文章目录
参考
-
自然语言搜索
https://dev.mysql.com/doc/refman/8.4/en/fulltext-search.html
-
分词长度
https://dev.mysql.com/doc/refman/8.4/en/fulltext-search-ngram.html
https://dev.mysql.com/doc/refman/8.4/en/server-system-variables.html#sysvar_ngram_token_size
-
最小查询词长度
https://dev.mysql.com/doc/refman/8.4/en/innodb-parameters.html#sysvar_innodb_ft_min_token_size
-
全文检索单表cache
https://dev.mysql.com/doc/refman/8.4/en/innodb-parameters.html#sysvar_innodb_ft_cache_size
-
全文检索总cache
https://dev.mysql.com/doc/refman/8.4/en/innodb-parameters.html#sysvar_innodb_ft_total_cache_size
-
停止词
https://dev.mysql.com/doc/refman/8.4/en/fulltext-stopwords.html
-
其它参考
全文检索
bash
cat my.cnf
bash
#最大值1600M
innodb_ft_total_cache_size=1600M
#最大值80M
innodb_ft_cache_size=80M
#默认值3
innodb_ft_min_token_size=2
#默认值2
ngram_token_size=2默认分词
默认分词(自然语言分词)默认分词器基于空格、标点符号、停止词的来分隔单词,主要针对英文按单词分词,对中文这种没有空格的语言就难搞。使用方法:CREATE FULLTEXT INDEX idx_content ON articles(content);
或 ALTER TABLE articles ADD FULLTEXT INDEX idx_content(content);
ngram分词
ngram分词器将文本分解成所有可能的连续字符子串(n-gram),其中n是一个指定的数字,表示子串的长度。它不会区分单词边界,因此适用于没有明确单词分隔符的语言,如中文、日文和韩文。它为每个n-gram
创建索引条目,可以用于执行全文搜索
。它适用于中文、日文、韩文等不使用空格分隔单词的语言。适用于需要按字符序列进行搜索的场景。 Mysql默认ngram分词器的长度为2:
查询默认ngram分词器的长度:
sql
show VARIABLES like 'ngram_token_size'设置默认ngram分词器的长度:
sql
SET GLOBAL ngram_token_size = 2;测试样例
sql
ALTER TABLE `report_information`
ADD FULLTEXT INDEX `idx_account` (`account`) WITH PARSER ngram ;
ALTER TABLE `report_information`
ADD FULLTEXT INDEX `idx_content` (`content`) WITH PARSER ngram ;
sql
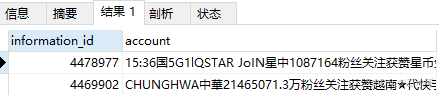
select information_id, account from report_information
where MATCH (account) against ('+星星' IN NATURAL LANGUAGE MODE);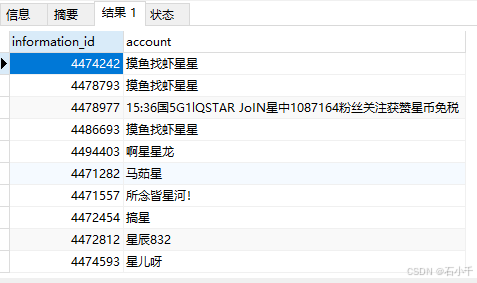
sql
select information_id, account from report_information
where MATCH (account) against ('+星星' in Boolean MODE);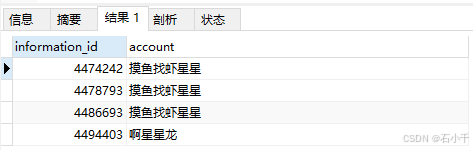
sql
select information_id, account from report_information
WHERE MATCH(account) AGAINST('+星星' WITH QUERY EXPANSION);