一、背景介绍
在现代前端与 Node.js 生态中,版本号管理与变更日志维护是保障依赖一致性、提升协作透明度的核心环节。尤其是在 Monorepo 架构下,多包之间的版本协同、依赖升级与发布节奏控制变得尤为复杂。
在 Changesets 出现之前,大多数项目要么依赖手动修改版本号、零散维护变更日志,要么使用早期工具(如 Lerna)进行批量处理。然而这些方案普遍存在以下痛点:
- 版本号与实际变更不匹配:开发者难以准确判断某次改动应触发哪个包的版本升级;
- 依赖升级遗漏:跨包依赖关系处理不够精细,导致消费者安装到不兼容版本;
- 变更日志质量低下:CHANGELOG 沦为 commit 消息的简单堆砌,缺乏可读性;
- 发布节奏僵化:无法灵活控制"何时发、发哪些、怎么发"。
正是为了解决这些痛点,Changesets 应运而生。它以结构化的"变更集"(Changeset)记录为核心,规范了变更说明的收集流程,同时提供自动化版本计算、变更日志生成、跨包依赖同步升级等能力,为 Monorepo 项目提供了一套标准化、可扩展的版本管理与发布工作流方案。
二、方案分析:三代工具的演进与选择
单包项目的版本管理很简单:改了什么 → 升什么版本 → 发布。但 Monorepo 引入了三个本质难题:
- 变更归属:一次提交可能改了多个包,怎么知道哪个包该升版本、升什么级别?
- 依赖传导:包 A 升了 major,依赖它的包 B 和包 C 的版本范围要不要更新?怎么更新?
- 发布粒度:多个包有变更,是一次全发,还是只发有变化的?它们的版本号怎么保持语义连贯?
这三个问题叠加在一起,让 Monorepo 的版本管理从"简单计算"变成了"需要上下文判断的决策"。对此,社区经历了三代工具的递进。
2.1 手动和批处理时代:Lerna
Lerna 是 Monorepo 管理的开山之作,核心贡献是解决了"批量操作"问题。它的 lerna version 会遍历所有包,交互式询问每个包升什么版本,然后统一打 tag、统一发布。
然而,Lerna 的局限并非"依赖 commit 消息",而是更深层的设计问题:
- 版本决策依赖人工记忆:开发者要自己记住改了哪个包、改了什么性质,在发布时一次性回顾并选择。这在包多、迭代快的场景极易出错。
- 无变更上下文沉淀:发完就完了,没有留下"为什么升 minor 而不是 patch"的记录。CHANGELOG 的生成能力很弱,只是 commit 消息的简单拼接。
- 依赖联动粗糙:能更新内部依赖的版本范围,但缺乏"包 A 是 breaking change,所以依赖它的包 B 也应该升 major"这样的语义判断。
Lerna 后来推出的 --conventional-commits 模式试图用提交解析来缓解第一个问题,但它仍然只是把"事后人工判断"变成了"事后机器判断",没有解决上下文沉淀和依赖联动的问题。后来 Lerna 维护停滞,对 pnpm、yarn workspace 等现代工具的原生支持也不够好。
2.2 提交驱动时代:Semantic Release 与 Release It
代表工具有 Semantic Release 、Release It ,以及 Monorepo 场景下的 Bumpy 、FerrFlow 等。
这类工具的核心思想是:如果团队的提交信息足够规范,就能从提交历史中自动推导一切。工作流程通常是:
- 严格遵循 Conventional Commits(
feat:→ minor,fix:→ patch,BREAKING CHANGE:→ major); - 发布时工具分析自上次发布以来的所有 commit;
- 自动计算每个包的版本号;
- 自动生成 CHANGELOG;
- 自动发布。
这个范式在单包项目非常成功,但在 Monorepo 场景有三个不可回避的短板:
- 变更归属困难 :你怎么从 commit 消息知道这次改动影响的是哪个包?常见的做法是在 commit message 里加 scope(如
feat(ui): add button),但这依赖于开发者严格、准确地标注。一旦忘记或标错,版本就乱了。 - 跨包依赖的语义理解缺失:假设包 A 改了内部数据结构的类型定义,这是一个 breaking change。包 B 并没有修改任何代码,但它引用了这个类型。提交驱动的工具很难判断"包 B 虽然没有 commit 变更,但因为依赖的 A 破了,B 也应该升 major"。它看到的只是包 B 目录没有 commit,所以不升版本。这可能导致发布后包 B 的消费者遭遇类型错误。
- 缺乏人机协作的缓冲带:有时一个 PR 同时包含 feat 和 fix,你希望合并成一次 minor 发布;有时需要将多个 PR 攒成一个大版本发布。提交驱动模式下,这些灵活控制很难实现,要么提前 squash commit,要么在发布时手动干预,破坏了自动化流程的完整性。
2.3 意图驱动时代:Changesets
代表工具有 Changesets(以及 pnpm、Turborepo、Nx 等现代工具链的内置集成功能)。
Changesets 做了一个范式层面的转换 :不从事后的机器记录(commit)中反推意图,而是在开发的当下,让开发者显式声明意图。
核心机制是**"变更集"(Changeset)**。开发者在提交代码时,运行 changeset add,交互式选择"我改了哪些包"、"分别是什么性质的变更(major/minor/patch)"、"写一段给用户看的变更说明"。工具生成一个独立的 Markdown 文件存在 .changeset/ 目录下,随代码一起提交。发布时,changeset version 消费所有这些变更集,统一计算版本号、更新内部依赖、生成 CHANGELOG,然后消费掉这些文件。
这个设计一举解决了前两代方案的核心痛点:
① 变更归属精确到包
因为是开发者主动选择,不存在"从 commit message 猜测影响范围"的歧义。一个 PR 改了 5 个包,可以分别记录 5 个变更集,各自声明变更类型。
② 跨包依赖联动有语义依据
Changesets 在消费变更集时,会分析整个仓库的依赖图。如果包 A 被标记为 major 变更,工具会自动更新所有依赖 A 的包的版本范围(从 ^1.0.0 变成 ^2.0.0)。虽然它不会自动给依赖方也升 major(这仍需人工判断),但至少保证了消费者不会安装到不兼容的新版本。这种"依赖图感知"的能力是提交驱动很难做到的。
③ 版本决策与发布节奏解耦
变更集文件是一种"意图的持久化"。你可以今天记录 3 个 patch 级别的变更,下周转为 1 个 minor 发布;也可以把多个贡献者的变更集攒到一起,统一发一个大版本。版本决策不再是"发布瞬间一次性拍脑袋",而是分散在日常开发中,发布时只需汇总执行。
④ 变更上下文成为一等公民
每个变更集都强制要求写一段面向用户的说明。这让 CHANGELOG 的质量从"commit 消息的堆砌"变成了"有可读性的产品变更记录"。对于开源项目或需要对外沟通的产品团队,这个价值很大。
2.4 从设计哲学看工具的选择
| 维度 | 提交驱动 | 意图驱动(Changesets) |
|---|---|---|
| 信息来源 | commit 记录(机器语言) | 变更集文件(人机共同语言) |
| 决策时机 | 发布时集中计算 | 开发时分散声明,发布时汇总 |
| 精确度 | 依赖 discipline,易出错 | 依赖工具引导,出错率低 |
| 跨包依赖处理 | 弱,只能分析"哪些目录有 commit" | 强,能结合依赖图做语义判断 |
| 灵活性 | 受限于 commit 粒度 | 变更集与 commit 多对多,灵活组合 |
| CHANGELOG 质量 | commit 消息拼凑,噪音多 | 专门撰写的用户面向说明,可读性好 |
| 开发者负担 | 要求严格遵循提交规范 | 每次改动后多一步 changeset add |
Changesets 不是什么"银弹",它也有代价:增加了开发流程中的一步操作(虽然很轻量);变更集文件可能产生合并冲突(但团队习惯后处理不难);对于极小团队或纯个人项目,可能觉得仪式感过重。但放在它要解决的那个问题域里------多人协作、多包耦合、需要可追溯的版本历史和可读的 CHANGELOG------这个代价换来的确定性和灵活性,是目前所有方案中性价比最高的。
2.5 现代工具链的收敛趋势
值得注意的是,2023 年以后,Monorepo 工具的版本管理能力在趋同:
- Nx 在 v17 后推出了
nx release,既可以按提交驱动,也支持类似 Changesets 的独立版本文件; - Turborepo 官方推荐 Changesets 作为版本管理方案;
- pnpm 原生支持 workspace,和 Changesets 集成非常顺畅;
- Lerna 在 Nrwl 接手后复活,也开始内建对 Changesets 类工作流的支持。
这说明**"意图驱动"正在成为社区共识的方向**。提交驱动更适合单包或规则非常明确的场景,而一旦进入多包协同、需要人判断的复杂度,显式声明意图的优势就凸显出来了。
三、实操步骤:从零搭建 Changesets 工作流
这里从零开始,一步步搭建一个最小的 Monorepo 项目,并完整走通 Changesets 的工作流。
3.1 第一阶段:创建 Monorepo 项目
第一步:初始化项目
打开终端,创建一个新目录并初始化:
bash
mkdir changeset-demo
cd changeset-demo
pnpm init这会在根目录生成一个 package.json,内容如下:
json
{
"name": "changeset-demo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}第二步:配置 pnpm workspace
创建 pnpm-workspace.yaml 文件,告诉 pnpm 哪些目录是子包:
yaml
packages:
- "packages/*"这意味着 packages/ 目录下的所有文件夹都会被视为独立的包。
第三步:创建两个子包
我们会创建两个包来模拟真实场景:utils(工具函数库,被依赖的一方)和 app(应用代码,依赖 utils 的一方)。
bash
mkdir -p packages/utils
mkdir -p packages/app第四步:编写 utils 包
packages/utils/package.json:
json
{
"name": "@my/utils",
"version": "1.0.0",
"main": "index.js",
"license": "MIT"
}packages/utils/index.js:
javascript
// 当前只有一个简单的函数
function greet(name) {
return `Hello, ${name}!`;
}
module.exports = { greet };第五步:编写 app 包
packages/app/package.json:
json
{
"name": "@my/app",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"dependencies": {
"@my/utils": "workspace:*"
}
}注意 "workspace:*"------这是 pnpm 的特殊语法,表示依赖本地的 @my/utils 包,安装时会自动链接到本地。
packages/app/index.js:
javascript
const { greet } = require("@my/utils");
console.log(greet("World"));第六步:安装依赖并测试
运行 pnpm install 命令安装依赖。安装完成后,目录结构是:
changeset-demo/
├── package.json
├── pnpm-workspace.yaml
├── pnpm-lock.yaml
├── node_modules/
└── packages/
├── utils/
│ ├── package.json
│ └── index.js
└── app/
├── package.json
└── index.js验证一下:
bash
node packages/app/index.js
# 输出: Hello, World!Monorepo 的基础项目就搭好了,@my/app 成功引用了本地的 @my/utils。
3.2 第二阶段:接入 Changesets
第七步:安装 Changesets
bash
pnpm add -Dw @changesets/cli-D 是开发依赖,-w 是安装在 workspace 根目录。
第八步:初始化 Changesets
bash
pnpm changeset init这会在根目录生成 .changeset/ 文件夹,里面有一个 config.json 文件。打开 .changeset/config.json,保持默认就好:
json
{
"$schema": "https://unpkg.com/@changesets/config@3.1.1/schema.json",
"changelog": "@changesets/cli/changelog",
"commit": false,
"fixed": [],
"linked": [],
"access": "restricted",
"baseBranch": "main",
"updateInternalDependencies": "patch",
"ignore": []
}3.3 第三阶段:模拟一次真实的开发和发布
假设我们现在要给 utils 包新增一个功能:添加一个 farewell 函数。
第九步:修改代码
编辑 packages/utils/index.js,新增一个函数:
javascript
function greet(name) {
return `Hello, ${name}!`;
}
// 这是我们新增的功能
function farewell(name) {
return `Goodbye, ${name}!`;
}
module.exports = { greet, farewell };第十步:添加变更集
代码改完了,现在我们要告诉 Changesets:"我改了 @my/utils,这是一个新功能"。执行 pnpm changeset add 命令,终端会进入交互模式:
🦋 Which packages would you like to include? ...
◯ changed packages
◉ @my/utils ← 用空格选中/取消,不想选直接按 enter 键
◯ unchanged packages
◯ @my/app
🦋 Which packages should have a major bump? ...
◯ all packages ← 用空格选中/取消,不想选直接按 enter 键
◯ @my/utils@1.0.0
🦋 Which packages should have a minor bump? ...
◯ all packages
◉ @my/utils@1.0.0
🦋 The following packages will be patch bumped:
🦋 @my/app@1.0.0
🦋 Please enter a summary for this change (this will be in the changelogs).
🦋 (submit empty line to open external editor)
🦋 Summary › 新增 farewell 函数,用于发送告别消息注意,change 有三种类型,分别是 patch (修复 bug)、minor (新增功能)、major(破坏性变更)。
完成后,.changeset/ 目录下会多出一个文件,文件名是随机生成的,比如 .changeset/tiny-bears-sing.md,内容自动生成:
markdown
---
"@my/utils": minor
---
新增 farewell 函数,用于发送告别消息这就是**"变更集"**------它记录了你的意图,但还没有真正改变任何版本号。
第十一步:提交代码
bash
git init
git add .
git commit -m "feat(utils): 新增 farewell 函数"注意:变更集文件也一并提交了。
3.4 第四阶段:执行发布(模拟)
现在我们"发布"。因为我们没有真的 npm 账号,所以只执行到版本号更新这一步,看看 Changesets 做了什么。
第十二步:消费变更集,生成版本
执行 pnpm changeset version 命令,观察终端输出和文件变化,你会发现:
① packages/utils/package.json 版本号变了:
json
{
"name": "@my/utils",
"version": "1.1.0", // ← 从 1.0.0 自动升到 1.1.0(minor)
"main": "index.js",
"license": "MIT"
}② packages/utils/CHANGELOG.md 自动生成了:
markdown
# @my/utils
## 1.1.0
### Minor Changes
- 新增 farewell 函数,用于发送告别消息③ .changeset/tiny-bears-sing.md 被删除了。(变更集已被消费)
第十三步:提交版本更新
在实际项目中,版本更新需要作为一个单独的 commit 提交:
bash
git add .
git commit -m "chore: release"第十四步:发布(如果有 npm 账号的话)
执行 pnpm changeset publish 命令,它会自动把 @my/utils@1.1.0 发布到 npm。因为我们没有配置,所以这步跳过。
3.5 完整流程图解
修改代码 → changeset add(记录意图) → git commit(代码+变更集)
↓
合并到主分支
↓
changeset version(消费变更集,生成版本)
↓
git commit(版本更新)
↓
changeset publish(发布到 npm)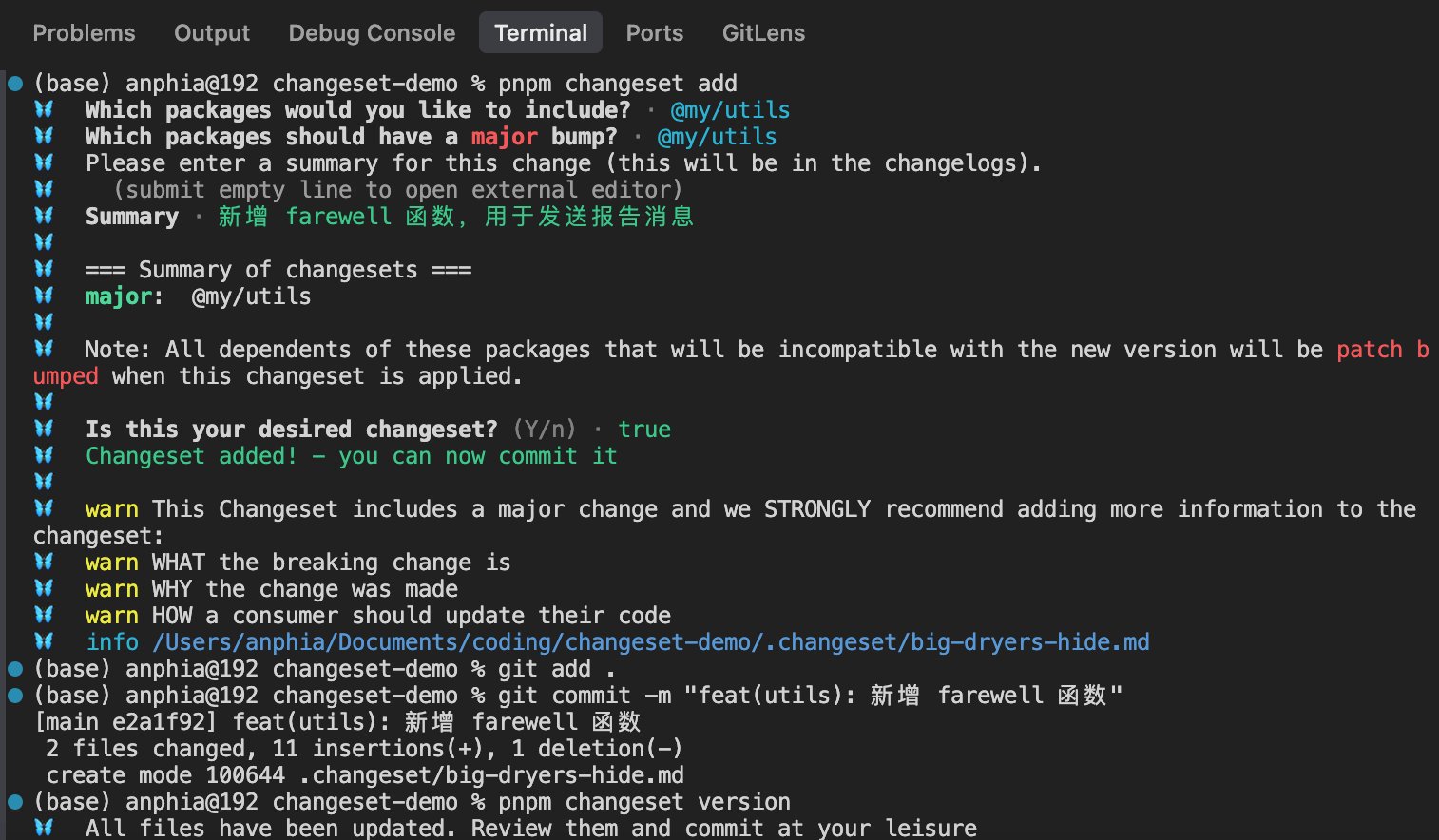
四、验证效果:Changesets 解决了什么问题
通过上面的实操,我们可以验证 Changesets 的核心价值:
| 场景 | 传统方式的问题 | Changesets 的解决方式 |
|---|---|---|
| 多包变更归属 | 靠 commit message 猜测,容易遗漏或误判 | 开发者显式选择,精确到包 |
| 版本号计算 | 人工记忆,发布时集中决策,易出错 | 变更集自动汇总,语义化计算 |
| CHANGELOG 质量 | commit 消息堆砌,噪音多 | 面向用户的说明,可读性好 |
| 依赖联动 | 手动更新版本范围,容易遗漏 | 自动分析依赖图,同步更新范围 |
| 发布节奏 | 受限于 commit 粒度,不灵活 | 变更集可攒可拆,灵活组合 |
五、总结与最佳实践
Changesets 的核心设计哲学是**"意图的显式声明"**。它不把版本管理交给事后的机器推断,而是在开发当下就让人参与决策,同时用工具保证决策的规范性和一致性。
对于正在使用或计划使用 Monorepo 的团队,以下是一些实践建议:
- 把
changeset add纳入代码审查流程:在 PR 模板中提醒贡献者"如果改了包的 API,请记得添加变更集"; - 版本更新作为独立 commit :
changeset version生成的改动单独提交,保持历史清晰; - 结合 CI/CD 自动化 :在合并到主分支后自动执行
changeset version和changeset publish,减少人工操作; - 团队共识优先:变更集的质量取决于开发者写的说明,建议制定内部的变更说明规范。