目录
摘要:
本博客介绍并使用13种文件函数接口,其中包含8种顺序读写函数,3种随机读写函数,2种状态检测函数,每种函数都会讲解和演示代码示例
一:文件操作的流程
想对文件进行读写操作,则流程一定为:打开文件--->读/写文件--->关闭文件,而读/写文件可能是只读,可能是只写,可能是追加,可能是既读又写,所以在使用fopen打开文件的时候,函数规定需要在fopen的对应参数选择对应的打开模式:
1:fopen
FILE * fopen ( const char * filename, const char * mode )
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
filename |
const char * |
要打开的文件名(可包含路径) |
mode |
const char * |
打开模式 |
函数作用:
-
建立调用fopen的程序与filename文件之间的连接
-
返回一个
FILE *类型的指针,供后续读写操作使用
返回值:
-
成功 :返回
FILE * -
失败 :返回
NULL
注意事项:
-
返回值为FILE*,是结构体FILE的指针,通过该指针可以进行文件的相关操作
-
必须检查返回值!后序读写前,务必先判断fopen的返回值是否为
NULL
常用的打开模式如下:
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| "r" (只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| "w" (只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| "a" (追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
| "rb" (只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| "wb" (只写) | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
| "ab" (追加) | 向一个二进制文件尾添加数据 | 建立一个新的文件 |
| "r+" (读写) | 为了读和写,打开一个文本文件 | 出错 |
| "w+" (读写) | 为了读和写,建议一个新的文件 | 建立一个新的文件 |
| "a+" (读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| "rb+" (读写) | 为了读和写打开一个二进制文件 | 出错 |
| "wb+" (读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| "ab+" (读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
2:fclose
int fclose ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
参数就是fopen的返回值 |
函数作用:
- 关闭文件,并且断开程序与文件之间的连接(顺便会刷新缓冲区)
返回值:
| 返回值 | 含义 |
|---|---|
0 |
关闭成功 |
EOF(通常是 -1) |
关闭失败(如缓冲区刷新失败、无效流指针等) |
注意事项:
- fclose关闭文件后,安全起见,必须将 FILE * 类型的fp设为 NULL,但由于flose一般都是代码的末尾执行,后面也不会在使用fp,所以往往会省去这一步,但加上才是更好的做法
所以文件操作的整体框架就为:
cpp
#include <stdio.h>
int main()
{
//打开⽂件
FILE* pFile = fopen("myfile.txt", "w");
//根据需求 进行⽂件读/写操作
//关闭文件
fclose(pFile);
return 0;
}3:文件的路径
在调用 fopen 时,可以直接在第一个参数中传入文件名(如 "data.txt"),此时系统会自动在当前工作目录下查找或创建该文件。当然,也可以传入完整的绝对路径"C:\\project\\data.txt" 来指定任意位置的文件。
某些打开模式,是要求在指定路径下必须存在目标文件的,所以当使用这些打开模式的时候,需要事先手动新建,或者使用能够自动新建的写函数去常见文件;而有些打开模式发现目录不存在会自动创建文件;
4:顺序和随机的区别
顺序读写函数和随机读写函数,都是因为存在文件位置指示器这个东西,每次打开一个文件,其对应的FILE结构体中就会维护着一个文件位置指示器(也叫文件指针、文件偏移量),它记录着下一次读写操作将从文件的哪个字节位置开始!
每次使用顺序读写函数后,文件位置指示器会自动向后移动相应字节数,因此读写操作会自然地形成顺序去进行读写!
而随机读写函数,其可以修改文件位置指示器的值,可以跳跃到文件的任意位置进行读写,而不必按照顺序一个个处理,所以叫做随机读写函数!
二:顺序读写函数
顺序读写函数有8种,如下:
| 函数名 | 功能 | 适用于 |
|---|---|---|
| fgetc | 字符输入函数 | 所有输入流 |
| fputc | 字符输出函数 | 所有输出流 |
| fgets | 文本行输入函数 | 所有输入流 |
| fputs | 文本行输出函数 | 所有输出流 |
| fscanf | 格式化输入函数 | 所有输入流 |
| fprintf | 格式化输出函数 | 所有输出流 |
| fread | 二进制输入 | 文件 |
| fwrite | 二进制输出 | 文件 |
**解释:**上⾯说的适用于所有输入流⼀般指适用于标准输⼊流和其他输⼊流(如文件输⼊流);所有输出流⼀般指适用于标准输出流和其他输出流(如文件输出流)
⚠️:此篇博客都是对当前路径下的test.txt文件进行操作,所以前后会有因果关系
1:fputc
int fputc ( int character, FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
character |
int |
要写入的字符的ascll码值 |
stream |
FILE * |
指向要写入的文件流的指针 |
注:character也可以直接传递'a'这种字符,因为字符的本质就是ascll码值(int类型)
函数作用:
- 将字符写入到文件中,成功写入后,文件位置指示器自动向后移动一个字节
返回值:
| 返回值 | 含义 |
|---|---|
| int (写入的字符的ascll码值) | 写入成功 |
EOF(-1) |
写入失败(读取时到达文件尾或发生错误) |
注意事项:
- fputc作为写函数,自然需要以写相关的打开模式去打开文件
使用示例:
a:写入单个字符
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "w");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
fputc('A', fp);
fclose(fp);
return 0;
}解释:
**①:**test.txt文件不存在,所以fopen以写的形式打开文件的时候,会在指定路径下新建该文件,这里的路径只有文件名字,所以路径就是当前程序对应的目录,文件如下:
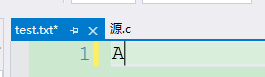
b:循环写入字符

**解释:**因为是w模式打开文件,而不是追加模式,所以下一次的写之前,会清空上一次所写的内容
2:fgetc
int fgetc ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要读取的文件的FILE结构体 |
函数作用:
- 从指定的文件流(stream)中读取一个字符
返回值:
-
返回该字符的 ASCII 值。如果读取时到达文件尾或发生错误,则返回
EOF -
End Of File,一个特殊的常量,通常在大多数系统中定义为 -1
注意事项:
- 会读取包括空格、换行在内的所有字符
使用示例:
①:读取单个字符
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
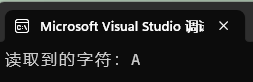
int ch = fgetc(fp);
if (ch != EOF) {
printf("读取到的字符:%c\n", ch);
}
fclose(fp);
return 0;
}
②:循环读取字符
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
int ch;
while ((ch = fgetc(fp)) != EOF) {
putchar(ch);
}
fclose(fp);
return 0;
}
**解释:**fgetc无法读取的返回值为EOF,所以当我们想循环读取文件的时候,就可以使用返回值不为EOF进行循环去读完整个文件
3:fputs
int fputs ( const char * str, FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
str |
const char * |
要写入的字符串(以 \0 结尾) |
stream |
FILE * |
指向要写入的文件流的指针 |
函数作用:
- 将字符串写入到指定的文件流中(将字符串str写入到文件流stream中),且文件位置指示器会向后移动写入的字节数
返回值:
| 返回值 | 含义 |
|---|---|
>= 0 |
写入成功(返回最后一个写入的非负字符数) |
EOF(-1) |
写入失败 |
注意事项:
-
fputs不会自动添加换行,需要换行要手动加\n(两次fputs会出现在同一行) -
字符串必须以
\0结尾,否则fputs会一直找字符串中的'\0',可能会导致越界访问
使用示例:
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "w");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
fputs("hello world", fp);
fclose(fp);
return 0;
}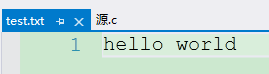
**解释:**写入了一个字符串,因为是w方式打开文件,所以之间的文件内容会被清空再写入
4:fgets
char * fgets ( char *str, int num, FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
str |
char * |
字符串的指针,该字符串用于存储读取到的字符串 |
num |
int |
最多读取的字符个数(包含结尾的 \0) |
stream |
FILE * |
指向要读取的文件流的指针 |
函数作用:
- 从文件流stream中读取一个最大字符数为**(num-1)**的字符串str
返回值:
| 返回值 | 含义 |
|---|---|
str(传入的指针str) |
读取成功 |
NULL |
到达文件末尾 或 发生读取错误 |
注意事项:
-
num参数包含了结尾的\0,所以实际最多读num-1个字符 -
缓冲区
str要足够大,至少num字节
fgets 停止读取的三种情况:
| 情况 | 说明 |
|---|---|
① 遇到换行符 \n |
读取换行符,将'\n'存入 str,然后停止,末尾加 \0 |
② 已读取 num-1 个字符 |
还没遇到换行符,停止,末尾加 \0 |
| ③ 遇到文件尾 EOF | 没有读到任何字符,返回 NULL;如果读到部分字符后遇到 EOF,也会停止并加 \0 |
Q:如果fgets读取的时候遇到了'\0'呢,会提前停止吗?
A:不会!fgets 是把 \0 当作普通数据字符读取,不会因为读到 \0 就停止!
验证示例:
我们往文件中写入字符'A' '\0' 'B' '\n' 'C',然后再用fgets读取10个字节
Q:为什么不用fputs直接写入字符串"A\0B\nC"?
A:因为fputs写入的时候,遇到\0就会停止,不再往后写入,这是特性,否则fputs停不下来
cpp
#include <stdio.h>
int main() {
// 用 fputs 写入(但 fputs 遇到 \0 会停止写入)
FILE* fp = fopen("test.txt", "w");
fputs("A", fp);
fputc('\0', fp); // 手动写入 \0
fputs("B\nC", fp);
fclose(fp);
// 用 fgets 读取
fp = fopen("test.txt", "r");
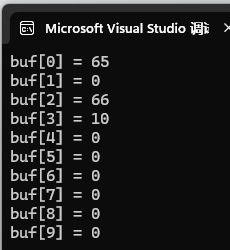
char buf[100] = { 0 };
fgets(buf, 100, fp);
for (int i = 0; i < 10; i++) {
printf("buf[%d] = %d\n", i, buf[i]);
}
fclose(fp);
return 0;
}
解释:
| 数组下标 | 十进制值 | 对应字符 | 说明 |
|---|---|---|---|
| buf0 | 65 | 'A' |
从文件读取的第一个字符 |
| buf1 | 0 | '\0' |
从文件读取的空字符 (fprintf 写入的 %c) |
| buf2 | 66 | 'B' |
\0 后面的 B,说明遇到 \0 没停止 |
| buf3 | 10 | '\n' |
换行符,遇到它 fgets 才停止读取 |
| buf4 | 0 | '\0' |
fgets 自动添加的字符串结束符 |
| buf5\~9 | 0 | '\0' |
缓冲区剩余空间被初始化为 0(未使用部分) |
这代表遇到第一个'\0'没有停止下来,而遇到'\n'换行符才会停止
Q:为什么要这么设置?
A:因为文本文件中压根就没有'\0',你在记事本中见过'\0'吗?但是存在换行!所以检测'\n'
5:fprintf
int fprintf ( FILE * stream, const char * format, ... );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要写入的文件流的指针 |
format |
const char * |
格式控制字符串(包含格式占位符如 %d、%s 等) |
... |
可变参数 | 对应格式占位符要输出的变量 |
函数作用:
- 将格式化的数据写入到指定的文件流中
返回值:
| 返回值 | 含义 |
|---|---|
>= 0 |
成功写入的字符总数 |
| 负数 | 写入失败 |
注意事项:
- 格式字符串与变量类型要匹配,否则结果不可预料
使用示例:
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "w");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
int age = 25;
float score = 92.5;
char name[] = "张三";
fprintf(fp, "%s\n", name);
fprintf(fp, "%d\n", age);
fprintf(fp, "%.1f\n", score);
//合成一行的写法
//fprintf(fp, "%s %d %.1f\n", name, age, score);
fclose(fp);
fp = NULL;
return 0;
}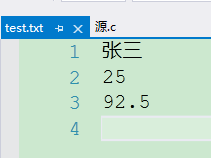
**解释:**说白了就是在printf的用法上,增加一个FILE*类型的参数fp而已
6:fscanf
int fscanf ( FILE * stream, const char * format, ... );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要读取的文件流的指针 |
format |
const char * |
格式控制字符串(指定如何解析数据) |
... |
可变参数 | 对应格式占位符的变量地址(用于存储读取的值) |
函数作用:
- 从文件中读取格式化的数据
返回值:
| 返回值 | 含义 |
|---|---|
| 正整数 | 成功匹配并赋值的参数个数 |
0 |
没有匹配到任何数据(但可能有字符被读取) |
EOF(-1) |
读取时到达文件尾 或 发生错误 |
注意事项:
-
功能与
scanf完全相同,区别是scanf从键盘读取,fscanf从文件读取 -
自动跳过空白字符(空格、换行、制表符等)
-
遇到类型不匹配或文件尾时停止
使用示例:
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
char name[50];
int age;
float score;
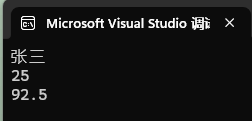
fscanf(fp, "%s", name);
fscanf(fp, "%d", &age);
fscanf(fp, "%f", &score);
printf("%s\n", name);
printf("%d\n", age);
printf("%.1f\n", score);
fclose(fp);
return 0;
}
7:fwite
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
ptr |
const void * |
指向要写入的数据的指针 |
size |
size_t |
每个元素的大小(字节数) |
count |
size_t |
要写入的元素个数 |
stream |
FILE * |
指向要写入的文件流的指针 |
函数作用:
- 将数据块以二进制的形式写入文件流(
fwrite从由ptr指向的内存块中取出count个元素,每个元素的大小为size字节,并将它们写入到stream指向的文件流中)
返回值:
| 返回值 | 含义 |
|---|---|
count |
成功写入的元素个数(等于 count 表示全部成功) |
< count |
部分写入成功(通常表示磁盘满或发生错误) |
注意事项:
-
文件通常以二进制模式打开(
"wb"、"ab"、"wb+") -
写入的是原始二进制数据,用记事本打开可能显示乱码
-
返回的是元素个数,不是字节数(实际字节数 = 返回值 × size)
-
适合配合
fread使用
使用示例:
cpp
#include <stdio.h>
int main() {
FILE *fp = fopen("test.txt", "wb");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
int arr[] = {10, 20, 30, 40, 50};
fwrite(arr, sizeof(int), 5, fp);
fclose(fp);
return 0;
}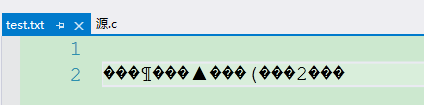
**解释:**fwrite以二进制的形式向test.txt文件中写入数据后,我们此时打开test.txt文件是乱码
8:fread
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
ptr |
void * |
指向存储读取数据的缓冲区的指针 |
size |
size_t |
每个元素的大小(字节数) |
count |
size_t |
要读取的元素个数 |
stream |
FILE * |
指向要读取的文件流的指针 |
函数作用:
-
从文件中以二进制形式读取数据到内存中
-
适合读取数组、结构体等二进制数据
-
文件位置指示器向后移动
size × 实际读取的元素个数字节
返回值:
| 返回值 | 含义 |
|---|---|
count |
成功读取的元素个数(等于 count 表示全部成功) |
< count |
部分读取成功(可能到达文件尾或发生错误) |
0 |
没有读取到任何元素(文件尾或错误) |
注意事项:
-
文件通常以二进制模式打开(
"rb"、"ab"、"rb+") -
读取的是原始二进制数据,必须与写入时的格式完全一致
-
缓冲区
ptr必须足够大,至少size × count字节 -
适合配合
fwrite使用
使用示例:
cpp
#include <stdio.h>
int main() {
// 先写入数据
FILE* fp = fopen("test.txt", "wb");
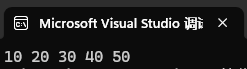
int arr1[] = { 10, 20, 30, 40, 50 };
fwrite(arr1, sizeof(int), 5, fp);
fclose(fp);
// 再读取数据
fp = fopen("test.txt", "rb");
int arr2[5];
fread(arr2, sizeof(int), 5, fp);
for (int i = 0; i < 5; i++) {
printf("%d ", arr2[i]);
}
fclose(fp);
return 0;
}
三:随机读写函数
1:fseek
int fseek ( FILE * stream, long int offset, int origin );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要操作的文件流的指针 |
offset |
long int |
偏移量(字节数),正数向后移动,负数向前移动 |
origin |
int |
起始位置(三个宏常量之一) |
origin 的三种取值:
| 宏常量 | 数值 | 含义 |
|---|---|---|
SEEK_SET |
0 | 从文件开头开始偏移 |
SEEK_CUR |
1 | 从当前位置开始偏移 |
SEEK_END |
2 | 从文件末尾开始偏移 |
函数作用:
-
移动文件位置指示器到指定位置
-
实现文件的随机读写(跳转到任意位置)
-
不会读写文件内容,只改变下一次读写的位置
-
可以向前或向后移动(取决于
offset正负)
返回值:
| 返回值 | 含义 |
|---|---|
0 |
移动成功 |
非0 |
移动失败(如偏移量超出文件范围) |
注意事项:
-
移动超出文件开头的偏移量是未定义行为
-
与
ftell配合使用可以保存和恢复位置 -
offset是偏移量,第一个字节的偏移量为0,以此类推,第n个字节的偏移量为n-1
使用示例:
目前已设置文件内容如下:

cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
fseek(fp, 10, SEEK_SET); // 跳到第 10 个字节处
int ch = fgetc(fp); // 读取第 10 个字节
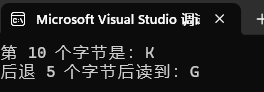
printf("第 10 个字节是:%c\n", ch);
fseek(fp, -5, SEEK_CUR); // 从当前位置后退 5 个字节
ch = fgetc(fp);
printf("后退 5 个字节后读到:%c\n", ch);
fclose(fp);
return 0;
}
解释:
**①:**偏移量为10,此时文件文件位置指示器指向的就是第11个字节,所以K
**②:**读取完K之后,文件位置指示器会向后走一个位置,此时偏移量变成11
**②:**偏移量为-5,代表偏移量从11变成了6,此时文件文件位置指示器指向的就是第7个字节,F
2:ftell
long int ftell ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要查询的文件流的指针 |
函数作用:
-
返回文件位置指示器的当前偏移量,用于获取当前读写位置
-
通常与
fseek配合使用(保存位置、稍后恢复) -
可以配合
fseek计算文件大小
返回值:
| 返回值 | 含义 |
|---|---|
>= 0 |
当前文件位置指示器的偏移量(字节数) |
-1L(long 类型的 -1) |
获取失败(通常表示流不支持定位或发生错误) |
注意事项:
-
文本模式下,
ftell返回的值不一定是实际字节偏移量(不同系统的换行符处理不同),但返回值都可使用于fseek -
二进制模式下,返回值就是精确的字节偏移量
使用示例:
a:ftell检测当前偏移量
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
fseek(fp, 5, SEEK_SET); // 跳到偏移量 5
long pos = ftell(fp); // 获取当前位置
printf("当前位置:%ld\n", pos); // 输出 5
fgetc(fp); // 读一个字符
pos = ftell(fp);
printf("读完后位置:%ld\n", pos); // 输出 6
fclose(fp);
return 0;
}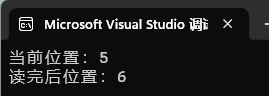
**解释:**使用fseek让偏移量为5,此时我们读一个字符,由于顺序函数的特性,偏移量会+1,再次使用ftell检测偏移量就为6了
b:ftell配合fseek得到文件大小
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "rb");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
fseek(fp, 0, SEEK_END); // 跳到文件末尾
long size = ftell(fp); // 获取偏移量 = 文件大小
printf("文件大小:%ld 字节\n", size);
fclose(fp);
return 0;
}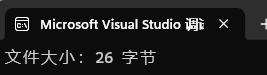
**解释:**直接使用fseek跳到文件的末尾,然后再使用ftell检测偏移量,偏移量就是文件字节大小
3:rewind
void rewind ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要操作的文件流的指针 |
函数作用:
-
将文件位置指示器移动到文件开头(偏移量 0)
-
相当于
fseek(fp, 0, SEEK_SET)
返回值:
| 返回值 | 含义 |
|---|---|
| 无返回值 | void 类型,不返回任何值 |
注意事项:
-
rewind没有返回值,无法判断是否成功 -
如果需要判断是否成功,建议用
fseek(fp, 0, SEEK_SET)替代(可检查返回值)
使用示例:
a:遍历两遍文件:
cpp
#include <stdio.h>
int main()
{
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
int ch;
// 第一遍:统计字符数
int count = 0;
while ((ch = fgetc(fp)) != EOF) {
count++;
}
printf("第一遍统计:%d 个字符\n", count);
// 重置到开头
rewind(fp);
// 第二遍:输出内容
printf("第二遍输出:");
while ((ch = fgetc(fp)) != EOF) {
putchar(ch);
}
fclose(fp);
return 0;
}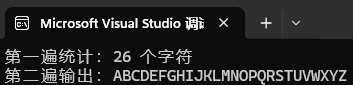
**解释:**先使用fgetc循环逐个读取文件,得到文件字符个数,然后再使用rewind让偏移量回到0,从头开始再使用fgetc打印文件内容
四:状态检测函数
我们知道文件读取或者写入的过程中,可能成功也可能失败,但肯定都会结束这次读/写的
**对于读:**①:成功读取,结束②:读取到了文件末尾,结束 ③:发生错误,结束
**对于写:**①:成功写入,结束 ②:发生错误结束
而上述的读写函数都有可能返回EOF,而返回EOF有两种可能,正常结束,发生错误,所以但我们想知道这次读写到底是因为正常结束还是发生错误,才返回EOF的时候,就需要使用状态检测函数,看到 EOF 只能说明没读/写到东西,但不知道精确原因
所以在文件读/写的过程中,如果发生错误,就会将一个错误标记设置一下。反之在文件读/写的过程中,如遇到文件末尾,就会将一个文件末尾的标记设置一下。二者只能标记其一,不会同时设置
状态检测函数有两个,feof 和 ferror,feof用去检测这个文件末尾标记是否被设置,如果被设置,就是在读取过程中遇到文件末尾才返回EOF的。ferror 去检测这个错误标记是否被设置,如果被设置,就是在读取过程中发生错误才返回EOF的。
总结:
EOF只是"没读/写到东西"的信号,具体原因要用feof和ferror去查。
1:feof
int feof ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要检查的文件流的指针 |
函数作用:
-
检查文件流的文件尾标志是否被设置
-
用于判断读/写失败的具体原因
返回值:
| 返回值 | 含义 |
|---|---|
非0 |
已到达文件末尾(文件尾标志被设置) |
0 |
尚未到达文件末尾 |
注意事项:
-
当最后一次读操作尝试读取超过文件末尾时,该标志被设置
-
用于区分
fgetc、fgets、fread等函数返回EOF或NULL时,到底是真的读完了还是出错了 -
需要配合
clearerr或rewind来清除标志
2:ferror
int ferror ( FILE * stream );
参数解释:
| 参数 | 类型 | 说明 |
|---|---|---|
stream |
FILE * |
指向要检查的文件流的指针 |
函数作用:
-
检查文件流的错误标志是否被设置
-
用于判断读/写失败的具体原因
返回值:
| 返回值 | 含义 |
|---|---|
非0 |
发生了错误(错误标志被设置) |
0 |
没有错误 |
注意事项:
-
错误标志一旦被设置,会一直保留直到被清除,需用
clearerr(fp)或rewind(fp)清除标志 -
perror或strerror可以获取具体错误信息 -
当读写操作发生错误时(如磁盘故障、权限问题等),该标志被设置
3:判断读取结束原因
cpp
#include <stdio.h>
int main() {
FILE* fp = fopen("test.txt", "r");
if (fp == NULL) {
perror("打开文件失败");
return 1;
}
int ch;
while ((ch = fgetc(fp)) != EOF) {
putchar(ch);
}
// 判断循环结束的原因
if (feof(fp)) {
printf("\n正常:已读到文件末尾\n");
}
if (ferror(fp)) {
printf("\n错误:读取过程中出现问题\n");
perror("具体错误");
}
fclose(fp);
return 0;
}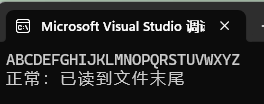
**解释:**fgetc在循环读取时停下了,返回值为EOF,分别使用feof 和 ferror去判断到底是正常读取文件末尾所以结束,还是发生错误结束,打印显示此次结束是因为读到了文件末尾
五:循环读的结束条件
使用读函数的时候,往往会让其循环一直读,直到把整个文件内容的都出来才停止,但是读函数之间对于无法读取的返回值不相同,所以总结一下各自的循环结束条件
| 函数 | 文件结束时返回值 | 循环结束条件 |
|---|---|---|
fgetc |
返回 EOF |
(ch = fgetc(fp)) != EOF |
fgets |
返回 NULL |
fgets(buf, size, fp) != NULL |
fscanf |
返回 EOF |
fscanf(fp, "%d", &n) != EOF |
fread |
返回实际读取元素个数(可能小于 count) | fread(buf, size, count, fp) < count |