RAG 真正难的地方,往往不是"把文档塞进向量库"这一步,而是系统上线以后怎么持续变准、变稳、变可维护。
一个最朴素的 RAG 流程可以拆成三段:
text
Indexing -> 怎么把知识更好地存起来
Retrieval -> 怎么从大量知识里找到少量有用内容
Generation -> 怎么结合用户问题和检索结果生成答案这三段看起来简单,但只要进入真实业务,就会遇到一堆工程问题:用户问法和知识切片对不上、对话里产生的新知识没有沉淀、知识库里有过期和冲突内容、版本更新后不知道效果有没有变差、召回结果太多太杂、单纯向量检索漏掉关键词、长文档上下文塞不进去、宏观问题又很难靠几个 chunk 回答。
所以 RAG 调优不能只盯着单一参数,例如 TopK、chunk size 或相似度阈值。更合理的看法是把 RAG 看成一条完整链路:
知识库处理 -> 高效检索/召回 -> Rerank 精排 -> GraphRAG 关系增强与全局理解 -> Agentic RAG 动态决策。
其中,知识库处理解决"知识本身是否可靠、可维护";高效检索解决"能不能找得到";Rerank 解决"找出来后能不能排得准";GraphRAG 解决"跨文档、跨实体、跨关系的全局理解";Agentic RAG 解决"检索流程是否可以根据问题动态规划"。
下面按这条链路,把 RAG 高级技术和调优方法整理一遍。
一、整体框架:先建立 RAG 调优的全局认识
1. RAG 调优先看全局
RAG 调优可以分成四组能力。
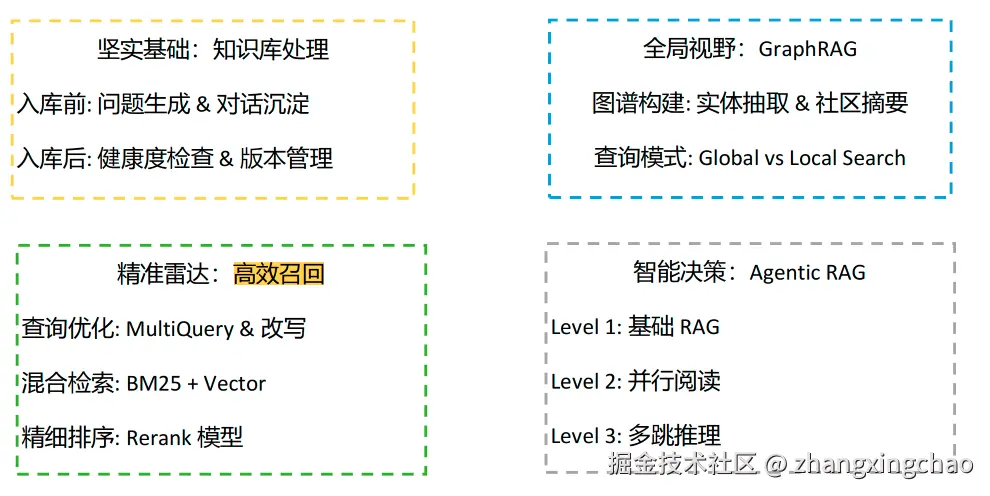
第一组是知识库处理。它解决的是"知识本身靠不靠谱、能不能持续维护"的问题,包括问题生成、对话沉淀、知识健康度检查、版本管理等。
第二组是高效检索与精排。它解决的是"相关内容能不能被找出来、找出来以后能不能排得准"的问题,包括 MultiQuery、多路召回、BM25 + Vector 混合检索,以及 Rerank 精排。
第三组是GraphRAG。它解决的是"跨文档、跨实体、跨关系的全局理解"问题。相比普通 RAG 主要依赖文本切片和相似度检索,GraphRAG 会进一步抽取实体、关系和主题结构,更适合大量文档中的宏观总结、关系分析和复杂推理。
第四组是Agentic RAG。它解决的是"检索流程是否固定"的问题。Native RAG 通常是固定流程,例如用户提问后直接检索、拼接上下文、生成回答;Agentic RAG 则让模型动态判断是否需要检索、调用哪个检索工具、是否进行问题改写、多跳查询或多轮检索。简单说,Native RAG 是流程驱动,Agentic RAG 是模型决策驱动。
这不是互相替代,而是 RAG 系统逐步增强的一条工程路线: 知识库处理 → 高效召回 → Rerank 精排 → GraphRAG 关系理解 → Agentic RAG 动态决策
RAG 不是一个单点工具,而是一套知识工程系统。
二、知识库建设与治理:让知识更容易被检索、更可靠、更可维护
1. 为什么要给知识切片生成问题
普通 RAG 通常直接把原始 chunk 做 embedding。问题是,用户的提问方式未必和原文长得像。
例如原始知识是:
text
创极速光轮位于明日世界,是上海迪士尼乐园中速度感较强的项目之一。用户可能会问:
text
如果我想体验最刺激的过山车,应该去哪个区域?这句话里没有"创极速光轮",也没有"明日世界",单靠原文相似度可能召回不稳。
一个实用做法是:为每个知识切片提前生成若干个"这个 chunk 能回答的问题"。入库时不只存原文特征,也存这些问题的特征。用户提问时,query 更容易和"生成的问题"匹配上。
整体逻辑是:
text
原始 chunk
-> LLM 生成 5 到 8 个可能问题
-> 原文建索引
-> 问题也建索引
-> 用户 query 同时检索原文和问题
-> 命中问题后,回到原始 chunk注意最后一步:返回给大模型的通常还是原文 chunk,不是生成的问题。生成的问题更像"检索入口",作用是帮系统更容易找到原始知识。
生成基础问题
可以先做一个基础版本,为每个 chunk 生成 5 个问题。
python
def generate_questions_for_chunk(knowledge_chunk: str, num_questions: int = 5):
instruction = """
你是一个专业的问答系统专家。给定一段知识内容,请判断它能够回答哪些问题。
问题需要满足:
1. 使用不同问法,例如直接问、间接问、对比问、条件问。
2. 避免重复和相似问题。
3. 不要超出知识内容本身。
4. 返回 JSON 格式。
"""
prompt = f"""
### 指令 ###
{instruction}
### 知识内容 ###
{knowledge_chunk}
### 生成问题数量 ###
{num_questions}
### 返回格式 ###
{{
"questions": [
{{
"question": "问题内容",
"question_type": "直接问/间接问/对比问/条件问",
"difficulty": "简单/中等/困难"
}}
]
}}
"""
response = get_completion(prompt)
response = preprocess_json_response(response)
return json.loads(response)["questions"]比如关于上海迪士尼的 chunk,可以生成这些问题:
text
1. 上海迪士尼乐园是什么时候开园的?
2. 中国大陆第一座迪士尼乐园在哪里?
3. 上海迪士尼和其他迪士尼相比有什么特殊意义?
4. 如果想游览全部主题园区,需要了解哪些区域?
5. 上海迪士尼乐园占地多少公顷?生成更多样化的问题
如果想让检索覆盖更多问法,可以把问题类型扩展到假设问、推理问、规划问等,并要求模型返回答案、角度、是否可回答。
python
def generate_diverse_questions(knowledge_chunk: str, num_questions: int = 8):
prompt = f"""
你是一个专业的问答系统专家。请为给定知识内容生成高度多样化的问题。
要求:
1. 问题类型多样:直接问、间接问、对比问、条件问、假设问、推理问。
2. 表达方式多样:不要只替换几个词,要换不同句式。
3. 难度层次多样:简单、中等、困难都要有。
4. 角度多样:时间、地点、用途、规划、限制、意义都可以覆盖。
5. 不能编造知识内容之外的信息。
### 知识内容 ###
{knowledge_chunk}
### 生成数量 ###
{num_questions}
### 返回 JSON ###
{{
"questions": [
{{
"question": "问题内容",
"question_type": "问题类型",
"difficulty": "难度等级",
"perspective": "提问角度",
"is_answerable": true,
"answer": "基于该知识的回答"
}}
]
}}
"""
response = get_completion(prompt)
return json.loads(preprocess_json_response(response))["questions"]这个方法本质上就是 Doc2Query。它不是为了让模型"凭空知道更多",而是给原有知识增加更多可匹配的入口。
原文检索和问题检索的效果对比
材料里的示例用 BM25 做了对比:原文检索准确率是 66.7%,问题检索准确率是 100%。尤其是"如果我想体验最刺激的过山车,应该去哪个区域?"这种口语化问题,问题索引明显更容易命中。
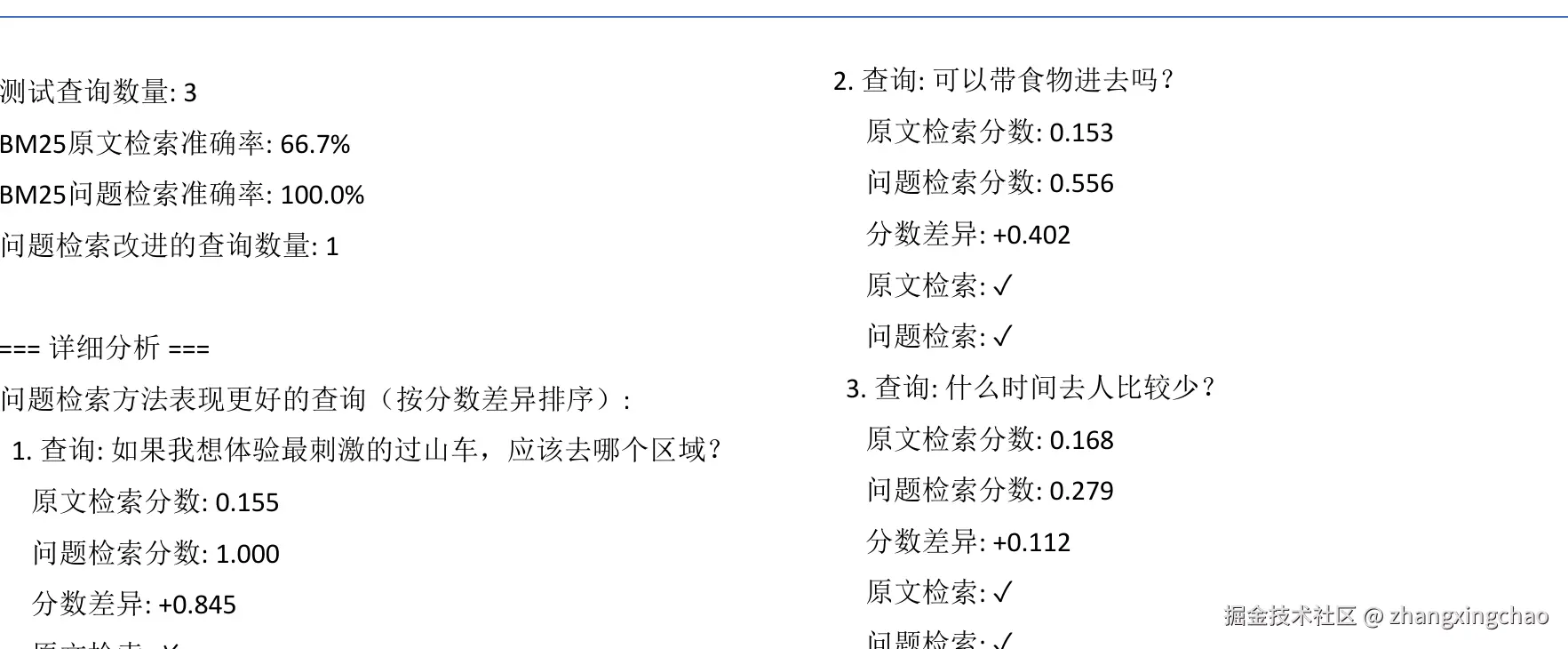
这里的关键不是具体数字,而是思路:
text
原文 chunk 适合保真
生成问题适合召回
命中问题以后再回到原文2. 对话知识沉淀:把线上问答变成知识库
产品上线以后,每天会产生大量用户对话。里面有很多信息不应该只停留在聊天记录里,比如:
- 用户反复问到的新问题。
- 客服临时补充的规则。
- 某个流程的真实操作步骤。
- 高频误解和注意事项。
- 某些知识库没有覆盖到的内容。
对话知识沉淀的目标是:从对话里提取稳定、有复用价值的知识,再合并、过滤、入库。
从单次对话中提取结构化知识
可以让 LLM 把一段对话整理成结构化 JSON。
python
def extract_knowledge_from_conversation(conversation: str):
prompt = f"""
你是一个专业的知识提取专家。请从给定对话中提取有价值的知识点。
可提取的知识类型包括:
1. 事实性信息:地点、时间、价格、规则等。
2. 用户需求和偏好。
3. 常见问题和解答。
4. 操作流程和步骤。
5. 注意事项和提醒。
### 对话内容 ###
{conversation}
### 返回 JSON ###
{{
"extracted_knowledge": [
{{
"knowledge_type": "事实/需求/问题/流程/注意",
"content": "知识内容",
"confidence": 0.0,
"source": "用户/AI/对话",
"keywords": ["关键词1", "关键词2"],
"category": "分类"
}}
],
"conversation_summary": "对话摘要",
"user_intent": "用户意图"
}}
"""
response = get_completion(prompt)
return json.loads(preprocess_json_response(response))例如用户询问上海迪士尼门票、预订和交通方式,系统可以提取出:
text
事实:成人票价格、儿童票价格、免票规则
流程:从浦东机场坐地铁或打车到迪士尼
注意:周末和节假日建议提前预订
摘要:用户在规划迪士尼出行
意图:了解票价、购票建议和交通方式过滤临时信息
不是所有对话内容都适合入库。需求和问题往往是临时的、个性化的,不一定要作为知识沉淀。
python
filtered_knowledge = [
item for item in knowledge_list
if item.get("knowledge_type") not in ["需求", "问题"]
]这一步很重要。知识库应该沉淀"稳定知识",而不是把每一个用户的临时想法都塞进去。
合并相似知识
不同对话里可能反复出现同类信息,比如门票、交通、停车、携带食物。可以先按知识类型分组,再用 LLM 合并相似内容。
python
def merge_similar_knowledge(filtered_knowledge):
knowledge_by_type = {}
for item in filtered_knowledge:
knowledge_type = item.get("knowledge_type", "其他")
knowledge_by_type.setdefault(knowledge_type, []).append(item)
merged_knowledge = []
for knowledge_type, group in knowledge_by_type.items():
if len(group) == 1:
merged_knowledge.append(group[0])
else:
merged = merge_knowledge_with_llm(group, knowledge_type)
merged_knowledge.append(merged)
return merged_knowledge合并提示词可以这样写:
text
你是一个专业的知识整理专家。请将以下同类型知识点进行智能合并,生成一个更完整、准确的知识点。
合并要求:
1. 保留所有重要信息,避免信息丢失。
2. 消除重复内容,整合相似表述。
3. 提高内容的准确性和完整性。
4. 保持逻辑清晰,结构合理。
5. 合并后的置信度取所有知识点中的最高值。合并后的结果可以带上 frequency 字段。某个知识点出现次数越高,越说明它可能是高频问题,应该优先维护。
3. 知识库健康度检查:完整性、时效性、一致性
RAG 系统上线后,知识库不是越大越好。更重要的是健康。
健康度可以从三方面看:
text
完整性:用户常问的问题,知识库有没有覆盖?
时效性:价格、活动、政策、版本是不是过期?
一致性:不同 chunk 之间有没有互相冲突?检查缺失知识
完整性检查通常需要一组测试查询。LLM 读取测试查询和知识库内容后,判断哪些问题缺少知识支撑。
python
def check_missing_knowledge(knowledge_text: str, queries_text: str):
prompt = f"""
你是一个知识库完整性检查专家。请分析给定测试查询和知识库内容,判断知识库中是否缺少相关知识。
检查标准:
1. 查询是否能在知识库中找到相关答案。
2. 知识是否完整、准确。
3. 是否覆盖用户的主要需求。
4. 是否存在知识空白。
### 知识库内容 ###
{knowledge_text}
### 测试查询 ###
{queries_text}
### 返回 JSON ###
{{
"missing_knowledge": [
{{
"query": "测试查询",
"missing_aspect": "缺少的知识方面",
"importance": "高/中/低",
"suggested_content": "建议补充内容",
"category": "知识分类"
}}
],
"coverage_score": 0.0,
"completeness_analysis": "完整性分析"
}}
"""
return json.loads(preprocess_json_response(get_completion(prompt)))检查过期知识
时效性检查要把当前时间传进去。价格、营业时间、活动、技术版本、政策规则都容易过期。
python
from datetime import datetime
def check_outdated_knowledge(knowledge_text: str):
current_time = datetime.now().strftime("%Y年%m月%d日")
prompt = f"""
你是一个知识时效性检查专家。请分析给定知识内容,判断是否存在过期或需要更新的信息。
检查标准:
1. 时间相关信息是否过期。
2. 价格、费用、票价是否最新。
3. 政策、规定、规则是否更新。
4. 活动信息是否有效。
5. 联系方式是否准确。
6. 技术版本或标准是否过时。
### 知识库内容 ###
{knowledge_text}
### 当前时间 ###
{current_time}
### 返回 JSON ###
{{
"outdated_knowledge": [
{{
"chunk_id": "知识切片ID",
"content": "知识内容",
"outdated_aspect": "过期方面",
"severity": "高/中/低",
"suggested_update": "建议更新内容",
"last_verified": "最后验证时间"
}}
],
"freshness_score": 0.0,
"update_recommendations": "更新建议"
}}
"""
return json.loads(preprocess_json_response(get_completion(prompt)))检查冲突知识
一致性检查更像"知识库体检"。同一主题不同说法、价格不一致、营业时间冲突、规则互相矛盾,都要被找出来。
python
def check_conflicting_knowledge(knowledge_text: str):
prompt = f"""
你是一个知识一致性检查专家。请分析给定知识库,找出可能存在冲突或矛盾的信息。
检查标准:
1. 同一主题的不同说法。
2. 价格信息差异。
3. 时间信息不一致。
4. 规则政策冲突。
5. 操作流程差异。
6. 联系方式差异。
### 知识库内容 ###
{knowledge_text}
### 返回 JSON ###
{{
"conflicting_knowledge": [
{{
"conflict_type": "冲突类型",
"chunk_ids": ["相关切片ID"],
"conflicting_content": ["冲突内容"],
"severity": "高/中/低",
"resolution_suggestion": "解决建议"
}}
],
"consistency_score": 0.0,
"conflict_analysis": "冲突分析"
}}
"""
return json.loads(preprocess_json_response(get_completion(prompt)))材料里的健康度报告示例给出了整体评分、覆盖率、新鲜度、一致性和改进建议。

这里有个现实问题:LLM 能不能在大量 chunk 中全面找出冲突?
不能指望一次性把十万条 chunk 全塞进去检查。更实际的做法是先分类,再分组检查。例如:
text
票价类知识 -> 单独检查价格冲突
活动规则 -> 单独检查时间和规则冲突
交通类知识 -> 单独检查路线和耗时冲突
权限制度 -> 单独检查适用范围和版本冲突也就是先用 metadata 或目录结构缩小范围,再让 LLM 做局部健康检查。
4. 知识库版本管理与性能比较
RAG 的知识库会持续更新。只要持续更新,就需要版本管理。
版本管理至少要解决几个问题:
- 当前知识库是哪一版?
- 新版和旧版差了哪些 chunk?
- 新版检索效果是否更好?
- 新版有没有破坏旧问题的召回?
- 上线前怎么验收?
创建版本
版本里可以记录名称、描述、chunk 数量、平均长度、分类分布和内容 hash。
python
import hashlib
from datetime import datetime
def calculate_kb_hash(knowledge_base):
raw = json.dumps(knowledge_base, ensure_ascii=False, sort_keys=True)
return hashlib.md5(raw.encode("utf-8")).hexdigest()
def create_version(name: str, description: str, knowledge_base: list):
lengths = [len(item["content"]) for item in knowledge_base]
return {
"version_name": name,
"description": description,
"created_at": datetime.now().isoformat(),
"hash": calculate_kb_hash(knowledge_base),
"chunk_count": len(knowledge_base),
"avg_chunk_length": sum(lengths) / len(lengths) if lengths else 0,
"knowledge_base": knowledge_base,
}版本差异检测
差异检测可以先不用 LLM,用集合运算就能识别新增、删除和修改。
python
def detect_changes(kb1: list, kb2: list):
kb1_dict = {chunk["id"]: chunk for chunk in kb1}
kb2_dict = {chunk["id"]: chunk for chunk in kb2}
added_ids = set(kb2_dict) - set(kb1_dict)
removed_ids = set(kb1_dict) - set(kb2_dict)
common_ids = set(kb1_dict) & set(kb2_dict)
modified = []
for chunk_id in common_ids:
if kb1_dict[chunk_id]["content"] != kb2_dict[chunk_id]["content"]:
modified.append({
"id": chunk_id,
"old_content": kb1_dict[chunk_id]["content"],
"new_content": kb2_dict[chunk_id]["content"],
})
return {
"added": [kb2_dict[i] for i in added_ids],
"removed": [kb1_dict[i] for i in removed_ids],
"modified": modified,
}检索性能评估
性能评估要准备固定测试集。每次版本更新后,用同一批 query 测:准确率、响应时间、通过率。
python
def evaluate_version_performance(version, test_queries, retriever):
total = len(test_queries)
correct = 0
response_times = []
for query_info in test_queries:
query = query_info["query"]
expected_answer = query_info["expected_answer"]
start = datetime.now()
retrieved_chunks = retriever.retrieve(query, version_name=version["version_name"], k=3)
end = datetime.now()
response_times.append((end - start).total_seconds())
if evaluate_retrieval_quality(expected_answer, retrieved_chunks):
correct += 1
return {
"accuracy": correct / total if total else 0,
"avg_response_time": sum(response_times) / len(response_times) if response_times else 0,
"total_queries": total,
}材料里的示例中,v1.0 只有 3 个 chunk,v2.0 增加到 5 个 chunk,并补充了儿童票、交通、特色项目等信息。结果是准确率从 60% 提升到 100%,但响应时间略有增加。

这正是版本管理的价值:不要凭感觉说"新版更好",要用固定测试集量化对比。
三、召回、排序与上下文组织:先找全,再排准,最后用好
1. 高效召回:先把候选找全
召回阶段的目标不是一步到位选出最终答案,而是先把可能有用的候选找出来。
如果召回阶段漏掉了正确 chunk,后面的 LLM 再强也很难回答对。
材料里有一个 DeepSeek + FAISS 的本地知识库检索案例,问题是:
text
客户经理被投诉了,投诉一次扣多少分?系统从文档中找到了"有客户投诉的,每投诉一次扣 2 分"的规则,并基于检索结果回答。

用 LangChain + FAISS 时,基础代码大概是这样:
python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Tongyi
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
knowledge_base = FAISS.from_texts(chunks, embeddings)
llm = Tongyi(
model_name="deepseek-v3",
dashscope_api_key=DASHSCOPE_API_KEY,
)最简单的召回调参是增大 k:
python
docs = knowledge_base.similarity_search(query, k=10)但 k 不是越大越好。候选多了,召回率可能变高,但噪声也会变多,后续生成成本也会上升。因此一般会配合 Rerank:粗召回多拿一点,精排后只保留少量高质量 chunk。
2. MultiQuery:把一个问题改写成多个问题
用户问题经常很短,表达也不稳定。MultiQuery 的思路是让 LLM 生成多个查询变体,从不同角度检索。
例如原问题:
text
客户经理被投诉了,投诉一次扣多少分?可以改写成:
text
客户经理投诉扣分标准是什么?
银行客户经理被投诉一次会扣除多少绩效分?
金融机构客户经理投诉处罚机制是什么?代码可以这样写:
python
from typing import List
def generate_multi_queries(query: str, llm, num_queries: int = 3) -> List[str]:
prompt = f"""
你是一个检索查询改写助手。请根据用户问题生成 {num_queries} 个不同但相关的查询。
要求:
1. 每个查询都表达同一个信息需求。
2. 尽量从不同角度改写。
3. 不要输出编号和解释。
4. 每行一个查询。
原始问题:{query}
"""
response = llm.invoke(prompt)
queries = [line.strip() for line in response.splitlines() if line.strip()]
return [query] + queries[:num_queries]然后对每个 query 分别检索,再去重:
python
def multi_query_search(query: str, retriever, llm, k: int = 4):
queries = generate_multi_queries(query, llm)
all_docs = []
for q in queries:
docs = retriever.similarity_search(q, k=k)
all_docs.extend(docs)
return deduplicate_documents(all_docs)MultiQuery 的价值是提高召回覆盖率,代价是会多次检索,也可能引入更多噪声。适合问题短、问法多、同义表达多的场景。
3. 混合检索:BM25 + Vector
向量检索擅长语义相似,但有时会漏掉精确关键词。BM25 擅长关键词匹配,但不懂同义词和语义。
所以实际项目里经常做混合检索。
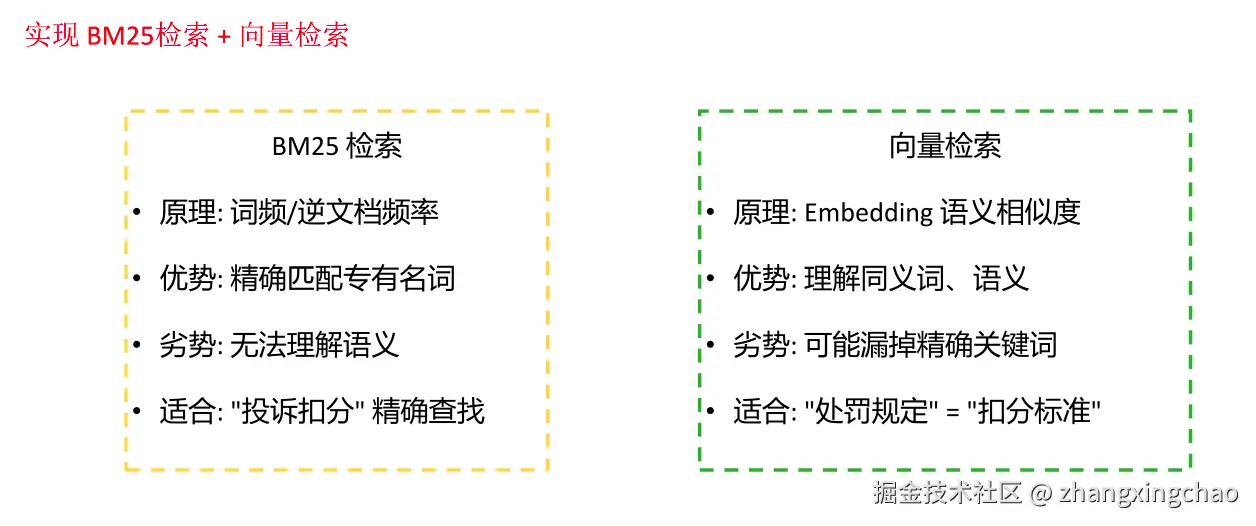
BM25 可以理解为 TF-IDF 的改进版本。它会看:
text
一个词在当前文档里出现得多不多
这个词在整个语料库里稀不稀有
当前文档长度是否影响分数对于法规、制度、技术文档、专有名词、编号、字段名、接口名,BM25 往往非常有用。
混合检索的流程是:
text
用户 query
-> BM25 检索得到关键词分数
-> 向量检索得到语义分数
-> 两种分数归一化到 [0, 1]
-> 按权重融合
-> 返回 Top-K融合公式:
text
Score = alpha * VectorScore + (1 - alpha) * BM25Scorealpha 控制偏向:
alpha = 0.0:纯 BM25,只看关键词。alpha = 0.3:偏关键词,兼顾语义。alpha = 0.5:平衡,常用默认值。alpha = 0.7:偏语义,兼顾关键词。alpha = 1.0:纯向量,只看语义。

一个混合检索实现
下面是简化版代码,便于理解逻辑。
python
import jieba
import numpy as np
from rank_bm25 import BM25Okapi
class HybridRetriever:
def __init__(self, chunks, vectorstore):
self.chunks = chunks
self.vectorstore = vectorstore
self.tokenized_corpus = [self.tokenize(chunk.page_content) for chunk in chunks]
self.bm25 = BM25Okapi(self.tokenized_corpus)
def tokenize(self, text: str):
return [word for word in jieba.lcut(text) if word.strip()]
def bm25_search(self, query: str):
tokenized_query = self.tokenize(query)
scores = self.bm25.get_scores(tokenized_query)
max_score = max(scores) if len(scores) and max(scores) > 0 else 1
return [score / max_score for score in scores]
def vector_search_scores(self, query: str):
vector_results = self.vectorstore.similarity_search_with_score(
query,
k=len(self.chunks),
)
vector_scores = [0.0] * len(self.chunks)
max_distance = max(distance for _, distance in vector_results) or 1
for doc, distance in vector_results:
idx = doc.metadata["chunk_index"]
vector_scores[idx] = 1 - distance / max_distance
return vector_scores
def search(self, query: str, k: int = 5, alpha: float = 0.5):
bm25_scores = self.bm25_search(query)
vector_scores = self.vector_search_scores(query)
combined = []
for idx, chunk in enumerate(self.chunks):
score = alpha * vector_scores[idx] + (1 - alpha) * bm25_scores[idx]
combined.append((chunk, score))
combined.sort(key=lambda item: item[1], reverse=True)
return [doc for doc, _ in combined[:k]]几个常见问题可以一起说明。
BM25 分数和向量分数不是同一个尺度。BM25 可能大于 1,cos 相似度通常在 [0, 1] 或 [-1, 1],L2 距离又是越小越相似。所以融合前要做归一化。
FAISS 本身不做 BM25。FAISS 管向量相似度,BM25 需要另外的工具库,比如 rank_bm25、Elasticsearch、OpenSearch 等。
BM25 很依赖分词。中文场景里分词质量会明显影响结果,尤其是专业词、产品名、机构名、字段名。
如果语义相似度很高但关键词一个都没命中,BM25 分可能是 0,但向量分仍然高。融合后不会直接变成 0,只是综合分会被拉低。这就像考试偏科:一科高、一科低,最终总分中等。
4. Rerank:粗召回之后再精排
Embedding 检索适合快速从大量文档里找候选,但它是"双塔"思路:query 和 doc 分别编码,再算相似度。速度快,但交互不够细。
Rerank 模型通常是 Cross-Encoder:把 (Query, Doc) 一起送进模型,让模型直接判断相关性。它更准,但更慢。
可以这样理解:
text
Embedding:快速批量筛选候选
Rerank:对候选逐个打相关性分
LLM:基于最终上下文生成答案材料里的排序关系可以记成:
text
Embedding < Rerank < LLM这里不是说能力绝对强弱,而是说计算成本和理解深度通常逐级提高。
常见 Rerank 有两类:
- BGE-Rerank:开源,可本地部署,适合中文和数据敏感场景。
- Cohere Rerank:商业 API,接入简单,多语言效果好。
BGE Rerank 基础用法
python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-reranker-base")
model = AutoModelForSequenceClassification.from_pretrained("BAAI/bge-reranker-base")
model.eval()
pairs = [
["what is panda?", "The giant panda is a bear species endemic to China."],
["what is panda?", "The Eiffel Tower is in Paris."],
]
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
with torch.no_grad():
scores = model(**inputs).logits.view(-1).float()
print(scores)BGE 的输出是 logits,不是严格的 0 到 1 概率。分数可以为负,也可以大于 1。一般只需要关心同一批候选里的相对排序。
封装成 Reranker
python
from typing import List
import torch
from modelscope import snapshot_download
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class Reranker:
def __init__(self, model_name="BAAI/bge-reranker-base", cache_dir="./models"):
model_dir = snapshot_download(model_name, cache_dir=cache_dir)
self.tokenizer = AutoTokenizer.from_pretrained(model_dir)
self.model = AutoModelForSequenceClassification.from_pretrained(model_dir)
self.model.eval()
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model.to(self.device)
def rerank(self, query: str, documents: List, top_k: int = 4):
pairs = [[query, doc.page_content] for doc in documents]
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
).to(self.device)
with torch.no_grad():
scores = self.model(**inputs).logits.squeeze(-1).cpu().tolist()
scored_docs = sorted(
zip(documents, scores),
key=lambda item: item[1],
reverse=True,
)
return [doc for doc, _ in scored_docs[:top_k]]MultiQuery + Hybrid + Rerank
更完整的召回流程通常是两阶段:
text
Stage 1:MultiQuery + Hybrid Search 粗召回 10 到 20 个候选
Stage 2:Rerank 精排,最终保留 3 到 5 个
python
def hybrid_multi_query_search_with_rerank(
query: str,
hybrid_retriever,
reranker,
llm,
initial_k: int = 10,
final_k: int = 4,
):
queries = generate_multi_queries(query, llm)
candidate_docs = []
for q in queries:
docs = hybrid_retriever.search(q, k=initial_k, alpha=0.5)
candidate_docs.extend(docs)
candidate_docs = deduplicate_documents(candidate_docs)
print(f"初步召回 {len(candidate_docs)} 个候选")
reranked_docs = reranker.rerank(query, candidate_docs, top_k=final_k)
print(f"Rerank 后保留 {len(reranked_docs)} 个")
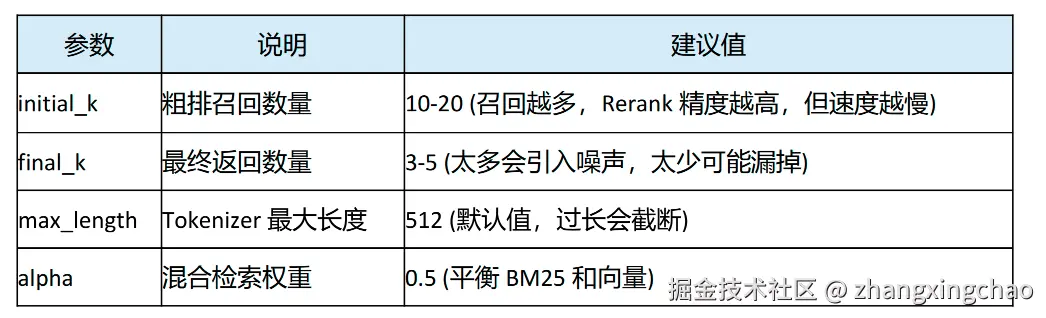
return reranked_docs参数建议:
initial_k:10 到 20。太小可能漏召回,太大会拖慢 Rerank。final_k:3 到 5。太多容易引入噪声。max_length:512。长文档需要分段,否则会被截断。alpha:先从 0.5 开始,再根据业务测试集调。
5. Query2Doc 和 Doc2Query
双向改写主要解决短文本向量化效果不稳定的问题。
Query2Doc
Query2Doc 是把用户的短 query 扩写成一段"可能的答案文档"。
比如用户问:
text
如何提高深度学习模型的训练效率?LLM 可以扩写成:
text
提高深度学习模型训练效率可以从优化算法、混合精度训练、分布式训练、数据预处理、学习率调度等角度入手。这样扩写后的内容更像文档,embedding 时语义特征更丰富。
python
def query_to_doc(query: str, llm):
prompt = f"""
请把下面这个检索问题扩写成一段可能出现在相关文档中的内容。
不要直接回答成最终答案,而是生成适合检索的背景描述。
用户问题:{query}
"""
return llm.invoke(prompt)Doc2Query
Doc2Query 是为每个文档 chunk 生成可能问题,然后把问题和原文一起用于索引。实际入库时可以这样组织:
text
原始 chunk:500 token
生成问题:5 个,约 200 token
索引用文本:原始 chunk + 生成问题
向量:embedding(索引用文本)
返回给 LLM:原始 chunk代码结构可以这样写:
python
def build_doc2query_index_text(chunk: str, generated_questions: list[str]):
questions_text = "\n".join(f"Q: {q}" for q in generated_questions)
return f"""
### 原始知识 ###
{chunk}
### 这个知识可以回答的问题 ###
{questions_text}
""".strip()如果用户 query 匹配到了生成问题 D,系统仍然通过 metadata 找回原始 chunk K,把 K 放进 prompt。不要只把问题 D 丢给大模型。
6. Small-to-Big:先用小内容定位,再取大上下文
Small-to-Big 是处理长文档时很常用的策略。
它的核心思想是:
text
small:摘要、标题、关键句、小段落,用来检索
big:原文大段、完整章节、完整文档,用来回答为什么要这样做?
小内容更适合做索引,因为它短、信息密度高、检索快。大内容更适合给 LLM,因为它上下文完整,不容易断章取义。
一个简单数据结构可以这样设计:
python
small_index_items = [
{
"small_id": "paper_001_summary",
"big_id": "paper_001_full",
"content": "本文介绍了 Transformer 在机器翻译任务中的应用,并提出改进注意力机制。",
"type": "summary",
}
]
big_store = {
"paper_001_full": {
"title": "Transformer 论文全文",
"content": "完整论文内容...",
"source": "paper_001.pdf",
}
}查询时先搜 small:
python
def small_to_big_search(query: str, small_vectorstore, big_store, k: int = 3):
small_hits = small_vectorstore.similarity_search(query, k=k)
big_contexts = []
for hit in small_hits:
big_id = hit.metadata["big_id"]
big_contexts.append(big_store[big_id])
return big_contexts这个问题和笔记里的"small 存哪里、big 存哪里"可以对应起来:
text
small 存向量索引,用于检索
big 存原文库或文档库,用于回填上下文
small 和 big 通过 id 关联如果用 FAISS,也可以理解成两个存储:
text
faiss_small:存 summary / question / key sentence 的 embedding
原文库:存完整 chunk / 章节 / 文档
metadata:记录 small_id -> big_id四、GraphRAG:处理跨文档、跨实体和全局理解问题
1. GraphRAG:从文本相似度走向图谱推理
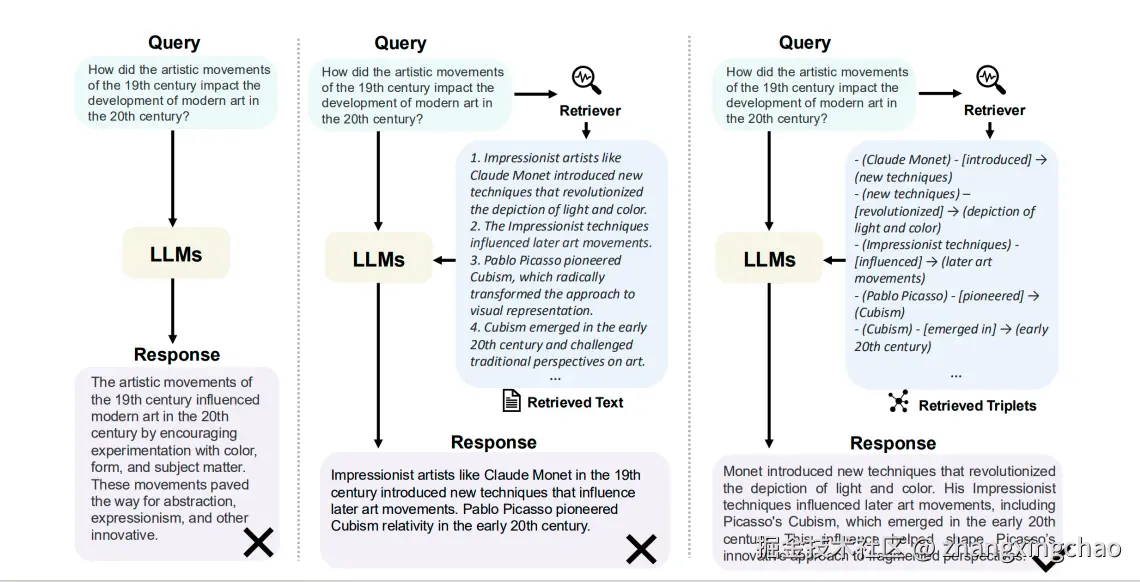
传统 RAG 主要依赖向量相似度。它适合回答局部事实问题,但对两类问题不太擅长。
第一类是"连接点"问题。答案分散在多个文档里,单个 chunk 看起来都不完整,需要通过实体和关系串起来。
第二类是"宏观理解"问题。比如用户问"这个数据集的主要主题是什么""一批投诉记录反映出哪些共性问题",仅靠 Top-K chunk 很难回答完整。
GraphRAG 的思路是:先从文本中抽取实体、关系、主张,构建知识图谱,再对图谱做社区聚类和摘要。查询时,系统不只找文本 chunk,还可以利用实体、关系和社区摘要。
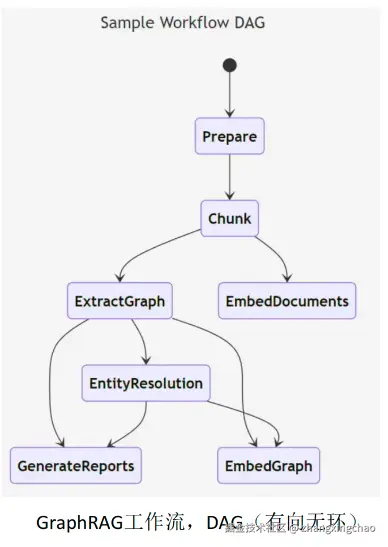
GraphRAG 索引阶段
GraphRAG 最重的是索引阶段。它把非结构化文本变成结构化图谱。
text
源文档
-> 切成 TextUnits
-> LLM 抽取 Entity / Relationship / Claim
-> 合并相同实体和关系
-> Leiden 社区发现
-> 自下而上生成社区摘要
-> 生成图谱、社区报告、向量索引和可视化数据其中几个对象很关键:
Document:原始文档。TextUnit:切分后的文本单元。Entity:实体,例如人、地点、组织、概念。Relationship:实体之间的关系。Covariate / Claim:从文本中抽取的主张或事实陈述。Community Report:社区摘要。
GraphRAG 不只是"多存一点 metadata",而是改变了检索组织方式:从纯文本片段,变成文本 + 实体 + 关系 + 社区摘要。
安装和初始化
官方 GraphRAG 的基本流程大概是:
bash
git clone https://github.com/microsoft/graphrag.git
cd graphrag
pip install -e .初始化项目:
bash
graphrag init --root .初始化后一般会生成:
text
.env
settings.yaml
prompts/
input/
output/
cache/
logs/.env 里配置 API Key:
bash
GRAPHRAG_API_KEY=<API_KEY>settings.yaml 里配置模型、输入输出目录、向量存储、local search、global search 等参数。
把待检索文档放入 input 目录,然后创建索引:
bash
graphrag index --root .索引构建会比较慢,因为它要做 LLM 抽取、图构建、社区检测和摘要生成。
Global Search 和 Local Search
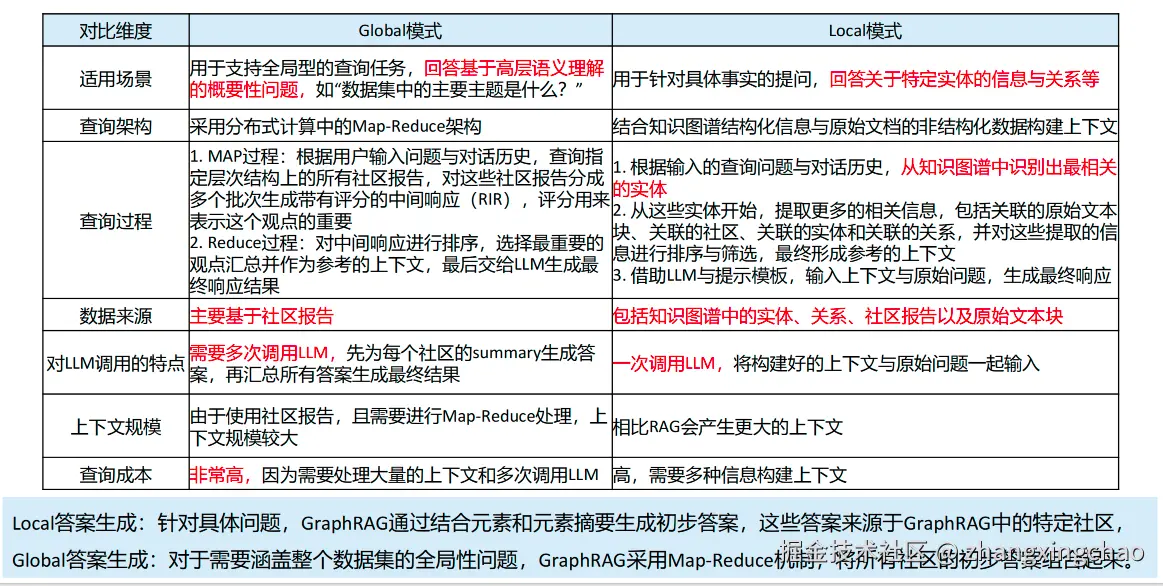
GraphRAG 常见两种查询模式:Global 和 Local。
 Global Search 用于回答全局问题,例如:
Global Search 用于回答全局问题,例如:
text
这批文档的主要主题是什么?
《三国演义》主要讲了哪些冲突?
这个数据集反映出哪些高层趋势?它会基于社区报告做类似 Map-Reduce 的流程:先让多个社区报告分别生成中间答案,再汇总重要观点,形成最终回答。成本较高,但适合宏观问题。
Local Search 用于回答具体实体问题,例如:
text
关羽战胜过哪些武将?
某个客户经理制度里投诉扣分规则是什么?
某个实体和哪些实体有关?它会从 query 识别相关实体,再扩展到邻居实体、关系、TextUnit、社区报告和主张,最后构建上下文回答。
查询命令类似:
bash
graphrag query --root . --method global --query "和曹操相关的人物都有哪些?"或:
bash
python -m graphrag.query --root ./cases --method local "关羽战胜过哪些武将?"GraphRAG 查询模式可以这样对比。
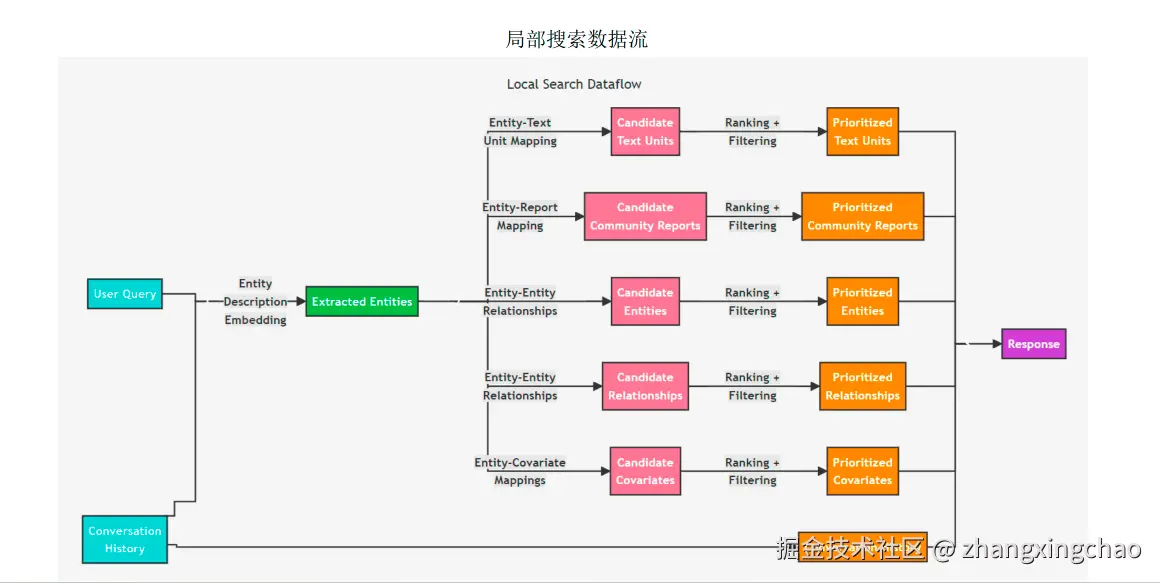
更完整的 Global / Local 差异如下。
如果想让 Local Search 匹配到更多 entities 和关系,可以调这些参数:
text
如果想让 GraphRAG Local Search 匹配到更多 entities 和 relationships,
可以适当调大 top_k_entities、top_k_relationships、max_context_tokens 等参数;
但参数不是越大越好,因为上下文变大后,成本、延迟和噪声都会上升。但这些参数不是越大越好。上下文变大以后,成本、延迟和噪声都会上升。
五、Agentic RAG 与常见工程问题:让流程更灵活,但也更可控
1. Agentic RAG 和 Native RAG 的区别
Native RAG 是固定流程。用户一提问,系统就按既定顺序执行:
text
query -> embedding -> retrieve -> prompt -> generateAgentic RAG 更灵活。它会让模型判断:
- 是否需要检索?
- 该用哪个知识库?
- 要不要先改写问题?
- 要不要调用 BM25、向量检索、GraphRAG 或数据库?
- 一次检索够不够,要不要多跳?
可以简单理解为:
text
Native RAG = 固定流水线
Agentic RAG = LLM 决策 + 工具调用 + 检索但不要把 Agentic RAG 理解成"更高级所以一定更好"。固定流程更稳定、更容易评估;Agentic RAG 更灵活,但也更难控成本和行为。
真实项目里经常是混合形态:核心链路固定,复杂问题再交给 Agent 决策。
2. 几个容易踩坑的问题
元数据到底有什么用
metadata 是检索命中以后回到业务数据的桥。
向量只负责算相似度,不能还原原始知识。如果没有 metadata,系统只能知道"某个向量相似",但不知道它来自哪个文件、哪一页、哪个部门、哪个版本、有没有权限。
常见 metadata 包括:
text
file_name
page_number
chunk_id
author
department
version
created_at
permission_tags
source_url权限控制也可以放在 metadata 里。比如财务、销售、行政看到的知识不同,可以给 chunk 打 permission_tags,检索时先按用户权限过滤。
芯片寄存器解析适合 RAG 吗
适合,但不要让 RAG 直接"计算 bit"。
更合理的做法是:
text
RAG 负责查寄存器定义
代码负责按 bit / byte 解析
LLM 负责解释结果例如用户给寄存器地址和 32bit 数据,系统先用 RAG 查到寄存器字段定义,再调用一个确定性的解析函数。
python
def parse_register(value: int, fields: list[dict]):
parsed = {}
for field in fields:
name = field["name"]
start = field["start_bit"]
end = field["end_bit"]
mask = (1 << (end - start + 1)) - 1
parsed[name] = (value >> start) & mask
return parsed这里 RAG 不负责算,RAG 负责找"规则"。确定性计算交给代码更可靠。
为什么要求"根据 RAG 回答"还是会幻觉
常见原因有几类:
- 正确 chunk 没召回。
- 召回了太多无关 chunk,干扰模型。
- chunk 切分把关键上下文切断了。
- metadata 没有过滤版本、权限或来源。
- prompt 没有要求"无法从资料确认时说明不知道"。
- LLM 把常识和检索资料混在一起回答。
解决时不要只改 prompt,要从检索链路排查:测试集、召回率、Top-K、Rerank、chunk、metadata、版本、来源权威性都要看。
BM25 和向量检索对 chunk 要求一样吗
不完全一样。
向量检索更看语义完整性,chunk 太碎可能语义不足,太长又可能稀释重点。
BM25 更看关键词分布。固定字数切分如果把关键词和上下文切开,也会影响 BM25。对制度、法规、接口文档,可以按标题、条款、章节切分,而不是完全按固定字数切。
Rerank 是怎么知道相关性的
Rerank 模型是训练出来的。训练数据通常是 (query, document, label) 或成对偏好数据,让模型学习什么样的文档更相关。
例如:
python
pairs = [
["what is panda?", "The giant panda is a bear species endemic to China."],
["what is panda?", "Pandas are cute."],
["what is panda?", "The Eiffel Tower is in Paris."],
]模型会学到第一条最相关,第二条一般,第三条不相关。
六、落地排查路径与总结:从 Demo 走向可维护系统
1. 调优时可以按这个顺序排查
遇到 RAG 效果不好,不建议一上来就换大模型。可以按下面顺序查:
text
测试集是否明确
正确答案是否在知识库里
chunk 是否切得合理
metadata 是否能过滤权限、版本、来源
query 是否需要改写
是否需要 BM25 补关键词召回
是否需要 MultiQuery 提升覆盖率
是否需要 Rerank 精排
是否需要 Small-to-Big 补完整上下文
是否需要 GraphRAG 处理全局和关系问题
是否需要 Agentic RAG 做动态工具选择一套比较稳的工程链路可以是:
text
入库前:清洗、切分、问题生成、metadata 标注
入库时:原文索引 + 问题索引 + 向量索引 + BM25 索引
检索时:MultiQuery + Hybrid Search
排序时:Rerank
生成时:严格引用检索上下文,不知道就说不知道
上线后:健康度检查、版本管理、回归测试
复杂场景:Small-to-Big / GraphRAG / Agentic RAG2. 总结
RAG 高级调优不是单个技巧,而是一整套知识工程。
知识库处理解决"知识本身是否可靠":问题生成、对话沉淀、健康度检查、版本管理。
高效召回解决"能不能找得到":MultiQuery、BM25、向量检索、混合检索、Rerank。
上下文组织解决"找到了怎么用":Small-to-Big、metadata 回溯、Top-K 控制、长文档分段。
GraphRAG 解决"跨文档、跨实体、全局理解":实体、关系、社区摘要、Global / Local Search。
Agentic RAG 解决"流程是否固定":让 LLM 根据问题决定是否检索、怎么检索、是否多跳。
最终目标不是堆更多工具,而是让系统在真实业务里稳定回答:
text
答案来自哪里?
依据是否正确?
权限是否合规?
版本是否最新?
召回是否可评估?
更新是否可回归?能回答这些问题,RAG 才从一个 demo 变成真正可维护的应用。