摘要
https://arxiv.org/pdf/2511.18344v3
随着低空无人机(UAV)的普及,视觉多目标跟踪正成为一项关键的安全技术,即使在复杂环境条件下也要求具备显著的鲁棒性。然而,在具有挑战性的场景(例如低照度、杂乱背景和快速运动)中,仅使用单一视觉模态跟踪无人机往往会失败。尽管多模态多目标无人机跟踪更具韧性,但由于缺乏专用的公共数据集,有效解决方案的发展一直受到阻碍。为弥补这一空白,我们发布了MM-UAV,这是首个大规模多模态无人机跟踪基准,集成了三种关键传感模态:RGB、红外(IR)和事件信号。该数据集涵盖超过30个挑战性场景,包含1,321个同步多模态序列和超过280万标注帧。伴随数据集,我们提供了一种专为无人机跟踪应用设计的新型多模态多无人机跟踪框架,作为未来研究的基线。我们的框架包含两项关键技术创新:用于解决传感器间空间不匹配的偏移引导自适应对齐模块,以及用于平衡不同模态传递的互补信息的自适应动态融合模块。此外,为克服多目标跟踪中传统外观建模的局限性,我们引入了一种事件增强关联机制,利用事件模态的运动线索实现更可靠的身份维持。综合实验表明,所提框架始终优于最先进的方法,尤其在挑战性视觉条件下表现突出,在复杂低空环境中实现了突破性性能。为促进多模态无人机跟踪的进一步研究,数据集和源代码将公开于:https://xuefeng-zhu5.github.io/MM-UAV/。
关键词------视觉目标跟踪,多无人机跟踪,多模态跟踪数据集,RGB,IR,事件模态。
I. 引言
无人机(UAV)的快速普及已对民用物流、空中摄影、基础设施检查、应急响应和环境监测等多个领域产生重大影响。其适应性和操作效率使其在商业和工业领域不可或缺。然而,这种广泛的用途引入了严重的安全漏洞,引发了对个人隐私、公共安全和国家安全的重大担忧。因此,开发鲁棒的无人机检测和跟踪系统已成为一项迫切的技术需求1。
作为低空安全系统的基本组成部分,无人机跟踪需要越来越鲁棒的算法来应对不断演变和复杂的无人机威胁。其核心目标是在多样化和挑战性环境中实现无人机连续、实时和稳定的轨迹估计。与传统的雷达2或射频3反制措施相比,基于视觉的无人机跟踪因其显著得益于计算机视觉4,5,6和视觉跟踪算法7,8,9,10,11,12的进步而备受关注。
为解决这些挑战,越来越多的研究13--20致力于开发针对无人机应用的视觉目标跟踪方法。然而,这些努力大多仍局限于单一视觉模态和单目标跟踪(SOT)框架。尽管多无人机跟踪近期受到关注21,22,23,现有方法仍主要依赖单一类型的传感器数据。单模态跟踪固有地受到传感器特定限制的影响,在实际场景中导致显著的性能瓶颈。例如,工作在可见光谱的RGB相机在低照度条件(如夜间、浓雾或雨天)下性能极易退化,导致显著噪声和细节丢失。相反,红外(IR)传感器检测热辐射并能在黑暗中工作,但容易因鸟类或其他发热物体产生误报,且无法分辨无人机的文本或细粒度视觉特征。这些限制大幅降低了单模态跟踪器在实际反无人机行动中的操作有效性。
类似地,通常需要在第一帧手动初始化单个目标的SOT范式,虽能保持对单个对象的跟踪,但不适用于涉及可变数量无人机的场景。在真实的无人机任务中,威胁可能突然出现、消失或无先验知识地重新进入视场,使手动初始化不切实际。尽管如15等方法尝试减少对手动先验信息的依赖,但仍局限于单模态SOT跟踪,无法处理多目标场景。因此,多模态多目标跟踪(MM-MOT)通过利用互补传感器信息增强不同条件下的鲁棒性,同时支持对多个不确定无人机目标的自主检测和跟踪,呈现出广阔的应用前景。这一能力对于动态复杂环境中响应迅速且可扩展的反无人机系统至关重要。
一般而言,多目标跟踪(MOT)旨在跨视频序列检测和定位多个目标,同时随时间保持一致的身份7。与行人跟踪33,34等传统MOT任务相比,多无人机跟踪在身份保持方面面临更大挑战22,23。这些困难主要源于三个因素。首先,无人机通常表现出快速且不规则的运动模式,导致传统卡尔曼滤波35累积较大预测误差,进而引发基于IoU的关联模块中的身份不匹配。其次,与通常具有独特外观特征的行人不同,无人机通常具有高度相似或相同的外观特征,极大限制了基于外观的重识别(Re-ID)模型的判别能力。第三,无人机通常呈现为纹理细节有限的小目标,易与背景杂乱混淆,导致假阴性和假阳性升高。
由于这些挑战,主要依赖卡尔曼滤波和外观嵌入的传统MOT框架7,8,9,36,37在多无人机场景中表现出显著局限性。为此,新兴的事件模态视觉传感技术(以高时间分辨率捕获异步稀疏运动流38--41)最近在视觉跟踪中受到越来越多关注。通过直接编码随时间的光强变化,事件相机能够实现鲁棒的基于运动的推理,有助于区分无人机等快速移动的小目标。该模态提供强大的运动线索,补充传统RGB或IR传感器,从而减少由外观模糊或异常运动模式引起的身份切换。
鉴于现有无人机跟踪研究21,22,23中缺乏多模态框架,我们提出了一种专为解决无人机场景身份判别挑战而设计的新型多模态多目标跟踪方法。我们的方法称为多模态感知简单在线实时跟踪(MMA-SORT),在统一跟踪框架内有效融合RGB、IR和事件模态。除了使用卡尔曼滤波的常规运动预测和通过Re-ID特征的外观建模外,我们引入了直接从事件数据派生的额外运动嵌入。该嵌入捕获细粒度时间动态,与外观线索互补,显著增强了外观相似无人机目标的判别能力,并减少了由背景杂乱或异常运动引起的身份切换。值得注意的是,所提运动嵌入以无需训练的方式直接从原始事件流中提取,避免了深度特征提取的计算开销,从而保证高推理速度。MMA-SORT框架有效结合了三种互补传感模态的优势,在单模态或传统双模态跟踪器往往失败的挑战性条件下提供鲁棒性能。
此外,在需要高定位精度的多模态视觉任务中,模态间的时空不匹配构成关键挑战。这种不匹配源于异构传感器在成像机制、视场、数据传输延迟和分辨率上的差异42,43。虽然对较大目标通常可容忍,但即使是轻微的不匹配也会导致仅占几个像素的小无人机目标产生严重定位误差,显著削弱多模态融合的有效性。
为解决此问题,我们提出偏移引导自适应对齐模块(OGAA),在融合前执行特征级跨模态对齐。OGAA采用两种互补策略(可变形卷积44和空间变换网络45)动态调整特征图以减少空间差异。对齐后,引入轻量级自适应动态融合模块以平衡不同模态的贡献,进一步提升融合质量和鲁棒性。这些组件共同构成连贯的融合流水线,显著提升小且快速移动的无人机目标的跟踪精度。
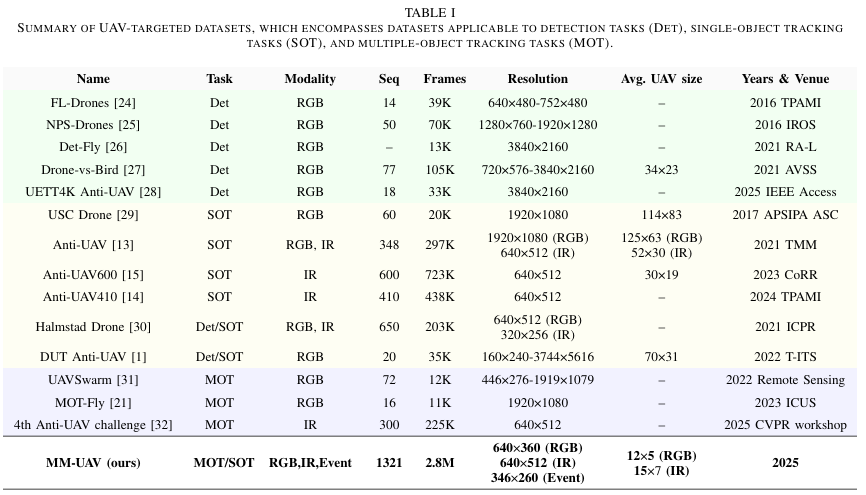
现有的视觉无人机跟踪和检测基准数据集(如表I总结)主要关注单模态检测或单目标跟踪13--15。尽管少数数据集(如AntiUAV和Halmstad Drone)包含多种模态(如RGB和红外),但仍局限于单目标跟踪场景。因此,明显缺乏支持多模态多目标无人机跟踪的大规模公开数据集,阻碍了鲁棒解决方案的开发。为弥补这一空白,我们引入MM-UAV,首个大规模多模态无人机跟踪数据集,专为三种传感模态(RGB、红外和事件数据)的多目标跟踪设计。MM-UAV包含1,321个序列(1,200个训练,121个测试),每模态约280万帧,提供前所未有的规模和多样性。值得注意的是,我们采用更严格的轨迹标注协议:离开并重新进入场景的无人机保留其原始身份,避免其他数据集中常见的身份碎片化。MM-UAV的关键特征可总结为:(1)目标尺寸更小,(2)数据规模更大,(3)模态种类更丰富,(4)身份标注更一致。据我们所知,这是迄今为止同类最大最全面的数据集。数据集的详细描述和统计分析见第III节。
本文主要贡献如下:
- 首个大规模飞行无人机多模态多目标跟踪数据集。包含三种视觉模态、1321个视频序列和每模态超过280万帧,具有更大规模、更小目标、扩展模态和更严格轨迹。
- 首个多模态多无人机跟踪框架,作为该数据集的基准基线。在网络检测端,引入偏移引导自适应对齐模块和自适应动态融合模块以实现多模态特征对齐与融合。在跟踪端,提出结合运动嵌入的新型跟踪器(MMA-SORT),有效利用运动嵌入缓解复杂背景中错误检测引起的不正确ID关联。
- 首次尝试将事件模态引入多模态多目标跟踪,利用其运动感知能力增强对尺寸极小、运动不规则目标(如无人机)的判别能力。
- 大量实验表明,所提新型多模态多目标框架优于当前单模态多目标跟踪SOTA方法,尤其在低照度条件和快速运动场景中表现突出,为未来多无人机跟踪研究提供严格基线和技术基础。
II. 相关工作
A. 针对无人机的跟踪解决方案
与无人机视角跟踪(UAV作为空中观察者进行地对空跟踪)不同,针对无人机的跟踪将无人机作为感兴趣对象,旨在复杂低空场景中实现连续稳定的轨迹跟踪。相比依赖独特外观线索和适度尺度变化的一般单目标跟踪任务,无人机目标通常较小、视觉不显著、快速移动且常被遮挡。因此,无人机场景中的单目标跟踪需在视频帧中维持初始化目标的轨迹,同时克服外观判别力弱、频繁消失和间歇性重新出现等额外挑战。现有解决方案多基于Siamese网络架构,通过跨帧模板特征匹配实现目标定位11。代表作品包括早期CNN-based的SiamFC47、SiamRPN48、SiamRPN++49,以及基于Transformer的Stark50、OSTrack51、MixFormer52。然而,这些跟踪器主要在GOT-10k53、TrackingNet54和LaSOT55等大规模通用跟踪数据集上优化,缺乏对无人机的特定描述。
鉴于无人机外观的特异性和跟踪任务的长期性,许多反无人机SOT解决方案采用"局部跟踪+全局重检测"框架。例如,SiamSTA18利用时空注意力和三阶段全局重检测策略跟踪快速移动无人机。UTTracker20结合时间线索进行多区域局部跟踪,并结合全局检测和背景校正模块处理剧烈尺度变化、频繁消失和相机运动。尽管取得成就,这些方案仍局限于单目标跟踪,无法处理未知数量无人机协同入侵的复杂场景。因此,多无人机跟踪已成为满足实际需求的焦点。
一般而言,多目标跟踪聚焦于跨帧检测和跟踪多个目标。在此基础上,多无人机跟踪旨在无先验目标初始化情况下关联多个无人机的轨迹,代表迈向实用反无人机技术的关键一步。当前主流MOT框架分为两类范式:基于检测的跟踪(如DeepSORT7、ByteTrack8、BoTSORT9、BoostTrack36)和基于查询的跟踪(如TransTrack56、Trackformer10、MOTR57、MeMOTR58)。然而,无人机特定挑战显著降低其性能。首先,高外观相似性降低传统ReID嵌入的有效性。其次,快速不规则运动违反卡尔曼滤波的线性运动假设,导致预测误差和ID切换。第三,小无人机目标尺寸增加检测失败率,进一步复杂化数据关联。
这些局限凸显了多目标跟踪范式中对无人机导向解决方案的需求。基于此,近期研究探索将通用MOT流水线适配于小目标,特别是在热红外视频中。DistTracker22结合基于YOLOv1259的尺度-形状-质量检测器与L2-IoU跟踪器融合,处理低对比度、尺度变化和运动不稳定性。Strong Baseline23使用YOLOv12和BoT-SORT框架及定制训练/推理策略取得竞争性结果。然而,多无人机跟踪进展有限,多数方法局限于单模态输入,导致复杂条件下鲁棒性不足。
B. 针对无人机的跟踪基准
尽管SOT和MOT范式取得显著进展,其发展仍受限于合适数据集的可用性,促使设计无人机专用基准。
对于单目标跟踪,Chen等29引入USC Drone数据集(60序列,20K帧),配合Fast-RCNN+MDNet系统,残差图像输入提升对快速无人机运动的适应性。Huang等14构建Anti-UAV410大规模热红外基准(410序列,438K帧),提出SiamDT双语义特征处理微小目标。Zhu等15发布Anti-UAV600(600热红外序列,723K帧),无先验边界框初始化,设计"全局检测+局部跟踪"框架,通过证据协作避免依赖首帧信息。尽管取得进展,这些基准仍局限于SOT,无法描绘涉及多无人机的场景。
对于多无人机跟踪,UAVSwarm31构建可见光数据集(72序列,12K帧),验证Faster-RCNN/YOLOX+ByteTrack基线。MOT-FLY21提供空对空高分辨率数据集(1920×10801920\times10801920×1080,16序列,11K帧),基准化先进MOT框架。近期,第4届Anti-UAV挑战32发布首个大规模红外多无人机基准(300序列,225K帧)。
值得注意的是,现有研究仍有限:数据集规模小且仅提供单一模态(RGB或IR)。通常,单模态传感器在复杂场景中固有挣扎:可见光在低光或恶劣天气下性能退化,而红外虽全天候但目标-背景对比度低且缺失细节。这些限制严重限制复杂低空环境中多无人机跟踪系统的鲁棒性,促使多模态融合成为关键使能解决方案。
C. 多模态跟踪潜力
单一视觉模态在复杂场景中表现出的性能瓶颈推动了多模态融合技术6的发展,如RGB-T(RGB+热红外)、RGB-D(RGB+深度)和RGB-E(RGB+事件)。整合不同模态传递的互补信息显著提升跟踪鲁棒性。
然而,反无人机任务中的多模态研究仍稀缺。例外包括Anti-UAV数据集13,首个引入RGB-T数据集(348序列,297K帧)。作为基线,13提出双流特征语义一致性训练策略。但由于模态未对齐,无法真正利用跨模态互补潜力,仅独立使用。类似地,Halmstad Drone数据集30包含650段视频(365段IR,285段RGB)及90段音频,但侧重构建自动化多传感器系统而非研究基于深度学习的融合。其IR与可见光数据的不完全对应也限制了多模态反无人机研究的实用性。此外,这些数据集主要面向检测或SOT,留下多模态多无人机跟踪基准和方法的空白。
多模态跟踪的根本挑战在于模态不匹配。虽然多数研究假设数据时空对齐,真实数据常因成像原理、视场、分辨率和传输延迟差异而失配。此问题对无人机跟踪尤为关键,目标小且快速移动,轻微偏移即破坏有效融合。传统像素级方案依赖特征点匹配和仿射/透视变换实现对齐,但引入显著预处理延迟,不适用于实时多无人机跟踪。因此,近期研究强调可学习特征对齐。60提出对齐区域CNN,使用RoI抖动对齐RGB和热区域。42提出跨模态空间偏移建模,结合偏移引导可变形对齐与融合,实现无需严格预对齐的鲁棒无人机RGB-IR检测。受此启发,我们采用两种特征级对齐策略用于无人机跟踪:(1)通过可变形卷积44学习采样偏移;(2)通过空间变换网络45预测仿射变换矩阵。两种策略均可端到端训练且无需额外损失,高效缓解多模态融合中的不匹配。
此外,鉴于无人机尺寸小、运动不规则,且传统RGB或IR模态在相似外观或温度下无法区分目标与背景,本研究进一步引入事件模态。作为前沿视觉传感器,事件相机通过记录光强变化捕获异步事件流。具备高动态范围和微秒级时间分辨率等独特优势,特别适合极端场景。现有基于事件的跟踪研究产生VisEvent61、FE10839、EventVOT40和COESOT38等数据集,以及CEUTrack38、TENet41、ViPT62和AFNet63等方法,但均局限于单目标跟踪任务,留下基于事件的多无人机跟踪关键空白。
III. MM-UAV 基准
A. 数据采集
在MM-UAV数据集中,无人机目标通过红外相机(infiRay LG6122)、RGB相机(Stereolabs ZED)和事件相机(DAVIS 346)同步捕获,所有模态同步生成30 FPS视频序列。具体而言,RGB、IR和事件模态的分辨率分别为640×360640\times360640×360、640×512640\times512640×512和346×260346\times260346×260像素。整个数据集涵盖30多个场景的1321个序列,1200个分配给训练集,121个给测试集。图1提供直观数据感受。

B. 数据标注
由于传感器类型在成像原理、视场和分辨率上存在差异,存在两个关键挑战:同一目标的尺寸和可见性在不同模态间变化。特别是对于小无人机,这种差异被放大,使得跨模态共享边界框标注极为困难。因此,本数据集中RGB和IR模态的标注是独立提供的。
注意,事件模态设计用于捕获光强变化,表现出信息不稳定、高噪声和稀疏性。这些特性使得仅靠事件模态直接定位具有精确尺寸和位置的目标不切实际。因此,事件模态不提供标注,仅作为辅助输入。
为便于高效边界框标注同时保持外观多样性,采用稀疏标注策略。每个训练序列每100帧标注一次,121个测试集的序列每20帧标注一次。具体而言,每个标注包含唯一ID和目标的精确空间坐标。重要的是,在我们的标注设置中,严格执行ID持久性规则。在序列内,无论无人机离开并重新进入视场多少次,均保留其唯一ID。
C. 统计信息
本节详细阐述数据集的各种统计特征,以深入理解其属性。
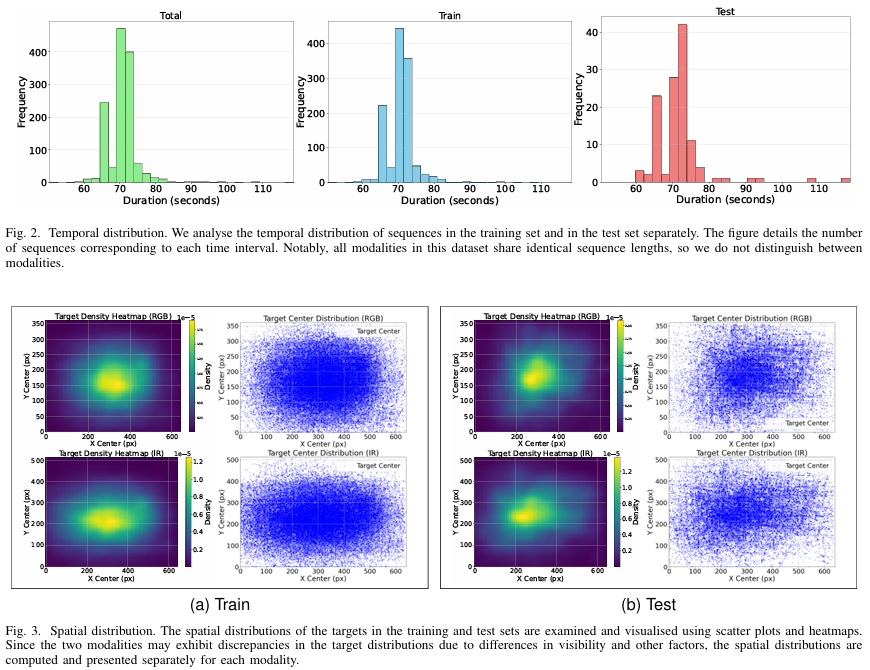
时间分布 :如图2所示,1321个序列总时长26小时,训练集占23.6小时,测试集占2.4小时。单个序列时长范围50至118秒,平均70.96秒。
空间分布 :训练集和测试集中目标的空间分布如图3可视化。无人机目标广泛分布在整个视场,中心区域密度增加。
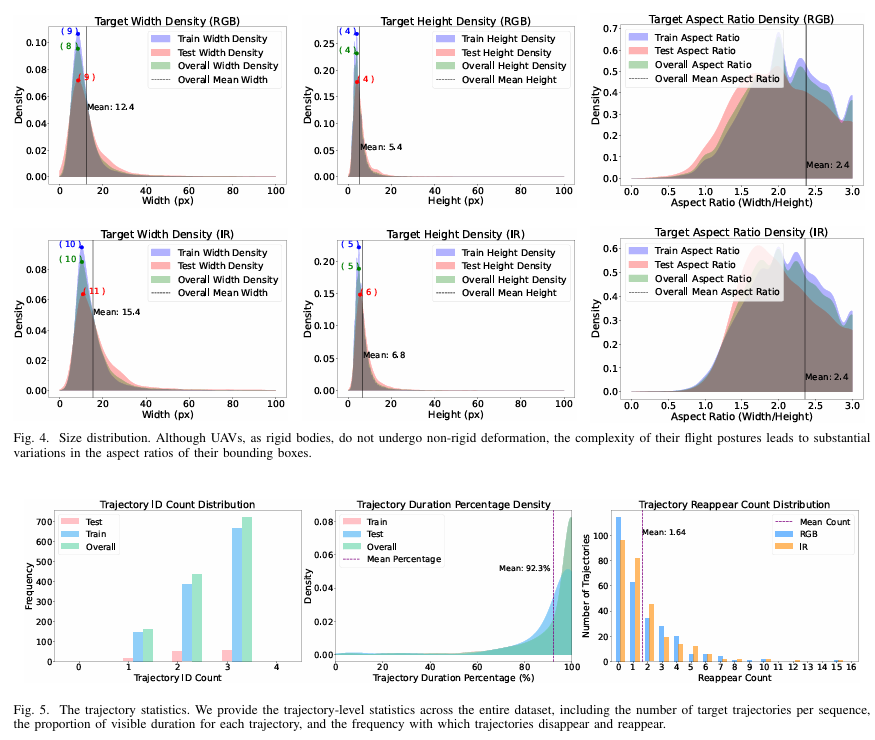
尺寸分布 :原则上,无人机目标特征为尺寸小且易被遮挡。在MM-UAV中,如图4所示,RGB模态中无人机平均尺寸为12.4×5.412.4\times5.412.4×5.4像素,IR模态为15.4×6.815.4\times6.815.4×6.8像素,两种模态平均长宽比均为2.4。跨模态长宽比分布表明,由于快速且不规则运动,无人机经历频繁且剧烈的姿态变化。
轨迹分布 :与主要关注高密度无人机集群的现有数据集不同,本数据集强调无人机的隐身特性,旨在支持稀疏分布和未知数量下的鲁棒多目标跟踪。具体而言,每个序列包含1至4个无人机目标,平均每个序列2.42条轨迹,如图5报告。整个轨迹平均可见持续时间为92.32%,最低2.78%,最高100%。平均每条轨迹经历1.55次进出事件,极端情况下最多15次目标进出。这些特征凸显跟踪算法必须具备处理频繁遮挡和重新出现场景的能力。
D. 挑战性属性
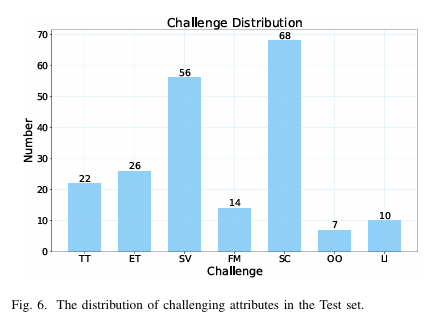
为全面评估和分析各场景跟踪性能,收集序列标注了七种挑战性属性:
微小目标(TT) :为评估区分微小目标的能力,定义"微小目标"属性用于尺寸在8×88\times88×8至16×1616\times1616×16像素间的无人机。具体而言,若此类目标在超过50%的整序列帧中出现,则序列标注此属性。鉴于RGB和IR独立标注,仅当两种模态均达此标准时才分配"微小目标"属性。
极微小目标(ET) :在"微小目标"定义基础上,"极微小目标"指小于8×88\times88×8像素的无人机。这些目标通常仅占图像面积的0.01%--0.02%,几乎完全丢失纹理和轮廓特征,极易与背景噪声或小干扰物(如鸟类碎片、光斑)混淆。为此,需要鲁棒的判别特征提取能力和对背景杂乱的强恢复力以保持轨迹连续性和准确性。与微小目标标准一致,仅当RGB和IR模态在超过50%帧中包含极微小目标时,序列才分配此属性。
尺度变化(SV) :若对于任何轨迹,同一目标在200帧窗口内最大与最小尺度比超过4:1,则分配此属性。此类场景源于无人机-传感器距离的突变(如突然从近距离离开或快速远距离接近),视觉上导致目标在短时间内从微小变为中等尺寸,反之亦然。此属性要求反无人机设计具备强尺度适应性,包括提取时使用多尺度判别特征,以及在运动预测模块中有效建模非线性尺度变化,避免轨迹断裂或ID混淆。
快速运动(FM) :若两个连续边界框间目标质心距离超过60像素,且此类帧占整序列30%以上,则适用此属性。高无人机机动性(如俯冲、急转弯)常导致帧间运动模糊和轮廓畸变,使基于平滑运动假设的传统关联策略(如IoU匹配)失效。
低照度(LI) :若序列中RGB图像平均亮度≤50\le 50≤50(像素强度),则分配此属性。低照度通常在RGB帧中引入噪声增加、对比度降低和纹理细节丢失,导致依赖颜色或纹理特征的系统检测失败风险高。此类场景凸显单独使用RGB模态的局限性,并作为有效多模态融合的关键测试平台。
相似杂乱(SC) :若序列超过50%的帧包含多个尺度相似的目标(目标间边界框尺度比不超过2:1),则获此属性。无人机群通常共享相似外观(如均匀旋翼结构、可比飞行姿态),结合几乎相同的尺度,降低ReID提取外观嵌入的判别力,增加目标误识别风险。
目标重叠(OO) :若两条轨迹间存在超过一次边界框重叠实例,则标注此属性。重叠导致相互特征遮挡和局部信息丢失,可能引发ID关联错误,尤其对外观相似的无人机。
这些挑战性属性的分布和示例分别见图6和图7。

IV. 方法
A. 概述
鉴于反无人机跟踪系统对实时响应的要求,我们采用主流"基于检测的跟踪"范式。一般而言,关于模态融合策略,我们选择在检测阶段对高度互补的RGB和IR模态进行特征级融合,而在跟踪阶段将事件模态纳入决策级融合。此战略选择源于各模态的独特属性:RGB和IR模态均可提供相对可靠稳定的全场景表示。相反,事件模态通过捕获像素级光强变化来精确表征目标的快速运动轨迹和瞬时姿态变化,固有地提供比RGB或IR更稀疏和不稳定的信息。因此,最好在跟踪阶段利用其在运动状态建模中的优势,从而补充源自RGB和IR的传统外观特征。
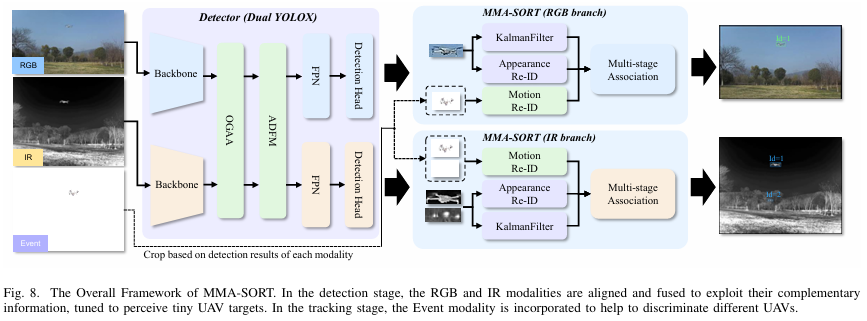
整体框架如图8所示。具体而言,我们在检测阶段采用双流YOLOX架构,接收来自RGB模态和IR模态的帧。由各自独立骨干网络XrgbX_{rgb}Xrgb和XirX_{ir}Xir产生的特征首先通过偏移引导自适应对齐模块(OGAA)对齐,生成Xrgb′X'{rgb}Xrgb′和Xir′X'{ir}Xir′。这些对齐特征随后通过自适应动态融合模块(ADFM)融合,该模块自适应组合每个对齐特征Xrgb′/Xir′X'{rgb}/X'{ir}Xrgb′/Xir′与其对应的原始特征Xrgb/XirX_{rgb}/X_{ir}Xrgb/Xir,生成融合特征Xrgb−fusedX_{rgb-fused}Xrgb−fused和Xir−fusedX_{ir-fused}Xir−fused。
融合特征Xrgb−fusedX_{rgb-fused}Xrgb−fused和Xir−fusedX_{ir-fused}Xir−fused随后输入检测头以感知潜在无人机。检测结果传输至跟踪阶段的MMA-SORT以实现多目标跟踪。值得注意的是,由于两种模态均提供标注数据,我们的双流框架同时输出两种模态各自坐标系下的检测结果,为未对齐多传感器相机应用提供全面参考。对齐模块、融合机制和MMA-SORT的细节将在后续章节介绍。

B. 偏移引导自适应对齐
该模块旨在将一种模态的特征对齐到另一种的坐标系,例如将XrgbX_{rgb}Xrgb对齐到XirX_{ir}Xir(或反之)。我们提出两种对齐策略:一种通过可变形卷积隐式学习相对于原始采样点的偏移,另一种通过基于仿射变换的空间变换网络(STN)显式变换特征坐标。
基于可变形卷积的对齐方案如图9(a)所示,采用双分支架构实现模态间相互对齐。对于骨干网络提取的XrgbX_{rgb}Xrgb和XirX_{ir}Xir,我们首先应用共享的3×33\times33×3卷积层降低通道维度并捕获共同特征表示。处理后的特征拼接后输入两个独立分支。每个分支包含多尺度空洞卷积模块(空洞率3、6、9)以聚合不同感受野的上下文信息,为偏移预测提供空间线索。经1×11\times11×1卷积降维和3×33\times33×3卷积局部聚合后,网络输出可变形卷积的偏移Δp\Delta pΔp。最后,XrgbX_{rgb}Xrgb使用IR分支生成的偏移Δpir\Delta p_{ir}Δpir对齐到XirX_{ir}Xir的坐标系,生成对齐特征Xrgb′X'{rgb}Xrgb′。同时,XirX{ir}Xir使用Δprgb\Delta p_{rgb}Δprgb适配到RGB坐标系,生成Xir′X'{ir}Xir′。输出可公式化为:
{Xrgb′=DefConvrgb(Xrgb,Δpir)Xir′=DefConvir(Xir,Δprgb)(1) \begin{cases} X'{rgb} = \text{DefConv}{rgb}(X{rgb}, \Delta p_{ir}) \\ X'{ir} = \text{DefConv}{ir}(X_{ir}, \Delta p_{rgb}) \end{cases} \tag{1} {Xrgb′=DefConvrgb(Xrgb,Δpir)Xir′=DefConvir(Xir,Δprgb)(1)
此隐式对齐机制无需显式计算变换矩阵即可学习最优采样策略。
基于STN的对齐方案如图9(b)所示,利用数据集先验知识简化学习过程。考虑到直接学习完整仿射变换的难度,我们预计算初始仿射矩阵M0M_0M0,并训练网络预测相对于该矩阵的偏移ΔM\Delta MΔM。具体而言,XrgbX_{rgb}Xrgb和XirX_{ir}Xir进行共享3×33\times33×3卷积特征提取和降维,拼接后输入双分支。此过程与可变形卷积对齐方案相同。每个分支采用多层卷积和下采样操作细化空间变换特征,最终通过Tanh激活函数预测六个偏移参数Δα,Δβ,Δγ,Δδ,Δϵ,Δζ\\Delta\\alpha, \\Delta\\beta, \\Delta\\gamma, \\Delta\\delta, \\Delta\\epsilon, \\Delta\\zetaΔα,Δβ,Δγ,Δδ,Δϵ,Δζ。最终仿射变换矩阵计算为:
{Mrgb=argb brgb crgb drgb ergb frgb⏟M0,rgb+Δαrgb Δβrgb Δγrgb Δδrgb Δϵrgb Δζrgb⏟ΔMrgbMir=air bir cir dir eir fir⏟M0,ir+Δαir Δβir Δγir Δδir Δϵir Δζir⏟ΔMir(2) \begin{cases} M_{rgb} = \underbrace{a_{rgb}\\ b_{rgb}\\ c_{rgb}\\ d_{rgb}\\ e_{rgb}\\ f_{rgb}}{M{0,rgb}} + \underbrace{\\Delta\\alpha_{rgb}\\ \\Delta\\beta_{rgb}\\ \\Delta\\gamma_{rgb}\\ \\Delta\\delta_{rgb}\\ \\Delta\\epsilon_{rgb}\\ \\Delta\\zeta_{rgb}}{\Delta M{rgb}} \\ M_{ir} = \underbrace{a_{ir}\\ b_{ir}\\ c_{ir}\\ d_{ir}\\ e_{ir}\\ f_{ir}}{M{0,ir}} + \underbrace{\\Delta\\alpha_{ir}\\ \\Delta\\beta_{ir}\\ \\Delta\\gamma_{ir}\\ \\Delta\\delta_{ir}\\ \\Delta\\epsilon_{ir}\\ \\Delta\\zeta_{ir}}{\Delta M{ir}} \end{cases} \tag{2} ⎩ ⎨ ⎧Mrgb=M0,rgb argb brgb crgb drgb ergb frgb+ΔMrgb Δαrgb Δβrgb Δγrgb Δδrgb Δϵrgb ΔζrgbMir=M0,ir air bir cir dir eir fir+ΔMir Δαir Δβir Δγir Δδir Δϵir Δζir(2)
这些矩阵驱动STN模块变换XrgbX_{rgb}Xrgb和XirX_{ir}Xir,生成对齐特征Xrgb′X'{rgb}Xrgb′和Xir′X'{ir}Xir′:
{Xrgb′=STN(Xrgb,Mrgb)Xir′=STN(Xir,Mir)(3) \begin{cases} X'{rgb} = \text{STN}(X{rgb}, M_{rgb}) \\ X'{ir} = \text{STN}(X{ir}, M_{ir}) \end{cases} \tag{3} {Xrgb′=STN(Xrgb,Mrgb)Xir′=STN(Xir,Mir)(3)
需注意,此显式对齐机制通过建模全局坐标变换有效补偿空间不匹配。
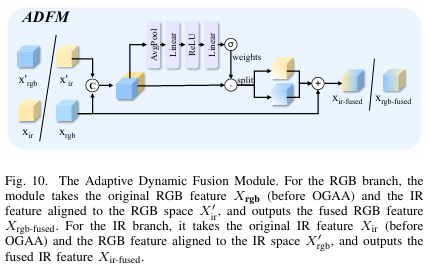
C. 自适应动态融合模块
为动态平衡两种模态的贡献,我们采用简单的注意力加权通道融合机制。对于双流模态的每个分支,模块接收两个输入:一是当前模态的原始输入特征,二是对齐到当前模态的另一模态特征。
以RGB分支为例,ADFM接收原始特征XrgbX_{rgb}Xrgb和对齐到RGB空间的特征Xir′X'{ir}Xir′。这两个特征首先沿通道维度拼接:
Fconcat,rgb=Concat(Xrgb,Xir′)(4)F{concat,rgb} = \text{Concat}(X_{rgb}, X'_{ir}) \tag{4}Fconcat,rgb=Concat(Xrgb,Xir′)(4)
然后输入额外的通道注意力分支,通过下式获取通道权重WrgbrgbW^{rgb}{rgb}Wrgbrgb和WirrgbW^{rgb}{ir}Wirrgb:
{Fgap,rgb=ReLU(Linear(AvgPool(Fconcat,rgb)))Wrgbrgb=Sigmoid(Linear(Fgap,rgb))Wirrgb=Sigmoid(Linear(Fgap,rgb))(5) \begin{cases} F_{gap,rgb} = \text{ReLU}(\text{Linear}(\text{AvgPool}(F_{concat,rgb}))) \\ W^{rgb}{rgb} = \text{Sigmoid}(\text{Linear}(F{gap,rgb})) \\ W^{rgb}{ir} = \text{Sigmoid}(\text{Linear}(F{gap,rgb})) \end{cases} \tag{5} ⎩ ⎨ ⎧Fgap,rgb=ReLU(Linear(AvgPool(Fconcat,rgb)))Wrgbrgb=Sigmoid(Linear(Fgap,rgb))Wirrgb=Sigmoid(Linear(Fgap,rgb))(5)
原始特征XrgbX_{rgb}Xrgb乘以WrgbrgbW^{rgb}{rgb}Wrgbrgb,对齐特征Xir′X'{ir}Xir′乘以WirrgbW^{rgb}{ir}Wirrgb。为保留原始特征信息,引入残差连接。最终融合特征为:
Xrgb−fused=(Xrgb⊙Wrgbrgb)+(Xir′⊙Wirrgb)+Xrgb(6)X{rgb-fused} = (X_{rgb} \odot W^{rgb}{rgb}) + (X'{ir} \odot W^{rgb}{ir}) + X{rgb} \tag{6}Xrgb−fused=(Xrgb⊙Wrgbrgb)+(Xir′⊙Wirrgb)+Xrgb(6)
类似地,IR模态分支操作如下:
Xir−fused=(Xir⊙Wrgbir)+(Xrgb′⊙Wirir)+Xir(7)X_{ir-fused} = (X_{ir} \odot W^{ir}{rgb}) + (X'{rgb} \odot W^{ir}{ir}) + X{ir} \tag{7}Xir−fused=(Xir⊙Wrgbir)+(Xrgb′⊙Wirir)+Xir(7)
此设计动态平衡对齐特征与原始特征的贡献,确保鲁棒融合,同时缓解信息丢失。
D. MMA-SORT
现有MOT模型(如SORT64及其变体7,65,66,8,9,36,37)在无人机目标跟踪任务中表现出显著局限。首先,无人机目标的小尺寸和复杂运动模式对运动建模构成重大挑战。卡尔曼滤波固有的线性运动假设常导致当前帧中基于前一帧预测的边界框与实际检测间产生显著差异。这使得以IoU指标为中心的跟踪器无法实现跨帧身份关联,从而导致大量ID切换(IDSW)。
为解决此问题,我们在目标身份关联过程中弱化IoU指标的作用。与将IoU匹配视为身份关联必要前提的传统跟踪器不同,我们认为在模拟小且不规则运动的无人机目标时,卡尔曼滤波不如对行人和车辆等目标可靠。因此,在多无人机跟踪任务中 rigidly 坚持将IoU匹配作为前提过于严格。
其次,无人机目标提供的判别性外观线索不足。具体而言,当目标较小时,仅依赖外观嵌入难以区分不同身份的无人机。也难以有效分离无人机目标与背景物体。为此,我们引入事件模态以描绘无人机运动状态,使用运动嵌入辅助外观嵌入进行目标身份判别。
考虑到无人机跟踪任务的严格实时要求,我们采用无学习方法,直接利用原始事件模态图像的像素级统计信息生成运动嵌入。这避免了引入耗时ReID模块导致的速度下降。
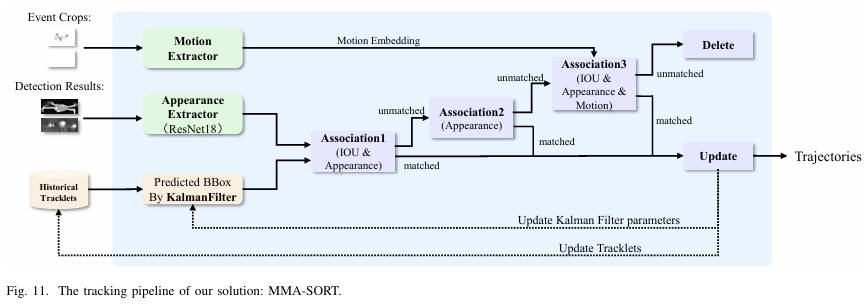
基于上述分析,我们提出一种结合事件模态的新型跟踪器,其详细流水线如图11所示。跟踪器接收超过置信度阈值的检测结果,关联过程分为三个阶段。
第一阶段 ,对于所有输入检测和已确认轨迹,结合IoU匹配与外观嵌入区分目标。检测与轨迹间距离计算如下:
d=min(diou,dapp)(8)d = \min(d_{iou}, d_{app}) \tag{8}d=min(diou,dapp)(8)
其中ddd表示最终距离,dioud_{iou}diou为检测框与轨迹预测框间的IoU距离,dappd_{app}dapp为检测与轨迹间的外观嵌入距离。IoU距离和外观距离的计算遵循BoT-SORT9。
第二阶段 ,对于未匹配检测和剩余轨迹,使用外观嵌入恢复IoU不匹配的目标。此阶段检测框与轨迹间外观距离dappd_{app}dapp的计算与第一阶段相同。
第三阶段 ,对于剩余检测和未确认轨迹,结合IoU、外观嵌入和运动嵌入进行匹配。考虑到事件模态图像的信息稀疏性和任务实时要求,我们不采用ReID模型进行逐层特征提取。而是直接计算目标区域内非背景像素的统计特征,并将其显式建模为7维向量:
Emotion=Nnon−bg,μx,σx,μy,σy,Sx,Sy(9)E_{motion} = N_{non-bg}, \\mu_x, \\sigma_x, \\mu_y, \\sigma_y, S_x, S_y \tag{9}Emotion=Nnon−bg,μx,σx,μy,σy,Sx,Sy(9)
其中运动嵌入的每个维度代表以下统计量:非背景像素数Nnon−bgN_{non-bg}Nnon−bg、归一化X均值μx\mu_xμx、归一化X标准差σx\sigma_xσx、归一化Y均值μy\mu_yμy、归一化Y标准差σy\sigma_yσy、归一化X范围SxS_xSx和归一化Y范围SyS_ySy。运动嵌入距离的计算遵循余弦相似度定义:
dmotion=1−Emotioni⋅Emotionj∥Emotioni∥⋅∥Emotionj∥(10)d_{motion} = 1 - \frac{E^i_{motion} \cdot E^j_{motion}}{\|E^i_{motion}\| \cdot \|E^j_{motion}\|} \tag{10}dmotion=1−∥Emotioni∥⋅∥Emotionj∥Emotioni⋅Emotionj(10)
其中dmotiond_{motion}dmotion表示两目标间运动嵌入距离,EmotioniE^i_{motion}Emotioni和EmotionjE^j_{motion}Emotionj分别表示第iii和第jjj个目标的运动嵌入,⋅\cdot⋅表示点积运算,∥⋅∥\|\cdot\|∥⋅∥表示向量L2范数。计算IoU距离dioud_{iou}diou、外观距离dappd_{app}dapp和运动距离dmotiond_{motion}dmotion后,类比IoU距离和外观距离,我们定义带阈值的运动距离dmd_mdm用于过滤,公式为:
dmotion={dm,if dm≤θmotion1,otherwise(11)d_{motion} = \begin{cases} d_m, & \text{if } d_m \le \theta_{motion} \\ 1, & \text{otherwise} \end{cases} \tag{11}dmotion={dm,1,if dm≤θmotionotherwise(11)
此阶段最终距离ddd为:
d={max(dapp,dmotion),if diou≤θiou1,otherwise(12)d = \begin{cases} \max(d_{app}, d_{motion}), & \text{if } d_{iou} \le \theta_{iou} \\ 1, & \text{otherwise} \end{cases} \tag{12}d={max(dapp,dmotion),1,if diou≤θiouotherwise(12)
此阶段引入运动嵌入旨在解决复杂背景中易出现外观相似的无人机假阳性样本问题。这些干扰物体被初始化为未确认轨迹,扰乱后续匹配过程。运动嵌入可防止目标与干扰背景的错误关联,减少标签错位,从而有效抑制背景噪声干扰。每个阶段均将匈牙利匹配算法应用于所得距离矩阵,实现检测与轨迹的最优匹配。
需注意,事件模态与RGB和IR模态存在一定时空不匹配。此外,其缺乏详细纹理信息使得传统方法难以预对齐。同时,考虑到数据集专为稀疏开阔场景的无人机跟踪任务定制,密集目标重叠实例极罕见。因此,从事件图像裁剪目标时,我们通过扩大裁剪范围(宽度和高度方向各向外扩展20像素)缓解传感器引起的模态间时空不匹配。
V. 评估
A. 实现细节
在所提框架中,检测器的骨干、FPN模块和检测头遵循原始YOLOX4。对于两种模态的RGB图像(640×360640\times360640×360)和IR图像(640×512640\times512640×512),我们首先使用标准YOLOX预处理流水线将其resize至640×640640\times640640×640,然后输入骨干进行特征提取。所提OGAA和ADFM模块插入骨干与FPN之间,负责跨模态对齐与融合由两个模态特定骨干独立提取的三尺度特征图。融合后的多尺度特征随后转发至各自FPN模块进行后续检测,最终检测结果传递至MMA-SORT跟踪器进行多目标跟踪。
训练期间,双流架构为每种模态产生独立检测输出。因此,RGB和IR头的检测损失分别计算并同时反向传播,各模态损失函数与YOLOX保持一致。原则上,基于YOLO的检测器通常依赖多样数据增强策略(如随机颜色抖动、Mosaic和Mixup)提升鲁棒性。然而,此类多图像混合和随机几何变换对未注册多模态特征的对齐与融合施加额外挑战。此问题对基于STN的对齐尤为关键,因为这些增强虽提升复杂场景鲁棒性,但常破坏输入固有空间结构,阻碍STN学习有效仿射变换。为此,我们采用两阶段训练策略。第一阶段,使用数据增强训练网络100个epoch,仅独立更新各模态的骨干、FPN和检测头,无跨模态交互。第二阶段,冻结骨干和FPN权重,禁用数据增强,训练OGAA和ADFM模块50个epoch,同时微调检测头。第一阶段使用SGD,初始学习率5e−35e-35e−3,动量0.9,batch size 32。第二阶段使用AdamW,相同学习率和batch size。所有训练和推理在单张NVIDIA RTX 4090 GPU上执行。
关于基于STN的对齐策略,初始仿射变换矩阵通过关键点匹配计算。从数据集选取一对RGB和IR图像,使用传统关键点检测方法导出矩阵。由于数据采集期间RGB和IR相机相对位置固定,同一矩阵可应用于所有序列,作为全局唯一初始化。最终计算两个仿射矩阵,一个将RGB对齐到IR,另一个将IR对齐到RGB。
对于基于外观的ReID模块,鉴于无人机目标视觉信息有限,我们直接采用DeepSORT7的ReID模型和训练策略,使用ResNet骨干提取判别性外观特征。
推理期间,检测置信度阈值为0.3。对于跟踪器,IoU阈值θiou\theta_{iou}θiou为0.9,外观阈值为0.2,运动阈值θmotion\theta_{motion}θmotion为0.2,初始化新轨迹的置信度阈值为0.7。
B. 定量比较
为提供全面参考,我们对数据集上的最先进多目标跟踪方法进行广泛评估。此外,验证了所提多模态跟踪器的优越性,证明多模态融合框架显著提升反无人机跟踪鲁棒性。
为对比评估,系统评估了两类SOTA多目标跟踪方法,包括基于检测的跟踪(DeepSORT7、BoT-SORT9、OC-SORT66、Deep OC-SORT65、BoostTrack36、BoostTrack++37)和基于查询的跟踪(TransTrack56、MOTR57、MOTRv267、MeMOTR58、MOTIP68)。所有跟踪器在MM-UAV上重新训练和测试以确保公平比较。由于现有方法为单模态跟踪设计,实验在RGB和IR模态上独立进行。结果汇总于表II。为公平起见,所有基于检测的方法共享相同检测器权重,基于查询的方法按默认配置重新训练。
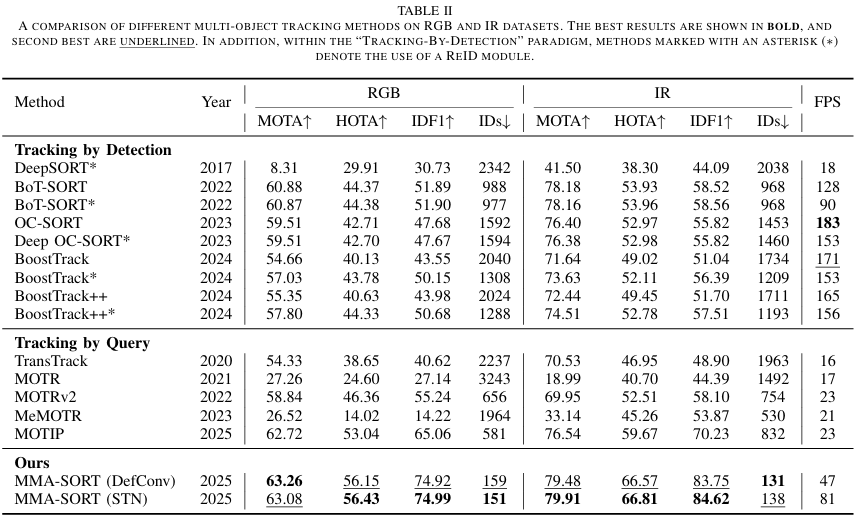
性能使用标准MOT指标69,70评估,包括MOTA、IDF1、HOTA和ID切换。使用可变形卷积对齐时,我们的方案在RGB模态上取得63.26 MOTA、56.15 IDF1、74.92 HOTA和159 IDs,IR模态上为79.48、66.57、83.75和131。使用STN对齐时,RGB结果为63.08、56.43、74.99和151,IR为79.91、66.81、84.62和138。结果表明,所提多模态融合方法在所有指标上始终优于现有单模态方法,尤其在HOTA和IDF1上提升显著。例如,相比最强单模态基线MOTIP,可变形对齐策略在RGB模态上将HOTA和IDF1提升3.11%和9.86%,STN策略提升3.39%和9.93%。
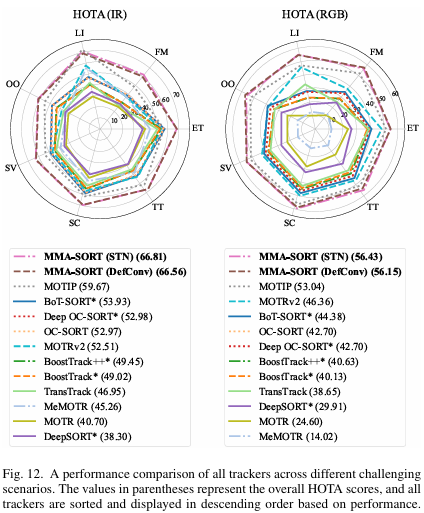
此外,鉴于实时性能对无人机跟踪应用至关重要,报告了推理速度(FPS)。相比基于Transformer的查询跟踪方法,基于检测的方法通常因轻量YOLO检测器而速度更快。尽管所提多模态方法引入额外对齐和融合操作,速度略慢于单模态基于检测方法,但实现显著更鲁棒的跟踪,同时仍满足实时要求。为全面评估各挑战性场景下跟踪器性能,我们在多种代表性条件下进行详细评估,见图12。为公平直观量化跟踪有效性,采用整体HOTA指标。实验结果表明,我们的方法在几乎所有场景下始终优于现有MOT跟踪器,尤其在快速运动(FM)和低照度(LI)条件下优势显著。这些发现强烈表明,所提多模态融合框架利用模态间互补信息,实现更强身份关联。
C. 消融研究
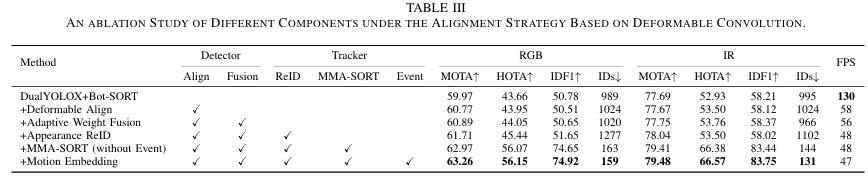
为验证框架中各组件有效性,我们基于可变形卷积对齐策略和STN对齐策略进行系统消融研究。结果分别报告于表III和表IV。具体而言,第一行表示基线,检测阶段无跨模态对齐或动态融合。两种模态的对齐特征直接相加,跟踪阶段使用无ReID模块的原始BoT-SORT。在此基础上,第二行引入对齐模块。第三行报告将简单求和替换为动态加权融合的影响。第四至六行聚焦跟踪阶段消融。第四行在BoT-SORT中加入基于外观的ReID模块,以补偿复杂无人机运动下仅IoU匹配的局限。第五行采用我们提出的MMA-SORT三阶段关联流水线,但仅使用IoU相似度和外观嵌入,不引入事件模态。第六行呈现最终版本,引入事件模态的运动嵌入以突显其在多无人机跟踪中的潜力。
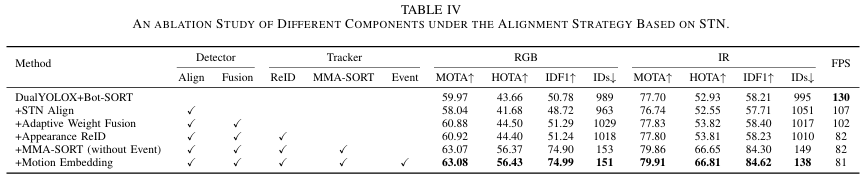
对齐与融合模块效果 :表III和表IV前三行表明,结合对齐模块与自适应动态融合带来一致性能提升,但牺牲部分运行时开销。对齐模块旨在缓解模态间空间差异。表III中,引入可变形卷积对齐带来显著增益,尤其对较弱的RGB模态,MOTA提升0.8%,HOTA提升0.29%。然而,直接相加模态特征放大噪声,产生更多假阳性并增加ID切换。相比之下,STN模块执行全局仿射变换实现对齐,但缺乏可变形卷积的局部自适应学习能力,直接相加特征时对噪声更脆弱。这解释了表IV中仅使用STN对齐时的性能下降。值得注意的是,当对齐模块与动态融合结合时(两表第三行),两种模态更好平衡,带来显著性能提升。此外,由于STN显式应用仿射变换对齐,我们进一步可视化特征变化,见图13。

ReID模块效果:许多现有跟踪器严重依赖运动线索,使用卡尔曼滤波预测和基于IoU的边界框相似度进行关联。然而,此类策略对轨迹不稳定且频繁消失重现的无人机目标不可靠。因此,ReID模块对跟踪无人机目标至关重要。表III和表IV第四行确认此设计有效性,显示无人机跟踪精度一致提升。
关联策略效果:合适的关联策略对MOT至关重要。多数现有跟踪器严重依赖边界框间IoU相似度,但无人机目标的小尺寸和不规则运动显著降低基于IoU关联的可靠性。为克服此问题,我们提出的MMA-SORT通过(1)提高IoU过滤阈值,和(2)引入事件模态捕获的运动嵌入辅助外观ReID,弱化IoU主导地位。表III和表IV结果表明,MMA-SORT在身份关联中提供显著优势。例如,在可变形卷积对齐下,RGB模态HOTA从45.44提升至56.07,IDF1从51.65提升至74.92,ID切换从1277降至159。IR模态HOTA从53.50提升至66.57,IDF1从58.02提升至83.75,ID切换从1102降至131。类似地,在STN对齐下,RGB模态HOTA从44.40升至56.43,IDF1从51.24升至74.99,ID切换从1018降至151。IR模态HOTA从53.81提升至66.81,IDF1从58.23提升至84.62,ID切换从1010降至138。
运动嵌入效果 :最后,我们评估事件模态在多无人机跟踪中的价值。如表III和表IV第六行所示,引入事件模态运动嵌入在所有指标上带来一致整体提升。为说明其贡献,我们在图14中提供跟踪结果的定性可视化,事件信息的整合导致更准确的轨迹关联。

D. 局限性与讨论
尽管所提多模态跟踪框架取得 promising 结果,仍存在若干局限需在未来的研究中解决。
模态对齐局限:多模态融合的关键瓶颈在于不完美模态对齐的风险。尽管所提OGAA和ADFM模块在一定程度上缓解跨模态不匹配,但无法完全消除由传感器放置、分辨率差异或环境变化引起的差异。结果,不同模态的互补优势(尤其是事件模态)尚未完全发挥。此局限表明需要更先进的时空对齐技术以释放多模态多无人机跟踪的全部潜力。
小无人机跨模态标注挑战:与目标尺寸在各模态间相对一致的现有基准不同,无人机目标极小且在不同模态间表观尺寸差异显著。这种差异使得共享统一跨模态标注不可靠。为缓解此问题,我们为RGB和IR帧提供独立标注,并采用处理各模态独立的双流网络架构。虽此设计确保评估的公平性和可靠性,但仍属妥协而非原则性解决方案。
VI. 结论
本文提出MM-UAV,首个大规模多模态多无人机跟踪基准,旨在解决该领域缺乏权威数据集的问题。MM-UAV涵盖三种关键视觉模态------RGB、IR和事件------包含1,321个视频序列(1,200训练,121测试),每模态超过280万帧。除前所未有的规模和多样性外,该基准引入严格标注协议,在遮挡和重新出现期间维持一致身份标签。此外,定义七种挑战性场景属性,确保真实世界条件的忠实表征,为评估算法鲁棒性提供可靠基础。
基于此基准,我们提出首个专为反无人机应用设计的多模态多目标跟踪框架,实现高效跨模态融合与协作。遵循基于检测的跟踪范式,我们的框架在检测阶段引入偏移引导自适应对齐模块(OGAA)和自适应动态融合模块(ADFM)。OGAA利用可变形卷积和空间变换网络(STN)策略解决不同传感器间的时空不匹配,从而实现小无人机目标的精确定位。ADFM采用通道注意力机制动态平衡RGB和红外特征的贡献,充分发挥其互补优势。在跟踪阶段,我们设计MMA-SORT跟踪器以缓解相似目标外观和不规则运动模式引起的身份切换。MMA-SORT首次融入源自事件数据的运动嵌入,与外观嵌入协同工作,显著提升身份关联准确性,并极有效抑制复杂背景中的假检测和匹配错误。
展望未来,我们计划研究更先进的事件模态融合策略,并持续优化所提多模态多无人机跟踪框架,以推进多模态无人机跟踪研究。
致谢
本工作部分受国家自然科学基金(62020106012, 62576152)、江苏省基础研究计划(BK20250104)、中央高校基本科研业务费(JUSRP202504007)及Leverhulme Trust Emeritus Fellowship(EM-2025-06-09)支持。