深度学习的学习中发现python欠缺的相关知识比较多,严重影响自己理解代码,弥补。下面笔记记录的是笔者自己比较疑惑的点,所以写的比较简单。
1 基础
1.1 字面量
字面量:在代码中,被写下来的固定的值,称之为字面量
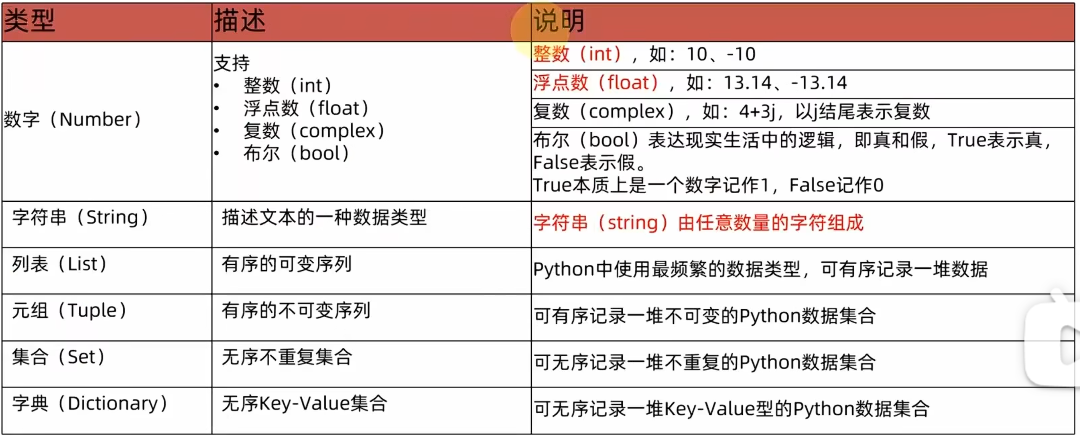
- 常用的值类型:python 中常用的由6种值(数据)的类型
1.2 注释
注释是用来增强代码可读性的内容,不会被执行。
- 单行注释:以 # 开头,通常将其与注释内容以一个空格隔开
- 多行注释:以 一对三个双引号 引起来

1.3 变量
变量:在程序运行时,能够存储计算结果或表示值的抽象概念;简单来说,变量就是在重新运行时,记录数据用的。
1.4 数据类型
数据是有类型的,数据类型决定了其操作方位和范围。python 提供了 type()语句来获取数据类型。
//示例:
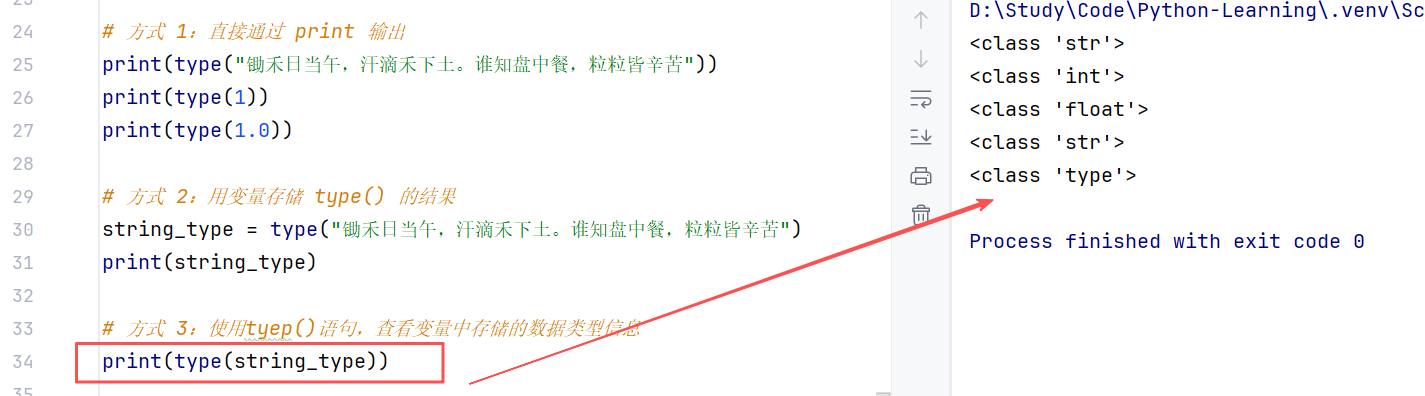
我们通过 type(变量) 可以输出类型,查看的是变量存储的数据的类型,因为,变量无类型,但是它存储的数据有。
1.5 数据类型转换
数据类型转换是我们需要用到的重要功能:比如从文件中读取的数字,默认是字符串,所以需要将其转换为数字类型;将数字转换成字符串可以实现把数据写到磁盘上...
//示例:
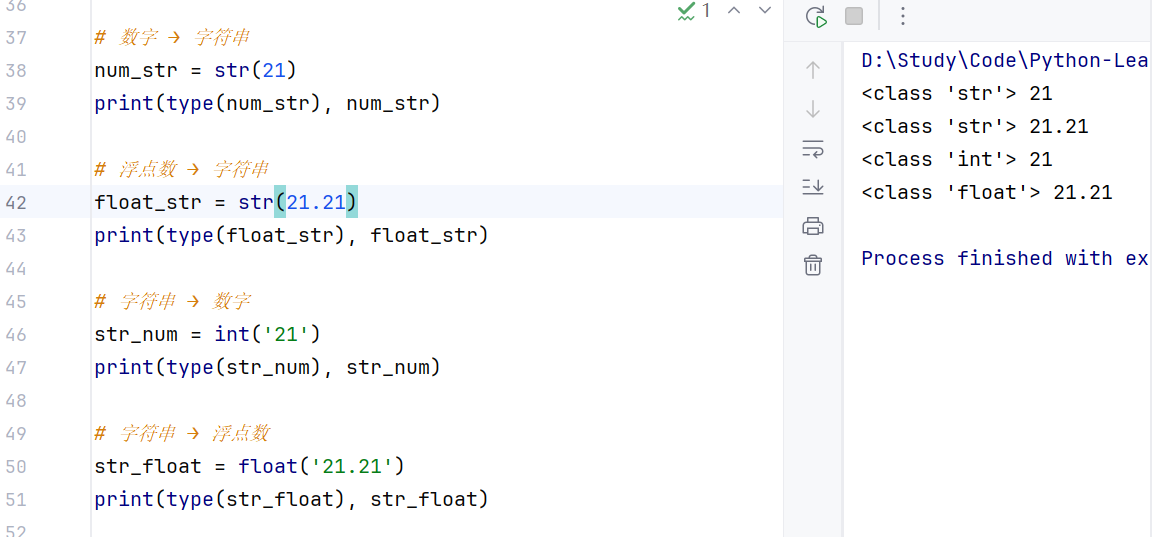
注意细节:万物可以转为字符串,但是将字符串转为特定的数据类型需要注意内容是否规范,另外,浮点数转整数可能丢失精度,整数可以转浮点数。
1.6 标识符
(1)定义:是用户在编程时所使用的一系列名字,用于给变量、类、方法等命名。
(2)命名规则:①大小写敏感 ②不能使用关键字 ③内容限定:只允许 数字、字母、下划线(其实python也支持中文,但是不推荐,会存在一些隐藏的问题),且不允许数字开头
//常见关键字:

(3)命名规范:(为了标准、专业、高级!)
变量名:见名知意、下划线命名法、英文字母全小写
类名:
方法名:
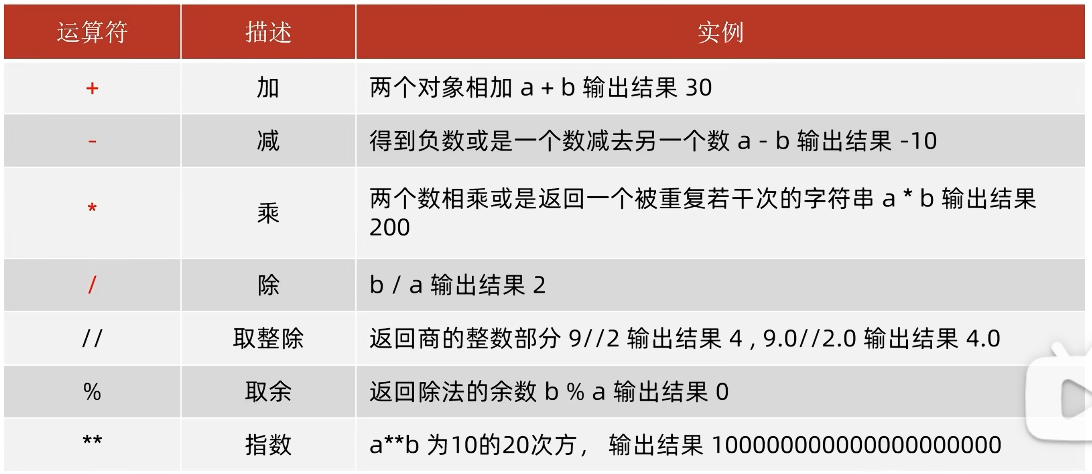
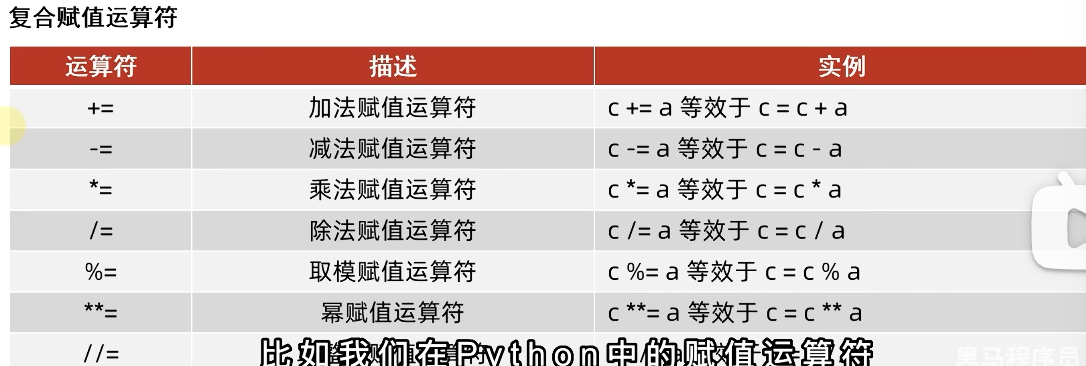
1.7 常见运算符

1.8 字符串扩展
- 字符串(string):又称为"文本",是由任意数量的字符如中文、英文、各类符号、数字等组成。注意字符串要用引号包围起来
(1)字符串的三种定义方式:
Python 允许我们灵活使用单引号或双引号来包裹字符串,主要是为了方便处理字符串内部包含的引号。
//示例:

除了单、双引号,Python 还支持使用三个连续的引号('''...'''或"""...""")来定义字符串,注意:如果使用变量接收它,它就是字符串,不使用变量接收它,就可以作为多行注释使用。

(2)字符串拼接
用于将多个字面量(变量)拼接为一个字符串。
① 如果都是字符串字面量,可以直接用"+"
//示例1:将age_int的输入实际上是将其转为字符串之后拼接

② 字符串格式化(通过 "%" 占位的方式)
//示例2:使用相应类型的占位符

③ 快速格式化:通过语法 f"内容{变量}"的格式
//示例3:需要注意的是这种方式不理会类型,不做精度控制

(3)格式化的精度控制
使用辅助符号"m.n"来控制数据的宽度和精度。
m:控制宽度,要求是数字,设置的宽度小于数字自身,不生效
.n:控制小数点精度,要求是数字,会进行小数的四舍五入
//示例:小数点和小数部分也算入宽度计算

(4)对表达式进行格式化
表达式:一条具有明确执行结果的代码语句。如:1+1,5*2 这样有具体的结果,又或者 name="张三",age=12+34 ...
//示例:在无需使用变量进行数据存储的时候,可以直接格式化表达,简化代码

1.9 数据输入
input语句(函数):用来获取键盘输入,使用一个变量接收(存储)即可。
//示例:

2 函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。好处:可重复使用、代码可读性、简洁性提升。
2.1 函数的定义
注意事项:参数、返回值如不需要可以省略;函数必须先定义后使用

2.2 函数的参数
函数定义中的参数:称为形式参数;函数调用中的参数,称为实际参数,函数参数的数量不限,使用逗号分开;传参的时候要和形参一一对应。
2.3 函数的返回值
(1)函数执行结束后返回的结果,通过 return 返回;但是注意 return 之后的代码不会再执行。
(2)None是类型"NoneType"的字面量,用于表示:空的、无意义的;常用于函数返回值、if 判断、变量定义等场景;"return "或"return None"都表示返回 None
2.4 函数的说明文档
函数是纯代码语言,我们可以给函数添加说明,辅助理解函数的作用。
//示例:

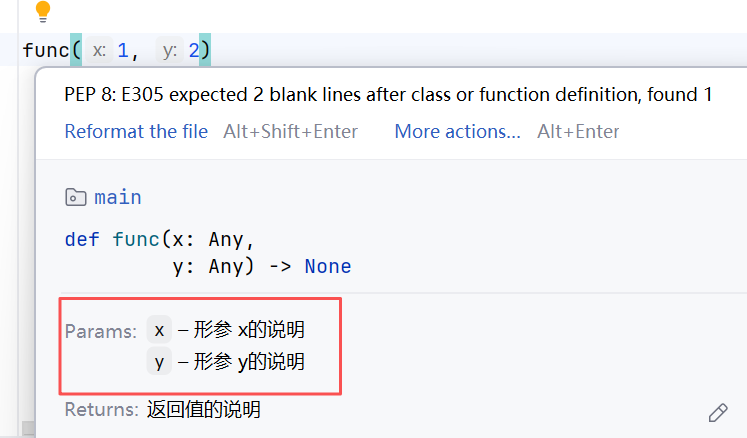
通过多行注释的形式,对函数进行说明解释。(内容应写在函数体前)
2.5 函数的嵌套调用
一个函数里面又调用了另外一个函数。
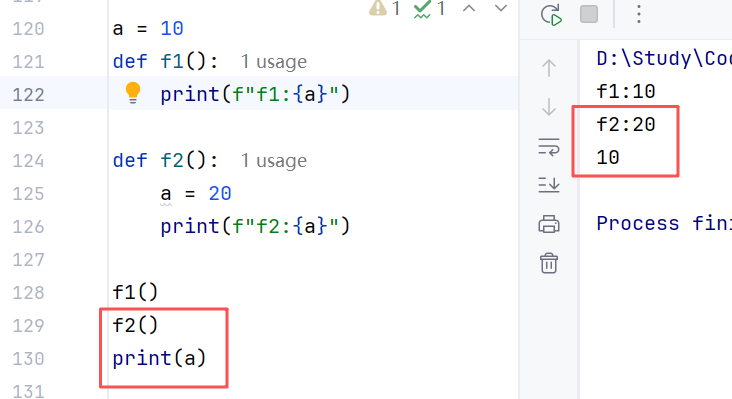
2.6 变量的作用域
变量作用域是指:变量的作用范围(变量在哪里可用,在哪里不可用),主要分为两类:
局部变量:定义在函数体内部的变量,即只在函数体内部生效。作用:在函数体内部-临时保存数数据,当函数调用完成之后,则销毁局部变量。
全局变量:在函数体内、外都能生效的变量。
//示例:对于f2来说相当于创建了一个名字叫做num的局部变量,不会影响全局变量的值。
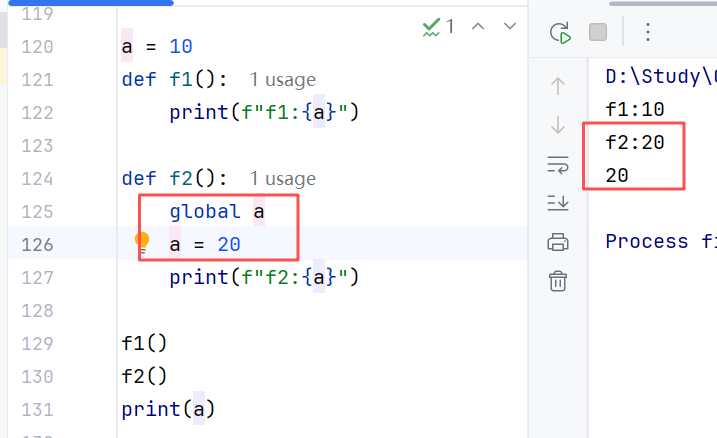
global关键字:可以在函数内部声明变量为全局变量。
3 数据容器
3.1 数据容器了解
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每个元素可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:是否支持重复元素、是否可以修改、是否有序等,分为5类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)。
3.2 列表(list)
(1)定义
列表用于存储多个数据。且可以为不同的数据类型,支持嵌套。
//示例:
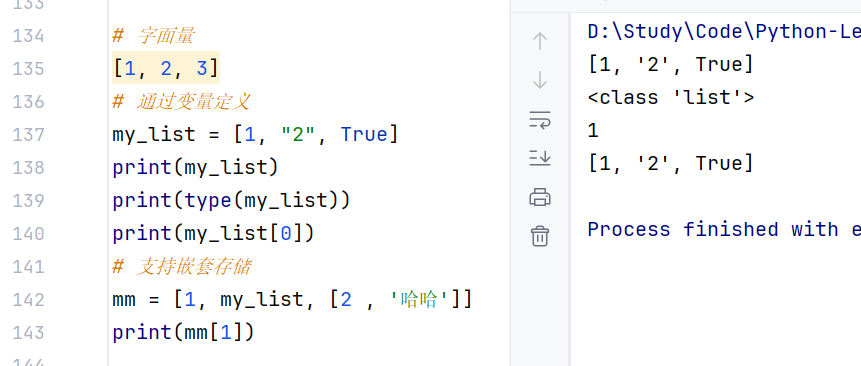
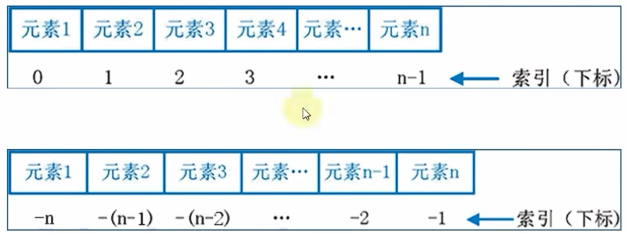
(2)列表的下标索引:
正向索引:0,1,2,3,......; 反向索引:-1,-2,-3.......需要注意索引的取值范围,超出范围会报错。
(3)列表的常用操作
除了定义、通过下标索引来获取值之外,列表也提供了功能:插入元素、删除元素、清空列表等,这些功能我们都称之为:列表的方法。
函数与方法:函数是一个封装的代码单元,可以提供特定功能,在Python中,如果将函数定义为 class(类)的成员,那么函数会被称之为方法;它们功能一样,只是写的地方不同。
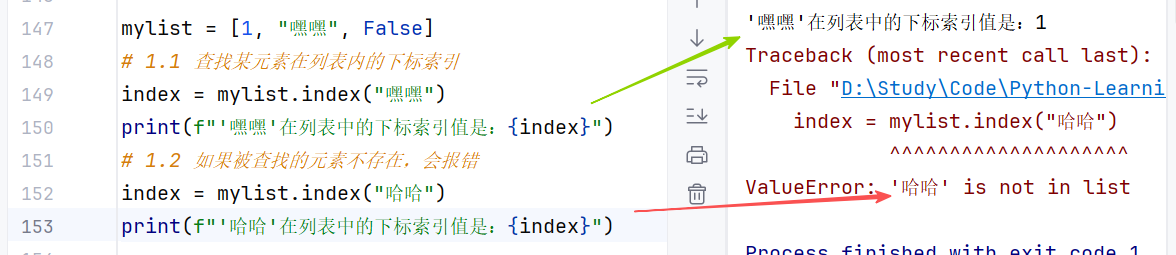
- 查询:查找指定元素在列表的下标,若找不到则报错 ValueError;语法:.index(元素)
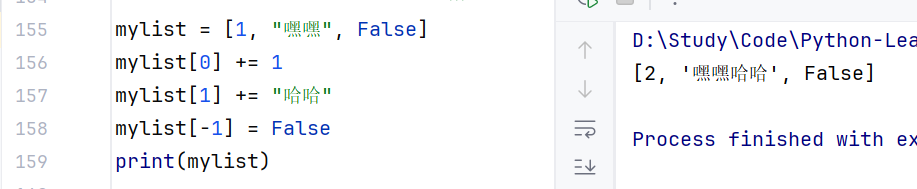
- 修改:修改特定位置的元素值;语法:列表下标=值;
- 插入元素:在指定下标位置,插入指定的元素;语法:列表.insert(下标,元素)
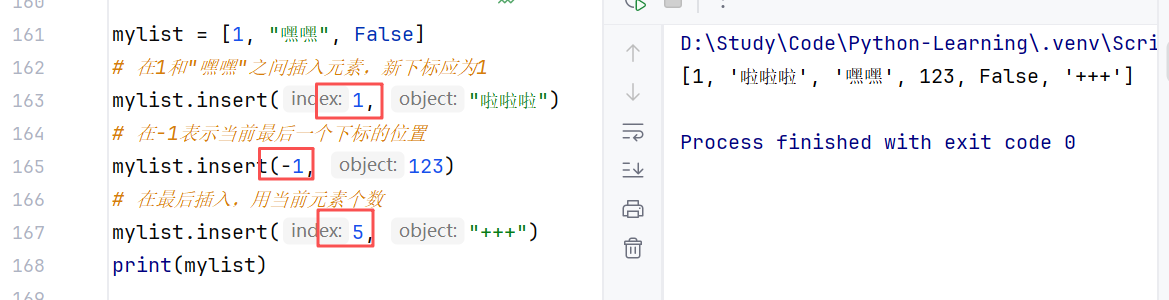
- 追加元素:追加到列表的尾部;语法:列表.append(元素)------单个元素

- 追加容器:列表.extend(其他数据容器)------多个元素,将数据容器的内容取出,依次追加到列表尾部。

- 删除元素:语法1:del 列表下标; 语法2:列表.pop(下标),可以获取删除的元素

- 删除某元素在列表中的第一个匹配项;语法:列表.remove(元素)

- 清空列表:列表.clear()

- 统计某元素在列表中有几份:列表.count(元素)

- 统计列表中元素总个数:len(列表)

(4)列表的特点
①可以容纳多个元素(上限为 2**63-1个)② 可以容纳不同类型的元素(混装) ③数据时有序存储的(有下标序号) ④允许重复数据存在 ③可以修改(增删查改)
3.3 tuple(元组)
(1)为什么需要元组?
列表是可以修改的,当我们需要程序内封装数据,又不希望封装的数据被篡改,元组!
(2)元组的定义
元组同列表一样,都是可以封装多个不同类型的元素在内,但最大的不同点在于:元组一旦定义完成,就不可修改。
//示例1:

//示例2:注意定义单个元素的元组时,需要在末尾添加 ','

//示例3:tuple不支持修改

//特例:若元素是一个列表,那列表中的元素可以修改

(3)元组的特点
和列表(list)基本一致,但是其不可修改。特别的,若元素是一个列表,那列表中的元素可以修改。
3.4 掌握字符串的常见操作
- 下标索引:正向从0开始; 负向从-1开始;
- 字符串时无法修改的数据容器,因此:修改指定下标的字符、移除指定下标的字符、追加字符等均无法完成。
- .index(a):查找特定字符串 a 的索引值
- .replace(str1, str2):字符串的替换。将 str1 的全部替换为 str2。注意,不是修改字符串本身,而是得到一个新的字符串。

- .split(分隔字符串),按照指定的分隔字符串,将字符串划分为多个字符串,并存入列表对象。(注意:字符串本身不变,而是得到一个列表对象)

- .strip()、.lstrip()、.rstrip():字符串的规整操作:去空格。
//示例1:去前后空格

//示例2:去前后指定字符串(说明该参数有默认值" ")

//示例3:注意,.strip()并不完全按照传入的字符串做前后去除,而是前后只要存在该字符串的某个元素,就会被删除!

- .count(a):统计字符串中a出现的次数

- len(str):统计字符串的长度
3.5 序列
(1)定义
指内容连续、有序、可使用下标索引的一类数据容器。列表、元组、字符串均可视为序列。
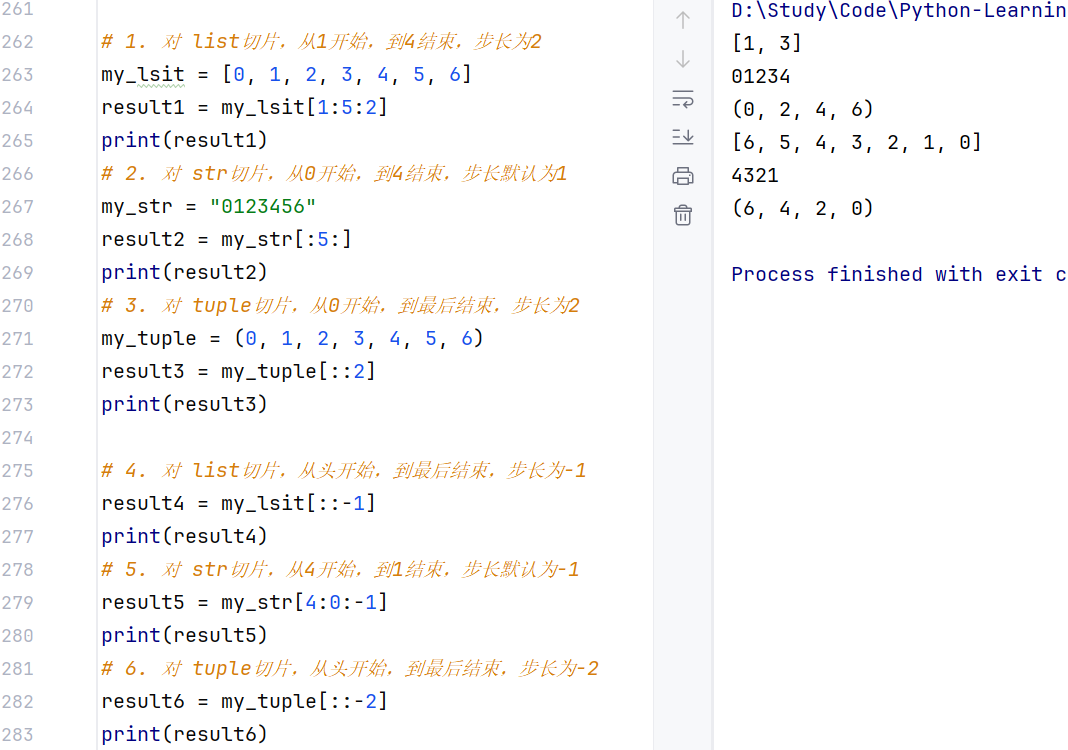
(2)序列的常用操作-切片
切片:从一个序列中,取出一个子序列。
语法:序列begin_index:end_index:step,即从begin_index开始(可以留空表示从头开始),截取到end_index前一个(可以留空表示截取到结尾),step表示每次跳过step-1个元素取,步长为负数表示反向取(注意,此时起始下标和结束下标也要反向标记)。
注意:此擦从左不会影响序列本身,而是会得到一个新的序列。
//示例:
3.6 集合(set)
(1)为什么使用集合?
我们学到的序列(列表、元组、字符串等)基本满足大多数的使用场景,为何又需要学习新的集合类型呢?------ 它们都支持重复元素且有序,如果场景需要对内容做去重处理,那它们就不再方面,而集合最大的特点就是:不支持元素重复(自带去重功能),并且内容无序。
(2)集合的定义
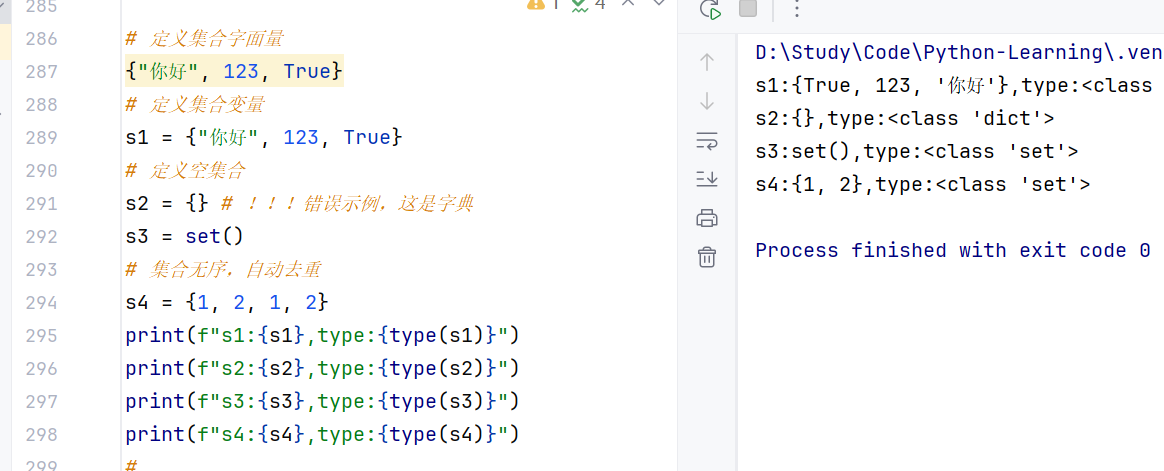
现在简单回顾一下,列表用:\[\]、元组用 :()、字符串用:"",集合用:{}
(3)集合的常用操作
首先,集合是无序的,所以不支持下标索引访问。但是支持修改。(可以联系数学集合理解)
- 添加元素:.add(ele)

- 移除元素:.remove(ele)
//示例1:移除元素成功
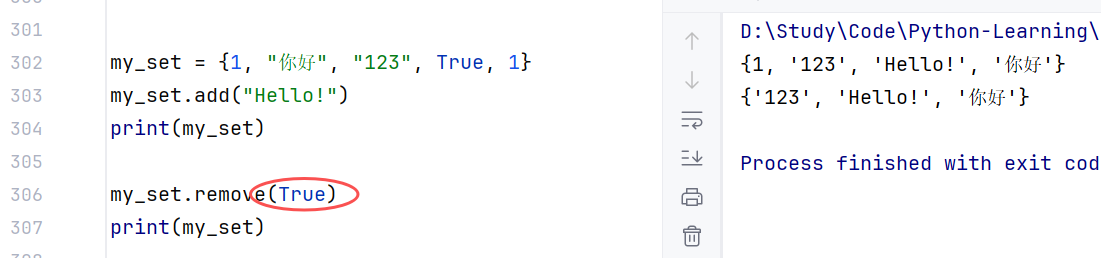
//示例2:若元素不存在,则会报错
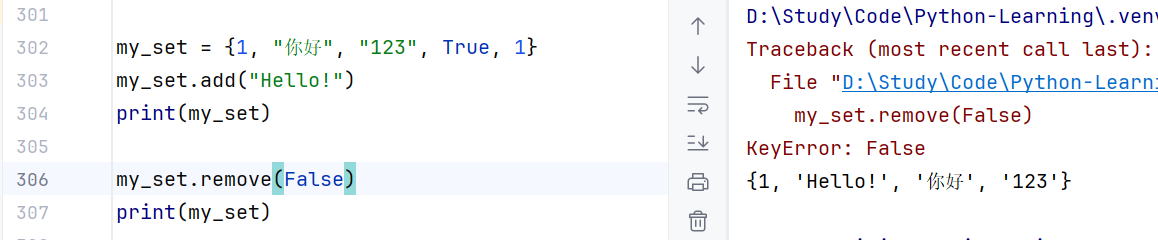
- 随机取出元素;语法:集合.pop(),同时集合本身会被修改。

- 清空集合:集合.clear(),集合本身被清空。

- 求集合的差集:s1.difference(s2),取出s1有而s2没有的,结果的得到一个新集合,原来两个集合不变。

- 消除差集:s1.difference_update(s2);结果 s1中中删除s2的部分,s2不变。

- 求集合的的并集:s1.union(s2),将s1、s2组合成新集合,结果得到一个新集合,s1、s2不变

- 统计集合元素个数:len(s)

- 集合的遍历:不能 while 可以 for

(4)集合的特点
通过上述对集合的学习,可以总结出集合有以下特点:① 可以容纳多个数据 ② 可以容纳不同类型的数据(混装)③ 数据无序存储(不支持下标索引) ④ 不允许重复数据存在 ⑤可以修改(增加或删除元素等) ④支持for循环
3.7 数据容器:dict(字典、映射)
(1)定义
同样使用{},不过存储的元素是一个个的:键值对,如下语法:
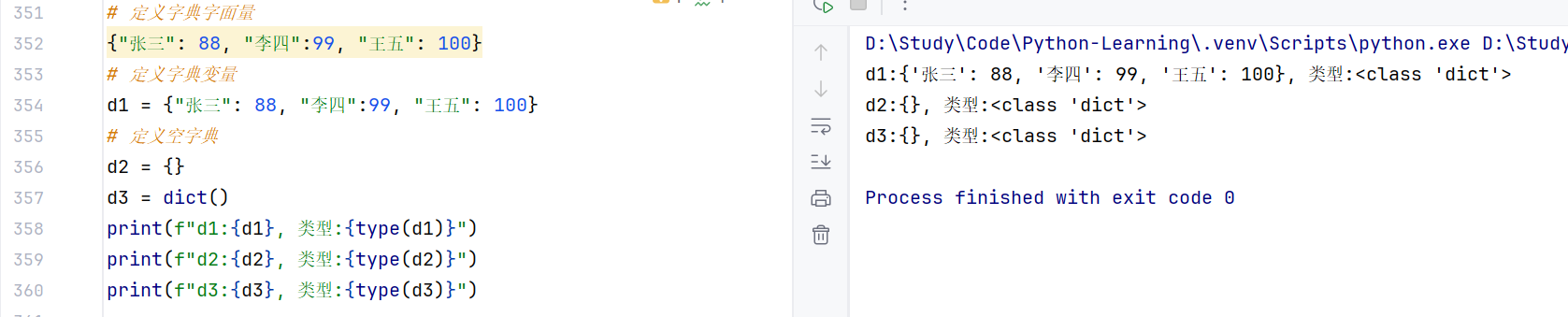
//注意:字典中不支持重复的的内容,只会取最新的内容覆盖原来的

(2)常用的操作
- 获取数据:通过key获取对应的的value
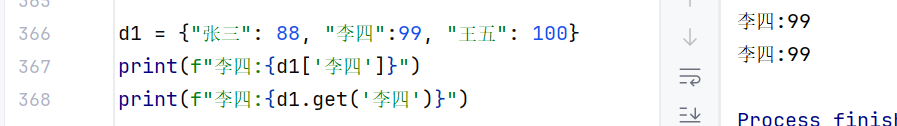
- 字典的嵌套:key必须满足一个核心条件:必须是可哈希的不可变数据(任何在创建后无法被修改的对象,通常都可以作为字典的键,数字、字符串、元组等),而value则不受限制。
//示例1:

//示例2:记录学生各科的考试信息

- 修改/新增元素:dkey=value,若key存在则表示更新元素,否则表示添加一个新元素。

- 删除元素:.pop(key),获取key对应的value,删除相应内容

- 清空元素:.clear()

- 获取全部的key:字典的keys(),结果:得到字典中的全部key,类型 dict_keys

- 字典遍历
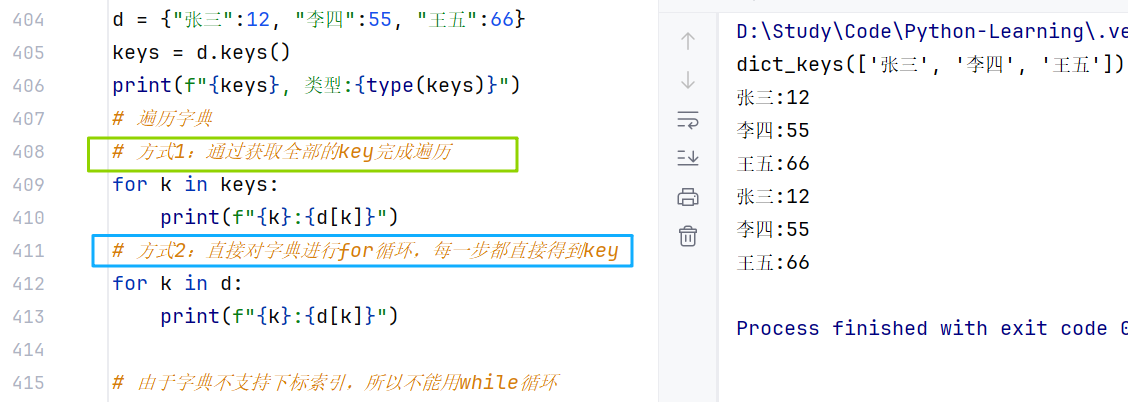
(3)字典的特点

3.8 数据容器对比总结
(1)对比总结
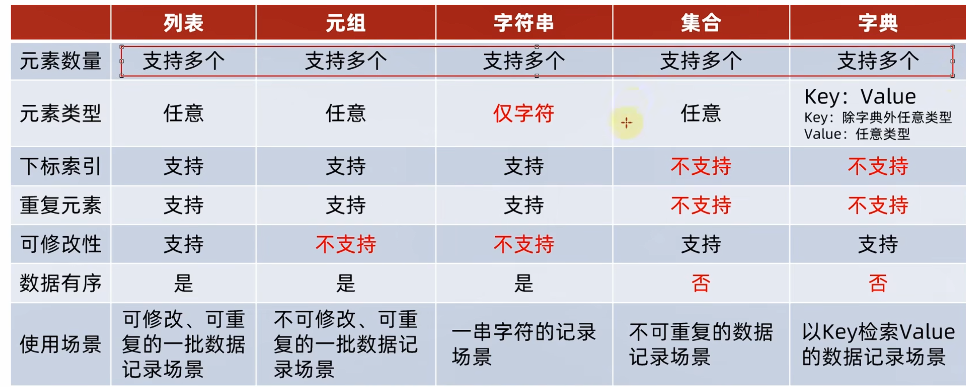
(2)通用操作
数据容器尽管各自有各自的特点,但是它们也有通用的一些操作。
- 遍历:5类数据容器都支持 for 循环。其中,集合、字典无法下标索引,不支持 while 循环。
- 通用统计功能:

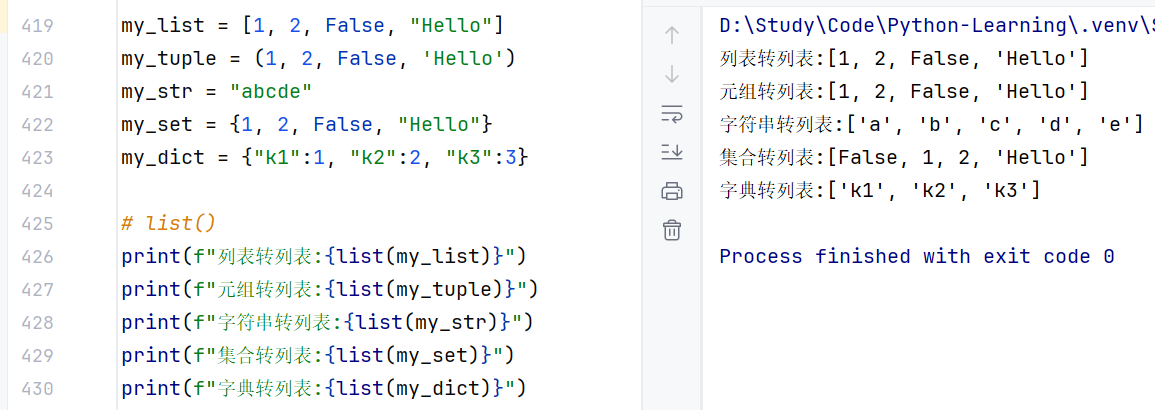
- 转换:可以通过通用类型转换

//示例1:转列表,注意字典转列表会只保留key而抛弃value
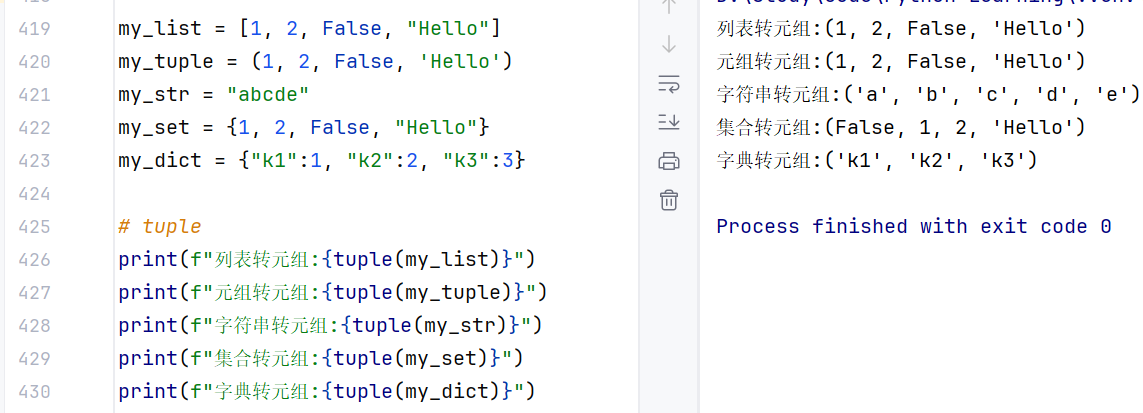
//示例2:转元组
//示例3:转集合,仍然保持自动去重功能。
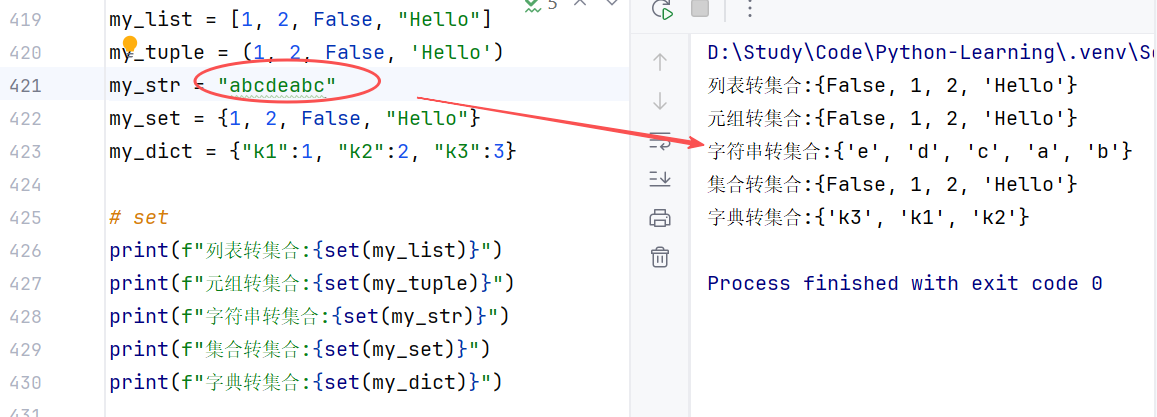
//示例4:转字符串,注意此转换可以保留字典的全部信息
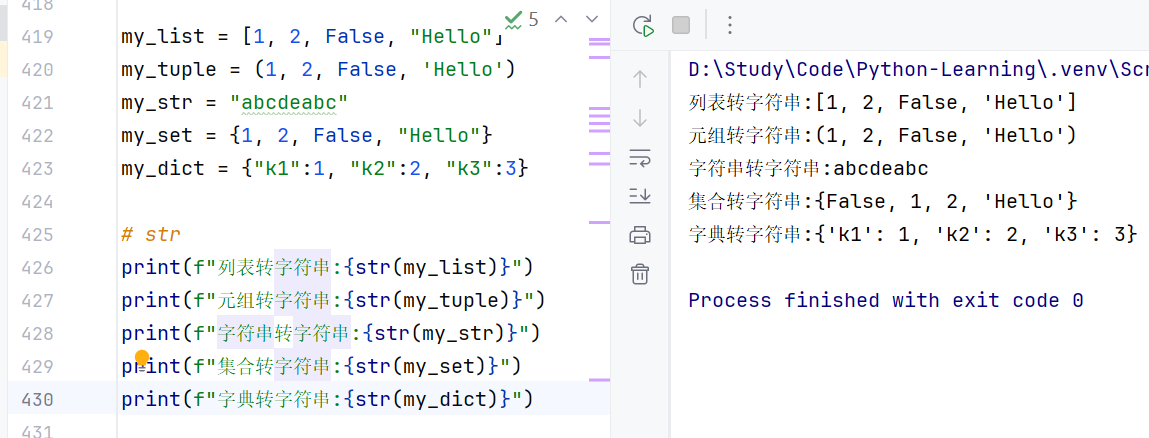
注意,由于字典的数据元素是一个键值对,因此对其他类型使用 dict()转换,会报错!
- 通用排序功能:sorted(容器,reserve=True),且结果会变成列表对象
//示例1:默认为从小到大排序
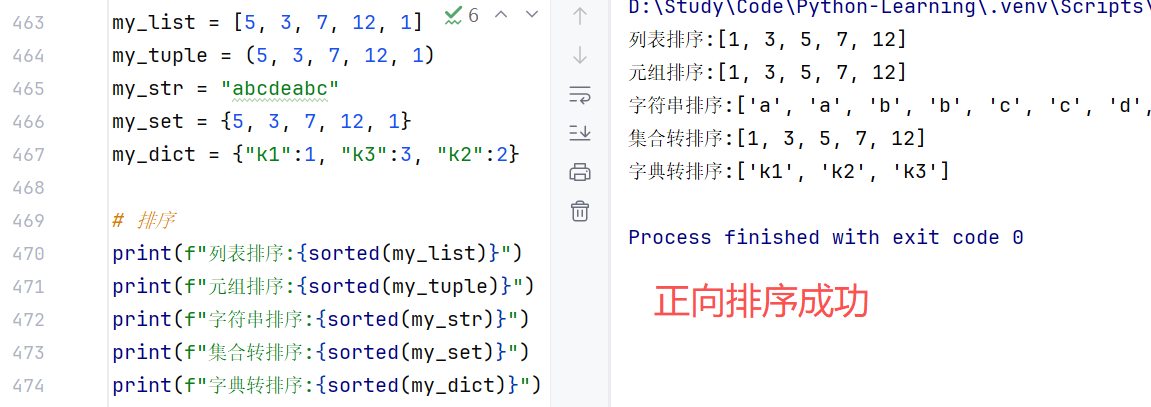
//示例2:注意数据元素必须相同,否则会报错------不同数据类型可能无法比较大小
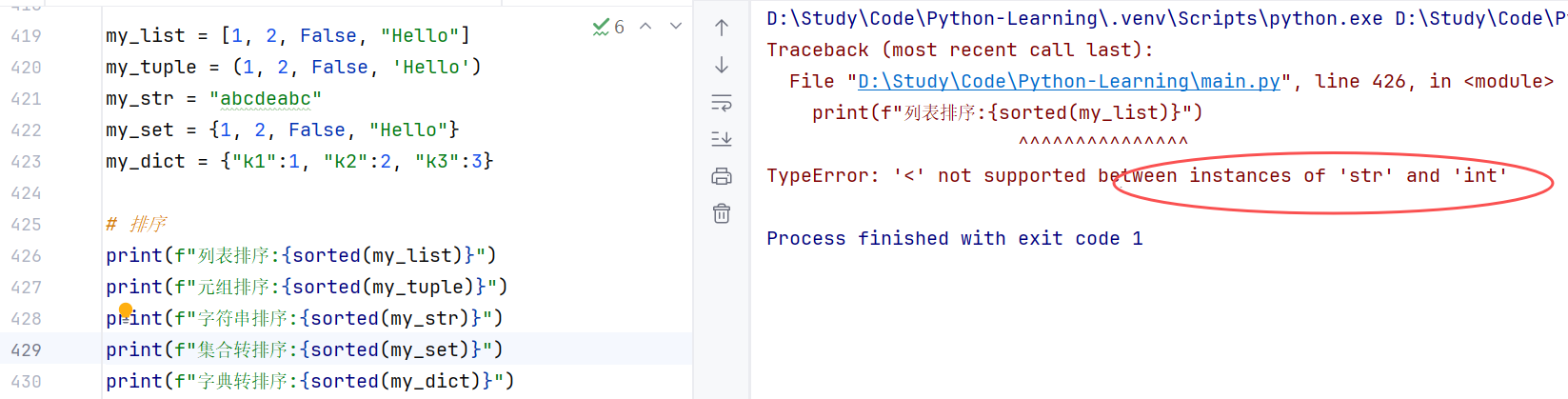
4 函数进阶
4.1 多个返回值
- 若一个函数有多个返回值,通过 ',' 隔开;

- 接收:按照返回值的顺序,写对应顺序的多个变量接收即可,变量直接用逗号隔开,且支持不同类型的数据 return .
4.2 函数的多种传参方式
(1)位置参数

(2)关键字参数

(3)缺省参数

(4)不定长参数

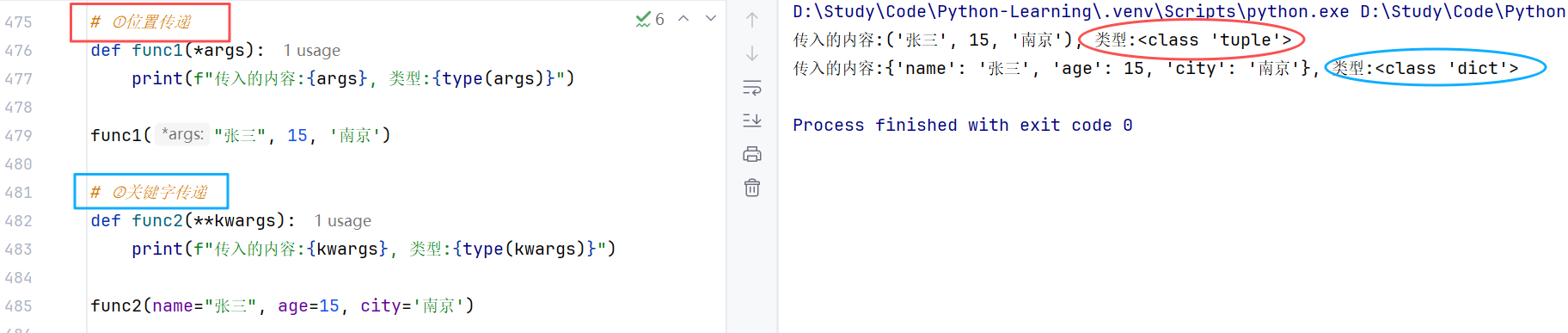
① 位置传递:*args接收,传进的所有参数都会被args变量接收,他会根据传进参数的位置合并为一个元组 (tuple),args 是元组类型。
② 关键字传递:**kwargs接收,参数必须是"键=值"形式(否则会报错),且会根据其组成字典。
//示例:
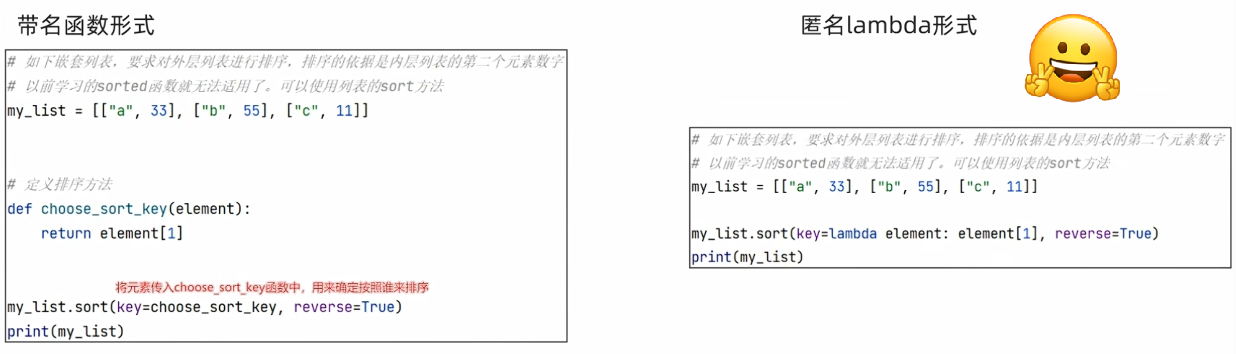
4.3 匿名函数
(1) 函数作为参数传递
参数可以是数据,也可以是函数。

所有,这是一种,计算逻辑的传递,而非数据的传递。任何逻辑都可以自行定义并作为函数传入。
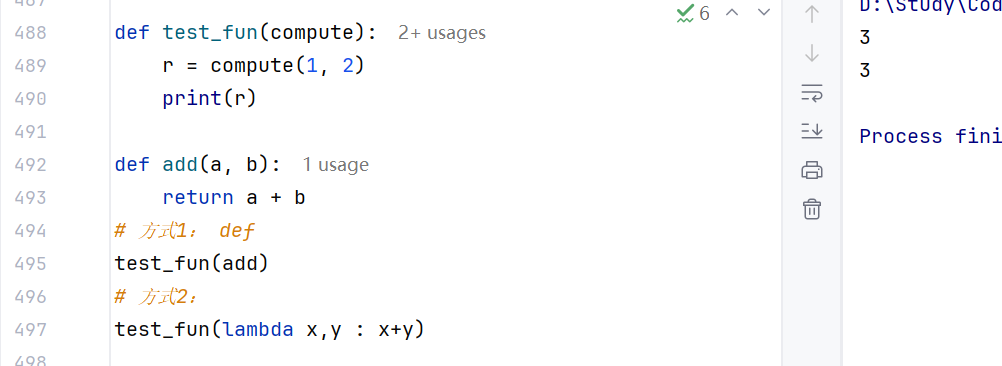
(2) lambda 匿名函数
- 带有名称的函数:def 定义,可以基于名称重复使用;
- 无名称(匿名)函数: lambda 定义,只可临时使用一次(可以提高代码间接性)
匿名函数定义语法:

5 文件操作
5.1 文件的编码

编码技术:翻译的规则,记录了 内容机器语言 的翻译规则。eg. UTF-8、GBK......
UTF-8是目前全球通用的编码格式,除非特殊需求,否则,一律以UTF-8格式进行文件编码即可。
5.2 文件的读取

文件的操作:打开、关闭、读、写等。
(1)打开文件


//示例:注意open还有其他参数,编码方式不是其第3位置参数,因此这里使用关键字编码。

(2) 读操作相关方法
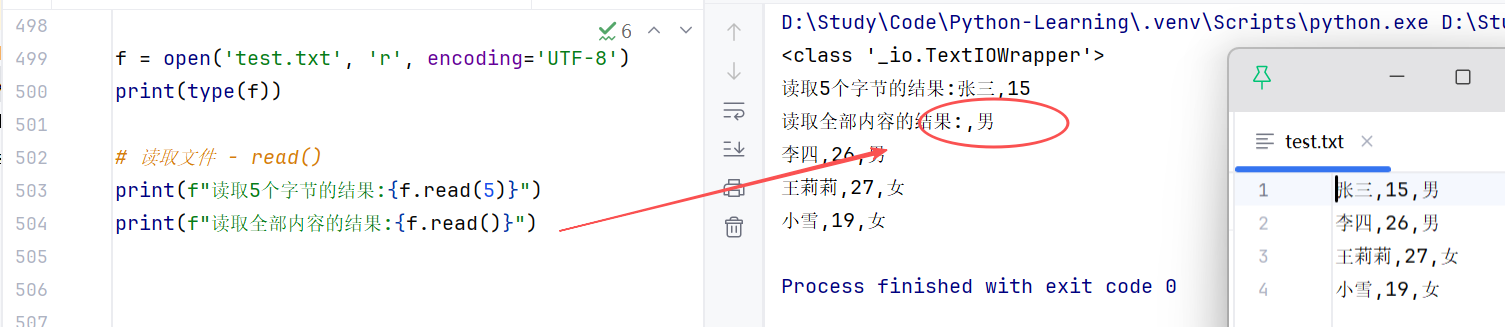
- read():文件对象.read(num),num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
//示例:注意,若连续使用 read() ,会从上一次读取截止处继续读取。
- readlines():按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
//示例2:

- readline():一次读取一行内容。

- for 循环读取文件行
(3)关闭文件
close():关闭对文件的占用,否则若此时程序仍在运行,则这个文件将一直被该程序占用。
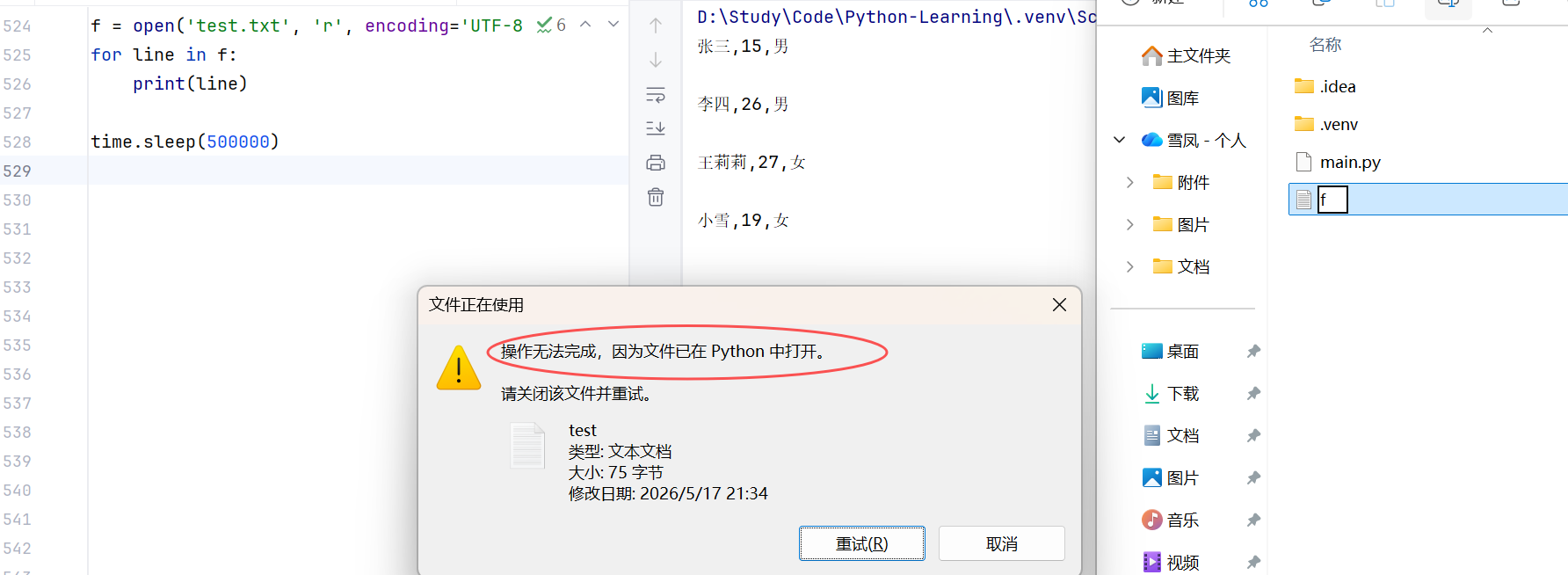
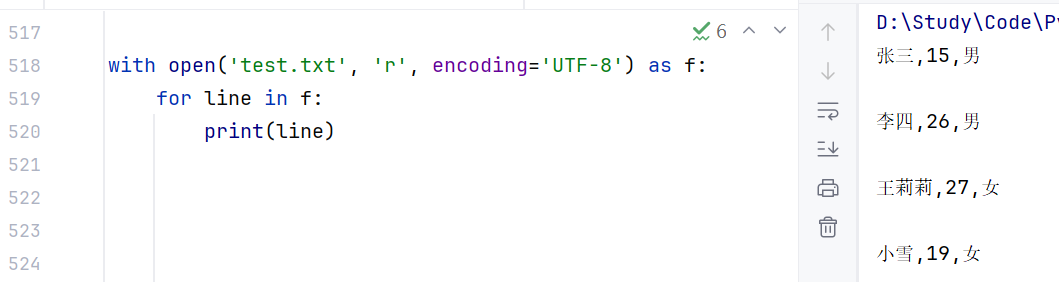
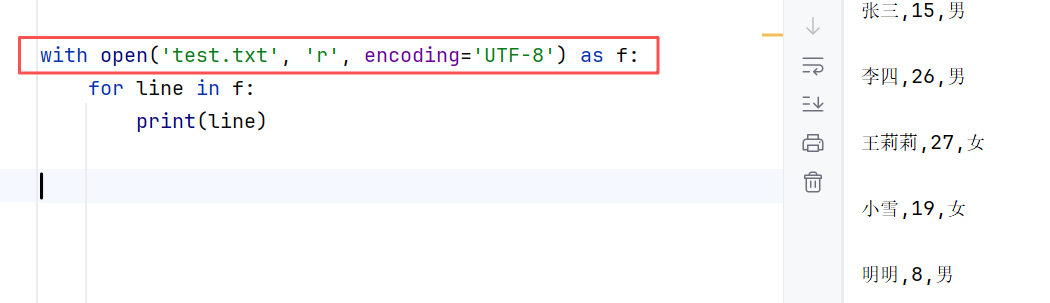
(4)with open 语法
可以自动关闭(不需要手动执行.close()方法)
5.3 文件的写入

//示例:若文件不存在则创建一个新文件;若文件已存在,则将write()内容覆盖旧内容

5.4 文件的追加
模式指定'a',若文件不存在则创建一个新文件;若文件已存在,则追加写入文件。

6 异常、模块与包
6.1 异常
(1)了解异常
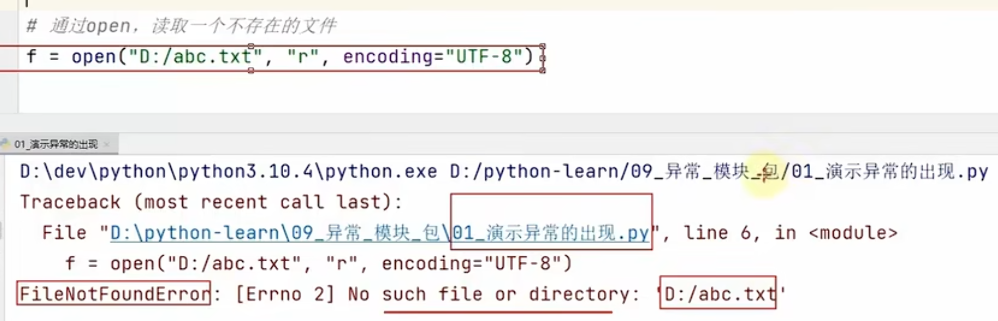
当检测到一个错误时,Python 解释器无法继续执行,反而出现了一些错误的提示,这就是所谓"异常,也就是我们常说的"BUG"。
//示例:
(2)为什么捕获异常
异常处理(捕获异常):我们要在力所能及的范围内,对可能出现的Bug,进行提前准备和处理。
我们的程序遇到了BUG,那么接下来会有两种情况:
①整个程序因为一个BUG停止运行; ②对BUG进行提醒,整个程序继续运行
在真实工作中,我们肯定不能因为一个小BUG就让整个程序全部崩溃,我们希望达到②。
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的异常出现的时候,可以有解决方式,而不是任其导致程序无法运行。
(3)如何捕获异常
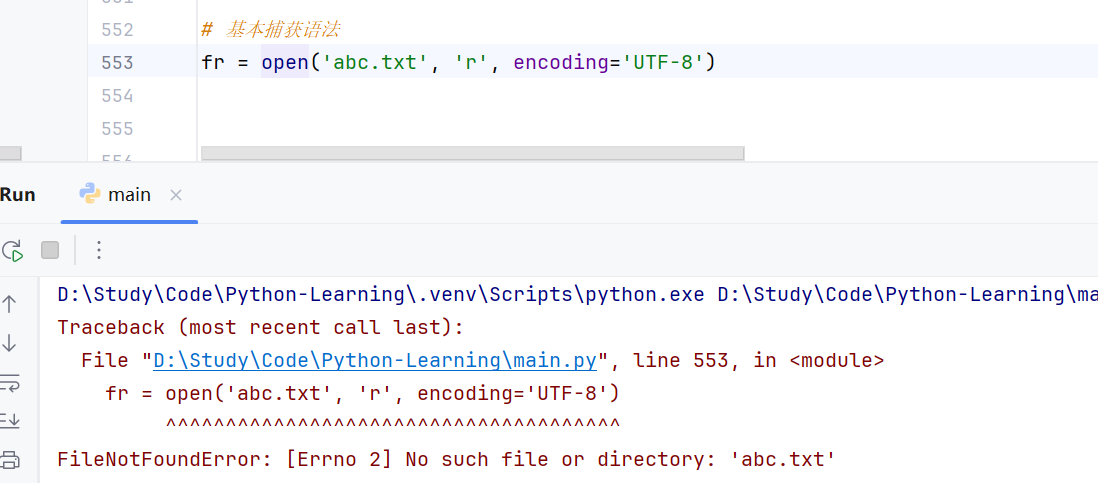
①捕获常规异常

//示例:打开一个不存在的文件
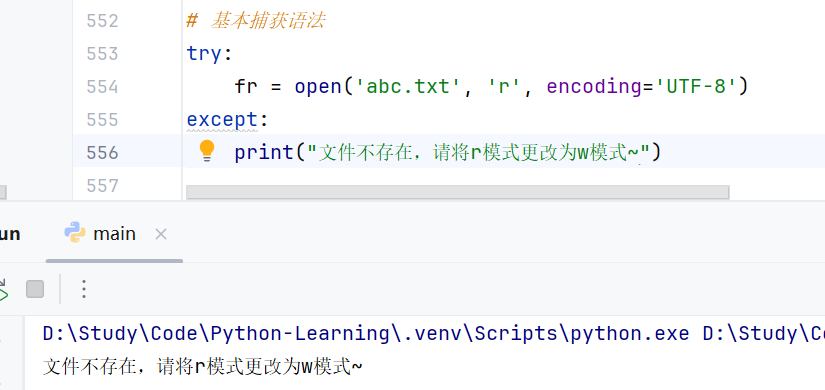
②捕获指定异常
如果尝试执行的代码异常类型和要捕获的异常类型不一致,则无法捕获异常;一般 try 下方只放一行尝试执行的代码。
//示例:(左)捕获指定异常成功; (右)捕获指定异常失败
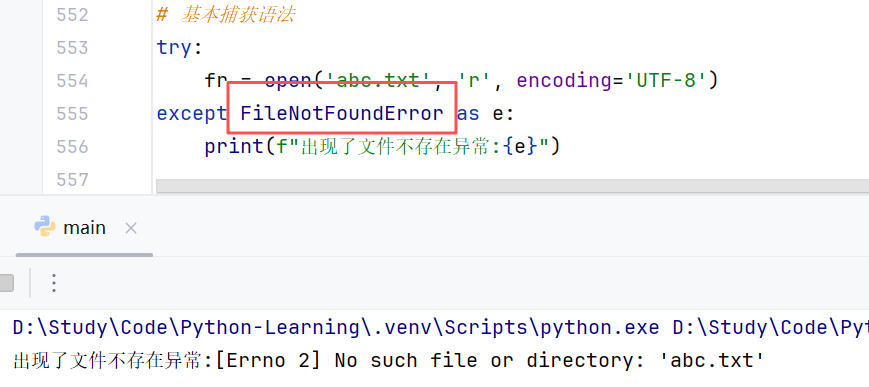
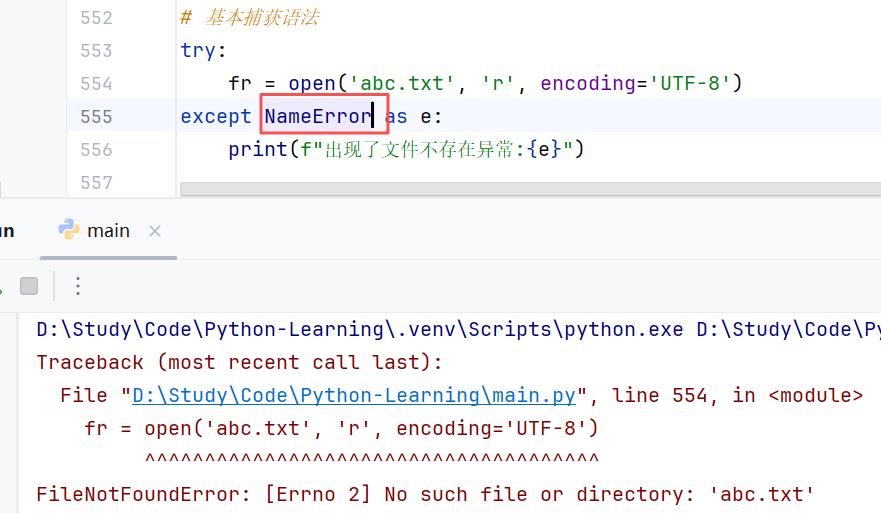
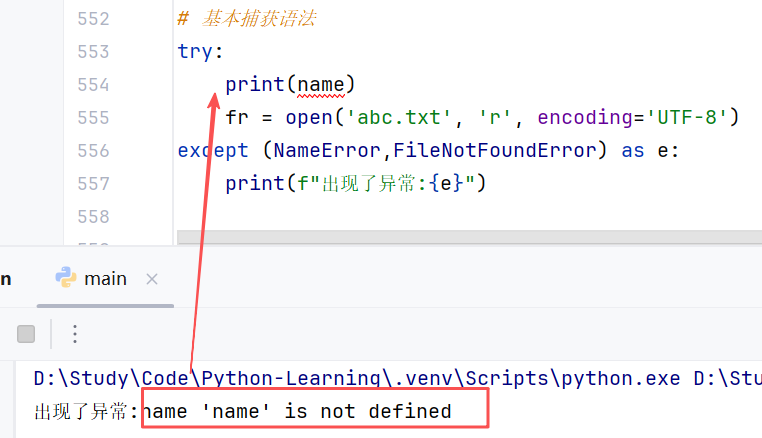
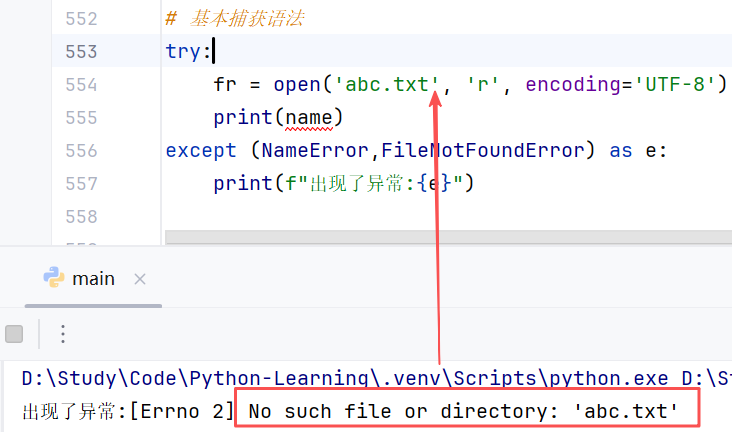
③捕获多个异常

//示例:捕获最先出现的异常
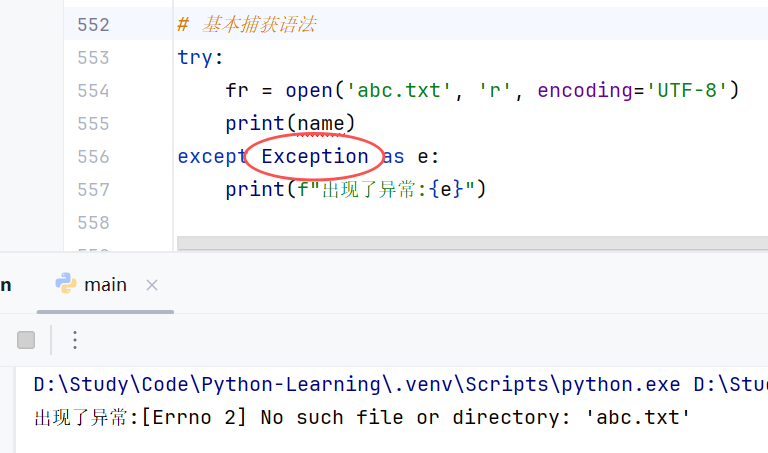
④捕获全部异常
当我们不确定会发生什么类型的异常时,可以写捕获所有异常,且写法①也是捕获全部异常。
//示例:
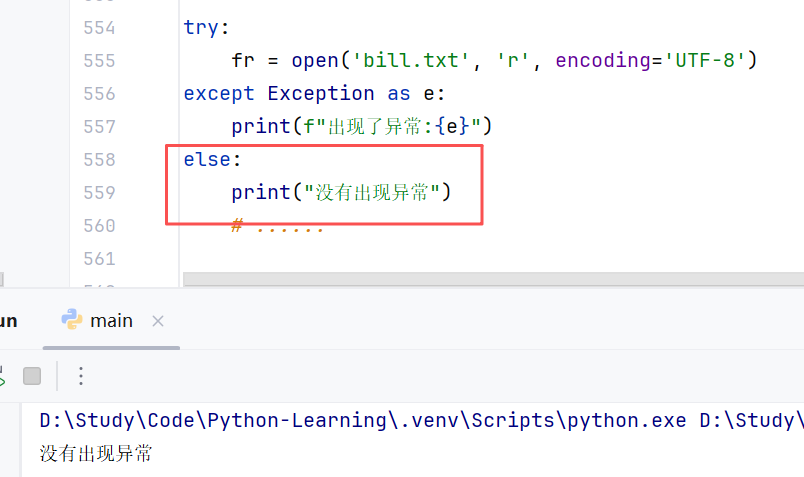
⑤异常的else和finally语法
- else:表示如果没有出现异常而要执行的代码。(可选)
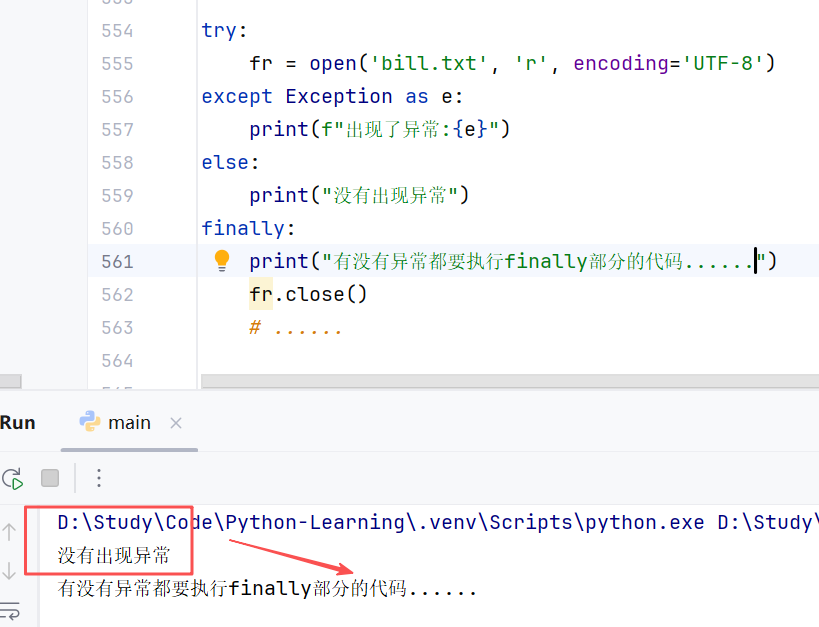
- Finally:表示无论是否异常都要执行的代码,例如关闭文件(可选)
//示例:
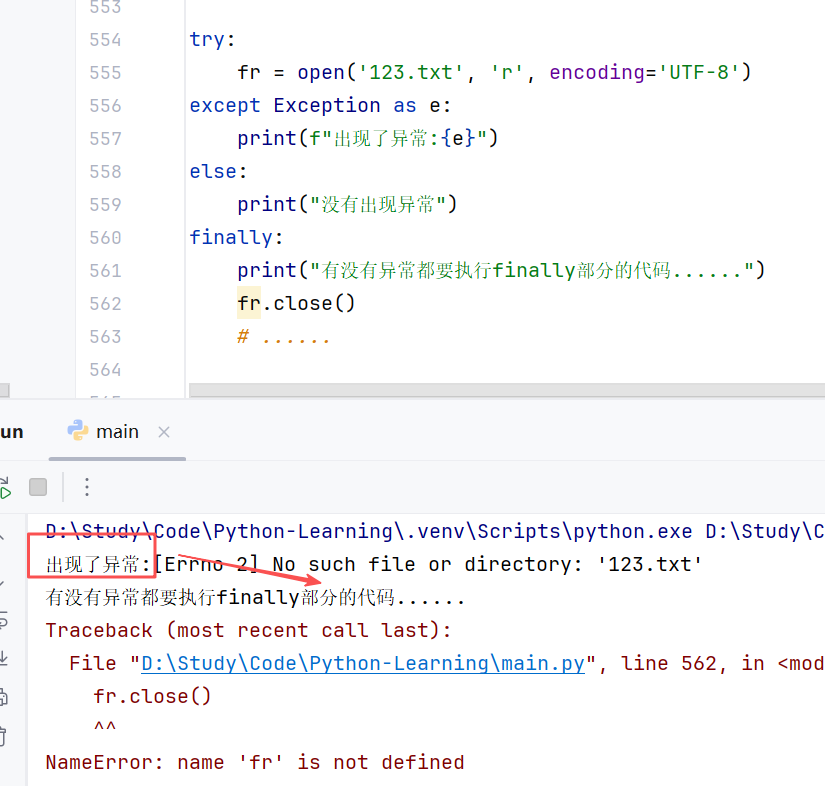
(4)异常的传递
可以在高层级捕获到低层级的异常。

6.2 Python模块
(1)什么是模块
Python 模块(Module),是一个Python 文件,以.py结尾,模块能定义函数、类和变量,模块里也能包含可执行的代码。
- 模块的作用:python中有各种不同的模块,每一个模块都可以帮助我们快速实现一些功能,比如实现和时间相关的功能就可以使用time模块,我们可以认为一个模块就是一个工具包,每一个工具包都有各种不同的工具供我们使用进而实现各种不同的的功能。
(2)模块的导入
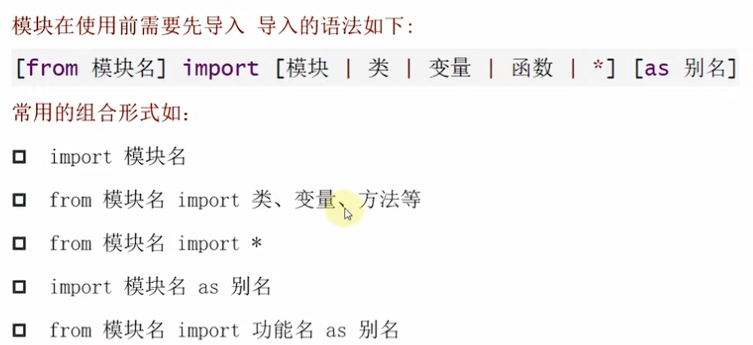
//示例:

(3)自定义模块
- 在Python代码文件中正常写代码即可;通过import、from关键字导入即可使用;
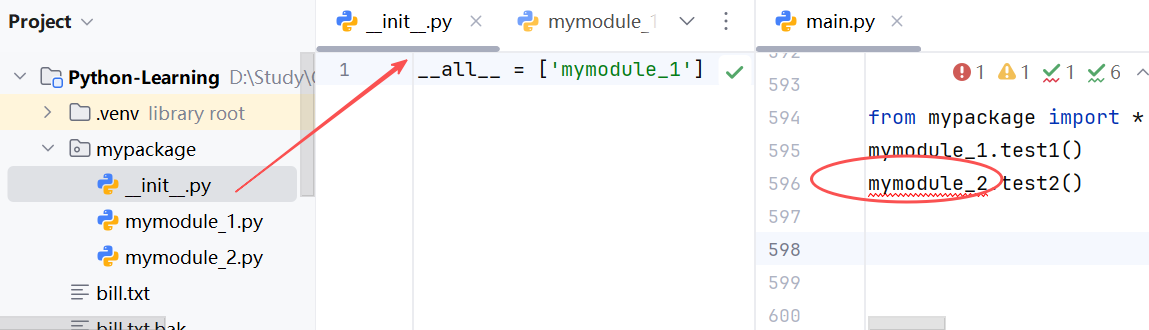
- 当导入的模块中有测试函数(或会直接执行的代码),此时要将 这部分代码使用 if name == "main"包含起来,它表示:只有当程序是直接执行的才会进入 if 内部执行,若是被导入的,则无法进入 if 执行这部分代码。
- 当导入不同模块的同名功能、类等,后导入的会覆盖先导入的;
- 对于 *,若模块中没有 __all__变量(list变量),则可以直接导入所有功能;若有,则只能导入 __all__中控制指定的功能。
6.3 Python 包
基于Python模块可以在编写代码的时候导入许多外部代码来丰富功能,但是若模块太多,就可能造成混乱!------通过Python包的功能来管理。
(1)了解Python包
- 从物理上看,包就是一个文件夹,在该文件夹下包含了一个 init.py文件,该文件夹可用于包含多个模块文件。
- 从逻辑上看,包的本质依然是模块。
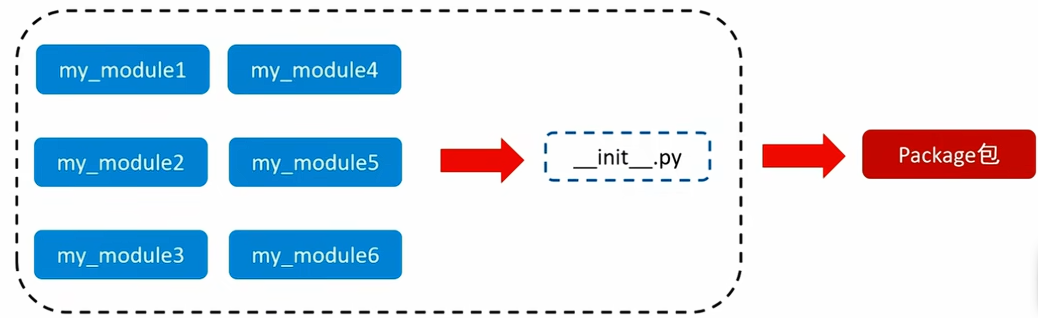
包的作用:当我们的模块越来越多,包可以帮助我们管理这些模块,包的作用就是包含多个模块,本质还是模块。(有__init__.py→Python包;没有__init__.py→普通文件夹)
(2)自定义包
- 方式1:import 包名.模块名 / from 包名 import 模块名 / from 包名.模块名 import 功能.....
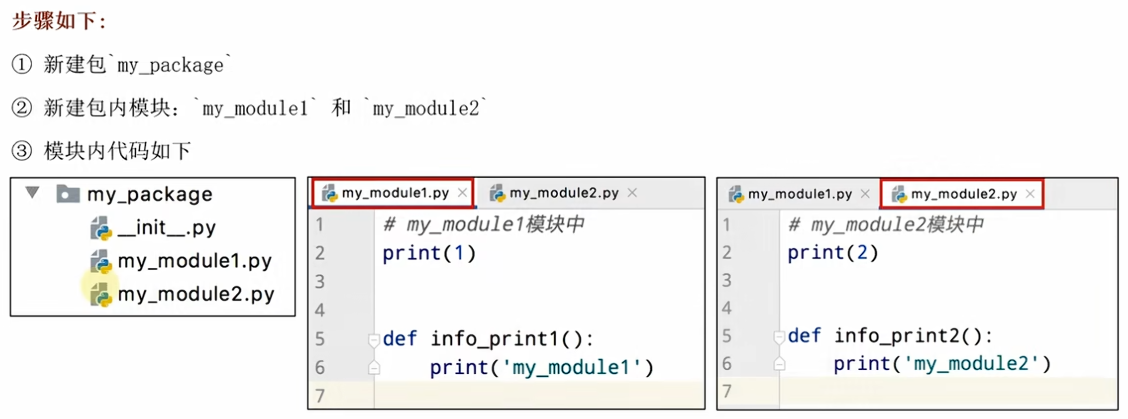
//示例:
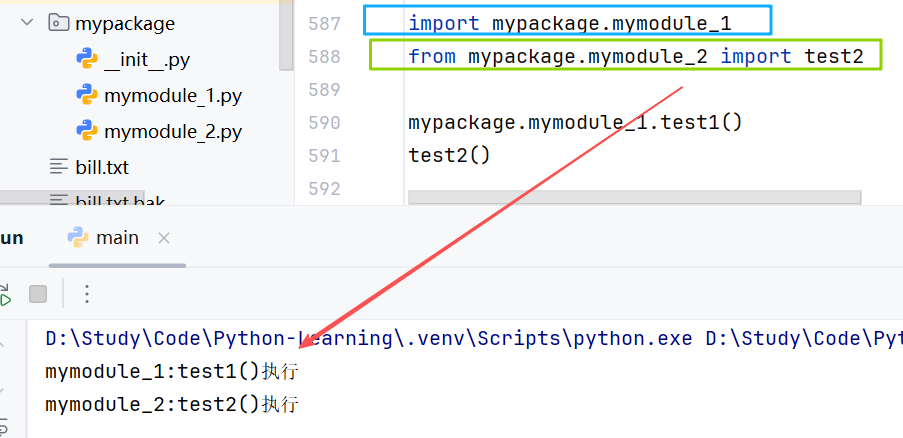
- 方式2:__all__控制 import * 能够导入的内容
(3)安装第三方包

- 命令提示符:① pip install 包名称 ② pip的网络优化(镜像):pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
- pytharm安装:
7 Python基础综合案例
7.1 数据来源

7.2 json数据格式



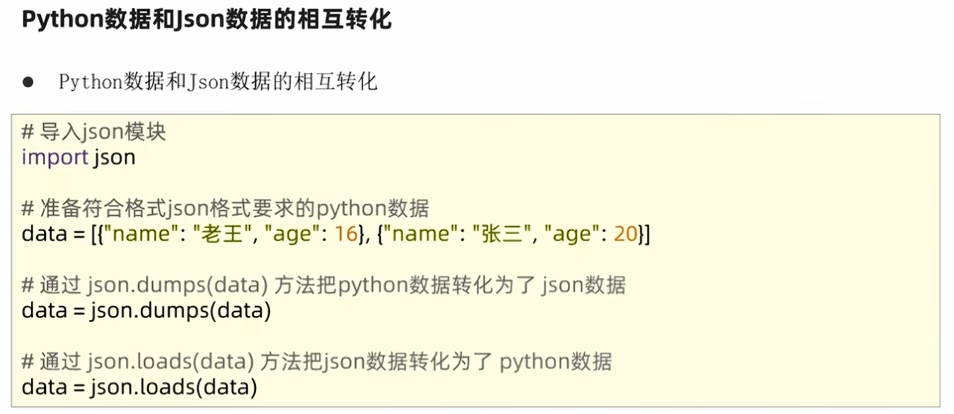
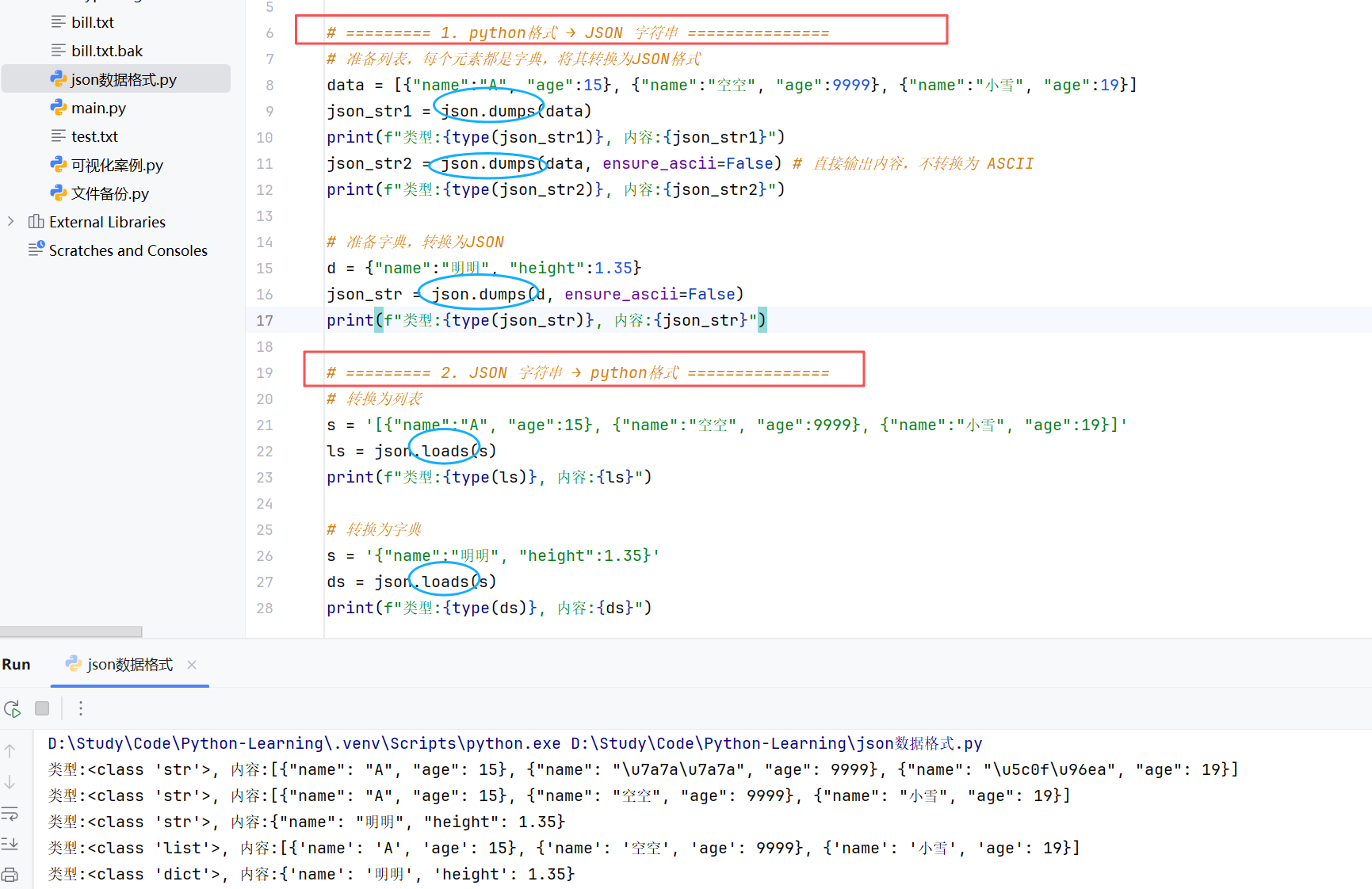
//示例:Python使用JSON有很大优势,因为JSON无非就是一个单独的字典或一个内部元素都是字典的列表,所有JSON可以直接和Ptrhon的字典或列表进行无缝转换。
7.3 pyecharts模块介绍
画廊网站:Bar3d - Bar3d_base - Document
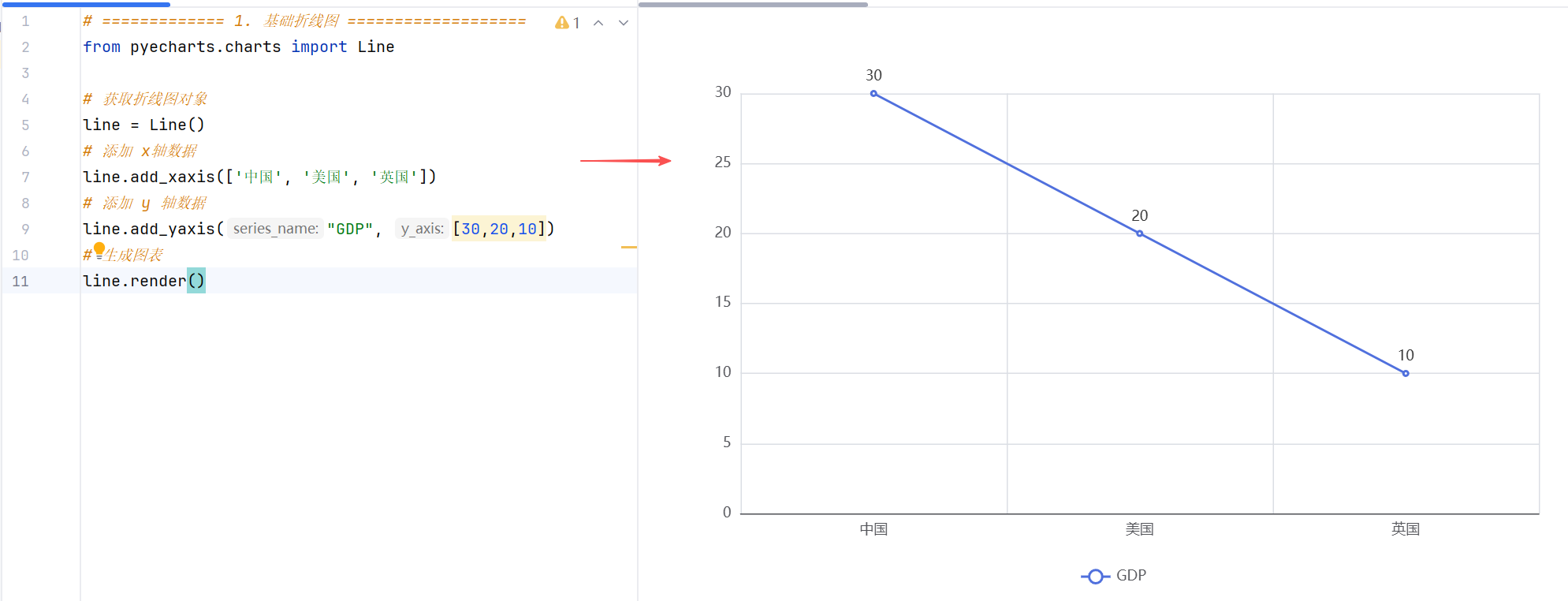
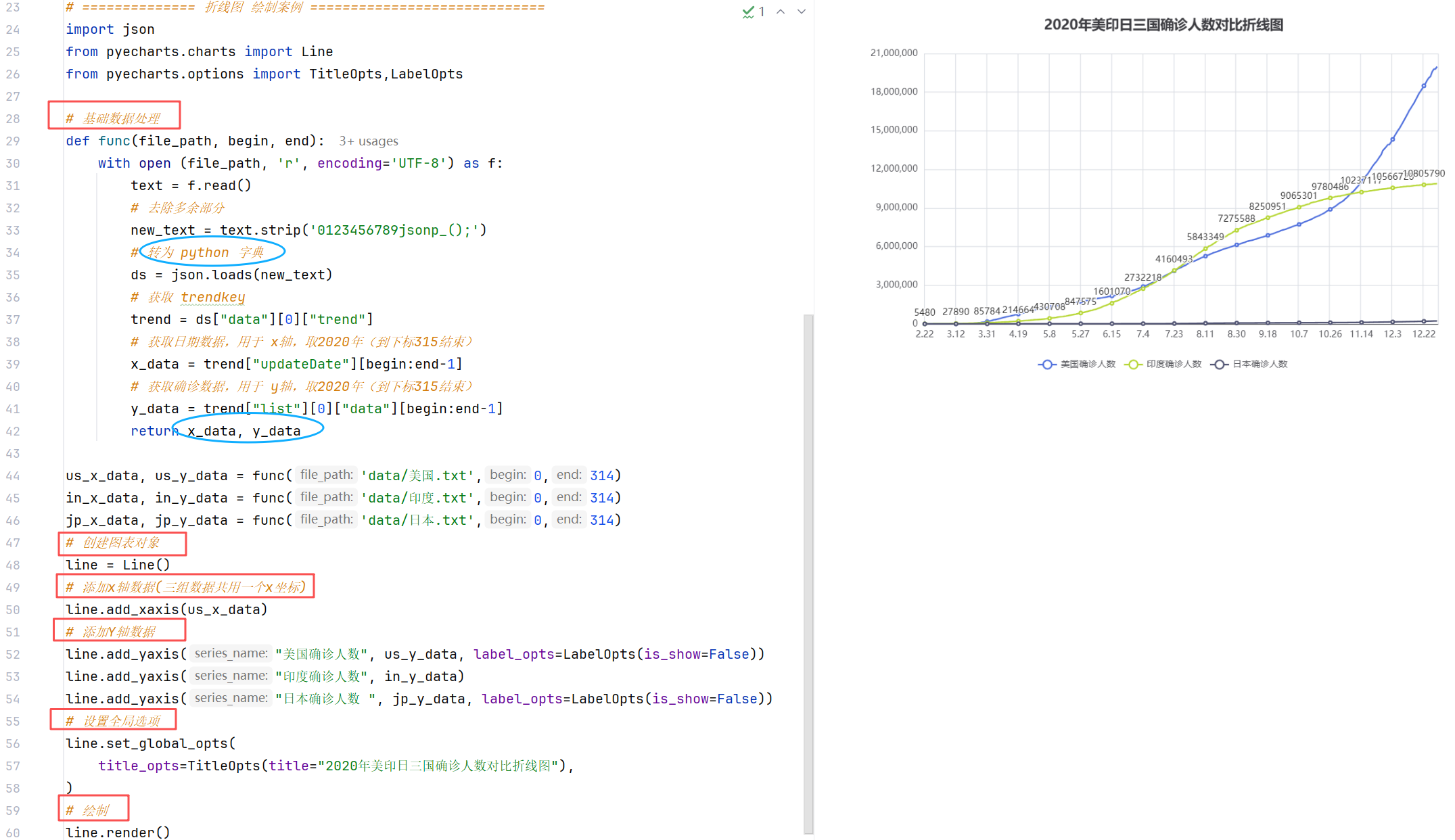
案例1:折线图绘制
//示例1:最后一行得到render.html文件,在浏览器中打开预览。
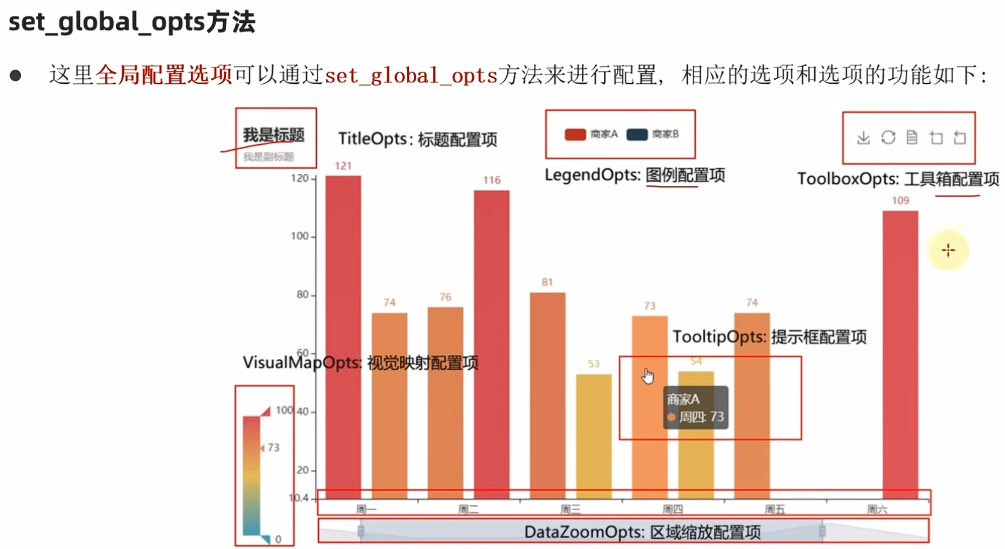
pyecharts模块中有很多配置选项,常用到2个类别的选项:
**①全局配置选项:**标题、图例、提示框、工具箱等------元素层级的配置
**②系列配置选项:**数据层级的配置
(更多了解:图表配置 - pyecharts - A Python Echarts Plotting Library built with love.)
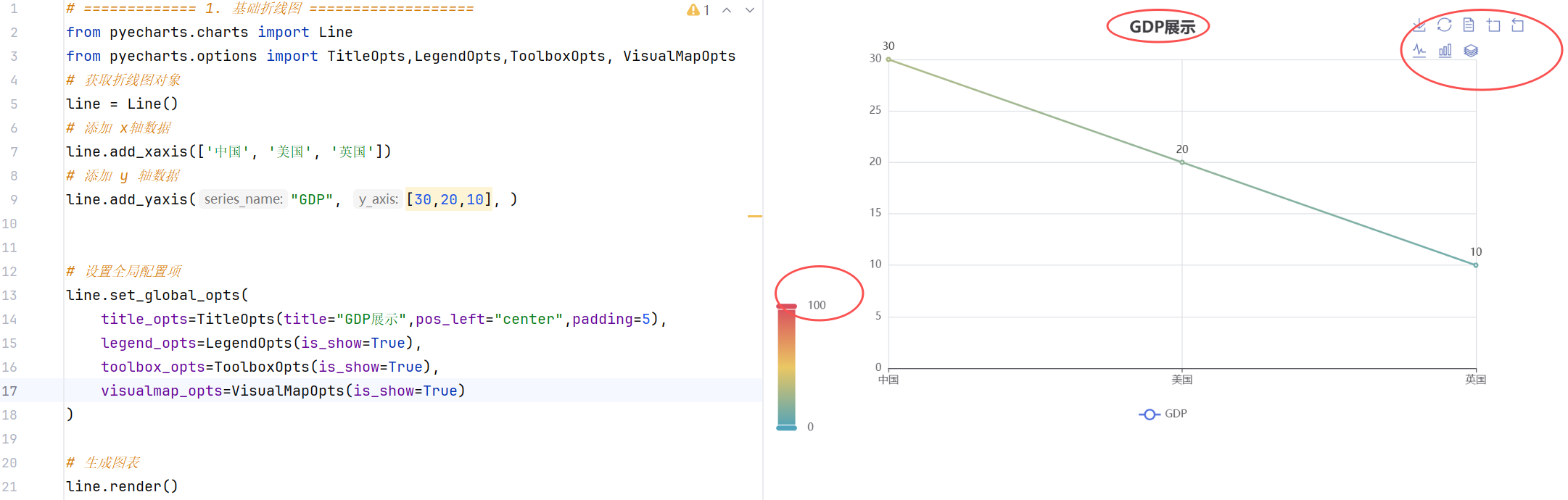
//示例2:设置全局配置选项
json视图查看工具:在线JSON格式化工具-json在线校验-json在线解析

数据处理:将前后两个多余部分去除。
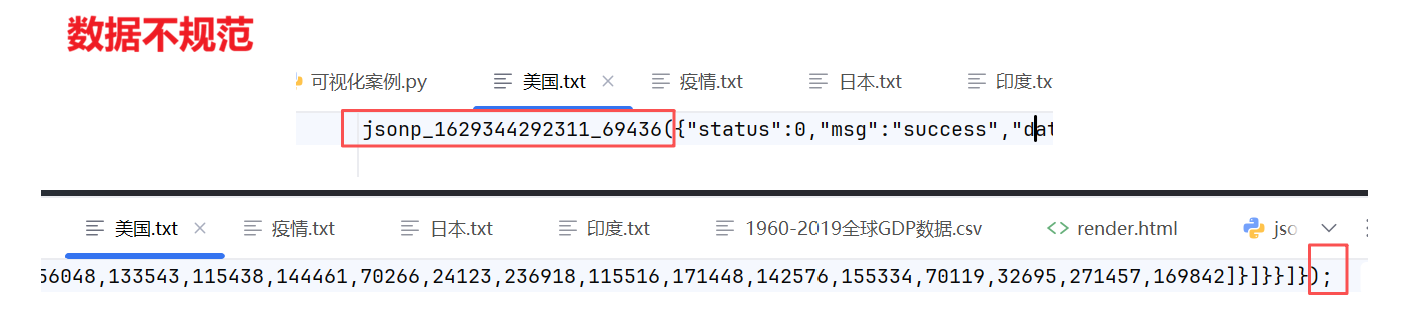
//示例3:三个文件的前后冗余数据由数字和'jsonp_'以及');'构成,可以使用 strip() 去除,因此对文件的处理可以封装为一个函数。
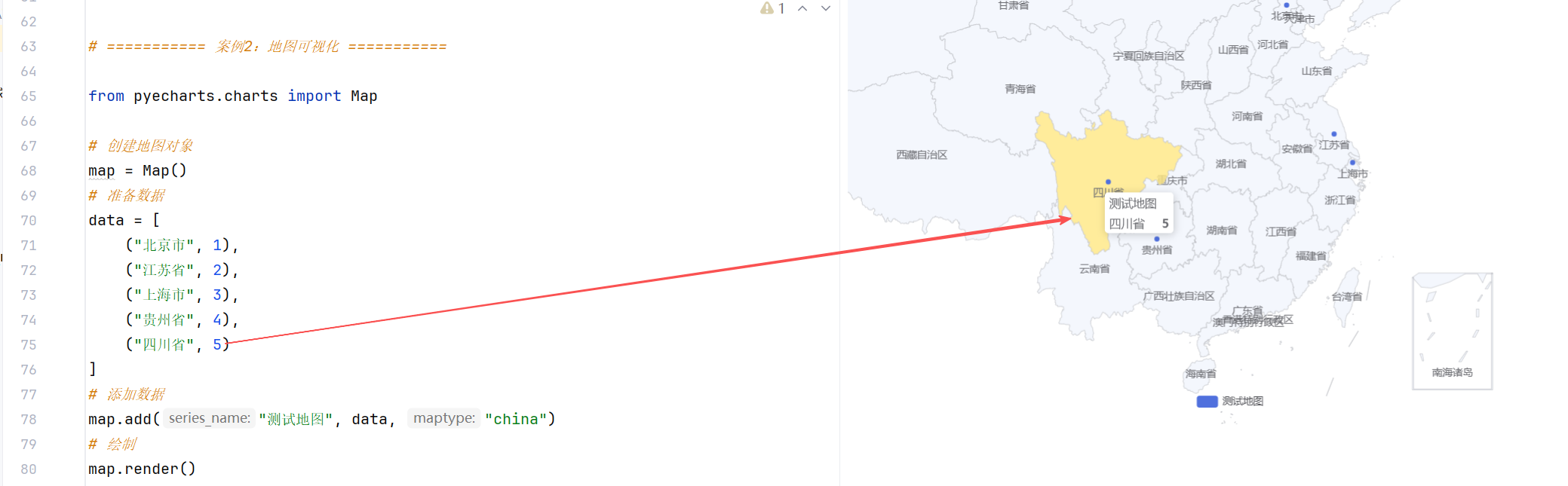
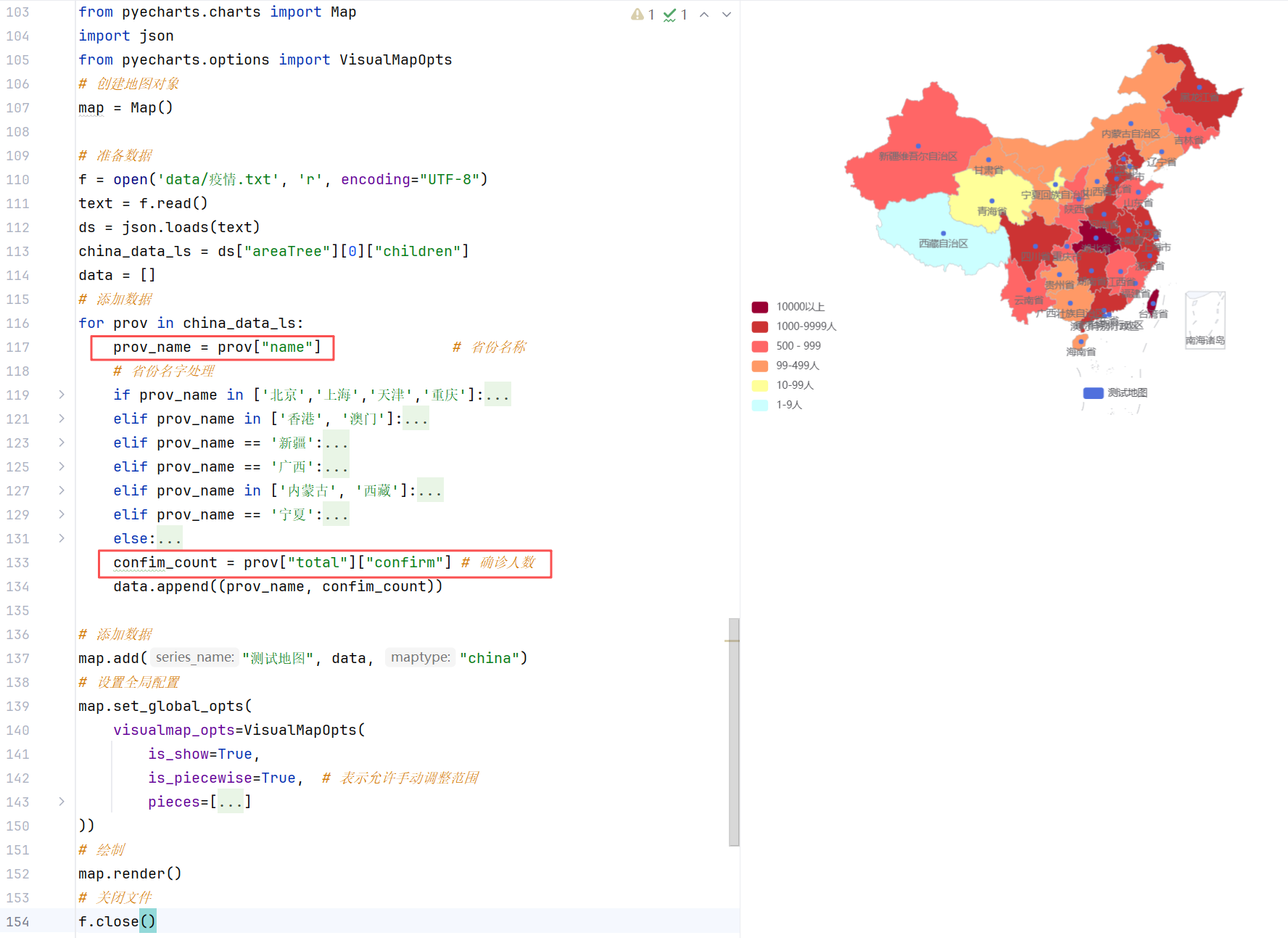
案例2:地图可视化
//示例1:通过Map对象绘制地图
//示例2:通过全局配置项设置视觉显示器
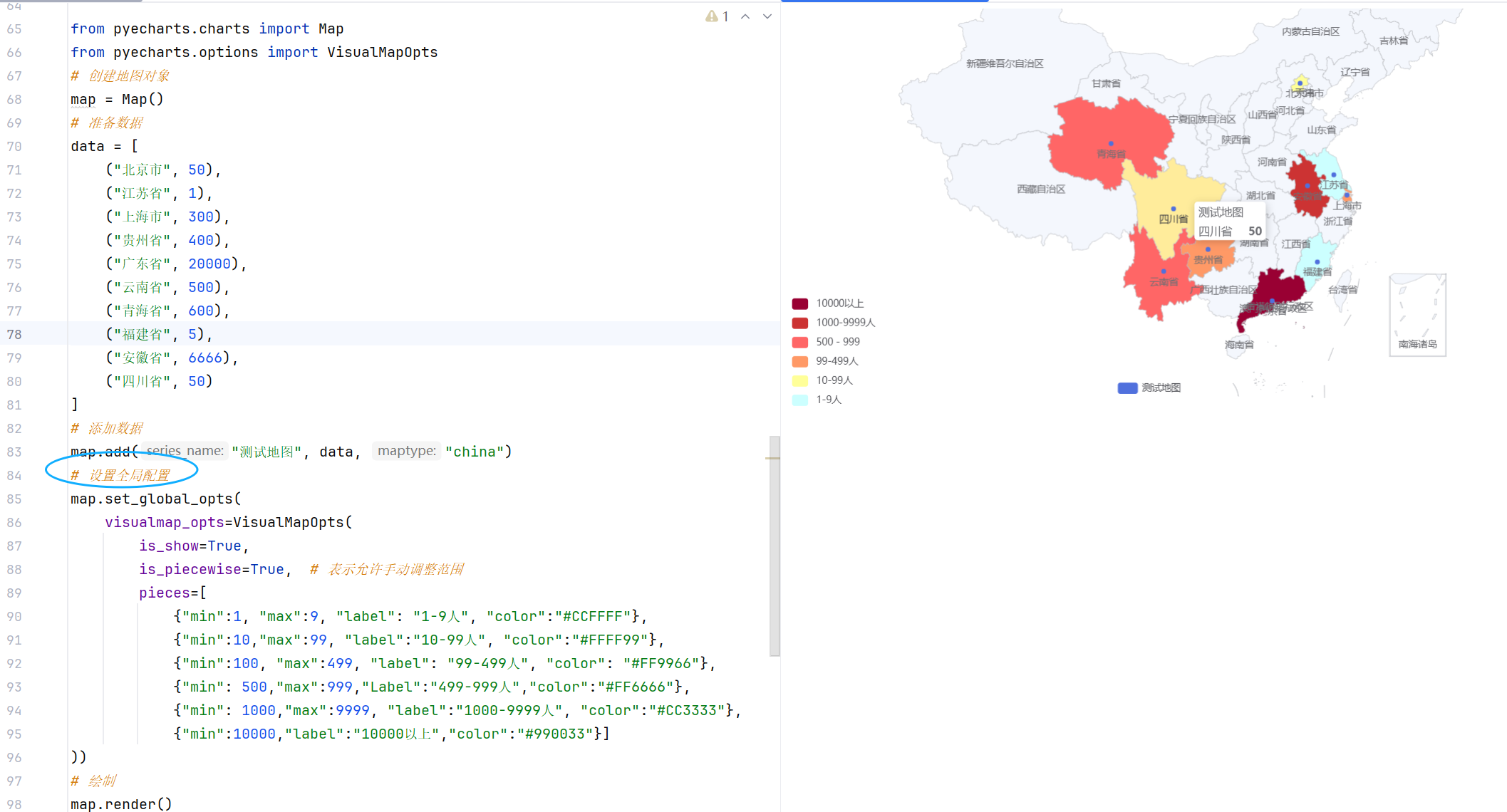
//示例3:全国每个省份的确诊信息
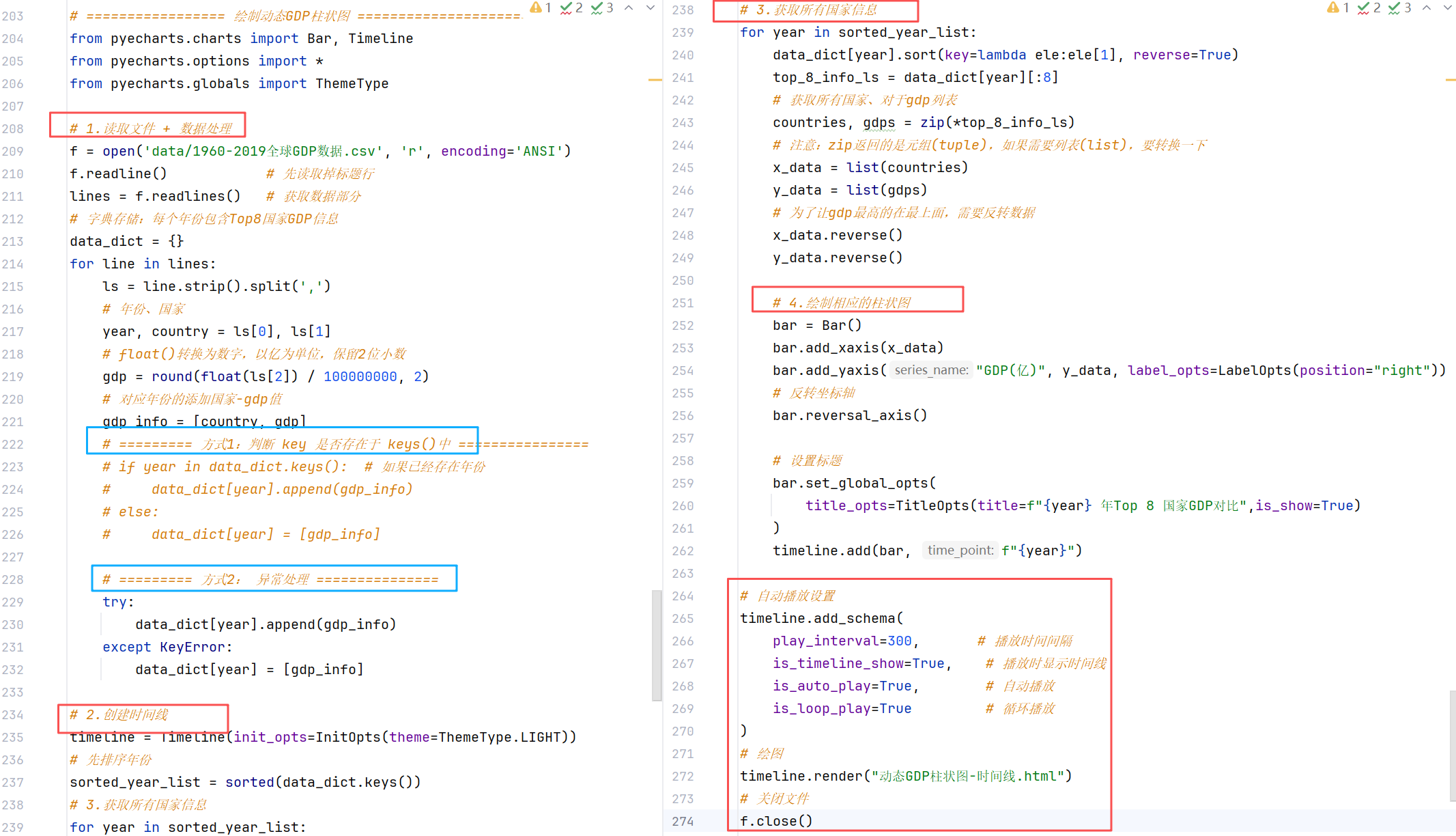
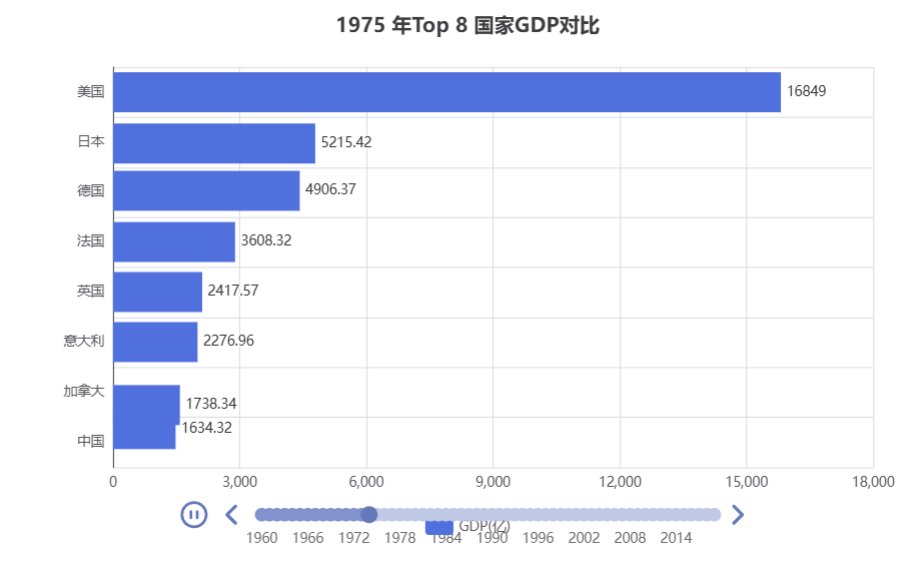
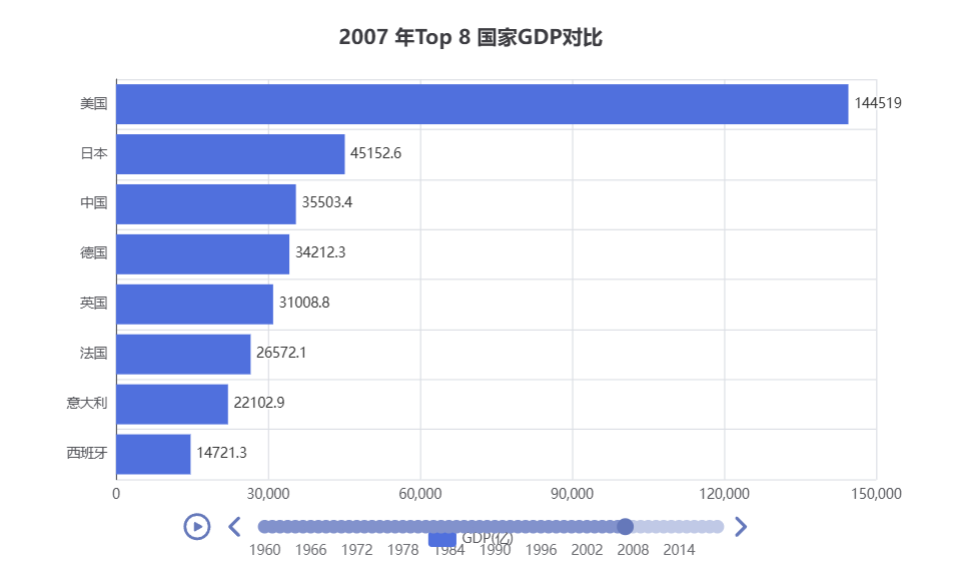
案例3:动态柱状图
//示例1:基础柱状图

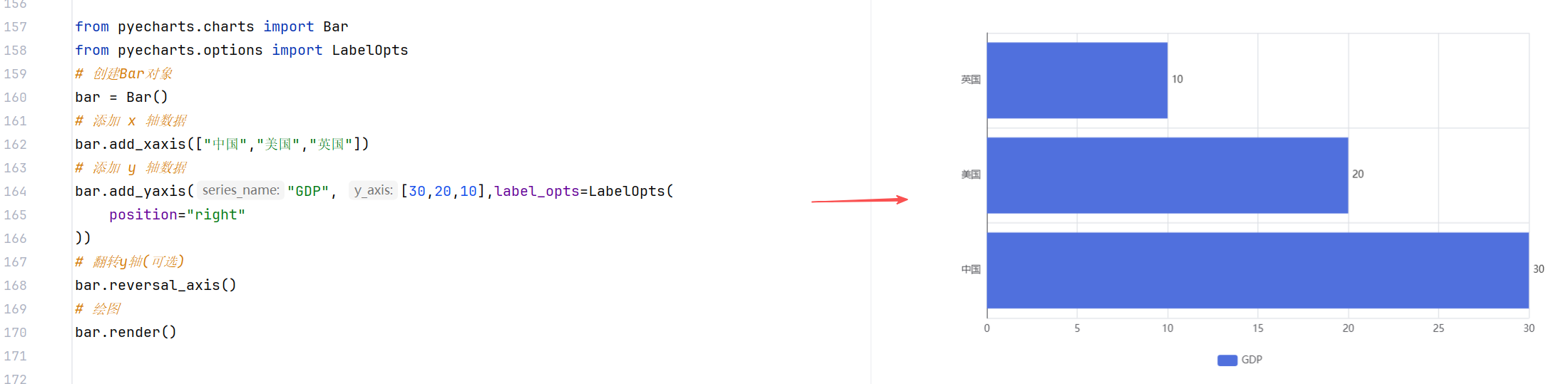
//示例2:基础时间线柱状图
Timeline()-时间线
柱状图描述的是分类数据,回答的是每一个分类中 有多少? 这个问题,很难动态描述一个趋势性的数据。pyecharts为我们提供了一种解决方案-时间线 ------ 创建一个一维的 x 轴,轴上每一个点就是一个图标对象!

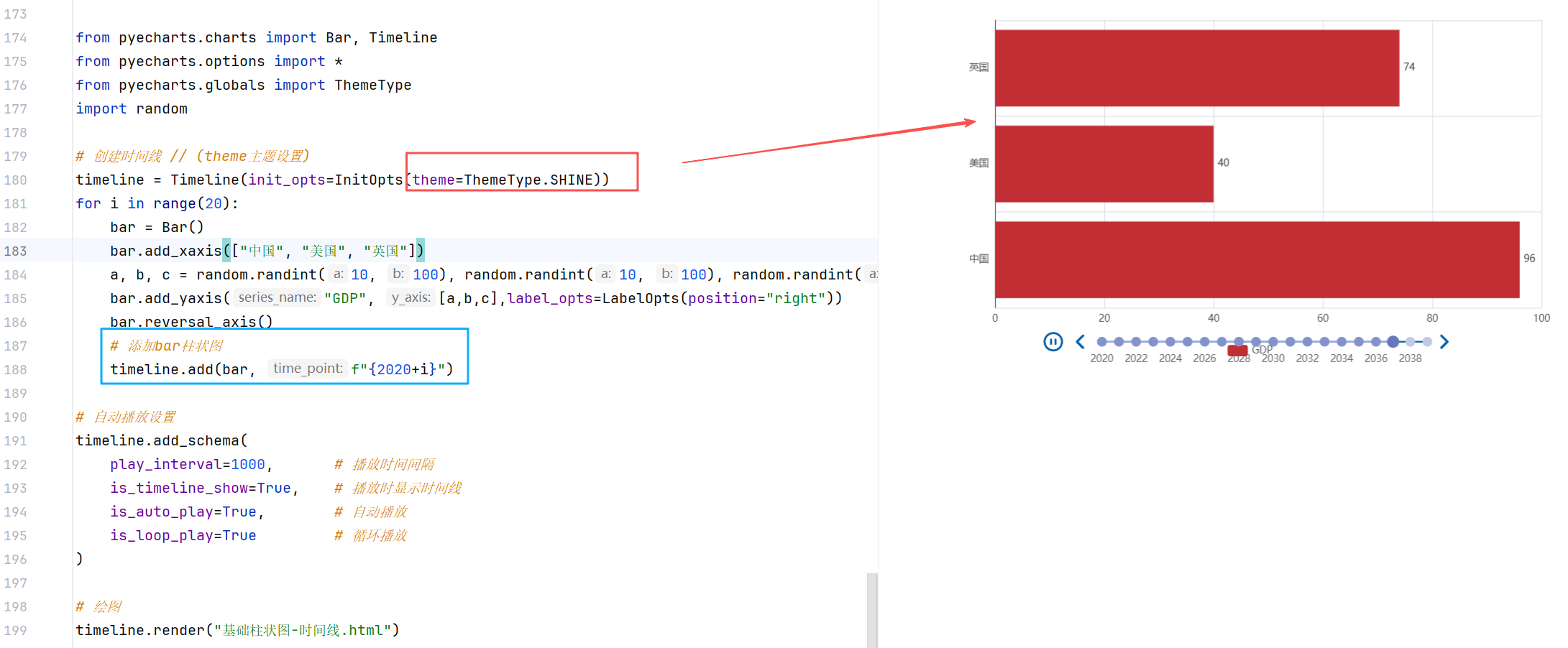
//示例3:GDP动态柱状图绘制
sorted函数可以对数据容器进行排序,但是不能自定义规则(之前不同数据类型的排序就报错了)
sort()可以实现:列表.sort(key=选择排序依据的函数,reverse=True|False)。
- Key:要求传入一个函数。表示将列表的每一个元素都传入函数中,返回排序的依据
- reverse:是否反转排序结果,True表示降序,False表示升序。