RAG 做到文本问答,只是第一步。真实业务中的知识并不只存在于纯文本里。一个客服知识库可能同时有 Word、PDF、网页、表格、活动海报、产品图片、视频说明;一个运营分析场景里,可能有 Excel、截图、合同扫描件、录音、会议视频;一个财务对账场景里,可能还有托管行 PDF、日文材料和内部系统数据。
所以多模态 RAG 要解决的核心问题是:
text
不同模态的数据
-> 解析成可处理的内容
-> 转成统一的语义表示
-> 建立索引
-> 用户提问时统一检索
-> 把文本、图片、视频等结果一起交给 LLM
-> 输出答案,并附上相关媒体这里有两条主线:
- 多模态大模型可以直接理解图像、音频、视频、PDF、代码等输入。
- 多模态 Embedding 可以把文本、图片、视频映射到统一向量空间,支撑跨模态检索。
这两条线结合起来,才能做出"既能查文档,又能找图片,还能关联视频"的 RAG 应用。
一、多模态 RAG 的背景与模型能力
多模态不只是"看图说话"
多模态能力常被理解成"上传一张图,让模型描述图片"。这只是最表层的能力。
从应用角度看,多模态可以覆盖以下几类任务:
- 文本:制度、说明书、问答、网页、代码。
- 图片:海报、截图、票据、照片、图表。
- 音频:语音讲解、播客、会议录音。
- 视频:监控片段、操作录屏、课程视频、活动视频。
- PDF / Word / PPT / Excel:混合了文本、表格、图片和版式结构的文档。
如果只做文本 RAG,那么图片里的文字、表格结构、视频内容、页面位置关系都会丢失。多模态 RAG 的价值就在于把这些非文本内容也纳入知识系统。
比如一个跨境基金运营智能对账场景,业务痛点可能是:
- 托管行材料是 PDF,而且可能是日文。
- 内部系统数据在 Excel 里。
- 每天都要人工核对大量数据。
- 流程繁琐、耗时,而且容易因为语言隔阂产生疏漏。
这类问题不是简单问答,而是要把 PDF、Excel、截图、业务规则一起理解,再进一步生成对账方案、流程说明、汇报材料,甚至演示内容。
用多模态模型做快速研究和材料生成
多模态模型不仅能回答问题,也能把一个领域的资料加工成不同形式的材料。
常见输出包括:
- 汇报材料。
- 信息图。
- 思维导图。
- 音频讲解。
- 视频讲解。
- PPT 演示。
如果要把一段内容做成视频,大致可以拆成几个工程步骤:
text
原始材料
-> LLM 生成视频脚本
-> 按脚本拆分成 6-8 张配图
-> 每张图和脚本段落对应
-> 生成口播音频
-> 生成字幕
-> 合成视频这也是多模态应用和普通聊天应用的重要区别:普通聊天只输出一段文字,多模态应用会把文字、图片、音频、视频串成一个完整工作流。
工具选择上,可以这样理解:
- NotebookLM 更适合把资料整理成 summary、标签、问答和音频式讲解。
- Gemini 这类多模态模型适合处理图像、视频、PDF 等复杂输入。
- 国内图像和视频生成场景中,可以考虑即梦、MiniMax 等工具。
- 多模态理解可以使用 Qwen、Gemini 等支持视觉输入的模型。
对于工作汇报,图像生成也很实用。常见风格包括白板书、视觉笔记、未来科技风、3D 黏土风等。
比如讲 CNN 的由来,可以把文字材料转成"教授板书照片"的样子:用箭头、方框、图表和中文说明来解释 S 细胞、C 细胞、卷积层和池化层之间的关系。这类图的重点不只是美观,而是把抽象概念转成更容易理解的视觉结构。
Gemini 的多模态处理能力
Gemini 这类多模态模型的特点在于:可以把文本、图像、音频、视频、PDF、代码等不同形态的数据一次性喂给模型,让模型在同一套神经网络里完成理解、推理和生成,不一定要先把所有东西转成文本。
它的核心能力可以概括成四点。
第一,原生统一架构。
从预训练开始就把多种模态放在同一个表征空间里学习,而不是先训练一个大语言模型,再外挂视觉模块或语音模块。这样做的好处是信息损耗更小,也更容易保留时序、细节和跨模态关系。
第二,端到端推理。
同一组 Transformer 参数可以直接处理任意组合输入。例如:
- 给一张 CT 影像和病历文本,模型可以同步给出诊断建议。
- 给一段手写食谱视频,模型可以直接整理成数字菜谱。
第三,长上下文。
长窗口模型可以一次性读入很长的视频或 PDF,再输出结构化报告。长上下文不能替代 RAG,但它让"直接理解完整材料"变得更容易。
第四,生成能力。
多模态模型不仅能看和听,还能画和说。例如文本生成图像、编辑图像、图像修复、流式生成音频等。
Gemini API 的基本用法
如果用 Gemini API,第一步是申请 API Key,然后设置环境变量:
text
GEMINI_API_KEY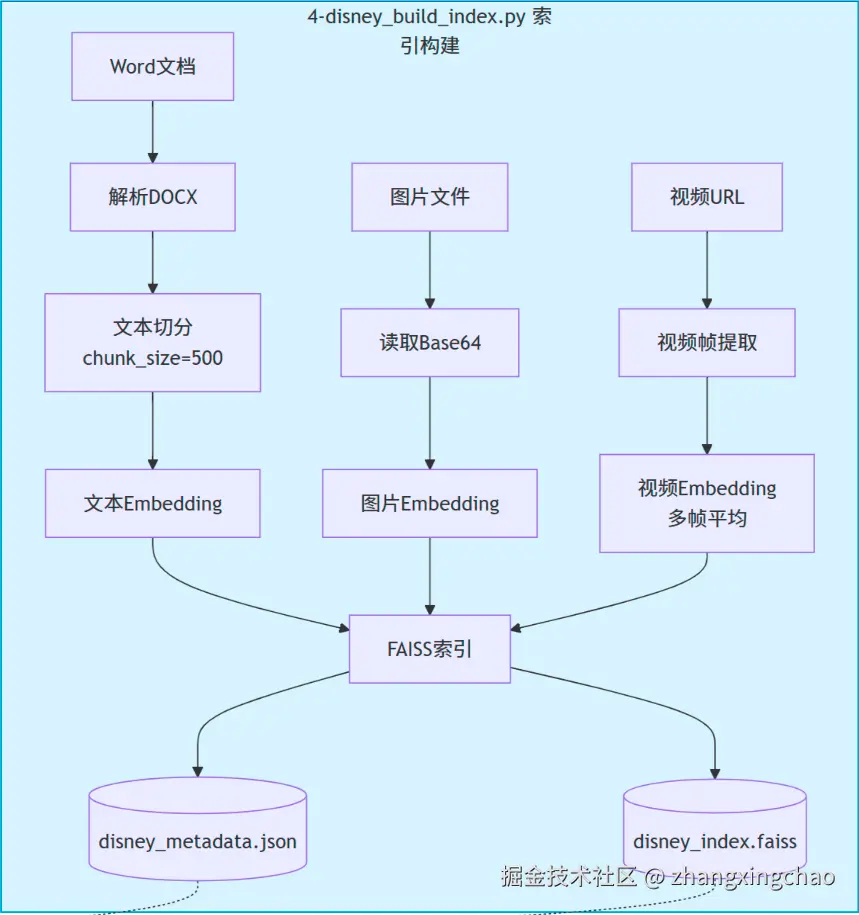 文本生成的代码可以写成:
文本生成的代码可以写成:
python
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="用中文解释AI大模型是如何工作的",
)
print(response.text)图像理解时,关键变化是:contents 变成一个列表,同时放图片对象和文字问题。
python
from PIL import Image
image = Image.open("dog_and_girl.jpeg")
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[image, "帮我解释下这张照片"],
)
print(response.text)视频理解要多一个上传和等待处理的过程。视频上传后,服务端需要几秒钟进行转码和处理:
python
import time
from google import genai
client = genai.Client()
print("正在上传视频...")
video_file = client.files.upload(file="car.mp4")
print(f"上传成功: {video_file.name}")
while video_file.state.name == "PROCESSING":
print("视频处理中,请稍候...")
time.sleep(2)
video_file = client.files.get(name=video_file.name)
if video_file.state.name == "FAILED":
raise ValueError("视频处理失败")
print("视频就绪,开始推理...")
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
video_file,
"详细描述视频里发生了什么?如果有对话,请把关键对话提取出来。",
],
)
print(response.text)这类多模态 LLM 更适合"直接理解和生成"。但如果要在大量资料中做检索,还需要引入 Embedding 和向量索引。
二、迪士尼 RAG 助手与多模态 Embedding 路线
迪士尼 RAG 助手要解决什么
可以用一个迪士尼客服助手来说明多模态 RAG。
目标是构建一个 7×24 小时在线的 AI 客服助手,能力包括:
- 自动回答票务、入园须知、会员权益等高频问题。
- 所有回答尽量来自官方知识库,避免信息错误或过时。
- 不仅回答文本问题,也能处理图片相关问题,比如活动海报。
- 遇到视频相关问题时,可以关联视频素材或视频理解结果。
这个场景的难点主要体现在三方面。
第一,知识来源多样。
知识库里可能有 PDF 格式的官方规定、Word 格式的内部 FAQ、网页公告,以及包含图片和表格的活动介绍文件。
第二,非结构化数据处理复杂。
PDF 和 Word 里不仅有纯文本,还有表格、图片、版式。图片里可能有文字,表格里有结构,PDF 页面的顺序和层次也会影响理解。
第三,回答必须基于检索结果。
客服场景最怕模型乱编。RAG 系统要让最终答案严格基于检索到的内容,同时在合适的时候附上图片或视频。
两种技术路线
处理多模态知识库有两种常见路线。
方案一:不同模态分开处理
这种方式比较传统:
- PDF 用 PyMuPDF 解析。
- Word 用 python-docx 解析。
- 图片里的文字用 OCR,比如 pytesseract、PaddleOCR、DeepSeek-OCR、MinerU 等。
- 文本用文本 Embedding 模型。
- 图片用 CLIP 或图像 Embedding 模型。
- 向量检索用 FAISS,生产环境也可以用 Milvus、ChromaDB 或 Elasticsearch。
- 最终回答用 Qwen、DeepSeek、Gemini 等 LLM。
这条路线的优点是可控,每一步都很清楚。缺点是模块较多,文本、图片、视频可能不在同一个语义空间里,跨模态检索需要额外处理。
方案二:统一多模态 Embedding
另一种方式是:文本 Embedding、图像 Embedding、视频 Embedding 都使用同一个多模态 Embedding 模型。
也就是把文本、图片、视频都转换成同一语义空间中的向量。这样可以实现:
- 以文搜图。
- 以图搜图。
- 以文搜视频。
- 以图搜视频。
- 文本、图片、视频之间做统一相似度计算。
- 对内容进行分类、聚类、打标签。
这也是迪士尼 RAG 助手更适合使用的路线。
Multimodal Embedding 怎么理解
多模态 Embedding 的关键点是:不同模态生成的向量位于同一个语义空间。
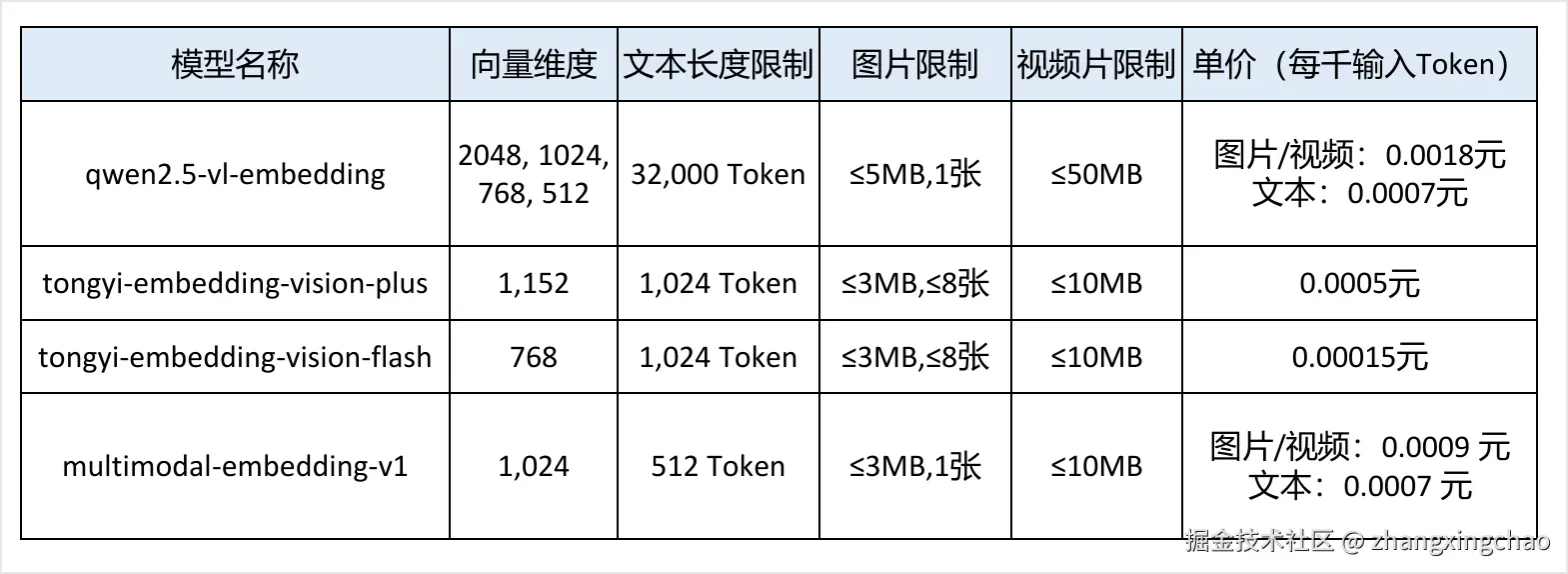
表中几个模型的差异,主要体现在向量维度、文本长度限制、图片限制、视频限制和价格上。
例如:
qwen2.5-vl-embedding支持较长文本,向量维度可选。tongyi-embedding-vision-plus输出 1152 维向量,支持文本、图片和视频。tongyi-embedding-vision-flash成本更低,维度为 768。multimodal-embedding-v1输出 1024 维向量。
从 RAG 的角度看,最重要的不是"模型名字",而是以下几个问题:
- 文本、图片、视频是否真的在同一向量空间里?
- 向量维度是多少?
- 图片是否需要 Base64?
- 视频是本地上传还是 URL 输入?
- 一次可以传多少张图片?
- 输入 token 成本能不能接受?
- 检索效果是否能覆盖自己的业务问题?
文本、图片、视频如何向量化
文本向量化相对直接,把文本放到 input 中即可:
python
import dashscope
import json
from http import HTTPStatus
text = (
"上海迪士尼乐园门票分为一日票、两日票和特定日票三种类型。"
"一日票可在购买时选定日期使用,价格根据季节浮动,平日成人票475元起"
)
input_data = [{"text": text}]
resp = dashscope.MultiModalEmbedding.call(
model="tongyi-embedding-vision-plus",
input=input_data,
)
if resp.status_code == HTTPStatus.OK:
result = {
"status_code": resp.status_code,
"request_id": getattr(resp, "request_id", ""),
"code": getattr(resp, "code", ""),
"message": getattr(resp, "message", ""),
"output": resp.output,
"usage": resp.usage,
}
print(json.dumps(result, ensure_ascii=False, indent=4))图片向量化通常需要先读取为 Base64,再组装成 data URL:
python
import base64
import dashscope
import json
from http import HTTPStatus
image_path = "./disney_knowledge_base/images/1-聚在一起说奇妙.jpg"
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
image_format = "jpg"
image_data = f"data:image/{image_format};base64,{base64_image}"
input_data = [{"image": image_data}]
resp = dashscope.MultiModalEmbedding.call(
model="tongyi-embedding-vision-plus",
input=input_data,
)
if resp.status_code == HTTPStatus.OK:
result = {
"status_code": resp.status_code,
"request_id": getattr(resp, "request_id", ""),
"code": getattr(resp, "code", ""),
"message": getattr(resp, "message", ""),
"output": resp.output,
"usage": resp.usage,
}
print(json.dumps(result, ensure_ascii=False, indent=4))视频向量化要注意:有些多模态向量模型目前只支持视频 URL,不支持直接传本地视频文件。
python
import dashscope
import json
from http import HTTPStatus
video = "https://dataset-1255932437.cos.ap-nanjing.myqcloud.com/mp4/car.mp4"
input_data = [{"video": video}]
resp = dashscope.MultiModalEmbedding.call(
model="tongyi-embedding-vision-plus",
input=input_data,
)
if resp.status_code == HTTPStatus.OK:
result = {
"status_code": resp.status_code,
"request_id": getattr(resp, "request_id", ""),
"code": getattr(resp, "code", ""),
"message": getattr(resp, "message", ""),
"output": resp.output,
"usage": resp.usage,
}
print(json.dumps(result, ensure_ascii=False, indent=4))这里需要区分两个概念:
- 多模态 LLM:直接理解图片或视频,然后生成文字回答。
- 多模态 Embedding:把图片或视频压成向量,用来做相似度检索。
前者偏向"理解和生成",后者偏向"召回和匹配"。
图片一定要转文字吗
不一定。图片通常有两种处理方式。
第一种,把图片转成文本:可以用 OCR 提取图片里的文字,也可以用多模态 LLM 生成图片描述。这样所有模态最终都统一成文本,再进入文本 Embedding 或文本 RAG 流程。优点是可解释性强,结果容易调试,也方便和文件名、标签、业务字段一起进入检索。缺点是部分信息会丢失。图片里的构图、颜色、人物动作、视觉风格、空间关系,不一定能完整转成文字。
第二种,直接做图片 Embedding:图片直接进入多模态 Embedding 模型,输出向量。这样可以实现以文搜图、以图搜图,也能保留一些视觉语义。优点是跨模态检索能力强。缺点是向量不可读,命中错误时不如文本结果容易解释。
实际项目中通常会两种方式结合使用:
text
图片原文件
-> OCR / 多模态 LLM 生成文字描述
-> 图片 Embedding
-> 文本描述 + 图片向量 + metadata 一起保存这样召回时,既可以依赖图片向量,也可以依赖文本描述和关键词。
三、文档解析、FAISS 索引与元数据
Word 和 PDF 怎么解析
多模态 RAG 的数据层首先要把文件拆开。
Word 文档
Word 里可能有段落,也可能有表格。一个 parse_docx 函数需要遍历 .docx 文件中的所有元素,把段落和表格提取成独立内容块。
段落处理时:
- 找出所有段落。
- 提取段落内纯文本。
- 去掉多余空白。
- 标记为
type: text。
表格处理时:
- 读取表头。
- 逐行读取单元格。
- 转成 Markdown 表格。
- 标记为
type: table。
简化代码如下:
python
def parse_docx(file_path):
doc = DocxDocument(file_path)
content_chunks = []
for element in doc.element.body:
if element.tag.endswith("p"):
paragraph_text = ""
for run in element.findall(
".//w:t",
{"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main"},
):
paragraph_text += run.text if run.text else ""
if paragraph_text.strip():
content_chunks.append({
"type": "text",
"content": paragraph_text.strip(),
})
elif element.tag.endswith("tbl"):
md_table = []
table = [t for t in doc.tables if t._element is element][0]
if table.rows:
header = [cell.text.strip() for cell in table.rows[0].cells]
md_table.append("| " + " | ".join(header) + " |")
md_table.append("|" + "---|" * len(header))
for row in table.rows[1:]:
row_data = [cell.text.strip() for cell in row.cells]
md_table.append("| " + " | ".join(row_data) + " |")
table_content = "\n".join(md_table)
if table_content.strip():
content_chunks.append({
"type": "table",
"content": table_content,
})
return content_chunksPDF 文档
PDF 更复杂,因为它可能同时包含文本、扫描图、嵌入图片和复杂版式。
使用 PyMuPDF 时,可以逐页提取文本,也可以提取每页嵌入的图片:
python
import os
import fitz
def parse_pdf(file_path, image_dir):
doc = fitz.open(file_path)
content_chunks = []
for page_num, page in enumerate(doc):
text = page.get_text("text")
content_chunks.append({
"type": "text",
"content": text,
"page": page_num + 1,
})
for img_index, img in enumerate(page.get_images(full=True)):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
image_ext = base_image["ext"]
image_path = os.path.join(
image_dir,
f"{os.path.basename(file_path)}_p{page_num + 1}_{img_index}.{image_ext}",
)
with open(image_path, "wb") as f:
f.write(image_bytes)
content_chunks.append({
"type": "image",
"path": image_path,
"page": page_num + 1,
})
return content_chunks这一步的结果不是最终答案,而是为后续索引做准备。
FAISS 索引怎么构建
构建多模态知识库时,可以把 Word、图片、视频都放到同一个 FAISS 索引里。
整体流程可以拆成五步:
-
解析 Word 文档。
parse_docx()遍历 DOCX 元素,提取段落文本和表格,并把表格转成 Markdown。 -
文本切分。
split_text()按固定长度切分,例如chunk_size=500,overlap=50。 -
多模态 Embedding。
使用
tongyi-embedding-vision-plus统一处理文本、图片和视频。 -
构建 FAISS 索引。
可以使用
IndexFlatL2,也就是基于 L2 距离的精确搜索索引。 -
持久化存储。
索引保存为
disney_index.faiss,元数据保存为disney_metadata.json。
多模态统一索引的结构可以概括为:
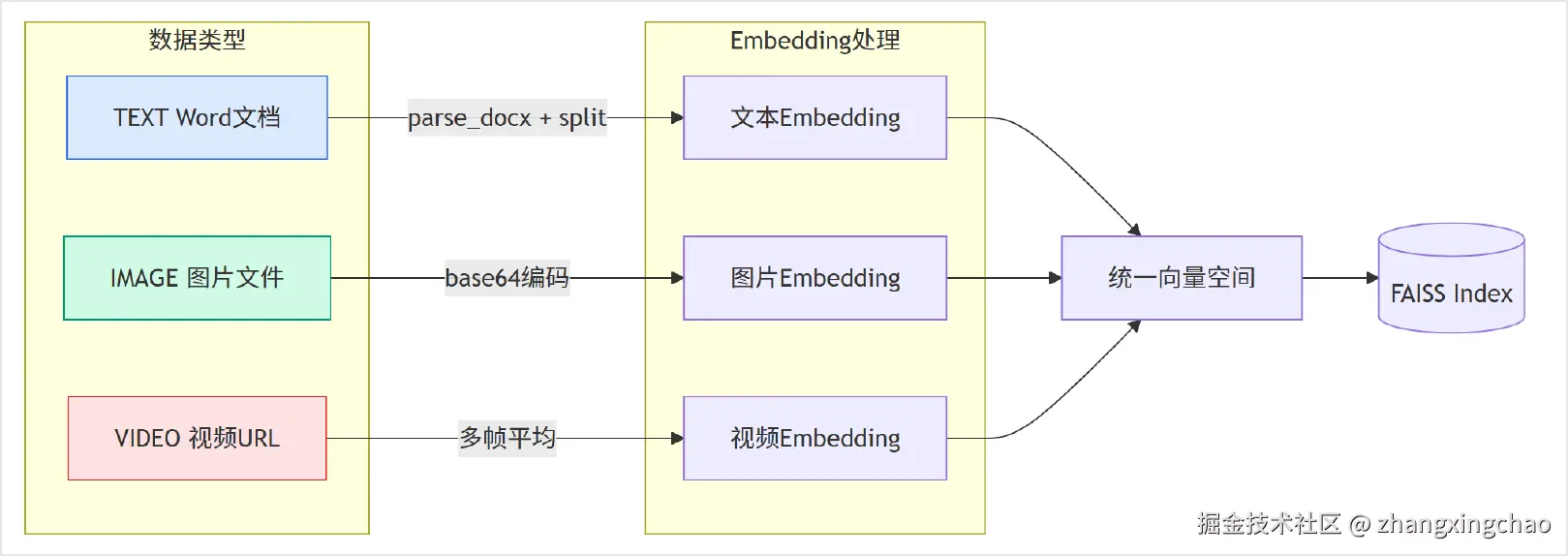
这里有几个关键点:
文本可以直接编码。
图片需要先 Base64 编码后发送。
视频可以先提取多帧,再计算平均向量;如果模型直接支持视频 URL,也可以把 URL 传给模型。
最终都进入统一向量空间,再写入同一个 FAISS Index。
元数据要保存什么
FAISS 本身更像一个向量检索库,它重点管理向量和索引。真实业务里,不能只存向量,还要单独维护元数据。
典型 metadata 可以这样设计。
文本类型:
json
{
"id": 0,
"source": "退票政策.docx",
"type": "text",
"content": "退票内容..."
}图片类型:
json
{
"id": 10,
"source": "图片: poster.jpg",
"type": "image",
"path": "images/poster.jpg",
"content": "[图片] poster.jpg"
}视频类型:
json
{
"id": 15,
"source": "视频: 汽车剐蹭",
"type": "video",
"url": "https://...",
"description": "汽车剐蹭视频"
}也就是说,向量数据库或 FAISS 索引负责"找相似向量",metadata 负责"回到原始业务内容"。
有一个常见问题是:向量数据库中是否只存向量,而不存原始文本和图片?
答案是:可以存,也可以不存,取决于具体数据库。FAISS 只是库,不会像完整数据库那样帮你管理业务数据。如果用 FAISS,原始文本、图片路径、视频 URL、来源文件、页码、权限标签这些都需要自己维护。
Query 查询怎么处理
用户提问时,系统需要先把问题转换成向量,再到 FAISS 中检索。
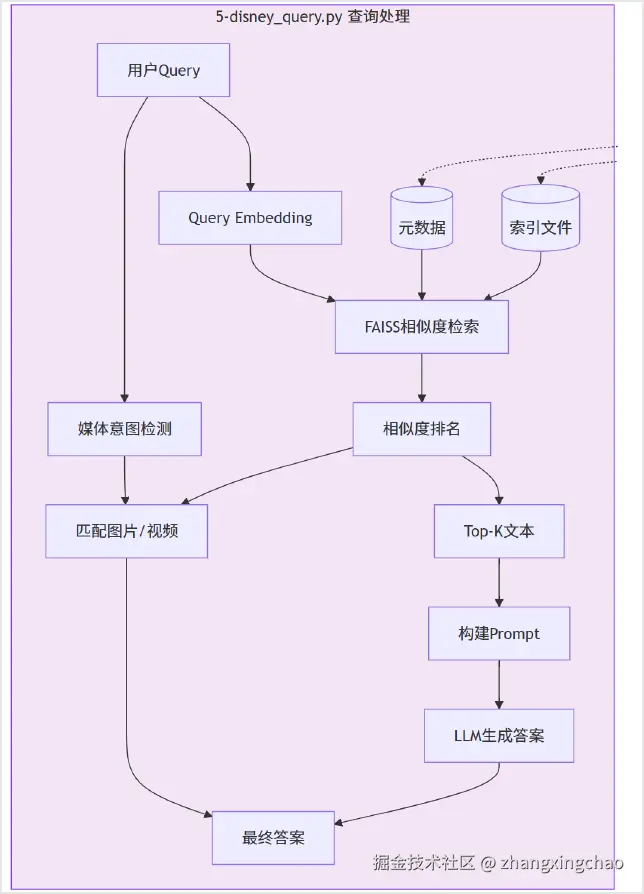
完整流程如下:
-
加载索引。
load_index()从文件加载 FAISS 索引和元数据 JSON。 -
Query Embedding。
把用户问题转成向量,和索引里的向量放到同一个空间比较。
-
相似度检索。
检索全部记录,按 L2 距离排序,再转换成相似度:
text
sim = 1 / (1 + distance)- 媒体意图检测。
用关键词判断用户是否需要图片或视频。
python
IMAGE_KEYWORDS = ["图片", "海报", "照片", "看看", "长什么样"]
VIDEO_KEYWORDS = ["视频", "录像", "播放"]-
结果筛选。
文本取 Top-K,例如默认
k=3。图片和视频只有在距离小于阈值时才采纳,例如MEDIA_DISTANCE_THRESHOLD = 3.0。 -
LLM 生成。
构建 prompt,把背景知识和用户问题交给
qwen-flash生成答案,并在需要时附上匹配到的图片或视频链接。
关键配置可以这样写:
python
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
EMBEDDING_MODEL = "tongyi-embedding-vision-plus"
LLM_MODEL = "qwen-flash"
MEDIA_DISTANCE_THRESHOLD = 3.0统一向量空间到底是什么意思
统一向量空间可以理解为:文本、图片、视频都被映射到同一个坐标系里。
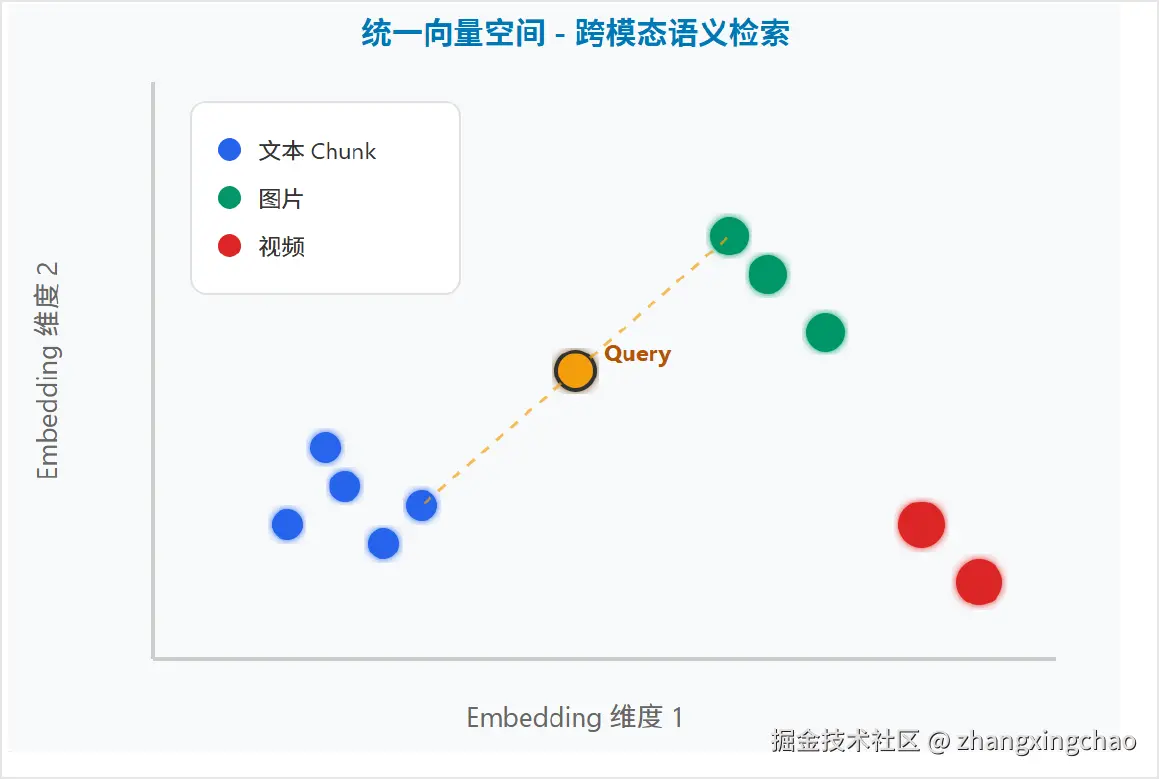
图里蓝色点代表文本 chunk,绿色点代表图片,红色点代表视频。用户 query 也会被编码成一个向量。如果 query 离某张图片更近,就可以实现"以文搜图";如果 query 离某段视频更近,就可以实现"以文搜视频"。
这个能力的前提是:这些模态必须由同一个多模态 Embedding 模型映射到统一空间,或者至少经过对齐训练。
还有一个常见问题:图片 embedding 把图片压缩成向量后,能否和纯文本 query 的向量匹配?
答案是可以,前提是模型本身支持跨模态对齐。多模态 Embedding 的训练目标之一,就是让"描述同一语义的文本和图片"在向量空间里距离更近。
统一索引 + 后筛选
多模态 RAG 可以采用"统一索引 + 后筛选"的检索策略。

伪代码如下:
python
# 1. 统一检索:一次查询返回所有类型
results = search_with_details(query, index, metadata)
# 2. 意图检测:关键词判断是否需要媒体
want_image, want_video = detect_media_intent(query)
# 3. 文本无条件取 Top-K
top_results = [
r for r in results
if r["type"] == "text"
][:k]
# 4. 图片仅当用户需要图片且距离足够近时才返回
if want_image:
image_results = [
r for r in results
if r["type"] == "image" and r["distance"] < 3.0
]
matched_image = min(image_results, key=lambda x: x["distance"])这个策略背后的考虑包括:
- 单索引架构:文本、图片、视频共享统一向量空间,索引维护简单。
- 意图驱动:通过关键词检测用户意图,按需触发媒体检索,避免无关媒体干扰。
- 文本优先:文本结果无条件进入 prompt,媒体作为附件补充,保证回答质量。
- 阈值过滤:媒体需要满足距离阈值,防止低相关性媒体误匹配。
完整工作流可以概括成:
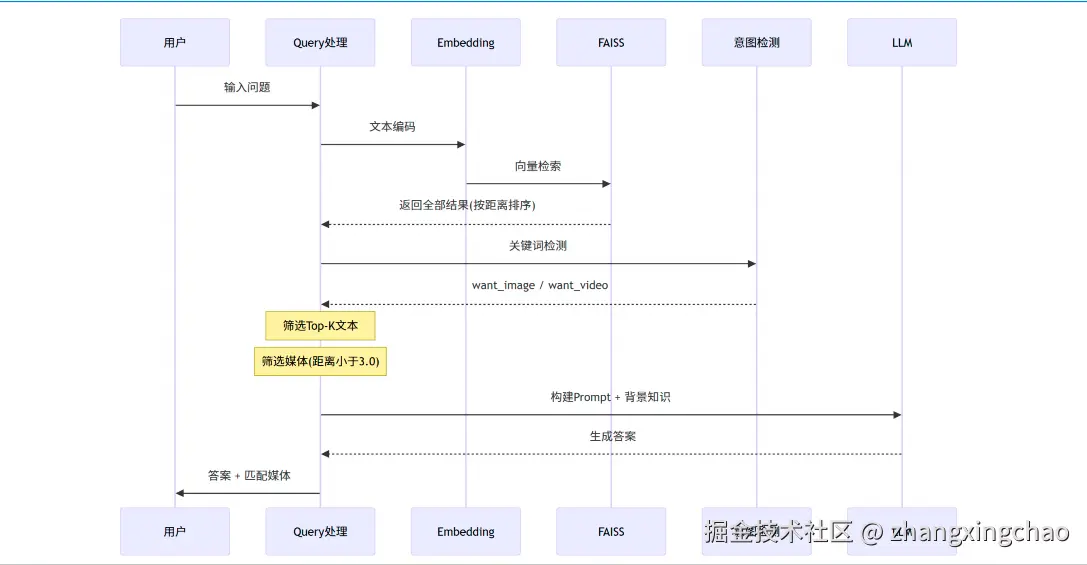
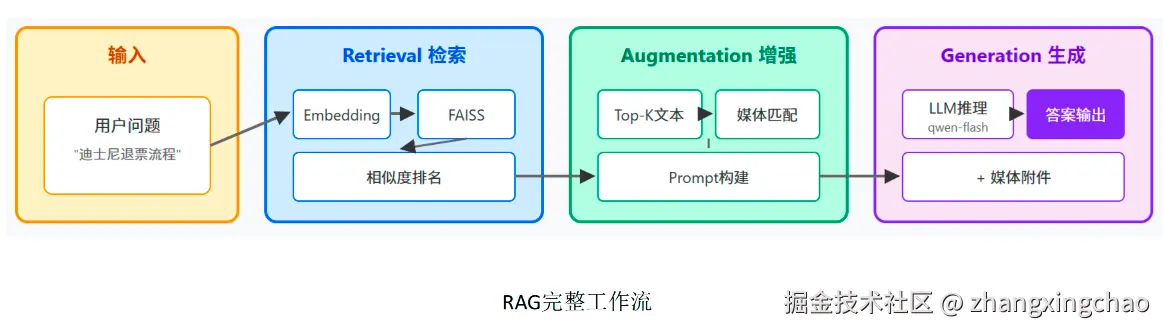 更细的查询处理流程如下:
更细的查询处理流程如下:
索引构建结果怎么看
构建知识库后,日志大概长这样:
text
--- 构建多模态知识库 ---
切分参数: chunk_size=500, overlap=50
处理文档: 1-上海迪士尼门票规则.docx
文档长度: 1342 字符, 切分为 3 个 chunk
处理文档: 2-迪士尼老人票价规定.docx
文档长度: 879 字符, 切分为 2 个 chunk
处理文档: 3-迪士尼乐园游玩攻略清单.docx
文档长度: 641 字符, 切分为 2 个 chunk
处理文档: 4-上海迪士尼乐园酒店会员制度.docx
文档长度: 790 字符, 切分为 2 个 chunk
处理图片...
- 1-聚在一起说奇妙.jpg
- 2-万圣节.jpeg
处理视频...
- 汽车剐蹭视频
向量维度: 1152
索引已保存: disney_index.faiss
元数据已保存: disney_metadata.json
完成! 文本:9, 图片:2, 视频:1从这段日志中可以看出几个信息:
- 文档中的文字内容被切成 9 个 chunk。
- 图片有 2 张。
- 视频有 1 个。
- 所有内容统一生成 1152 维向量。
- FAISS 索引和 metadata 分开保存。
四、查询处理、案例验证与媒体结果处理
用户问题 1:门票退款流程
用户问:
text
我想了解一下迪士尼门票的退款流程系统会先做相似度排名,然后发现不需要图片,也不需要视频:
text
意图检测: 需要图片=False, 需要视频=False接着选取 Top-3 文本构建 prompt,并调用 LLM 生成回答。
生成结果里包含:
- 退改时间限制:入园前至少 48 小时操作才可修改或退票。
- 不足 48 小时通常无法办理退改。
- 特殊情况如突发疾病、意外事故,可提交相关证明申请处理。
- 门票过期后 30 天内可能可以补差价延期。
- 操作方式包括官方 App、官网、微信公众号或小程序。
- 退款一般原路退回,可能需要 3-7 个工作日。
这个例子说明:当用户只问文本政策时,媒体内容不需要进入答案。否则会增加噪声。
用户问题 2:万圣节活动海报
用户问:
text
最近万圣节的活动海报是什么这个问题里有"海报",所以意图检测结果是:
text
需要图片=True
需要视频=False系统除了检索 Top-K 文本,还会从图片类型结果里找距离小于阈值的匹配:
text
匹配到图片: disney_knowledge_base/images/2-万圣节.jpeg
距离: 1.5501
相似度: 0.3921最终回答不仅会描述活动内容,还会附上相关图片路径。
这里有一个容易误解的地方:用户问题里出现"海报",并不意味着一定要把所有图片都返回。仍然要经过相似度、阈值和类型筛选。
用户问题 3:汽车被剐蹭了,能看到视频吗
用户问:
text
我的汽车被剐蹭了,你能看到视频么?这个问题里有"视频",所以系统会触发视频意图:
text
需要图片=False
需要视频=True检索结果里命中了一个视频:
text
匹配到视频: https://dataset-1255932437.cos.ap-nanjing.myqcloud.com/mp4/car.mp4
距离: 1.5424
相似度: 0.3933最终回答需要注意业务边界:客服助手不能假装自己能查看监控,也不能直接给出不存在的权限。更合理的回答是:
- 抱歉听到车辆被剐蹭。
- 建议联系游客服务中心。
- 保留现场照片或视频证据。
- 如果有目击者,留下联系方式。
- 如涉及保险理赔,及时通知保险公司。
- 可以附上相关视频链接,但不能夸大自己对监控系统的访问能力。
这就是多模态 RAG 的边界:可以检索媒体,但不能把检索到的媒体当成模型实际拥有的业务权限。
为什么文本结果有时排在图片前面
笔记里提到一个现象:问图片内容时,文本相关结果可能还排在前面。
这是正常现象。
因为统一索引返回的是所有类型的向量结果,文本、图片、视频一起排序。如果文本 chunk 的语义和 query 更接近,它就会排在前面。
因此才需要"意图检测 + 后筛选":
- 用户只是问政策,就只用文本。
- 用户明确问海报、图片、照片,就从图片结果中再挑。
- 用户明确问视频、录像、播放,就从视频结果中再挑。
如果只看全局相似度,不看用户意图,可能会出现媒体误匹配。
也可能有人会问:是不是因为图片文件名中带有"万圣节",所以才命中?
如果 FAISS 检索只用图片 embedding,本身不会看文件名。但如果把文件名、图片描述、OCR 文本也一起做了 embedding,那么文件名和描述会影响文本侧召回。这并不是坏事,关键是要清楚自己到底把哪些信息放进了向量化输入。
图片和视频向量能还原原图原视频吗
不能。
Embedding 是特征提取,不是可逆压缩。它把原始内容映射成一串浮点数,用来做相似度计算。
所以:
- 图片转成 embedding 后,不能从 embedding 还原原图。
- 视频转成 embedding 后,也不能从 embedding 还原原视频。
- 原始图片和视频仍然要保存。
这也是 metadata 重要的原因。FAISS 命中向量以后,要通过 metadata 找回原始图片路径、视频 URL、文件名、页码或业务 ID。
视频怎么做 Embedding
视频可以理解为多帧图像与时间关系的组合。
常见方式有几种:
- 直接把视频 URL 交给支持视频输入的多模态 Embedding 模型。
- 对视频抽关键帧,每一帧做图片 embedding。
- 对多个帧 embedding 做平均或加权平均,得到视频级向量。
- 先用多模态 LLM 描述视频内容,再对描述文本做 embedding。
可以用下面这种方式直观理解:
text
8 个关键帧
-> 8 个 embedding
-> 加权平均
-> 视频 embedding如果视频内容很长,单一向量可能会丢失细节。更稳妥的方式是分段抽帧,每段保留一个向量和一个时间戳,命中以后可以回到具体片段。
五、切片策略、页面结构与质量控制
切片策略为什么重要
知识切片是 RAG 系统的核心环节,直接影响检索质量和回答准确性。
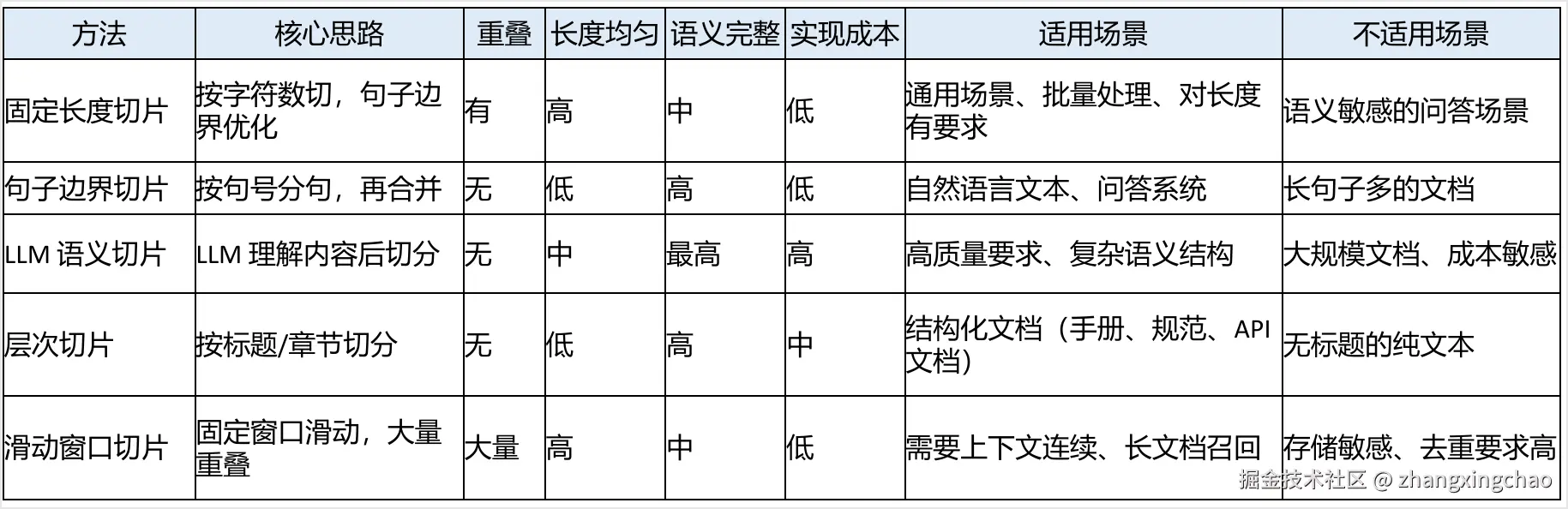
常见切片方法有五种:
- 固定长度切片。
- 句子边界切片。
- LLM 语义切片。
- 层次切片。
- 滑动窗口切片。
固定长度切片
按固定字符数切分文本,可以带 overlap,也可以优先在句子边界附近切,避免强行切断句子。
优点是实现简单、速度快、长度统一,适合批量处理技术文档和规范文件。
缺点是语义不一定完整,容易把一个完整知识点切断。
句子边界切片
按句号、段落等自然语言边界切分,再合并成 chunk。
优点是语义保持好,适合自然语言文本和问答系统。
缺点是长度可能不均匀。如果文档里长句很多,chunk 会变得不好控制。
LLM 语义切片
让 LLM 理解内容后按语义切分。
Prompt 可以这样写:
text
请将以下文本按照语义完整性进行切片,每个切片不超过 {max_chunk_size} 字符。
要求:
1. 保持语义完整性。
2. 在自然的分割点切分。
3. 返回 JSON 格式的切片列表。
文本内容:
{text}
请返回 JSON:
{
"chunks": [
"第一个切片内容",
"第二个切片内容"
]
}优点是语义完整性最好,适合复杂结构和高质量要求。
缺点是成本高、速度慢,不适合大规模文档全部这么处理。
层次切片
按标题、章节、段落切分,保留文档结构。
适合手册、规范、API 文档等结构清晰的材料。
缺点是依赖文档本身有标题层级。如果是一坨无标题纯文本,就不太适合。
滑动窗口切片
使用固定大小窗口在文本上滑动,产生大量重叠内容。
优点是上下文连续,长文档召回时不容易漏信息。
缺点是冗余多、存储成本高、去重压力大。
切片大小怎么选
没有通用的固定答案。
笔记里提到 300 和 800 这样的数字,本质上是在提醒:chunk 大小要测试。
可以这样理解:
- chunk 太小:召回更细,但上下文不完整,LLM 可能缺背景。
- chunk 太大:上下文完整,但噪声更多,检索命中不够精确。
- overlap 太小:容易断上下文。
- overlap 太大:重复内容太多,索引变大,召回结果也可能重复。
- step_size 不能太小,否则滑动窗口会产生大量高度重复的 chunk。
实际项目中,最好准备一组测试问题,比较不同 chunk_size、overlap 和切分策略下的命中率与回答质量。
PageIndex 和 RAG 是替代关系吗
PageIndex 更像是对 RAG 的增强,而不是替代。
普通 RAG 只把文档切成文本块,容易丢掉页面结构、图片位置、表格关系和页码信息。
PageIndex 更关注页面级组织:这一页有哪些区域、哪些文本、哪些图片、哪些表格,它们之间的位置关系是什么。对于 PDF、扫描件、报告、论文、说明书这类版式复杂的资料,页面结构非常重要。
可以这样理解:
text
RAG:更关注知识片段能不能被检索到。
PageIndex:更关注页面结构、版面位置和引用回溯。两者可以结合使用:先用 PageIndex 保存页面结构和定位信息,再把文本块、图片块、表格块送进 RAG 检索系统。
知识冲突和噪声怎么处理
如果检索内容中混入虚假信息、过时信息或噪声,LLM 本身的防御能力有限。
更可靠的做法是在 RAG 流程里增加控制:
- 来源分级:官方文档优先,用户评论和普通网页降权。
- 时间过滤:过期文档不要进入检索,或在 metadata 里标记版本。
- 规则校验:关键字段用程序校验,不只靠模型判断。
- 多来源交叉验证:多个来源冲突时,提示冲突而不是强行合并。
- LLM 自检:让模型列出依据、冲突点和不确定项。
- 人工审核:高风险答案不要自动执行。
知识冲突可以用 prompt 让 LLM 辅助发现,但不要只靠 prompt。真正稳定的系统,需要依赖数据治理、权限控制、版本管理和来源可信度。
专利检索为什么效果不佳
专利检索如果只做普通 embedding 相似度,效果可能不稳定。
原因是专利文本通常有这些特点:
- 句子长。
- 术语多。
- 表达绕。
- 同义改写很多。
- 法律边界和技术边界都很重要。
可以从以下几个方向优化:
- 使用更适合技术文本的 embedding 模型。
- 做 query 改写,把用户问题改成专利检索式。
- 做混合检索,结合关键词、BM25、向量检索。
- 增加 rerank 模型。
- 保存 IPC 分类号、申请人、年份、领域等 metadata。
- 用结构化字段过滤后再做向量召回。
只依赖一个向量库,很难把专利检索做好。
六、工程实现、概念辨析与最终链路
Skills 和 Function Call 的关系
笔记里提到一个说法:
text
skills = 高阶版的 function call可以这样理解:
Function Call 更像是"模型可以调用一个函数"。函数通常是代码里预先注册好的工具。
Skill 更像是"一个可复用任务能力包",通常包括:
- 独立脚本。
- 使用说明。
- 输入输出约定。
- 何时触发。
- 任务流程。
所以 Skill 不只是一个函数,而是把一类任务的流程和工具封装起来,供模型按需加载。
用 AI 编程工具写这类代码,应该怎么提需求
不需要把所有 RAG 和 Agent 代码都手敲一遍。
更实际的做法是:先理解整体流程,再让 AI 编程工具辅助实现。
给 AI 的提示词需要包含技术关键词,并明确输入和输出要求。例如:
text
我打算构造一个多模态向量数据库,使用 FAISS。
数据源在 disney_knowledge_base 文件夹中,里面有 Word 文档、图片和视频 URL。
请参考这些已有代码:
@1-文本embedding.py
@2-图片embedding.py
@3-视频embedding.py
要求:
1. 解析 Word 文档,提取段落和表格。
2. 文本按 chunk_size=500、overlap=50 切分。
3. 图片转 Base64 后调用 tongyi-embedding-vision-plus。
4. 视频用 URL 调用多模态 embedding。
5. 所有向量写入 FAISS。
6. metadata 单独保存为 JSON。
7. 最后持久化为 disney_index.faiss 和 disney_metadata.json。如果已经有旧代码,可以直接引用旧代码,让 AI 在旧代码基础上修改,这通常比从零描述所有细节更稳。
几个容易混淆的问题
Tongyi 只能用 DashScope 上的模型吗
调用方式取决于平台和 SDK。DashScope 是阿里云提供的模型服务接口,ModelScope 则更偏模型托管和开源模型生态。实际项目里要区分"模型在哪里""通过什么 API 调用""是否本地部署"这几件事。
多模态向量是不是固定 768 维
不一定。
不同模型的向量维度不同,例如 768、1024、1152、2048 都可能出现。维度不是越高越好,最终要看检索效果、成本、速度和存储压力。
图片 embedding 会有 chunk 过程吗
文本通常需要 chunk,因为文本可能很长。
图片一般一张图可以看成一个 chunk。如果图片本身很复杂,也可以先做 OCR、区域切分、图像描述,再把不同区域或描述作为多个 chunk。
视频是否可以理解为多张图片
可以这样近似理解:
视频包含多个帧,也包含时间顺序。工程上经常抽关键帧做 embedding,再聚合成视频向量。但如果模型支持视频输入,也可以直接让模型处理视频 URL。
Base64 会不会太大
Base64 是原始图片的一种编码方式,体积确实会比较大。但最终进入向量库的是 embedding,不是 Base64 字符串本身。
Base64 常用于把图片传给接口。原始图片仍然要作为文件保存,向量库只负责检索。
图像转文本是不是更好
不一定。
图像转文本的可解释性更好,也能提取关键词,但一定会丢失部分视觉信息。图片 embedding 保留视觉语义更好,但不好解释。实际项目里可以两者结合。
意图识别怎么做
简单方式是关键词匹配:
python
IMAGE_KEYWORDS = ["图片", "海报", "照片", "看看", "长什么样"]
VIDEO_KEYWORDS = ["视频", "录像", "播放"]更复杂的方式是让 LLM 输出结构化判断:
json
{
"want_image": true,
"want_video": false,
"reason": "用户明确询问活动海报"
}关键词方式便宜、稳定,但覆盖不全。LLM 方式灵活,但成本更高,也要防止误判。
FAISS 里存 metadata 吗
FAISS 本身不负责完整业务 metadata 管理。一般做法是:
python
metadata_store = []向量进 FAISS,metadata 进 JSON 或数据库。检索命中向量 ID 后,再用 ID 找 metadata。
为什么相似度越大,答案反而不准
相似度只说明"向量空间里接近",不等于业务答案一定正确。
可能原因包括:
- query 本身不清楚。
- chunk 切得不好。
- embedding 模型不适合业务。
- 文本、图片、视频混在一起后没有做类型筛选。
- metadata 没有参与过滤。
- 缺少 rerank。
- prompt 没有要求严格基于资料回答。
所以检索系统不能只看相似度分数,还要看召回内容、类型、来源和业务约束。
RAG 联网检索如何防虚假信息
联网搜索需要更谨慎。
可以把来源分成等级:
text
官方渠道
> 权威媒体 / 平台
> 普通网页
> 用户评论如果不同来源冲突,应该提示"不一致",而不是让模型硬编一个统一答案。
Native RAG 是什么
Native RAG 可以理解为朴素 RAG 或原生 RAG:自己控制解析、切分、向量化、索引、检索、prompt 组装和生成,不完全依赖上层框架。
它的好处是流程透明,适合学习底层逻辑和做定制化系统。
最终链路
把前面的内容串起来,一个多模态 RAG 助手的整体链路大致如下:
text
数据层
-> 解析 Word / PDF / 图片 / 视频
-> 文本切分,图片和视频保留原始文件
-> 表格转 Markdown,图片可做 OCR 或图像描述
向量化层
-> 使用多模态 Embedding
-> 文本、图片、视频映射到统一向量空间
-> 写入 FAISS
-> metadata 单独保存
检索层
-> 用户 query 转向量
-> FAISS 做 L2 距离检索
-> 文本取 Top-K
-> 根据意图筛选图片或视频
-> 按距离阈值过滤低相关媒体
生成层
-> Top-K 文本构建上下文 prompt
-> LLM 生成回答
-> 自动附加匹配到的图片或视频链接一句话总结:
text
多模态 RAG = 文档解析 + 多模态 Embedding + 统一向量索引 + 元数据回溯 + LLM 生成如果只记住几个关键点,可以记这些:
- 多模态 LLM 负责理解和生成,多模态 Embedding 负责检索和匹配。
- 文本、图片、视频可以进入同一个向量空间,前提是模型支持跨模态对齐。
- FAISS 只解决向量检索,原始文本、图片、视频和 metadata 要单独保存。
- 图片可以直接 embedding,也可以先转文本,实际项目里常常两者结合。
- 视频可以直接输入模型,也可以抽关键帧再聚合向量。
- 统一索引后要做类型筛选,否则图片、视频、文本容易互相干扰。
- chunk 切分没有固定最优解,要根据测试问题集调。
- 权威来源、版本、权限、metadata,比单纯相似度更重要。
- 多模态 RAG 的目标不是"让模型看起来很聪明",而是让它能在复杂资料里找到正确证据,并把答案和证据一起交付。 AI应用开发四:RAG多模态数据处理