1. 背景
平台对外提供了很多股票买卖策略,在策略上架之前,需要对策略进行回测以验证策略效果,传统的流程是产品同学提出策略算法,开发同学写回测代码,跑回测,产品同学再基于回测结果进行算法优化或者参数调优。整个流程如图1,通常耗时1~2周,投入2个人力。存在耗时长,迭代慢问题。除此之外,用户侧也希望平台能够提供回测功能,基于平台的数据,开发与测试用户自己的策略。因此业务侧打算开发一个回测系统,既能够内部使用,提升研发效率,也能够提供给用户使用,提升用户留存。开发时间从25年11月开始,历时1个月左右上线。
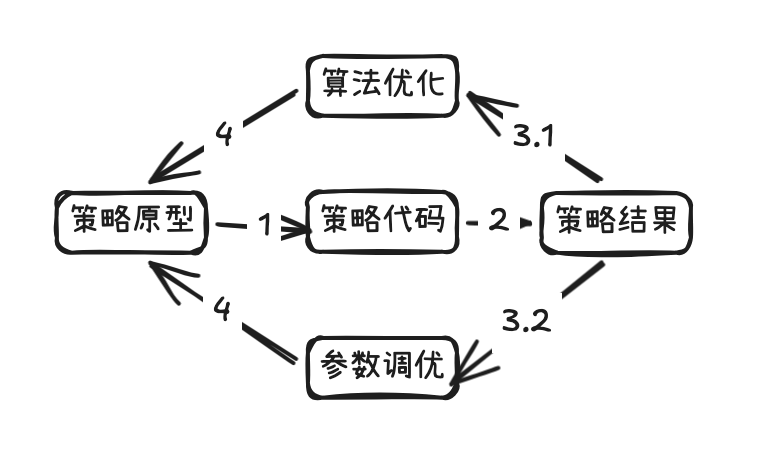 图1
图1
2. 任务
实现回测系统,系统要求如下:
2.1. 低门槛
即便是小白用户,也能够随便创建策略,无需具备金融、编程等领域知识。
2.2. 高自由度
要求支持自定义策略,任意算法。
2.3. 高性能
回测系统要尽可能快速给出回测结果。
2.4 高准确性
回测结果要稳定可靠,不能多次运行结果不一致。
3. 难点与解决方案
3.1 难点
3.1.1 如何实现低门槛、高自由度、高准确性的回测系统?
3.1.2 回测如何实现高性能?
3.2 解决方案
在开发回测系统之前,我有一些回测程序开发经验,主要是对我们平台的策略进行回测,这些策略比较复杂,涉及十几个算法数百个指标。对代码实现准确性要求很高。另外回测程序往往需要反复的调算法、调参数、取数据、计算、分析,整个过程冗长、繁琐、重复,效率很低。如何实现一套高扩展性、高自由度、高准确性的回测系统确实是一个难题。没啥头绪。于是先去调研了一下业内常用的回测系统实现方案:
3.2.1 方案调研
3.2.1.1. 方案一 固定模板+动态参数
最早的方案就是这种,平台预先设置几种常用回测模板,用户可以调整回测参数,点击一键运行。
优点:
- 回测结果准确性强,算法经过迭代优化,不会出错。
缺点:
-
不灵活,自由度差。回测模板固定,无法满足用户自定义的策略。
-
门槛高,需要用户对回测算法、金融术语有理解。
3.2.1.2. 方案二 自定义脚本(GPL,General-Purpose Language,通用编程语言)
这种方案是用户可以自定义回测脚本,平台提供算力和数据。
优点:
- 最灵活,理论上支持任意策略。
缺点:
-
门槛高,需要用户具备编码、金融知识。
-
迭代慢,需要人工分析、进行参数调优。
3.2.1.3. 方案三 DSL (Domain-Specific Language,领域特定语言)
这种方案是在方案二的基础上进行了抽象,降低用户编码难度。比如下面这个例子,
在价格突破20日均线且RSI14低于30的时候买入。
如果使用方案二,需要写一个均线函数、RSI函数,然后写一个主函数在实现。
如果使用方案三,只需要 close > MA(20) and RSI(14) < 30,类似于伪代码。
方案二需要用户能够看懂代码,并进行debug,方案三则只需要用户看懂伪代码即可,至于伪代码的具体实现,则无需关心。显著降低用户编码门槛。
优点:
-
灵活度比较高,能够满足常见的策略实现,但对于一些特别复杂的策略,还是有些弱。
-
准确性高,算法都是预先优化调试好的,不会存在bug。
缺点:
-
实现复杂,DSL的运行需要实现一个编译器,具备词法分析、语法分析、生成AST(抽象语法树)、AST执行引擎,实现难度大。
-
门槛还是比较高,虽然用户无需理解代码,但还是需要掌握基本的金融术语,如RSI, MACD等等。
3.2.1.4. 方案四 LLM+GPL
方案四是在方案二的基础上进行了优化,使用LLM进行代码生成,用户只需自然语言描述即可,极大降低用户编码门槛。另外灵活性也比较高,理论上支持任意策略。但缺点也很明显,LLM生成质量不可控,对于复杂策略生成的代码质量可靠性不足。我们内部初期就曾尝试过使用LLM进行回测策略代码生成,结论是完全不可以生产使用。对于简单的策略,成功率能够达到50%,但是一旦涉及到复杂策略,生成的代码完全不可靠、结果不可控、不可调试。
优点:
-
低门槛,用户只需自然语言描述即可生成策略代码。
-
灵活度高,理论上LLM可以生成任何策略代码。
缺点:
- 质量不可控,LLM生成代码质量不可控,无法判断对错。另外,对于特别复杂的策略,往往涉及到数千行代码,这种场景验证与调试就是一个噩梦。
我们的设计目标是既要满足低门槛,又要满足高灵活度、确定性。典型的既要又要。在计算机领域,有一个经典论断, "没有银弹"(No Silver Bullet), 即不存在单一的技术,能够一劳永逸的解决所有问题。这并不意味着问题无法解决。当出现这种"既要又要"的时候,确实存在一个经典的解法,"混合策略"。
混合策略指结合多个方法的优点来解决同一个问题。比如在计算机领域,使用多级缓存(cpu片上缓存、内存、磁盘) 解决性能与成本问题,又比如Redis 混合AOF(既结合了RDB恢复快、占用空间小的优点,又结合了AOF实时性强的优点),其它还有很多,如feeds流系统设计中的推拉结合等等。结合我们的业务场景和业内实现,想到第五种方案:
3.2.1.5. 方案五 LLM+DSL混合方案
在我们这个场景,既然要同时实现高灵活度、低门槛、高确定性。那就可以将LLM、DSL结合起来,LLM提供高灵活性、低门槛,DSL提供确定性。
这种方案的优点是及利用了LLM生成的灵活性,低门槛,又利用了DSL确定性。从而能够满足业务要求,缺点是实现复杂,需要实现一个DSL编译器,如果在没有智能编码助手的时代,开发一个编译器难度很大,起码要耗时2个月起步,但有了Cursor或者Claude之后,仅仅需要几天时间就能够搞定。
这里简单说一下DSL的设计,我们预先实现了150+种算法, 如RSI, MACD, MA等等,DSL里直接调用即可,无需LLM从零开始生成,极大降低LLM出错的概率,同时确保了算法的准确性。另外对于系统不支持的算法,DSL也提供了基本的运算符,包括加减乘除、逻辑运算符等等,即便用户自创了一个新的算法,这套系统也能够利用基本的运算符表达式来生成对应的函数,就像搭积木一样。
关于DSL编译器,这里使用Cursor 来生成,功能包括词法分析、语法分析、AST生成、AST执行引擎等基本功能,AST执行引擎的实现原理是基础的树遍历解释器方案。
就以之前的例子(在价格突破20日均线且RSI14低于30的时候买入。)来说,LLM生成如下配置
bash
Strategy:
final_result:
close > MA(20) and RSI(14) < 30AST经过词法、语法分析之后,生成的AST如下
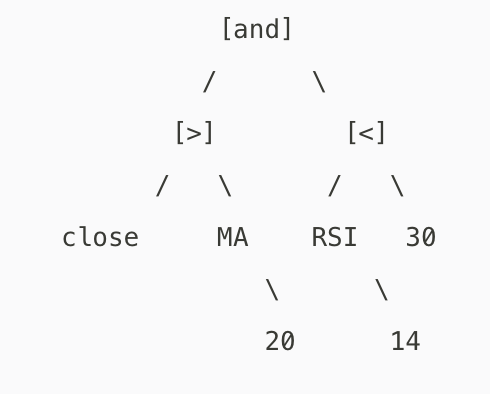 图2
图2
AST执行引擎会自底向上递归执行表达式,最终返回一个true or false, 即买卖信号。
通过LLM+DSL混合方式实现了低门槛、高灵活、高准确性的业务要求。
3.2.2 实现高性能
下一个问题是如何实现高性能。
回测程序执行时间由以下几个部分决定
Ticker总数、回测时间段、回测K线粒度、算法复杂度。
对于单个ticker的回测执行过程如下
取Ticker行情数据 -> 计算 -> 分析
Ticker越多,回测周期越长、K线粒度越细,所需要的计算、存储资源越多。这里的时间主要由两部分组成,数据读取+数据计算。
如果要对标普500成分股回测一年min1(1分钟)的K线:
K线总数=500*250*390=48.75M
单根K线(OHLCV,ID,Timestamp,Ticker), 大小约为 20*5 + 8*2 + 16 = 132Byte
本次回测需要读取的总数据量再 48.75M*132Byte = 6G
仅单次任务就需要从DB读取48.75M条记录,占用内存空间6G,耗费资源过大。因为我们使用MySQL存储K线数据,面对如此海量的数据读取,直接读取MySQL肯定是不行的。另外,我们单个节点的内存上限是16G,即便全部运行回测,也无法同时执行多个回测任务。因此需要对数据读取和计算进行大量优化。
3.2.2.1 数据读取优化
针对数据读取,采用的优化方案包括,多级缓存+数据压缩。这里的多级缓存包含文件缓存+内存缓存。缓存的内容是使用zstd压缩后的行情数据。缓存服务启动后,会从数据库中读取原始数据,经过pb编码之后,再经过zstd压缩写入到本地文件中。当接口请求的时候,先读取内存换成,缓存不命中再读取文件缓存。如果文件缓存也没有,则通过singleflight防击穿机制从数据库中加载。之后再异步pb编码和zstd压缩,更新缓存。
以AAPL为例,不压缩的情况下,5年日线占用的空间为
5*250*132Byte = 165K, 经过zstd压缩编码后只需要38.2K左右, 压缩率为(38.2*100/165)=23.2%。
美股5年日线原始大小为10K*5*250*132Byte=18.8M, 这个数据全量缓存到内存里完全无压力。美股1年日内min1原始大小为10K*250*390*132Byte=1.44G。日内数据量要远远超过日间数据。业务侧需要缓存min1, min5, min15, min30, 1h, 2h, 4h, 1d, 1wk. 如果不做任何优化处理,单独缓存这些数据就需要一个ec2 节点,成本比较高。结合实际的使用场景,我们仅针对热门股票进行缓存,比如标普500, 纳斯达克 100,以及市值前1000的股票。
总的缓存标的不超过2000个,整个文件缓存占用空间大小约100MB。
3.2.2.2 计算优化
接下来说一说如何提升计算速度,最简单的方法就是并行计算,创建多个协程并行执行,比如同时回测1000个Ticker, 开N路协程提升N倍,这里为了避免单个用户占用过多资源,会限制单个任务的并发数。除此之外,回测引擎也针对计算做了优化,很多算法使用到相同的指标,比如MA, RSI, KDJ等等。这里会缓存指标结果,如果多个算法使用到相同的指标,则可以直接复用。还有一点,业务层面做了几点保护措施,一个是限制了单次回测Ticker总数,另一个是针对不同时间粒度所能够获取的时间段也做了限制,如日线可以获取5年,min1 最多提供半年。目标是减少回测的计算量。
整体设计流程图如下
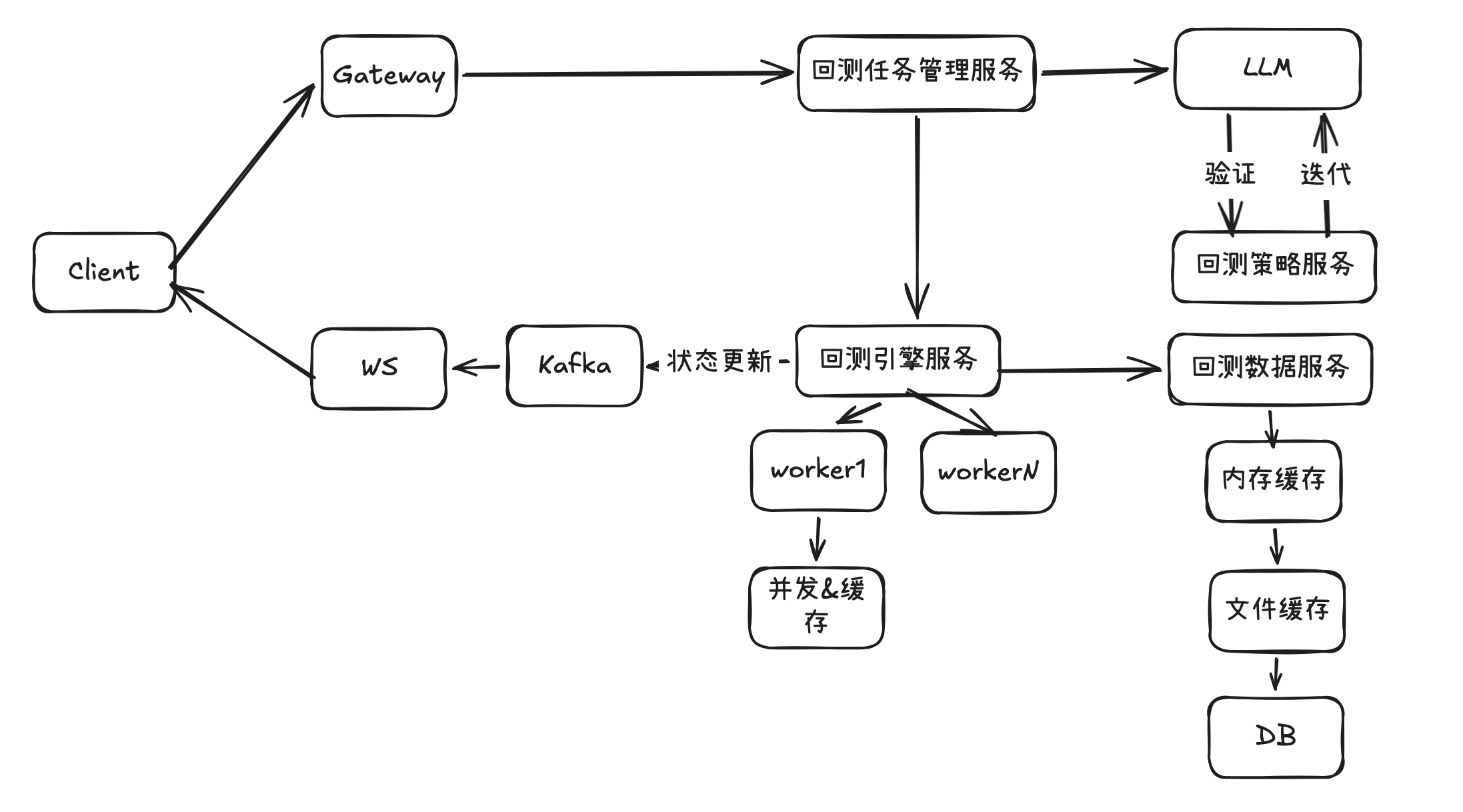 图3
图3
4. 结果
-
缓存命中率93%,基本上不对数据库造成任何压力。
-
回测任务平均执行时长27s,小型回测任务5秒内返回结果。
上线后效果还不错,无论是执行效率、执行时间、执行结果准确性、策略自由度各方面都满足预期。
5. 收获
5.1 多用AI编码工具,要是没有Cursor或者Claude,人工手搓一个编译器不知道要耗时多久。
5.2 面对既要又要的场景,考虑使用混合策略。