在 Linux 开发中,文件 IO 是我们最常用的操作之一,但很多开发者只停留在会用 fopen、fread 的层面,却很少思考:++为什么同样是写文件,用 C 库函数和系统调用的性能差距能达到几十倍?重定向的本质到底是什么?缓冲区到底是怎么帮我们提升性能的?++
本文我们将从基础 IO 的核心知识点出发,结合源码、性能数据与可视化图表,带你彻底搞懂 Linux 基础 IO 的底层逻辑。
一、用户态与内核态
很多初学者会疑惑,为什么操作文件会有两套接口?一套是 C 语言的 fopen、fread、fwrite ,另一套是 fopen、fread、fwrite?
这是因为操作系统为了安全和管理,将系统的运行空间分为了用户态和内核态:
-
用户态:应用程序运行的空间,不能直接访问硬件,也不能直接操作内核数据
-
内核态:操作系统内核运行的空间,可以访问硬件,管理所有系统资源
而我们的文件操作,本质上是要和磁盘等硬件打交道,所以必须要陷入内核态来完成。这就有了两种方式:
-
库函数(标准 IO):C 标准库提供的封装接口,运行在用户态,内部会调用系统调用,帮我们做了很多优化(比如缓冲区)
-
系统调用(系统 IO):操作系统内核提供的底层接口,是用户态进入内核态的唯一入口,是所有文件操作的最终实现
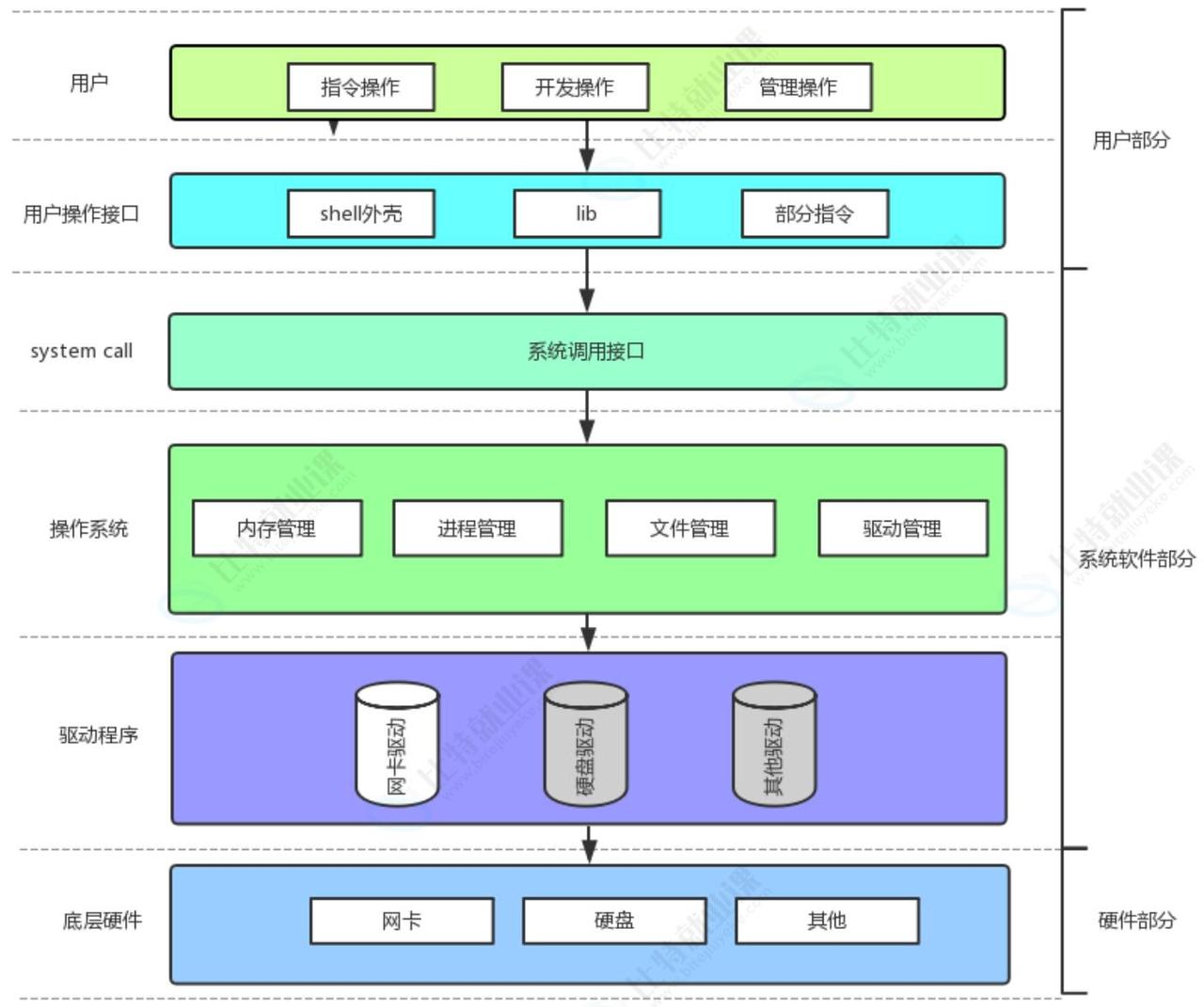
简单来说,所有的语言层文件操作,最终都会封装成系统调用,交给内核来完成实际的硬件操作。
二、标准 IO
我们最常用的 C 标准库文件操作,就是标准 IO,它帮我们屏蔽了很多底层细节,同时提供了缓冲优化,让我们的开发更简单高效。
2.1 文件路径
很多人写过这样的代码:
cpp
#include <stdio.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
while(1);
}
fclose(fp);
return 0;
}我们没有写绝对路径,那这个myfile到底创建在了哪里?
答案是:进程的当前工作目录里!
Linux 下每个进程都有自己的当前工作目录,我们可以通过 /proc/pid/cwd 来查看:
bash
# 先找到进程ID
ps ajx | grep myProc
# 查看进程的工作目录
ls /proc/533463 -l输出中我们可以看到:
bash
lrwxrwxrwx 1 hyb hyb 0 Aug 26 16:53 cwd -> /home/hyb/io这个 cwd 就是当前进程的工作目录,所以不带路径的文件,默认都会创建在这个目录下。
2.2 默认的三个流
C 程序默认会帮我们打开++三个文件流++ ,这就是我们为什么可以直接用 printf、scanf 的原因:
|----|---|---|-------|-------|-------|----------|
| 模式 | 读 | 写 | 清空原文件 | 从开头操作 | 从末尾追加 | 文件不存在则创建 |
| r | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ |
| r+ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ |
| w | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ |
| w+ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
| a | ❌ | ✅ | ❌ | ❌ | ✅ | ✅ |
| a+ | ✅ | ✅ | ❌ | 读从开头 | 写从末尾 | ✅ |
三、系统 IO
当我们需要更灵活的文件操作时,就会用到系统调用接口,这些接口是内核直接提供的,没有 C 库的封装,更接近底层。
3.1 位运算
在系统调用中,我们经常会看到类似 O_WRONLY|O_CREAT 这样的参数,这是怎么做到一个参数传递多个选项的?
其实这就是位运算的经典用法,用整数的每一位代表一个标志位:
cpp
#include <stdio.h>
#define ONE 0001 // 0000 0001,第0位代表ONE
#define TWO 0002 // 0000 0010,第1位代表TWO
#define THREE 0004 // 0000 0100,第2位代表THREE
void func(int flags) {
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}
int main() {
func(ONE); // 只传ONE
func(THREE); // 只传THREE
func(ONE | TWO); // 同时传ONE和TWO
func(ONE | TWO | THREE); // 三个都传
return 0;
}输出结果:
bash
flags has ONE!
flags has THREE!
flags has ONE! flags has TWO!
flags has ONE! flags has TWO! flags has THREE!通过按位或,我们可以把多个标志位合并成一个整数,然后通过按位与,就可以检查是否包含某个标志,这就是系统调用标志位的实现原理。
3.2 核心接口
系统 IO 的核心接口很简单,open、read、write、close,我们看一个写文件的例子:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
// 只写打开,不存在则创建,权限0644
int fd = open("myfile", O_WRONLY|O_CREAT, 0644);
if(fd < 0){
perror("open");
return 1;
}
int count = 5;
const char *msg = "hello bit!\n";
int len = strlen(msg);
while(count--){
// 向fd对应的文件写入数据
write(fd, msg, len);
}
close(fd);
return 0;
}这里的 fd 就是文件描述符,它是系统 IO 的核心,我们接下来详细讲。
3.3 文件描述符
很多人都知道,文件描述符是一个小整数,那它到底是什么?
Linux 下,每个进程都有一个 files_struct 的结构体,里面有一个数组,这个数组的下标就是文件描述符,数组的内容就是对应的文件的内核对象指针。
而进程默认会打开三个文件,所以这个数组的前三个下标:0、1、2,就被占用了,分别对应我们之前说的标准输入、标准输出、标准错误。
文件描述符的分配规则
当我们打开新文件的时候,系统会在这个数组里,找到当前没有被使用的最小的下标,作为新的文件描述符。
++比如我们关闭了 1(标准输出),然后再打开新文件,那新文件的 fd 就会是 1!++
这就是重定向的本质!
3.4 重定向
我们看这段代码:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1); // 关闭标准输出
// 打开新文件,此时最小的可用下标是1,所以fd=1
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
// 本来要输出到显示器的内容,现在写到了fd=1对应的文件里
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
exit(0);
}运行这段代码,我们会发现,printf 的内容没有输出到屏幕,而是写到了 myfile 文件里,这就是输出重定向!
它的本质就是:修改了文件描述符表中,下标 1 对应的文件指针,从原来的显示器文件,改成了我们的普通文件。
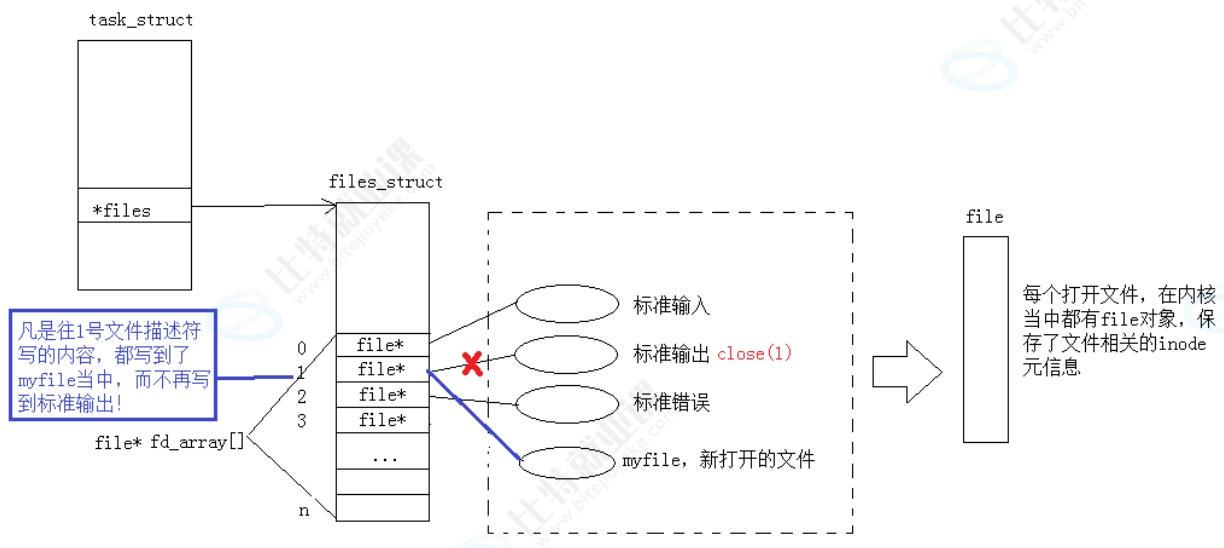
我们平时用的++>、>>、<++这些重定向符号,底层都是这个原理。
四、缓冲区
为什么同样是写文件,C 库的函数比系统调用快这么多?答案就是缓冲区。
4.1 本质:减少系统调用的次数
系统调用的成本是很高的,因为它需要从用户态切换到内核态,这个切换的开销虽然单次很小,但是如果频繁调用,累积起来就会非常大。
而缓冲区的作用,就是先把我们要写的数据,先存在用户态的内存里,等缓冲区满了,或者满足刷新条件的时候,再一次性调用系统调用,把数据写到内核里,这样就大大减少了系统调用的次数。
我们看不同缓冲类型的性能对比:
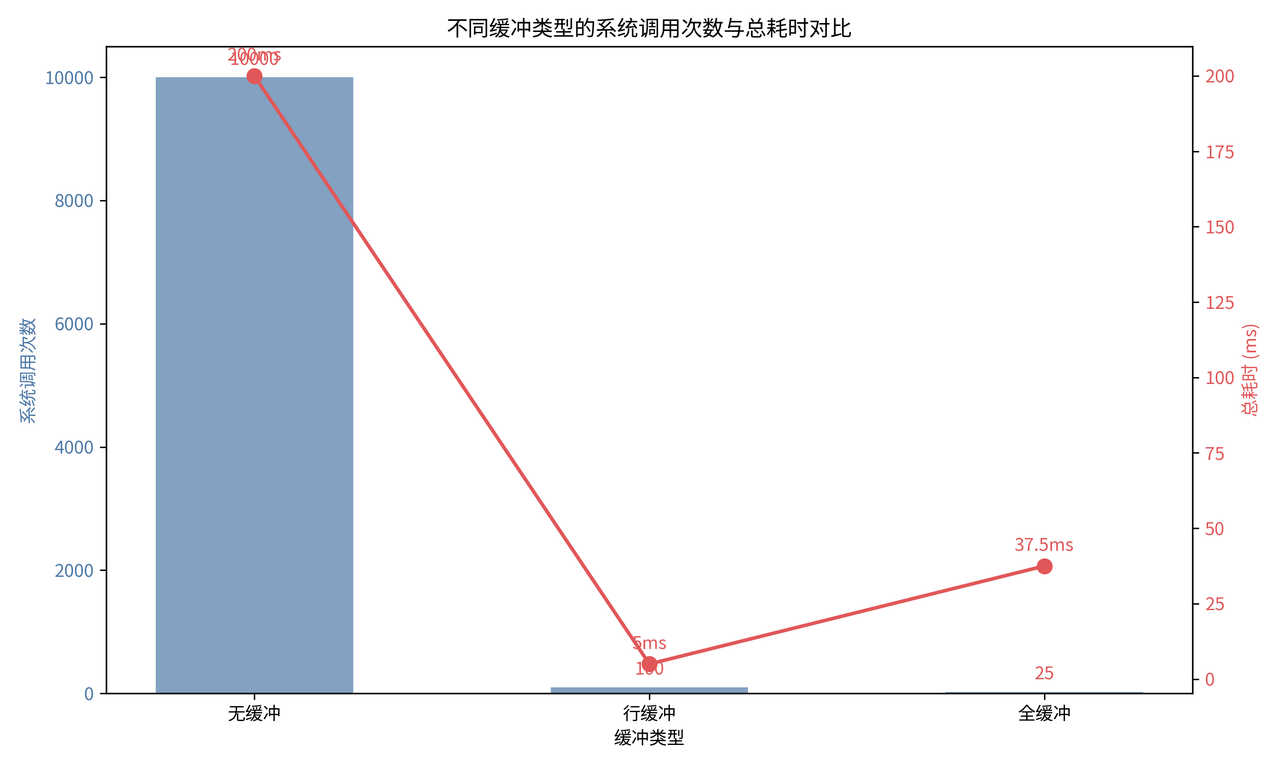
可以看到:
-
无缓冲:每次写都要调用系统调用,10000 次写就有 10000 次系统调用,总耗时 200ms
-
行缓冲:遇到换行就刷新,10000 次写只有 100 次系统调用,总耗时只有 5ms
-
全缓冲:缓冲区满了才刷新,10000 次写只有 25 次系统调用,总耗时 37.5ms
这就是为什么带缓冲的标准 IO,比直接用系统调用快得多!
4.2 刷新时机
缓冲区不是一直存着数据的,它会在这些时机刷新:
-
缓冲区满了:这是全缓冲的默认刷新时机
-
遇到换行符 :这是行缓冲的默认刷新时机,所以我们往显示器输出的时候,printf("hello\n") 会立刻输出
-
程序退出:进程退出的时候,会刷新所有缓冲区
-
手动调用 fflush :我们可以手动调用 fflush 来强制刷新缓冲区
4.3 缓冲区问题:fork 后的重复输出
有一个经典的问题,这段代码的输出是什么?
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello printf\n");
write(1, "hello write\n", 12);
fork();
return 0;
}很多人会以为输出两行,但是实际运行,你会发现:
cpp
hello write
hello printf
hello printfprintf 的内容输出了两次,而 write 的只输出了一次!
这就是缓冲区的原因:
-
write 是系统调用,没有用户态缓冲区,所以数据直接写到了内核,fork 的时候,父子进程共享这个已经写入的数据,所以只会输出一次
-
printf 是库函数,有用户态缓冲区,数据还在用户态的缓冲区里,没有刷新。fork 的时候,父子进程会拷贝这个缓冲区,所以父子进程退出的时候,都会刷新一次,就输出了两次!
当我们把输出重定向到文件的时候,这个现象会更明显,因为重定向后,stdout 的缓冲方式从行缓冲变成了全缓冲,数据不会因为换行而刷新,就会更明显的看到这个问题。
五、模拟 C 库的标准 IO
理解了缓冲区的原理,我们其实可以自己实现一个简化版的 C 库标准 IO,来彻底搞懂它的本质。
首先我们定义自己的 FILE 结构体:
cpp
// my_stdio.h
#define SIZE 1024
#define FLUSH_NONE 0
#define FLUSH_LINE 1
#define FLUSH_FULL 2
typedef struct _IO_FILE
{
int fileno; // 对应的文件描述符
int flag; // 缓冲类型
char outbuffer[SIZE]; // 缓冲区
int size; // 缓冲区当前已经使用的大小
int cap; // 缓冲区的总容量
}mFILE;
mFILE *mfopen(const char *filename, const char *mode);
int mfwrite(const void *ptr, int num, mFILE *stream);
void mfflush(mFILE *stream);
void mfclose(mFILE *stream);然后我们实现这些接口:
cpp
// my_stdio.c
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
mFILE *mfopen(const char *filename, const char *mode)
{
int fd = -1;
if(strcmp(mode, "r") == 0)
{
fd = open(filename, O_RDONLY);
}
else if(strcmp(mode, "w")== 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_TRUNC, 0666);
}
else if(strcmp(mode, "a") == 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_APPEND, 0666);
}
if(fd < 0) return NULL;
// 分配我们自己的FILE结构体
mFILE *mf = (mFILE*)malloc(sizeof(mFILE));
if(!mf)
{
close(fd);
return NULL;
}
mf->fileno = fd;
mf->flag = FLUSH_LINE; // 默认行缓冲
mf->size = 0;
mf->cap = SIZE;
return mf;
}
// 刷新缓冲区
void mfflush(mFILE *stream)
{
if(stream->size > 0)
{
// 把缓冲区的数据一次性写到内核
write(stream->fileno, stream->outbuffer, stream->size);
// 强制刷新到磁盘
fsync(stream->fileno);
stream->size = 0;
}
}
// 我们自己的写函数
int mfwrite(const void *ptr, int num, mFILE *stream)
{
// 1. 先把数据拷贝到我们的缓冲区
memcpy(stream->outbuffer+stream->size, ptr, num);
stream->size += num;
// 2. 检查是否需要刷新
if(stream->size == stream->cap)
{
// 缓冲区满了,全缓冲刷新
mfflush(stream);
}
else if(stream->flag == FLUSH_LINE)
{
// 行缓冲,检查有没有换行
if(strchr(ptr, '\n') != NULL)
{
mfflush(stream);
}
}
return num;
}
void mfclose(mFILE *stream)
{
mfflush(stream); // 关闭前先刷新缓冲区
close(stream->fileno);
free(stream);
}你看,我们自己实现的这个标准 IO,是不是和 C 库的逻辑一模一样?这就是标准 IO 的本质:在用户态加了一层缓冲区,封装了系统调用,帮我们自动管理刷新时机。
六、标准 IO vs 系统 IO
我们做了一组测试,在不同的缓冲区大小下,对比标准 IO 和系统 IO 的拷贝性能:
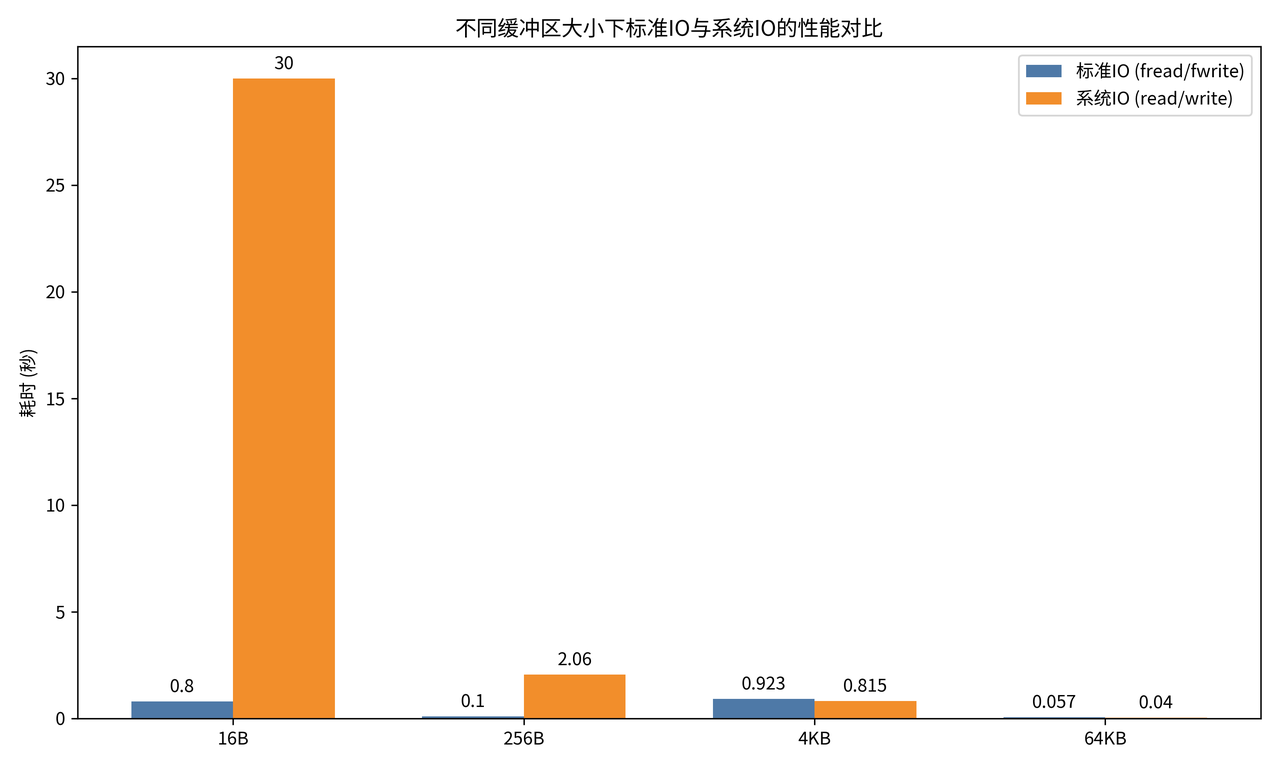
我们可以看到非常明显的差异:
-
小缓冲区场景(比如 16B):系统 IO 的耗时高达 30 秒,而标准 IO 只需要 0.8 秒,差距达到了 37.5 倍!这是因为小缓冲区下,系统 IO 会频繁调用系统调用,而标准 IO 的缓冲区把这些调用合并了。
-
大缓冲区场景(比如 64KB):两者的差距变得很小,系统 IO 甚至略快一点,因为这时候系统调用的次数已经很少了,标准 IO 的缓冲区反而多了一次用户态的拷贝。
这也告诉我们:
-
平时小数据量的零散写,用标准 IO 就好,它的缓冲会帮我们优化性能
-
如果我们自己已经做了大缓冲区的批量操作,那用系统 IO 也可以,性能差距不大
七、总结
Linux 基础 IO 看似简单,实则贯穿了操作系统的核心设计逻辑,其底层每一个细节都围绕**"高效、安全、易用"**三大目标展开,核心设计要点可总结为四点:
-
用户态与内核态:保障了系统安全,同时也带来了系统调用的固有开销,这也是 IO 优化的核心出发点;
-
缓冲区的:通过"批量合并系统调用",有效减少了用户态与内核态的切换次数,大幅提升了 IO 操作的整体性能;
-
文件描述符:将所有设备、文件统一封装为整数下标,让重定向、文件管理等操作变得简洁高效,是 Linux"一切皆文件"思想的核心体现;
-
库函数对系统调用:屏蔽了底层复杂的内核交互细节,降低了开发门槛,让开发者无需关注内核逻辑即可快速实现 IO 操作。
吃透这些底层逻辑,于编写高效、健壮的系统程序至关重要。希望本文能够帮助读者深入理解这些核心概念,并在实际开发中灵活运用。
当然,Linux 的 IO 体系远不止于此,后续还有直接 IO、异步 IO、io_uring 等进阶方向等待探索,但基础 IO 是所有进阶内容的根基------唯有夯实基础,才能在 Linux 开发的道路上走得更稳、更远!!!!
参考资料
1 书籍:《Linux内核设计与实现》(Robert Love 著),书中第12章详细讲解了 Linux IO 子系统的架构、文件描述符的管理及内核缓冲区的实现原理,是理解 Linux 基础 IO 底层逻辑的核心参考
2 官方手册:man 手册(man 2 open、man 2 read、man 2 write、man 3 fopen),详细说明了系统调用与标准 IO 库函数的参数、返回值及使用规范,是实际开发中的必备参考。
3 书籍:《UNIX环境高级编程》(W. Richard Stevens 著),第3章至第5章深入讲解了标准 IO 与系统 IO 的区别、缓冲区机制及文件操作的最佳实践,补充了基础 IO 的实际应用场景。
4 【Linux指南】基础IO系列(三):Linux 系统 IO 接口 ------ 深入内核的文件操作_linux文件操作符-CSDN博客
5 【Linux指南】基础IO系列(三):Linux 系统 IO 接口 ------ 深入内核的文件操作_linux文件操作符-CSDN博客