6349 --cluster reshard 192.168.1.129:6300
How many slots do you want to move?-->5461
What is the receiving node ID?-->8961f71370b5f6cc3313b6d8aad0fe0f2e517328
↑你要把槽移给谁?6349 的 ID
redis-cli -a 123456 -p 6300 CLUSTER NODES | grep 6349
Please enter all the source node IDs.-->3bd2a82c7636185d7a2fd85b2e15663894cf282e
↑从谁那里拿走槽?6300的ID
redis-cli -a 123456 -p 6300 CLUSTER NODES | grep 6300
done
Do you want to proceed?-->yes
#第三步:检查 6300 槽位是否变成 0
redis-cli -a 123456 -p 6349 --cluster check 192.168.1.129:6349
# 第四步:删除 6300 主节点
redis-cli -a 123456 -p 6349 --cluster del-node 192.168.1.129:6349 3bd2a82c7636185d7a2fd85b2e15663894cf282e
Redis测试与监控
业务/功能模块上线=>测试=>观察数据
项目的组成:linux系统+代码+MySql+Redis......
*测试做什么?-->功能是否正常
*压力测试:看系统在多大并发下系统会崩溃-->系统的最大并发
系统:
CPU、MEM、DISK、NET
模块Redis:
*内存使用情况:
root@localhost \~# redis-cli -a 123456 -p 6349 info memory
used_memory:2641680
*查看Redis状态
root@localhost \~# redis-cli -a 123456 -p 6349info stats
instantaneous_ops_per_sec:2-->QPS:吞吐量,每天处理请求的数量
acl_access_denied_auth:0-->认证失败次数,过高黑客攻击
- keyspace_hits /misses(命中率)
- instantaneous_ops_per_sec(QPS)
- rejected_connections(拒绝连接)
- evicted_keys(内存溢出删数据)
- expired_keys(过期 key)
- total_commands_processed(总命令)
- latest_fork_usec(持久化卡顿)--> RDB 持久化耗时,太大 (>10000) 会卡顿
- master_repl_offset(主从同步)-->判断主从同步是否正常
root@localhost \~# redis-cli -a 123456 -p 6349 --bigkeys-->可进行拆分
hotkeys热门key(短期内被非常高频率访问)-->每个分类商品有一个key-->秒杀商品-->拆分
root@localhost \~# redis-cli -a 123456 -p 6349 --hotkeys
压力测试
集群模式
root@localhost \~# redis-benchmark -a 123456**--cluster** -c 50 -n 100000 -t get
-c 客户端越多压力越大

单机模式
root@localhost \~# redis-benchmark -a 123456 -p 6349 -c 1000 -n 100000 -t get