#这比赛纯达芬,mobile让AI跑跑就行了,不会的我这里放一下wp#
深海金库
初步审计
题目给的是一个 Android APK:`app-release-01.apk`。先看压缩包结构,可以看到除了常规的 `classes.dex`、资源文件以外,还带了一个 native 库:
```text
lib/arm64-v8a/libsecure_verify.so
lib/armeabi-v7a/libsecure_verify.so
lib/x86/libsecure_verify.so
lib/x86_64/libsecure_verify.so
```
这说明 flag 校验大概率不是纯 Java 层完成,而是 Java 先做一部分处理,再把结果交给 native 层。
题目描述里提到"秘密深藏于耐心之中,而开启的旋律会随深度起伏",这里的"旋律随深度起伏"一开始看起来像提示某种递推流或周期变换。后面分析 native 时确实能对应到 Fibonacci 流异或。
定位 Java 层入口
用 Jadx 打开 APK 后,包名为:
```text
com.example.mobile02
```
!Java 入口与隐藏触发
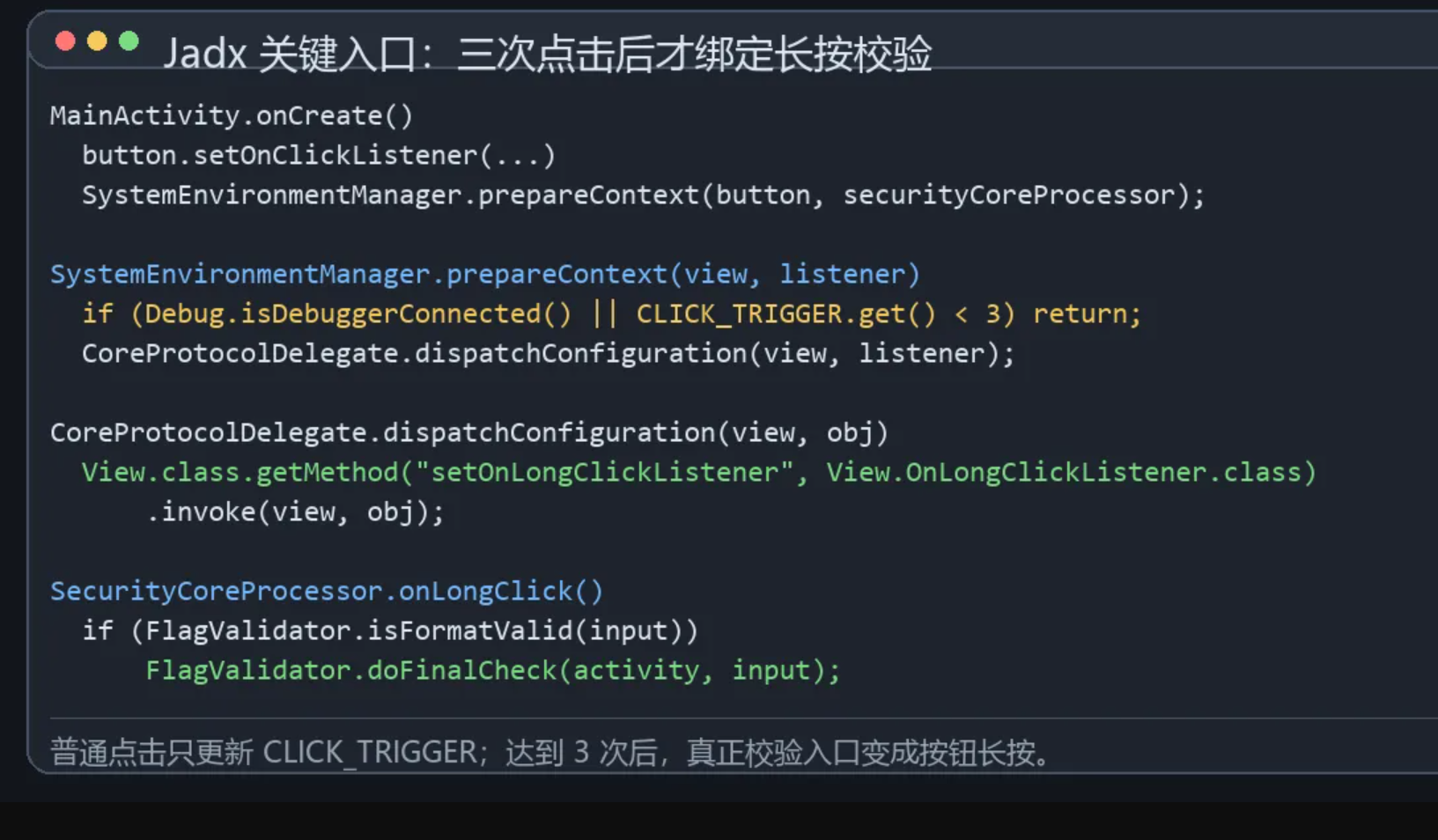
上图把入口链路整理出来了:普通点击只更新内部计数,达到 3 次后才会通过反射把长按监听器绑定到按钮上。
入口界面逻辑在 `MainActivity` 中。`onCreate()` 里加载布局、找到按钮和输入框,然后给按钮绑定点击事件:
```java
protected void onCreate(Bundle bundle) {
final SecurityCoreProcessor securityCoreProcessor = new SecurityCoreProcessor(this);
super.onCreate(bundle);
setContentView(R.layout.activity_main);
final Button button = (Button) findViewById(R.id.btn_verify);
final EditText editText = (EditText) findViewById(R.id.et_flag);
button.setOnClickListener(...);
SystemEnvironmentManager.prepareContext(button, securityCoreProcessor);
}
```
按钮点击后并不直接校验 flag,而是先更新一个计数器:
```java
SystemEnvironmentManager.updateState();
SystemEnvironmentManager.prepareContext(button, securityCoreProcessor);
Toast.makeText(this, "Initializing Secure Handshake...", 0).show();
```
继续看 `SystemEnvironmentManager.prepareContext()`:
```java
public static void prepareContext(View view, View.OnLongClickListener onLongClickListener) {
if (Debug.isDebuggerConnected() || CLICK_TRIGGER.get() < 3) {
return;
}
CoreProtocolDelegate.dispatchConfiguration(view, onLongClickListener);
}
```
这里需要点击次数达到 3 次后,才会通过反射把按钮的长按监听器设置上:
```java
View.class
.getMethod("setOnLongClickListener", View.OnLongClickListener.class)
.invoke(view, obj);
```
所以真实校验入口不是普通点击,而是"三次点击后长按按钮"触发的 `SecurityCoreProcessor.onLongClick()`。
追到校验函数
`SecurityCoreProcessor.onLongClick()` 里先检查输入格式:
```java
String string = editText.getText().toString();
if (FlagValidator.isFormatValid(string)) {
if (FlagValidator.doFinalCheck(this.activity, string)) {
Toast.makeText(this.activity, "Deep Sea Vault Opened.", 1).show();
} else {
Toast.makeText(this.activity, "Security Protocol Active.", 0).show();
}
} else {
Toast.makeText(this.activity, "Invalid Format.", 0).show();
}
```
格式检查函数很简单:
```java
public static boolean isFormatValid(String str) {
return str != null && str.startsWith("ISCC{") && str.endsWith("}");
}
```
真正的校验在 `doFinalCheck()`:
```java
public static boolean doFinalCheck(MainActivity mainActivity, String str) {
return mainActivity.nativeVerify(
CryptoEngine.performTransformation(str.substring(5, str.length() - 1))
);
}
```
也就是说:
-
flag 必须是 `ISCC{...}` 格式;
-
只取花括号内部内容;
-
先经过 `CryptoEngine.performTransformation()`;
-
再传入 native 方法 `nativeVerify(byte\[\])`。
`MainActivity` 里加载的 native 库是:
```java
static {
System.loadLibrary("secure_verify");
}
```
因此下一步需要分析 `libsecure_verify.so`。
Java 层第一段变换
`CryptoEngine.performTransformation()` 的逻辑如下:
!Java 层变换逻辑
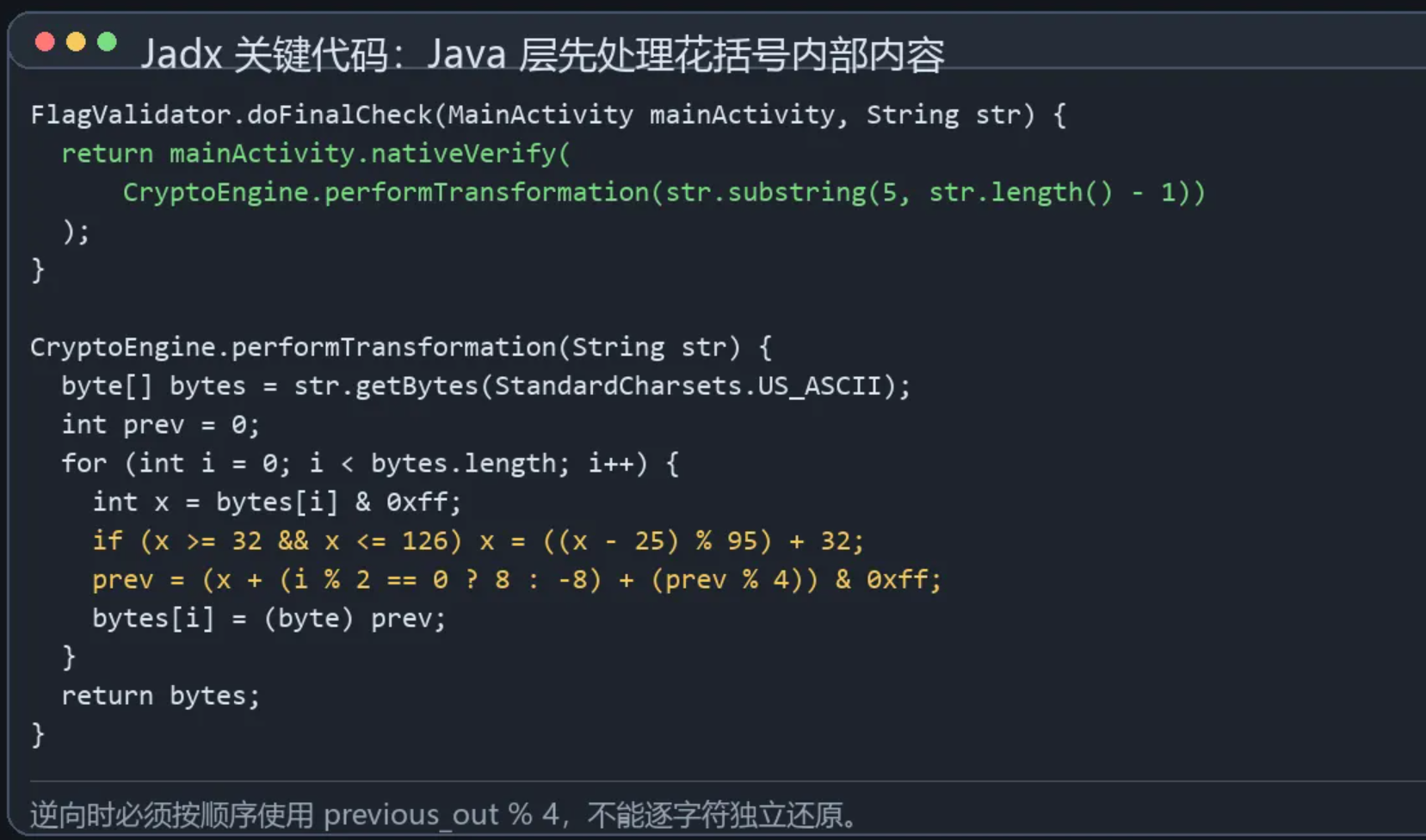
```java
public static byte\[\] performTransformation(String str) {
byte\[\] bytes = str.getBytes(StandardCharsets.US_ASCII);
int i = 0;
for (int i2 = 0; i2 < bytes.length; i2++) {
int i3 = bytesi2 & 255;
if (i3 >= 32 && i3 <= 126) {
i3 = ((i3 - 25) % 95) + 32;
}
i = (i3 + (i2 % 2 == 0 ? 8 : -8) + (i % 4)) & 255;
bytesi2 = (byte) i;
}
return bytes;
}
```
这里有两个点需要注意:
-
Jadx 里反编译出来的 `((i3 - 25) % 95) + 32` 对 Java 来说等价于对可打印字符做循环位移。由于输入是可打印 ASCII,实际效果可以按 `+7 mod 95` 理解。
-
当前字节的输出还依赖前一个输出字节的低 2 bit:`i % 4`。
因此逆向时不能逐字节独立还原,要按顺序用前一个变换结果参与计算。
进入 native 校验
在 `libsecure_verify.so` 中可以看到导出符号:
!Native 校验链路
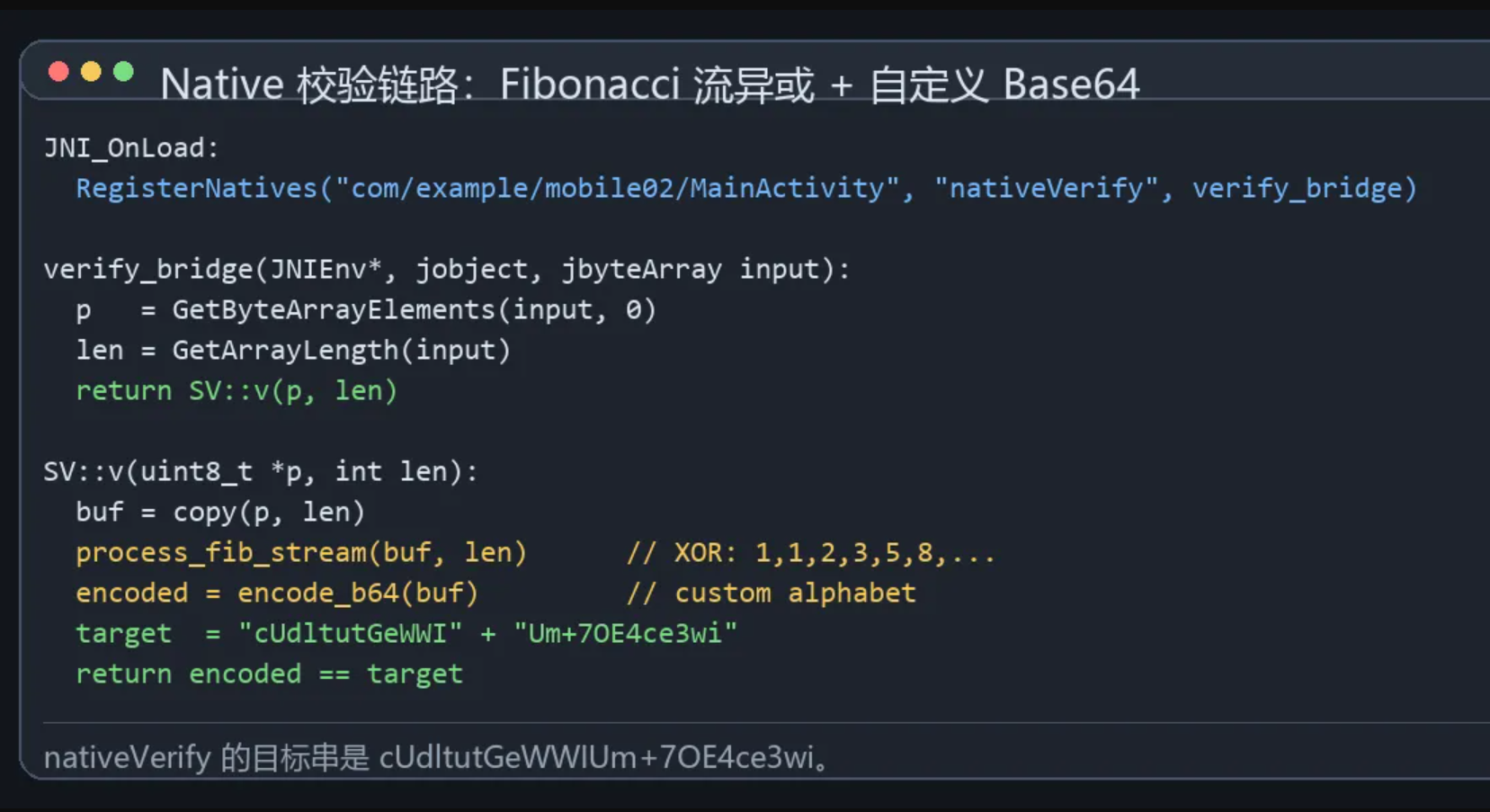
```text
_Z13verify_bridgeP7_JNIEnvP8_jobjectP11_jbyteArray
_ZN2SV1vEPKhi
_Z18process_fib_streamPhi
_Z10encode_b64RKNSt6__ndk16vectorIhNS_9allocatorIhEEEE
JNI_OnLoad
```
`JNI_OnLoad` 中把 Java 的 `nativeVerify` 注册到 `verify_bridge`,而 `verify_bridge` 的主要工作是从 Java byte array 取出数据,然后调用 `SV::v()`:
```text
GetByteArrayElements(...)
GetArrayLength(...)
SV::v(input, length)
ReleaseByteArrayElements(...)
```
继续看 `SV::v()`,流程很清楚:
-
拷贝 Java 层传入的字节;
-
调用 `process_fib_stream()`;
-
调用 `encode_b64()`;
-
和一个固定目标串比较。
固定目标串由两部分拼出来:
```text
cUdltutGeWWI
Um+7OE4ce3wi
```
拼接后得到:
```text
cUdltutGeWWIUm+7OE4ce3wi
```
Fibonacci 流异或
`process_fib_stream()` 的逻辑是对每个字节异或 Fibonacci 序列:
```text
1, 1, 2, 3, 5, 8, 13, 21, ...
```
也就是:
```python
a, b = 1, 1
for i in range(len(data)):
datai ^= a & 0xff
a, b = b, (a + b) & 0xff
```
这个函数正好对应题目描述里的"旋律会随深度起伏"。
自定义 Base64 表
一开始如果直接用标准 Base64 去解 `cUdltutGeWWIUm+7OE4ce3wi`,逆出来的结果对不上 Java 变换。回头看 `encode_b64()`,发现它没有使用标准 Base64 表,而是从初始化代码里构造了一张 64 字节的表:
```text
zKJUExRaVtM3Ydv5TQIsWD1frnHC78Lckl6euPh9AGoj0SgN4Zp+OwXi2F/ybmBq
```
所以正确方向是先把目标串从自定义表映射回标准 Base64 字符集,再进行 Base64 解码。
标准表为:
```text
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
```
映射后:
```text
cUdltutGeWWIUm+7OE4ce3wi
```
会变成:
```text
fDNhJkJpjUUSD9zc0EwfjL13
```
Base64 解码得到 18 字节:
```text
7c33612642698d45120fdcdcd04c1f8cbd77
```
这 18 字节再异或 Fibonacci 流,得到 Java 层变换后的目标字节:
```text
7d326325476180503038854c39357d57806f
```
逆回 flag 内部字符串
现在要逆 `CryptoEngine.performTransformation()`。正向公式可以写成:
```text
shifted = printable_shift(input)
outi = shifted + alt + (previous_out % 4)
```
其中:
```text
alt = 8 if i 是偶数
alt = -8 if i 是奇数
```
逆向时按顺序处理每个目标字节:
```text
shifted = outi - alt - (previous_out % 4)
input = shifted 逆循环位移
```
注意这里的循环位移要按 Java 代码的真实效果反推。对可打印字符而言,正向等价于:
```text
shifted = ((input - 25) mod 95) + 32
```
逆向就是:
```text
input = ((shifted - 32 - 7) mod 95) + 32
```
逐字节逆完后,花括号内部内容为:
```text
n2R#7_pQ!9vL*5mWnp
```
所以完整 flag 是:
```text
ISCC{n2R#7_pQ!9vL*5mWnp}
```
EXP
```python
#!/usr/bin/env python3
import base64
CUSTOM_B64 = "zKJUExRaVtM3Ydv5TQIsWD1frnHC78Lckl6euPh9AGoj0SgN4Zp+OwXi2F/ybmBq"
STD_B64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
TARGET = "cUdltutGeWWIUm+7OE4ce3wi"
def decode_custom_b64(s: str) -> bytes:
mapped = s.translate(str.maketrans(CUSTOM_B64, STD_B64))
return base64.b64decode(mapped)
def undo_fib_stream(data: bytes) -> bytes:
out = bytearray()
a, b = 1, 1
for x in data:
out.append(x ^ (a & 0xff))
a, b = b, (a + b) & 0xff
return bytes(out)
def undo_java_transform(data: bytes) -> str:
out = bytearray()
prev = 0
for i, y in enumerate(data):
alt = 8 if i % 2 == 0 else -8
shifted = (y - alt - (prev % 4)) & 0xff
输入是可打印 ASCII,逆 Java 层的循环位移。
ch = ((shifted - 32 - 7) % 95) + 32
out.append(ch)
prev = y
return out.decode("ascii")
def main():
native_decoded = decode_custom_b64(TARGET)
java_target = undo_fib_stream(native_decoded)
inner = undo_java_transform(java_target)
print(f"ISCC{{{inner}}}")
if name == "main":
main()
```
运行后得到:
!脚本运行结果
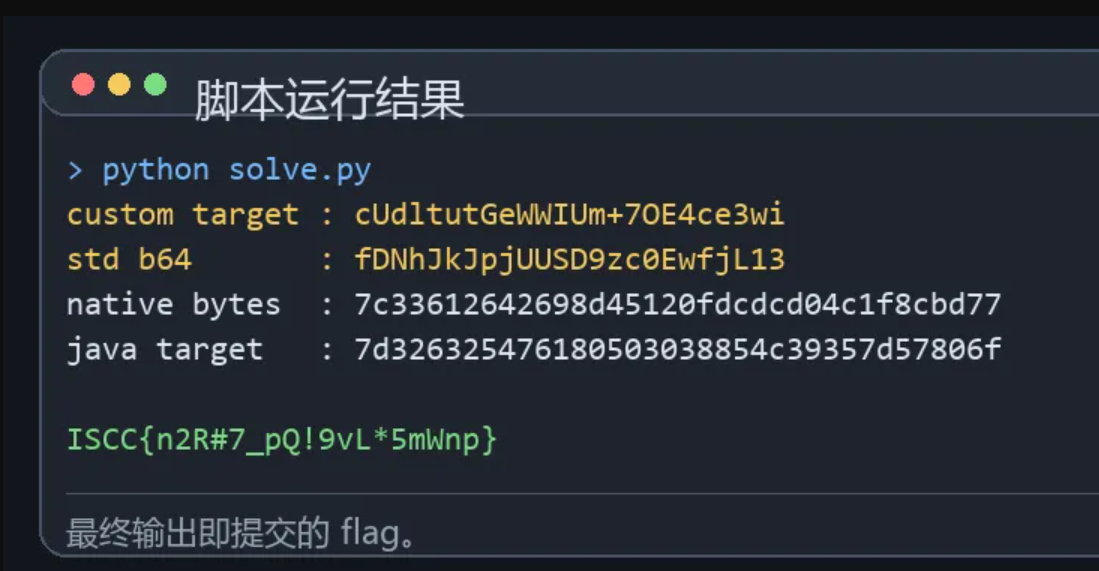
```text
ISCC{n2R#7_pQ!9vL*5mWnp}
```
Flag
```text
ISCC{n2R#7_pQ!9vL*5mWnp}
```
小结
这题的入口有一个小隐藏点:普通点击只会更新状态和弹错误提示,真正的校验要三次点击后长按按钮触发。算法上则是 Java 层可打印字符变换、native 层 Fibonacci 流异或、自定义 Base64 三层组合。只要注意 Base64 表不是标准表,剩下的变换都可以直接按顺序逆回去。
深潮协定
初步审计
题目给的是一个 Android APK。先看压缩包结构,除了常规的 `classes.dex` 和资源文件外,还有一个 native 库:
```text
assets/telemetry.bin
lib/arm64-v8a/libdeepseal.so
lib/armeabi-v7a/libdeepseal.so
lib/x86/libdeepseal.so
lib/x86_64/libdeepseal.so
```
这基本说明校验链路不会只停留在 Java 层。结合题目描述"海底的协议不会说话,但每一层都在留下签名",我优先按"Java 层一层变换 + native 层一层变换"的方向去找入口。
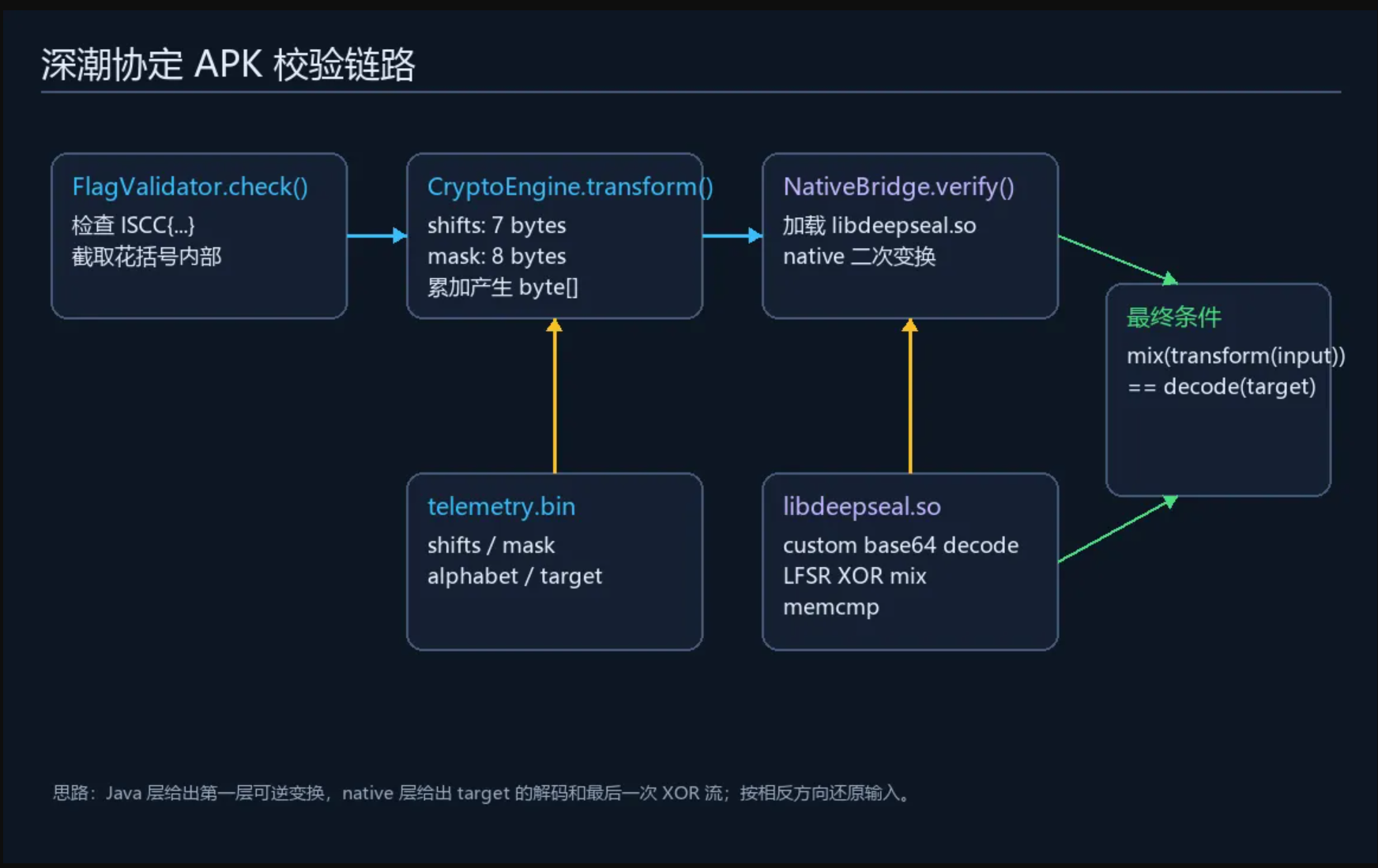
整体校验链路如下:
!APK 校验链路
定位 Java 层入口
用 Jadx 打开后,主要逻辑集中在 `cn.iscc.deepseal` 包下:
```text
cn.iscc.deepseal.FlagValidator
cn.iscc.deepseal.CryptoEngine
cn.iscc.deepseal.NativeBridge
cn.iscc.deepseal.Telemetry
```
!Jadx 中的关键 Java 类
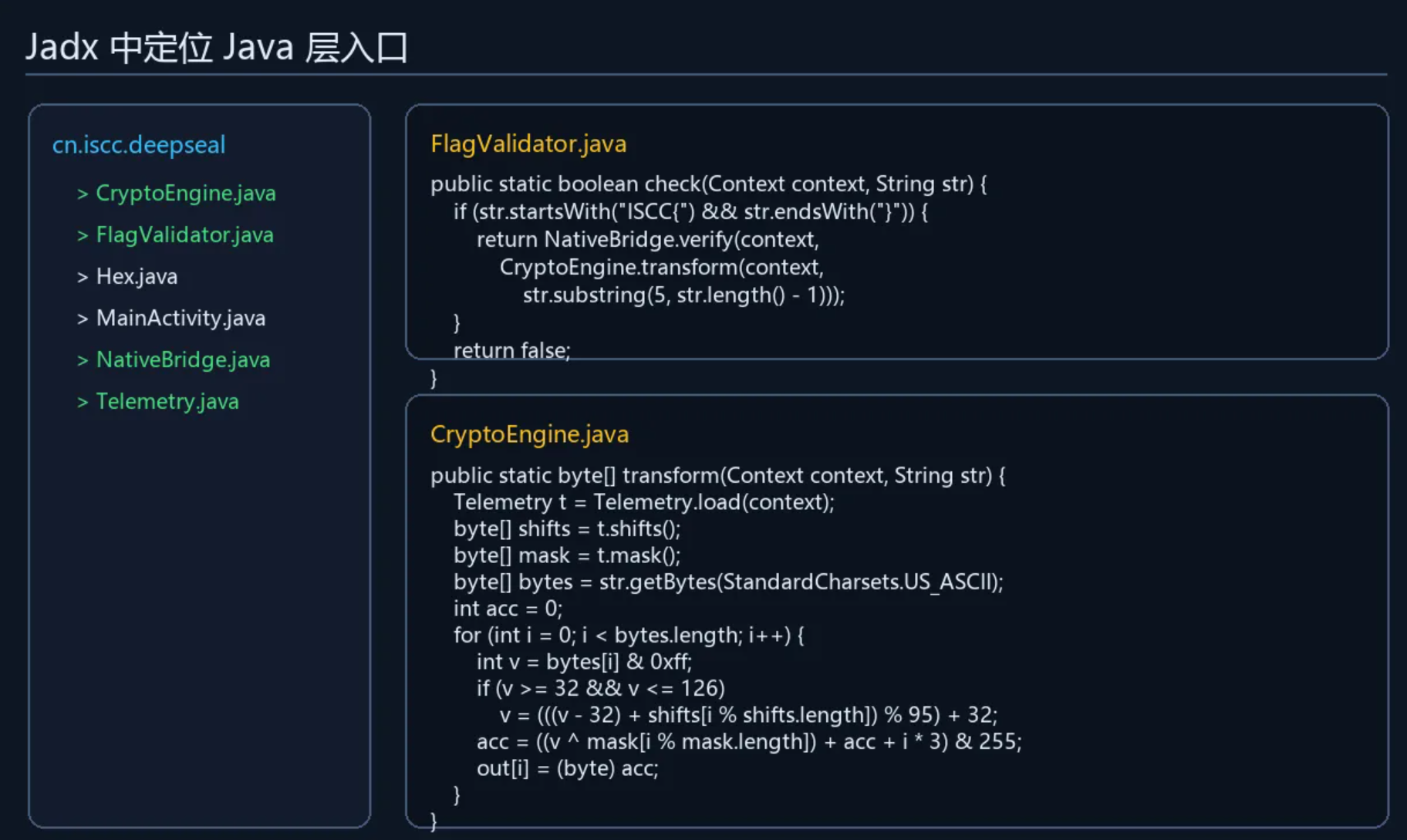
入口是 `FlagValidator.check()`:
```java
public static boolean check(Context context, String str) {
if (str.startsWith("ISCC{") && str.endsWith("}")) {
return NativeBridge.verify(
context,
CryptoEngine.transform(context, str.substring(5, str.length() - 1))
);
}
return false;
}
```
这里可以确定两点:
-
flag 外层格式是 `ISCC{...}`;
-
真正参与算法的是花括号内部字符串。
接着看 `CryptoEngine.transform()`。它先读取 `telemetry.bin`,取出 `shifts` 和 `mask`,然后对输入逐字节处理:
```java
int v = bytesi & 0xff;
if (v >= 32 && v <= 126) {
v = (((v - 32) + (shiftsi % shifts.length & 0xff)) % 95) + 32;
}
acc = ((v ^ (maski % mask.length & 0xff)) + acc + (i * 3)) & 255;
outi = (byte) acc;
```
这个变换看起来复杂,但每一步都是可逆的。因为最终 `acc` 被写入输出,所以反推第 `i` 位时,只要知道上一位输出 `prev`,就能还原当前字符经过位移后的值:
```python
shifted = ((cur - prev - i * 3) & 0xff) ^ maski % len(mask)
original = ((shifted - 32 - shiftsi % len(shifts)) % 95) + 32
```
读取 telemetry.bin
`Telemetry.load()` 会读取 `assets/telemetry.bin`,文件一共四行:
!telemetry.bin 参数(https://img.meituan.net/poiugc/a50c177f41adf9d94ae281ef3aedeb9e56640.png)
内容如下:
```text
0b04110916060d
1337c0de42a5197f
Qh2s7Ca9VxN4fKpB8J1mL+zoF0ewAyOu3DrRYSgPItU6McdkXl/WTnGEZ5ivbHjq
T8GHtJzYDRX7siXzWKLJCGlrpi1sVwnvMhZCPj3jwDWYU4Y=
```
前两行正好对应 Java 层的 `shifts` 和 `mask`:
```text
shifts = 0b04110916060d
mask = 1337c0de42a5197f
```
后两行暂时还没有被 Java 层使用,所以自然转向 native 层。第三行长度为 64,并且包含 `+`、`/`,非常像自定义 base64 字母表;第四行以 `=` 结尾,则像对应的密文 target。
分析 native 层
`NativeBridge` 只声明了一个 native 方法:
```java
public static native boolean verify(Context context, byte\[\] bArr);
```
在 `libdeepseal.so` 里能看到几个很直接的符号:
```text
Java_cn_iscc_deepseal_NativeBridge_verify
_Z17custom_b64_decode...
_Z21apply_native_lfsr_mixPhi
```
`custom_b64_decode` 的逻辑和名字一致:用 `telemetry.bin` 第三行作为 alphabet,对第四行 target 做 base64 解码。
真正需要反的部分是 `apply_native_lfsr_mix`。关键反汇编如下:
!native LFSR 逻辑

整理成伪代码是:
```python
state = 0x5d
for i in range(n):
bit = (state ^ (state >> 2) ^ (state >> 3) ^ (state >> 5)) & 1
state = ((state >> 1) | (bit << 7)) & 0xff
bufi ^= (state + i * 7) & 0xff
```
这里是 XOR 流,正向和反向是同一个操作。也就是说,native 层比较的实际条件可以写成:
```text
lfsr_mix(CryptoEngine.transform(input)) == custom_b64_decode(target)
```
所以反过来做:
-
先用自定义 base64 解码 `target`;
-
对解码结果再做一次同样的 LFSR XOR,得到 Java 层 `transform()` 的输出;
-
最后反推 `CryptoEngine.transform()`,得到花括号内部内容。
构造最终解法
自定义 base64 解码逻辑按 native 里的状态机写即可:
```python
def custom_b64_decode(data: str, alphabet: str) -> bytes:
table = {ch: i for i, ch in enumerate(alphabet)}
value = 0
bits = -8
out = bytearray()
for ch in data:
if ch == "=":
break
value = (value << 6) | tablech
bits += 6
if bits >= 0:
out.append((value >> bits) & 0xff)
bits -= 8
return bytes(out)
```
LFSR 流按反汇编还原:
```python
def lfsr_stream(size: int) -> bytes:
state = 0x5d
stream = bytearray()
for i in range(size):
bit = (state ^ (state >> 2) ^ (state >> 3) ^ (state >> 5)) & 1
state = ((state >> 1) | (bit << 7)) & 0xff
stream.append((state + i * 7) & 0xff)
return bytes(stream)
```
最后反推 Java 层:
```python
def reverse_java_transform(data: bytes, shifts: bytes, mask: bytes) -> bytes:
prev = 0
out = bytearray()
for i, cur in enumerate(data):
shifted = ((cur - prev - i * 3) & 0xff) ^ maski % len(mask)
original = ((shifted - 32 - shiftsi % len(shifts)) % 95) + 32
out.append(original)
prev = cur
return bytes(out)
```
EXP
最后我把整个过程整理成 `solve.py`:
```python
#!/usr/bin/env python3
SHIFTS_HEX = "0b04110916060d"
MASK_HEX = "1337c0de42a5197f"
ALPHABET = "Qh2s7Ca9VxN4fKpB8J1mL+zoF0ewAyOu3DrRYSgPItU6McdkXl/WTnGEZ5ivbHjq"
TARGET = "T8GHtJzYDRX7siXzWKLJCGlrpi1sVwnvMhZCPj3jwDWYU4Y="
def custom_b64_decode(data: str, alphabet: str) -> bytes:
table = {ch: i for i, ch in enumerate(alphabet)}
value = 0
bits = -8
out = bytearray()
for ch in data:
if ch == "=":
break
value = (value << 6) | tablech
bits += 6
if bits >= 0:
out.append((value >> bits) & 0xFF)
bits -= 8
return bytes(out)
def lfsr_stream(size: int) -> bytes:
state = 0x5D
stream = bytearray()
for i in range(size):
bit = (state ^ (state >> 2) ^ (state >> 3) ^ (state >> 5)) & 1
state = ((state >> 1) | (bit << 7)) & 0xFF
stream.append((state + i * 7) & 0xFF)
return bytes(stream)
def reverse_java_transform(data: bytes, shifts: bytes, mask: bytes) -> bytes:
prev = 0
out = bytearray()
for i, cur in enumerate(data):
shifted = ((cur - prev - i * 3) & 0xFF) ^ maski % len(mask)
original = ((shifted - 32 - shiftsi % len(shifts)) % 95) + 32
out.append(original)
prev = cur
return bytes(out)
def main() -> None:
shifts = bytes.fromhex(SHIFTS_HEX)
mask = bytes.fromhex(MASK_HEX)
decoded_target = custom_b64_decode(TARGET, ALPHABET)
native_reversed = bytes(
x ^ y for x, y in zip(decoded_target, lfsr_stream(len(decoded_target)))
)
inner = reverse_java_transform(native_reversed, shifts, mask)
flag = f"ISCC{{{inner.decode('ascii')}}}"
print(f"decoded target : {decoded_target.hex()}")
print(f"native reversed: {native_reversed.hex()}")
print(f"inner flag : {inner.decode('ascii')}")
print(f"flag : {flag}")
if name == "main":
main()
```
运行后得到:
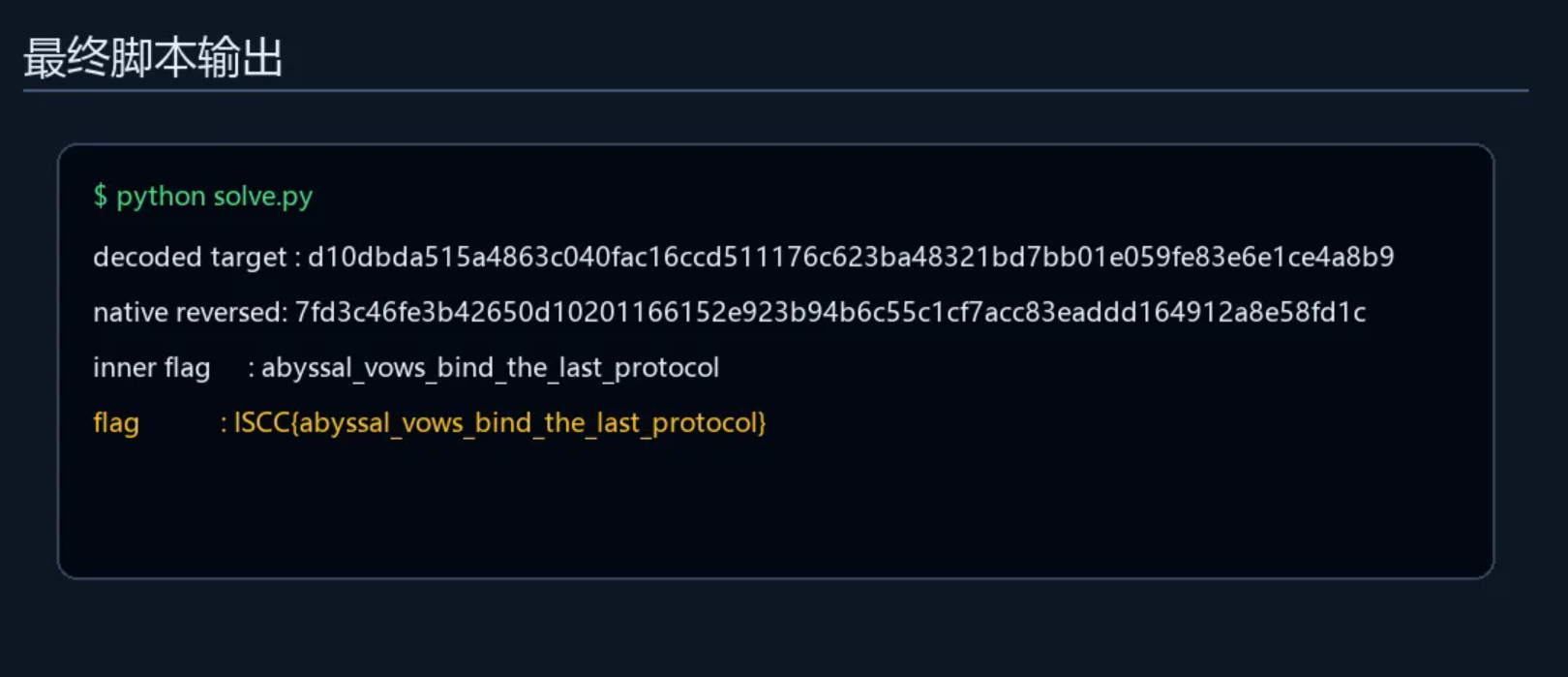
```text
decoded target : d10dbda515a4863c040fac16ccd511176c623ba48321bd7bb01e059fe83e6e1ce4a8b9
native reversed: 7fd3c46fe3b42650d10201166152e923b94b6c55c1cf7acc83eaddd164912a8e58fd1c
inner flag : abyssal_vows_bind_the_last_protocol
flag : ISCC{abyssal_vows_bind_the_last_protocol}
```
Flag
```text
ISCC{abyssal_vows_bind_the_last_protocol}
```
小结
这题的关键是不要只停在 Java 层。`CryptoEngine.transform()` 虽然已经有一层位移、异或和累加,但 Java 层没有出现 target;真正的 target 藏在 `telemetry.bin` 后两行,并由 native 层读取。native 里的 `custom_b64_decode` 和 `apply_native_lfsr_mix` 都是可逆变换,所以按 `target -> native 反向 -> Java 反向` 的顺序即可还原出 flag。
折叠回声
题目附件只有一个 `EchoFold.apk`,题面提示却把"回声"明确分成了三层:第一声像答案,第二声像线索,第三声才说真话。这样的提示说明样本里大概率存在明显诱饵,因此第一步不能停留在字符串表里的可疑 flag,而应该先确认 APK 的真实校验入口和资源结构。
初步审计
先看 APK 的基本信息。`AndroidManifest.xml` 里可以确认应用包名为 `com.iscc.echofold`,应用名为 `EchoFold`,入口只有一个 `MainActivity`,没有额外权限声明。样本体积也很小,压缩包里真正值得关注的文件只有几项:
```text
AndroidManifest.xml
classes.dex
assets/sleep_loop.webp
META-INF/ECHOFOLD.RSA
META-INF/ECHOFOLD.SF
META-INF/MANIFEST.MF
```
这类结构通常意味着关键逻辑都在本地:`classes.dex` 负责校验,`assets/` 负责藏数据,`META-INF/` 负责把结果和当前 APK 绑定起来。
!初步审计
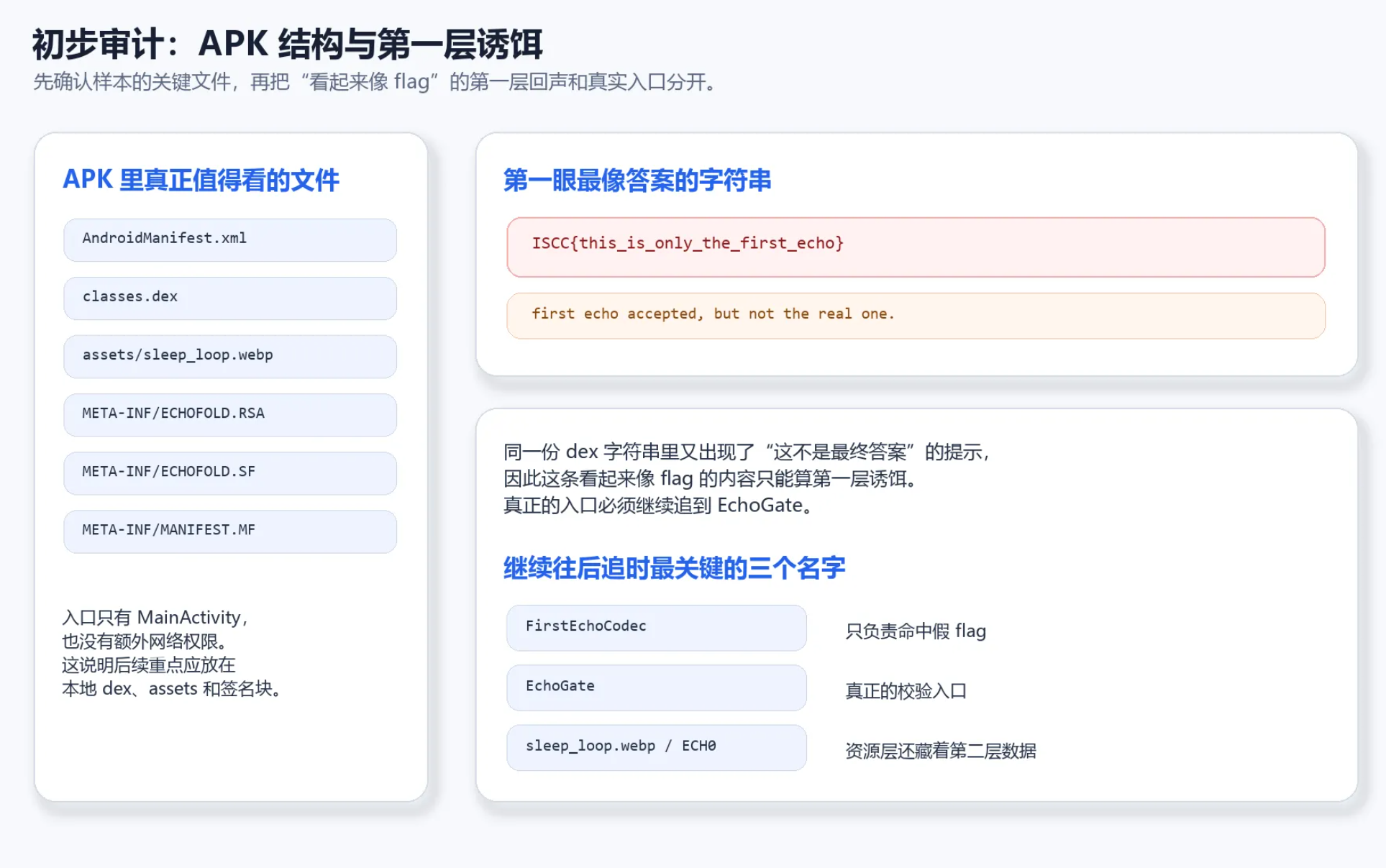
这张图把第一轮最值得关注的对象放到了一起:左侧是 APK 里真正参与解题的核心文件,右侧则把那条看起来像 flag、但同时被程序自己否认的字符串单独摘了出来。做到这一步时,题目的重心已经不再是"字符串里有没有 flag",而是"为什么样本要故意先给一个假答案"。
继续从 `classes.dex` 提取关键字符串,可以直接看到这条提示链:
```text
ISCC{this_is_only_the_first_echo}
first echo accepted, but not the real one.
The first echo still sounds convincing.
sleep_loop.webp
ECH0
fold-echo
vm-seed
FirstEchoCodec
EchoGate
TraceRecorder
```
这里最显眼的是一个非常像 flag 的字符串 `ISCC{this_is_only_the_first_echo}`,但同一份字符串表里又紧跟着出现了 `first echo accepted, but not the real one.`。这已经把题目的第一层误导写得很直白:样本故意放了一个"长得像答案"的假 flag,真正的逻辑在 `EchoGate` 之后。
第一处突破
主界面的分流逻辑并不复杂,关键在于它先经过一层诱饵校验,再进入真正校验。整理后可以写成下面的伪代码:
```java
if (FirstEchoCodec.check(input)) {
// first echo accepted, but not the real one.
} else {
EchoGate.verify(context, input);
}
```
`FirstEchoCodec.check()` 本身没有变换过程,只是把输入和固定字符串做比较:
```java
return "ISCC{this_is_only_the_first_echo}".equals(input);
```
这一步的意义不在于给出答案,而在于强迫分析继续往后走。题面里"第一声很像答案",对应的正是这条假 flag;真正值得继续追的对象变成了 `EchoGate.verify()`。
!三层回声链路
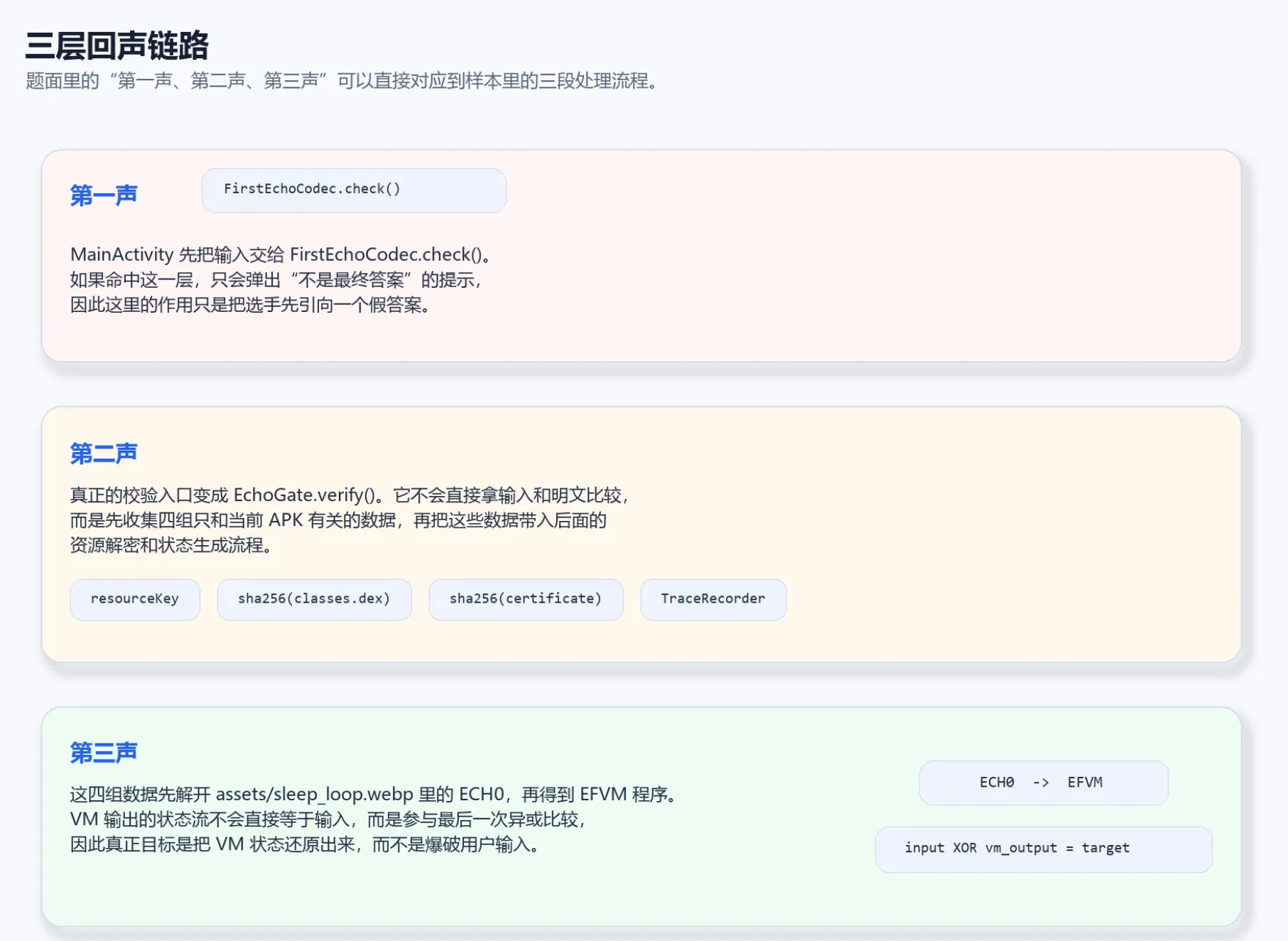
这张图把题面里的"三声回响"对应到了实际代码流程上:第一声停在 `FirstEchoCodec`,第二声开始收集 APK 绑定数据,第三声才通过 `ECH0` 和 `EFVM` 给出真实校验状态。后面的分析基本都沿着这条链展开。
继续分析
EchoGate 并不直接校验输入内容
`EchoGate.verify()` 的真正关键点在于:它并不是把输入直接和某个明文字符串比较,而是先拼出一组只和 APK 自身有关的数据,再用这些数据解开隐藏在资源文件里的 VM 程序。
整理这条链路后,可以把它概括成四个输入源:
-
`resourceKey(context)`
-
`classes.dex` 的 SHA-256
-
APK 签名证书的 SHA-256
-
`TraceRecorder.snapshot()` 返回的固定 6 字节
其中 `TraceRecorder` 非常短,内容就是一组常量:
```text
11 23 7a 42 51 66
```
本地从 APK 重新计算后,另外两项哈希分别为:
```text
classes.dex sha256
c82404bedd319ef962e9c114dcec9566265c140d621319f795c14a0a12d2df77
certificate sha256
1b62bcb48da1838d72a1ba812f0faa770f57998c5ae595a27f5741b12583e984
```
证书主题也能从签名块里直接解出来:
```text
CN=EchoFold,O=ISCC,C=CN
```
这说明题目没有把答案单独写死在 `dex` 或资源里,而是故意把 flag 和当前 APK 的代码、资源、签名一起绑定。
resourceKey 来自 styleable 数组
`resourceKey` 不是从普通字符串资源里直接读出来的,而是由 `R.styleable.EchoFoldPulse` 推导得到。该数组可以整理成一串连续整数:
```text
0x7f010000, 0x7f010001, ..., 0x7f01001f
```
`EchoGate` 用下面这段规则把它折成 24 字节:
```python
for i in range(24):
a = stylei % len(style)
b = style(i + 1) % len(style)
keyi = ((b - a) & 0xff) ^ (((a & 0x7f) << 1) & 0xff) ^ ((i * 13) & 0xff)
```
最后得到的 `resourceKey` 为:
```text
010e1f203d4a43547966979885b2abdcf1fecfd02d3a3304
```
到这里可以看出,这道题的第二层"回声"并不是普通 UI 提示,而是资源层本身:样本把真实校验数据拆到了 `styleable`、`classes.dex`、签名块和 `assets/` 里。
真正的数据藏在 `sleep_loop.webp` 的自定义 chunk 中
`assets/sleep_loop.webp` 的体积只有 282 字节,对一个图片资源来说明显过小。直接看文件头可以确认它属于标准 RIFF / WEBP 容器,但在正常块之外还多了一个自定义 chunk:
```text
RIFF .... WEBP .... ECH0 ...
```
本地解析这个文件时,`ECH0` chunk 的偏移和长度分别为:
```text
offset = 38
size = 236
```
这就是题面里"第二声很像线索"的落点:看起来是一张图片,实际上真正的数据被录进了回声文件里。
`ECH0` 的内容也不是明文,先要用下面的种子做流式异或解密:
```python
seed = sha256(b"fold-echo" + resource_key + dex_digest + cert_digest + trace)
plain = xor_stream(ech0_chunk, seed)
```
解密后的前四个字节是:
```text
45 46 56 4d
```
也就是 `EFVM`。说明 `ECH0` 里存的不是目标字符串,而是一段自定义 VM 的程序和目标密文。
第三声是 EFVM 和最终异或比较
`EFVM` 头部解出来之后,可以读到两个关键长度:
```text
prog_len = 192
out_len = 35
```
`out_len = 35` 非常重要,因为它刚好等于 `ISCC{}` 中大括号内容的长度。也就是说,VM 最终产出的字节流长度已经和 flag 主体对齐。
后续流程可以整理成三步:
-
用 `sha256(b"vm-seed" + resource_key + dex_digest + cert_digest + trace)` 初始化 8 个 32 位寄存器;
-
每 4 字节解释一条 VM 指令,依据首字节低 3 位选择不同的寄存器混合操作;
-
程序跑完后,从寄存器状态导出 `vm_output`。
真正决定解法的,不是每条指令的具体名字,而是最终比较方式。`EchoGate` 的末尾并不是:
```text
vm_output == input
```
而是:
```text
input_bytes XOR vm_output == encrypted_target
```
因此需要的不是爆破输入,而是把比较式直接改写成:
```text
input_bytes = encrypted_target XOR vm_output
```
到这里,题面里的"第三声才开始说真话"就完全落地了:只有把 `ECH0` 解出来、把 `EFVM` 跑完,真实 flag 才会出现。
!ECH0 到 flag 的还原过程
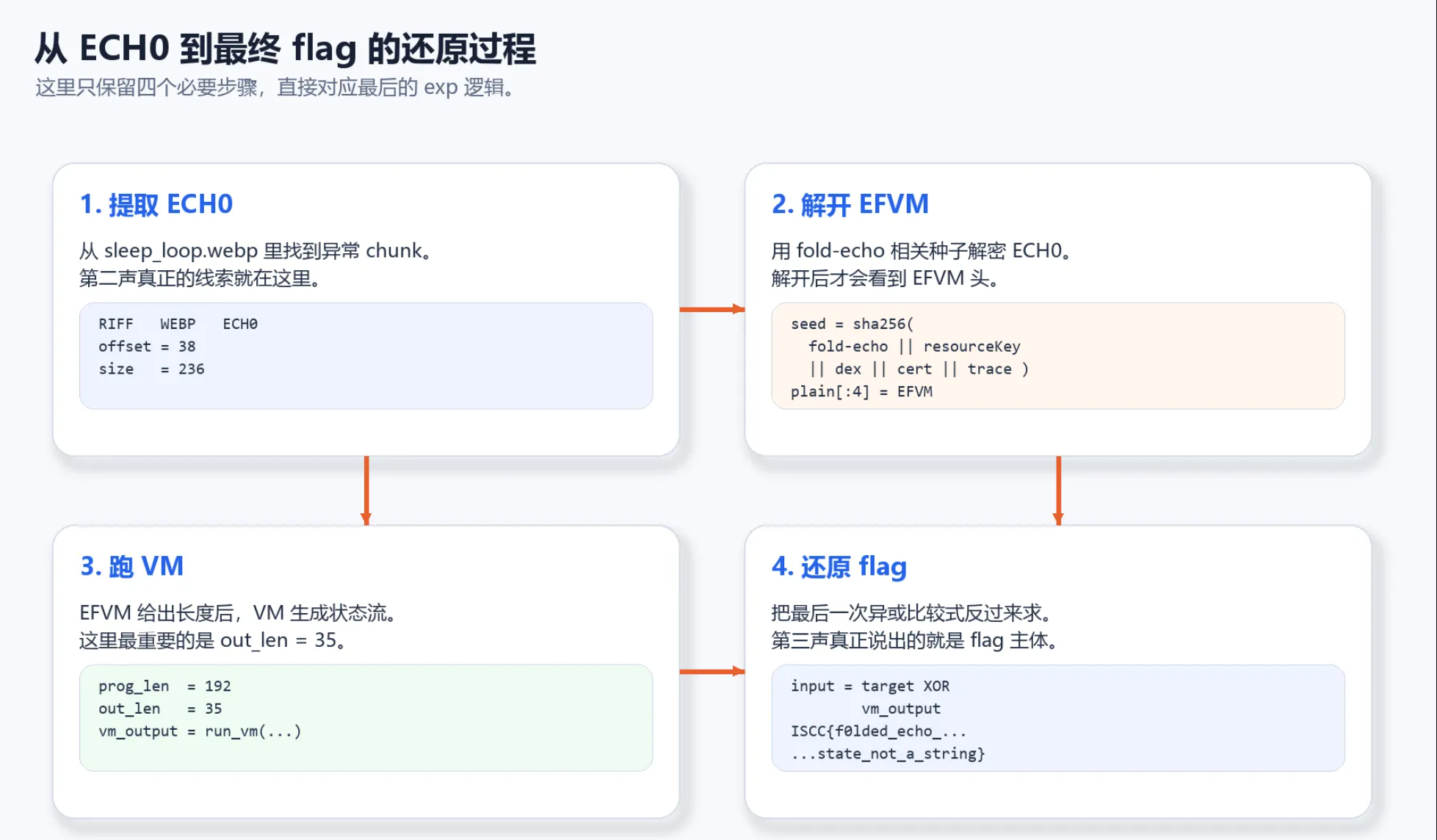
这张图把后半段求解过程压成了四步:先从 `sleep_loop.webp` 中提取 `ECH0`,再用 `fold-echo` 相关状态解出 `EFVM`,随后运行 VM,最后把末尾的异或比较式反过来求出真实输入。读者如果已经接受前面的推导,看到这里基本就能直接把它翻译成脚本。
构造最终解法
前面的分析可以直接压缩成一条自动化链路:
-
从 `EchoFold.apk` 读取 `classes.dex`、`META-INF/ECHOFOLD.RSA` 和 `assets/sleep_loop.webp`;
-
计算 `dex_digest`、`cert_digest`,并按 `EchoFoldPulse` 公式生成 `resource_key`;
-
从 `sleep_loop.webp` 中提取 `ECH0`,用 `fold-echo` 种子解出 `EFVM`;
-
执行 VM,得到 `vm_output`;
-
用 `encrypted_target XOR vm_output` 还原 flag 主体。
核心求解逻辑可以缩成下面几行:
```python
seed = sha256(b"fold-echo" + resource_key + dex_digest + cert_digest + trace)
plain = xor_stream(read_ech0_chunk(webp), seed)
program, encrypted_target = parse_efvm(plain)
vm_output = run_vm(program, resource_key, dex_digest, cert_digest, trace, len(encrypted_target))
flag_body = bytes(x ^ y for x, y in zip(encrypted_target, vm_output)).decode("ascii")
```
这段逻辑和前面的推导一一对应:`fold-echo` 负责解开第二层回声,`EFVM` 负责生成第三层状态,最后一次异或才把真正的 flag 主体还原出来。
EXP
前面的手工推导最后整理成了 `exp.py`。脚本会直接从 `EchoFold.apk` 中提取签名证书、资源块和 VM 程序,并输出最终答案。
运行方式如下:
```bash
python exp.py
```
关键输出只有一行:
```text
ISCC{f0lded_echo_is_a_state_not_a_string}
```
Flag
```text
ISCC{f0lded_echo_is_a_state_not_a_string}
```
完全脚本
import hashlib
import pathlib
import struct
import zipfile
APK_PATH = pathlib.Path(file).with_name("EchoFold.apk")
TRACE = bytes(0x11, 0x23, 0x7A, 0x42, 0x51, 0x66)
STYLE = 0x7F010000 + i for i in range(32)
FALLBACK_CERT_DIGEST = bytes.fromhex(
"1b62bcb48da1838d72a1ba812f0faa770f57998c5ae595a27f5741b12583e984"
)
def sha256(data: bytes) -> bytes:
return hashlib.sha256(data).digest()
def rotl32(value: int, shift: int) -> int:
value &= 0xFFFFFFFF
shift &= 31
return ((value << shift) | (value >> (32 - shift))) & 0xFFFFFFFF
def rotr32(value: int, shift: int) -> int:
value &= 0xFFFFFFFF
shift &= 31
return ((value >> shift) | (value << (32 - shift))) & 0xFFFFFFFF
def reverse_bytes32(value: int) -> int:
raw = (value & 0xFFFFFFFF).to_bytes(4, "little")
return int.from_bytes(raw::-1, "little")
def reverse_bits32(value: int) -> int:
value &= 0xFFFFFFFF
return int(f"{value:032b}"::-1, 2)
def build_resource_key() -> bytes:
key = bytearray()
for i in range(24):
a = STYLEi % len(STYLE)
b = STYLE(i + 1) % len(STYLE)
key.append(
(
((b - a) & 0xFF)
^ (((a & 0x7F) << 1) & 0xFF)
^ ((i * 13) & 0xFF)
)
& 0xFF
)
return bytes(key)
def load_cert_digest_from_apk(apk_path: pathlib.Path) -> bytes:
try:
from cryptography.hazmat.primitives.serialization import Encoding, pkcs7
except Exception:
return FALLBACK_CERT_DIGEST
with zipfile.ZipFile(apk_path, "r") as archive:
signature = archive.read("META-INF/ECHOFOLD.RSA")
certs = pkcs7.load_der_pkcs7_certificates(signature)
if not certs:
return FALLBACK_CERT_DIGEST
return sha256(certs0.public_bytes(Encoding.DER))
def read_ech0_chunk(webp: bytes) -> bytes:
if webp:4 != b"RIFF" or webp8:12 != b"WEBP":
raise ValueError("invalid webp container")
offset = 12
while offset + 8 <= len(webp):
chunk_type = webpoffset : offset + 4
chunk_size = struct.unpack_from("<I", webp, offset + 4)0
data_start = offset + 8
data_end = data_start + chunk_size
if data_end > len(webp):
raise ValueError("truncated chunk")
if chunk_type == b"ECH0":
return webpdata_start:data_end
offset = data_end + (chunk_size & 1)
raise ValueError("ECH0 chunk not found")
def xor_stream(data: bytes, seed: bytes) -> bytes:
out = bytearray()
counter = 0
while len(out) < len(data):
block = sha256(seed + counter.to_bytes(4, "little"))
base = len(out)
for i, byte in enumerate(block):
if base + i >= len(data):
break
out.append(database + i ^ byte)
counter += 1
return bytes(out)
def parse_efvm(blob: bytes) -> tuplebytes, bytes:
if blob:4 != b"EFVM":
raise ValueError("invalid EFVM magic")
prog_len = (blob5 << 8) | blob6
out_len = (blob7 << 8) | blob8
program = blob9 : 9 + prog_len
encrypted_target = blob9 + prog_len : 9 + prog_len + out_len
return program, encrypted_target
def initial_state(resource_key: bytes, dex_digest: bytes, cert_digest: bytes) -> listint:
seed = sha256(b"vm-seed" + resource_key + dex_digest + cert_digest + TRACE)
state = \[\]
for i in range(8):
value = int.from_bytes(seedi \* 4 : (i + 1) \* 4, "little")
value ^= (0x9E3779B9 * i) & 0xFFFFFFFF
state.append(value & 0xFFFFFFFF)
return state
def run_vm(
program: bytes,
resource_key: bytes,
dex_digest: bytes,
cert_digest: bytes,
out_len: int,
) -> bytes:
state = initial_state(resource_key, dex_digest, cert_digest)
i = 0
while i + 3 < len(program):
op = programi
ia = programi + 1 & 7
ib = programi + 2 & 7
ic = programi + 3 & 7
mix = (
resource_key(i // 4) % len(resource_key)
^ dex_digest(i // 2) % len(dex_digest)
^ cert_digest(i // 3) % len(cert_digest)
^ TRACE(i // 4) % len(TRACE)
) & 0xFF
kind = op & 7
if kind == 0:
temp = (stateib + mix + i) & 0xFFFFFFFF
temp = rotl32(temp, (ic + mix) & 31)
stateia = (temp ^ stateia) & 0xFFFFFFFF
elif kind == 1:
temp = (stateia + stateib + ((mix << 1) & 0xFFFFFFFF) + ic) & 0xFFFFFFFF
stateia = rotl32(temp, (ib + ic + i) & 31)
elif kind == 2:
temp = reverse_bytes32(stateic)
temp = (temp ^ stateib) & 0xFFFFFFFF
temp = (temp + mix) & 0xFFFFFFFF
stateia = (stateia ^ temp) & 0xFFFFFFFF
elif kind == 3:
old = stateia
stateia = (stateib + mix) & 0xFFFFFFFF
temp = rotr32((stateic + i) & 0xFFFFFFFF, mix & 31)
stateib = (temp ^ old) & 0xFFFFFFFF
elif kind == 4:
temp = rotr32((mix ^ stateib ^ i) & 0xFFFFFFFF, (ic + ia + 1) & 31)
stateia = (stateia + temp) & 0xFFFFFFFF
elif kind == 5:
temp = (stateib + stateic + mix) & 0xFFFFFFFF
temp = rotl32(temp, (i + ia + ib) & 31)
stateia = (temp ^ stateia) & 0xFFFFFFFF
elif kind == 6:
temp = (mix ^ stateia ^ stateib) & 0xFFFFFFFF
temp = (temp + reverse_bits32((stateic + i) & 0xFFFFFFFF)) & 0xFFFFFFFF
stateia = temp
else:
temp = (mix ^ stateic ^ stateib) & 0xFFFFFFFF
temp = (temp + i) & 0xFFFFFFFF
stateia = (stateia + temp) & 0xFFFFFFFF
i += 4
out = bytearray()
for j in range(out_len):
value = statej \& 7 ^ rotl32(state(j + 3) \& 7, j & 31)
value ^= resource_keyj % len(resource_key)
value ^= dex_digestj % len(dex_digest)
value ^= cert_digestj % len(cert_digest)
value ^= TRACEj % len(TRACE)
out.append(value & 0xFF)
return bytes(out)
def solve(apk_path: pathlib.Path) -> str:
with zipfile.ZipFile(apk_path, "r") as archive:
classes_dex = archive.read("classes.dex")
webp = archive.read("assets/sleep_loop.webp")
resource_key = build_resource_key()
dex_digest = sha256(classes_dex)
cert_digest = load_cert_digest_from_apk(apk_path)
echo_seed = sha256(b"fold-echo" + resource_key + dex_digest + cert_digest + TRACE)
ech0_plain = xor_stream(read_ech0_chunk(webp), echo_seed)
program, encrypted_target = parse_efvm(ech0_plain)
vm_output = run_vm(
program,
resource_key,
dex_digest,
cert_digest,
len(encrypted_target),
)
flag_body = bytes(x ^ y for x, y in zip(encrypted_target, vm_output)).decode("ascii")
return f"ISCC{{{flag_body}}}"
def main() -> None:
print(solve(APK_PATH))
if name == "main":
main()
小结
这题最容易浪费时间的地方有两个:一是被第一眼看到的假 flag 误导,二是把 `sleep_loop.webp` 当成普通资源文件略过去。真正的突破点其实很明确:先承认第一层是诱饵,再顺着 `EchoGate -> ECH0 -> EFVM` 这条链把校验状态还原出来。
如果从头再做一次,优先顺序应该是:先确认 `FirstEchoCodec` 只是诱饵,再检查 `assets/` 里的异常容器,最后把 VM 输出和末尾的异或比较关系连起来。只要走通这三步,就不需要任何爆破或动态 Hook。
Flag Shop
一、题目概述
拿到题目附件 `FlagShop.apk` 后,题面给出重要线索:所有 fakeflag 的明文均为 `ISCC{fakeflagfake}`。这说明 APK 内部存储了多个商品的加密数据,但明文是一致的,真正 flag 的明文与 fakeflag 不同,需要从 so 层的加密/校验逻辑入手还原。
核心解题路线:
-
反编译 APK 提取 DEX,梳理商品列表与 native 调用关系
-
逆向 `libflagshop.so`,恢复管理员登录凭据
-
编写 Unicorn 本地仿真脚本,用 fakeflag 样本打通 oracle
-
将 oracle 切换到 realflag,恢复真实 flag
二、DEX 层信息提取
使用 jadx 反编译 APK,在 DEX 中找到商品初始化代码。程序定义了 4 个商品:
| 商品 ID | 说明 |
|---------|------|
| `fakeflag1` | 虚假 flag 商品 1 |
| `fakeflag2` | 虚假 flag 商品 2 |
| `fakeflag3` | 虚假 flag 商品 3 |
| `realflag` | 真实 flag 商品 |
每个商品关联的并不是明文 flag,而是一段十六进制密文 `encryptedHex`。这说明 flag 不是直接存储的,而是经过某种 native 加密处理后的结果。
提取到的四组密文数据如下。
fakeflag1 对应密文:
```
46534850840912118da77c2d7f480b5a3497e1c9cfd5fb6a15ffc5a68067f7bbd6b07028b9d52e53f1ea68d460c840a407db326f5e986d7e1305f8df01796fc56e188068355aff017715c6673d15e5f3af30a9e818e229d8
```
fakeflag2 对应密文:
```
46534850840912112ba9a049c2cc27ba76c2fd1340624573a1133272a504c589b360fac0d187c7db0346ad02dc4e38638e5f336155f28b64d71ae1f61769c6c91c3130d83d675755ee56f0d5c4bd74a07e4c794222cef2f2
```
fakeflag3 对应密文:
```
465348508409121105764efa14c617d84804c0e4f4e669ea8f5abd029b6b5c7a0ded5b1cdd0abb7f1cd9b765fe9e9009bd0e8e3f4354746c5e20f6d946ff2ff2fadcefcab00bb06984633a4ca24a690368951c43d8a507c5
```
realflag 对应密文:
```
4653485084083011788fb5d735cfa35810b48a3433ced888c02965457ad21cf80e4936cc8a536fee26b3ffc2a64981a878511f0d3ab96cdd05879fac83f005f9b5e311fa07d299b0d0580b4611afd6c8a4db205c1f278134
```
继续在 DEX 中追踪调用链,定位到 native 方法声明:
```
NativeBridge.encryptFlag(String, String, String, String): String
```
通过向上追溯调用点,确定四个参数的语义分别为:
```java
encryptFlag(itemId, flagInput, username, password)
```
这个参数顺序在后续 Unicorn 仿真中至关重要,传错顺序会导致整个 oracle 走失败路径。
三、SO 层逆向分析
核心逻辑位于 `libflagshop.so`(arm64-v8a 架构)。使用 IDA Pro 加载后,定位到以下关键函数:
| 函数 | 功能 |
|------|------|
| `adminLogin` | 管理员账号密码校验 |
| `encryptFlag` | 商品 flag 的加密/校验入口 |
| `helper_copy_jstring` | JNI 字符串转 std::string |
| `helper_compare_or_transform` | 字符串比较 / 变换辅助函数 |
【图3:IDA 中关键函数列表截图】
可以得出结论:
-
管理员身份认证完全在 so 层完成,DEX 层无任何明文凭据
-
flag 的加密与校验逻辑同样在 so 层,无法直接从 DEX 恢复
-
必须通过 native 仿真获取真实 flag
四、管理员凭据还原
4.1 用户名
在 `.rodata` 段搜索与管理员相关的字符串,结合 `adminLogin` 函数中字符串比较指令的交叉引用,确认用户名为:
```
admin
```
4.2 密码恢复
密码的恢复过程相对复杂。密码不是在 rodata 中直接明文存储的,而是在 so 初始化阶段由密码生成函数运行时写入 `.bss` 段。
对密码初始化逻辑进行局部仿真,在地址 `0xf6f67` 附近追踪 `.bss` 段的写入操作。经过单步跟踪,最终在内存中恢复出完整密码:
```
FlagShopAdmin2026
```
这里有一个非常容易踩的坑:密码末尾的 `6` 容易在逆向时被忽略。早期分析时容易误判为 `FlagShopAdmin202`,但少一个字符会导致 `encryptFlag` 内部校验失败,直接返回空字符串,不会进入真正的加密流程。
验证方式:分别用 `FlagShopAdmin202` 和 `FlagShopAdmin2026` 走 `encryptFlag`------
-
前者:函数命中失败分支,没有任何有效输出
-
后者:函数进入真实处理路径
五、Unicorn 本地仿真 Oracle 设计
为了让 `encryptFlag` 在脱离 Android 环境的情况下复现运行,采用 Unicorn Engine 对 `libflagshop.so` 进行 arm64 指令级仿真。
5.1 内存布局
-
**映射 PT_LOAD 段**:遍历 ELF 的 LOAD 段,按虚拟地址映射到 Unicorn 内存空间,写入段数据并设置对应的 r/w/x 权限
-
**处理重定位表**:遍历 `.rela.dyn` 和 `.rela.plt`,对类型为 `R_AARCH64_RELATIVE`(1027)的重定位项写入 `base + addend` 的值
-
**分配栈空间**:在 `0x2000000` 分配栈内存,设置 SP 和 FP 寄存器
-
**构造 JNIEnv**:在 `0x3000000` 区域构造一个假的 JNIEnv 和虚函数表 vtable
5.2 函数桩 (Stub)
对于 so 依赖的外部函数,在 `0x3100000` 区域为每个导入符号分配一个桩地址,桩内容为 `ret` 指令。在每个桩被调用时,通过 hook 拦截并根据函数语义进行模拟:
| 函数 | 处理方式 |
|------|----------|
| `strlen` / `strcmp` / `strncmp` | 读取地址处 C 字符串,执行对应操作 |
| `memcmp` / `memcpy` / `memmove` / `memset` | 读取/写入原始内存字节 |
| `malloc` / `realloc` / `free` | 在仿真堆上分配/释放内存 |
| `__system_property_get` | 模拟 Android 系统属性读取(反 frida 检测返回 "1") |
| `getpid` | 返回固定值 1234 |
| `syscall` | 返回 0 |
| `abort` / `__stack_chk_fail` | 抛出异常终止仿真 |
5.3 JNI 桥接
在 vtable 中 `+0x538` 偏移处(对应 `NewStringUTF`)替换为一个自定义桩地址。当 so 调用 `NewStringUTF` 返回 Java string 时,hook 拦截并记录返回的字符串内容,同时将 PC 直接返回调用者。
在地址 `0x5007c` 处(对应 `helper_copy_jstring` 的核心逻辑),检测到对 Java 字符串的拷贝操作,将 Java 字符串按 `std::string` 的 SSO(Small String Optimization)布局写入目标地址,绕过对 JNI 实际对象的依赖。
六、Fakeflag 基准验证
题目已明确告知 fakeflag 明文为:
```
ISCC{fakeflagfake}
```
使用以下参数调用 `encryptFlag` 入口(地址 `0x517a8`):
| 参数 | 值 |
|------|-----|
| itemId (X2) | `fakeflag1` |
| flagInput (X3) | `ISCC{fakeflagfake}` |
| username (X4) | `admin` |
| password (X5) | `FlagShopAdmin2026` |
验证结果
-
**错误密码**(少一个 `6`):仿真结束,`encryptFlag` 走失败路径,返回值为空
-
**正确密码**(`FlagShopAdmin2026`):so 进入完整的处理路径,函数正常返回,且 `NewStringUTF` 被正确调用
这证实了:
-
管理员凭据完全正确
-
参数顺序 `(itemId, flagInput, username, password)` 完全正确
-
JNI 桥接和函数桩工作正常
-
本地 oracle 状态可靠,可以迁移到 realflag
七、Realflag 恢复
在 oracle 验证通过后,将仿真参数中的 itemId 切换为 `realflag`,flagInput 保持为真实 flag 的待求值。核心思路是:
-
将 `encryptFlag` 参数设为 `("realflag", X, "admin", "FlagShopAdmin2026")`
-
程序内部会用 `X` 与 so 中的真实 flag 进行比较
-
通过 hook `strcmp` / `strncmp` 桩函数,在每次比较时 dump 两个比较对象
-
从比较日志中提取 so 内部使用的真实 flag 明文
在 trace 日志中,`strcmp` 被调用时可以看到如下比较操作:
```
('call', 'strcmp', ..., 'ISCC{7H15_1$_r431_f146_4nd_17_h45n\'7_501d_0u7?!}', 'ISCC{...}')
```
由此恢复出真实 flag:
```
ISCC{7H15_1$_r431_f146_4nd_17_h45n'7_501d_0u7?!}
```
八、题目技术要点总结
本题的难点与关键点:
-
**虚假信息干扰**:题面给出的 3 个 fakeflag 对应的 `encryptedHex` 各不相同,但明文一致,容易误导解题者直接在 DEX 层搜索字符串
-
**逻辑下沉到 native**:管理员认证和 flag 校验都在 `libflagshop.so` 中完成,DEX 只是一个壳
-
**密码边界问题**:管理员密码末尾的 `6` 极易在逆向时遗漏,且没有直接报错提示,只会让所有后续仿真默默失败
-
**本地仿真工程化**:需要处理 ELF 重定位、构造假 JNIEnv、stub 导入函数、模拟 `std::string` SSO 布局等一系列工程问题才能打通 oracle
Exp
```python
import glob
import struct
from elftools.elf.elffile import ELFFile
from unicorn import Uc, UcError, UC_ARCH_ARM64, UC_MODE_ARM, UC_PROT_READ, UC_PROT_WRITE, UC_PROT_EXEC, UC_PROT_ALL, UC_HOOK_CODE
from unicorn.arm64_const import *
path = glob.glob(r'C:/Users/*/Downloads/FlagShop_extracted/lib/arm64-v8a/libflagshop.so')0
PAGE = 0x1000
def align_down(x):
return x & ~(PAGE - 1)
def align_up(x):
return (x + PAGE - 1) & ~(PAGE - 1)
def read_cstr(mu, addr, limit=0x1000):
out = bytearray()
for i in range(limit):
b = mu.mem_read(addr + i, 1)0
if b == 0:
break
out.append(b)
return out.decode('utf-8', 'replace')
def write_cstr(mu, addr, s):
mu.mem_write(addr, s.encode() + b'\x00')
with open(path, 'rb') as f:
elf = ELFFile(f)
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
for seg in elf.iter_segments():
if seg'p_type' != 'PT_LOAD':
continue
vaddr = seg'p_vaddr'
memsz = seg'p_memsz'
filesz = seg'p_filesz'
start = align_down(vaddr)
end = align_up(vaddr + memsz)
perms = 0
flags = seg'p_flags'
if flags & 4:
perms |= UC_PROT_READ
if flags & 2:
perms |= UC_PROT_WRITE
if flags & 1:
perms |= UC_PROT_EXEC
mu.mem_map(start, end - start, perms)
mu.mem_write(vaddr, seg.data())
if memsz > filesz:
mu.mem_write(vaddr + filesz, b'\x00' * (memsz - filesz))
for secname in ('.rela.dyn', '.rela.plt'):
sec = elf.get_section_by_name(secname)
if not sec:
continue
symtab = elf.get_section(sec'sh_link') if sec'sh_link' else None
for rel in sec.iter_relocations():
rtype = rel'r_info_type'
off = rel'r_offset'
addend = rel'r_addend' if rel.is_RELA() else 0
if rtype == 1027:
mu.mem_write(off, struct.pack('<q', addend))
stack = 0x2000000
mu.mem_map(stack, 0x200000, UC_PROT_ALL)
sp = stack + 0x1f0000
mu.reg_write(UC_ARM64_REG_SP, sp)
mu.reg_write(UC_ARM64_REG_X29, sp)
env = 0x3000000
vtbl = 0x3001000
mu.mem_map(0x3000000, 0x30000, UC_PROT_ALL)
mu.mem_write(env, struct.pack('<Q', vtbl))
stub_base = 0x3100000
mu.mem_map(stub_base, 0x10000, UC_PROT_ALL)
ret_stub = b'\xc0\x03\x5f\xd6'
stub_for = {}
stub_i = 0
plt = elf.get_section_by_name('.rela.plt')
if plt:
symtab = elf.get_section(plt'sh_link')
for rel in plt.iter_relocations():
sym = symtab.get_symbol(rel'r_info_sym').name if rel'r_info_sym' else ''
if sym not in stub_for:
stub_forsym = stub_base + stub_i * 0x100
mu.mem_write(stub_forsym, ret_stub)
stub_i += 1
mu.mem_write(rel'r_offset', struct.pack('<Q', stub_forsym))
newstring_stub = 0x3200000
mu.mem_map(newstring_stub, 0x1000, UC_PROT_ALL)
mu.mem_write(newstring_stub, ret_stub)
mu.mem_write(vtbl + 0x538, struct.pack('<Q', newstring_stub))
data = 0x3300000
mu.mem_map(data, 0x40000, UC_PROT_ALL)
def cstr(addr, s):
write_cstr(mu, addr, s)
return addr
item = cstr(data + 0x000, 'realflag')
flag = cstr(data + 0x100, 'ISCC{fakeflagfake}')
user = cstr(data + 0x200, 'admin')
pw = cstr(data + 0x300, 'FlagShopAdmin2026')
heap = 0x3400000
mu.mem_map(heap, 0x40000, UC_PROT_ALL)
heap_next = heap
def alloc(size, align=0x10):
cur = (heap_next0 + align - 1) & ~(align - 1)
heap_next0 = cur + size
return cur
def write_std_string(addr, s):
b = s.encode()
mu.mem_write(addr, b'\x00' * 0x20)
if len(b) <= 22:
mu.mem_write(addr, bytes(len(b) \<\< 1) + b + b'\x00' * (23 - len(b)))
return
ptr = alloc(len(b) + 1)
mu.mem_write(ptr, b + b'\x00')
mu.mem_write(addr, struct.pack('<Q', 1))
mu.mem_write(addr + 8, struct.pack('<Q', len(b)))
mu.mem_write(addr + 16, struct.pack('<Q', ptr))
ret_strings = \[\]
trace = \[\]
def decode_std_string(addr):
b0 = mu.mem_read(addr, 1)0
if (b0 & 1) == 0:
n = b0 >> 1
raw = bytes(mu.mem_read(addr + 1, n))
return raw.decode('utf-8', 'replace')
n = struct.unpack('<Q', bytes(mu.mem_read(addr + 8, 8)))0
p = struct.unpack('<Q', bytes(mu.mem_read(addr + 16, 8)))0
raw = bytes(mu.mem_read(p, min(n, 0x200)))
return raw.decode('utf-8', 'replace')
def emulate_symbol(sym):
x0 = mu.reg_read(UC_ARM64_REG_X0)
x1 = mu.reg_read(UC_ARM64_REG_X1)
x2 = mu.reg_read(UC_ARM64_REG_X2)
lr = mu.reg_read(UC_ARM64_REG_LR)
if sym == 'strlen':
trace.append(('call', sym, hex(lr), hex(x0), read_cstr(mu, x0):120))
mu.reg_write(UC_ARM64_REG_X0, len(read_cstr(mu, x0).encode()))
elif sym == 'strcmp':
a = read_cstr(mu, x0)
b = read_cstr(mu, x1)
trace.append(('call', sym, hex(lr), a:80, b:80))
mu.reg_write(UC_ARM64_REG_X0, (a > b) - (a < b))
elif sym == 'strncmp':
a = read_cstr(mu, x0):x2
b = read_cstr(mu, x1):x2
trace.append(('call', sym, hex(lr), a:80, b:80, x2))
mu.reg_write(UC_ARM64_REG_X0, (a > b) - (a < b))
elif sym == 'memcmp':
a = bytes(mu.mem_read(x0, x2))
b = bytes(mu.mem_read(x1, x2))
trace.append(('call', sym, hex(lr), x2, a:64.hex(), b:64.hex()))
mu.reg_write(UC_ARM64_REG_X0, (a > b) - (a < b))
elif sym in ('memcpy', '__memcpy_chk', 'memmove'):
trace.append(('call', sym, hex(lr), hex(x0), hex(x1), x2))
mu.mem_write(x0, bytes(mu.mem_read(x1, x2)))
mu.reg_write(UC_ARM64_REG_X0, x0)
elif sym == 'memset':
mu.mem_write(x0, bytes(x1 \& 0xff) * x2)
mu.reg_write(UC_ARM64_REG_X0, x0)
elif sym == 'malloc':
mu.reg_write(UC_ARM64_REG_X0, alloc(max(x0, 1)))
elif sym == 'realloc':
p = alloc(max(x1, 1))
if x0:
mu.mem_write(p, bytes(mu.mem_read(x0, x1)))
mu.reg_write(UC_ARM64_REG_X0, p)
elif sym == 'free':
mu.reg_write(UC_ARM64_REG_X0, 0)
elif sym == '__system_property_get':
prop = read_cstr(mu, x0)
val = '1' if 'frida' in prop.lower() else ''
write_cstr(mu, x1, val)
mu.reg_write(UC_ARM64_REG_X0, len(val))
elif sym == 'strstr':
hay = read_cstr(mu, x0)
nee = read_cstr(mu, x1)
idx = hay.find(nee)
mu.reg_write(UC_ARM64_REG_X0, 0 if idx < 0 else x0 + idx)
elif sym == 'getpid':
mu.reg_write(UC_ARM64_REG_X0, 1234)
elif sym == 'syscall':
mu.reg_write(UC_ARM64_REG_X0, 0)
elif sym in ('abort', '__stack_chk_fail'):
raise RuntimeError(sym)
else:
mu.reg_write(UC_ARM64_REG_X0, 0)
def hook_code(mu, addr, size, user_data):
if addr == 0x5007c:
src = mu.reg_read(UC_ARM64_REG_X1)
target = mu.reg_read(UC_ARM64_REG_X8)
s = read_cstr(mu, src)
write_std_string(target, s)
trace.append(('copy', hex(target), s, bytes(mu.mem_read(target, 24)).hex()))
mu.reg_write(UC_ARM64_REG_PC, mu.reg_read(UC_ARM64_REG_LR))
return
if addr == newstring_stub:
s = read_cstr(mu, mu.reg_read(UC_ARM64_REG_X1))
ret_strings.append(s)
trace.append(('retstr', hex(mu.reg_read(UC_ARM64_REG_LR)), s:120))
mu.reg_write(UC_ARM64_REG_X0, mu.reg_read(UC_ARM64_REG_X1))
mu.reg_write(UC_ARM64_REG_PC, mu.reg_read(UC_ARM64_REG_LR))
return
if addr in (0x52280, 0x522b4, 0x522c8, 0x522f4, 0x52384, 0x523b8, 0x523cc, 0x523f8, 0x52464, 0x52498, 0x524ac, 0x524d8, 0x53024, 0x53058, 0x5306c, 0x53098, 0x53154, 0x53188, 0x5319c, 0x531c8, 0x5377c, 0x537a8, 0x537bc):
base = mu.reg_read(UC_ARM64_REG_X8)
target = struct.unpack('<Q', bytes(mu.mem_read(base, 8)))0 if base else 0
trace.append(('indirect', hex(addr), hex(base), hex(target)))
for sym, stub in stub_for.items():
if addr == stub:
trace.append(('ext', sym))
emulate_symbol(sym)
mu.reg_write(UC_ARM64_REG_PC, mu.reg_read(UC_ARM64_REG_LR))
return
if addr == 0x6e1ac:
trace.append(('skip', hex(addr)))
mu.reg_write(UC_ARM64_REG_PC, mu.reg_read(UC_ARM64_REG_LR))
return
mu.hook_add(UC_HOOK_CODE, hook_code)
mu.reg_write(UC_ARM64_REG_X0, env)
mu.reg_write(UC_ARM64_REG_X1, 0x1234)
mu.reg_write(UC_ARM64_REG_X2, item)
mu.reg_write(UC_ARM64_REG_X3, flag)
mu.reg_write(UC_ARM64_REG_X4, user)
mu.reg_write(UC_ARM64_REG_X5, pw)
try:
mu.emu_start(0x517a8, 0x56000, count=10000000)
print('EMU_OK')
except Exception as e:
print('EMUERR', type(e).name, e)
print('PC', hex(mu.reg_read(UC_ARM64_REG_PC)))
print('LR', hex(mu.reg_read(UC_ARM64_REG_LR)))
print('RETCOUNT', len(ret_strings))
for i, s in enumerate(ret_strings:20):
print('RET', i, repr(s:200))
print('TRACECOUNT', len(trace))
for t in trace:
print('TRACE', t)
```
最终 Flag
```
ISCC{7H15_1$_r431_f146_4nd_17_h45n'7_501d_0u7?!}
```