目录
[1.0 前置知识](#1.0 前置知识)
[2.0 创建过程](#2.0 创建过程)
[(7) 强制登录](#(7) 强制登录)
[(8)MyBatis Generator](#(8)MyBatis Generator)
一、表白墙项目
优化点: 一旦服务器重启,数据仍然会丢失
要想数据不丢失,需要把数据存储在数据库中,需要借助MyBatis来实现数据的操作
便捷添加依赖的插件工具:
二、图书管理系统
1.0 前置知识
(1) 简介
三层架构 : 就是把后端代码分成三层

controller:接住请求参数 把参数传给service层去处理 把service返回的结果打包成JSON 返回用户
service:这种动脑子的层 做判断 做计算 调Mapper
mapper:只跟数据库对话 不处理业务逻辑,只负责执行SQL
setAttribute方法 :就是往对象里面存一个键值对数据 setAttribute 就像在一个一次性的便签条(这个请求)上,写个标签("username")并贴上内容("张三"),方便后面的人(比如下一个页面)能通过标签直接找到内容,而不用重新去数据库里查。
HttpSession session: 服务器给你这个用户建立的一份 临时档案袋 用setAttribute存东西,用getAttribute来取东西
StringUtils.hasLength(String str):判断字符串是否有长度 还有hasText方法
queryUserByName(name): 根据唯一的用户名从数据库中检索对应的用户实体
UserInfo: 这个类用来把数据库里"用户表的一行数据"装进Java对象里的容器 让你可以方便的在代码里读取和传递用户的信息
.equals方法:就是比较两个字符串的内容是不是一摸一样
log.info方法: 让程序在后台日志里打印一行提示,告诉你 我正在添加一本书
@Data注解:是Lombok的注解,自动帮你生成 getter、setter、toString、equals 和 hashCode 方法,省去手写这些样板代码。
location.search 是浏览器自带的一个变量,它存的是当前网址中?以及后面的部分
比如你的浏览器地址是:http://127.0.0.1:8080/book_list.html?currentPage=1 那么location.search的值就是:?currentPage=1 它是自动抓取网址上的参数 不需要手动写死
逻辑删除和物理删除:逻辑删除不是真正的删除,而是在某行数据上增加类型is_deleted的删除标识,一般用update语句 物理删除也称为硬删除,从数据库中删除某一行或者一集合数据,一般使用DELETE语句 数据是公司的重要财产,通常情况下,我们采用逻辑删除的方式,当然也可以采用物理删除+归档的方式 //创建一个与原表差不多结构,记录删除时间
2.0 创建过程
图书管理系统 //正式练手项目
(1)杂
数据库表
实体表(学生表 用户表 课程表 班级表)
关系表(实体和实体之间的关系) //一个课程 对应多个学生 一个班级对应多个关系
班级表:班级id 班级名称 学生表:学号 姓名 曾用名 专业 年龄
一对一:一个班级对应一个班长 把关系放在实体表中 作为实体的一个属性
一对多:一个导员对应多个班级 把1作为多的一个属性
多对多:一个学生可以选择多门课程 一个课程对应多个学生 就需要建关系表:学生id 课程id
总结:图书管理系统 实体:用户 图书 关系:用户和图书之间没有关系 //除有权限的管理员
用户:用户名 密码
图书:图书ID 书名 作者 数量 价格
引入Mybatis依赖和MySQL驱动依赖
java
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>配置数据库&日志
java
# 数据库连接配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/book_test?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
configuration:
map-unders-to-camel-case: true # 配置驼峰自动转换
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 打印SQL语句
# 设置日志文件的文件名
logging:
file:
name: spring-book.logModel创建Model的作用,就是在Java代码里,照着数据库的表,一比一复刻出一个类
Model是集装箱 把你纸上设计的数据库表,在代码里面用Java类再描述一遍
Model就是放实体类的 放的@Data注解
(2)用户登录接口
约定前后端交互接口:
实现服务器代码:
控制层:创建UserController 从数据库中,根据名称查询用户,如果可以查到,并且密码一致,就认为登录成功
java
@RequestMapping("/login")
public boolean login(String name, String password, HttpSession session){
// 账号或密码为空
if (!StringUtils.hasLength(name) || !StringUtils.hasLength(password)){
return false;
}
UserInfo userInfo = userService.queryUserByName(name);
if (userInfo == null){
return false;
}
// 账号密码正确
if(userInfo != null && password.equals(userInfo.getPassword())){
// 存储在Session中
userInfo.setPassword("");
session.setAttribute("session_user_key",userInfo);
return true;
}
// 账号密码错误
return false;
}业务层:创建UserService
java
@Service
public class UserService {
@Autowired
private UserInfoMapper userInfoMapper;
public UserInfo queryUserByName(String name) {
return userInfoMapper.queryUserByName(name);
}
}数据层:创建UserInfoMapper
java
@Mapper
public interface UserInfoMapper {
@Select("select id, user_name, `password`, delete_flag, create_time, update_time from user_info where delete_flag=0 and user_name=#{name}")
UserInfo queryUserByName(String name);
}(3)添加图书接口
约定前后端交互接口:
实现服务器代码:
控制层:在BookController补充代码
进行参数校验 后端接⼝可能会被⿊客攻击, 不通过前端来访问, 如果后端不进⾏校验, 会产⽣脏数据
java
@RequestMapping("/addBook")
public String addBook(BookInfo bookInfo) {
log.info("添加图书:{}", bookInfo);
if (!StringUtils.hasLength(bookInfo.getBookName())
|| !StringUtils.hasLength(bookInfo.getAuthor())
|| bookInfo.getCount() == null
|| bookInfo.getPrice() == null
|| !StringUtils.hasLength(bookInfo.getPublish())
|| bookInfo.getStatus() == null) {
return "输⼊参数不合法, 请检查⼊参!";
}
try {
bookService.addBook(bookInfo);
return "";
} catch (Exception e) {
log.error("添加图书失败", e);
return e.getMessage();
}
}业务层:在BookService中补充代码
java
public void addBook(BookInfo bookInfo) {
bookInfoMapper.insertBook(bookInfo);
}这段代码就是:往数据库里面添加一本书的完整动作 把活交给了mapper干了哈哈
数据层:创建BookInfoMapper文件
java
@Mapper
public interface BookInfoMapper {
@Insert("<script>"
+ "insert into book_info "
+ "(book_name, author, count, price, publish, status) "
+ "values "
+ "(#{bookName}, #{author}, #{count}, #{price}, #{publish}, #{status})"
+ "</script>")
Integer insertBook(BookInfo bookInfo);
}这里的代码把这本书的 书名 作者 数量 价格 出版社 状态全部存进book_info表里
实现客户端代码:
提供前面页面中,js已经提前留了空位
java
<button type="button" class="btn btn-info btn-lg" onclick="add()">确定</button>点击确定按钮 会执行add()方法
补全add方法:
java
function add() {
$.ajax({
type: "post",
url: "/book/addBook",
data: $("#addBook").serialize(),
success: function (result) {
if (result == "") {
location.href = "book_list.html"
} else {
console.log(result);
alert("添加失败:" + result);
}
},
error: function (error) {
console.log(error);
}
});
}这个函数就是把用户填的新书信息用 Ajax 悄悄发给后端添加接口,成功就跳转列表页,失败就弹窗报错。
测试:
前端和后端测试 后端测试注意看数据库里面是否真的添加了数据
(4)图书列表接口
我们之前做的表白查询功能,是将数据库中所有的数据查询出来并展示到页面上
试想如果数据库中的数据有很多(假设有十几万条)的时候,将数据全部展示出来肯定不显示,那么如何解决这个问题?
分页查询

想要实现这个功能,从数据库中进行分页查询,我们要使用LIMIT关键字
格式为:limit开始索引 每页显示的条数(开始索引从0开始)
查询第一页的SQL语句
java
SELECT * FROM book_info LIMIT 0,10查询第二页SQL语句
java
SELECT * FROM book_info LIMIT 10,10查询第三页SQL语句
java
SELECT * FROM book_info LIMIT 20,10实现方式:
前端发起查询请求时,需要向服务端传递的参数:currentPage(当前页码) pageSize(每页显示条数) 后端响应时,需要响应给前端的数据:records所查询到的数据列表(存储到List集合中) total总记录数(用于告诉前端显示多少页),显示页数为:(total+pageSize-1) / pageSize
翻页请求对象:
//我们需要根据currentPage和pageSize 计算出来开始索引
java
import lombok.Data;
@Data
public class PageRequest {
// 当前页
private int currentPage = 1;
// 每页中的记录数
private int pageSize = 10;
private int offset;
public int getOffset() {
return (currentPage - 1) * pageSize;
}
}翻页列表结果类:
java
import lombok.Data;
import java.util.List;
@Data
public class PageResult<T> {
private int total; // 所有记录数
private List<T> records; // 当前页数据
public PageResult(Integer total, List<T> records) {
this.total = total;
this.records = records;
}
}约定前后端交互接口:
我们约定 浏览器给服务器发送一个/book/getListByPage这样的HTTP请求,通过currentPage参数告诉服务器,当前请求为第几页数据,后端根据请求参数,返回对应页的数据
java
[请求]
/book/getListByPage?currentPage=1&pageSize=10
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
[参数]
无
[响应]
Content-Type: application/json
{
"total": 25,
"records": [
{
"id": 25,
"bookName": "图书21",
"author": "作者2",
"count": 29,
"price": 22.00,
"publish": "出版社1",
"status": 1,
"statusCN": "可借阅"
},
{
......
}
]
}实现服务器代码:
控制层:完善BookController
java
@RequestMapping("/getListByPage")
public PageResult<BookInfo> getListByPage(PageRequest pageRequest) {
log.info("获取图书列表, pageRequest:{}", pageRequest);
PageResult<BookInfo> pageResult = bookService.getBookListByPage(pageRequest);
return pageResult;
}PageRequest pageRequest:前端发过来的请求体,里面装着当前页码和每页条数(比如 {currentPage: 2, pageSize: 10})。
PageResult<BookInfo>:返回给前端的结果,里面装着查到的书列表和总记录数(records 和 total)。
PageResult<BookInfo> pageResult = bookService.getBookListByPage(pageRequest);
→ 把分页请求交给 Service 层(厨师)去处理,厨师去查数据库,把这一页的书和总数装进 PageResult 里还回来。
return pageResult;
→ 把查到的结果返回给前端,前端就能拿到书列表和总数,去渲染表格和页码条。
这个接口就是 接收分页条件,调用业务层查库,最后返回分页结果给前端
业务层:BookService
java
public PageResult<BookInfo> getBookListByPage(PageRequest pageRequest) {
Integer count = bookInfoMapper.count();
List<BookInfo> books = bookInfoMapper.queryBookListByPage(pageRequest);
for (BookInfo book : books) {
if (book.getStatus() == 0) {
book.setStatusCN("无效");
} else if (book.getStatus() == 1) {
book.setStatusCN("可借阅");
} else {
book.setStatusCN("不可借阅");
}
}
return new PageResult<>(count, books);
}总理解:这段代码就是Service层的核心业务逻辑 大白话来讲就是:厨师拿到分页请求后,先去仓库查总数,再翻出这一页的书,给每本书贴个中文标签,最后打包还回去
//第一行 接收分页请求 PageRequest pageRequest里面装着前端的那个
//先查总共有多少本书 再查这一页具体有哪些书
bookInfoMapper就是专门操作图书表的Mapper接口 count()是Mapper里定义的方法 背后执行的SQL是SELECT COUNT(*) FROM book_info
翻页信息需要返回数据的总数和列表信息,需要查两次SQL
图书状态和数据库存储的status有一定的对应关系 ,如果后续状态码有变动, 我们需要修改项⽬中所有涉及的代码, 这种情况, 通常采⽤枚举类来处理映射关系
创建enmus目录,创建BookStatus类: 这里代码就不写了
设置了无效 可借阅 不可借阅等 getNameByCode:通过code来获取对应的枚举,以获取枚举对应的中文名称,后续如果有状态变更,只需要修改该枚举类即可
此时,BookService的代码可以修改如下:
java
for (BookInfo book : books) {
book.setStatusCN(BookStatus.getNameByCode(book.getStatus()).getName());
}数据层
翻页查询SQL
java
select * from book_info where status !=0 order by id desc limit #{offset}, #
{pageSize}分页查询有效图书,按最新添加排序,跳过若干条后取出当前页数据
前端代码:
处理分页信息的时候 使用了一个分页插件:jqPaginator分页组件
onPageChange:回调函数 当换页时触发(包括初始化第一页的时候),会传入两个参数:
目标页的页码,Number类型 触发类型,可能的值:inti初始化 chage点击分页
我们在图书列表信息加载之后,需要分页信息,同步加载
分页组件需要提供一些信息:totalCounts:总记录数 pageSize:每页的个数 visiblePages:可视页数 currentPage:当前页码
这些信息,pageSize和visblePages前端直接设置即可,totalCounts后端已经提供,currentPage页可以从参数中取到,但太复杂了 咱们直接由后端返回即可
后端代码:
后端把当前页的信息一并返回,前端用插件画出页码条,点击页码时直接刷新页面并带上对应的页码参数,实现完整的翻页功能
这段是JS代码:总的来说就是画表格 画页码的完整流水线
画表格:把数据变成页面上的行
这段代码在success的回调函数里,意思是后端成功返回数据后,开始干活
java
if (result != null) {
var finalHtml = ""; // ① 准备一个空的大箱子,准备装所有行的 HTML 代码
for (var book of result.records) { // ② 遍历后端返回的书本列表
finalHtml += '<tr>'; // ③ 每本书开一个新行
finalHtml += '<td><input type="checkbox" ...></td>'; // 第1列:复选框
finalHtml += '<td>' + book.id + '</td>'; // 第2列:ID
finalHtml += '<td>' + book.bookName + '</td>'; // 第3列:书名
// ... 中间省略 ...
finalHtml += '<td>' + book.statusCN + '</td>'; // 状态
finalHtml += '<td>...修改...删除...</td>'; // 操作按钮
finalHtml += "</tr>"; // ④ 结束这一行
}
$("tbody").html(finalHtml); // ⑤ 把拼好的所有行一口气塞进表格的 <tbody> 里
}画页码:生成底部的页码按钮
表格画好之后,紧接着用jqPaginator这个插件在页面上生成页码
java
$("#pageContainer").jqPaginator({
totalCounts: result.total, // ① 告诉插件"总共有多少本书"
pageSize: 10, // ② "每页放 10 本"
visiblePages: 5, // ③ "最多显示 5 个页码按钮"
currentPage: result.pageRequest.currentPage, // ④ "我现在在第几页"
// 下面的 first/prev/next/last/page 就是"首页/上一页/下一页/尾页/普通页码"按钮的长相
first: '<li class="page-item"><a class="page-link">首页</a></li>',
prev: '<li class="page-item"><a class="page-link">上一页</a></li>',
next: '<li class="page-item"><a class="page-link">下一页</a></li>',
last: '<li class="page-item"><a class="page-link">最后一页</a></li>',
page: '<li class="page-item"><a class="page-link">{{page}}</a></li>',
// ⑤ 当页面初始化或点击页码时触发
onPageChange: function (page, type) {
console.log("第" + page + "页, 类型:" + type);
// 这里后面会补充跳转代码
}
});完善页面点击代码:当点击页码时,跳转到⻚⾯: book_list.html?currentPage=?
补充上述代码:
java
onPageChange: function (page, type) { // page是目标页码,type是触发类型
if (type != 'init') { // 不是初始化,是用户真的点了按钮
location.href = "book_list.html?currentPage=" + page;
// 把浏览器地址栏改成 book_list.html?currentPage=3
// 页面就会自动刷新,加载第3页的数据
}
}(5)修改图书
约定前后端交互接口
进入修改页面,需要显示当前图书的信息 //根据图书Id 获取当前图书的信息
点击修改按钮 修改图书信息 我们约定,浏览器给服务器发送一个/book/updateBook这样的HTTP请求,form表单的形式来提交数据 服务器返回处理结果,返回"表示添加图书成功,否则返回失败信息"
实现服务器代码:
控制层:BookController
两个典型的方法 一个根据ID查单本书,一个修改图书信息
java
@RequestMapping("/queryBookById")
public BookInfo queryBookById(Integer bookId){
if (bookId==null || bookId<=0){
return new BookInfo(); // 返回一个空壳
}
BookInfo bookInfo = bookService.queryBookById(bookId);
return bookInfo;
}
@RequestMapping("/updateBook")
public String updateBook(BookInfo bookInfo) {
log.info("修改图书:{}", bookInfo); // 记日志
try {
bookService.updateBook(bookInfo); // 让 Service 去更新数据库
return ""; // 成功就返回空串
} catch (Exception e) {
log.error("修改图书失败", e);
return e.getMessage(); // 失败就返回错误原因
}
}业务层:BookService
java
public BookInfo queryBookById(Integer bookId) {
2 return bookInfoMapper.queryBookById(bookId);
3 }
4
5 public void updateBook(BookInfo bookInfo) {
6 bookInfoMapper.updateBook(bookInfo);
7 }数据层:
根据图书ID,查询图书信息
更新逻辑相对比较复杂,传递了哪些值,咱们更新哪些值,需要使用动态SQL
对于初学者而言,注解的方式拼接动态SQL不太友好,咱们采用xml的方式来实现
配置xml路径: 以及最终的整体配置文件:
java
mybatis:
mapper-locations: classpath:mapper/**Mapper.xml
//下面是配置文件里面加的选项
mapper-locations: classpath:mapper/**Mapper.xml定义Mapper接口:BookInfoMapper
java
Integer updateBook(BookInfo bookInfo);xml实现:
创建BookInfoMapper.xml文件 这里的代码就不写了
实现客户端代码:
我们观察,在列表页时,我们已经补充了修改的链接
java
finalHtml += '<a href="book_update.html?bookId=' + book.id + '">修改</a>';点击修改链接时,就会自动跳转到 http://127.0.0.1:8080/book_update.html?bookId=25 (25为对应
的图书ID)
进入修改图书页面时,需要从后端拿到当前图书的信息,显示在页面上
java
function update() {
$.ajax({
type: "post", // ① 用 POST 方式提交(数据放请求体,安全且不拼在 URL 上)
url: "/book/updateBook", // ② 请求地址,对应后端的 updateBook 接口
data: $("#updateBook").serialize(), // ③ 把整个表单里所有字段打包成 key=value 字符串
success: function (result) { // ④ 请求成功后执行
if (result == "") { // ⑤ 如果后端返回空串(说明更新成功)
location.href = "book_list.html"; // ⑥ 跳转到图书列表页
} else {
console.log(result); // ⑦ 打印错误信息到控制台
alert("修改失败:" + result); // ⑧ 弹窗提示用户失败原因
}
},
error: function (error) { // ⑨ 如果网络错误或服务器崩溃
console.log(error); // ⑩ 打印错误到控制台
}
});
}这段js代码就是 修改图书表单的提交逻辑,用户改完书的信息,点提交按钮 它就会把表单数据悄悄发给后端,成功就跳回列表页,失败就弹窗报错
我们修改图书信息,是根据图书ID来修改的,所以需要前端传递的参数中,包含图书ID
方式:在form表单中,再增加一个隐藏输入框,存储图书ID 随 $("#updateBook").serialize() ⼀起提交到后端
页面加载时,给该hidden框赋值
java
<form id="updateBook">
<input type="hidden" class="form-control" id="bookId" name="id">
<div class="form-group">
<label for="bookName">图书名称:</label>
<input type="text" class="form-control" id="bookName" name="bookName">
</div>
<!-- 其他字段 -->
</form>(6)删除图书
约定前后端交互接口 //看一看长什么样子吧
java
[请求]
/book/updateBook
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
[参数]
id=1&status=0
[响应]
"" // 成功返回空字符串,失败返回错误信息实现客户端代码:
点击删除时,调用delete()方法,我们来完善delete方法
java
function deleteBook(id) {
var isDelete = confirm("确认删除?");
if (isDelete) {
// 删除图书(修改状态为0)
$.ajax({
type: "post",
url: "/book/updateBook",
data: {
id: id,
status: 0
},
success: function () {
// 重新刷新页面
location.href = "book_list.html";
}
});
}
}批量删除:
点击批量删除按钮时,只需要把复选框选中的图书的ID 发送到后端即可
多个id 我们使用List的形式来传递参数
实现服务器代码:
控制层:
java
@RequestMapping("/batchDeleteBook")
public boolean batchDeleteBook(@RequestParam List<Integer> ids){
log.info("批量删除图书, ids:{}",ids);
try{
bookService.batchDeleteBook(ids);
}catch (Exception e){
log.error("批量删除异常,e:",e);
return false;
}
return true;
}业务层:
java
public void batchDeleteBook(List<Integer> ids) {
bookInfoMapper.batchDeleteBook(ids);
}数据层:
批量删除需要用到动态SQL 初学者建议使用动态SQL的部分 都用xml实现'
这里就省略了
(7) 强制登录
虽然我们做了用户登录,但是我们发现,用户不登陆依然可以操作图书 这样是有极大风险的
如果用户未登录就访问图书列表或者添加图书等页面,强制跳转到登录页面
实现思路分析:
用户登录时,我们已经把用户的信息存储在了session中,那就可以通过Session中的信息来判断用户都是登录。 如果Session中可以取到的登录用户的信息,说明用户已经登录了,可以进行后续操作。 如果session中取不到登录用户的信息,说明用户未登录,则跳转到登录页面。
我们需要再增加一个属性告知后端的状态以及后端出错的原因,但是当前只是图书列表而已,图书的增加,修改,删除接口,都需要跟着修改,添加两个字段。这对我们代码的修改是巨大的
我们不妨对所有后端返回的数据进行一个封装
java
private int status;status为后端业务处理的状态码,也可以用枚举来表示
修改result 并添加一些常用的方法
//这部分有点跳过的内容了 &&&
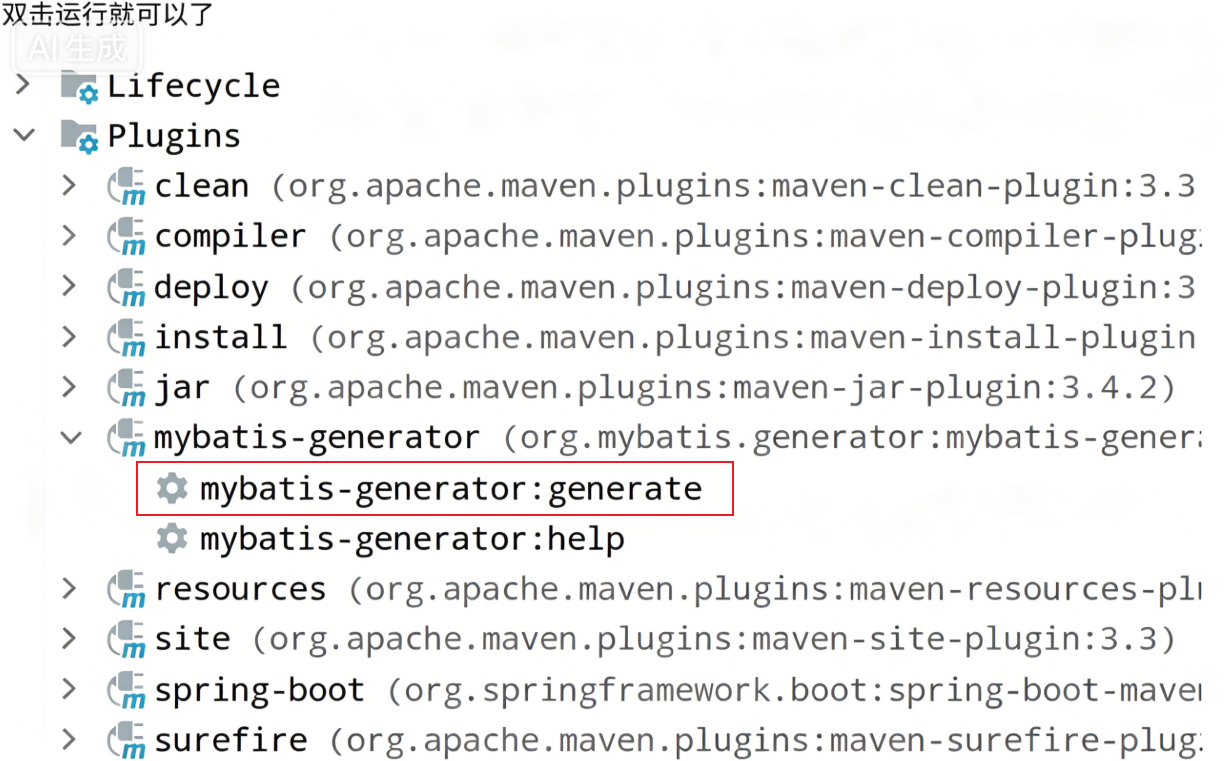
(8)MyBatis Generator
引入:
强制登录模块,我们只实现了一个图书列表,上述还有图书修改,图书删除等接口,也需要一一实现。如果应用程序功能更多的话,这样写下来会非常的浪费时间,并且容易出错误。
SpringBoot对于这种统一问题的处理方法
MyBatis Generator是⼀个为MyBatis框架设计的代码⽣成⼯具, 它可以根据数据库表结构⾃动⽣成相应的Java Model, Mapper接⼝以及SQL映射⽂件, 简化数据访问层的编码⼯作, 使得开发者可以更专注于业务逻辑的实现.
引入插件:
java
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.6</version>
<executions>
<execution>
<id>Generate MyBatis Artifacts</id>
<phase>deploy</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<configuration>
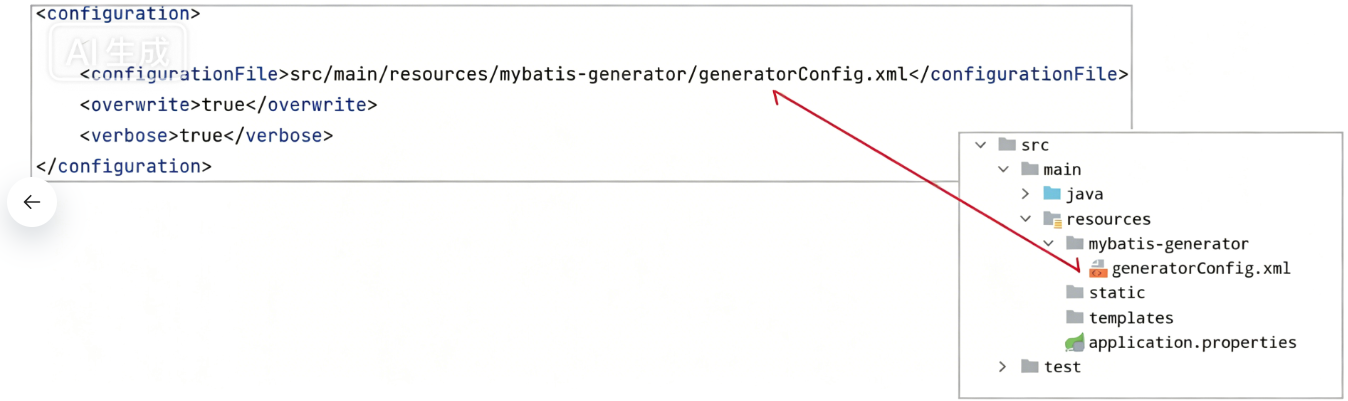
<!--generator配置文件所在位置-->
<configurationFile>src/main/resources/mybatisGenerator/generatorConfig.xml</configurationFile>
<!-- 允许覆盖生成的文件, mapxml不会覆盖, 采用追加的方式-->
<overwrite>true</overwrite>
<verbose>true</verbose>
<!--将当前pom的依赖项添加到生成器的类路径中-->
<includeCompileDependencies>true</includeCompileDependencies>
</configuration>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
</plugin>添加generatorConfig.xml并修改:
文件路径和上述配置保持一致:
生成文件: