GPU-Initiated Networking for NCCL
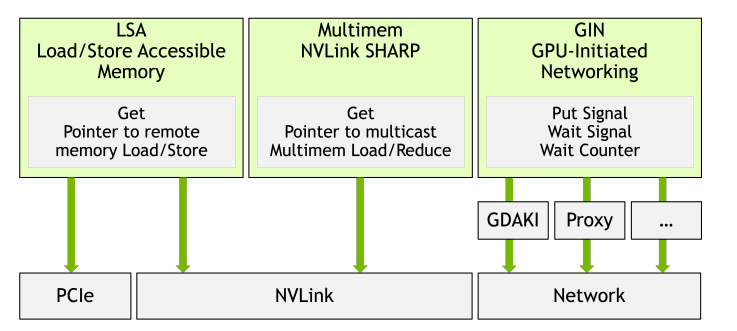
NCCL Device API architecture showing three operation modes and
their underlying interconnect technologies:
- Load/Store Accessible (LSA) uses PCIe and NVLink for intra-node memory operations.
- Multimem leverages NVLink SHARP for hardware multicast.
- GPU-Initiated Networking (GIN) provides dual backend implementations (GDAKI and Proxy) for network-based communication over InfiniBand and RoCE.
寻址模式
gin gdaki接口:ncclGinIbGdaki
mr注册函数,gdakiRegMrDmaBuf
cpp
status = wrap_mlx5dv_reg_dmabuf_mr(mr, pd, 0, aligned_size, 0, dmabuf_fd, access,
MLX5DV_REG_DMABUF_ACCESS_DATA_DIRECT);
// 或者
status = wrap_ibv_reg_dmabuf_mr(mr, pd, 0, aligned_size, 0, dmabuf_fd, access);gin proxy接口:ncclGinIbProxy
mr注册函数, ncclIbRegMrDmaBufInternal2
cpp
wrap_ibv_reg_dmabuf_mr(&mr, base->pd, offset, pages*pageSize, addr, fd, flags);
//或者
wrap_mlx5dv_reg_dmabuf_mr(&mr, base->pd, offset, pages*pageSize, addr, fd, flags, MLX5DV_REG_DMABUF_ACCESS_DATA_DIRECT);ncclGinIbProxy 和 ncclGinIbGdaki 在调用 wrap_mlx5dv_reg_dmabuf_mr(或类似的 wrap_ibv_reg_dmabuf_mr)时,对 IOVA (I/O Virtual Address) 参数传递了不同的值:
- GDAKI:iova = 0
- Proxy:iova = addr(用户空间的虚拟地址)
GDAKI:IOVA=0 → 基于偏移量的寻址
GDAKI 后端的核心设计是 GPU 直接向网卡提交 WQE,在这种模型下:
- MR 的物理地址已通过 DMA-BUF 绑定:cuMemGetHandleForAddressRange 获取了 GPU 内存的物理页文件描述符,注册时网卡已经知道这块内存的物理基地址。
- 设备端 API 只传递偏移量:在 GDAKI 的 doca_gpu_dev_verbs_put 调用中,目标地址 raddr.addr 直接等于一个偏移量(4096 * ginOffset4K + dstOffset),raddr.key 是 rkey。硬件执行的是 物理基地址 + 偏移量 的访问。
- IOVA=0 标志着"这个 MR 无需虚拟地址翻译":将 IOVA 设为 0,等于告诉网卡:这个 MR 使用物理地址作为基址,后续提供的地址字段应被解释为相对该基址的偏移量,而不是需要 MMU 翻译的虚拟地址。
根据参考链接:IBV_ACCESS_ZERO_BASED, Use byte offset from beginning of MR to access this MR, instead of a pointer address。iova设置为0,等同于设置IBV_ACCESS_ZERO_BASED的标志位。
RDMA 高级提到:
Zero based MR:MR注册后正常情况下对端是拿本端的VA地址来访问,但这容易泄露某些信息或者VA在进程重启后会变化。此时可调用ibv_reg_mr创建一个zero based MR (access flags |= IBV_ACCESS_ZERO_BASED),这样对端拿来访问的地址会在本端HCA被当成是MR的偏移,而不是一个具体的VA。
Proxy:IOVA=addr → 传统的虚拟地址寻址
Proxy 后端则不同,GPU kernel 无法直接操作网卡,而是将请求发送给一个主机端的代理线程,由代理线程调用传统的 libibverbs API (ibv_post_send) 来完成数据传输。
- 代理线程使用标准的 ibv_post_send:在 ncclGinIbProxyIPut 中,远端地址是这样计算的:
cpp
void *dstPtr = (void *)(dstMrHandle->base_vas[rank] + dstOff);
wr.wr.rdma.remote_addr = (uint64_t)dstPtr;- base_vasrank 必须是有效的虚拟地址:它是远端 MR 的基地址,被存储并在构造 RDMA 请求时使用。如果 IOVA 被设为 0,那么 base_vasrank 就会是 0,构造出的 remote_addr = 0 + dstOff 将是一个无效的虚拟地址,代理线程的 WQE 会失败。
- IOVA=addr 维持了标准的 VA 模型:通过将 MR 的 IOVA 设置为这块内存的用户空间虚拟地址 addr,网卡就建立了一个从虚拟地址到物理地址(由 DMA-BUF 提供)的映射。这样,代理线程就可以安全地用 base_vasrank + offset 构造出远端的真实虚拟地址,硬件会像往常一样进行 VA→PA 的翻译。
虽然 Proxy 也利用了 DMA-BUF 来获取物理页(以获得更好的性能,例如避免内存固定/拷贝),但它必须保留虚拟地址的抽象层,因为控制路径在 CPU 上,CPU 无法像 GDAKI 那样直接使用物理偏移量。
example
cpp
// Hybrid alltoall: GIN puts for non-LSA ranks; LSA stores for the LSA team.
template <typename T>
__global__ void HybridAlltoAllKernel(ncclWindow_t sendwin, size_t sendoffset,
ncclWindow_t recvwin, size_t recvoffset,
size_t count, struct ncclDevComm devComm) {
int ginContext = 0; // single context for simplicity
unsigned int signalIndex = blockIdx.x;
ncclGin gin { devComm, ginContext };
uint64_t signalValue = gin.readSignal(signalIndex);
ncclBarrierSession<ncclCoopCta> bar { ncclCoopCta(), ncclTeamTagWorld(), gin, blockIdx.x };
bar.sync(ncclCoopCta(), cuda::memory_order_acquire, ncclGinFenceLevel::Relaxed);
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int nthreads = blockDim.x * gridDim.x;
ncclTeam world = ncclTeamWorld(devComm);
ncclTeam lsa = ncclTeamLsa(devComm);
const int startLsa = world.rank - lsa.rank;
const int lsaSize = lsa.nRanks;
const size_t size = count * sizeof(T);
// Remote ranks: world ranks below and above the LSA range (split loops for clarity).
for (int r = tid; r < startLsa; r += nthreads) {
gin.put(world, r,
recvwin, recvoffset + world.rank * size,
sendwin, sendoffset + r * size,
size, ncclGin_SignalInc{signalIndex});
}
for (int r = startLsa + lsaSize + tid; r < world.nRanks; r += nthreads) {
gin.put(world, r,
recvwin, recvoffset + world.rank * size,
sendwin, sendoffset + r * size,
size, ncclGin_SignalInc{signalIndex});
}
// Local ranks: LSA ranks (single loop for clarity).
T* sendLocal = (T*)ncclGetLocalPointer(sendwin, sendoffset);
for (size_t offset = tid; offset < count; offset += nthreads) {
for (int lp = 0; lp < lsa.nRanks; lp++) {
int wr = startLsa + lp;
T* recvPtr = (T*)ncclGetLsaPointer(recvwin, recvoffset, lp);
recvPtr[world.rank * count + offset] = sendLocal[wr * count + offset];
}
}
int numRemotePeers = world.nRanks - lsa.nRanks;
// Wait only on the CTA whose signalIndex sees all GIN puts targeting this rank.
int receivingCta = (world.rank % nthreads) / blockDim.x;
if (blockIdx.x == receivingCta)
gin.waitSignal(ncclCoopCta(), signalIndex, signalValue + numRemotePeers);
gin.flush(ncclCoopCta());
bar.sync(ncclCoopCta(), cuda::memory_order_release, ncclGinFenceLevel::Relaxed);
}gin put 接口
cpp
template<unsigned beMask>
template<
typename RemoteAction, // one of ncclGin_{None|SignalInc}
typename LocalAction, // one of ncclGin_{None|CounterInc}
typename Coop,
typename DescriptorSmem,
typename SegmentType // one of ncclGin_{SegmentDevice|SegmentMixed|SegmentHostNuma}
>
NCCL_DEVICE_INLINE void ncclGin_BackendMask<beMask>::put(
ncclTeam team, int peer,
ncclWindow_t dstWin, size_t dstOffset,
ncclWindow_t srcWin, size_t srcOffset, size_t bytes,
RemoteAction remoteAction, LocalAction localAction,
Coop coop,
DescriptorSmem descriptor,
cuda::thread_scope givenRelease, cuda::thread_scope requiredRelease,
uint32_t optFlags, SegmentType bufType
) const {
using nccl::utility::loadConst;
using nccl::gin::internal::teamRankToGinRank;
ncclGinCtx_M<beMask> ctx = this->_makeCtx();
coop.sync();
if (coop.thread_rank() == 0) {
if (ncclGin_isDeviceOnly(bufType)) {
ncclGinCall<ncclGinApi_Put>(ctx,
ncclCoopThread(), teamRankToGinRank(this->comm, team, peer), /*hasWins=*/true,
loadConst(&dstWin->ginWins[this->connectionId]),
4096*size_t(loadConst(&dstWin->ginOffset4K)) + dstOffset,
loadConst(&srcWin->ginWins[this->connectionId]),
4096*size_t(loadConst(&srcWin->ginOffset4K)) + srcOffset, bytes,
ncclGin_getSignalDescriptor(*this, remoteAction),
ncclGin_getSignalOp(remoteAction),
ncclGin_getSignalOpArg(remoteAction),
ncclGin_isCounter(localAction),
ncclGin_getCounterId(*this, localAction),
ncclGin_isDescriptor(descriptor),
ncclGin_getDescriptor(descriptor),
requiredRelease,
givenRelease,
optFlags
);
} else {
if (srcWin->numSegments == 1 && dstWin->numSegments == 1) {
ncclGinCall<ncclGinApi_Put>(ctx,
ncclCoopThread(), teamRankToGinRank(this->comm, team, peer), /*hasWins=*/true,
loadConst(&dstWin->ginWins[this->connectionId]),
4096*size_t(loadConst(&dstWin->ginOffset4K)) + dstOffset,
loadConst(&srcWin->ginWins[this->connectionId]),
4096*size_t(loadConst(&srcWin->ginOffset4K)) + srcOffset, bytes,
ncclGin_getSignalDescriptor(*this, remoteAction),
ncclGin_getSignalOp(remoteAction),
ncclGin_getSignalOpArg(remoteAction),
ncclGin_isCounter(localAction),
ncclGin_getCounterId(*this, localAction),
ncclGin_isDescriptor(descriptor),
ncclGin_getDescriptor(descriptor),
cuda::thread_scope_system, // for safety, escalate to system regardless of what the user requested
givenRelease,
optFlags
);
} else {
// Multi-segment case. The puts are chunked to handle multiple registration entries and src/dst windows that potentially have a different number of segments
int srcSeg;
size_t srcSegOffset;
nccl::gin::internal::findSegmentFromWindow(srcWin, srcOffset, &srcSeg, &srcSegOffset);
int dstSeg;
size_t dstSegOffset;
nccl::gin::internal::findSegmentFromWindow(dstWin, dstOffset, &dstSeg, &dstSegOffset);
bool doneSysmemFence = false;
size_t remaining = bytes;
cuda::thread_scope localRequiredRelease = requiredRelease;
while (remaining > 0) {
struct ncclSegmentWindow const& dstSegmentWindow = dstWin->ginMultiSegmentWins[dstSeg];
struct ncclSegmentWindow const& srcSegmentWindow = srcWin->ginMultiSegmentWins[srcSeg];
if (!doneSysmemFence && srcSegmentWindow.memType == CU_MEM_LOCATION_TYPE_HOST_NUMA) {
localRequiredRelease = cuda::thread_scope_system; // for safety, escalate to system regardless of what the user requested
doneSysmemFence = true;
}
const size_t srcRemaining = srcSegmentWindow.segmentSize - srcSegOffset;
const size_t dstRemaining = dstSegmentWindow.segmentSize - dstSegOffset;
const size_t putSize = nccl::gin::internal::getSegmentChunkSize(srcRemaining, dstRemaining, remaining);
const bool isLastPut = (remaining == putSize);
ncclGinCall<ncclGinApi_Put>(ctx,
ncclCoopThread(), teamRankToGinRank(this->comm, team, peer), /*hasWins=*/true,
loadConst(&dstWin->ginMultiSegmentWins[dstSeg].ginWins[this->connectionId]),
dstSegOffset,
loadConst(&srcWin->ginMultiSegmentWins[srcSeg].ginWins[this->connectionId]),
srcSegOffset, putSize,
isLastPut ? ncclGin_getSignalDescriptor(*this, remoteAction) : ncclGin_getSignalDescriptor(*this, ncclGin_None{}),
ncclGin_getSignalOp(remoteAction),
ncclGin_getSignalOpArg(remoteAction),
isLastPut ? ncclGin_isCounter(localAction) : false,
ncclGin_getCounterId(*this, localAction),
ncclGin_isDescriptor(descriptor),
ncclGin_getDescriptor(descriptor),
localRequiredRelease,
givenRelease,
optFlags
);
remaining -= putSize;
nccl::gin::internal::advanceSegmentCursor(&srcSeg, &srcSegOffset, putSize, srcSegmentWindow.segmentSize);
nccl::gin::internal::advanceSegmentCursor(&dstSeg, &dstSegOffset, putSize, dstSegmentWindow.segmentSize);
localRequiredRelease = cuda::thread_scope_thread;
}
}
}
}
coop.sync();
}注意这里使用地址偏移。网卡需要offset从本地内存获取数据,发送到远端内存:
4096*size_t(loadConst(&dstWin->ginOffset4K)) + dstOffset
4096*size_t(loadConst(&srcWin->ginOffset4K)) + srcOffset
ncclGinApi_Put
cpp
template <enum doca_gpu_dev_verbs_resource_sharing_mode resource_sharing_mode, typename Coop>
NCCL_DEVICE_INLINE static void putImplMode(ncclGinCtx ctx, Coop coop, int peer, bool hasWins,
ncclGinWindow_t dstWin, size_t dstOff, ncclGinWindow_t srcWin,
size_t srcOff, size_t bytes, bool hasSignal,
size_t signalOffset, __be32 signalKey, ncclGinSignalOp_t signalOp,
uint64_t signalOpArg, bool hasCounter,
ncclGinCounter_t counterId, bool hasDescriptor,
ncclGinDescriptorSmem* descriptor,
cuda::thread_scope required, cuda::thread_scope given,
uint32_t optFlags) {
using nccl::utility::loadConst;
coop.sync();
if (coop.thread_rank() == 0) {
ncclGinGdakiGPUContext* gdaki = &((struct ncclGinGdakiGPUContext*)ctx.handle)[ctx.contextId];
doca_gpu_dev_verbs_qp* qp = loadConst(&gdaki->gdqp) + peer;
doca_gpu_dev_verbs_qp* companion_qp;
ncclGinGdakiMemHandle* dstMh = (ncclGinGdakiMemHandle*)dstWin;
ncclGinGdakiMemHandle* srcMh = (ncclGinGdakiMemHandle*)srcWin;
uint32_t codeOpt = nccl::gin::gdaki::docaOptFlagsFromGinOptFlags(optFlags);
doca_gpu_dev_verbs_addr raddr, laddr;
// 使用offset作为地址
if (hasWins) {
raddr.addr = dstOff;
raddr.key = loadConst(loadConst(&dstMh->rkeys) + peer);
laddr.addr = srcOff, laddr.key = loadConst(&srcMh->lkey);
}
doca_gpu_dev_verbs_addr sig_raddr, sig_laddr;
if (hasSignal) {
if (signalOp == ncclGinSignalInc) signalOpArg = 1;
sig_raddr.addr = signalOffset;
sig_raddr.key = signalKey;
sig_laddr.addr = 0;
sig_laddr.key = loadConst(&gdaki->sink_buffer_lkey);
}
doca_gpu_dev_verbs_addr counter_raddr, counter_laddr;
if (hasCounter) {
companion_qp = loadConst(&gdaki->companion_gdqp) + peer;
counter_raddr.addr = sizeof(uint64_t) * (counterId + loadConst(&gdaki->counters_table.offset));
counter_raddr.key = loadConst(loadConst(&gdaki->counters_table.rkeys) + ctx.rank);
counter_laddr.addr = 0;
counter_laddr.key = loadConst(&gdaki->sink_buffer_lkey);
}
// cuda::thread_scope_system has the lowest value
// DOCA guarantees SCOPE_GPU. Only add another release if SCOPE_SYSTEM is required.
if ((required == cuda::thread_scope_system) && (given > required)) {
doca_gpu_dev_verbs_fence_release<DOCA_GPUNETIO_VERBS_SYNC_SCOPE_SYS>();
}
if (hasWins) {
if (hasSignal && hasCounter) {
doca_gpu_dev_verbs_put_signal_counter<DOCA_GPUNETIO_VERBS_SIGNAL_OP_ADD, resource_sharing_mode>(
qp, raddr, laddr, bytes, sig_raddr, sig_laddr, signalOpArg, companion_qp, counter_raddr,
counter_laddr, 1, codeOpt);
} else if (hasSignal) {
doca_gpu_dev_verbs_put_signal<DOCA_GPUNETIO_VERBS_SIGNAL_OP_ADD, resource_sharing_mode>(
qp, raddr, laddr, bytes, sig_raddr, sig_laddr, signalOpArg, codeOpt);
} else if (hasCounter) {
doca_gpu_dev_verbs_put_counter<resource_sharing_mode>(
qp, raddr, laddr, bytes, companion_qp, counter_raddr, counter_laddr, 1, codeOpt);
} else {
doca_gpu_dev_verbs_put<resource_sharing_mode>(qp, raddr, laddr, bytes, codeOpt);
}
} else {
if (hasCounter) {
doca_gpu_dev_verbs_signal_counter<DOCA_GPUNETIO_VERBS_SIGNAL_OP_ADD, resource_sharing_mode>(
qp, sig_raddr, sig_laddr, signalOpArg, companion_qp, counter_raddr, counter_laddr, 1, codeOpt);
} else {
doca_gpu_dev_verbs_signal<DOCA_GPUNETIO_VERBS_SIGNAL_OP_ADD, resource_sharing_mode>(
qp, sig_raddr, sig_laddr, signalOpArg, codeOpt);
}
}
#ifdef NCCL_DEVICE_GIN_GDAKI_ENABLE_DEBUG
doca_gpu_dev_verbs_wait(qp);
if (hasCounter) doca_gpu_dev_verbs_wait(companion_qp);
#endif
}
coop.sync();
}offset作为地址信息,doca_gpu_dev_verbs_wqe_prepare_write将地址信息写入WQE中。
根据博客1,hasSignal和hasCounter的组合,分别对应几种使用模式:
最简单的 put(无完成动作)
cpp
__global__ void ginPutBasicExample(
ncclWindow_t sendWin, ncclWindow_t recvWin, ncclDevComm devComm)
{
ncclGin gin(devComm, /*contextIndex=*/0);
ncclTeam world = ncclTeamWorld(devComm);
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int nthreads = blockDim.x * gridDim.x;
size_t chunkSize = 4096;
// 最基本的 put:无任何完成动作
// 将自己 sendWin 偏移 0 处的 chunkSize 字节写入 peer 的 recvWin 偏移 0 处
int peer = (world.rank + 1) % world.nRanks; // 发送给下一个 rank
if (tid == 0) {
gin.put(world, peer,
recvWin, 0, // 远程目标
sendWin, 0, chunkSize); // 本地源, 无完成动作(均默认 ncclGin_None)
}
// 注意:此时无法知道数据何时落地到对端!
// 需要配合其他同步机制(信号、屏障等)
gin.flush(ncclCoopCta());
}put + SignalInc(最常用模式)
当数据落地到对端内存后,自动递增对端的信号值。接收端通过 waitSignal 检测数据到达。
cpp
__global__ void ginPutSignalIncExample(
ncclWindow_t sendWin, ncclWindow_t recvWin, ncclDevComm devComm)
{
ncclGin gin(devComm, 0);
ncclTeam world = ncclTeamWorld(devComm);
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int nthreads = blockDim.x * gridDim.x;
size_t perPeerSize = 1024 * sizeof(float);
unsigned signalId = 0;
// 先快照当前信号值(其他 rank 可能已经往我们写过数据)
uint64_t signalBefore = gin.readSignal(signalId);
// 向所有对端发送数据,每次 put 都附带 SignalInc
for (int r = tid; r < world.nRanks; r += nthreads) {
if (r == world.rank) continue; // 跳过自己
gin.put<ncclGin_SignalInc>( // RemoteAction = SignalInc
world, r,
recvWin, world.rank * perPeerSize, // 对端的接收偏移 = 发送者的 rank * 块大小
sendWin, r * perPeerSize, perPeerSize,
ncclGin_SignalInc{signalId}); // 数据落地后递增对端信号 0 一次
}
// 等待所有其他 rank 的数据到达本 rank
// 每个对端的 put 会让我们的 signal 递增 1,共 nRanks-1 个对端
gin.waitSignal(ncclCoopCta(), signalId,
signalBefore + (world.nRanks - 1));
gin.flush(ncclCoopCta());
// 此时 recvWin 中的数据已完整,可以安全读取
}put + CounterInc(本地发送端完成跟踪)
当源缓冲区的数据已被网络硬件读取("消费"),本地计数器递增。适用于需要复用发送缓冲区的流水线场景。
cpp
__global__ void ginPutCounterExample(
ncclWindow_t sendWin, ncclWindow_t recvWin, ncclDevComm devComm)
{
ncclGin gin(devComm, 0);
ncclTeam world = ncclTeamWorld(devComm);
unsigned signalId = 0;
unsigned counterId = 0;
size_t chunkSize = 4096;
// 发送第一个 chunk,同时跟踪远程到达(signal)和本地消费(counter)
gin.put<ncclGin_SignalInc, ncclGin_CounterInc>(
world, /*peer=*/1,
recvWin, 0,
sendWin, 0, chunkSize,
ncclGin_SignalInc{signalId}, // 远程:数据落地后递增对端信号
ncclGin_CounterInc{counterId}); // 本地:源缓冲区消费后递增计数器
// 等待本地计数器 = 1 → 说明第一个 chunk 的源数据已被网络硬件读走
gin.waitCounter(ncclCoopCta(), counterId, 1);
// 此时可以安全地复用 sendWin 偏移 0 处的 4096 字节,填入下一轮数据
float* sendLocal = (float*)ncclGetLocalPointer(sendWin, 0);
sendLocal[0] = 999.0f; // 安全!网络硬件已读完上一轮数据
// 发送第二个 chunk(复用同一缓冲区位置)
gin.put<ncclGin_SignalInc, ncclGin_CounterInc>(
world, 1,
recvWin, chunkSize,
sendWin, 0, chunkSize,
ncclGin_SignalInc{signalId},
ncclGin_CounterInc{counterId});
gin.waitCounter(ncclCoopCta(), counterId, 2);
gin.flush(ncclCoopCta());
}doca_gpu_dev_verbs_put_signal_counter
doca_gpu_dev_verbs_put_signal_counter处理流程
text
输入:qp (主QP), raddr (远端数据地址), laddr (本地数据地址), size,
sig_raddr/sig_laddr/sig_val (远端信号),
companion_qp, counter_raddr/counter_laddr/counter_val
Step 1: 分块计算
num_chunks = ceil(size / MAX_TRANSFER_SIZE)
Step 2: 预留主QP槽位
base_wqe_idx = doca_gpu_dev_verbs_reserve_wq_slots(qp, num_chunks + 1) // 数据WQE + 信号WQE
Step 3: 构造数据 Write WQE (循环 num_chunks 次)
for i = 0..num_chunks-1:
wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(qp, base_wqe_idx + i)
doca_gpu_dev_verbs_wqe_prepare_write(wqe_ptr,
raddr + i*MAX_SIZE, laddr + i*MAX_SIZE, size_i)
Step 4: 构造信号 Atomic WQE (Fetch & Add)
wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(qp, base_wqe_idx + num_chunks)
doca_gpu_dev_verbs_wqe_prepare_atomic(wqe_ptr, OP_ATOMIC_FA,
sig_raddr, sig_laddr, sig_val)
Step 5: 标记主QP的 WQE 就绪
doca_gpu_dev_verbs_mark_wqes_ready(qp, base_wqe_idx, base_wqe_idx+num_chunks)
Step 6: 预留 Companion QP 槽位 (2个WQE)
comp_base = doca_gpu_dev_verbs_reserve_wq_slots(companion_qp, 2)
Step 7: 在 Companion QP 上构造 Wait WQE (等待主QP的最后WQE完成)
wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(companion_qp, comp_base)
doca_gpu_dev_verbs_wqe_prepare_wait(wqe_ptr, wait_for_index = base_wqe_idx+num_chunks)
Step 8: 在 Companion QP 上构造本地计数器 Atomic WQE
wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(companion_qp, comp_base+1)
doca_gpu_dev_verbs_wqe_prepare_atomic(wqe_ptr, OP_ATOMIC_FA,
counter_raddr, counter_laddr, counter_val)
Step 9: 标记 Companion QP 的 WQE 就绪
doca_gpu_dev_verbs_mark_wqes_ready(companion_qp, comp_base, comp_base+1)
Step 10: 同时提交两个QP
qps[] = {qp, companion_qp}
prod_indices[] = {last_wqe_idx+1, comp_last_wqe_idx+1}
doca_gpu_dev_verbs_submit_multi_qps(qps, prod_indices)
硬件执行顺序 (网卡内部):
┌─────────────────────────────────────────────────────────────┐
│ 主QP顺序执行: │
│ Write #0 → Write #1 → ... → Write #N → Atomic (远端信号) │
│ │ │
│ └───→ 信号量 +sig_val │
│ │
│ 当最后一个WQE (Atomic) 完成时 → 产生CQE到主CQ │
└─────────────────────────────────────────────────────────────┘
│
↓ (触发等待)
┌─────────────────────────────────────────────────────────────┐
│ Companion QP顺序执行: │
│ WAIT (等待主CQ中指定CQE) → 条件满足 → Atomic (本地计数器)│
│ │
│ 本地计数器 +counter_val │
└─────────────────────────────────────────────────────────────┘doca_gpu_dev_verbs_wqe_prepare_write
doca_gpu_dev_verbs_wqe_prepare_write
该函数用于在 GPU 设备上构造一个 RDMA Write 操作的 WQE(工作队列元素)。它主要完成以下工作:
- 填充控制段(cseg):设置操作码、WQE 索引、QP 号(从 qp 结构读取并转换字节序)、控制标志以及可选的立即数。
- 填充远程地址段(rseg):设置远端目标内存地址(raddr)和 rkey,并进行必要的字节序转换。
- 填充数据段(dseg0):设置本地源内存地址(laddr0)、lkey0 和待传输的字节数(bytes0,并限制为内联段的最大值减一),同样进行字节序转换。
- 将三个段写入 WQE:通过 doca_gpu_dev_verbs_store_wqe_seg 依次将控制段、远程地址段和数据段存储到 WQE 指针所指向的 dseg0、dseg1、dseg2 位置。
mooncake中也有类似的函数:__mlx5gda_device_write_rdma_write_wqe。
WQE 内存布局(64 字节固定,以 ConnectX 系列为例):
text
┌─────────────────────────────────────────────────────────────┐
│ 控制段 (16B) │ 远端地址段 (16B) │ 数据段 (16B) │ ... │
│ - opcode (RDMA_WRITE)│ - raddr (64b) │ - laddr (64b) │ │
│ - wqe_idx │ - rkey (32b) │ - lkey (32b) │ │
│ - qpn_ds │ │ - byte_count │ │
│ - flags │ │ │ │
└─────────────────────────────────────────────────────────────┘
GPU SM 通过 st.weak.cs.v2.b64 指令一次写入两个 64-bit 字对应的结构体定义
cpp
struct doca_gpu_dev_verbs_wqe_ctrl_seg {
__be32 opmod_idx_opcode; /**< opcode + wqe idx */
__be32 qpn_ds; /**< qp number */
union {
struct {
uint8_t signature; /**< signature */
uint8_t rsvd[2]; /**< reserved */
uint8_t fm_ce_se; /**< fm_ce_se */
};
struct {
__be32 signature_fm_ce_se; /**< all flags in or */
};
};
__be32 imm; /**< immediate */
} __attribute__((__aligned__(8)));
struct doca_gpunetio_ib_mlx5_wqe_raddr_seg {
__be64 raddr;
__be32 rkey;
__be32 reserved;
};
struct doca_gpunetio_ib_mlx5_wqe_data_seg {
__be32 byte_count;
__be32 lkey;
__be64 addr;
};doca_gpu_dev_verbs_submit_multi_qps处理流程
text
doca_gpu_dev_verbs_submit_multi_qps 入口
│
├─ 获取 nic_handler 实际模式(若模板参数为 AUTO,则从 qps[0] 加载)
│
├─ 根据 nic_handler 分支
│
├─ 情况 1: NIC_HANDLER_GPU_SM_DB
│ └─ 调用 doca_gpu_dev_verbs_submit_db_multi_qps
│ │
│ ├─ 对每个 QP(num_qps >= 2):
│ │ ├─ [可选] 加锁 (resource_sharing_mode 相关)
│ │ ├─ atomic_max(&qp->sq_wqe_pi, prod_indices[i]) → 获取旧值
│ │ ├─ 若旧值 < 新值:
│ │ │ ├─ 加载 qp->sq_db 地址
│ │ │ ├─ 准备 db_val
│ │ │ ├─ 执行 fence_release (sync_scope)
│ │ │ ├─ 写入 Doorbell(relaxed MMIO 或 atomic_ref)
│ │ │ └─ [第一次 DB 写入 - Early ringing]
│ │ └─ [可选] 解锁(在第二阶段后)
│ │
│ └─ 对每个 QP 进行第二次 DB 写入(DBR 恢复):
│ ├─ doca_priv_gpu_dev_verbs_update_dbr
│ ├─ fence_release (至少 GPU 级作用域)
│ └─ 再次写入 Doorbell
│
├─ 情况 2: NIC_HANDLER_GPU_SM_NO_DBR
│ └─ 调用 doca_gpu_dev_verbs_submit_db_multi_qps_no_dbr
│ │
│ └─ 与情况 1 相同,但省略第二次 DB 写入(无 DBR 恢复)
│
└─ 情况 3: 其他(包括 NIC_HANDLER_GPU_PROXY 或未匹配)
└─ 调用 doca_gpu_dev_verbs_submit_proxy_multi_qps
│
├─ fence_release (sync_scope)
└─ 对每个 QP:
└─ doca_gpu_dev_verbs_ring_proxy (代理通知网卡)ginOffset4K 的计算
text
ncclDevrWindowRegisterInGroup
│
├─ 1. 本地注册内存 (ncclCommRegister)
│
├─ 2. 获取底层虚拟地址分配信息
│ ncclCuMemGetAddressRange(userPtr, userSize)
│ → 输出:
│ memAddr (底层分配的基地址)
│ memSize (分配大小)
│ numSegments (物理段数量)
│ hasSysmemSegment (是否包含系统内存段)
│
├─ 3. 计算窗口在分配内的字节偏移
│ memOffset = (CUdeviceptr)userPtr - memAddr
│ 【关键步骤:此偏移后续直接用于计算 ginOffset4K】
│
├─ 4. 对齐检查 (memOffset % 对齐要求)
│
├─ 5. 遍历每个物理段,保留分配句柄 (memHandles[])
│
├─ 6. 用句柄换取或复用 ncclDevrMemory 对象 (symMemoryObtain)
│ ├─ 若为新内存:
│ │ ├─ 分配 big VA space 偏移 (bigOffset)
│ │ ├─ 在 LSA 团队内映射 VA (symMemoryMapLsaTeam)
│ │ ├─ 若 GIN 已启用: 注册整个 Memory 到 GIN (symMemoryRegisterGin)
│ │ │ → 生成 ginDevWins[] (整个 Memory 的 RDMA 窗口句柄)
│ │ └─ 绑定多播团队 (symBindTeamMemory)
│ └─ 增加引用计数
│
├─ 7. 创建窗口 (symWindowCreate) ← 【ginOffset4K 在此赋值】
│ ├─ 分配窗口设备描述符 (ncclWindow_vidmem)
│ ├─ 填充描述符:
│ │ winDevHost->ginOffset4K = memOffset >> 12; ★ 核心 ★
│ │ winDevHost->ginWins[i] = mem->ginDevWins[i]; (拷贝 Memory 的 GIN 句柄)
│ │ winDevHost->bigOffset = mem->bigOffset + memOffset;
│ │ winDevHost->lsaFlatBase = ...;
│ │ winDevHost->worldRank / lsaRank 等
│ │
│ │ ★ ginOffset4K = (userPtr - memAddr) / 4096 ★
│ │ 表示窗口在底层分配内的 4KB 页偏移
│ │
│ └─ 将窗口插入窗口表并排序 (winSorted)
│
├─ 8. 同步流、全局 barrier
│
└─ 9. 将窗口插入全局映射表 (ncclIntruAddressMapInsert)ginOffset4K = (userPtr - memAddr) >> 12
- userPtr:用户调用 ncclCommWindowRegister 时提供的指针,即窗口起始地址
- memAddr:userPtr 所在的底层 cuMemCreate 虚拟分配基地址。这个基地址可能比 userPtr 低,差值就是窗口在分配内部的偏移。
- 右移 12 位:转换为 4KB 页 单位。GIN 硬件(特别是 GDAKI 路径)在进行 RDMA 操作时,地址字段填入的是一个字节偏移量,该偏移量 = ginOffset4K * 4096 + 窗口内偏移(dstOffset)。因此 ginOffset4K 预先除以 4096,可以在设备端通过 4096 * ginOffset4K 快速还原为字节偏移。
reference
2 NVIDIA NCCL 源码学习(十六)- nccl的ibgda(GIN