在实际的复杂业务系统开发与运维中,SQL查询的结构往往会随着业务复杂度的提升而变得臃肿不堪。为了保证代码的可读性和逻辑的直观性,开发者非常喜欢使用 CTE(公共表表达式)、多层子查询、窗口函数,以及标量子查询(Scalar Subquery)。
从业务语义上看,在 SELECT 列表中直接嵌套一个子查询来获取某个关联的统计值或属性,是非常符合人类直觉的。然而,这种直观的写法常常会给数据库的查询优化器和执行引擎带来灾难性的挑战。 最近在进行系统性能调优时,我深刻体会到了标量子查询引发的性能梦魇,以及金仓数据库Kingbase内核通过"子查询消除"与"向量化引擎"协同带来的巨大收益。今天,就来和大家深度聊聊这个话题。

@toc
一、 开发者最易踩的坑:标量子查询的性能陷阱
在很多客户的报表业务中,我们经常能看到类似下面这种结构的 SQL 逻辑:
sql
SELECT s11.id1,
(SELECT sum(s22.id1)
FROM s22
WHERE s22.id3 = s11.id3),
(SELECT sum(s22.id2)
FROM s22
WHERE s22.id3 = s11.id3)
FROM s11;这条 SQL 的目的是从主表 s11 中取出数据,并针对每一行,去 s22 表中计算两个不同的聚合指标。从开发角度,这段代码极其易读。但从数据库执行角度来看,这里隐藏着极其严重的性能隐患:
- 恐怖的行级迭代(Row-by-row) :对于外层表
s11的每一行记录,数据库都需要执行一次内层的子查询。如果s11有 1 万条记录,子查询就要被强制唤醒执行 1 万次。随着外表记录数的增多,查询耗时会呈指数级爆炸。 - 算力的无谓浪费 :仔细观察可以发现,
SELECT之后的两个子查询,其结构和过滤条件(s22.id3 = s11.id3)完全相同,仅仅是输出的聚合列不同。但在传统的执行模式下,这两个子查询会被分别执行,造成了针对同一份数据的重复扫描。
根本问题其实并不在于子查询本身,而在于这种"外层驱动内层,逐行循环调用"的执行机制。
二、 为什么优化器不直接改写?探究语义安全的壁垒
既然 Row-by-row 这么慢,为什么很多传统数据库的优化器不直接把它们改成 JOIN 呢?这就涉及到了数据库内核实现中极其重要的一环------语义安全性(Equivalence)。
将标量子查询改写为连接操作(Unnesting),如果处理不当,会直接改变 SQL 的原始语义,导致查询结果出错,这对于数据准确性要求极高的企业级应用是不可接受的。其技术难点主要体现在以下两个场景:
- 单行返回约束的破坏 :标量子查询在 SQL 标准中有一个硬性要求------必须且只能返回一行一列(或者 NULL)。如果将其简单粗暴地改写为
LEFT JOIN,当从表中存在多条匹配记录时,JOIN操作会产生笛卡尔积发散,不仅不报错,还会导致外层表数据倍增。而原生的标量子查询在这种情况下是会直接抛出运行期错误的。 - 聚合函数的 NULL 值陷阱 :这是最容易出Bug的地方。假设子查询中使用了
COUNT函数。当因为没有匹配条件而找不到数据时,子查询单独执行会返回COUNT=0。但如果改写成了外连接,没有匹配记录时,关联补全的值是NULL。如果优化器不对这种情况做特殊处理和转换(例如使用COALESCE等函数补齐),就会导致优化前后的结果集出现0和NULL的不一致。
因此,不仅要优化,还必须有严格的等价性判定作为前提。
三、 从行式到集合:标量子查询消除的核心设计
笔者近期接触的电科金仓的 V009R002C014 版本中,其内核层面引入了一套非常完善的"标量子查询消除"机制。这套机制能够智能地识别并安全地将标量子查询转换为更高效的算子,彻底打破传统方案的局限。其核心设计思路可以概括为严谨的三步: 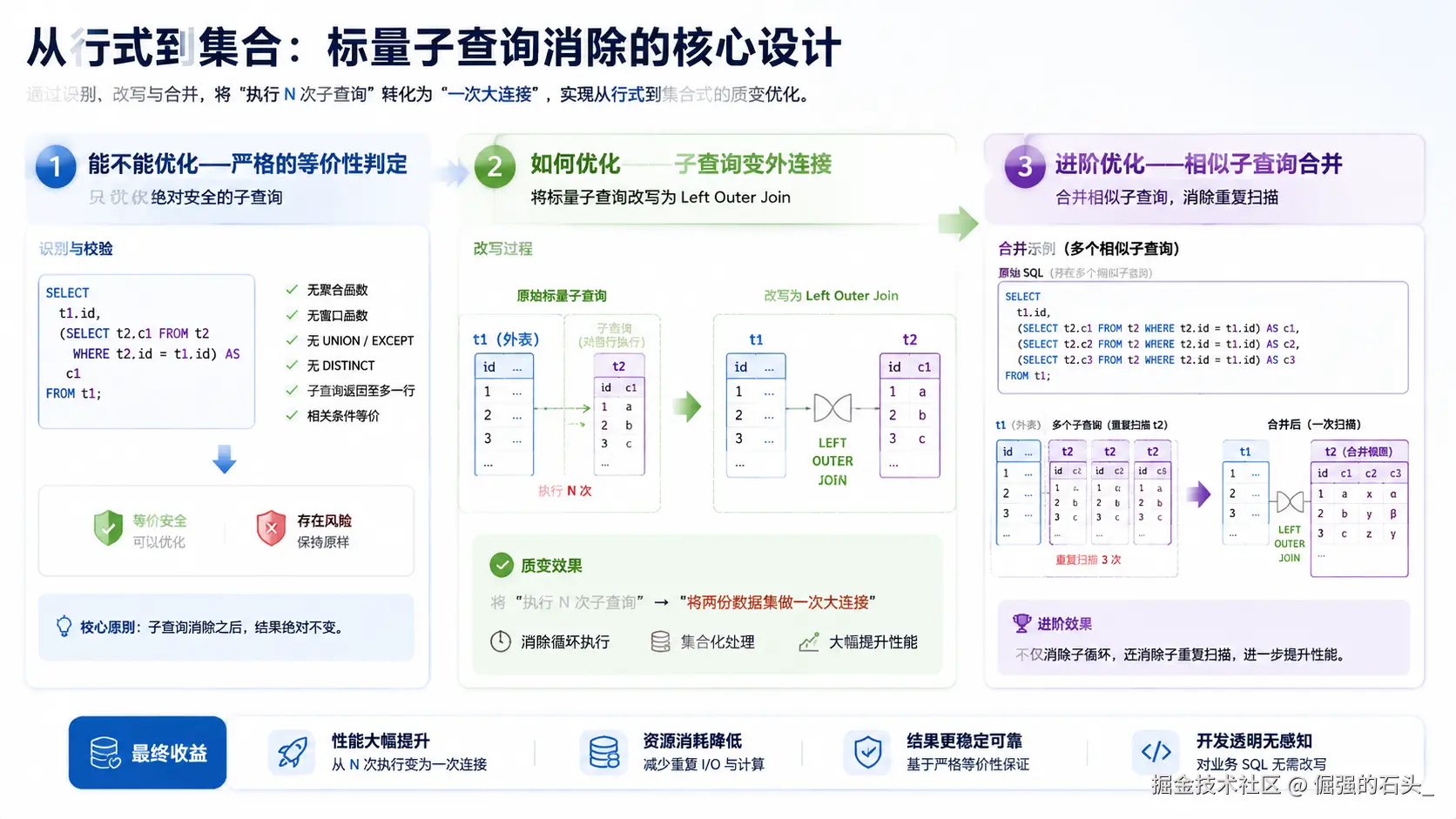
四、 深度碰撞:向量化引擎与 SIMD 的完美适配
如果我们仅仅只是把标量子查询消除这个事情,理解成是"减少了查询次数"的话,那就有点太片面了。也就是说咱们把眼光放到2026年的今天来看,通常来说现在的数据库内核里面,基本都用上了向量化执行引擎(Vectorized Execution)。这个时候,"标量子查询消除"就显得特别重要了。它其实就是一个前提条件,只有把它做好了,后面那个向量化引擎才能真正跑起来。
以前那种传统的"每一行执行一次子查询"(Row-by-row)的做法,说白了就是一行一行去处理。这种模式的情况下,现在的 CPU 其实是非常讨厌的。为什么会这样呢?每次去调用子查询的时候,系统都要去做上下文切换,接着还要搞函数压栈出栈。这样来回折腾下来,往往仅仅只是会导致 CPU 里面的那个指令缓存还有数据缓存,经常就失效了。还有一个挺麻烦的问题,就是这种一行一行迭代的话,根本没法用到现在 CPU 里面的 SIMD(单指令多数据流) 指令集。
Kingbase 这边搞的这个向量化执行机制呢,其实它最关键的地方就在于批处理(Batch)。也就是说,它需要把数据弄成那种列存数组的格式。然后一次性(Batch)全给它塞到 CPU 的寄存器里面去,这样一条指令发下去,就能同时处理好几条数据了。
所以当我们用金仓的优化器,把这个标量子查询给"消除"掉,并且改写成了外连接(Join)的时候,我们其实也就是在干一件事。就是把以前那种零散的、一块一块碎掉的循环操作,直接给整成了那种大批量的集合式处理(Set-based)。
- 如果在这个消除没做之前的话,外层的扫描老是会被打断,接着那个执行引擎基本也就退化成标量执行的模型了。
- 在做完这个消除(也就是 Join 改写)之后,底层其实就可以用那个优化得挺好的 Hash Join 算子了。这两个表的数据,其实也就是被分批(Batch)弄进内存里。接着再通过那种向量化的 Hash 探测函数,用上 SIMD 指令,就能在特别短的时间里面把一大批的数据匹配给跑完。
所以说啊,这活儿往往仅仅只是表面看着像换了个逻辑,其实根本不是这种简单的替换。实际上这就是金仓数据库的内核那边,为了去迎合现在新的 CPU 架构搞出来的一个设计。靠着这个改动,那个向量化执行引擎才算是真正把流程给跑通了,这确实是个挺实在的底层优化。
五、 震撼的实测对比:从 32 秒到 24 毫秒
为了验证这项内核技术的威力,我们可以在测试库中构建一个极端的场景进行性能压测:
sql
-- 创建测试表并插入1万行测试数据
create table t1(id numeric(10,1));
create table t2(id numeric(10,1));
insert into t1 values(generate_series(1,10000));
insert into t2 values(generate_series(1,10000));
-- 执行典型的标量子查询SQL
select (select sum(id) from t2 where t1.id=t2.id) from t1;场景 A:子查询未消除(传统行式执行) 在此模式下,对于 t1 表的每一条记录,优化器都要对 t2 进行一次全表扫描。由于 t1 有 1 万条记录,意味着 t2 表需要被扫描 1 万次 。 查看底层执行计划(EXPLAIN ANALYZE),可以看到刺眼的 SubPlan 1 嵌套,并且 Seq Scan on t2 的 loops=10000。 实测耗时:约 32 秒(Execution Time: 32740.188 ms) 。这在生产环境中会导致严重的连接阻塞。 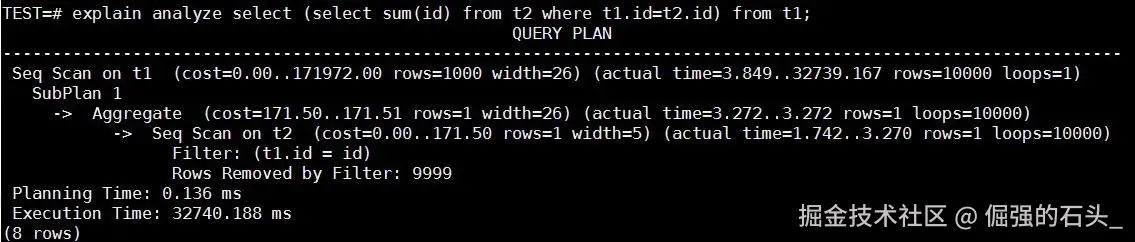
场景 B:子查询消除后(基于金仓新内核集合执行) 当引擎识别并触发了标量子查询消除,将子查询改写为内部的视图关联后,执行计划发生了翻天覆地的变化。原有的 SubPlan 消失了,取而代之的是 Hash Left Join 以及 HashAggregate。 此时,t2 表只需要进行一次 扫描并建立 Hash 表,随后 t1 表再进行一次扫描进行 Hash 探测即可。 实测耗时:仅仅约 24 毫秒(Execution Time: 24.643 ms)。
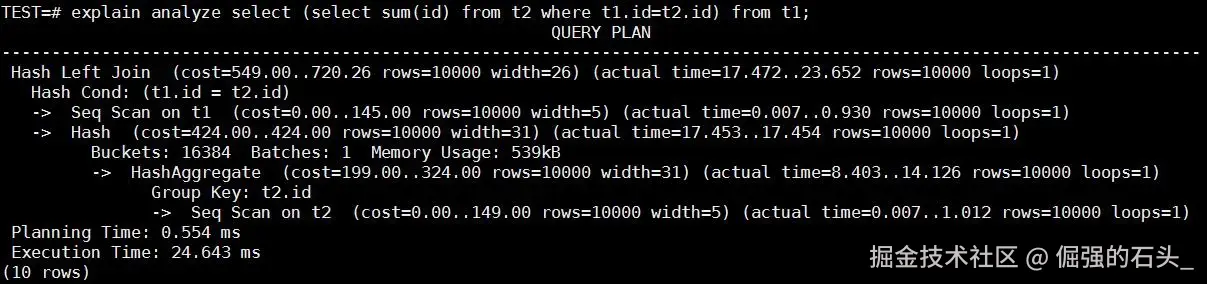
性能足足提升了 1300多倍,实现了数量级上的碾压。
六、 总结
在复杂的企业级数据分析优化中,"标量子查询消除"不仅将一个多次执行的标量操作转变为只执行一次的外连接操作,并将结构类似的子查询进行了智能合并,极大地减少了执行次数。更重要的是,通过这种集合式改写,它将 SQL 语句转换为最适合现代向量化执行引擎吞吐的形态。
作为开发者,我们固然应该在编写代码时尽量采用合理的 JOIN 来替代不必要的标量子查询。但业务的演进往往不可控,一款拥有强大自愈能力和前瞻性架构设计的数据库内核(如电科金仓),往往能在底层为我们的业务系统提供最坚实的性能兜底。从 Row-by-row 到向量化批处理,不仅是算法的升级,更是数据库技术紧跟硬件时代的最好注脚。