「H100 是不是突然从所有平台上消失了?」
X 用户 Jino Rohit 发出的这个疑问在社交媒体上迅速扩散,引发了 AI 圈的广泛共鸣。就连曾参与创立 OpenAI、被无数开发者奉为学习标杆的 Andrej Karpathy 也忍不住发声,感叹 H100 的获取难度正在成为人们参与 AI 研究和学习的真实瓶颈。
所以,到底发生了什么?为什么所有人都感觉 H100 的市场供应明显下降了?
事实上,这并不是一时的市场波动,也不是某个平台的运营问题。这是一场正在悄然改变 AI 产业格局的算力危机。而它的核心,远比「芯片不够用」复杂得多。
消失的 H100
如果你在 2026 年初尝试从 AWS、Google Cloud 或 Azure 的标准渠道租用 H100,大概率会碰壁。
SemiAnalysis 在今年 4 月发布的报告用一句话类比了这种荒诞:「找 GPU 算力就像在最后一班飞机起飞前订机票 ------ 价格奇高,座位几乎没有。」
数字可以说明问题的严重程度。
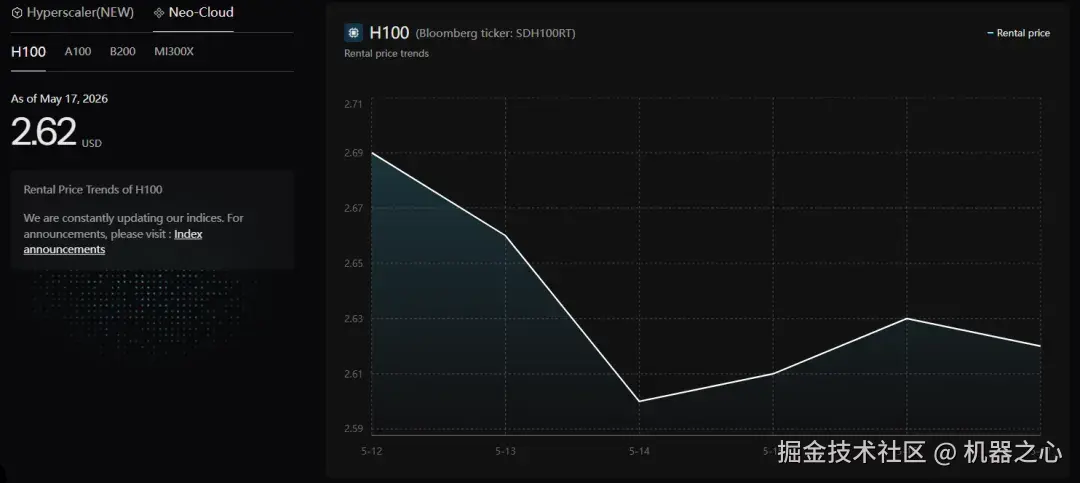
H100 SXM5 的一年期租约合同价格,从 2025 年 10 月的 1.70 美元/小时/GPU 低点,一路飙升至 2026 年 3 月的 2.35 美元/小时/GPU,涨幅接近 40%。
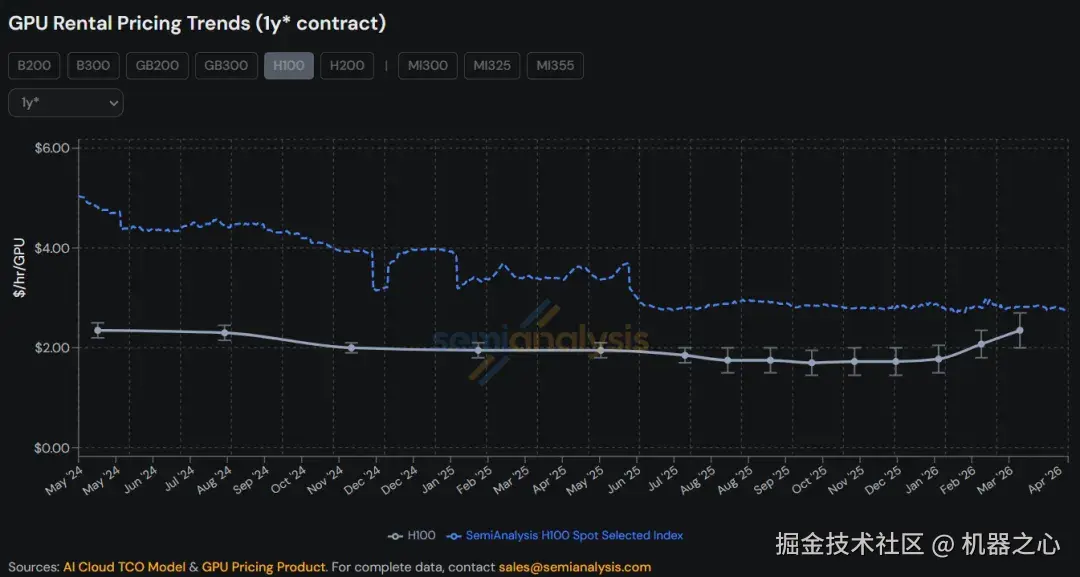
semianalysis.com/gpu-pricing...
与此同时,SiliconData 的 H100 超大规模指数在 4 月底进一步跳涨至 7.49 美元。这是一个反直觉的现象 ------ 明明更强大的下一代 Blackwell 架构芯片已经开始出货,上一代 H100 的价格却不降反升。
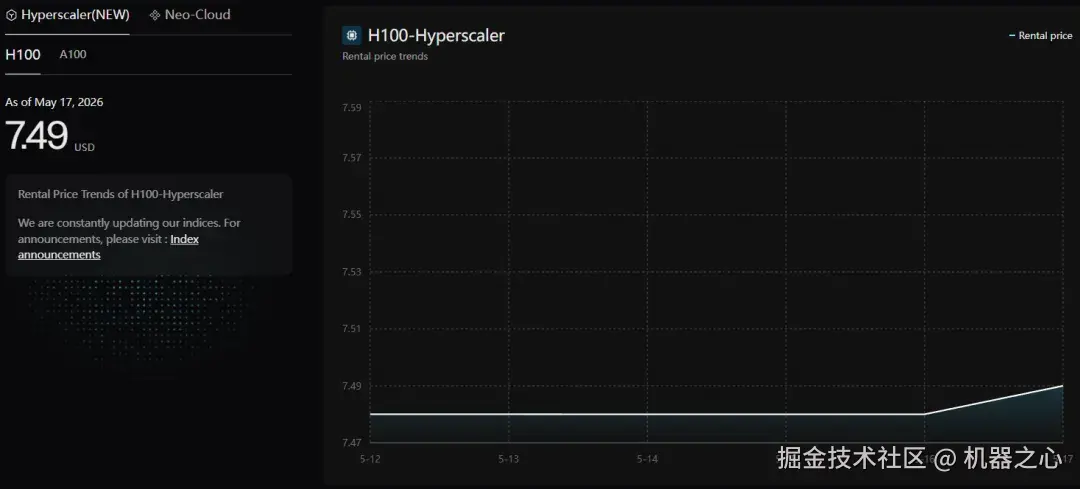
www.silicondata.com/products/si...
在直接采购渠道,情况更为严峻。来自 Spheron 的数据显示,H100 SXM5 的交货周期目前普遍在 36 至 52 周之间;H200 更长,超过 40 周;而最新的 B200 的可用产能已被预订至 2027 年下半年。一家 AI 研究机构描述了切身遭遇:原本预算 4 万美元的 Q2 训练任务,在找不到预留算力的情况下,转向按需定价后成本飙升至 8 至 12 万美元 ------ 如果还能找到算力的话。
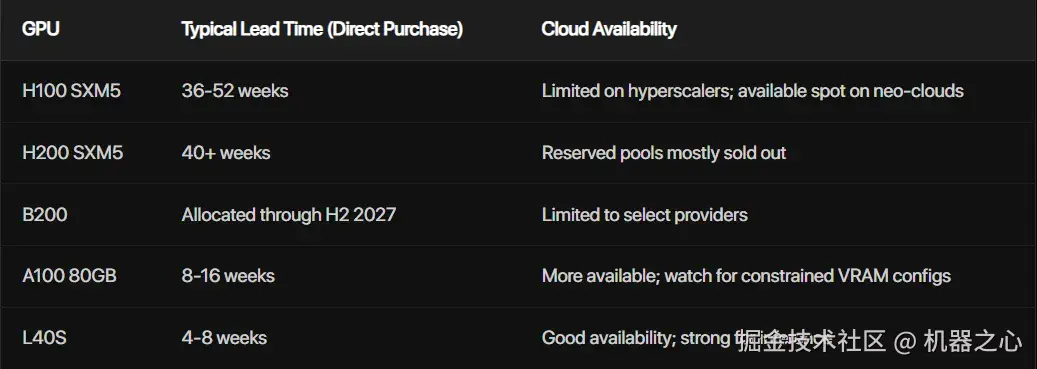
www.spheron.network/blog/gpu-sh...
数据中心层面同样告急。一份提交给美国证券交易委员会的文件显示,截至 2026 年初,北美数据中心的空置率已降至历史最低的 1.6%,全球 AI 相关支出预计在 2026 年达到 2.52 万亿美元,同比增长 44%。市场上所有计划在 2026 年 8 至 9 月前上线的算力,据报道已被全部预订一空。

那么,是谁在推高算力需求?
很显然,文章开始处的那条推文与 Karpathy 的感叹并非无的放矢,这也让 AI 的门槛从能力门槛变成了资源门槛。正如 X 网友 Rahul Chavan 调侃的那样:「英伟达悄然成为了整个行业的瓶颈」。

具体来看,将 H100 从市场上「抽走」的,是一批体量远超个人研究者的超级买家。
微软、谷歌、Meta、亚马逊在 2025 年就已相继签下数十亿美元的 Blackwell GPU(GB200、B200)前置订单,将英伟达 2026 年全年乃至 2027 年初的可用产能基本锁定。这种提前布局的能力,直接将中型企业和学术研究者挤出了正规采购渠道。
正如行业分析所指出的,这里存在一个显著的不对称性:超大规模云厂商和资金雄厚的前沿实验室,在危机真正爆发前的一两年里就通过远期合同锁定了供应。而其他所有人,只能竞争那些未被预留的现货和按需算力。
这批算力需求的规模令人震惊。OpenAI 承诺为下一代 AI 基础设施部署至少 10 吉瓦的英伟达系统;Anthropic 计划采用 1 吉瓦的 Grace Blackwell 计算容量;摩根士丹利预测,仅英伟达平台的 AI 服务器机柜需求,就将从 2025 年的约 2.8 万台跃升至 2026 年的至少 6-7 万台,规模翻倍有余。
超大规模算力的竞争,甚至已经从商业层面上升到地缘政治层面,「算力」也似乎正在成为国家竞争的战略资源。
真正的瓶颈:不是 GPU,是内存和封装
理解这场危机,有一个关键认知需要厘清:短缺的核心不是 GPU 芯片本身,而是围绕芯片的内存与封装工艺。
Spheron 的分析一语中的:这是「一个有两个根本原因的结构性问题:台积电的 CoWoS 封装产能已被全部占满,SK 海力士的 HBM 产量无法跟上需求。」
HBM 的生产困境
高带宽内存(HBM)是现代 AI 芯片的核心组件,H100 使用 HBM3,H200 和整个 Blackwell 系列则需要更先进的 HBM3e。全球有能力生产 HBM 的厂商只有三家:SK 海力士、三星和美光,而它们同时要为英伟达、AMD 和英特尔供货,同时又在争夺相同的 HBM 分配量。
HBM3e 的生产比 HBM2e 更为苛刻 ------ 更高的芯片堆叠数量和更严格的公差意味着每片晶圆的良率更低。随着 Blackwell 架构加速量产,对 HBM3e 的需求持续攀升,直接加剧了本已捉襟见肘的 H100/H200 供应。
TrendForce 的研究报告指出,从 2023 年到 2026 年,全球 HBM 总需求增长了约 3.8 倍(从 1.5BGB 到 5.7BGB)。三家供应商都有各自的扩产计划,但新工厂从建设到量产,需要不少时间。
CoWoS 封装:另一道卡脖子工序
台积电的 CoWoS(晶圆上晶片上基板)技术是将 HBM 芯片键合到 GPU 基板的必要工艺。目前,这一封装产能已被预订至至少 2027 年中期 ------ 事实上,部分订单的可见度已延伸至 2028 年。

www.digitimes.com.tw/tech/dt/n/s...
TrendForce 预计台积电 CoWoS 产能将在 2025 年达到每月约 7.5 万片晶圆,并在 2026 年底达到约 12 至 13 万片,但增长速度仍跟不上需求。
CoWoS 是 GPU 产量的瓶颈。当封装产能扩充时,GPU 出货量才能真正提升;而在此之前,即便芯片制造工艺一切正常,也无法解决供应不足的问题。
HBM 短缺的连锁效应
HBM 的供应紧张不仅仅让数据中心 GPU 变得稀缺,还产生了多重连锁反应:
其一,消费级 GPU 生产被大幅削减。据供应链媒体 Benchlife 等来源的报道,英伟达在 2026 年上半年将 RTX 5000 系列(Blackwell 架构)产量削减了 30 至 40%,直接原因是 GDDR7 内存供应紧张,以及公司战略向数据中心 SKU 倾斜。消费级 GPU 市场如今同样干涸。
其二,HBM 的紧缺推高了 GPU 的整体租用成本,即使是手头有库存的云服务提供商,也面临更高的硬件采购成本,并将其传导至租价。这解释了为何 H100 的现货价格没有因为 Blackwell 的出现而崩塌。
其三,AI 对内存的吞噬已经蔓延到了整个芯片产业链。正如机器之心此前报道的,HBM 紧缺的压力正在向普通 DRAM、LPDDR 甚至 CPU 市场传导。参阅《离谱:256G 内存比 RTX5090 还贵,你要为 AI 买单吗?》
谁在受伤?危机对 AI 生态的冲击
算力危机的影响并不均匀分布,它沿着资源能力的梯度,将 AI 生态的参与者划分成了截然不同的处境。
中小型团队:被迫重新规划
按照 Spheron 的分析,算力危机对 AI 团队产生了三个层面的冲击:
-
训练延误:规划在 2026 年第二季度开展训练的团队,发现超大云平台的预留算力已被现有客户锁定,按需定价的成本高出 2 至 3 倍,且随时可能无法获得算力。
-
推理成本激增:H100 按需价格的上涨让部分面向用户的 API 服务面临单 token 成本超出盈利临界点的困境,被迫转向更小的模型或更廉价的 GPU------ 这不是架构选择,而是财务必要。
-
规划周期崩溃:过去企业可以「需要时再购买算力」,如今面对 36 至 52 周的采购周期和提前半年以上预订的云端产能,这种弹性已经不复存在。
学术与独立研究者:门槛正在升高
Karpathy 的担忧触及了一个更深层的问题:当 H100 成为 AI 研究的事实标准,而 H100 又只对巨头开放,那么「参与 AI」这件事的准入门槛是否正在被资本决定?
对于高校实验室、独立研究者和初创团队而言,这是切切实实的现实困境。
应对策略
面对结构性的算力紧缺,产业界正在形成一套应对方法论。
向算力专属云迁移
AWS、Google Cloud、Azure 等通用云平台在算力紧张时优先保障自身 AI 业务和头部企业客户,对中小用户的按需算力供应日趋不稳定。
与此同时,CoreWeave、Lambda、Spheron、Hyperstack 等「新型算力云(Neo-cloud)」正在填补这一空缺。它们专注 GPU 供应,没有内部 AI 业务与用户竞争产能,在库存和可用性上反而有结构性优势。
充分利用 Spot 实例
所谓 Spot 实例,是云平台将暂时闲置、尚未被长期合同预订的 GPU 算力以折扣价对外开放的一种临时租用方式;代价是平台在需要回收资源时可以随时中断你的任务,因此也被称为「可被抢占的实例」。
正因为存在中断风险,Spot 实例的价格远低于稳定的按需实例 ------ 通常低 40% 至 70%。配合自动化检查点技术(每 15 至 30 分钟保存一次模型状态),即便任务被中断也只损失最近一个存档点的进度,可以大幅降低训练成本。
据报道,一支 12 人团队曾借助这一方式,将一个 70B 参数模型的训练成本控制在约 1.12 万美元。

www.spheron.network/blog/spot-g...
模型优化以降低硬件需求
当 GPU 数量难以继续扩张时,减少对 GPU 显存与带宽的依赖成为另一条路径。相比 FP16/BF16,FP8 量化通常可将模型权重内存占用降低约 50%,在推理场景下显著减少 GPU 需求;更激进的 INT4 量化甚至可让部分 13B 模型运行在单块 24GB 消费级 GPU 上。Blackwell 架构则开始支持 MXFP4 等 FP4 微缩放格式,而 NVIDIA 自家的 NVFP4 格式还能进一步降低内存占用与带宽压力。
混合专家(MoE)架构正是凭借「每 token 只激活少量参数」的特性赢得了新一轮青睐。通过激活部分参数,能让计算成本大幅降低。
知识蒸馏则是另一个选择:用大模型生成的输出训练小模型,让 7B 参数的学生模型在特定任务上达到大模型 85 至 95% 的表现,同时将推理时的 GPU 需求降低 10 至 20 倍。
多云编排与故障转移
单一供应商依赖在算力短缺时代是一种危险,因此主动在两至三家算力平台间分配工作负载,并设置自动切换机制,能够在某家平台突发断供时保障业务连续性。
算力短缺并非无解,但需要时间
供给侧:扩张已在路上,但时间表滞后
SK 海力士与美光正在持续扩充 HBM3e 与 HBM4 产能,新增供给预计将在 2026 年逐步爬坡,并于下半年后更明显缓解供应紧张。与此同时,台积电也在持续扩张 CoWoS 先进封装产能,AI GPU 的封装瓶颈有望逐步松动。
不过,NVIDIA 下一代 Rubin 架构虽然仍计划于 2026 年下半年推出,却面临供应链挑战。TrendForce 在 2026 年 4 月的报告中,将 Rubin 在 NVIDIA 高端 GPU 出货中的占比预测从 29% 下调至 22%,原因包括 HBM4 验证周期延长、ConnectX-9 网络升级适配、更高功耗,以及更复杂的液冷系统需求。与此同时,Rubin 平台本身也将消耗大量新增 CoWoS 产能,使先进封装资源短期内仍维持紧张。
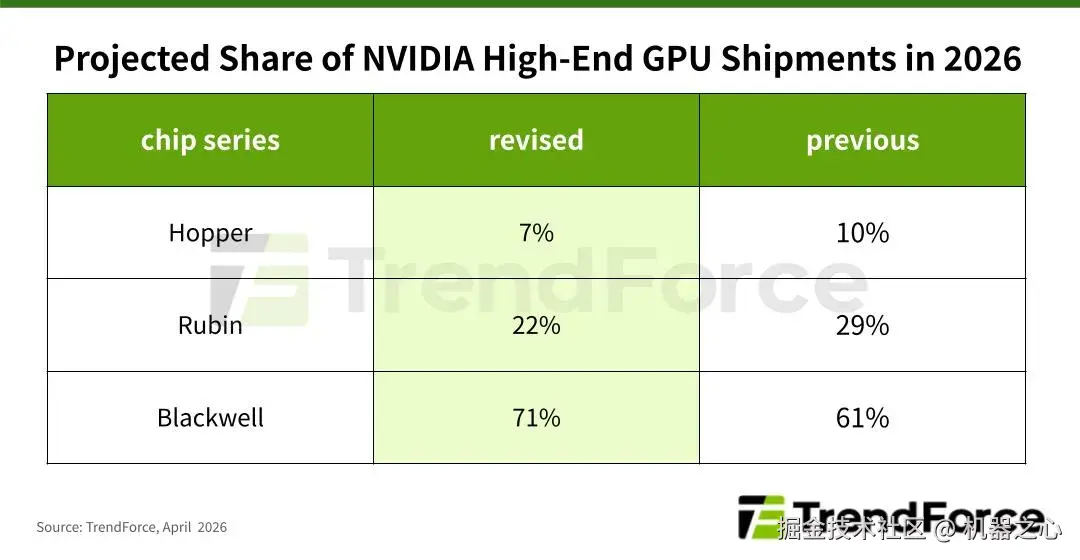
相比之下,更成熟的 Blackwell 平台将在短期内继续承担主力供应角色。TrendForce 预计,以 GB300/B300 为代表的 Blackwell 系列,将占 NVIDIA 2026 年高端 GPU 出货量的约 71%。
需求侧:Jevons 悖论正在上演
更令人忧虑的是需求端的逻辑。理论上,模型效率的提升应该减少对算力的需求;现实中,效率提升只会让 AI 工具的应用边界扩大,进而带来更高的总算力消耗。
效率提升不会减少需求,只会加速需求的扩张------这正是工业史上著名的杰文斯悖论(Jevons Paradox)。
从 SemiAnalysis 对 Claude Code 使用量的追踪来看,AI 编程工具的普及正以惊人速度吸收算力:他们预测 Claude Code 将在 2026 年底前占到全球日均代码提交量的 20% 以上。
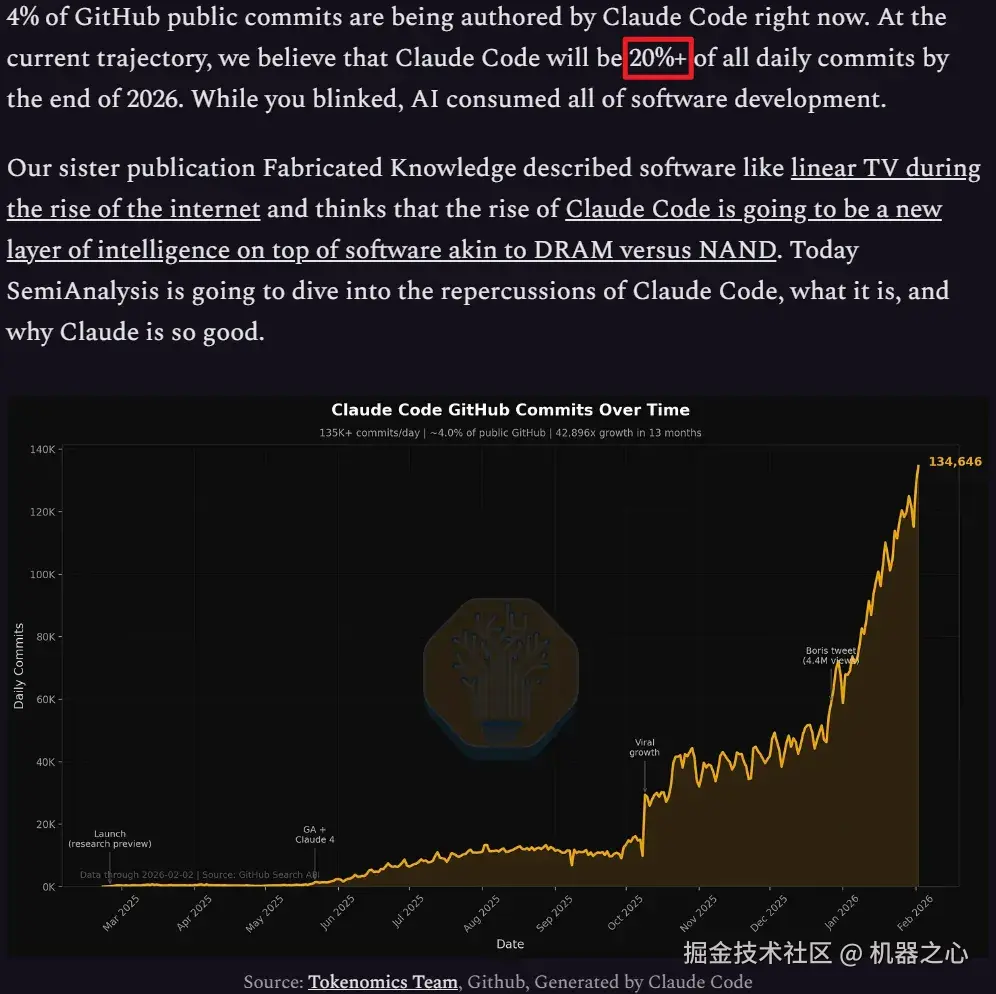
newsletter.semianalysis.com/p/claude-co...
普通消费者:买单者的时间窗口
对于普通消费者和中小型企业而言,这场算力危机已经通过内存涨价、消费级 GPU 减产、电脑手机配置缩水等方式悄然侵入日常。多家产业研究机构预计,即便供应链持续扩产,HBM 与先进封装等关键资源在未来几年内仍将维持紧张状态;SK 集团董事长崔泰源(Chey Tae-won)也曾警告,AI 基础设施的供需失衡可能持续数年。
如果说有什么确定性,大概是:未来数年,先进算力资源仍将是 AI 行业最关键的瓶颈之一;而对算力、能源与基础设施的争夺,也将持续决定谁能站在 AI 浪潮的前排。
随着下一代 Rubin Ultra 等 AI 系统功耗持续攀升,机柜级供电、散热与液冷系统的重要性和价值量也在快速上升。相比芯片本身,电源、网络、封装与数据中心基础设施,正在成为 AI 军备竞赛中越来越关键的组成部分。
AI 的军备竞赛还远未结束,而芯片只是这场竞赛中最看得见的战场。
参考链接
newsletter.semianalysis.com/p/the-great...
www.spheron.network/blog/gpu-sh...
www.trendforce.com/news/2025/0...