【PTQ】ERQ (ICML 2024)
摘要
问题: 激活量化和权重量化之间的误差存在相互依赖性,现有方法通常独立优化两者。
核心创新:
| 步骤 | 方法 | 作用 |
|---|---|---|
| Aqer(Activation Quantization Error Reduction) | 将激活量化误差最小化建模为 Ridge Regression 问题 | 在保持权重全精度的前提下更新激活缩放 |
| Wqer(Weight Quantization Error Reduction) | 迭代优化量化权重的舍入方向,使用代理指标 + Ridge Regression | 进一步降低量化权重带来的误差 |
结果: 在 W3A4(3-bit 权重,4-bit 激活)ViT-S 上,精度超过 GPTQ 方法最高达 22.36%--36.81%。
意义: 首次系统考虑了激活/权重量化的误差耦合关系,提出了两阶段协同优化框架。
instruction
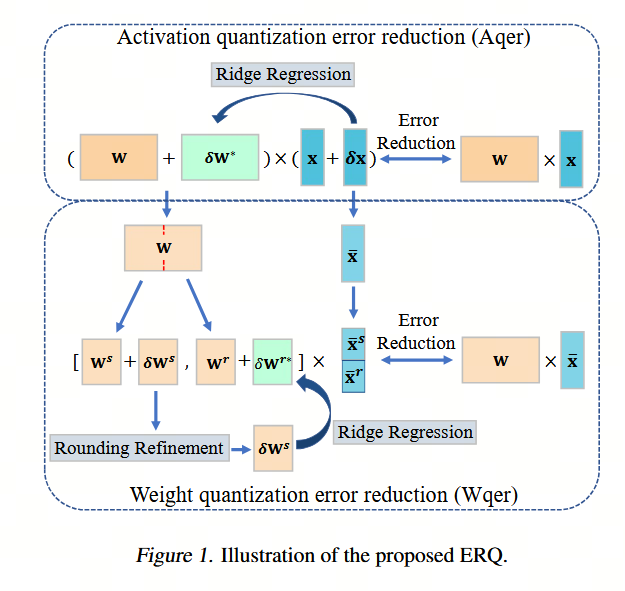
我们将 W W W 划分为两个部分:前半部分 W s i , : ∈ R 1 × D s in W_s^{i,:} \in \mathbb{R}^{1 \times D_s^{\text{in}}} Wsi,:∈R1×Dsin 被指定用于量化,而剩余部分 W r i , : ∈ R 1 × D r in W_r^{i,:} \in \mathbb{R}^{1 \times D_r^{\text{in}}} Wri,:∈R1×Drin 则保持全精度。相应地,我们得到 x ˉ s ∈ R D s in \bar{x}_s \in \mathbb{R}^{D_s^{\text{in}}} xˉs∈RDsin 和 x ˉ r ∈ R D r in \bar{x}_r \in \mathbb{R}^{D_r^{\text{in}}} xˉr∈RDrin。
3. Preliminaries
对于除 Softmax 激活之后的激活值之外的所有权重和激活值,我们采用均匀量化器。给定全精度值 x x x 和位宽 b b b,均匀量化器定义如下。对于长尾分布的 Softmax 后激活,采用 log√2 量化器(Li 等,2023)。

目标损失:

4. Method
4.1. Activation Quantization Error Reduction
为减轻激活量化引入的误差,我们引入了激活量化误差减少(Aqer)方法。
在深度学习中,为了减少模型体积和加速推理,研究人员常使用模型量化技术,即将原本使用高精度浮点数(如 FP32)存储的数据转换为低精度格式(如 INT8)。
然而,量化会带来误差:
- 激活量化误差 ( δ x \delta x δx):输入数据或中间层激活值在量化过程中产生的细微偏差。
- 传统做法通常只关注权重本身的量化,而忽略了激活值量化对最终输出精度的影响。
本文的核心观点是:如果我们在训练或校准阶段,主动调整网络的权重(Weight),使其能够"抵消"或"补偿"激活值量化带来的误差,那么即使使用低精度激活值,模型的整体精度也不会下降太多。
4.1.2. 核心概念与术语澄清
在深入公式之前,我们先厘清几个关键符号:
- W W W:原始的网络权重矩阵。
- x x x:原始(未量化)的输入激活值。
- δ x \delta x δx :激活量化误差。即量化后的值与原始值之间的差值。
- x ˉ = x + δ x \bar{x} = x + \delta x xˉ=x+δx :量化后的激活值 (Quantized Input)。注意:原文定义 x ˉ \bar{x} xˉ 为量化后的输入。
- δ W ∗ \delta W^* δW∗ :我们需要计算出的权重调整量 。我们要找到这个调整量,加到原始权重 W W W 上,形成新的权重 W + δ W ∗ W + \delta W^* W+δW∗。
- MSE (Mean Squared Error):均方误差,用来衡量预测值与真实值之间的差距。
- 岭回归 (Ridge Regression):一种正则化的线性回归方法。它不仅试图最小化误差,还通过添加惩罚项来防止模型过拟合,并确保数学上的稳定性。
4.1.3. 文本逻辑与数学推导详解
这段文本展示了一个完整的数学建模过程,旨在求解最优的权重调整量 δ W ∗ \delta W^* δW∗。我们可以将其分为三个步骤:
第一步:定义目标(最小化误差)
文本首先定义了我们要最小化的对象。
如果不进行任何调整,量化激活值 x + δ x x+\delta x x+δx 带来的误差是:
L M S E = E ∥ W x − W ( x + δ x ) ∥ 2 2 L_{MSE} = \mathbb{E} \\\| Wx - W(x + \\delta x) \\\|_2\^2 LMSE=E∥Wx−W(x+δx)∥22
这表示:原始权重乘以原始输入,与原始权重乘以量化后输入之间的差异。
第二步:引入调整项,构建岭回归问题
我们希望通过调整权重来减轻这个误差。假设调整后的权重为 W + δ W ∗ W + \delta W^* W+δW∗。
此时,量化激活值 ( x + δ x ) (x + \delta x) (x+δx) 乘以新权重后的输出应与原始输出 W x Wx Wx 尽可能接近。
文本将目标函数改写为公式 (6):
E ∥ δ W ∗ x ˉ + W δ x ∥ 2 2 + λ 1 ∥ δ W ∗ ∥ 2 2 \mathbb{E} \\\| \\delta W\^\* \\bar{x} + W\\delta x \\\|_2\^2 + \lambda_1 \| \delta W^* \|_2^2 E∥δW∗xˉ+Wδx∥22+λ1∥δW∗∥22
这里有两个部分:
- 误差项 ∥ δ W ∗ x ˉ + W δ x ∥ 2 2 \| \delta W^* \bar{x} + W\delta x \|_2^2 ∥δW∗xˉ+Wδx∥22:我们希望这个值越小越好。通过推导,这部分代表了"调整后的权重"与"量化误差"之间的相互作用。
- 正则化项 λ 1 ∥ δ W ∗ ∥ 2 2 \lambda_1 \| \delta W^* \|_2^2 λ1∥δW∗∥22:这是岭回归的核心。
- λ 1 \lambda_1 λ1 是一个超参数,控制正则化的强度。
- 它的作用是限制 δ W ∗ \delta W^* δW∗ 的大小,防止调整幅度过大导致模型不稳定或过拟合。
第三步:求解最优解
为了找到使上述公式最小的 δ W ∗ \delta W^* δW∗,作者使用了微积分中的梯度下降思想(这里是解析解):
- 对 δ W ∗ \delta W^* δW∗ 求导(公式 7)。
- 令导数为 0,解出 δ W ∗ \delta W^* δW∗(公式 8)。
最终得到的解为:
δ W ∗ = − W E δ x x ˉ T ( E x ˉ x ˉ T + λ 1 I ) − 1 \delta W^* = - W \mathbb{E}\\delta x \\bar{x}\^T (\mathbb{E}\\bar{x} \\bar{x}\^T + \lambda_1 I)^{-1} δW∗=−WEδxxˉT(ExˉxˉT+λ1I)−1
这个公式的含义是:
- 我们需要统计校准数据集中,激活误差 δ x \delta x δx 和量化输入 x ˉ \bar{x} xˉ 的相关性( E δ x x ˉ T \mathbb{E}\\delta x \\bar{x}\^T EδxxˉT)。
- 我们需要统计量化输入 x ˉ \bar{x} xˉ 自身的协方差矩阵( E x ˉ x ˉ T \mathbb{E}\\bar{x} \\bar{x}\^T ExˉxˉT)。
- 利用这些统计量,结合原始权重 W W W,计算出每一个权重应该微调多少( δ W ∗ \delta W^* δW∗)。
第四步:实际应用与结果
- 正则化矩阵求逆的重要性 :公式中的 ( E x ˉ x ˉ T + λ 1 I ) − 1 (\mathbb{E}\\bar{x} \\bar{x}\^T + \lambda_1 I)^{-1} (ExˉxˉT+λ1I)−1 部分,加上单位矩阵 I I I 是为了确保矩阵可逆(因为如果数据存在多重共线性,直接求逆会失败)。这保证了计算的数值稳定性。
- 抑制离群值(Outliers):正则化还能抑制极端值的影响,防止模型过度拟合某些特殊样本。
- 便于后续量化 :文本最后提到,通过这种方式调整权重,可以将权重的分布范围限制在一个更合理的区间内。这对于后续的权重量化至关重要,因为如果权重范围太大,低精度量化会丢失大量信息。
4.1.4. 关键洞察与意义总结
A. 核心创新点:将"激活量化误差"转化为"权重调整"
通常,量化误差被视为一种需要忍受的噪声。但 Aqer 方法认为,我们可以通过微调权重来主动补偿这种误差。这就像你在听一个有背景噪音(激活误差)的电话时,通过调整自己的音量或语调(权重调整)来让对话更清晰。
B. 为什么使用岭回归?
- 稳定性 :深度学习中的数据往往存在相关性,直接使用最小二乘法求解可能会遇到矩阵不可逆的问题。岭回归通过 λ I \lambda I λI 解决了这个问题。
- 泛化能力 :正则化项 λ 1 ∥ δ W ∗ ∥ 2 2 \lambda_1 \| \delta W^* \|_2^2 λ1∥δW∗∥22 防止调整量 δ W ∗ \delta W^* δW∗ 变得过大,从而保证模型在未见过的数据上也能表现良好(防止过拟合)。
- 兼容后续量化:控制权重调整的大小,有助于保持权重的数值分布稳定,这对后续将权重本身也进行量化(例如从 FP16 量化为 INT8)非常有利。
C. 实际计算流程
- 准备校准数据集 :选取一小批具有代表性的数据(大小为 B × T B \times T B×T)。
- 前向传播并量化 :计算这些数据的量化激活值 x ˉ \bar{x} xˉ 和误差 δ x \delta x δx。
- 统计期望 :计算样本均值 1 N ∑ δ x n x ˉ n T \frac{1}{N} \sum \delta x_n \bar{x}_n^T N1∑δxnxˉnT 和 1 N ∑ x ˉ n x ˉ n T \frac{1}{N} \sum \bar{x}_n \bar{x}_n^T N1∑xˉnxˉnT。
- 求解 δ W ∗ \delta W^* δW∗:代入公式 (8) 计算出每个层的权重调整量。
- 更新权重 :执行 W n e w = W o l d + δ W ∗ W_{new} = W_{old} + \delta W^* Wnew=Wold+δW∗。
4.2. Weight Quantization Error Reduction
在 Aqer 之后,我们执行权重量化,并提出权重量化误差降低(Wqer)方法。
文本中出现的公式定义了目标函数:
LMSE = E ∥ W ˉ x ˉ − ( W ˉ + δ W ˉ ) x ˉ ∥ 2 2 \text{LMSE} = \mathbb{E} \\\| \\bar{W}\\bar{x} - (\\bar{W} + \\delta\\bar{W})\\bar{x} \\\|_2\^2 LMSE=E∥Wˉxˉ−(Wˉ+δWˉ)xˉ∥22
- LMSE (Local Mean Squared Error,局部均方误差) :
- 这是一个损失函数(Loss Function),用来衡量"量化后的权重"与"原始全精度权重"在产生输出时的差异。
- W ˉ \bar{W} Wˉ:代表原始的、高精度的权重矩阵(Full-precision weights)。
- x ˉ \bar{x} xˉ:代表输入数据或激活值(Activations)。
- δ W ˉ \delta\bar{W} δWˉ :代表量化引入的误差权重(Quantization error weight)。简单来说,量化后的权重可以看作是 W q u a n t i z e d = W o r i g i n a l + δ W W_{quantized} = W_{original} + \delta W Wquantized=Woriginal+δW。
- ∥ ⋅ ∥ 2 2 \| \cdot \|_2^2 ∥⋅∥22:表示欧几里得距离的平方,即计算向量之间差的平方和。
- E \mathbb{E} E:表示期望值(Expected Value),即在整个数据集上的平均表现。
4.2.2. 数学拆解与独立性分析
文本指出:
LMSE = ∑ i = 1 D o u t LMSE i = ∑ i = 1 D o u t E ∥ W i , : x ˉ − ( W i , : + δ W i , : ) x ˉ ∥ 2 2 \text{LMSE} = \sum_{i=1}^{D_{out}} \text{LMSE}i = \sum{i=1}^{D_{out}} \mathbb{E} \\\| W_{i,:} \\bar{x} - (W_{i,:} + \\delta W_{i,:})\\bar{x} \\\|_2\^2 LMSE=i=1∑DoutLMSEi=i=1∑DoutE∥Wi,:xˉ−(Wi,:+δWi,:)xˉ∥22
- 关键洞察 :等式将总的误差分解为对每个输出通道(Output Channel) i i i 的误差求和。
- W i , : W_{i,:} Wi,: :表示权重矩阵的第 i i i 行。在卷积神经网络(CNN)或全连接层中,这对应于产生特定输出特征图的那个神经元或滤波器。
- 独立性结论 :文本强调,"minimization across output channels operates independently"(跨输出通道的最小化操作是相互独立的)。
- 这意味着,我们在优化第 1 个通道的量化误差时,不需要考虑第 2 个通道。我们可以单独处理每一个输出通道,最后再汇总。这大大简化了计算复杂度。
具体而言,我们首先从当前的全精度权重 W_i: 及其对应的 x ˉ \bar{x} xˉ 开始。随后,我们将 W W W 划分为两个部分:前半部分 W s i , : ∈ R 1 × D s in W_s^{i,:} \in \mathbb{R}^{1 \times D_s^{\text{in}}} Wsi,:∈R1×Dsin 被指定用于量化,而剩余部分 W r i , : ∈ R 1 × D r in W_r^{i,:} \in \mathbb{R}^{1 \times D_r^{\text{in}}} Wri,:∈R1×Drin 则保持全精度。相应地,我们得到 x ˉ s ∈ R D s in \bar{x}_s \in \mathbb{R}^{D_s^{\text{in}}} xˉs∈RDsin 和 x ˉ r ∈ R D r in \bar{x}_r \in \mathbb{R}^{D_r^{\text{in}}} xˉr∈RDrin。
其中, x ˉ s \bar{x}s xˉs 和 x ˉ r \bar{x}r xˉr 分别包含 x ˉ \bar{x} xˉ 中对应于 W s , i , : W{s,i,:} Ws,i,: 和 W r , i , : W{r,i,:} Wr,i,: 的行。量化后 W s , i , : W_{s,i,:} Ws,i,: 的量化误差记为 δ W s , i , : = W ˉ s , i , : − W s , i , : \delta W_{s,i,:} = \bar{W}{s,i,:} - W{s,i,:} δWs,i,:=Wˉs,i,:−Ws,i,:,由此得到的均方误差(MSE)为
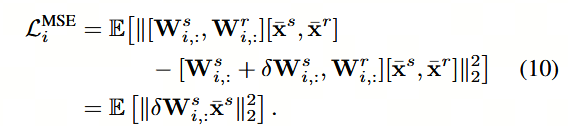
在此,定义 W i : = W i , : s , W i , : r W_i := W_{i,:}\^s, W_{i,:}\^r Wi:=Wi,:s,Wi,:r, x ˉ = x ˉ s , x ˉ r \bar{x} = \\bar{x}\^s, \\bar{x}\^r xˉ=xˉs,xˉr。为减轻公式 (10) 中的误差,我们首先引入舍入优化(Rounding Refinement)步骤,在该步骤中,对量化权重的舍入方向进行优化,即调整 δ W i , : s \delta W_{i,:}^s δWi,:s,以直接减小 E ∥ δ W i , : s x ˉ s ∥ 2 2 \mathbb{E}\left\\\|\\delta W_{i,:}\^s \\bar{x}\^s\\\|_2\^2\\right E∥δWi,:sxˉs∥22 本身。随后,在舍入优化得到 E ∥ δ W i , : s x ˉ s ∥ 2 2 \mathbb{E}\left\\\|\\delta W_{i,:}\^s \\bar{x}\^s\\\|_2\^2\\right E∥δWi,:sxˉs∥22 的基础上,我们构建一个岭回归(Ridge Regression)问题,通过调整 W i , : r W_{i,:}^r Wi,:r 来进一步减轻该误差。
4.2.1. ROUNDING REFINEMENT
量化通常涉及"舍入"(Rounding)。例如,一个权重值是 3.7,量化后可能需要变成 4 或 `3"。
-
向下舍入(Floor, ⌊ ⋅ ⌋ \lfloor \cdot \rfloor ⌊⋅⌋)与向上舍入(Ceil, ⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉):
- 文本中提到的
Qun↓和Qun↑指的是两种舍入策略。 - 对于非整数值,量化误差( δ \delta δ)就是原值与量化后值的差。
- δ ↓ > 0 \delta^{\downarrow} > 0 δ↓>0:如果你向下取整(Floor),量化后的值比原值小,所以误差是正的。
- δ ↑ < 0 \delta^{\uparrow} < 0 δ↑<0:如果你向上取整(Ceil),量化后的值比原值大,所以误差是负的。
- 文本中提到的
-
目标函数 E ∥ δ W i , : x ˉ s ∥ 2 2 E\\\|\\delta W_{i,:} \\bar{x}_s\\\|_2\^2 E∥δWi,:xˉs∥22:
- 这是作者试图最小化的量化误差损失。
- W i , : W_{i,:} Wi,::表示矩阵 W W W 的第 i i i 行(即连接到某个神经元的所有输入权重)。
- x ˉ s \bar{x}_s xˉs:表示输入数据或激活值。
- δ W \delta W δW:量化误差向量。
- 这个公式计算的是:由于权重舍入产生的误差,在经过输入数据加权后,最终输出端产生的均方误差(Mean Squared Error)。 简单说,就是衡量"因为把权重舍入整数,导致最终预测结果偏离了多少"。
-
NP-hard 问题:
- 这是一个计算复杂性理论中的术语。意思是,随着神经网络层数和权重的数量增加,寻找全局最优的舍入组合所需的时间会呈指数级增长。理论上没有已知的快速算法能在合理时间内解决所有情况。
-
MIPQ (Mixed-Integer Quadratic Programming,混合整数二次规划):
- 这是一种数学优化技术,专门用来解决包含整数约束和非线性目标函数的问题。在这里,作者试图用 MIPQ 来精确地决定每个权重应该向下舍入还是向上舍入,以使总误差最小。
分为两个阶段:理想化的精确解 vs 实际中的高效替代方案。
第一阶段:理想目标与遇到的瓶颈
- 目标 :我们要调整量化权重的舍入方向(向上或向下),使得量化后的模型与原始模型之间的误差( E ∥ δ W i , : x ˉ s ∥ 2 2 E\\\|\\delta W_{i,:} \\bar{x}_s\\\|_2\^2 E∥δWi,:xˉs∥22)最小。
- 方法:使用 MIPQ 算法来寻找最优解。
- 困境 :
- 这是一个 NP-hard 问题,计算量巨大。
- 直接计算上述复杂的误差公式并作为 MIPQ 的目标函数,耗时极长。
- 数据支撑 :文本提到表 1 显示,这样做需要约 130小时。这对于工程应用来说是完全不可接受的(通常我们希望量化过程在几分钟或几小时内完成,而不是几天)。
第二阶段:提出解决方案------高效代理(Efficient Proxy)
- 动机:既然精确计算太慢,我们需要找一个"代理"(Proxy),即一个计算简单、速度快,但又能近似反映真实误差的数学表达式。
- 数学推导 :
作者利用了概率论中的基本恒等式将复杂的目标函数分解:
E ∥ δ W i , : x ˉ s ∥ 2 2 = ( E δ W i , : x ˉ s ) 2 + V a r ( δ W i , : x ˉ s ) E\\\|\\delta W_{i,:} \\bar{x}_s\\\|_2\^2 = (E\\delta W_{i,:} \\bar{x}_s)^2 + Var(\delta W_{i,:} \bar{x}_s) E∥δWi,:xˉs∥22=(EδWi,:xˉs)2+Var(δWi,:xˉs)- E ⋅ E\\cdot E⋅ 表示期望(平均值)。
- V a r ( ⋅ ) Var(\cdot) Var(⋅) 表示方差。
- 这个等式表明,总误差可以分解为偏差的平方 (Bias项)加上方差(Variance项)。
隐含意义 :
虽然文本在此处截断,但通常这种分解的目的是为了后续引入更简单的近似。例如,如果假设输入 x ˉ s \bar{x}_s xˉs 和误差 δ W \delta W δW 是独立分布的,或者均值接近零,那么 ( E ... ) 2 (E\\dots)^2 (E...)2 这一项可能很小,或者可以通过统计特性快速估计,而不需要每次都进行复杂的矩阵乘法运算。这就是所谓的"Efficient Proxy"------用一个计算成本极低但物理意义相近的公式来替换那个昂贵的 130 小时计算。
此处, Δ \Delta Δ 表示利用 E Z 2 = ( E Z ) 2 + Var Z EZ\^2 = (EZ)^2 + \text{Var}Z EZ2=(EZ)2+VarZ。正如 (Klambauer et al., 2017) 所证明的,根据中心极限定理,神经网络内部众多的乘法和加法运算使得激活值通常服从高斯分布,这也是量化领域许多先前工作中的基本假设 (Ding et al., 2019; Sun et al., 2022; Lin et al., 2022; Chmiel et al., 2020)。同时,图 2 展示了全精度与量化激活值的通道分布。可以看出,量化激活值仍然表现出近似的高斯分布 (Krishnamoorthi, 2018)。因此,我们认为 x ˉ s \bar{x}_s xˉs 的通道分布仍可由高斯分布来捕捉,并用维度为 D s in D_s^{\text{in}} Dsin 的高斯分布 N ( μ s , Σ s ) \mathcal{N}(\mu_s, \Sigma_s) N(μs,Σs) 对 x ˉ s \bar{x}_s xˉs 进行建模,其中 μ s ∈ R D s in \mu_s \in \mathbb{R}^{D_s^{\text{in}}} μs∈RDsin, Σ s ∈ R D s in × D s in \Sigma_s \in \mathbb{R}^{D_s^{\text{in}} \times D_s^{\text{in}}} Σs∈RDsin×Dsin。于是,公式 (11) 变为:
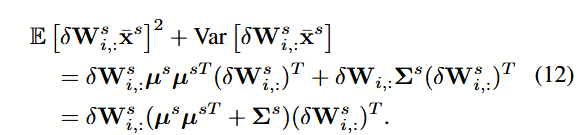
此处,公式(12)是用于近似 E ∥ δ W i , : s x ˉ s ∥ 2 2 E\\\|\\delta W\^s_{i,:} \\bar{x}_s\\\|_2\^2 E∥δWi,:sxˉs∥22 的代理量。在实际应用中,我们利用给定的校准数据集来估计经验均值 μ ^ s \hat{\mu}_s μ^s 和经验协方差矩阵 Σ ^ s \hat{\Sigma}_s Σ^s。需要注意的是,对于所有输出通道, μ ^ s \hat{\mu}_s μ^s 和 Σ ^ s \hat{\Sigma}_s Σ^s 均为共享参数,仅需计算一次。图 3 展示了该代理量与真实期望值 E ∥ δ W i , : s x ˉ s ∥ 2 2 E\\\|\\delta W\^s_{i,:} \\bar{x}_s\\\|_2\^2 E∥δWi,:sxˉs∥22 之间的关系。可以看出,所提出的代理量与真实值呈比例关系,从而验证了其保真度。
使用我们的代理方法的计算复杂度为 O ( ( D s in ) 2 ) O((D_s^{\text{in}})^2) O((Dsin)2),而计算 E ∥ δ W s i , : x ˉ s ∥ 2 2 E \|\delta W_s^{i,:} \bar{x}_s\|_2^2 E∥δWsi,:xˉs∥22 的复杂度为 O ( N D s in ) O(N D_s^{\text{in}}) O(NDsin),其中 N ≫ D s in N \gg D_s^{\text{in}} N≫Dsin。因此,该代理方法可作为一种低成本目标函数,用于求解 δ W s i , : \delta W_s^{i,:} δWsi,:。
文本的逻辑分为三个主要步骤:
- δ W i , j s \delta W^s_{i,j} δWi,js :这是第 s s s 层、第 i i i 行、第 j j j 列的权重更新值或量化误差项。它是一个浮点数。
- δ W i , j ↓ \delta W^\downarrow_{i,j} δWi,j↓ 和 δ W i , j ↑ \delta W^\uparrow_{i,j} δWi,j↑ :分别代表对该数值进行向下舍入 (向下取整)和向上舍入 (向上取整)后的离散值。
- 例子 :如果 δ W i , j s = 3.7 \delta W^s_{i,j} = 3.7 δWi,js=3.7,那么 δ W ↓ = 3 \delta W^\downarrow = 3 δW↓=3, δ W ↑ = 4 \delta W^\uparrow = 4 δW↑=4。
- 索引集合 S S S :这是一组特定的位置索引 ( i , j ) (i, j) (i,j)。算法决定只修改集合 S S S 中元素的舍入方向,而保持其他元素不变。这样做是为了节省计算资源,只"修复"那些对误差影响最大的关键部分。
- 代理函数(Proxy, Eq. 12):虽然原文未给出 Eq. 12,但从上下文看,这是一个用来衡量当前量化方案优劣的目标函数(通常是均方误差 MSE 或类似指标)。算法通过最小化这个"代理"来优化模型。
- 梯度 G δ W i , : s G_{\delta W^s_{i,:}} GδWi,:s:这是损失函数相对于权重的导数。在优化理论中,梯度告诉我们:如果稍微改变权重,误差会发生什么变化。
第一步:初始状态
首先,所有权重都使用标准的"最近舍入"策略。此时,每个权重要么是向下舍入的,要么是向上舍入的。
δ W i , j s ∈ { δ W i , j ↓ , δ W i , j ↑ } \delta W^s_{i,j} \in \{ \delta W^\downarrow_{i,j}, \delta W^\uparrow_{i,j} \} δWi,js∈{δWi,j↓,δWi,j↑}
第二步:寻找需要反转的元素(集合 S S S)
算法的目标是找到一组索引 S S S,将这些位置的舍入方向"反转"(Overturn)。
- 如果原本应该向下舍入,现在改为向上;
- 如果原本应该向上舍入,现在改为向下。
关键约束:并不是所有位置都可以随意反转。只有当反转能减小误差时,反转才是合法的。
第三步:利用梯度筛选 S S S
这是文本中最核心的数学部分。
-
计算梯度 :
G δ W i , : s = 2 δ W i , : s ( μ s μ s T + Σ s ) G_{\delta W^s_{i,:}} = 2\delta W^s_{i,:}(\mu_s\mu_s^T + \Sigma_s) GδWi,:s=2δWi,:s(μsμsT+Σs)这里计算的是误差关于权重的变化率。
-
判断可行性(同符号原则) :
文本指出:"We only select the elements whose gradients are the same sign... since this is the only way to allow overturn."
- 解释 :假设当前权重 δ W i , j s \delta W^s_{i,j} δWi,js 是负数(即 δ W i , j s = δ W i , j ↓ \delta W^s_{i,j} = \delta W^\downarrow_{i,j} δWi,js=δWi,j↓,且值为负,例如 -3.7 舍入为 -4)。
- 如果我们想把它"反转"变成 δ W i , j ↑ \delta W^\uparrow_{i,j} δWi,j↑(即 -3),我们需要看梯度 G G G 的符号。
- 直观理解:在优化中,我们要向梯度的反方向更新权重以减少损失。但如果我们要做一个离散的"跳跃"(从向下舍入跳到向上舍入),只有当梯度方向与我们想要移动的方向一致时,这个跳跃才是"有利"的(即能降低误差代理值)。
- 简化逻辑 :如果当前值是负的(向下舍入),且梯度也是负的,说明往负方向走(或保持负趋势)有助于降低误差。此时,如果我们强行将其改为向上舍入(变得更接近0,即变大),我们需要确认这种变化是否符合梯度指示的优化方向。公式 (15) 中的点积( ⊙ \odot ⊙)正是用来检查当前权重符号 与梯度符号是否一致。
-
选择 Top-k 元素 :
M = ∣ G δ W i , : s ⊙ 1 ( G δ W i , : s ⊙ δ W i , : s ) ∣ M = |G_{\delta W^s_{i,:}} \odot 1(G_{\delta W^s_{i,:}} \odot \delta W^s_{i,:})| M=∣GδWi,:s⊙1(GδWi,:s⊙δWi,:s)∣1(...)是一个指示函数,如果括号内非负则为1,否则为0。这用于筛选出"符号相同"的元素。|...|取绝对值,计算这些候选元素对误差影响的"大小"(重要性)。topk index(M):选出影响最大(绝对值最大)的前 k k k 个元素。这些元素是被选中进行舍入方向反转的候选者。
4.2.2. RIDGE REGRESSION
在完成舍入细化之后,我们建议利用 δ W i , : ∗ \delta W^*{i,:} δWi,:∗ 对 W i , : W{i,:} Wi,: 进行调整,以进一步抵消
E ∥ δ W i , : s x ˉ s ∥ 2 2 \mathbb{E} \left \\\| \\delta W\^s_{i,:} \\bar{x}_s \\\|_2\^2 \\right E∥δWi,:sxˉs∥22。
在深度学习(Deep Learning)中,模型由很多层组成,每一层都有大量的参数(权重,Weight)。
- w ˉ s \bar{w}_s wˉs (Source/Static Weights): 通常指那些被固定下来、或者作为基准的权重(例如在量化过程中,参考权重或主权重)。
- w ˉ r \bar{w}_r wˉr (Correction/Residual Weights): 指用于修正或微调的权重。
- x ˉ s \bar{x}_s xˉs 和 x ˉ r \bar{x}_r xˉr: 分别对应这两个权重分支的输入数据。
这段文字的核心目标 是:找到一个新的权重更新量 δ w r \delta w_r δwr,使得当我们用它去修正原始权重时,模型的预测结果与真实标签之间的误差最小化。同时,为了防止模型"过拟合"(即死记硬背训练数据而导致泛化能力差),作者加入了一个正则化项。
第一部分:损失函数(Loss Term)
E w ˉ s x ˉ s + δ w r x ˉ r i − y ˉ E \\bar{w}_{s} \\bar{x}_{s} + \\delta w_{r} \\bar{x}_{r} _i - \bar{y} Ewˉsxˉs+δwrxˉri−yˉ
(注:原文符号略有省略,根据上下文推断, y ˉ \bar{y} yˉ 代表真实标签 Target。原文写的是 E ⋯ − target E \dots - \text{target} E⋯−target,即预测值与真实值之差)
- 含义 :这是**均方误差(Mean Squared Error, MSE)**的形式。
- w ˉ s x ˉ s \bar{w}{s} \bar{x}{s} wˉsxˉs:这是基于固定权重的初始预测。
- δ w r x ˉ r \delta w_{r} \bar{x}_{r} δwrxˉr:这是我们要优化的部分,即权重的变化量带来的输出变化。
- 整个第一项试图让"初始预测 + 修正后的预测"尽可能接近"真实目标(Target)"。
第二部分:正则化项(Regularization Term)
λ 2 ∥ δ w r ∥ 2 2 \lambda_2 \| \delta w_{r} \|_2^2 λ2∥δwr∥22
- ∥ ⋅ ∥ 2 \| \cdot \|_2 ∥⋅∥2 :表示向量的 L2 范数(即欧几里得距离的平方)。简单来说,它是衡量向量长度的指标。
- λ 2 \lambda_2 λ2 (Lambda-2) :这是一个超参数(Hyper-parameter) 。
- 作用:控制正则化的强度。
- 目的 :如果我们只最小化第一项,模型可能会让 δ w r \delta w_r δwr 变得非常大以完美拟合噪声数据,导致过拟合。加入这一项后,算法不仅要求误差小,还要求权重的变化量 δ w r \delta w_r δwr 尽可能小且平滑。这有助于提高模型的稳定性。
总结公式 (16) :这是一个标准的带 L2 正则化的最小二乘法问题 ,在机器学习中被称为岭回归(Ridge Regression)。
3. 求解过程:如何得到最优解?
文本提到,最小化公式 (16) 的解由公式 (17) 给出:
δ w r , i , : ∗ = − δ w s , i , : E x ˉ s x ˉ r T ( E x ˉ r x ˉ r T + λ 2 I ) − 1 \delta w_{r, i,:}^* = - \delta w_{s, i,:} E \\bar{x}_s \\bar{x}_r\^T ( E \\bar{x}_r \\bar{x}_r\^T + \lambda_2 I )^{-1} δwr,i,:∗=−δws,i,:ExˉsxˉrT(ExˉrxˉrT+λ2I)−1
这里涉及几个关键步骤:
-
期望值 E ⋅ E\\cdot E⋅ 的估计:
- 理论上是数学上的期望值,但在实际计算机操作中,我们无法计算无限的期望。
- 文本解释 :用样本平均值来代替期望值。
- 1 N ∑ n = 1 N x ˉ r , n x ˉ s , n T \frac{1}{N} \sum_{n=1}^{N} \bar{x}{r,n} \bar{x}{s,n}^T N1n=1∑Nxˉr,nxˉs,nT
- 这意味着算法会遍历 N N N 个数据样本,计算输入向量的外积(Outer Product),然后取平均值。这在统计学中是协方差矩阵的标准估计方法。
-
矩阵求逆:
- ( E x ˉ r x ˉ r T + λ 2 I ) − 1 (E \\bar{x}_r \\bar{x}_r\^T + \lambda_2 I)^{-1} (ExˉrxˉrT+λ2I)−1:这是对协方差矩阵加上一个单位矩阵的倍数后求逆。这是岭回归的核心数学技巧,确保矩阵是可逆的(即使数据存在共线性),并且防止数值计算中的不稳定。
-
最终更新:
- w r , i , : = w r , i , : + δ w r , i , : ∗ w_{r, i,:} = w_{r, i,:} + \delta w_{r, i,:}^* wr,i,:=wr,i,:+δwr,i,:∗
- 得到最优的更新量后,直接将其加到当前的权重 w r w_r wr 上,从而完成修正。
- 流程回顾 :
- 定义目标:最小化预测误差 + 权重变化幅度。
- 估算统计量:用样本数据计算输入向量的协方差。
- 求解公式:利用矩阵代数求出最优权重更新量。
- 执行更新:将高精度权重加上这个更新量,完成迭代。
通过这种方式,模型能够在不进行全量反向传播(Backpropagation)的情况下,利用前向传播统计的信息来高效地微调权重。
评价一下!最终部署时, δ W \delta W δW 是什么格式?
**在优化和计算阶段,这些"改善量"(修正量)本质上是浮点数。
1. 在优化阶段必须是浮点数?
在论文提出的 Aqer 和 Wqer 过程中,数学推导(如岭回归、梯度下降、矩阵求逆)都依赖于连续空间的数学运算。
- 岭回归求解 :公式 (17) δ W ∗ = − ... ( E x ˉ x ˉ T + λ I ) − 1 \delta W^* = -\dots (E\\bar{x}\\bar{x}\^T + \lambda I)^{-1} δW∗=−...(ExˉxˉT+λI)−1 中涉及矩阵求逆。整数运算无法直接进行这种复杂的线性代数求解(除非使用专门的整数优化器,但效率极低)。因此,在寻找最优解 的过程中, δ W \delta W δW 必须是浮点数。
- 舍入方向的微调:在 Rounding Refinement 中,作者通过比较梯度来决策是向上舍入还是向下舍入。这个决策过程是离散的,但评估其优劣(计算 Proxy)时,依然是在浮点域进行的。
结论 :在训练/校准/优化阶段 , δ W \delta W δW 是一个浮点数向量。
2. 最终部署时, δ W \delta W δW 是什么格式?
这里需要区分"全精度修正"和"完全量化"两种路径。
路径 A:混合精度推理(常见于大多数 PTQ 方案)
很多先进的量化技术(包括本文提到的这类基于误差建模的方法)并不一定强迫所有权重都变成 Int8。
- 主权重 ( W q u a n t i z e d W_{quantized} Wquantized):被量化为 Int8,用于加速大部分计算。
- 修正权重 ( δ W \delta W δW) :保持为 FP16 或 FP32。
- 计算方式 :
O u t p u t = ( W q u a n t i z e d ⊗ I n p u t i n t 8 ) + ( δ W f p 16 × I n p u t f p 16 ) Output = (W_{quantized} \otimes Input_{int8}) + (\delta W_{fp16} \times Input_{fp16}) Output=(Wquantized⊗Inputint8)+(δWfp16×Inputfp16)
其中 ⊗ \otimes ⊗ 表示 Int8 量化卷积。 - 优点:极大地减少了量化误差,几乎无损精度。
- 缺点:硬件支持度稍差,因为需要同时支持 Int8 和 FP16 计算单元,且增加了内存带宽压力。
路径 B:完全量化推理(本文可能暗示的方向)
如果目标是极致压缩(例如在嵌入式设备上运行),那么 δ W \delta W δW 也必须被量化。
- 步骤 :
- 计算出浮点数的修正量 δ W f l o a t \delta W_{float} δWfloat。
- 对 δ W f l o a t \delta W_{float} δWfloat 进行二次量化(Re-quantization) ,得到 δ W i n t 8 \delta W_{int8} δWint8。
- 在模型中,最终存储的有效权重是 W t o t a l = W b a s e _ i n t 8 + δ W i n t 8 W_{total} = W_{base\int8} + \delta W{int8} Wtotal=Wbase_int8+δWint8。
- 难点 :这样会带来双重量化误差 (Quantization Error + Quantization Error of Correction)。因此,论文中提到的 Rounding Refinement 和 Ridge Regression 就是为了尽量减小这一步再次量化带来的损失,确保修正量在变小精度的情况下依然有效。
实现了权重+激活的耦合,思路很好,但是部署可能还有问题?