
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [1 ~> 总结](#1 ~> 总结)
- [2 ~> 完整思维导图](#2 ~> 完整思维导图)
- [3 ~> 展开总结](#3 ~> 展开总结)
-
- [3.1 导入](#3.1 导入)
- [3.2 HTTP 协议基础认知](#3.2 HTTP 协议基础认知)
-
- [3.2.1 定义与超文本的含义](#3.2.1 定义与超文本的含义)
- [3.2.2 核心特性](#3.2.2 核心特性)
- [3.2.3 底层通信基础](#3.2.3 底层通信基础)
- [3.2.4 通信模式](#3.2.4 通信模式)
- [3.3 核心概念详解](#3.3 核心概念详解)
-
- [3.3.1 URI 与 URL 的区别与关系](#3.3.1 URI 与 URL 的区别与关系)
- [3.3.2 域名与域名解析](#3.3.2 域名与域名解析)
- [3.3.3 两类 DNS 服务的详细区分](#3.3.3 两类 DNS 服务的详细区分)
-
- [3.3.3.1 域名解析服务对比表](#3.3.3.1 域名解析服务对比表)
- [3.3.3.2 核心重点标注](#3.3.3.2 核心重点标注)
- [3.4 URL 结构与编码规则](#3.4 URL 结构与编码规则)
-
- [3.4.1 URL 的完整结构](#3.4.1 URL 的完整结构)
- [3.4.2 全网资源唯一性原理](#3.4.2 全网资源唯一性原理)
- [3.4.3 上网行为的本质](#3.4.3 上网行为的本质)
- [3.4.4 URL 编码与解码(Encode/Decode)](#3.4.4 URL 编码与解码(Encode/Decode))
- [3.5 HTTP 请求格式](#3.5 HTTP 请求格式)
-
- [3.5.1 格式规范](#3.5.1 格式规范)
- [3.5.2 请求的组成部分](#3.5.2 请求的组成部分)
- [3.5.3 实际 HTTP 请求示例](#3.5.3 实际 HTTP 请求示例)
- [3.6 HTTP 服务器实践开发](#3.6 HTTP 服务器实践开发)
-
- [3.6.1 核心开发思路](#3.6.1 核心开发思路)
- [3.6.2 完整的文件结构](#3.6.2 完整的文件结构)
- [3.6.3 核心代码逻辑](#3.6.3 核心代码逻辑)
- [3.6.4 编译、运行与测试](#3.6.4 编译、运行与测试)
- [3.6.5 学习与建议](#3.6.5 学习与建议)
- [4 ~> 核心问题与完整答案](#4 ~> 核心问题与完整答案)
- [5 ~> 思维导图](#5 ~> 思维导图)
- 结尾

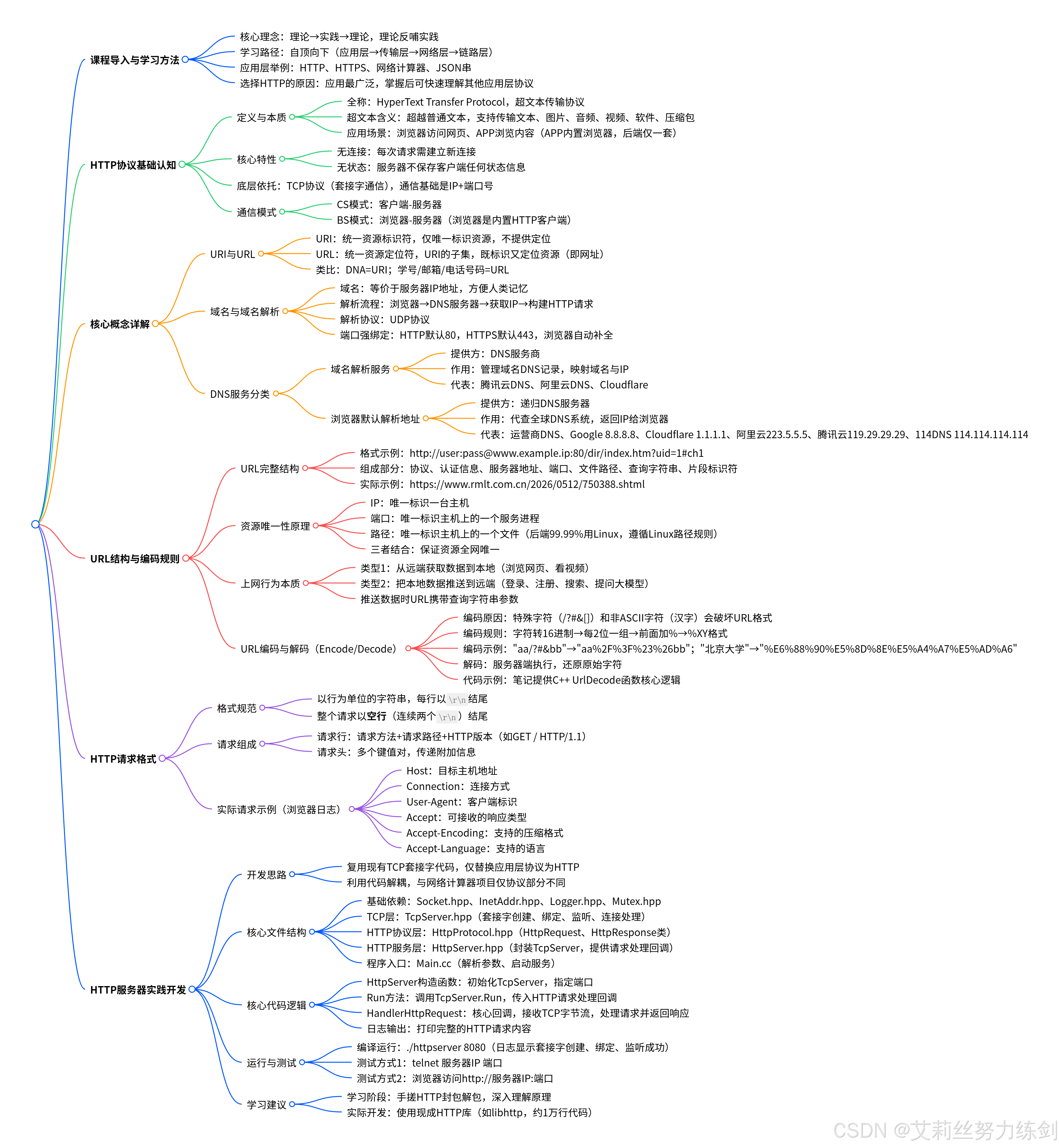
1 ~> 总结
本文以自顶向下 的网络学习方法和 "理论 - 实践 - 理论" 的循环理念为指导,聚焦互联网应用最广泛的应用层超文本传输协议 HTTP,明确其基于 TCP 套接字通信、无连接无状态的核心特性,以及 CS/BS 两种通信模式(BS 模式下浏览器为内置 HTTP 客户端,多数 APP 本质也是包裹浏览器实现);详细厘清 URI 与 URL 的从属关系(URL 是 URI 的最常见子集)及类比解释,完整讲解域名解析的流程、依赖的 UDP 协议、HTTP 默认 80 端口与 HTTPS 默认 443 端口的强绑定规则,并分类说明两类 DNS 服务的提供方、作用与常见代表;拆解 URL 的完整结构与 "IP + 端口 + 路径" 的全网资源唯一性原理,指出上网行为本质是 "从远端获取数据" 和 "向远端推送数据" 两类,深入解释 URL 编码 / 解码的原因、具体规则与执行主体;通过实际日志展示 HTTP 请求以\r\n为行分隔、空行结尾的格式规范,以及请求行 + 请求头的组成;最后给出基于现有 TCP 套接字代码手写 HTTP 服务器的完整开发思路、核心文件结构、代码逻辑与测试方法,并提出 "学习阶段手搓理解原理,实际开发使用现成库(如 libhttp)" 的建议。
2 ~> 完整思维导图
3 ~> 展开总结
3.1 导入
1、核心学习理念:理论上升到实践,再把实践转换成理论,理论再反哺实践,强调动手实践对理解网络协议的重要性。
2、网络学习路径:采用自顶向下的方法,从最贴近开发者的应用层开始,逐步深入到传输层、网络层、链路层。
3、应用层协议举例:除了 HTTP、HTTPS,网络版本计算器、JSON 串的传输也都属于应用层范畴。
4、选择 HTTP 的原因:它是互联网中应用最广泛的应用层协议,掌握 HTTP 的原理和设计思路后,能够快速理解其他所有应用层协议。
3.2 HTTP 协议基础认知
3.2.1 定义与超文本的含义
- HTTP 全称是 HyperText Transfer Protocol,即超文本传输协议。
- "超文本" 不是指普通的文本,而是超越文本的所有网络资源,包括文字、图片、音频、视频、可下载软件、压缩包等。
- 应用场景:不仅浏览器访问网页使用 HTTP,绝大多数 APP 浏览内容也使用 HTTP------ 因为 APP 内部本质是包裹了一个浏览器内核,很多公司后端只需要维护一套服务即可同时支持网页端和 APP 端。
3.2.2 核心特性
- 无连接:每次客户端向服务器发送请求时,都需要建立一个新的 TCP 连接,请求处理完成后连接就会关闭。
- 无状态:服务器不会保存任何客户端的状态信息,每次请求都是独立的,服务器无法区分两次请求是否来自同一个客户端。
3.2.3 底层通信基础
- HTTP 底层完全基于TCP 协议实现,本质就是 TCP 套接字通信。
- 网络通信的基础是IP 地址 + 端口号:IP 地址唯一标识互联网中的一台主机,端口号唯一标识主机上的一个服务进程。
3.2.4 通信模式
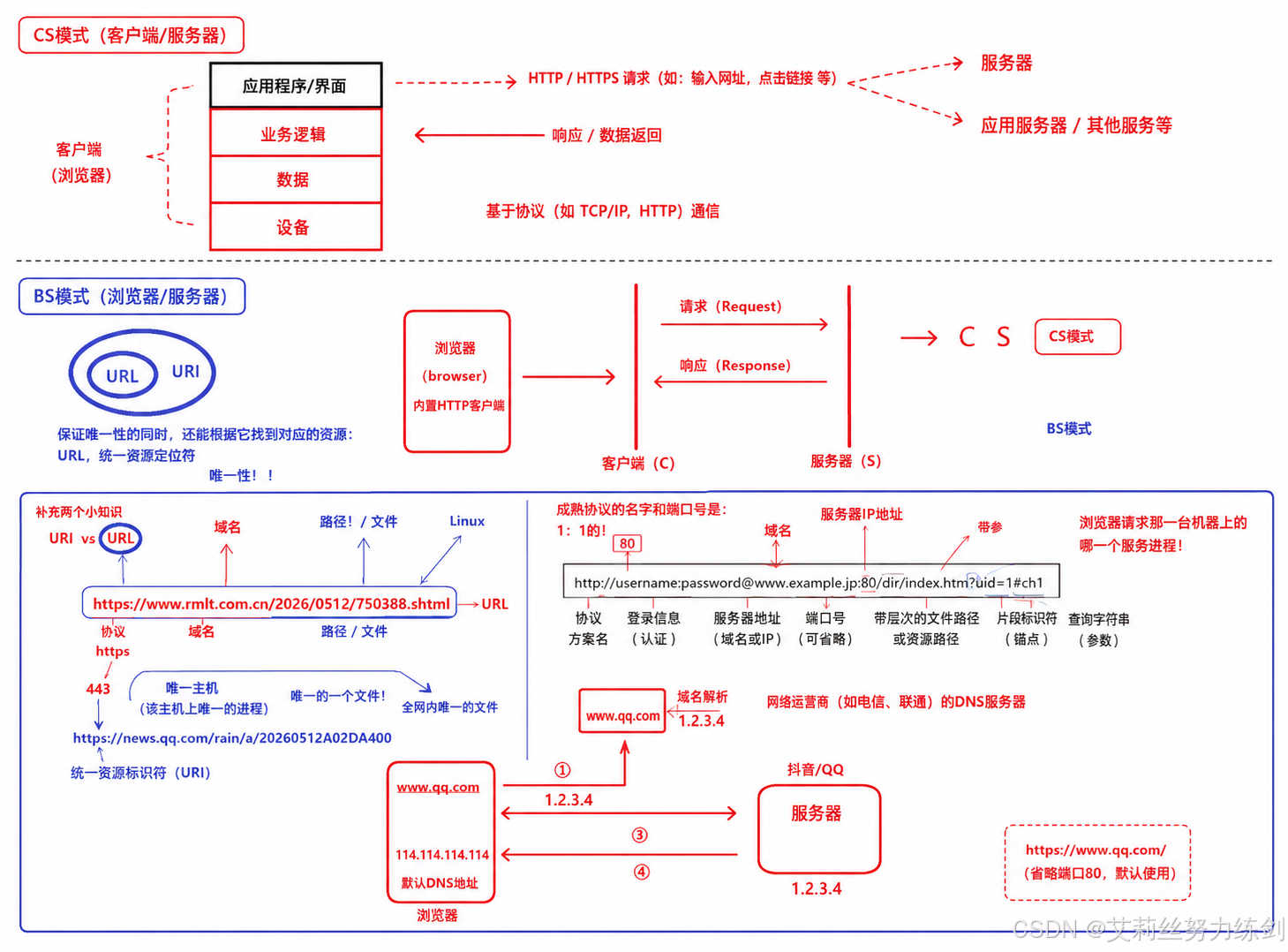
- CS 模式:即 Client-Server(客户端 - 服务器)模式,需要单独开发客户端和服务器程序。
- BS 模式 :即 Browser-Server(浏览器 - 服务器)模式,浏览器本身就是一个内置的 HTTP 客户端,因此开发者只需要开发服务器端即可,无需单独开发客户端。
3.3 核心概念详解
3.3.1 URI 与 URL 的区别与关系
- URI :全称
Uniform Resource Identifier,统一资源标识符。它的作用仅仅是唯一标识一个网络资源,但不提供如何找到这个资源的信息。 - URL :全称
Uniform Resource Locator,统一资源定位符。它是URI 的最常见的一种形式,也就是我们日常所说的 "网址"。URL 不仅能唯一标识资源,还能明确告诉我们 "这个资源在哪里" 以及 "如何访问它"。
类比理解:
- DNA 可以唯一标识一个人,但你无法通过 DNA 直接找到这个人,所以 DNA 相当于 URI;
- 学号、邮箱、电话号码既可以唯一标识一个人,又可以通过这些信息找到对应的人,所以它们相当于 URL。
3.3.2 域名与域名解析
- 域名的本质:域名等价于服务器的 IP 地址,只是为了方便人类记忆而设计的字符串。
- 完整的域名解析流程:
- 用户在浏览器中输入域名(如腾讯网);
- 浏览器不会直接访问域名,而是自动向 DNS 服务器发起域名解析请求;
- DNS 服务器返回该域名对应的 IP 地址(如 1.2.3.4);
- 浏览器使用这个 IP 地址构建 HTTP 请求,访问目标服务器;
- 服务器处理请求并返回响应给浏览器。
- 解析协议:域名解析使用UDP 协议进行通信。
- 端口号的强绑定:成熟的网络协议和端口号是一一对应的,就像 "110" 和 "警察" 强绑定一样。其中,HTTP 协议默认使用 80 端口,HTTPS 协议默认使用 443 端口。当 URL 中省略端口号时,浏览器会自动根据协议补全对应的默认端口。
3.3.3 两类 DNS 服务的详细区分
3.3.3.1 域名解析服务对比表
| 服务类型 | 服务提供方 | 核心作用 | 面向用户 | 常见代表 / 地址 |
|---|---|---|---|---|
| 域名解析服务 | DNS 服务商 | 管理域名的 DNS 记录,负责回答 "这个域名对应哪个 IP" | 网站管理员(购买、管理域名时使用) | 腾讯云 DNS、阿里云 DNS、Cloudflare 等 |
| 浏览器默认解析地址 | 递归 DNS 服务器 | 替普通用户 "跑腿",向全球 DNS 系统查询结果并返回给浏览器 | 普通上网用户(设备后台自动请求) | 8.8.8.8 (Google)、114.114.114.114、223.5.5.5 (阿里) |
3.3.3.2 核心重点标注
-
权责区分:
- 域名解析服务(Authoritative DNS):你是"房东",在这里登记你的房子(域名)在哪里。
- 递归 DNS(Recursive DNS):它是"快递员",帮上网的人去查房东的登记信息。
-
配置场景:
- 如果你是站长 ,你应该在域名后台配置
DNS 服务商给你的服务器地址。 - 如果你是普通用户 ,网速慢或打不开网页时,你应该在电脑/路由器设置里更换
递归 DNS 地址(如 8.8.8.8)。
- 如果你是站长 ,你应该在域名后台配置
域名解析服务 (Authoritative DNS):是网站所有者使用的,决定了别人访问你的域名时指向哪里。
递归 DNS (Recursive DNS):是上网终端(电脑/手机)使用的,它是帮你去询问全球记录并反馈结果的"中转站"。
3.4 URL 结构与编码规则

3.4.1 URL 的完整结构
- 标准格式:
协议://[认证信息@]服务器地址[:端口号]/文件路径[?查询字符串][#片段标识符] - 完整示例:
http://user:pass@www.example.ip:80/dir/index.htm?uid=1#ch1 - 各部分说明:
- 协议:指定使用的应用层协议,如 http、https;
- 认证信息:可选,用于登录验证,格式为用户名:密码@;
- 服务器地址:可以是域名或 IP 地址;
- 端口号:可选,省略时使用协议默认端口;
- 文件路径:服务器上资源的路径,遵循 Linux 文件系统规则;
- 查询字符串:可选,以?开头,多个参数用&分隔,用于向服务器传递数据;
- 片段标识符:可选,以#开头,用于定位页面内的特定位置。
- 实际使用示例:
https://www.rmlt.com.cn/2026/0512/750388.shtml

3.4.2 全网资源唯一性原理
- IP 地址:唯一标识互联网中的一台主机;
- 端口号:唯一标识该主机上的一个服务进程;
- 文件路径:唯一标识该进程管理的一个文件(后端服务器 99.99% 使用 Linux 系统,Linux 下一切皆文件);
- 三者结合,就可以唯一标识互联网中的任何一个资源。
3.4.3 上网行为的本质
- 所有的上网行为本质上都是进程间通信 ,可以分为两类:
- 从远端获取数据到本地:如浏览网页、看视频、下载文件等;
- 把本地数据推送到远端:如登录账号、注册用户、搜索内容、向大模型提问等。
- 当需要向服务器推送数据时,URL 中通常会携带查询字符串参数。
3.4.4 URL 编码与解码(Encode/Decode)
- 为什么需要编码:URL 中已经定义了
/?#&[]等字符作为格式分隔符,如果查询参数中包含这些特殊字符,或者包含汉字等非 ASCII 字符,就会干扰 URL 的正常解析,导致服务器无法正确识别参数。 - 具体编码规则:
- 将需要转码的字符转换为对应的 16 进制数值;
- 从右到左取 4 位(不足 4 位直接处理),每 2 位分为一组;
- 在每组前面加上百分号%,最终编码为%XY的格式。
- 编码示例:
- 搜索关键词
aa/?#&bb会被浏览器自动编码为aa%2F%3F%23%26bb; - 搜索关键词
北京大学会被编码为%E6%88%90%E5%8D%8E%E5%A4%A7%E5%AD%A6。
- 搜索关键词
- 解码:编码由浏览器自动执行,解码工作由服务器端完成 ,服务器需要将
%XY格式的编码还原为原始字符。 - 代码示例:笔记中提供了 C++ 实现的
UrlDecode函数核心逻辑,通过遍历字符串,识别%字符并将后续两位十六进制数转换为原始字符。
3.5 HTTP 请求格式
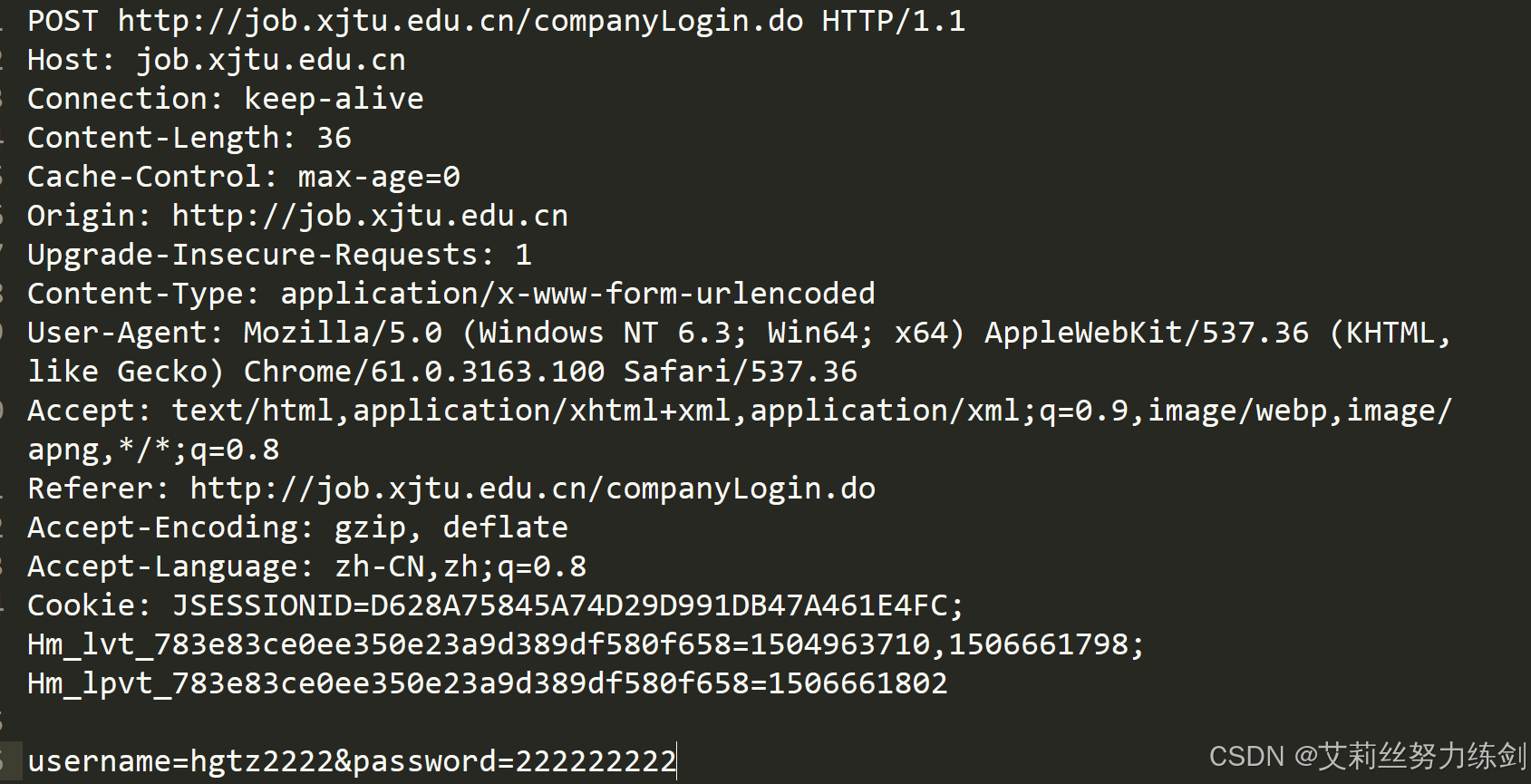
- 首行:
[方法] + [url] + [版本]; - Header:请求的属性,冒号分割的键值对;每组属性之间使用
\r\n分隔;遇到空行表示Header部分结束; - Body:空行后面的内容都是Body.Body允许为空字符串,如果Body存在,则在Header中会有一个
Content-Length属性来标识Body的长度。
3.5.1 格式规范
- HTTP 请求是一个纯文本格式的字符串,以行为单位进行组织;
- 每一行的结尾都是
\r\n(回车换行符); - 整个请求的最后以一个空行 (即连续两个
\r\n)结尾,表示请求头结束。
3.5.2 请求的组成部分
- 请求行 :是 HTTP 请求的第一行,包含三个部分:请求方法、请求路径、HTTP 协议版本。例如:
GET / HTTP/1.1。 - 请求头:从第二行开始到空行结束,由多个键值对组成,每个键值对占一行,用于向服务器传递请求的附加信息。
3.5.3 实际 HTTP 请求示例
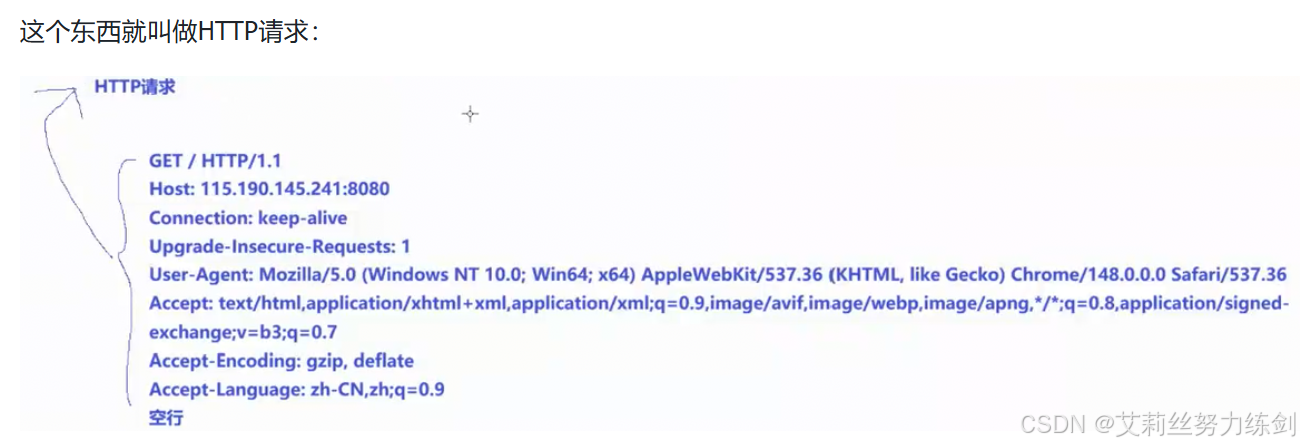
这个请求是以行为单位的字符串,整个都是以\r\n为结尾的,最后以空行结尾,所以HTTP是有自己的格式的。
bash
GET / HTTP/1.1
Host: 115.190.145.241:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
(空行)常见请求头说明:
Host:目标服务器的地址和端口号;Connection:指定连接方式,如keep-alive表示保持连接;User-Agent:客户端的标识信息,包括浏览器类型、版本、操作系统等;Accept:客户端能够接收的响应内容类型;Accept-Encoding:客户端支持的压缩格式;Accept-Language:客户端支持的语言。
HTTP的请求是如何序列化的应答又是如何反序列化的?
3.6 HTTP 服务器实践开发
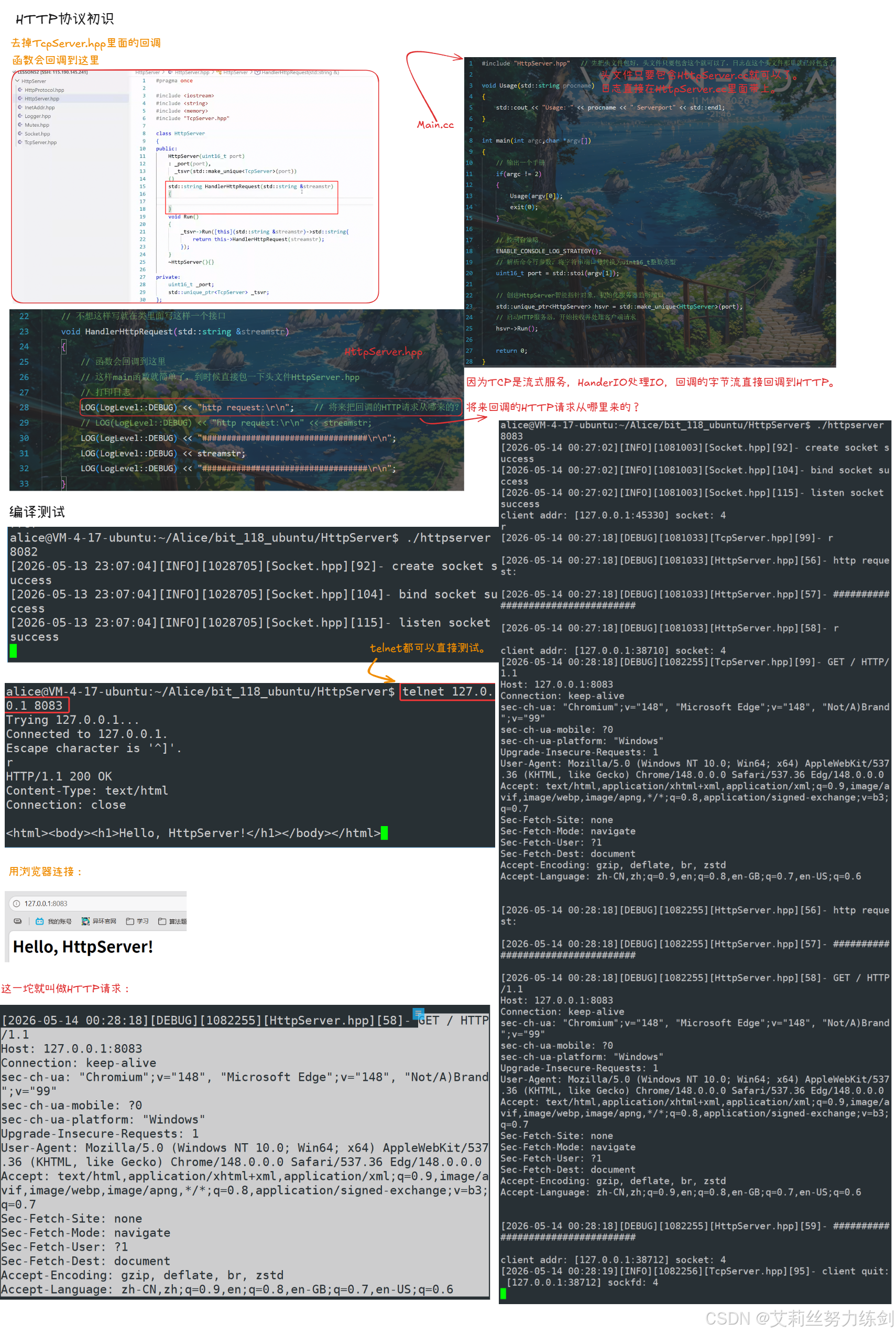
3.6.1 核心开发思路
- 由于 HTTP 底层基于 TCP 协议,因此可以完全复用之前开发的 TCP 套接字代码,只需要将应用层的协议处理部分替换为 HTTP 协议即可。
- 这体现了代码解耦的优势:与之前的网络计算器项目相比,仅仅是应用层协议不同,底层的 TCP 通信代码完全不需要修改。
3.6.2 完整的文件结构
- 基础依赖文件(直接复用之前的代码,无需修改):
Socket.hpp:封装了套接字的创建、关闭等操作;InetAddr.hpp:封装了网络地址的表示和操作;Logger.hpp:日志模块,用于输出调试和运行信息;Mutex.hpp:互斥锁模块,用于保证线程安全。
- TCP 层文件:
TcpServer.hpp,实现了 TCP 服务器的基础功能,包括套接字绑定、监听、接受连接、处理客户端数据等。 - HTTP 协议层文件:
HttpProtocol.hpp,定义了HttpRequest(HTTP 请求)和HttpResponse(HTTP 响应)两个类,用于封装请求和响应数据。
cpp
#ifndef __HTTPSERVER_HPP
#define __HTTPSERVER_HPP
// HTTP协议底层就是TCP协议
// 也需要请求和应答
class HttpRequest
{};
class HttpResponse
{};
#endif- HTTP 服务层文件:
HttpServer.hpp,封装了TcpServer,提供了 HTTP 服务器的对外接口,并定义了 HTTP 请求的处理回调函数。 - 程序入口文件:
Main.cc,负责解析命令行参数(获取端口号),创建HttpServer实例并启动服务。
cpp
#include "HttpServer.hpp" // 先把头文件包好,头文件只要包含这个就可以了,日志在这个头文件那里就已经包含了
void Usage(std::string procname)
{
std::cout << "Usage: " << procname << " Serverport" << std::endl;
}
int main(int argc,char *argv[])
{
// 输出一个手册
if(argc != 2)
{
Usage(argv[0]);
exit(0);
}
// 控制台策略
ENABLE_CONSOLE_LOG_STRATEGY();
// 解析命令行参数,将字符串端口号转换为uint16_t整数类型
uint16_t port = std::stoi(argv[1]);
// 创建HttpServer智能指针对象,初始化服务器监听端口
std::unique_ptr<HttpServer> hsvr = std::make_unique<HttpServer>(port);
// 启动HTTP服务器,开始接收并处理客户端请求
hsvr->Run();
return 0;
}3.6.3 核心代码逻辑
HttpServer构造函数:接收端口号作为参数,初始化内部的TcpServer实例。
cpp
HttpServer(uint16_t port)
: _port(port),
_tsvr(std::make_unique<TcpServer>(port))
{}Run方法:调用TcpServer的Run方法,并传入一个 lambda 表达式作为回调函数。当 TCP 服务器接收到客户端的数据时,会自动调用这个回调函数,将数据交给 HTTP 层处理。
cpp
void Run()
{
_tsvr->Run();
}HandlerHttpRequest方法:这是 HTTP 请求处理的核心函数,接收 TCP 服务器传递过来的字节流,解析为 HTTP 请求,处理后返回 HTTP 响应字符串。笔记中在这个函数中添加了日志输出,用于打印完整的 HTTP 请求内容,方便调试。
cpp
void HandlerHttpRequest(std::string &streamstr)
{
// 函数会回调到这里
// 这样main函数就简单了,到时候直接包一下头文件HttpServer.hpp
// 打印日志
LOG(LogLevel::DEBUG) << "http request:\r\n"; // 将来把回调的HTTP请求从哪来的?
// LOG(LogLevel::DEBUG) << "http request:\r\n" << streamstr;
LOG(LogLevel::DEBUG) << "##################################\r\n";
LOG(LogLevel::DEBUG) << streamstr;
LOG(LogLevel::DEBUG) << "##################################\r\n";
}3.6.4 编译、运行与测试
- 编译运行:在 Linux 终端中执行
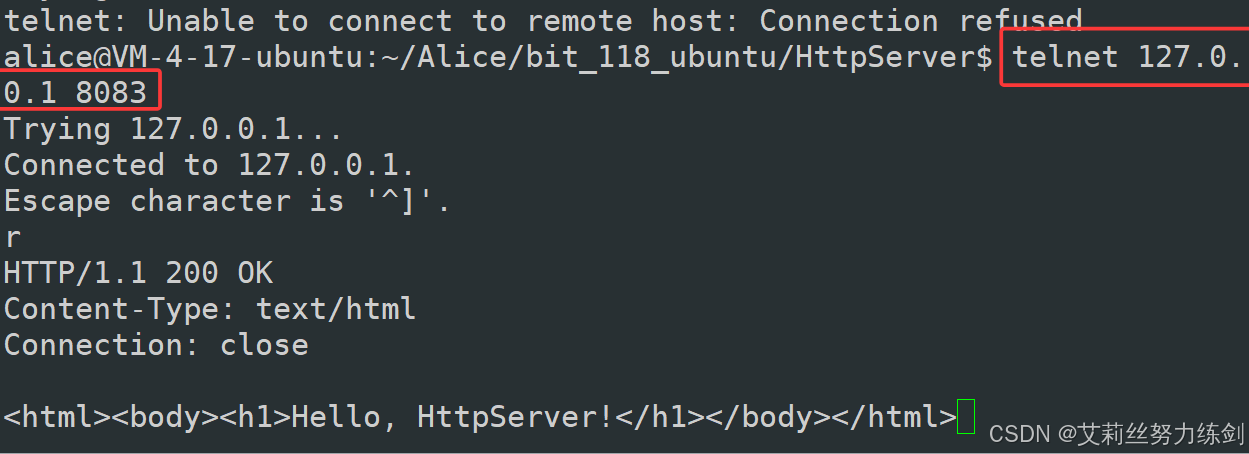
./httpserver 8080,启动 HTTP 服务器,监听 8080 端口。启动成功后,日志会依次显示 "create socket success"、"bind socket success"、"listen socket success"。 - 测试方式 1 :使用telnet工具测试,执行
telnet 115.190.145.241 8080,手动输入 HTTP 请求内容。
- 测试方式 2 :使用浏览器测试,在地址栏输入
http://115.159.25.17:8082,服务器会在日志中打印出浏览器发送的完整 HTTP 请求。
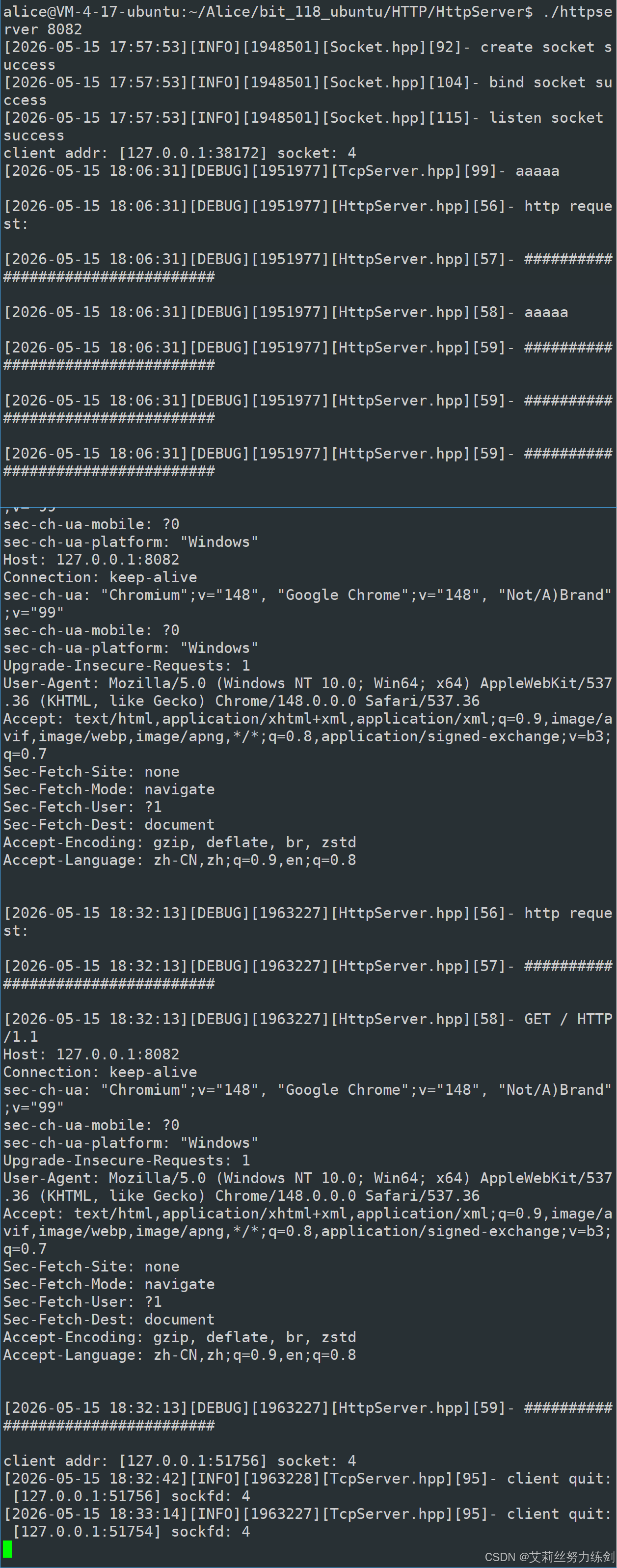
这里并没有给别人应答,所以客户端在应用上会有重传机制,给我很多次回应。
- 测试方式 3 :使用浏览器测试,在地址栏输入
http://127.0.0.1:8083
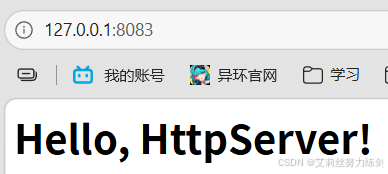
3.6.5 学习与建议
- 学习阶段:建议手动实现 HTTP 协议的封包和解包逻辑,只有亲手写一遍,才能真正理解 HTTP 协议的格式和原理。
- 实际开发:不需要自己从头实现 HTTP 协议,可以使用现成的开源 HTTP 库,例如
libhttp,这个库非常轻量,通篇只有约 1 万行代码。
4 ~> 核心问题与完整答案
问题 1:为什么说 "应用层协议是程序员自己定的",但我们还要学习 HTTP 协议?
答案:从理论上来说,应用层协议不需要操作系统内核支持,完全可以由开发者根据自己的需求自定义。但早在 90 年代,行业前辈们已经定义了很多非常实用、经过验证的应用层协议,HTTP 就是其中最成功的一个。学习这些成熟的协议,可以避免重复造轮子,同时掌握通用的应用层协议设计思路,能够快速开发出稳定、高效的网络应用。
问题 2:为什么 HTTP 协议是无状态的?这会带来什么问题?
答案:HTTP 协议设计为无状态,是为了简化服务器的实现,提高服务器的并发处理能力 ------ 服务器不需要为每个客户端维护状态信息,每个请求都是独立处理的。这带来的问题是,服务器无法区分不同的客户端,也无法记住客户端的历史操作,例如用户登录状态无法自动保留。后续的 Cookie、Session 等技术就是为了解决 HTTP 无状态的问题而出现的。
问题 3:手写 HTTP 服务器时,为什么不需要单独开发 HTTP 客户端?
答案:因为浏览器本身就是一个功能完整的内置 HTTP 客户端,它会自动按照 HTTP 协议的格式构建请求、发送请求、解析响应。此外,绝大多数 APP 内部也本质是包裹了浏览器内核,同样可以作为 HTTP 客户端使用。因此,在开发和测试 HTTP 服务器时,直接使用浏览器或 telnet 工具即可,无需单独开发客户端。
问题 4:URL 中的 "?" 和 "#" 分别有什么作用?
答案:URL 中的 "?" 是查询字符串的起始标志,后面跟着的是客户端向服务器传递的参数,多个参数用 "&" 分隔,这些参数会被服务器接收并处理。"#" 是片段标识符的起始标志,后面跟着的是页面内的锚点,用于定位到页面的特定位置,这个部分只会被浏览器解析,不会发送给服务器。
5 ~> 思维导图
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ### 艾莉丝努力练剑 C/C++ & Linux 底层探索者 | 一个正在努力练剑的技术博主 *** ** * ** *** 👀 【关注】 跟随我一起深耕技术领域,见证每一次成长。 ❤️ 【点赞】 让优质内容被更多人看见,让知识传递更有力量。 ⭐ 【收藏】 把核心知识点存好,在需要时随时查、随时用。 💬 【评论】 分享你的经验或疑问,评论区一起交流避坑! 不要忘记给博主"一键四连"哦! "今日练剑达成!"  "技术之路难免有困惑,但同行的人会让前进更有方向。" |
"技术之路难免有困惑,但同行的人会让前进更有方向。" |
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Linux网络】Linux 网络编程:应用层自定义协议与序列化(3):网络计算器实现和守护进程
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
