一、工具包准备
所需要的工具包:EEGlab,ERPlab。
将ERPlab解压后放在eeglab文件夹内的plugins文件夹下。
然后打开matlab, 将整个EEGlab包加载进去。
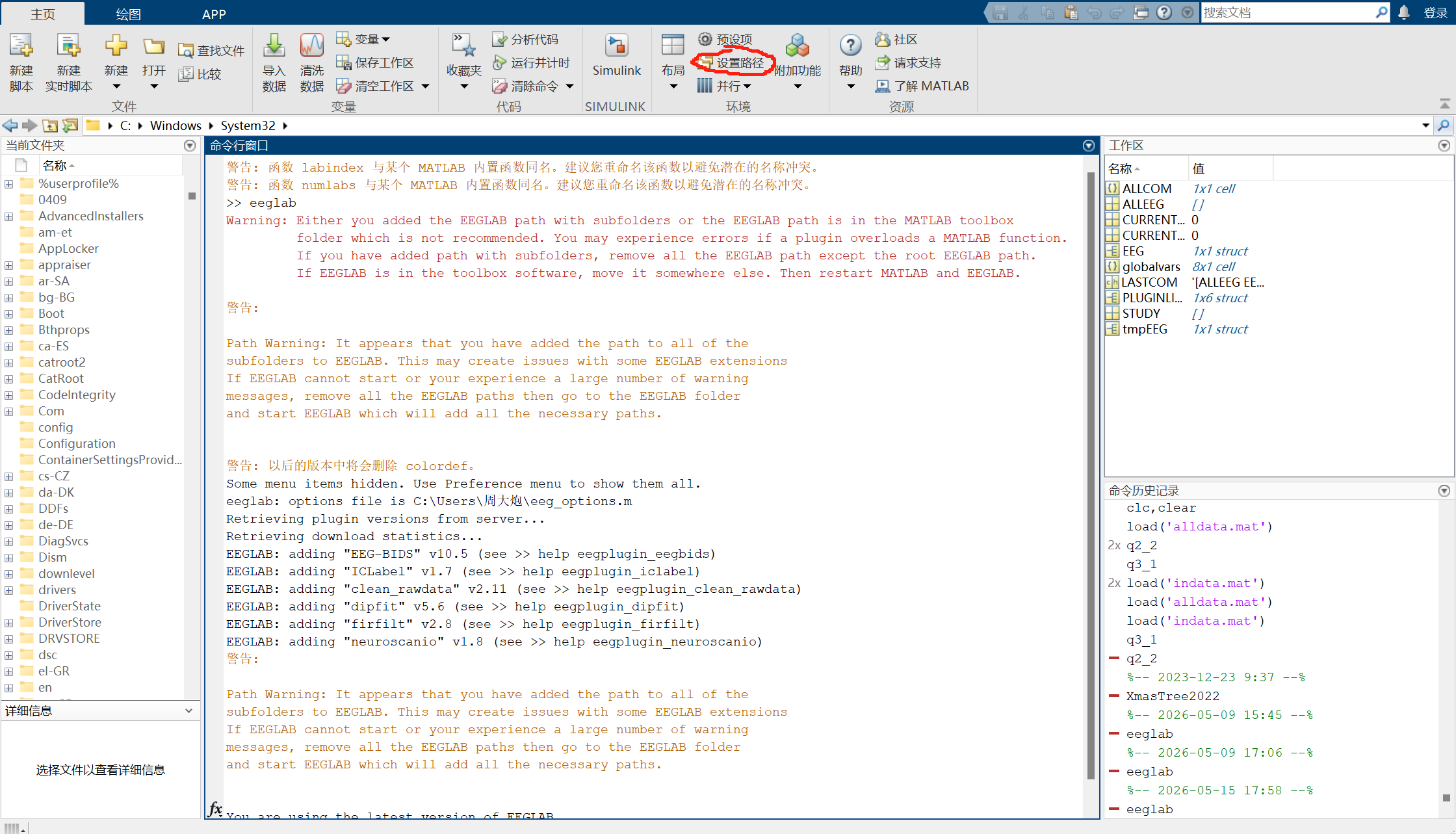
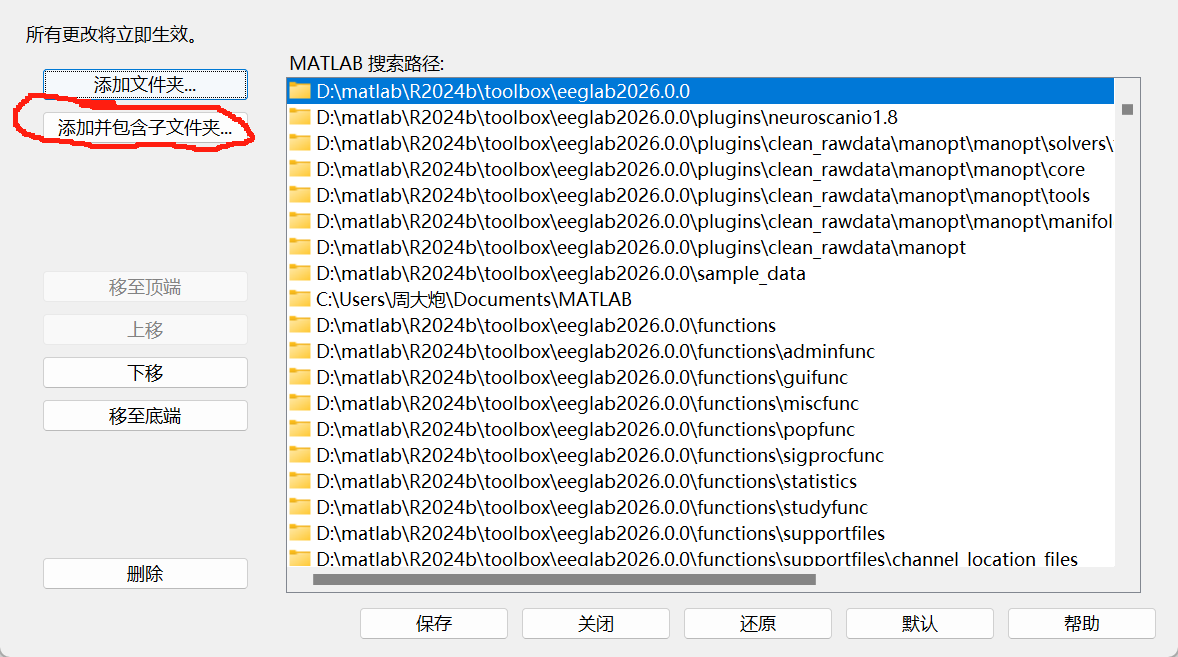
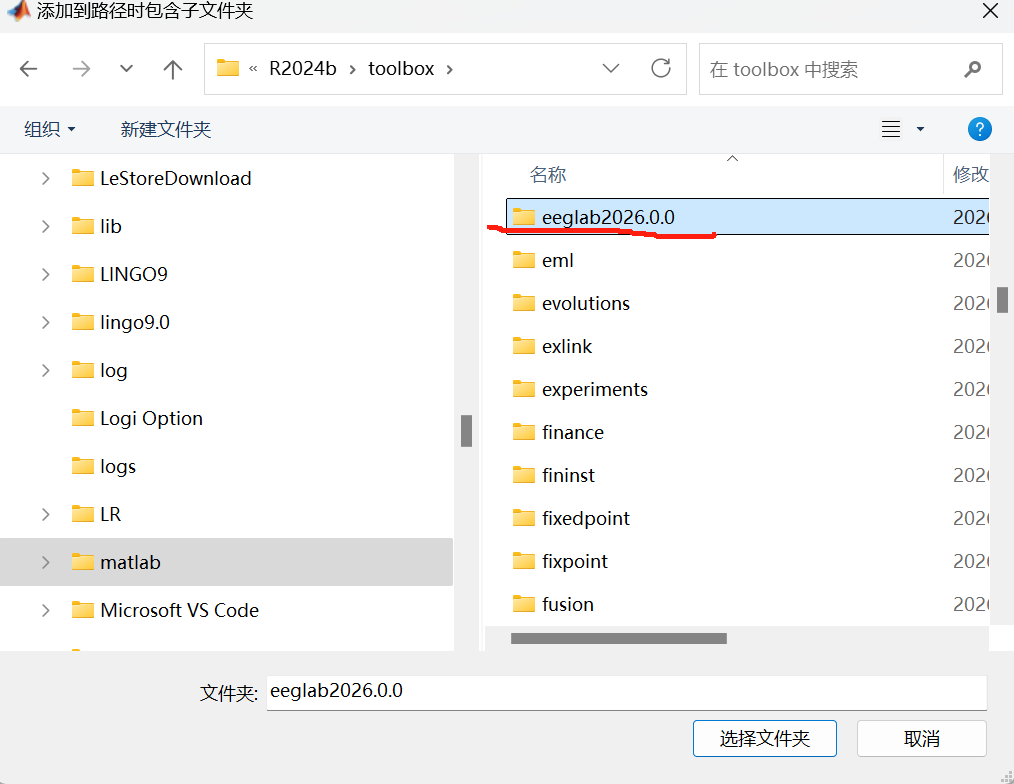
养成好的习惯:每次用matlab前将set path恢复为默认设置,再添加新的包;将当前路径调整为数据所在路径(或者你的工作文件夹)。
二、单被试预处理
记得将路径换成工作路径(你所要处理的数据所在的位置)
数据处理的基本逻辑:
1、读取数据(获取路径、文件名等信息)
2、进行处理
3、数据存储(存储数据的名称、路径)
单被试数据处理流程:
我们在脑电数据预处理之前首先先要引用一些文献:

防御审稿人攻击你数据处理是否规范的手段。
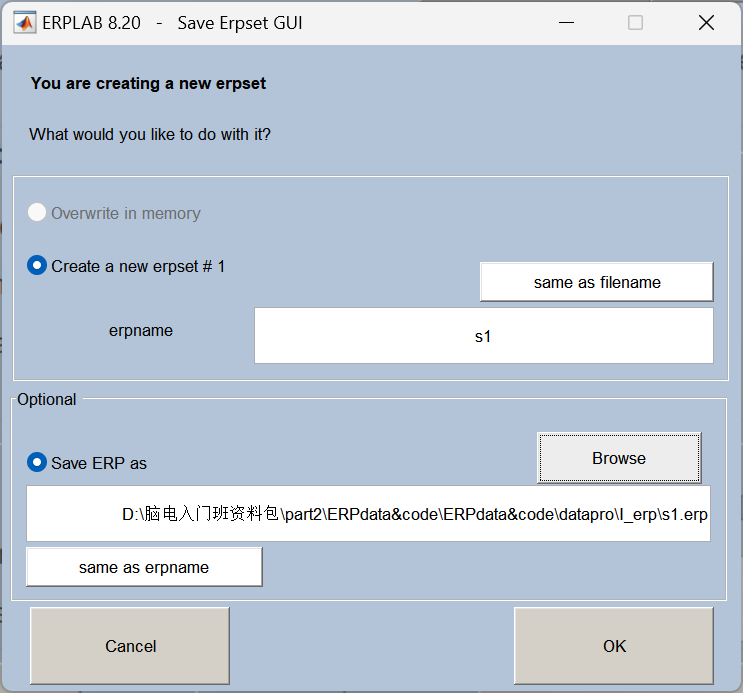
1、 Load data**(加载数据)**
此处就是命名,直接ok。
此处已经导入成功,显示数据信息。
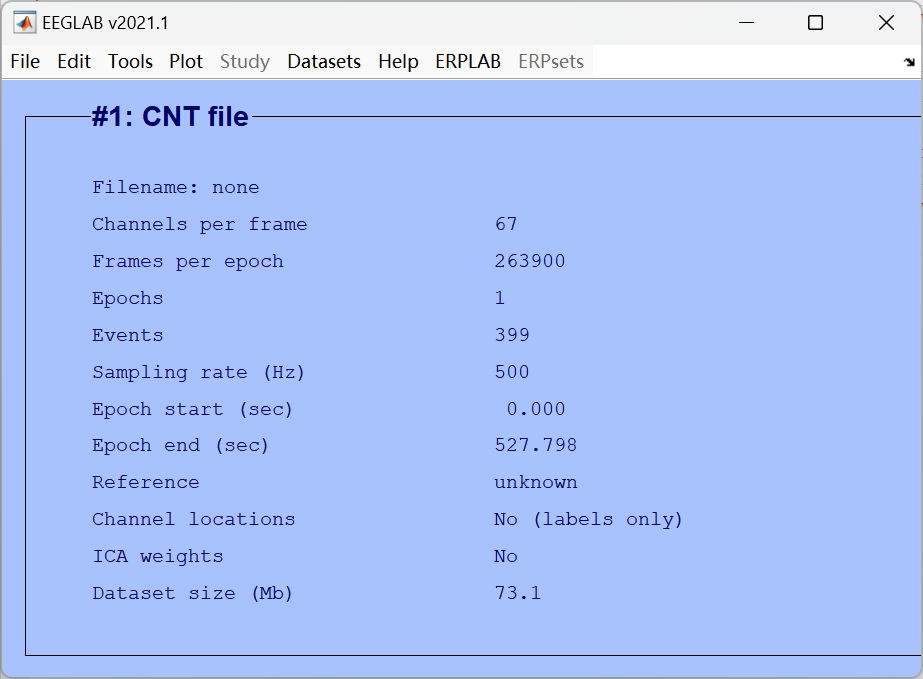
| 参数 | 数值 | 通俗解释(笔记版) |
|---|---|---|
Channels per frame |
67 | 每帧数据的通道数 = 你戴的 EEG 帽子上有67 个电极,每个电极对应 1 个通道的信号。 |
Frames per epoch |
263900 | 每个 epoch(数据片段)里有 263900 个采样点,这里因为还是连续数据,所以等于整个实验的总采样点数。 |
Epochs |
1 | 当前数据还是连续数据,还没按刺激分段(epoch),所以只有 1 个大的 "片段"。 |
Events |
399 | 实验过程中一共记录了399 个事件标记(trigger),比如刺激出现、按键反应的标记,后面用来分段和分组。 |
Sampling rate (Hz) |
500 | 采样率 = 每秒采 500 个数据点,也就是每 2 毫秒就记录一次脑电信号,采样率越高,信号越精细。 |
Epoch start (sec) |
0.000 | 数据的起始时间是 0 秒,也就是实验开始的那一刻。 |
Epoch end (sec) |
527.798 | 数据的结束时间,整个实验记录了约 527.8 秒,大概 8 分多钟。 |
Reference |
unknown | 参考电极未知,后续需要做重参考处理(比如换成平均参考),这是 EEG 预处理的关键步骤之一。 |
Channel locations |
No (labels only) | 只有通道的名称标签,没有电极在头皮上的位置信息,后续需要加载通道位置文件,才能做坏电极插值、画地形图等操作。 |
ICA weights |
No | 还没有做 ICA(独立成分分析),所以没有 ICA 权重,后面去除眼电、肌电伪迹时会用到。 |
Dataset size (Mb) |
73.1 | 这个数据集的文件大小是 73.1MB,属于正常的 EEG 数据大小。 |
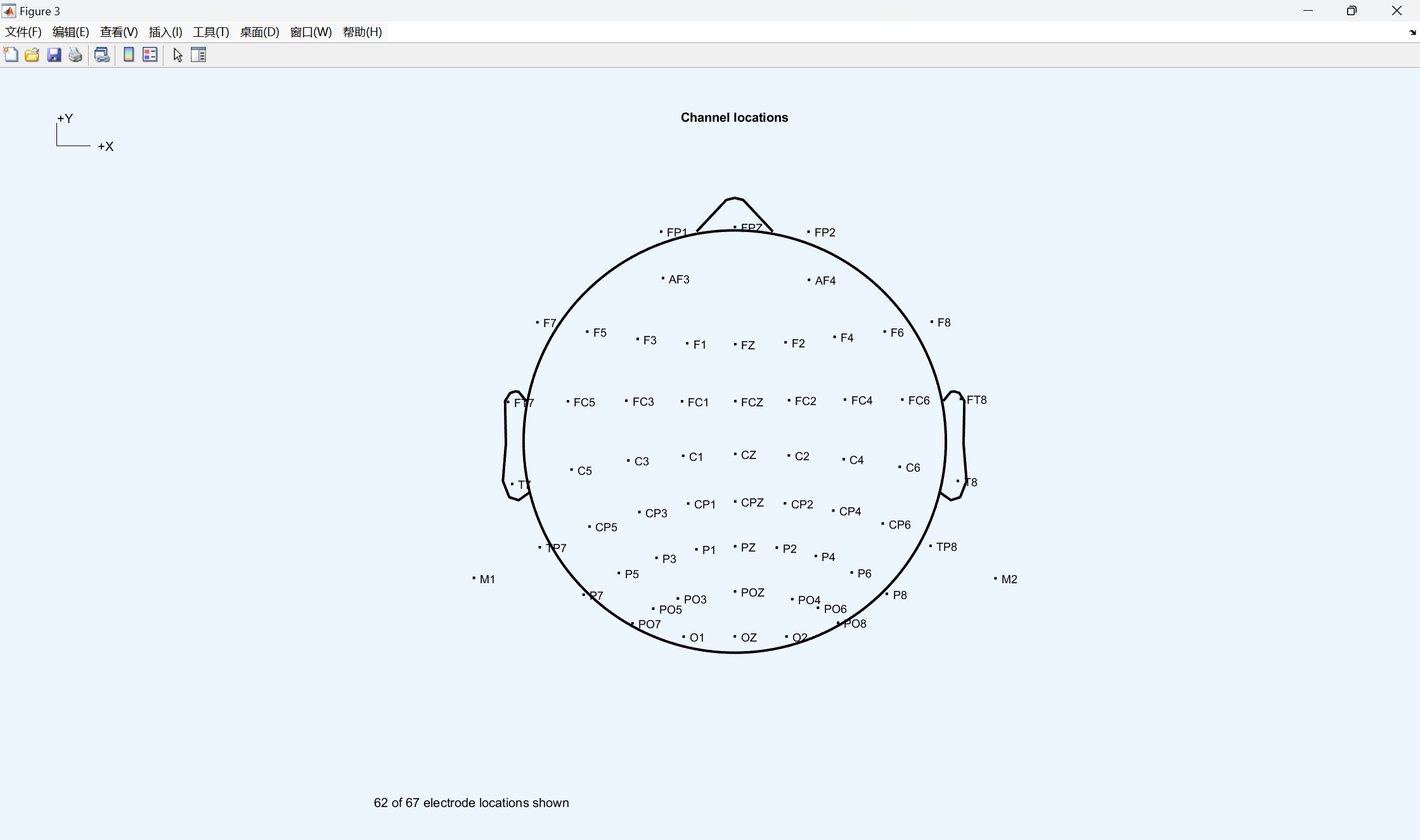
2、 Channel location**(电极位置设置)**
正常情况:
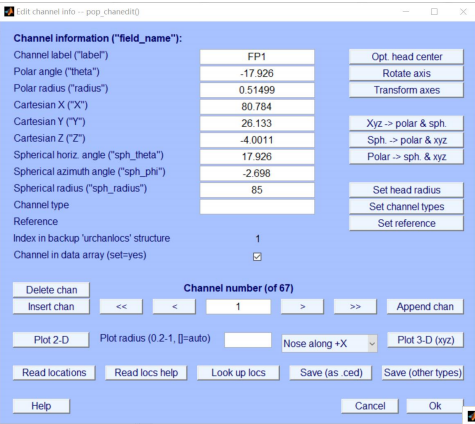
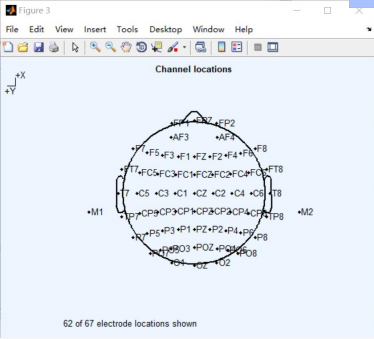
载入失败等异常情况:
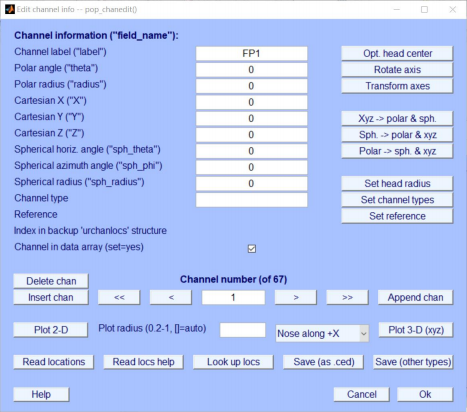
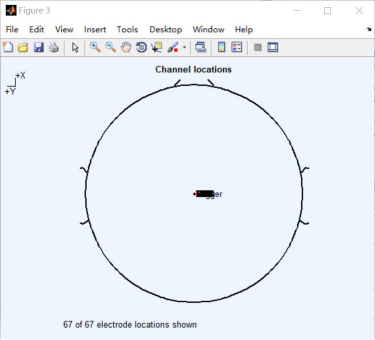
操作流程:
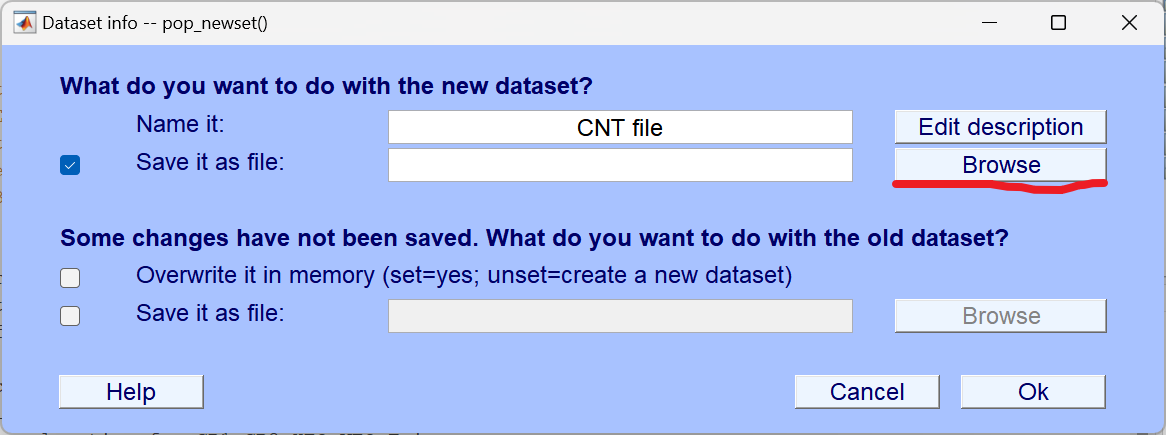
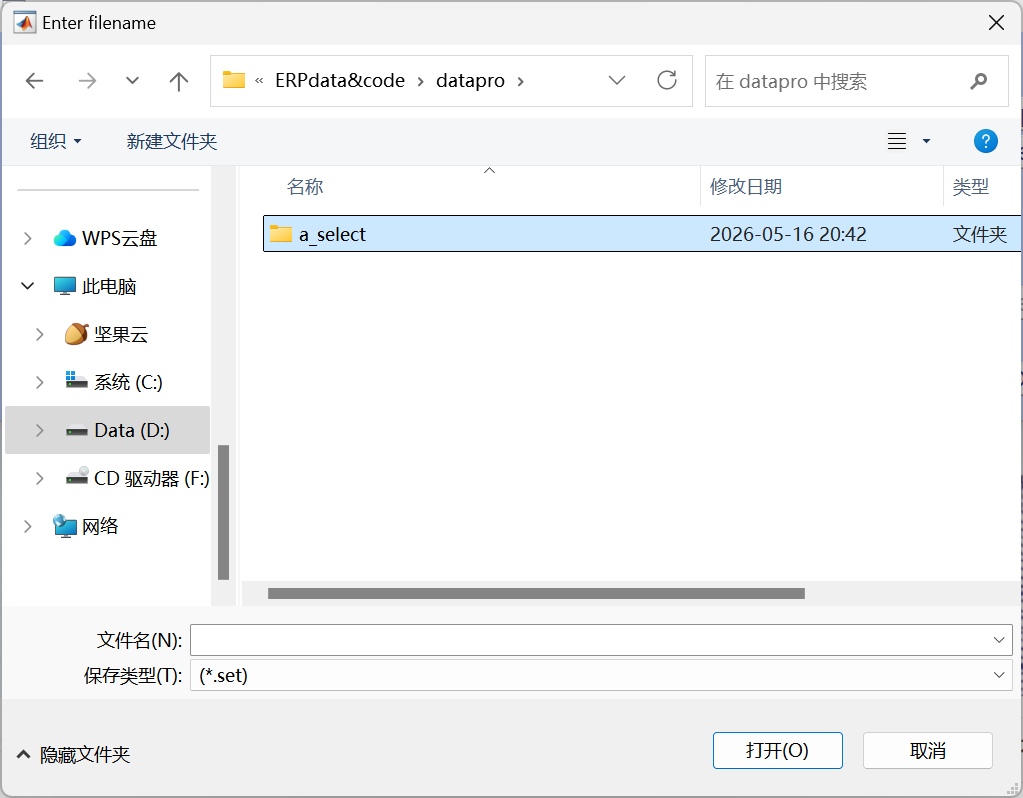
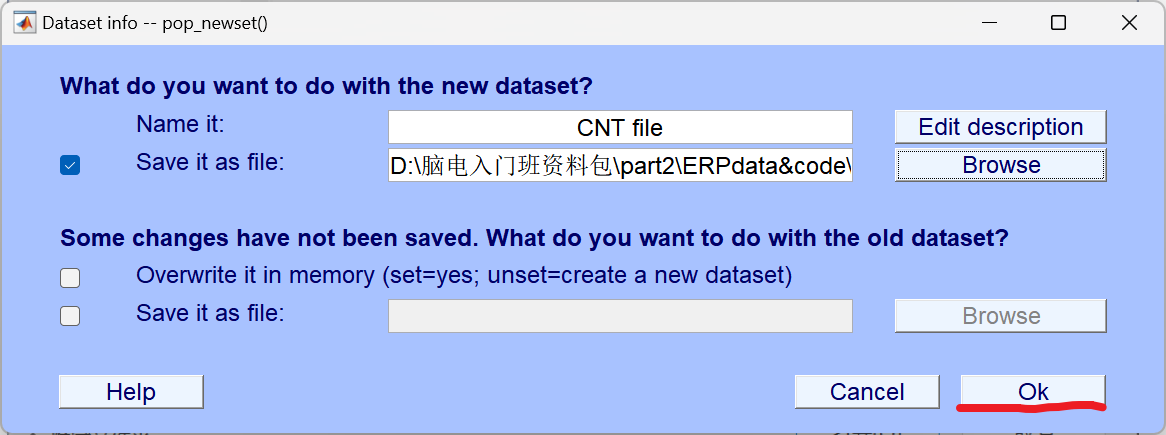
3、 Select data**(数据选择)**
截取或筛选出你需要处理的实验数据片段(比如剔除设备调试、休息时段的数据)。
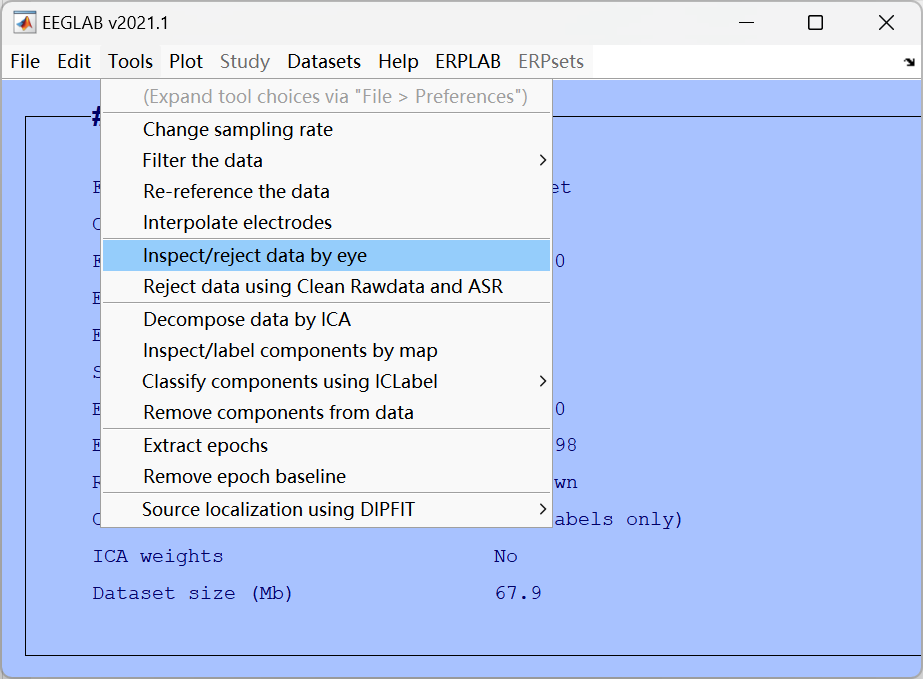
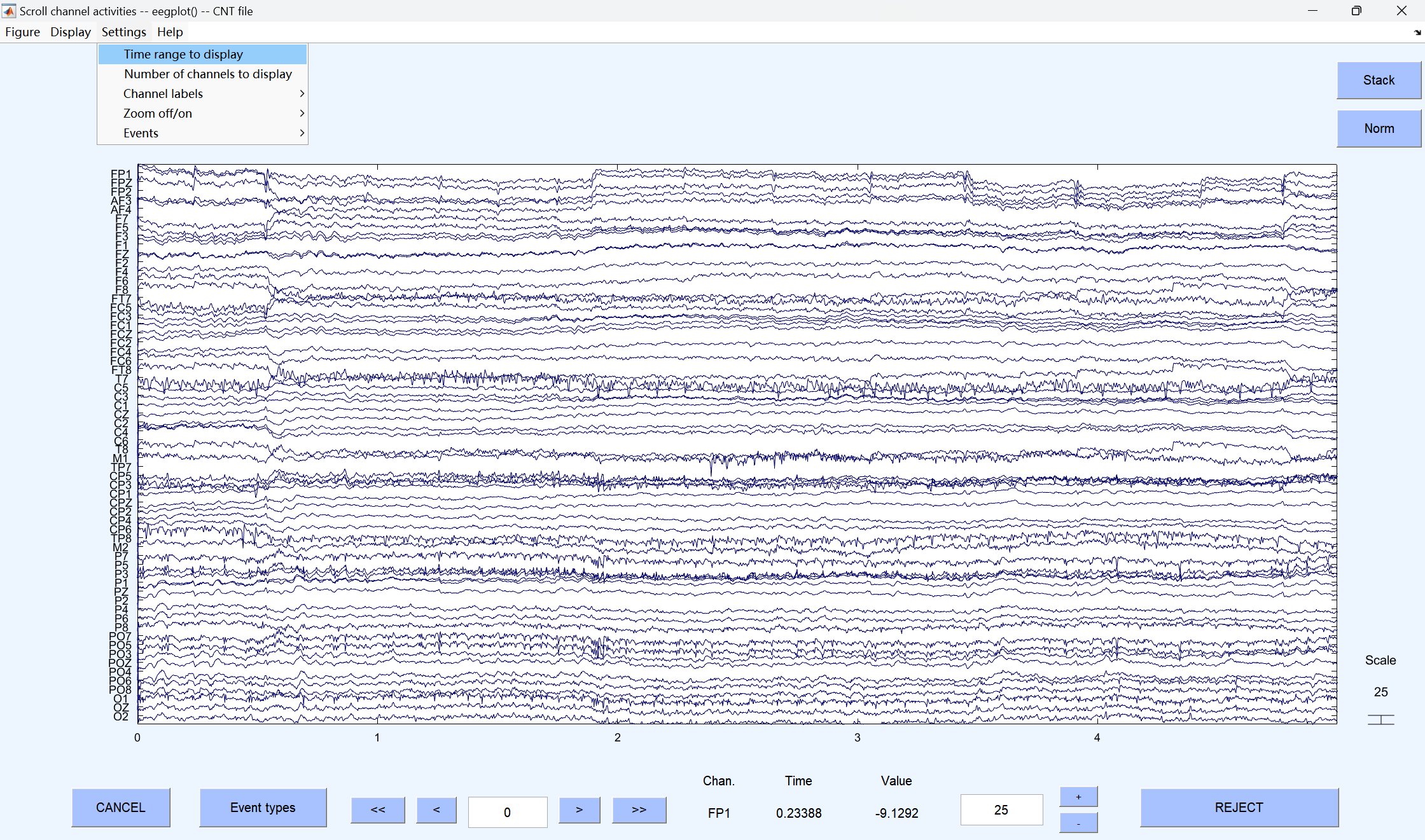
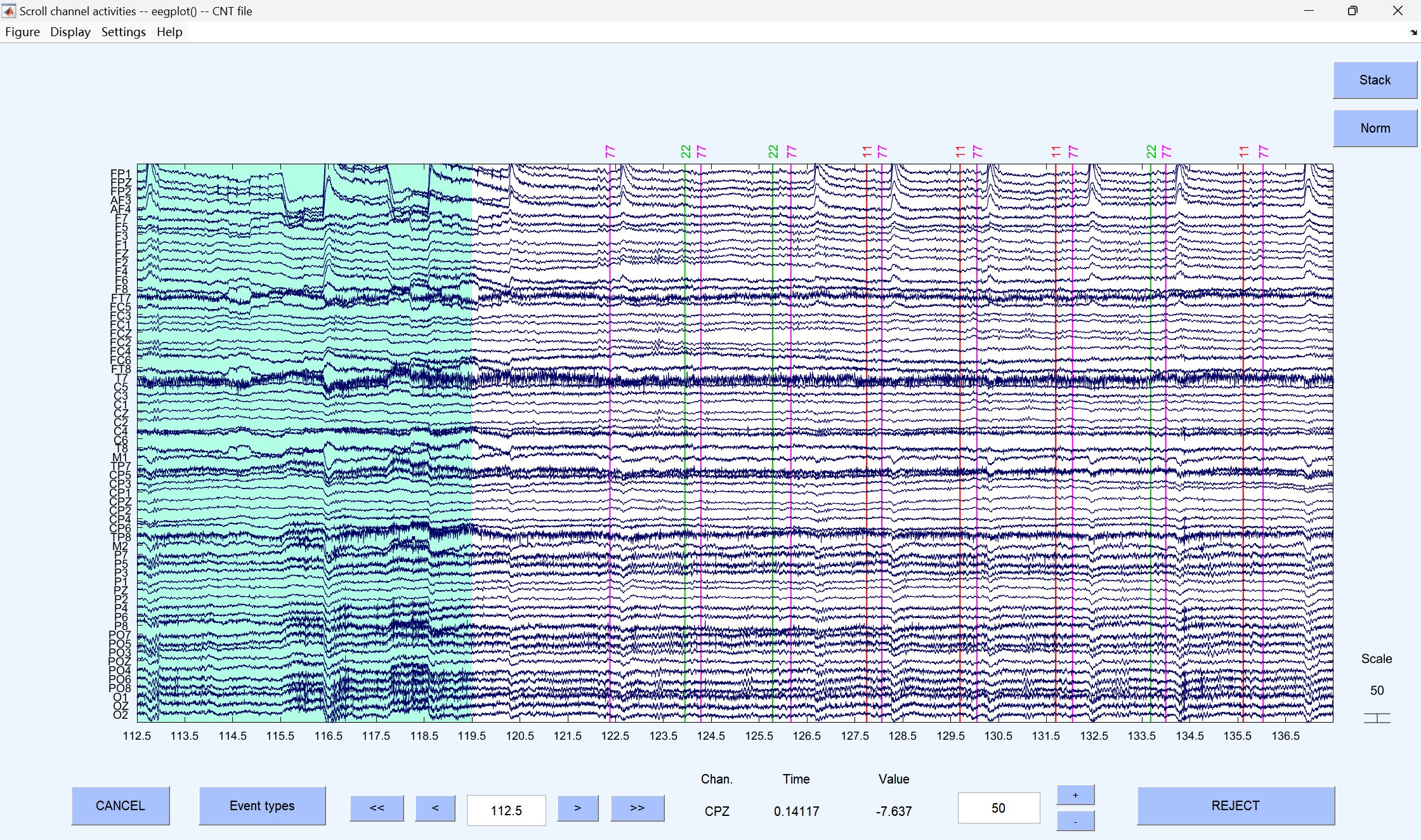
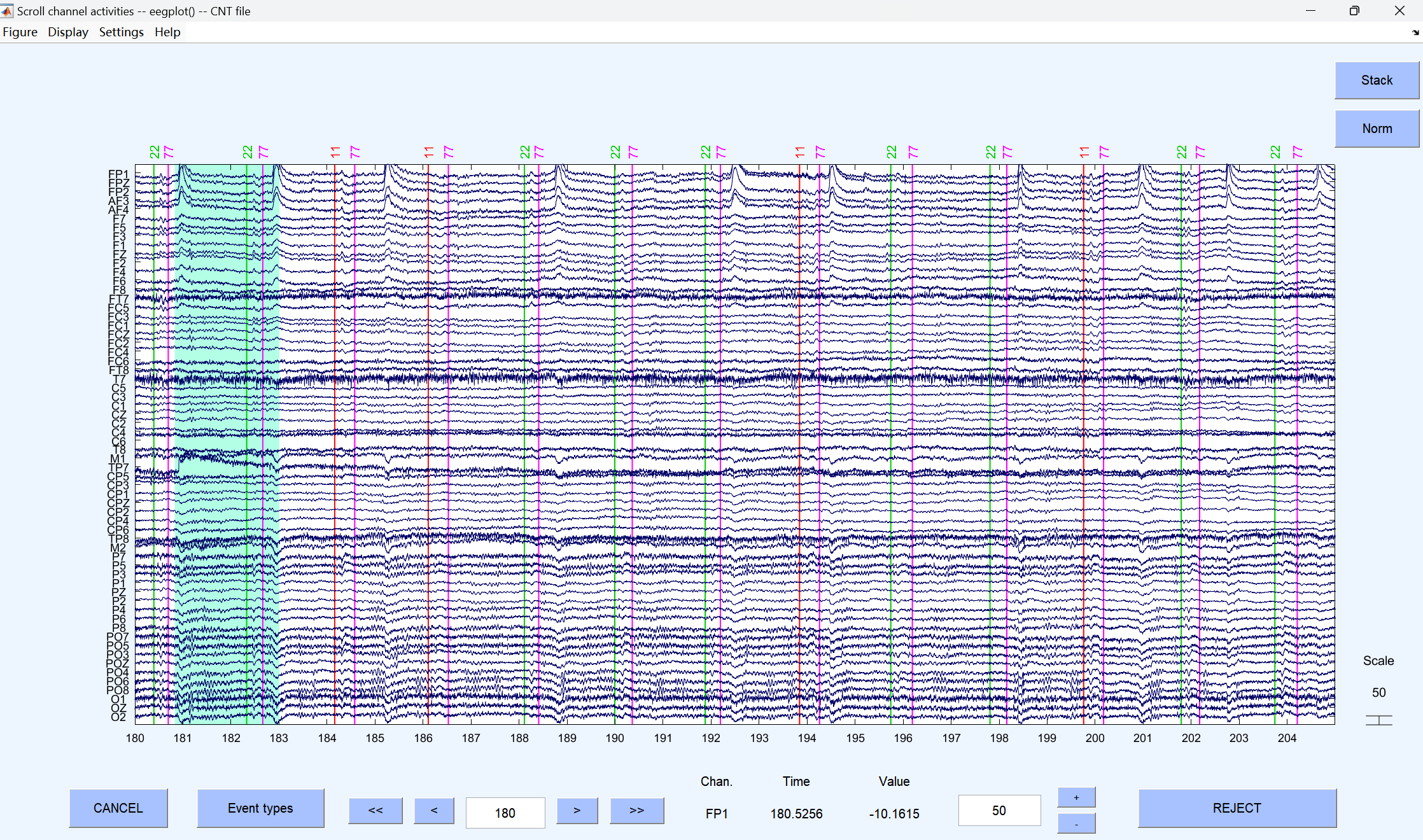
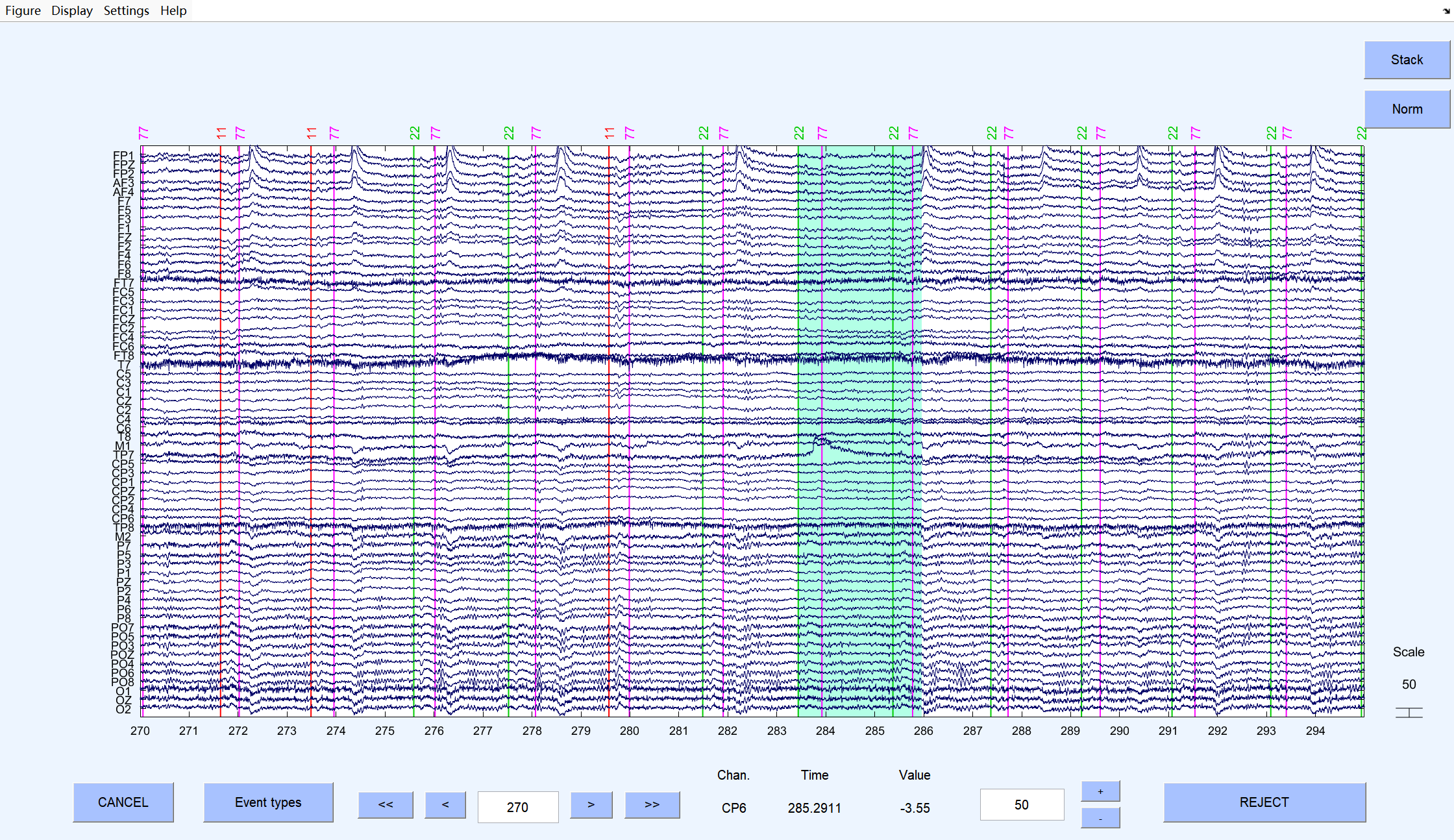
4、 Reject continuous data by eye**(人工目视剔除连续数据中的坏段)**
肉眼检查原始连续数据,手动标记并剔除明显的大幅噪声(如剧烈头动、设备故障导致的伪迹)。同时观察是否有需要插值的坏导,做好数据处理记录
处理流程:
修改时间窗口:
按住鼠标左键一直往右拖到底,然后按右键换一页,一直拖到mark的前几秒(按个人习惯)。
5、 Filter for EEG data**(EEG数据滤波)**
对数据进行带通滤波(通常是高通 + 低通),去除直流漂移、工频噪声(如 50/60Hz 市电干扰)等,是数据预处理的关键步骤。
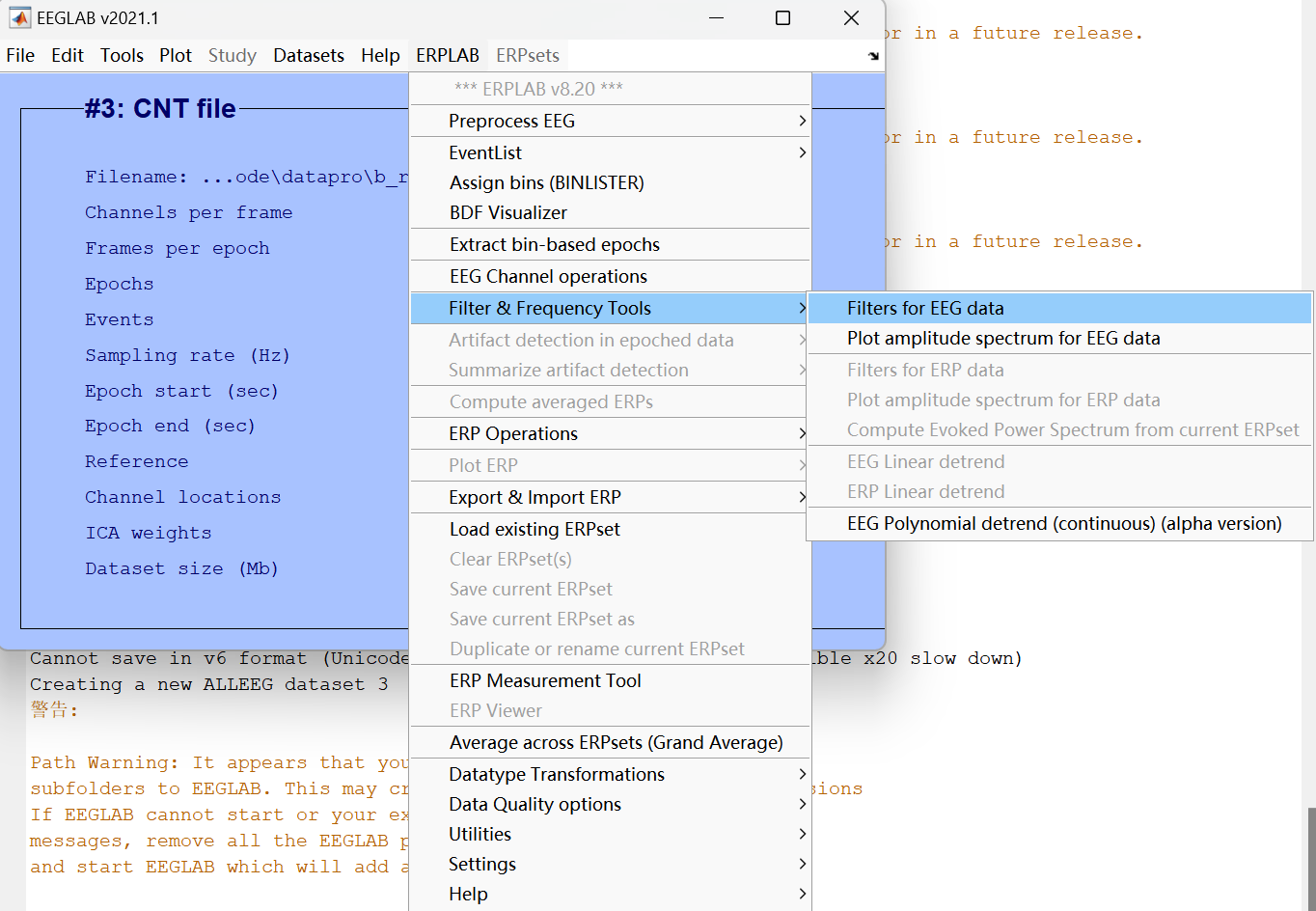
选择无线脉冲滤波。
Order:它是用来控制滤波器 "陡峭程度"的核心参数,这里设置的是 4,也就是4 阶巴特沃斯滤波器。
High-Pass(高通滤波):让高频率的信号通过,把低于某个频率的信号 "挡住"。
Low-Pass(低通滤波):让低频率的信号通过,把高于某个频率的信号 "挡住"。
只让 0.1Hz ~ 30Hz 这个频率范围的脑电信号通过,把不在这个区间的噪声都挡掉,这是 ERP 研究里非常经典的滤波设置。
先不存,还要进行下一步滤波。
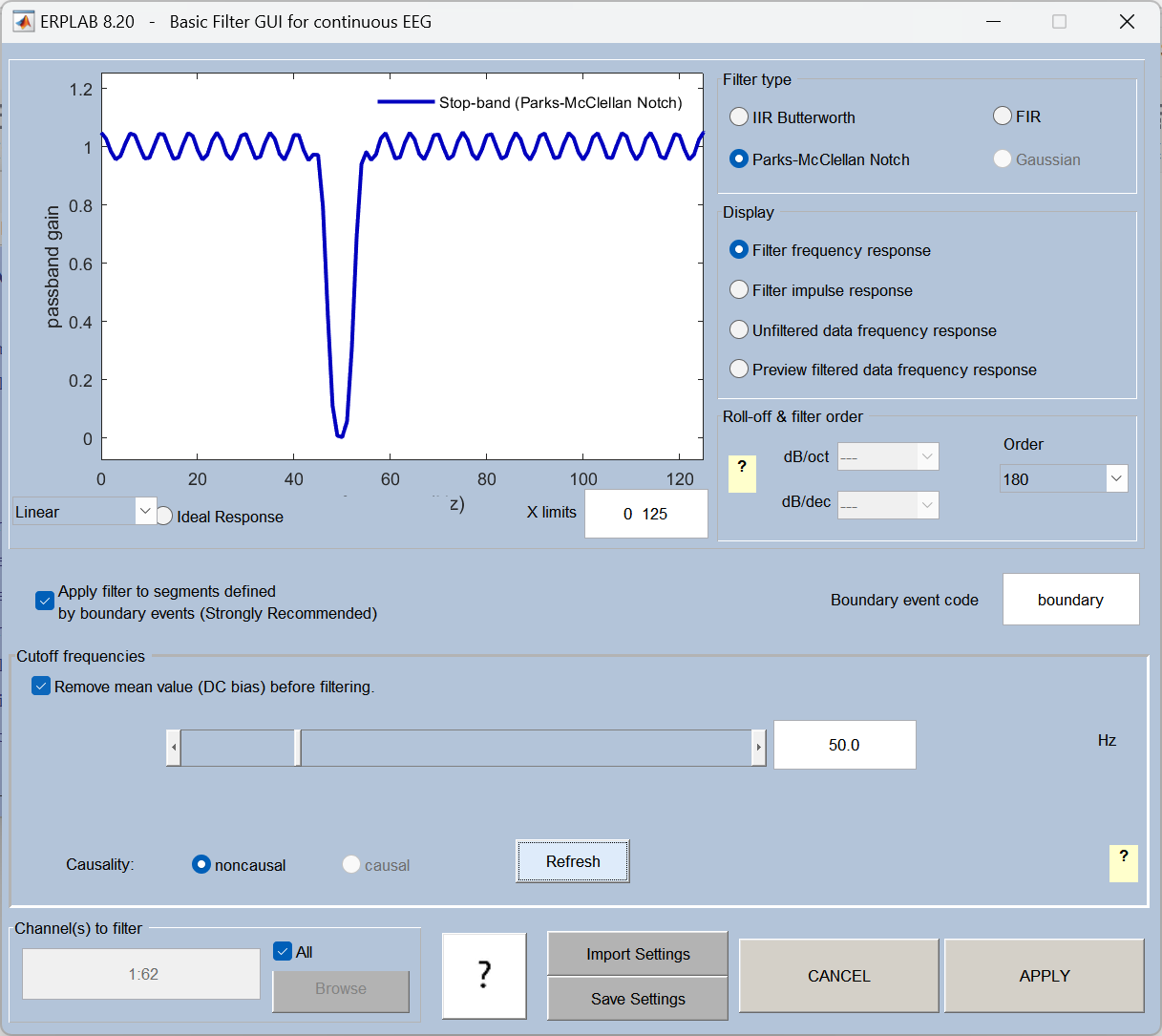
这是在用 Parks-McClellan Notch(陷波滤波器) ,给你的 EEG 数据去除 50Hz 的市电干扰。
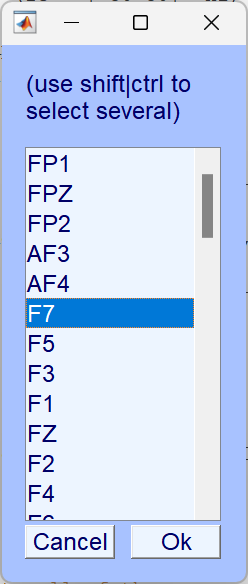
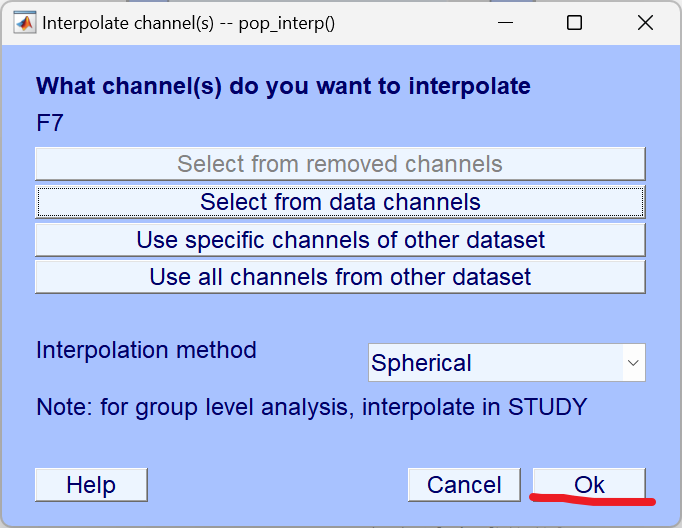
6、Interpolate bad electrodes(坏电极插值)
如果某个电极信号始终异常(如接触不良、噪声过大),用周围正常电极的数据估算并替换该通道的数据。
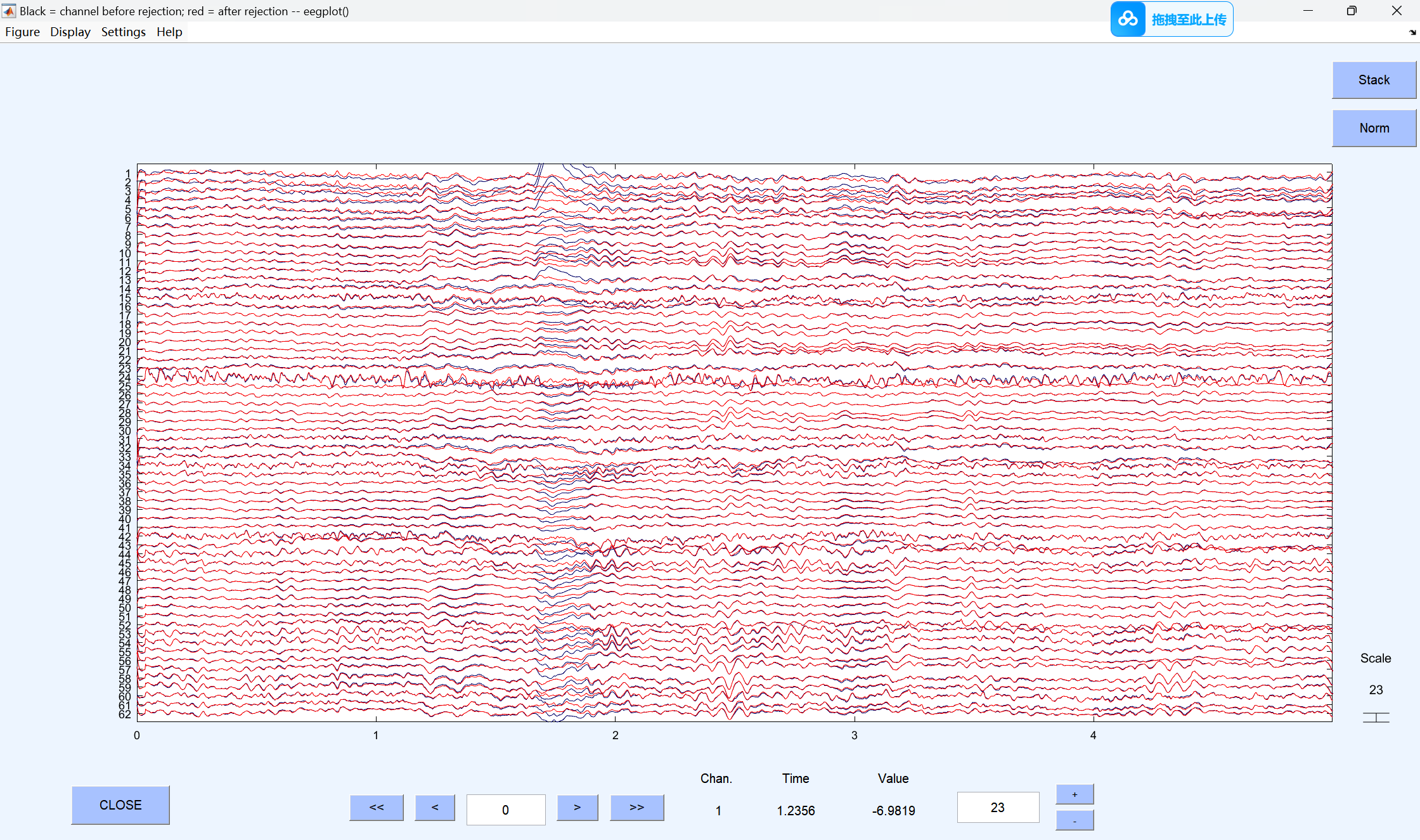
7、Run ICA and remove components(运行独立成分分析(ICA)并去除伪迹成分)
ICA 是去除眼电(眨眼、眼球转动)、肌电(咬牙、头动)等生理伪迹的核心方法,通过分解数据并剔除伪迹对应的独立成分来净化信号。

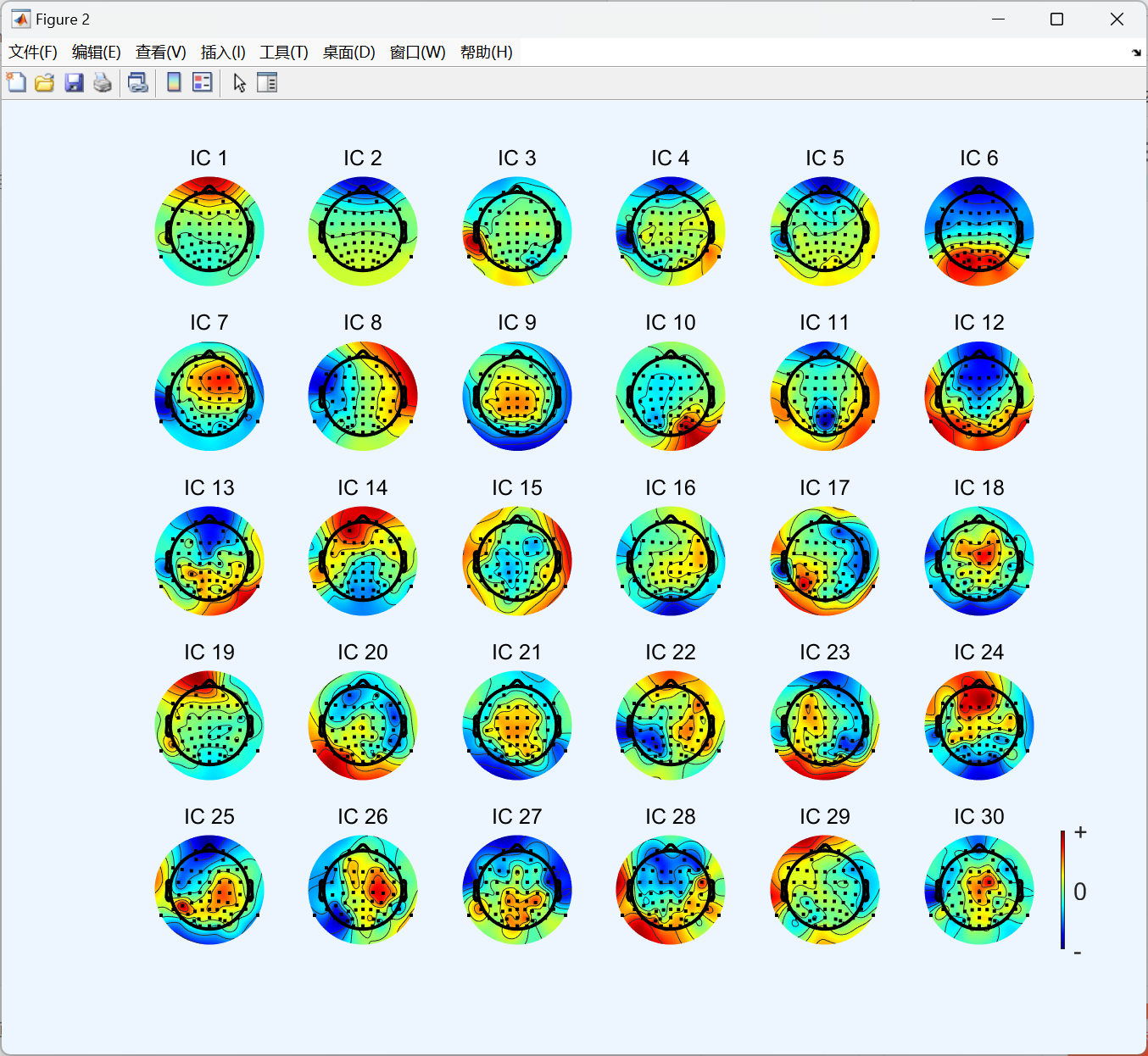
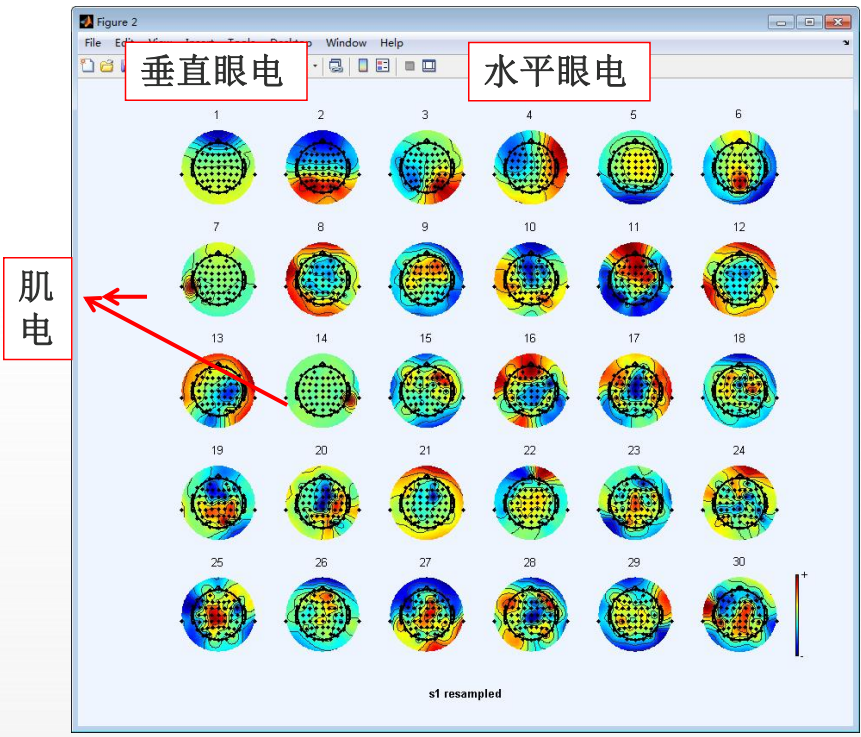
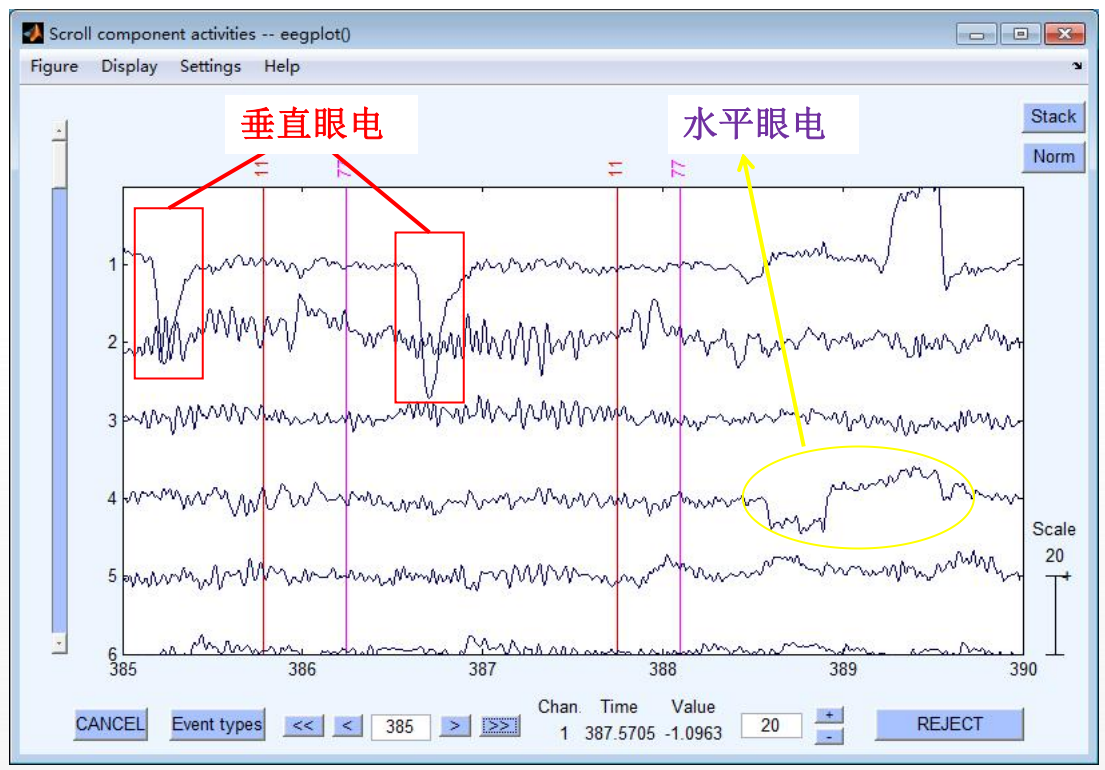
很明显,成分2就是一个垂直眼电(但它似乎反了)。



一号明显是垂直眼电:

八号很明显是水平眼电:

所以现在我们将它们移除:

黑色是去眼电前的波形图,红色是去眼电后的:

8、Re-reference(重参考)
将数据从原始参考电极转换为新的参考(如平均参考、乳突参考等),是 EEG 处理的标准步骤之一。
一、核心思想
重参考的本质是更换脑电信号的 "零电位基准" 。脑电信号记录的是「电极电位 - 参考电极电位」的差值,原始参考电极(如单侧乳突、鼻尖)存在噪声 或偏差 ,会扭曲信号 。重参考通过选择更合理的基准(如全通道平均参考),消除参考偏差,还原脑电信号的真实分布与差异。
二、关键概念与简要解释
| 关键概念 | 简要解释 |
|---|---|
| 参考电极(Reference Electrode) | 脑电信号的 "零电位基准",所有电极的信号都是相对于它的电位差。 |
| 原始参考(Raw Reference) | 设备采集时默认使用的参考电极,通常是单侧乳突、鼻尖或头顶,存在噪声 / 偏差。 |
| 平均参考(Average Reference) | 最常用的重参考方法:将所有脑电电极的信号取平均值,作为新的零电位基准,再用每个电极信号减去该平均值。 |
| 重参考偏差(Reference Bias) | 原始参考电极本身的噪声、不对称性导致的信号整体偏移或左右半球电位失衡。 |



以下是操作流程:
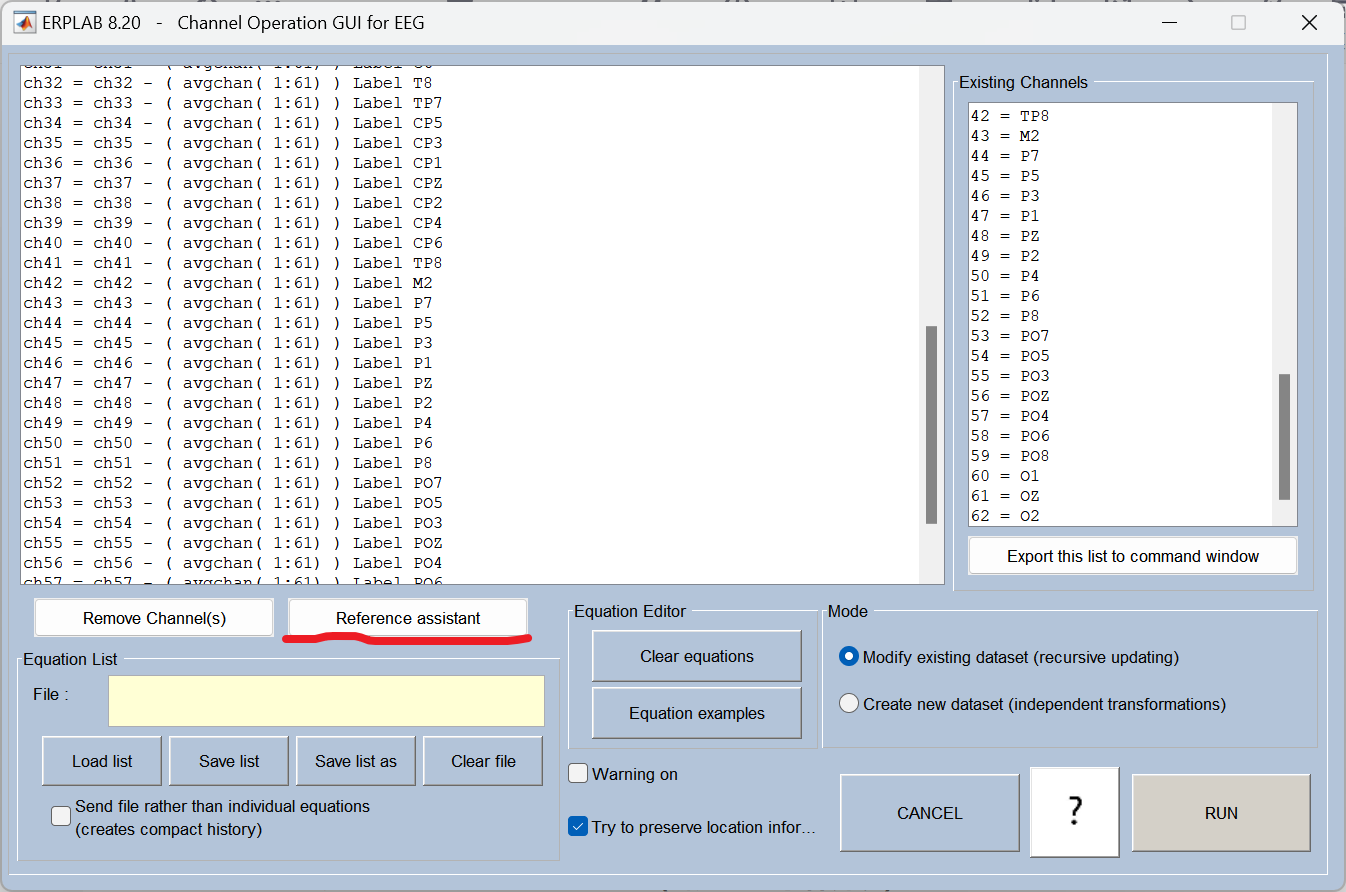
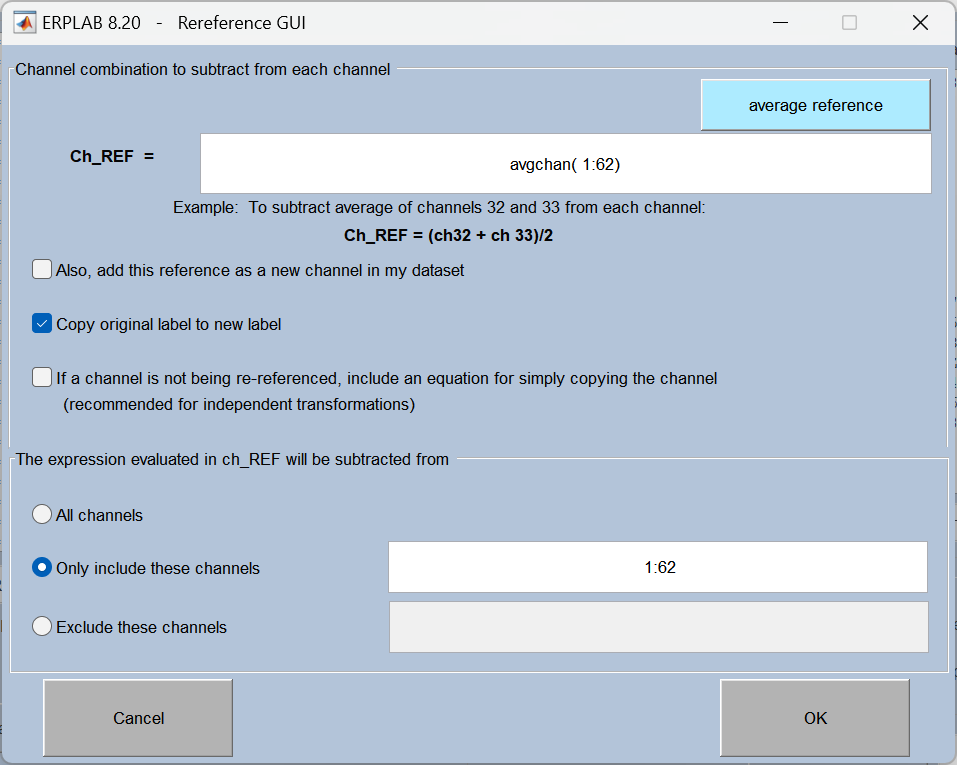
数据需要我们手动保存。
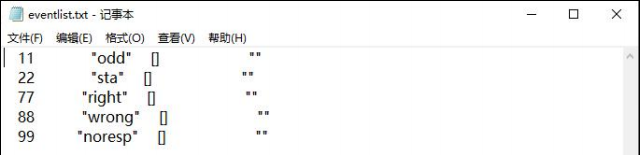
9、Create EEG EVENTLIST(创建EEG事件列表)
提取实验中的刺激标记(trigger/event),生成事件时间戳列表,用于后续按刺激分段(epoch)。
举例:
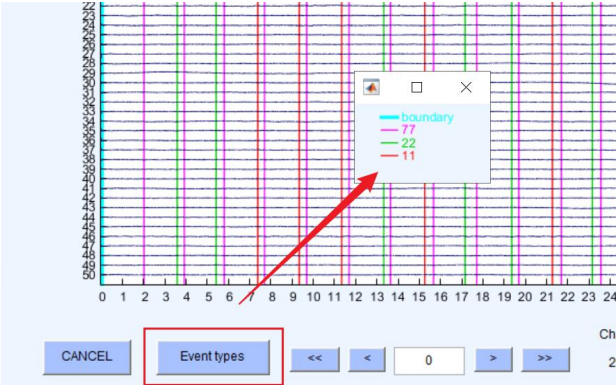
Tip:相比于eventtype中的mark可以多但是不能少
操作流程:
如何看我们的数据有多少marker?
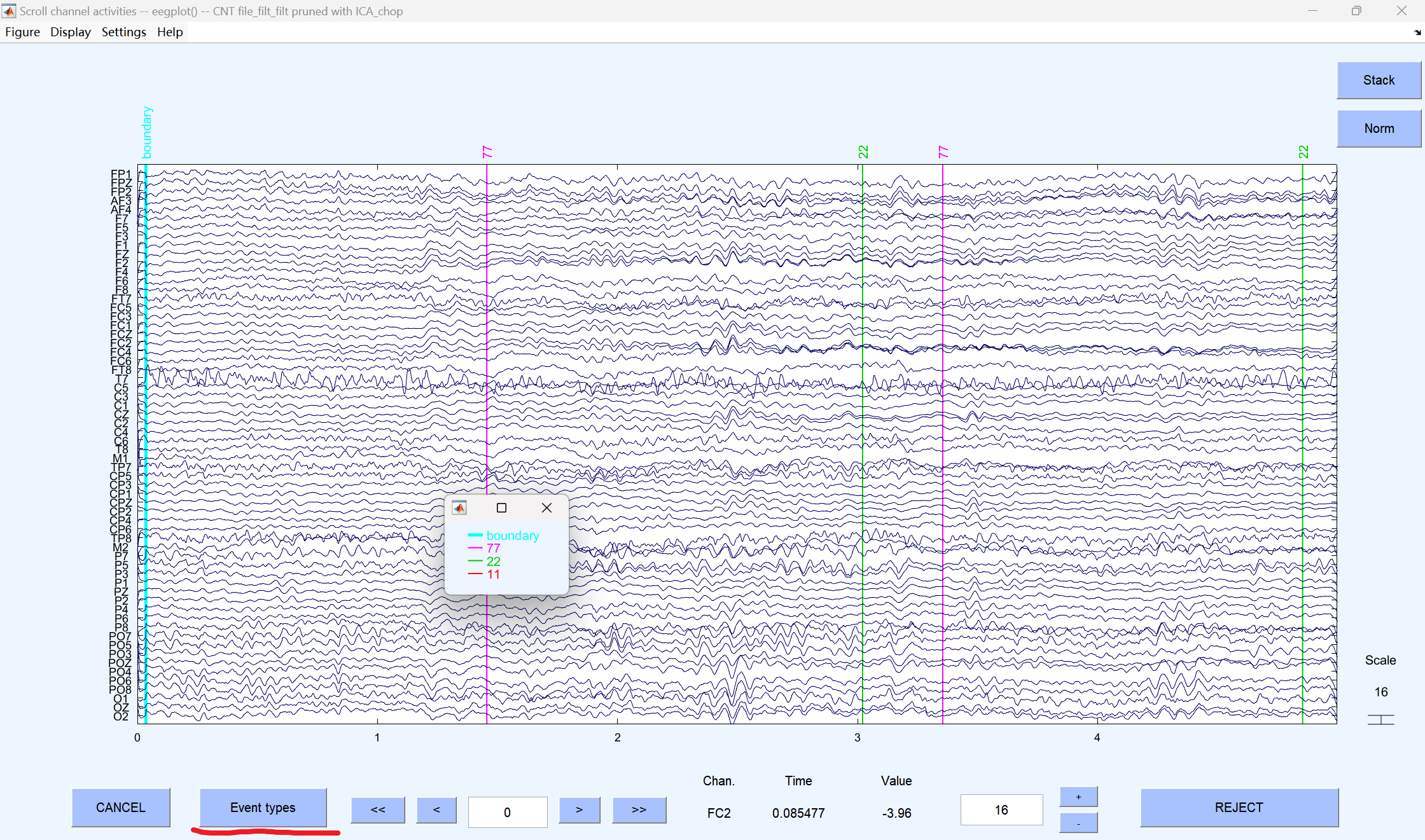
11、22、77:实验刺激材料。
boundary:自动生成,剪掉坏段之后,他会自动把前后数据拼接到一起。
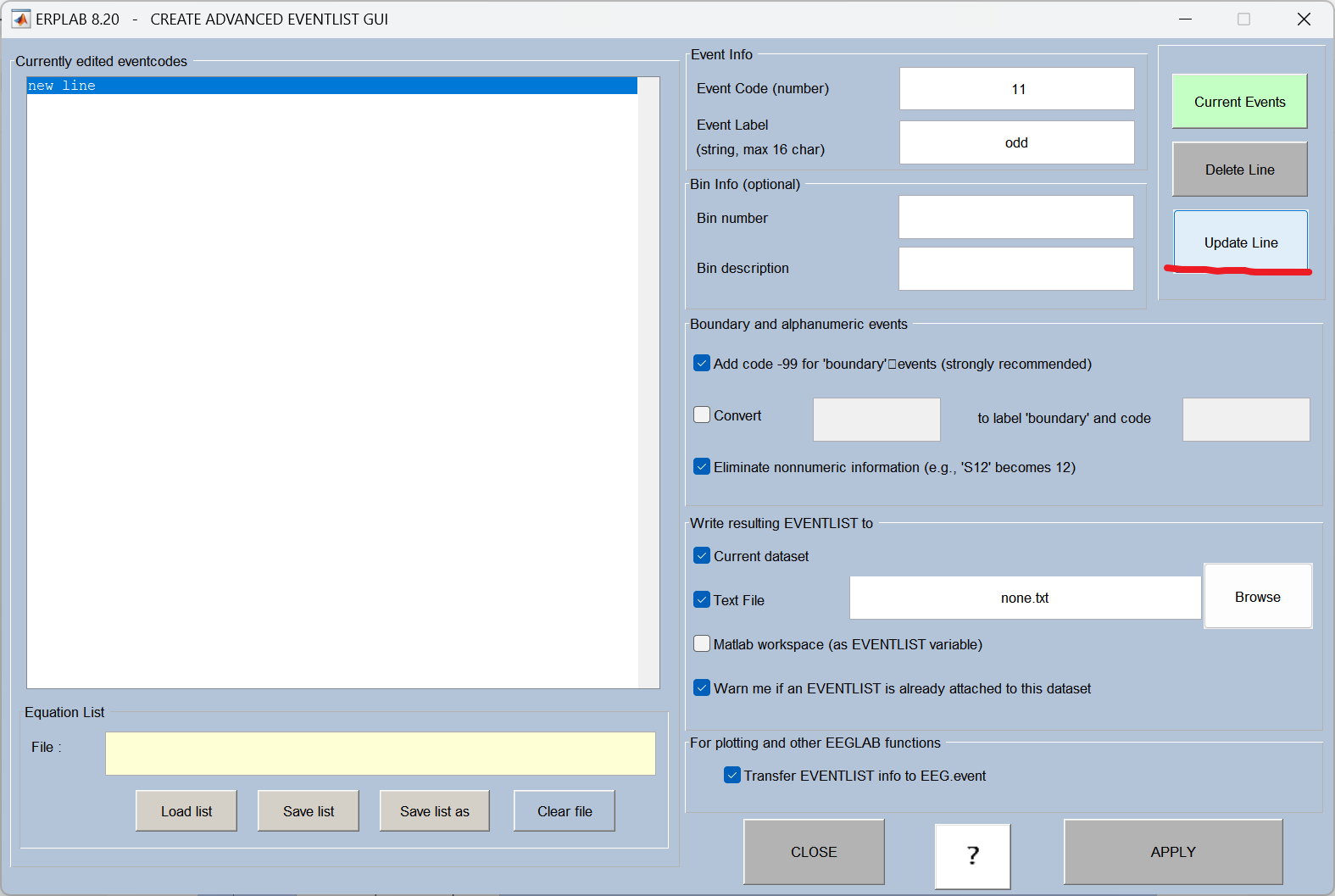
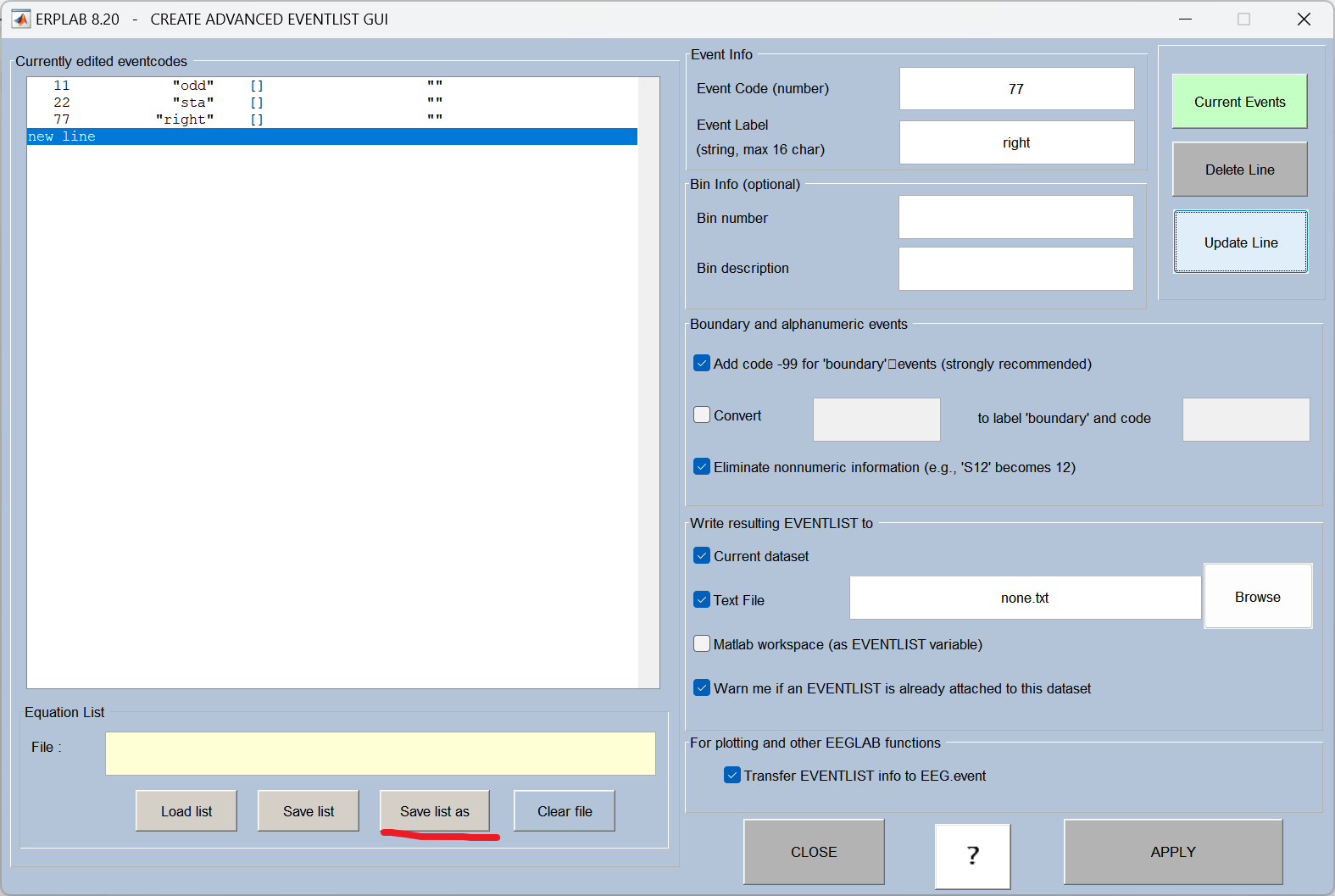
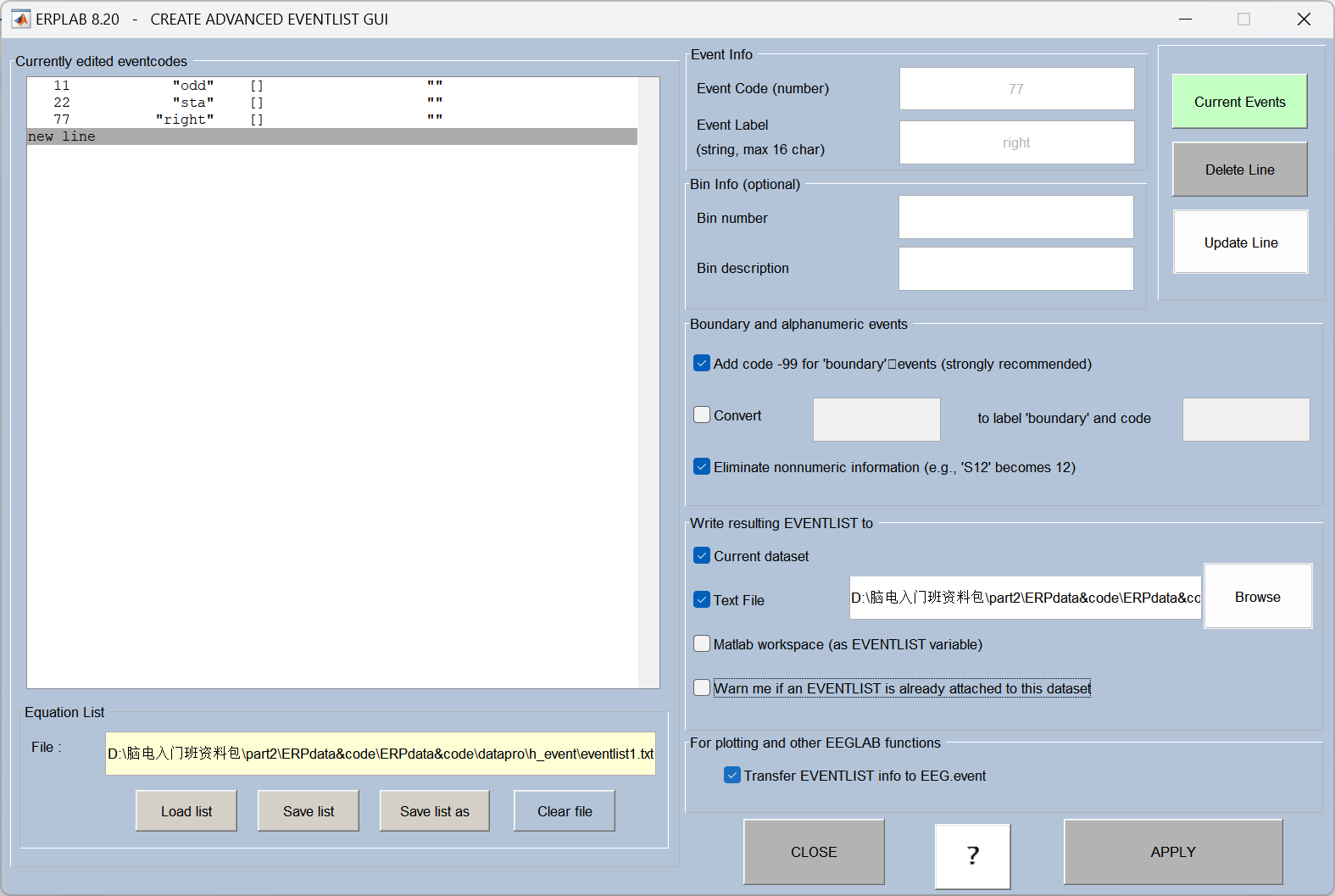
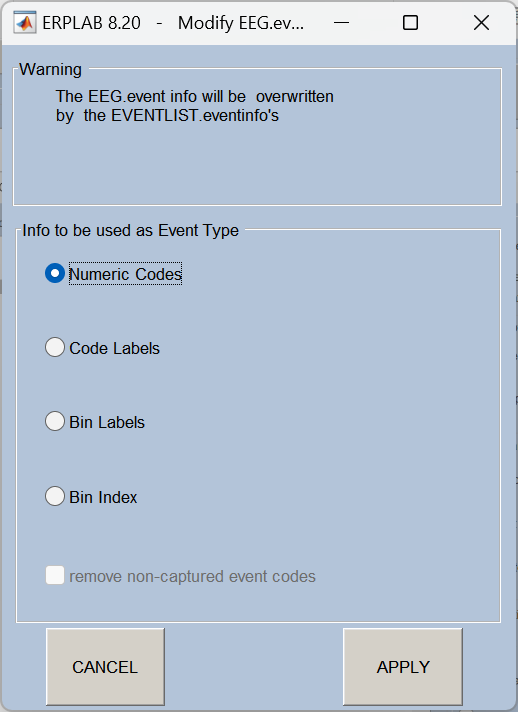
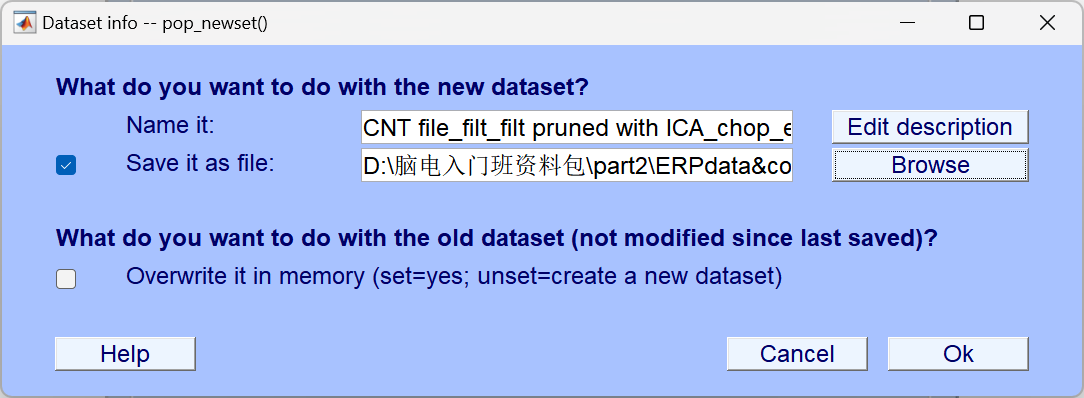
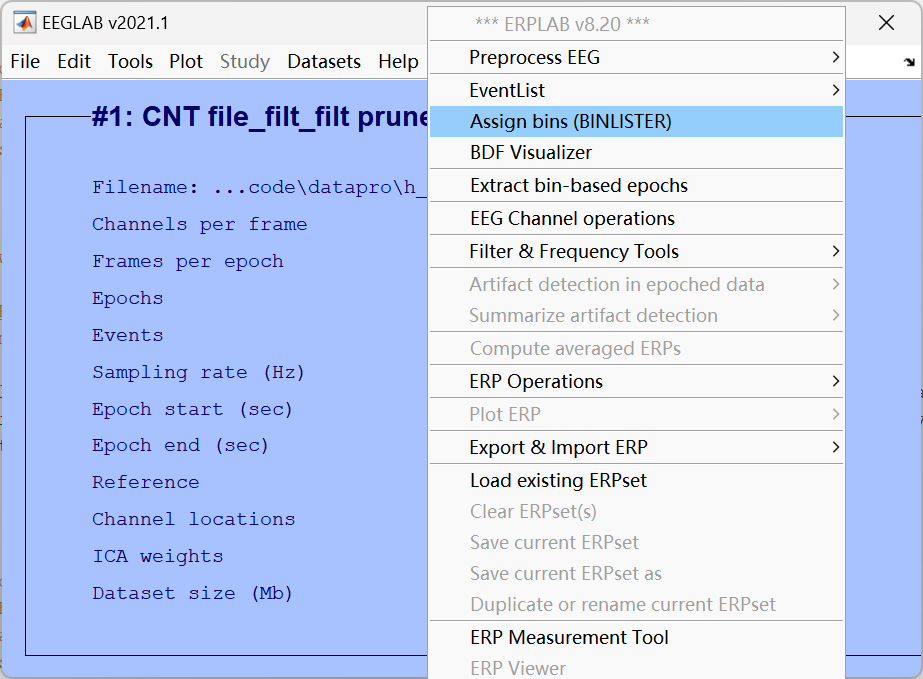
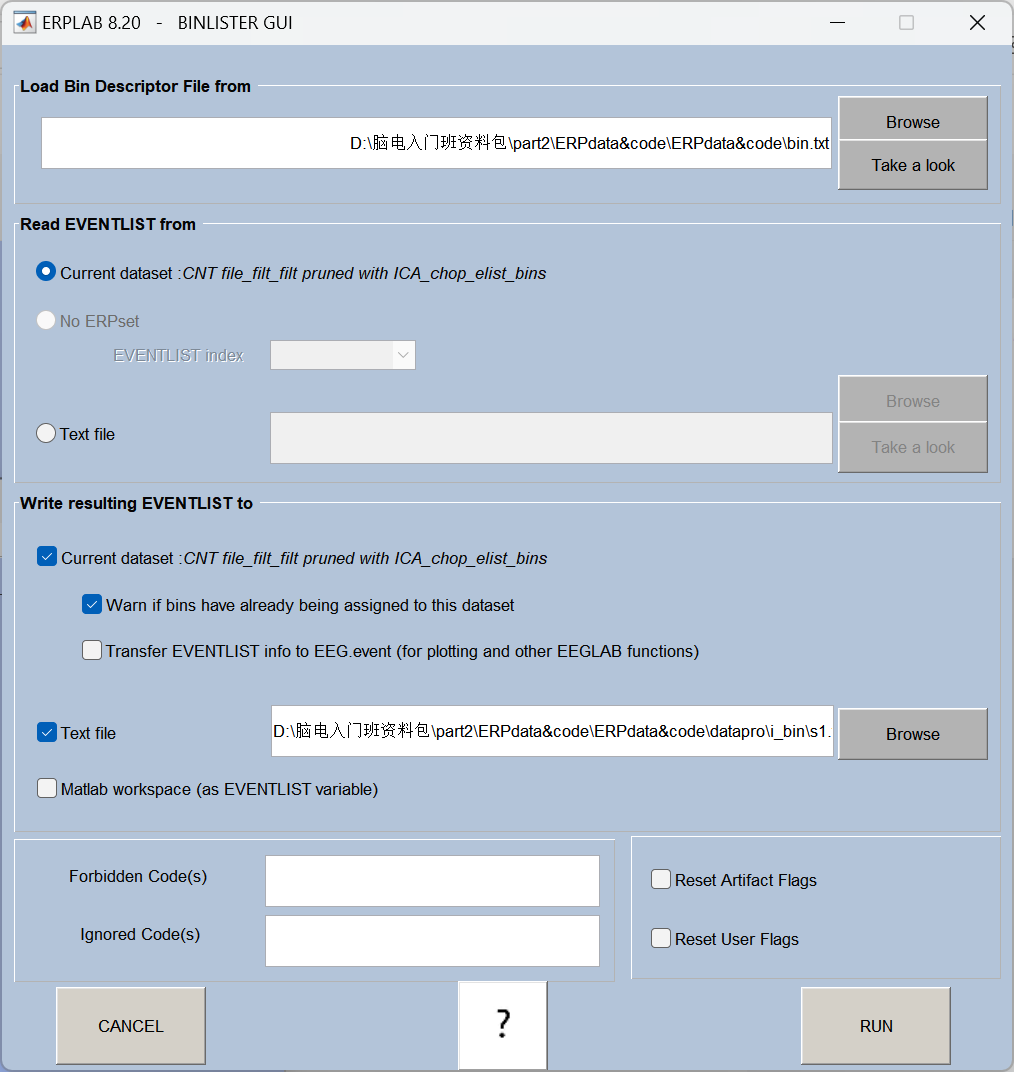
10、Assign bins (分配数据分组,使用BINLISTER工具)
根据事件类型给不同的刺激条件分组 (比如按 "目标刺激 / 非目标刺激" 分类),BINLISTER 是 EEGLAB 中用于设置条件分组的常用工具。

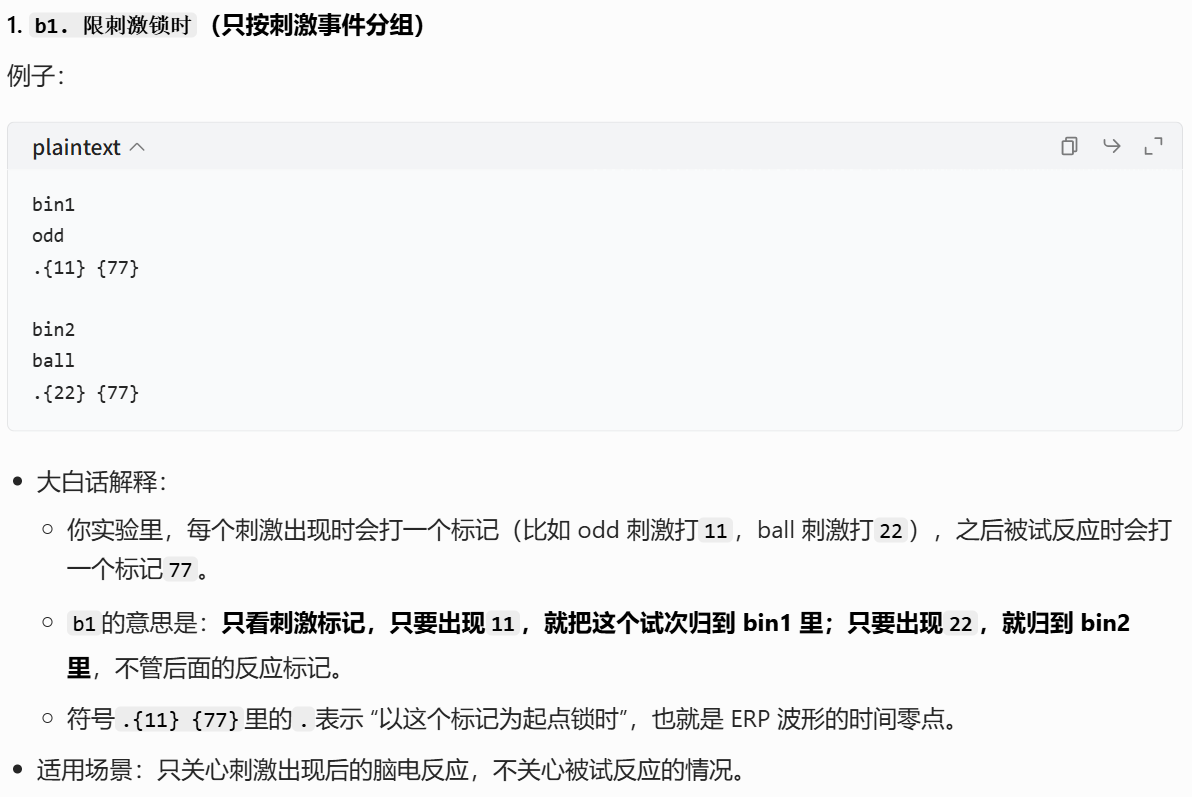
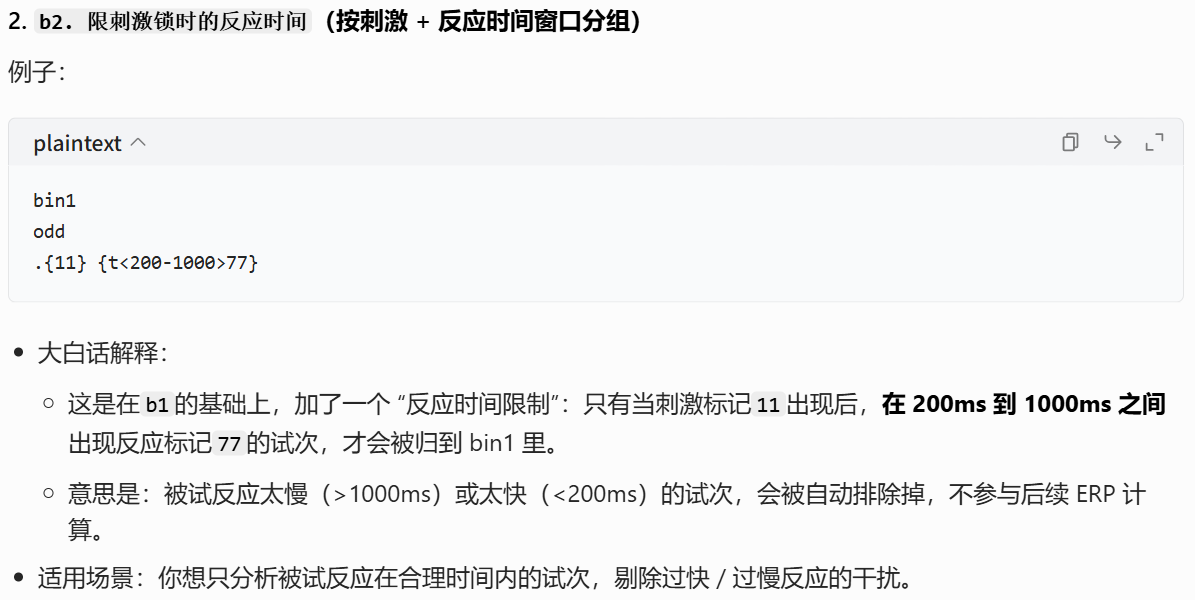


操作流程:
11、Epochs and Baseline correction(分段与基线校正)
按刺激事件将连续数据切分为短片段(epoch,如刺激前 200ms 到刺激后 800ms),并以刺激前的基线时段校正数据,消除整体漂移。
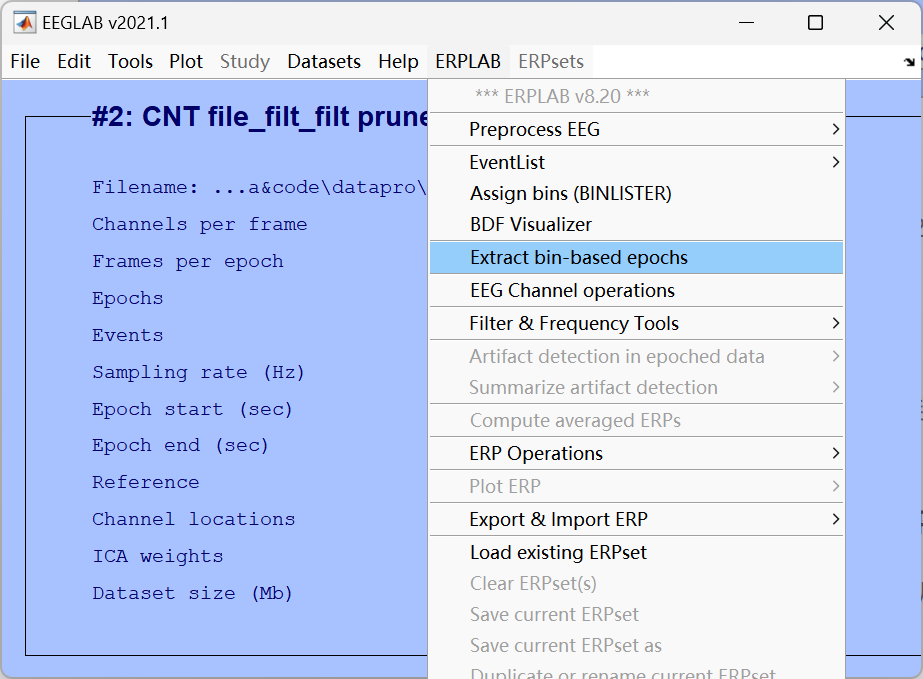
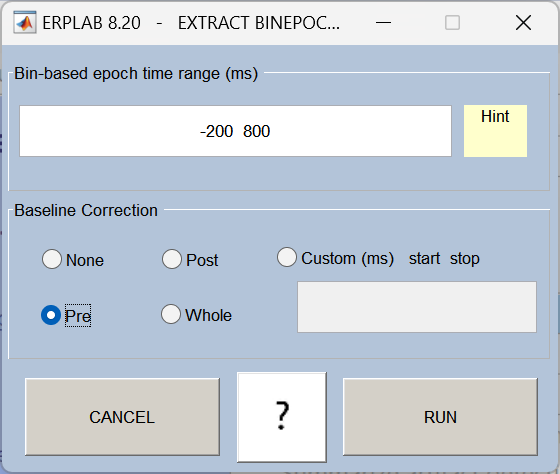
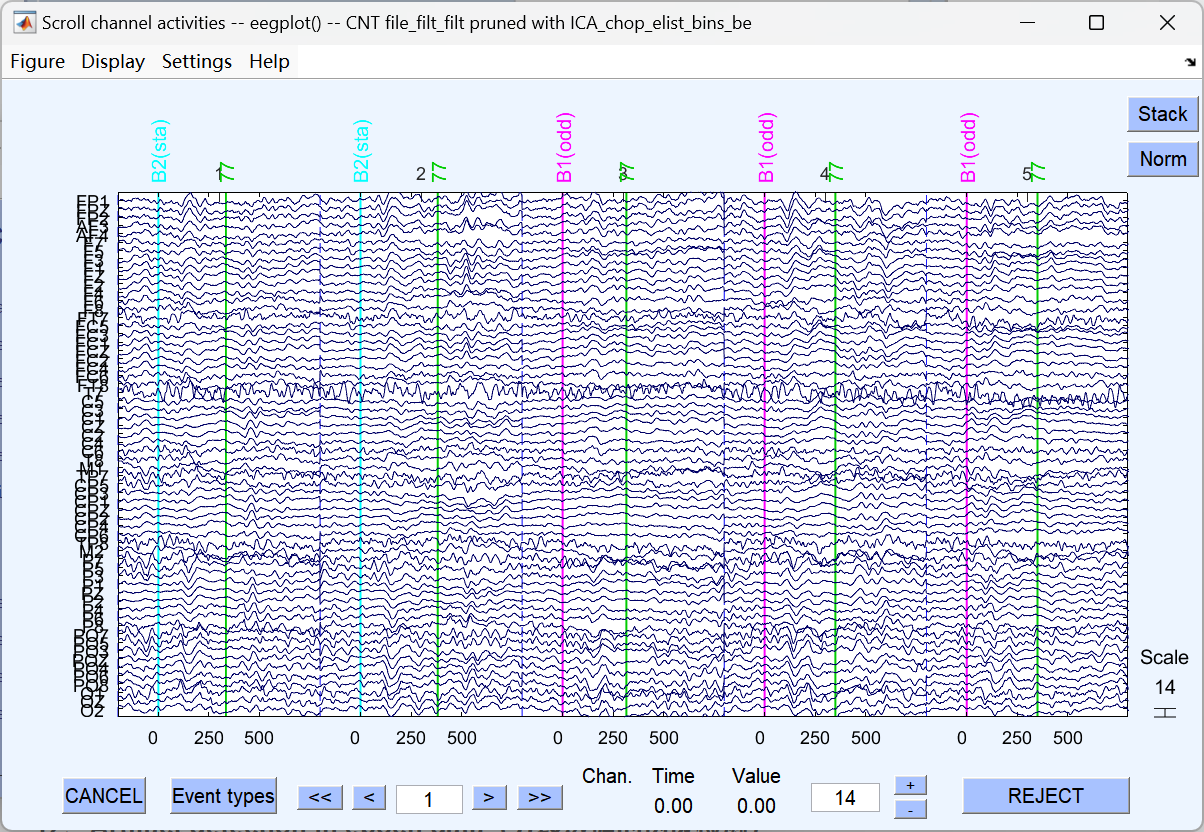
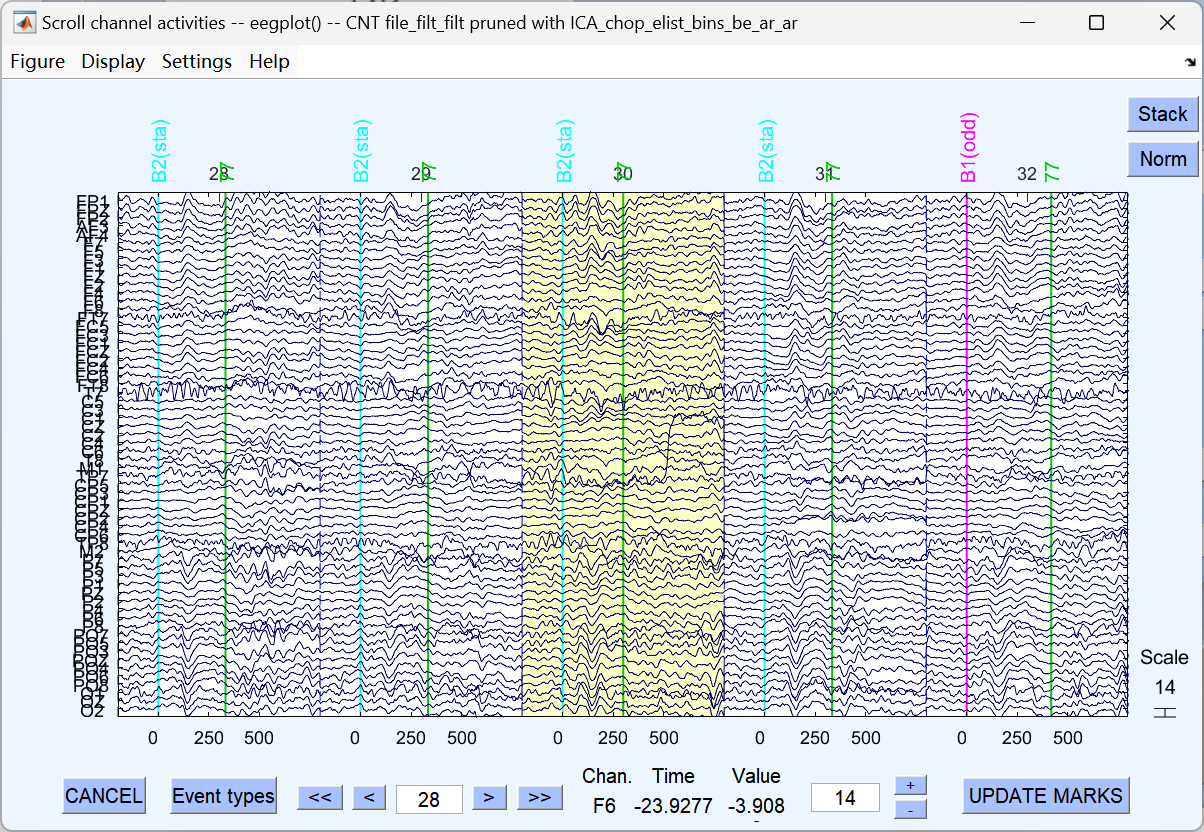
12、Artifact detection in epoch data(分段数据的伪迹检测)
自动或手动检查切分后的 epoch,剔除仍有残留伪迹(如超出阈值的大幅波动)的片段。
滑动窗口去伪迹:
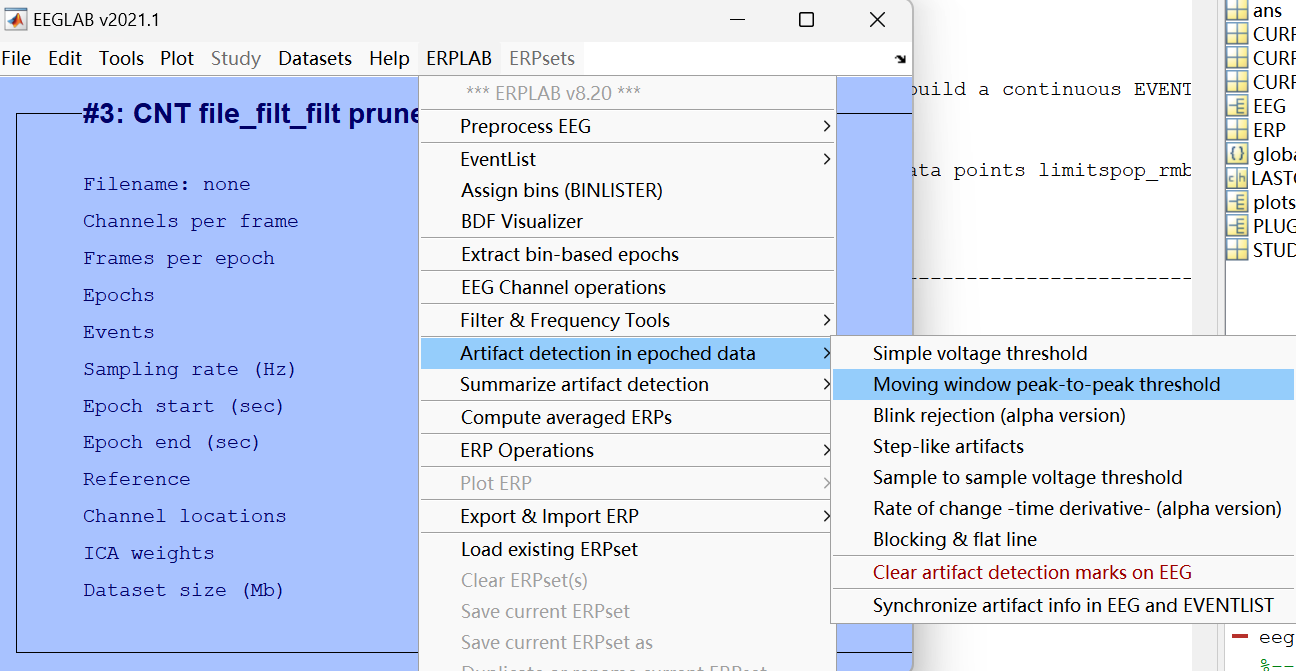
这是 ERPLAB 里 **「滑动窗口峰 - 峰值伪迹检测」** 的设置界面:
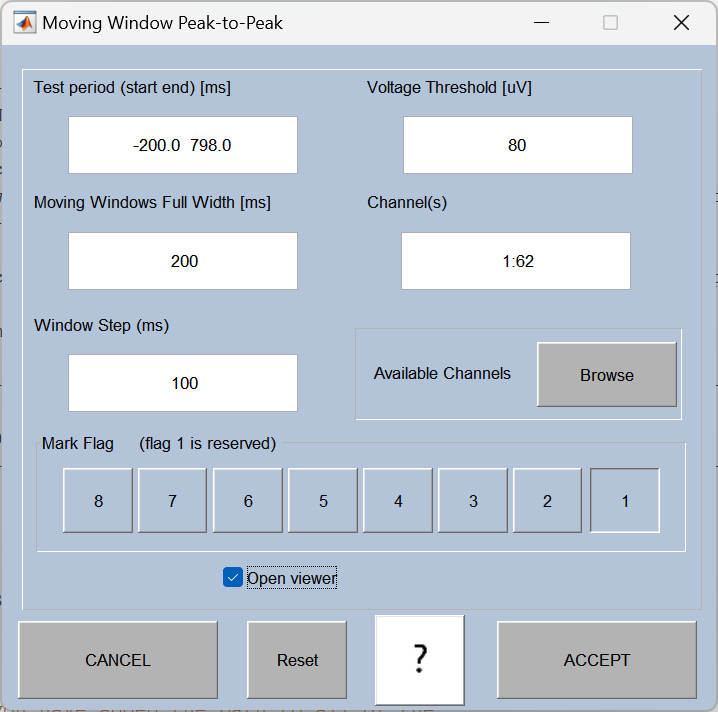
它的核心作用是:**自动检查你切好的每一段脑电数据(epoch),如果信号波动太大(比如眨眼、咬牙导致的大幅跳变),就把这个试次标记为 "坏试次",后续计算 ERP 时会自动排除掉。**简单说就是:帮你自动 "筛掉脏数据",不用你肉眼一个个挑。

写798是为了避开数据的边界,让软件能稳定地读完所有有效数据,不会因为读不到最后一个点而出错,而且对分析结果没有任何影响。


绝对值去伪迹:
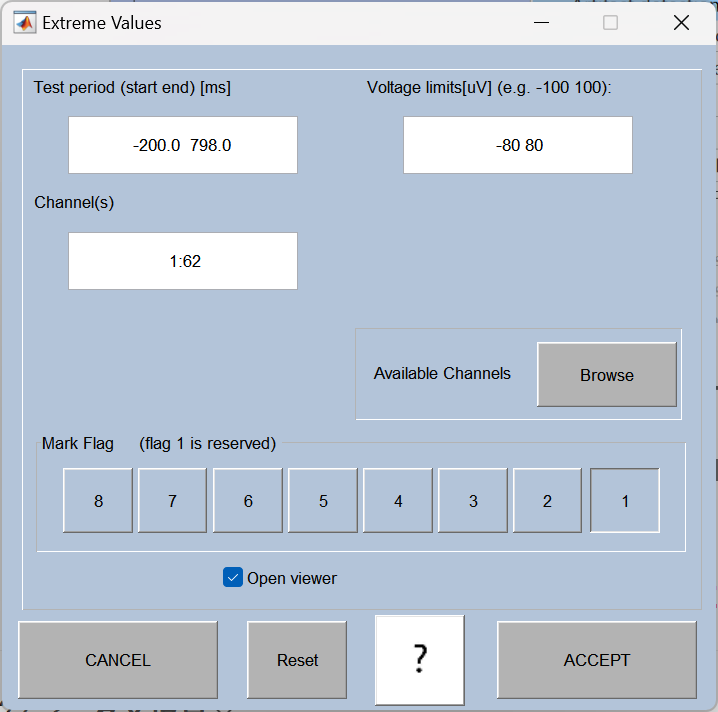
13、Compute averaged ERPs(计算事件相关电位(ERP)平均波形)
将同一条件下的所有有效 epoch 数据取平均,得到 ERP 波形,这是 ERP 研究的最终处理结果。
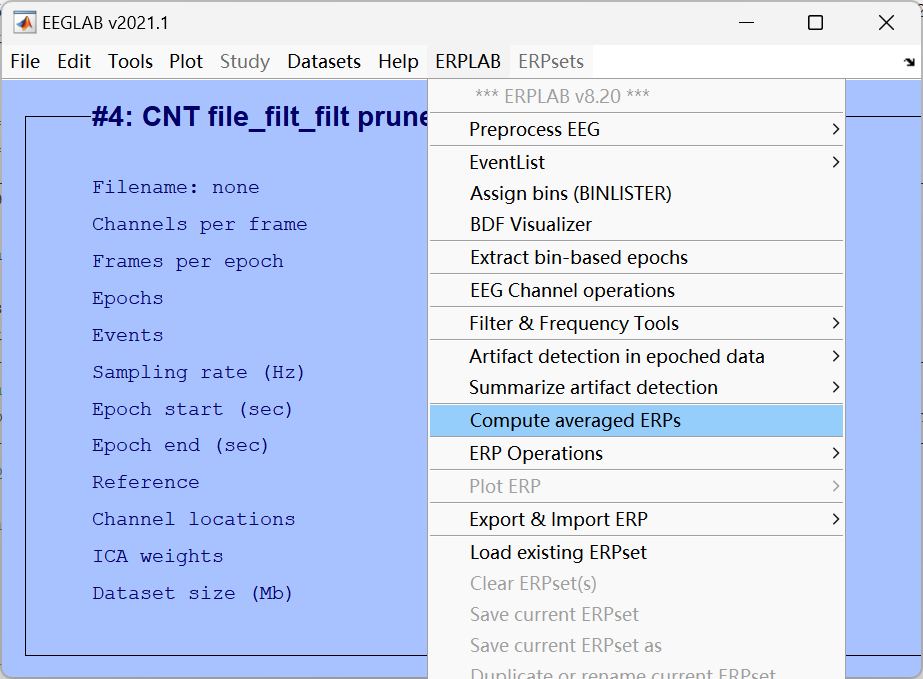
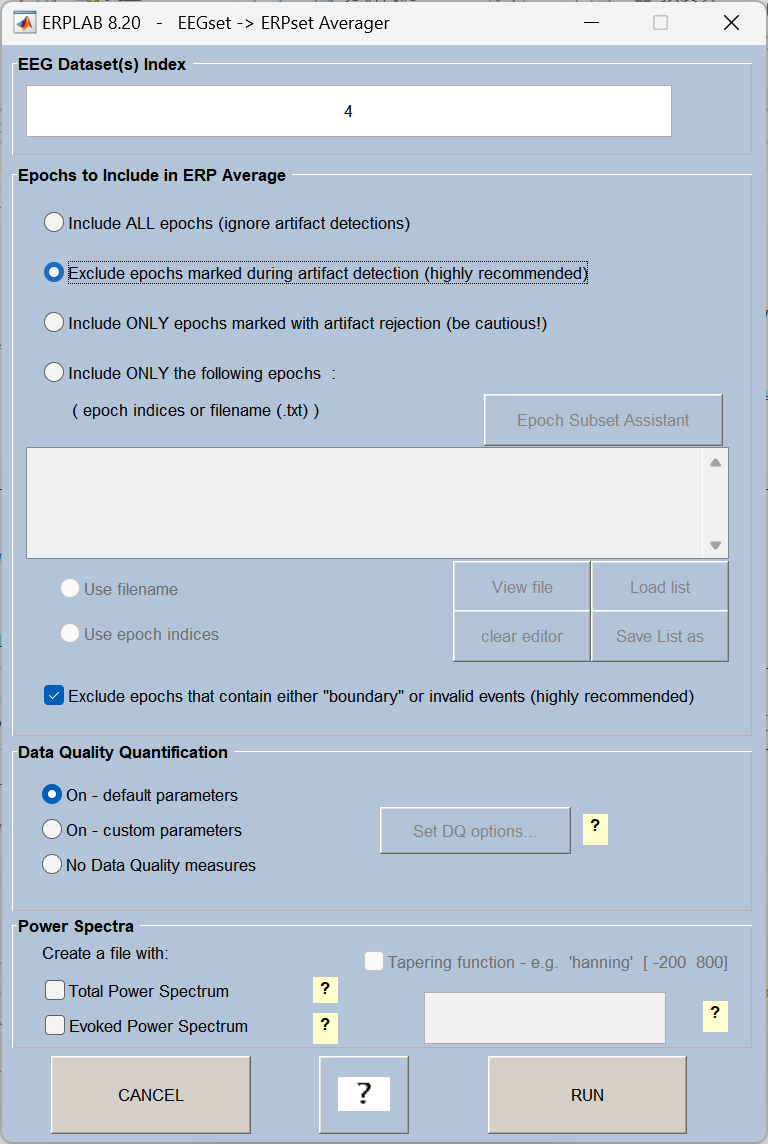
Tip:预处理流程的5、8、9、10、11、12、13步都是在ERPLAB中完成的。
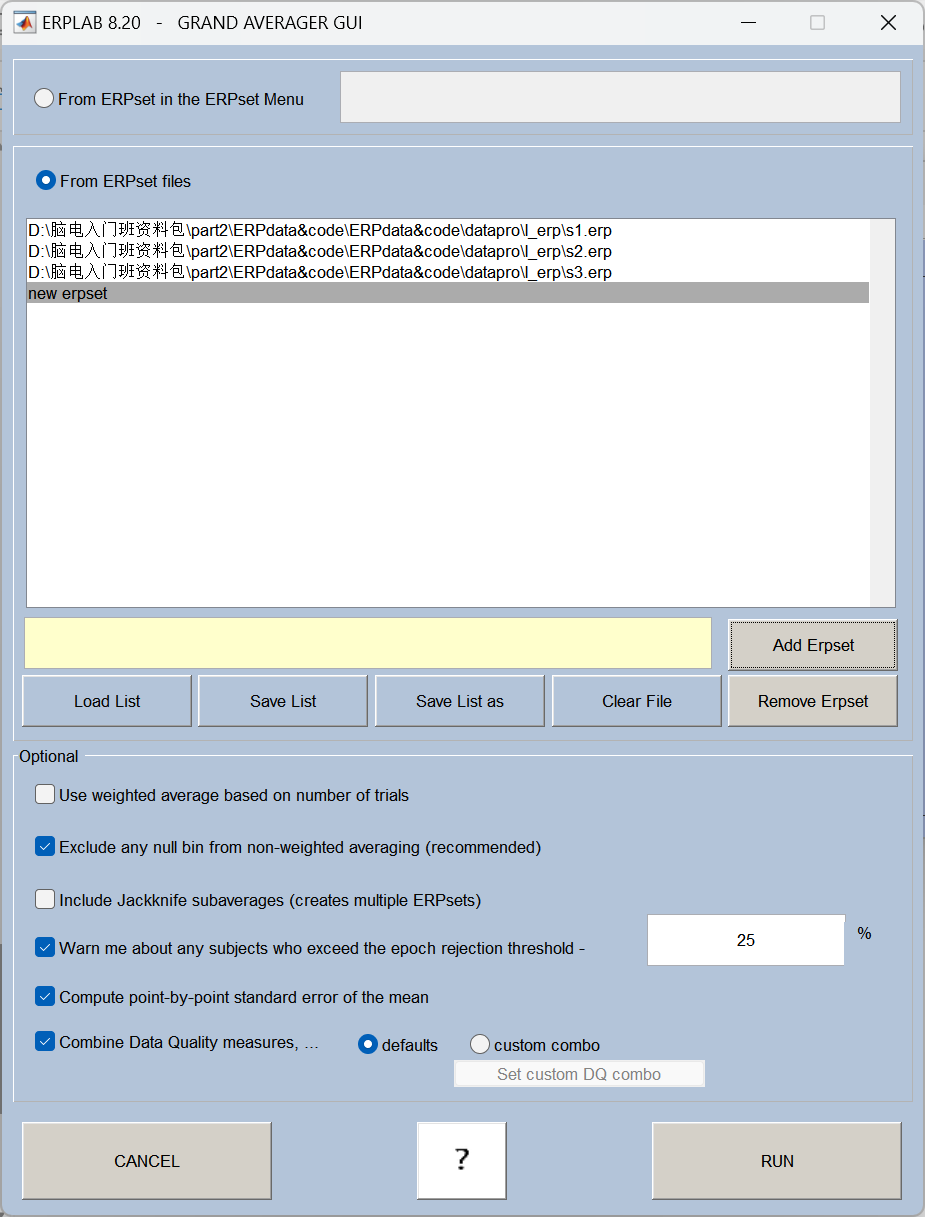
三、组水平叠加平均

二、组叠加平均的核心作用
1、进一步降低个体差异带来的噪声每个被试的脑电反应强度、潜伏期都有个体差异,组平均可以把这些差异 "抹平",凸显出群体的共同反应模式。
**2、得到可以做统计分析的 "组水平结果"**你做实验最终要分析的,通常是 "不同条件下,群体的 ERP 成分有没有差异",而不是单个被试的结果。组平均是做后续 t 检验、方差分析的基础。
小白笔记核心总结:
1、叠加平均的本质:用多次重复的试次,把随机噪声抵消,凸显固定的刺激诱发脑电信号。
2、步骤:先做单个被试内的试次叠加平均 → 再做多个被试间的组叠加平均。
3、目的:得到稳定、干净、能反映群体反应模式的 ERP 波形,用于后续分析。
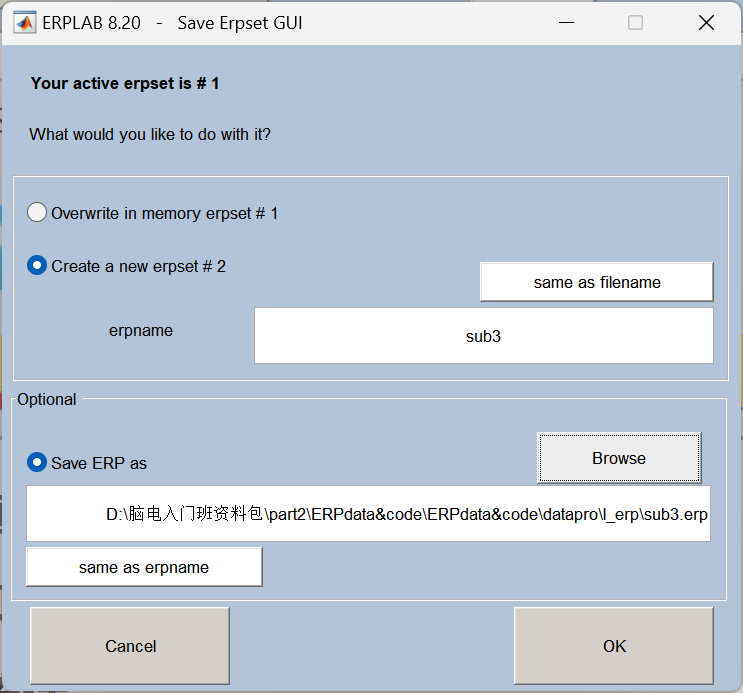
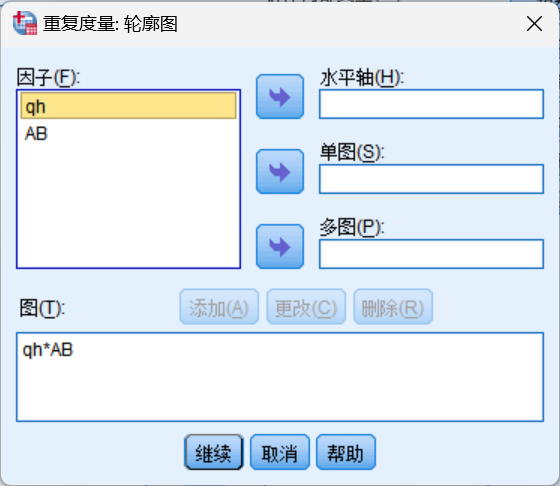
四、画图
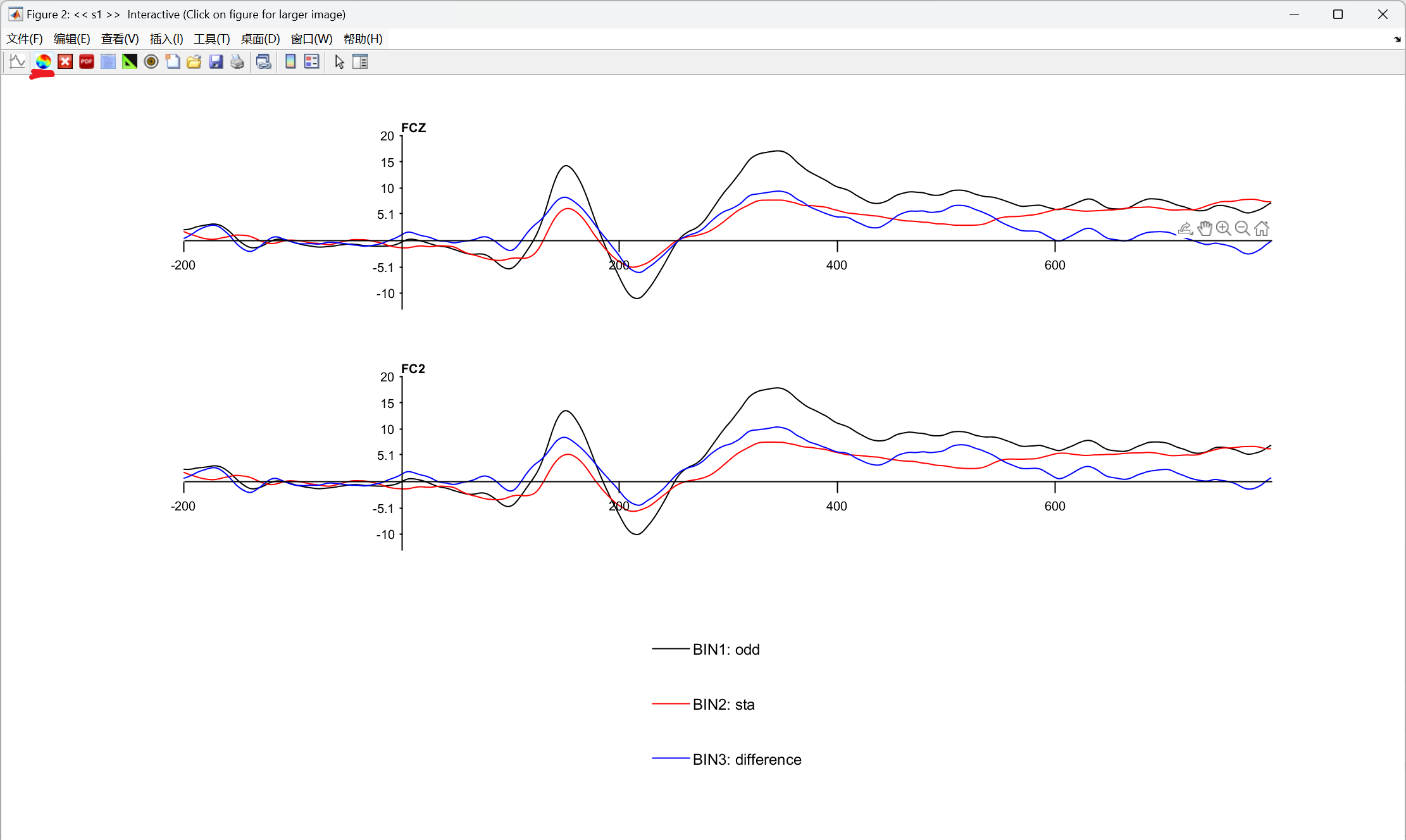
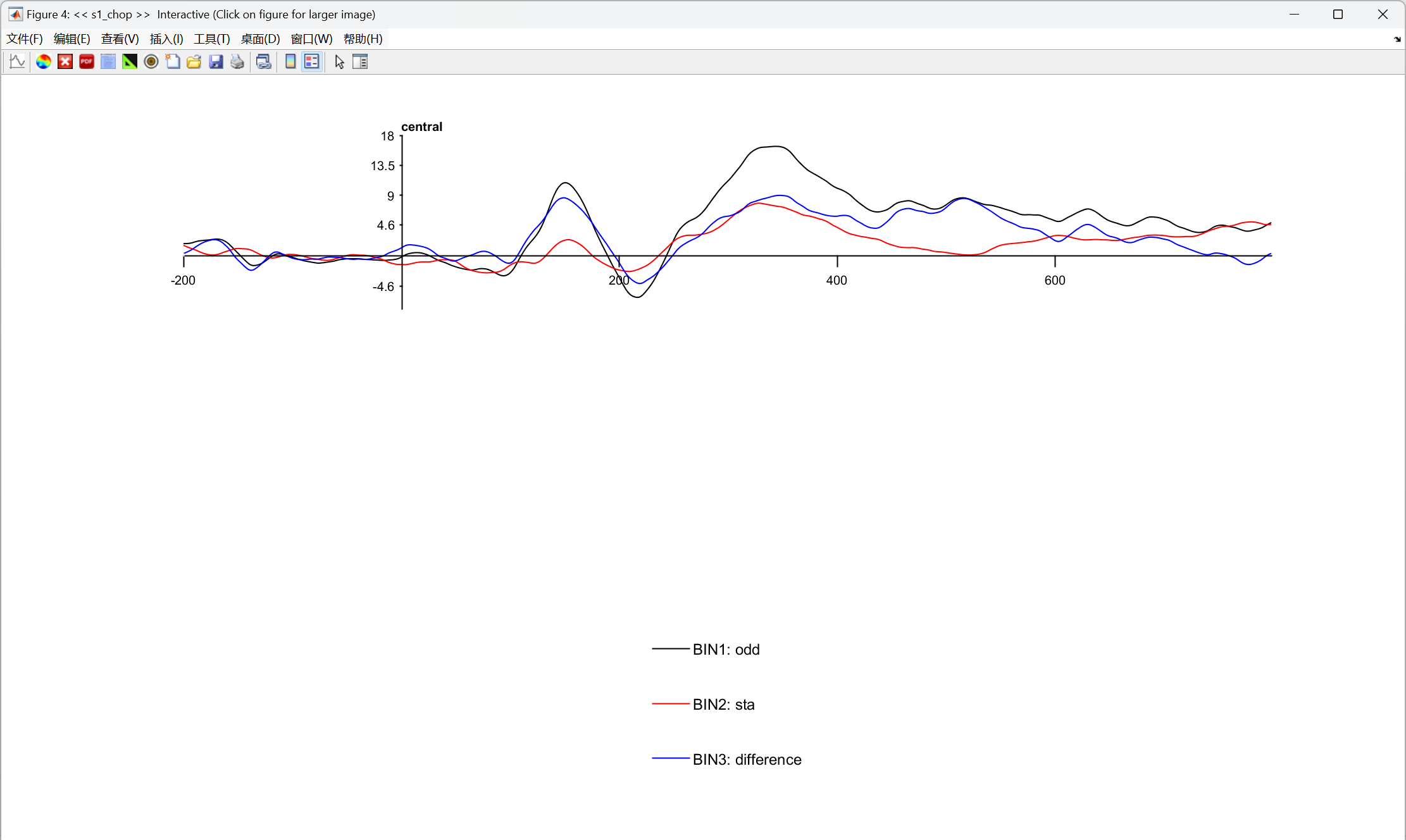
波形图:
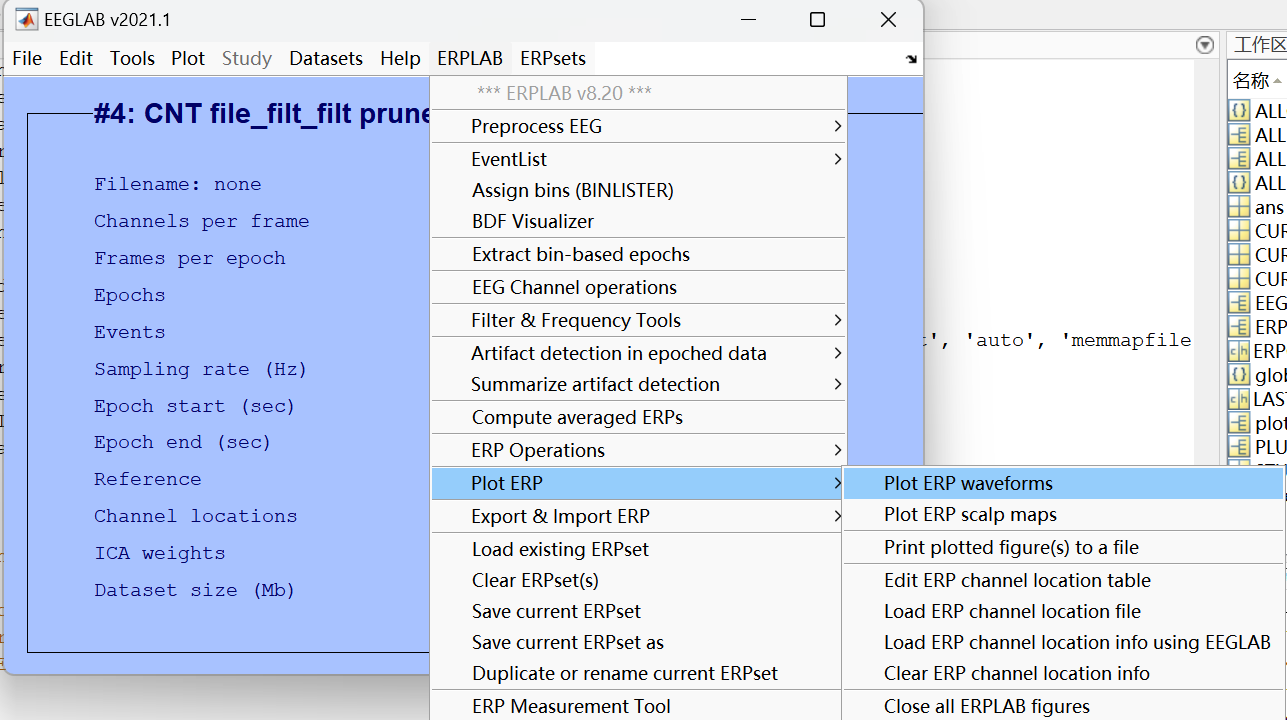
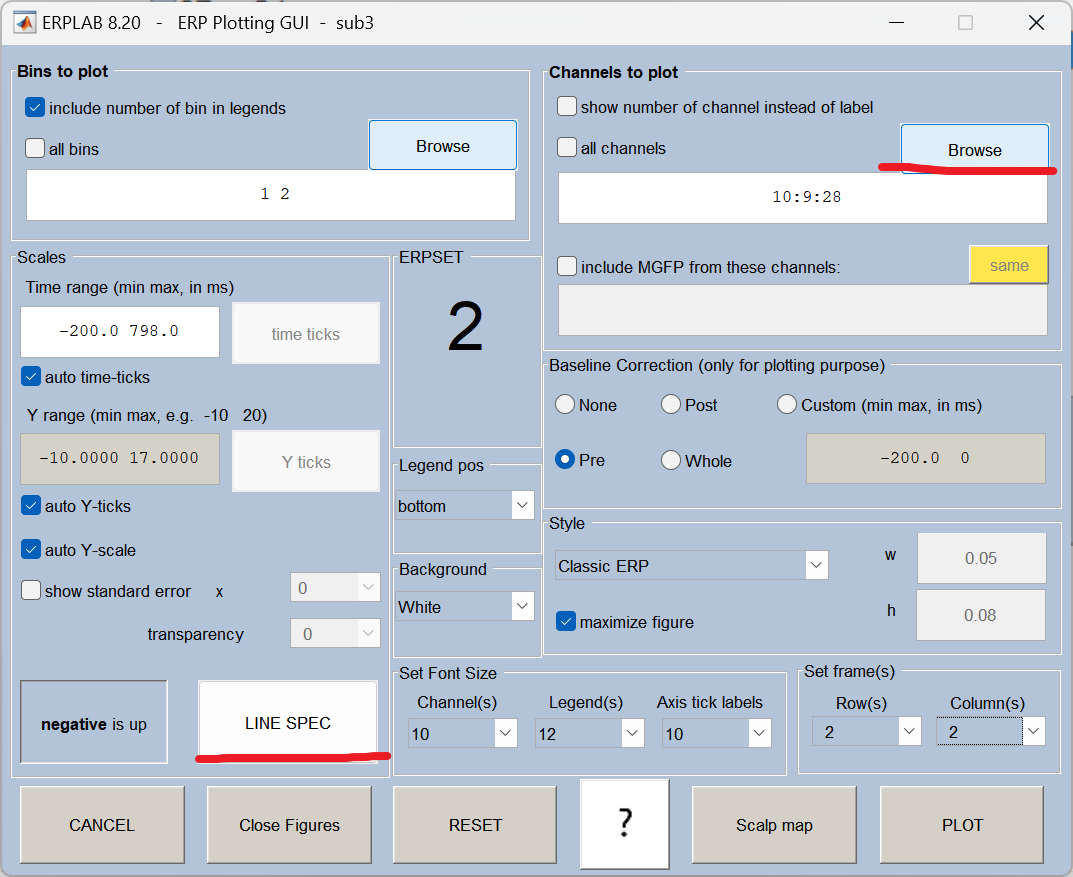
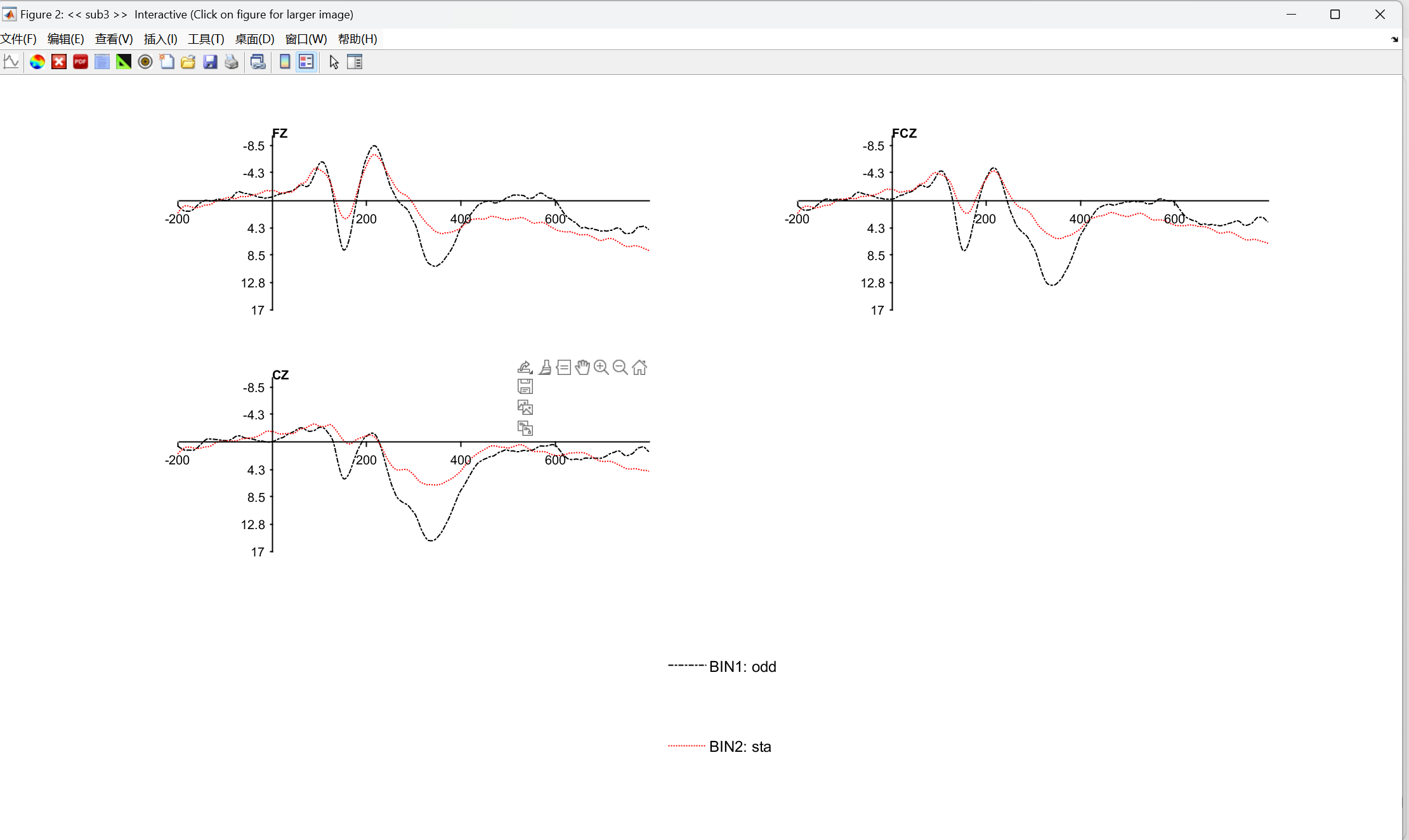
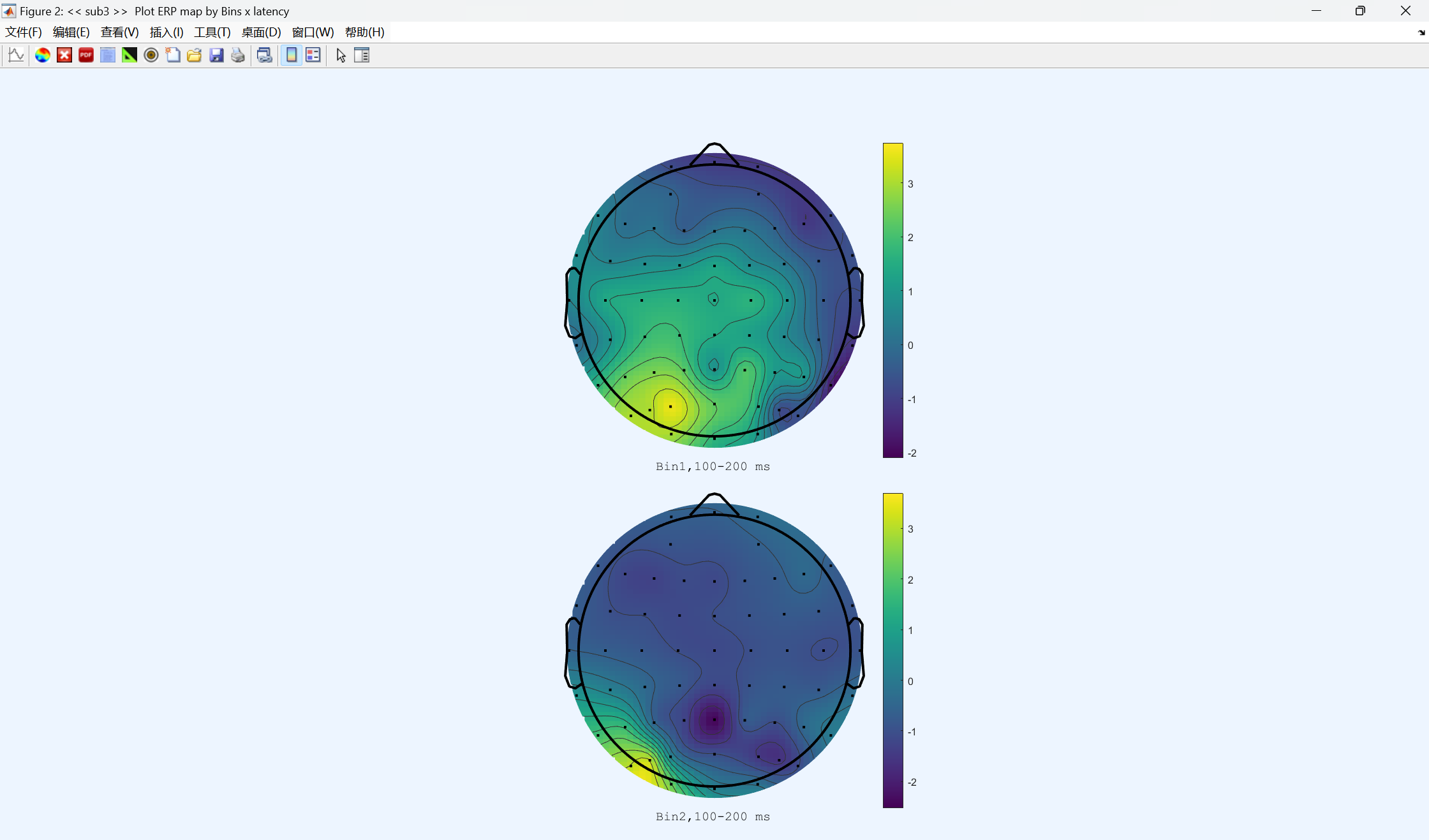
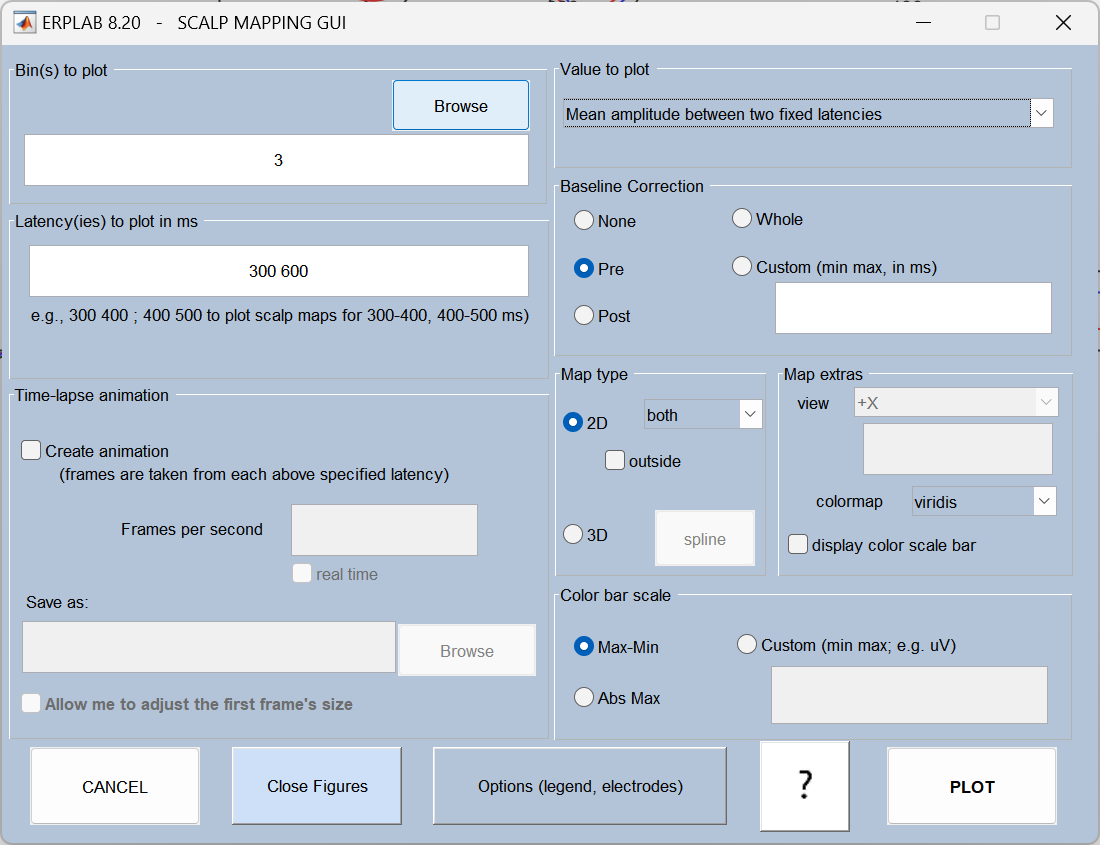
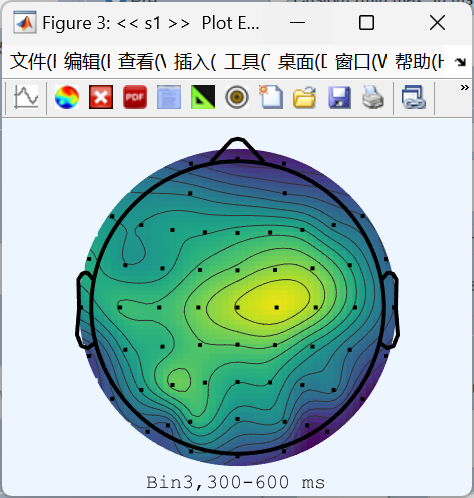
地形图:
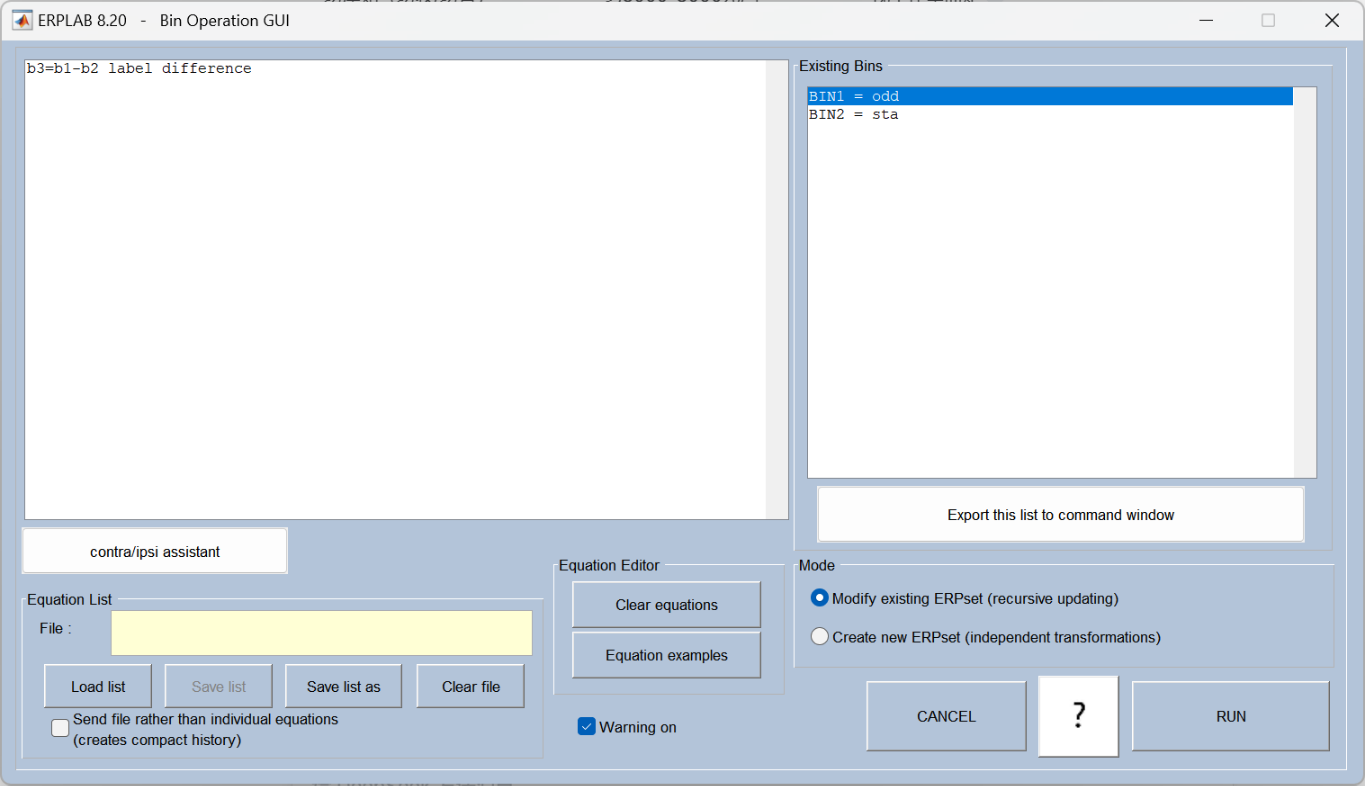
Bin operations:
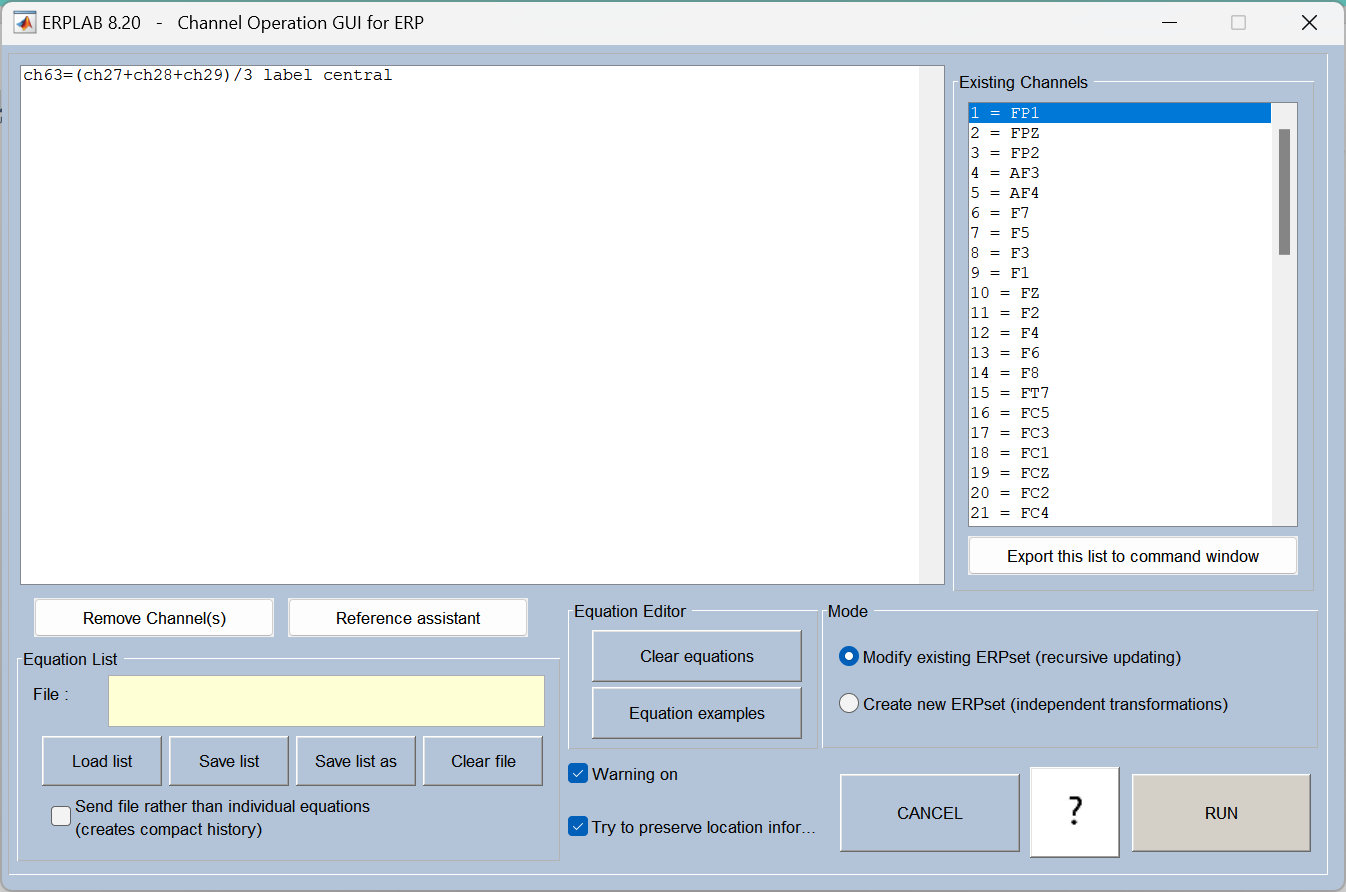
channel operations:
append ERPs:
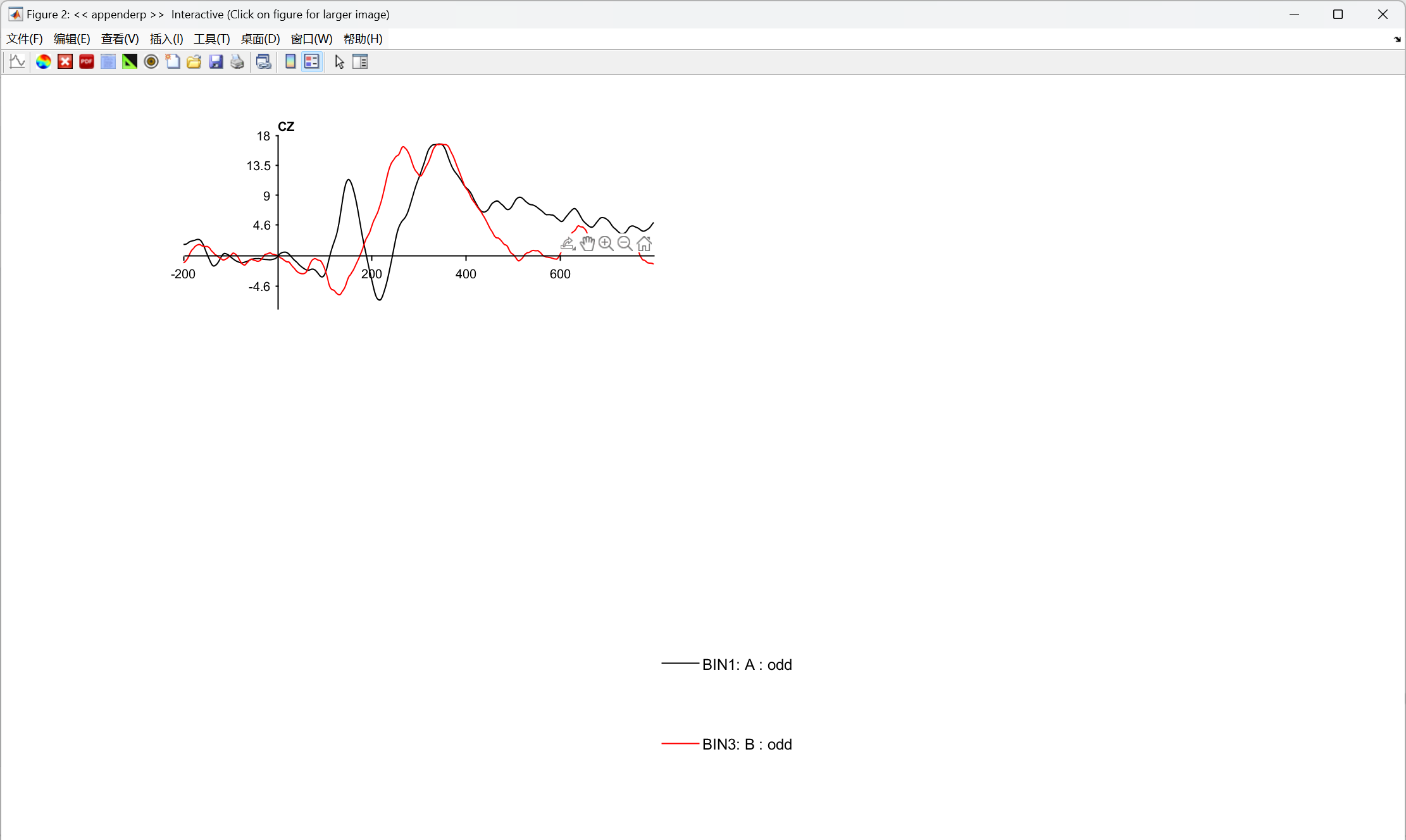
五、如何确定脑电成分
你看到的 ERP 波形上的 "波峰 / 波谷",不等于脑电成分本身。就像你看到水面上的波浪,它其实是水下多个水流叠加出来的结果,你没法单从表面波浪判断下面有几条水流。
1、波峰≠脑电成分,它只是多个成分叠加后的表面结果;
2、单条波形无法反推里面的潜在成分,同一个波形可以由无数种成分组合产生;
3、波峰时间窗口的差异,不能直接等同于该波峰对应成分的差异;
4、解决方法:计算差异波,把共同成分抵消,凸显出和实验操纵相关的特定成分。
六、测量与导出数据
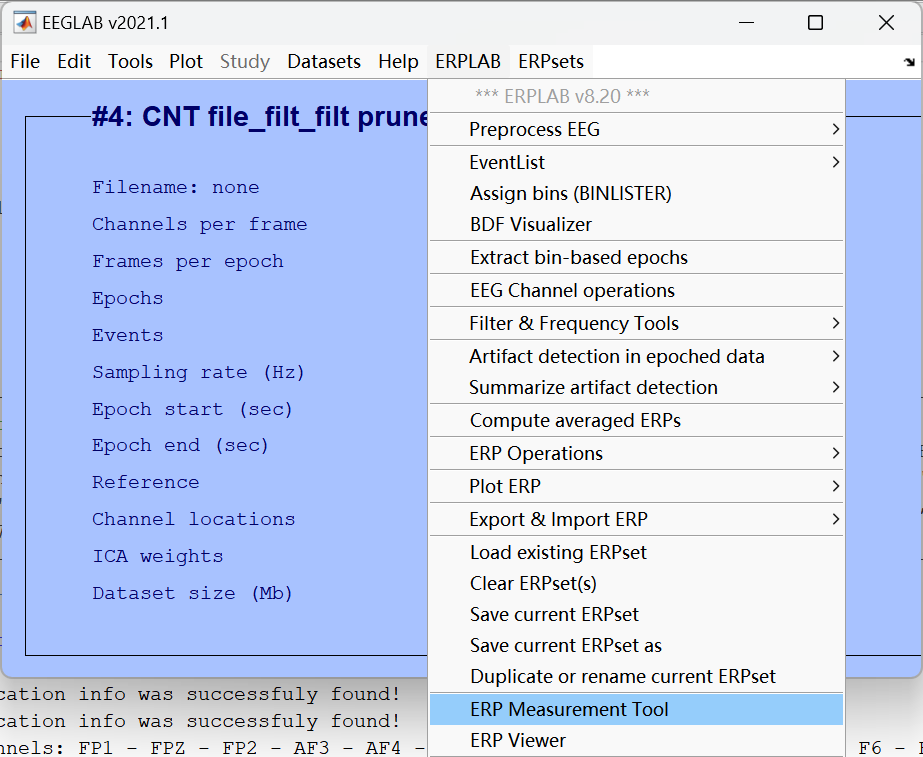
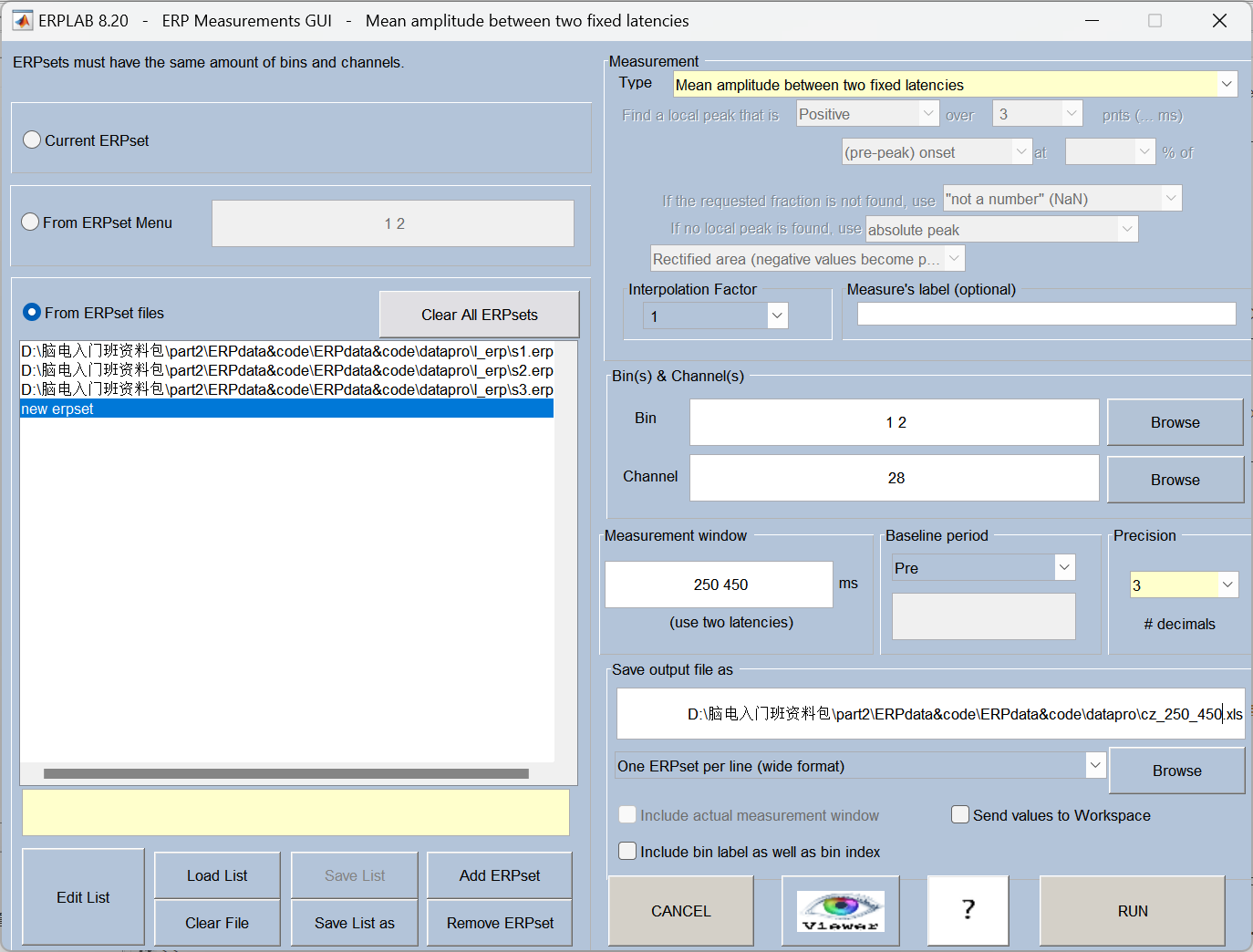
选 250-450ms,是因为:
1、这个窗口刚好覆盖了 P300 成分的效应区间,两种条件的差异在这段时间最明显;
2、用这段时间的平均波幅来量化 P300,比只取峰值更稳定、更可靠,也更能反映成分的整体强度。
你做 oddball 范式的 ERP 实验,核心目的是:证明「靶刺激(odd)」和「标准刺激(sta)」诱发的脑电反应存在显著差异 ,也就是我们关注的 P300 成分在两种条件下不一样。所以,我们分析的不是单个波形,而是两种条件的差异。
举个例子:

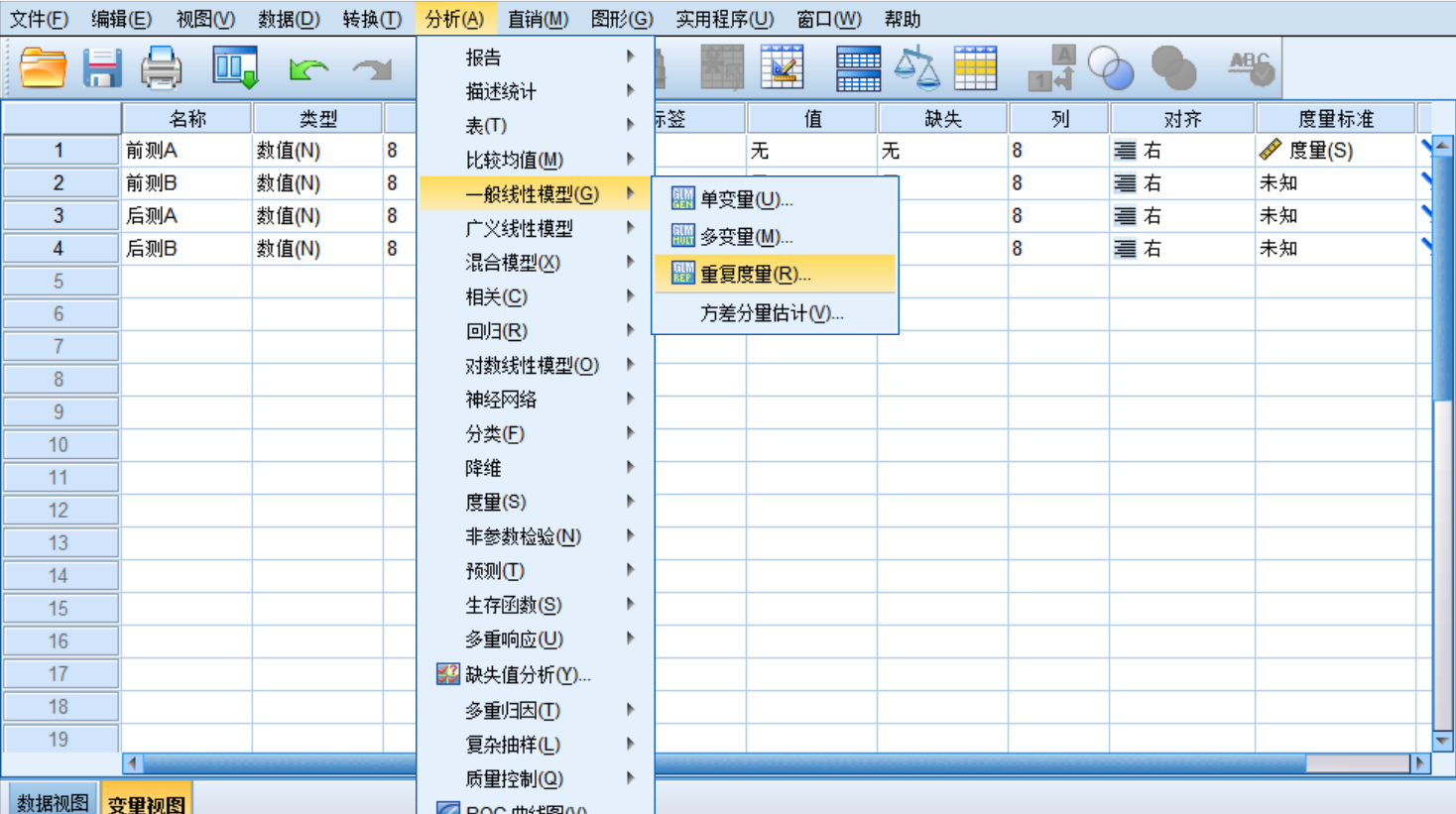
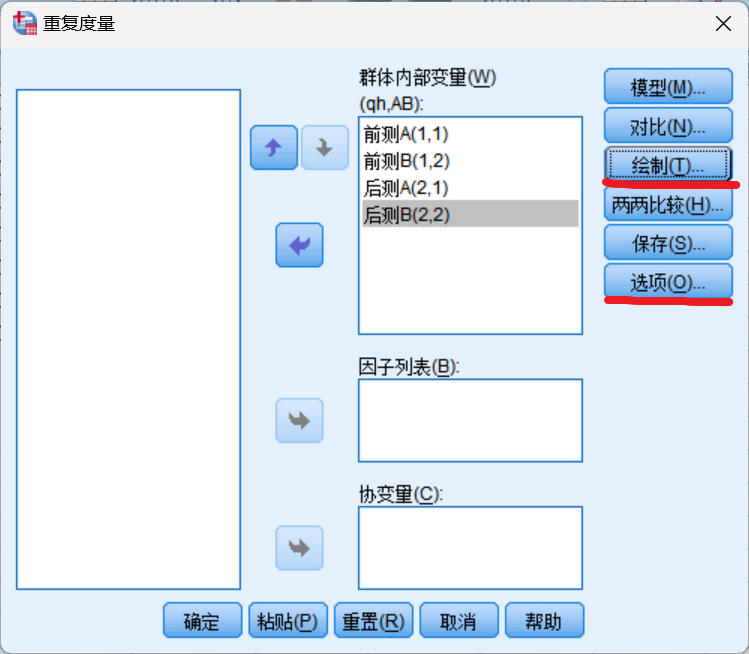
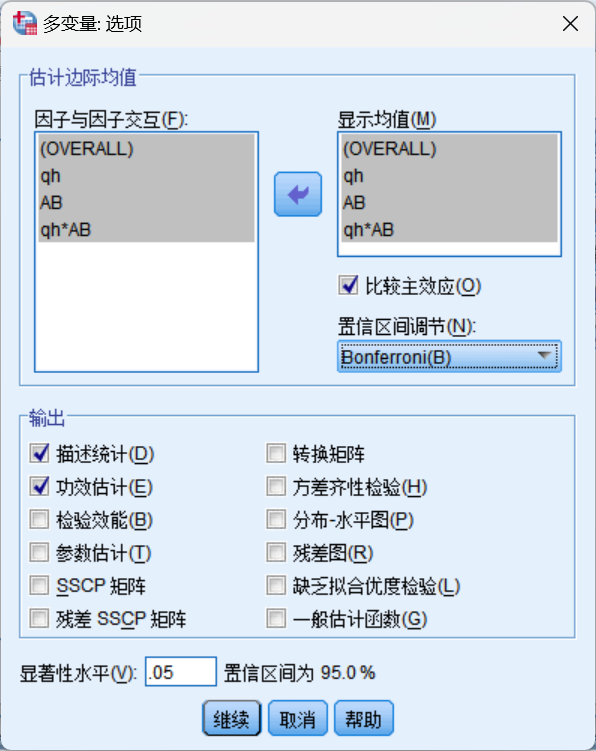
七、统计
为什么ERP实验的最后要做统计?




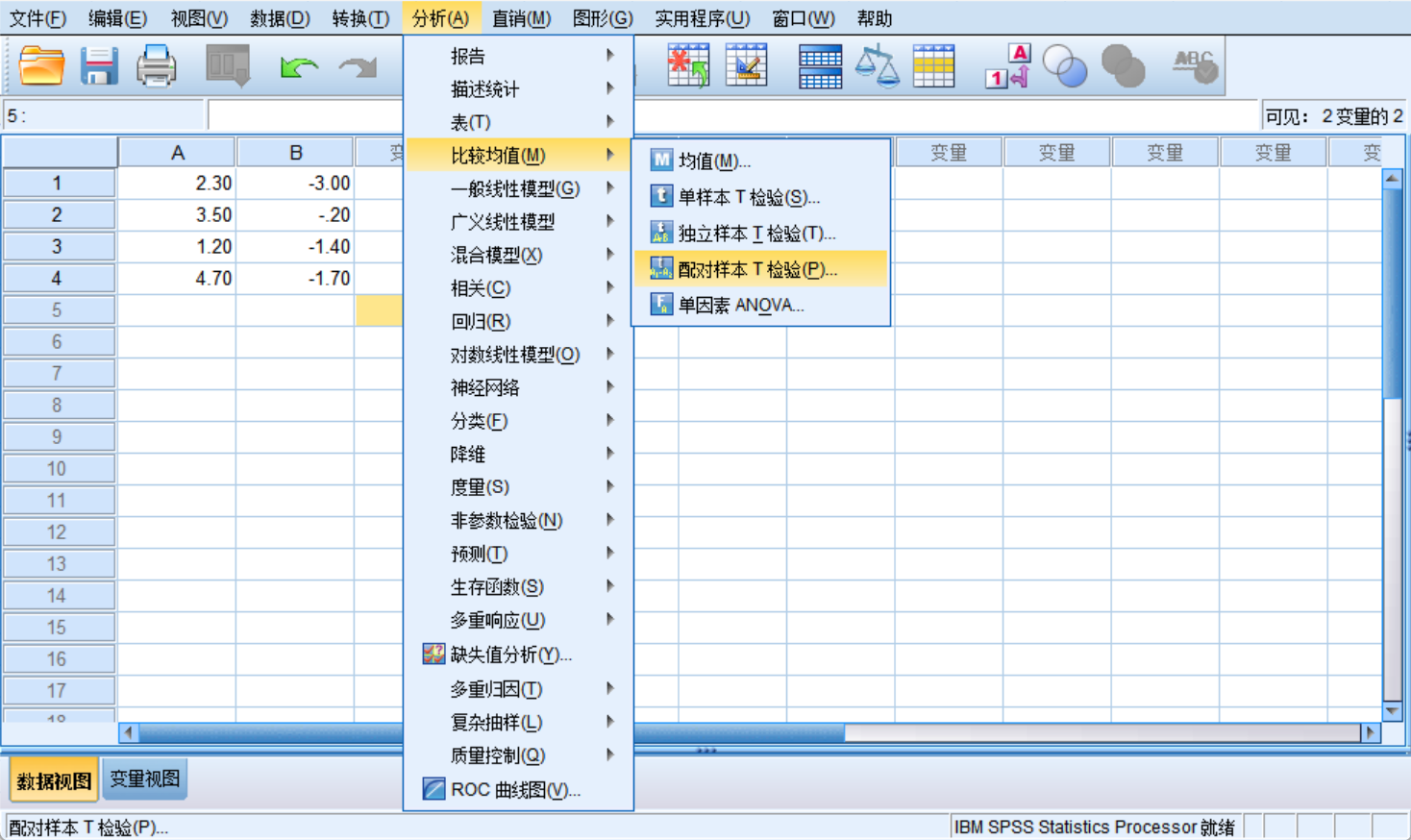
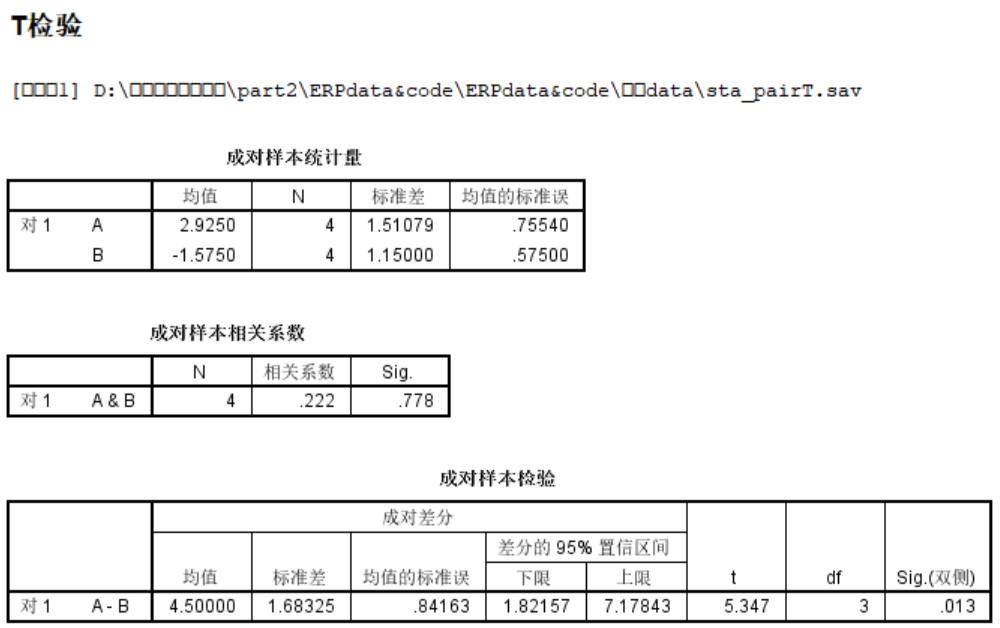
配对T:

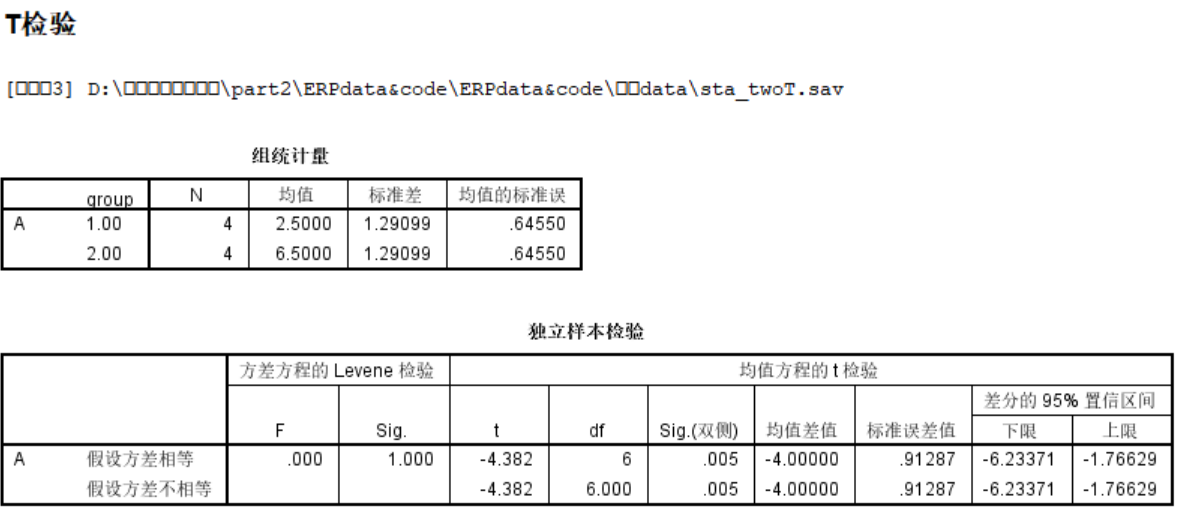
双样本T:

ANOVA: