(一).基础概念
前面我们介绍完了应用层的HTTP和HTTPS协议。事实上,应用层的很多操作,都是调用传输层提供的接口的,这个接口就是 socket api(网络套接字),这个也在前面介绍过。TCP是依靠 ServerSocket 和 Socket;UDP是依靠 DatagramSocket 和 DatagramPacket
下面主要先介绍UDP,TCP后面再介绍
(二).UDP
1.概念
UDP是无连接,不可靠,面向数据报,全双工传输
在写UDP套接字代码的时候,我们知道,UDP不像TCP一样有一个accept()方法来建立连接,而是直接获取对端的ip地址和端口号然后直接传输,这就是无连接。
对于"不可靠",套接字代码中不容易体现出来,其实就是将数据发送出去就不管了。
对于"面向数据报",我们知道,UDP在传输数据的时候,都是以一个DatagramPacket数据报为单位进行传输的。
"全双工传输",意味着客户端和服务器都可以进行接收和发送数据,在套接字代码中也有具体的体现。
2.UDP协议报文格式
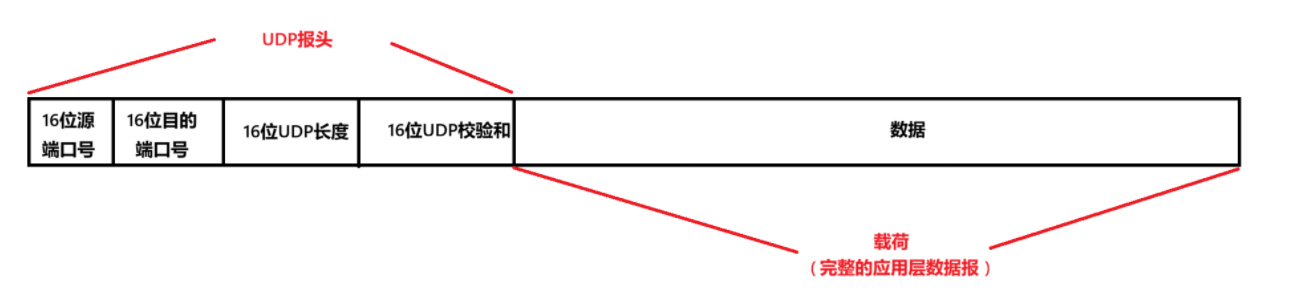
首先要明确,UDP报头分为四个部分,每个部分占两个字节,也就是16个bit位
UDP的报头和HTTP的报头格式不同,HTTP的报头格式为文本格式的,UDP的报头格式为二进制的。包括后面介绍到的TCP以及IP协议的报头也都是二进制格式的
整个UDP数据报就相当于UDP报头+载荷,构建的过程就相当于一个简单的字符串拼接
(1).源端口号和目的端口号
源端口号和目的端口号都是各占两个字节,16个bit位。所以一个端口号的取值范围为 0~65535,事实上,一般会把1024以下的端口号保留。我们使用的端口号都是 1024~65535这个范围的,如果使用的端口号超过了65535,则会判定为非法端口号
(2).UDP长度
UDP长度的范围也是16个bit位,范围也是0~65535,表示的是 UDP报头+载荷 的长度,UDP报头固定是8个字节。对于65535字节,换算过来就是大约为64kb。64kb在互联网发展的早期当时已经很充裕了,但是现在是一个非常小的数字,现在随便一个图片都几个MB,所以就会出现新的问题,如何传输一个大的数据?
方案1:在应用层进行拆包操作。将一个大的应用层数据包拆成多个小的数据报,然后使用多个UDP数据报传输。这需要我们写大量的逻辑,实现分包拆包的功能,并且需要进行复杂的验证,因为按照某个顺序拆包之后,还要按照某个顺序进行组包。
方案2:使用TCP协议进行传输,TCP协议没有数据包长度的限制
(3).校验和
"校验和"是验证数据是否发生修改的手段
UDP的校验和 和 HTTPS的数字签名不同。HTTPS的数字签名是为了防止黑客篡改数据的,也就是说"防人"的;UDP的校验和,不是为了防人的,UDP的校验和 与安全性无关,而是为了防止数据传输的过程中,出现"比特翻转"的。"比特翻转"就是,数据在传输的过程中,是以电信号,光信号,电磁波进行传输的,如果收到外界的干扰,可能会使高低电平/高低频光信号发生改变,即 0变1或1变0
校验和的工作原理
数据在发送之前,先计算一个校验和,把整个数据报的数据全部代入。然后把数据和校验和一起发送给对端。接收方收到之后重新计算一个校验和,然后和收到的校验和进行对比,如果两个校验和的值不一样,则UDP会直接丢弃该数据报
UDP的在计算校验和的时候,采用的使CRC方式来进行校验,即循环冗余校验。把除了校验和为止的部分之外的每个字节都当作整数,进行累加,即使溢出了也没有关系,继续累加,最终得到结果。在传输的过程中,如果数据出现错误了,对端在再次计算校验和后,进行比较就会知道和第一个校验和不一样,从而丢弃数据报了
注意:其实上面的逻辑是有错误的。
如果两个原始数据相同,则使用相同的校验和算法,算出的校验和也是相同的;
如果两个校验和相同,则原始数据不一定相同!
例如:前一个字节出现了bit翻转,刚好小了1,后一个字节出现了bit翻转,刚好大了1.那么最终算的校验和也是一样的
只不过,在工程上出现这样的概率很小,可以忽略不计
站在UDP的角度,如果发现校验和不对,只会将该数据报丢弃,不会触发重传的动作。如果想要重传,要么使用TCP,要么在应用层代码中自己实现重传机制