OpenStack管理-nova计算
nova负责:
•虚拟机生命周期管理
•其他计算资源生命周期管理
nova不负责:
•承载虚拟机的物理主机自身的管理
•全面的系统状态监控
nova系统架构
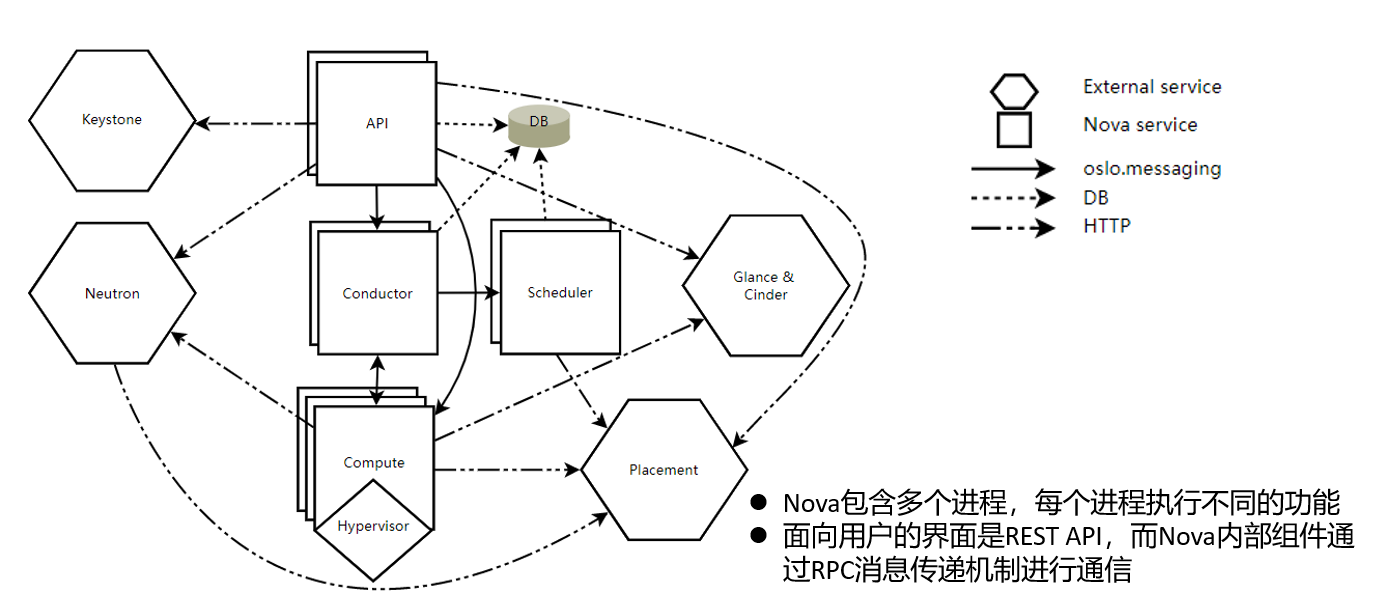
•DB:用于数据存储的SQL数据库。
•API:接收 HTTP 请求、转换命令并通过oslo.messaging队列或 HTTP与其他组件通信的组件。
•Scheduler:为虚拟机选择合适的物理主机。
•Compute:虚拟机生命周期和复杂流程控制。
•Conductor:处理需要协调(构建/调整大小)的请求,充当数据库代理或处理对象转换。
•Placement:跟踪资源提供者的库存和使用情况。
nova-api
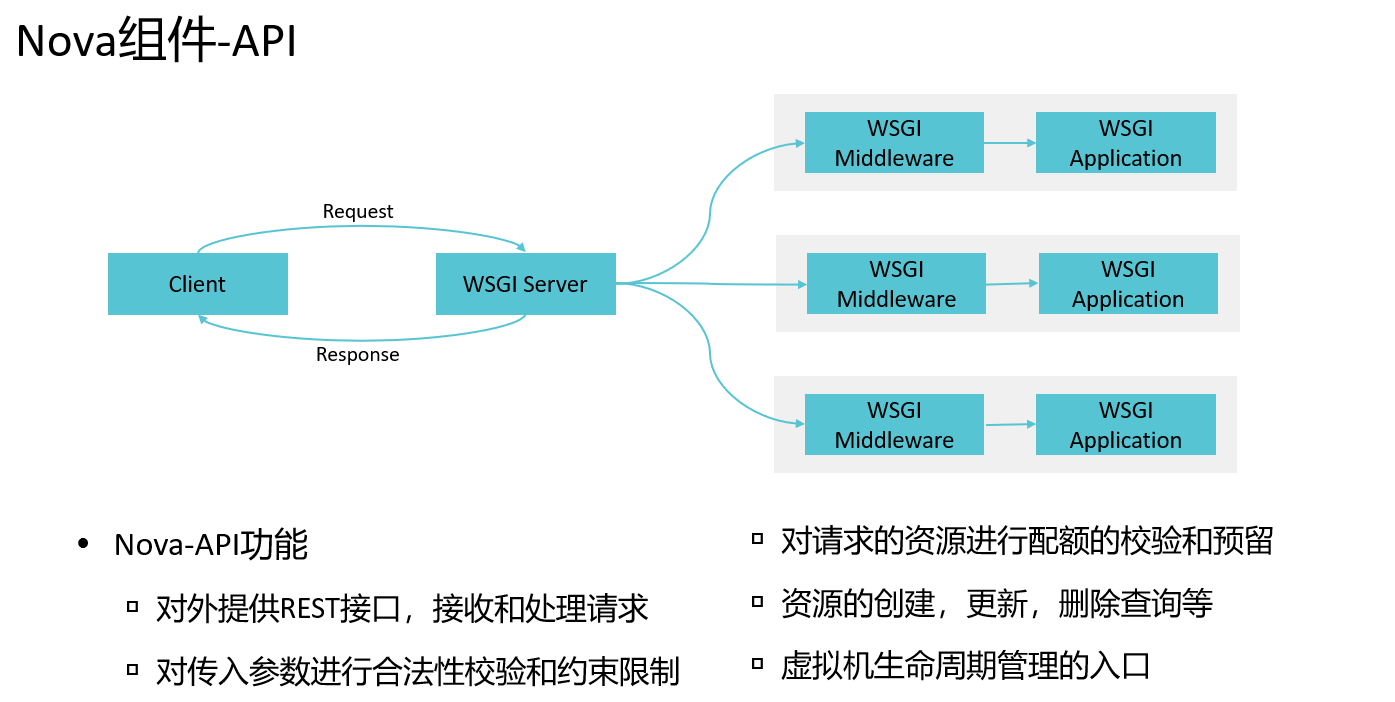
nova-conductor
Nova-Conductor功能
1.数据库操作,解耦其他组件(Nova-Compute)数据库访问
2.Nova复杂流程控制,如创建,冷迁移,热迁移,虚拟机规格调整,虚拟机重建
3.其他组件的依赖,如nova-compute需要nova-conductor启动成功后才能启动
4.其他组件的心跳定时写入
nova-scheduler
Nova-Scheduler功能
筛选和确定将虚拟机实例分配到哪一台物理机
分配过程主要分为过滤和权重两步,
过滤和权重:
通过过滤器选择满足条件的计算节点
通过权重选择最优的节点
Filter scheduler
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步:
- 通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
- 上创建 Instance。
RetryFilter
RetryFilter 的作用是刷掉之前已经调度过的节点。
AvailabilityZoneFilter
为提高容灾性和提供隔离服务,可以将计算节点划分到不同的Availability Zone中。
过虑时会将Availability Zone的节点外的实例直接筛选掉。
RamFilter
RamFilter 将不能满足 flavor 内存需求的计算节点过滤掉。
对于内存有一点需要注意: 为了提高系统的资源使用率,OpenStack 在计算节点可用内存时允许
overcommit,也就是可以超过实际内存大小。 超过的程度是通过 nova.conf 中 ram_allocation_ratio
这个参数来控制的,默认值为 1.5倍
如果计算节点的内容为 10GB,OpenStack 则会认为它有 50GB(10*1.5)内存。
DiskFilter
DiskFilter 将不能满足 flavor 磁盘需求的计算节点过滤掉。Disk 同样允许 overcommit,通过 nova.conf
中 disk_allocation_ratio 控制,默认值为 1
216 #disk_allocation_ratio=
CoreFilter
CoreFilter 将不能满足 flavor vCPU 需求的计算节点过滤掉。vCPU 同样允许 overcommit,通过
nova.conf 中 cpu_allocation_ratio 控制,默认值为 16
cpu_allocation_ratio=16.0
这意味着一个 8 vCPU 的计算节点,nova-scheduler 在调度时认为它有 128 个 vCPU。 需要提醒的是:
nova-scheduler 默认使用的 filter 并没有包含 CoreFilter。 如果要用,可以将 CoreFilter 添加到
nova.conf 的 scheduler_default_filters 配置选项中。
ComputeFilter
ComputeFilter 保证只有 nova-compute 服务正常工作的计算节点才能够被 nova-scheduler调度。
ComputeFilter 显然是必选的 filter。
ComputeCapabilitiesFilter
ComputeCapabilitiesFilter 根据计算节点的特性来筛选。
例如我们的节点有 x86_64位 和 ARM 架构的,如果想将 Instance 指定部署到 x86_64 架构的节点上,就可
以利用 ComputeCapabilitiesFilter。
ImagePropertiesFilter
ImagePropertiesFilter 根据所选 image 的属性来筛选匹配的计算节点。
ServerGroupAntiAffinityFilter(反亲和性)
ServerGroupAntiAffinityFilter 可以尽量将 Instance 分散部署到不同的节点上。
例如有 inst1,inst2 和 inst3 三个 instance,计算节点有 A,B 和 C。
调度时 ServerGroupAntiAffinityFilter 会将 inst1, inst2 和 inst3 部署到不同计算节点 A, B 和 C。
ServerGroupAffinityFilter(亲和性)
与 ServerGroupAntiAffinityFilter 的作用相反,ServerGroupAffinityFilter 会尽量将 instance 部署到同
一个计算节点上。
Weight
经过前面一堆 filter 的过滤,nova-scheduler 选出了能够部署 instance 的计算节点。
Scheduler 会对每个计算节点打分,得分最高的获胜。 打分的过程就是 weight,翻译过来就是计算权重
值。
目前 nova-scheduler 的默认实现是根据计算节点空闲的内存量计算权重值: 空闲内存越多,权重越
大,instance 将被部署到当前空闲内存最多的计算节点上。
日志
整个过程都被记录到 /var/log/nova-scheduler.log的日志文件中。
bash
[root@controllernova(keystone_admin)]#cat/var/log/nova/nova-scheduler.log|grepFilter
nova-compute
•虚拟机生命周期操作的真正执行者(会调用对应的hypervisor的driver)。
•底层对接不同虚拟化的平台(KVM/VMware/XEN/Ironic等)。
•内置周期性任务,完成资源刷新,虚拟机状态同步等功能。
•资源管理模块(resource_tracker)配合插件机制,完成资源的统计。
RabbitMQ性能查看
开源的消息队列中间件
把服务A的消息发送rabbitmq,再由它转给服务B,A和B不用直接对接,不用互相等
查看RabbitMQ服务状态:
bash
[root@controller ~]# systemctl status rabbitmq-server.service
● rabbitmq-server.service - RabbitMQ broker
Loaded: loaded (/usr/lib/systemd/system/rabbitmq-server.service; enabled;
vendor preset: disabled)
Drop-In: /etc/systemd/system/rabbitmq-server.service.d
└─90-limits.conf
Active: active (running) since Thu 2024-09-26 09:06:19 CST; 18min ago
Main PID: 1721 (beam.smp)
Status: "Initialized"
Tasks: 91 (limit: 100416)
Memory: 118.7M
CGroup: /system.slice/rabbitmq-server.service
├─1721 /usr/lib64/erlang/erts-10.7.2.1/bin/beam.smp -W w -A 64 -MBas
ageffcbf -MHas ageffcbf -MBlmbcs 512>
├─2144 /usr/lib64/erlang/erts-10.7.2.1/bin/epmd -daemon
├─3100 erl_child_setup 16384
├─7806 inet_gethost 4
└─7807 inet_gethost 4RabbitMQ 有一个管理 plugin,提供了图形管理界面,可以在运行 RabbitMQ 的节点(一般是控制
节点)执行下面的命令启用。
bash
[root@controller ~]# rabbitmq-plugins enable rabbitmq_management
Enabling plugins on node rabbit@controller:
rabbitmq_management
The following plugins have been configured:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@controller...
The following plugins have been enabled:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
started 3 plugins.创建一个 用户,用来登录管理控制台
bash
[root@controller ~]# iptables -F
[root@controller ~]# rabbitmqctl add_user user_admin passwd_admin #创建用户名密码
Adding user "user_admin" ...
[root@controller ~]# rabbitmqctl set_user_tags user_admin administrator
rabbitmqctl set_permissions -p / user_admin ".*" ".*" ".*" #授权
Setting tags for user "user_admin" to [administrator, rabbitmqctl,
set_permissions, user_admin, .*, .*, .*] ...
以用 user_admin(密码 passwd_admin)登录
地址是http://192.168.108.10:15672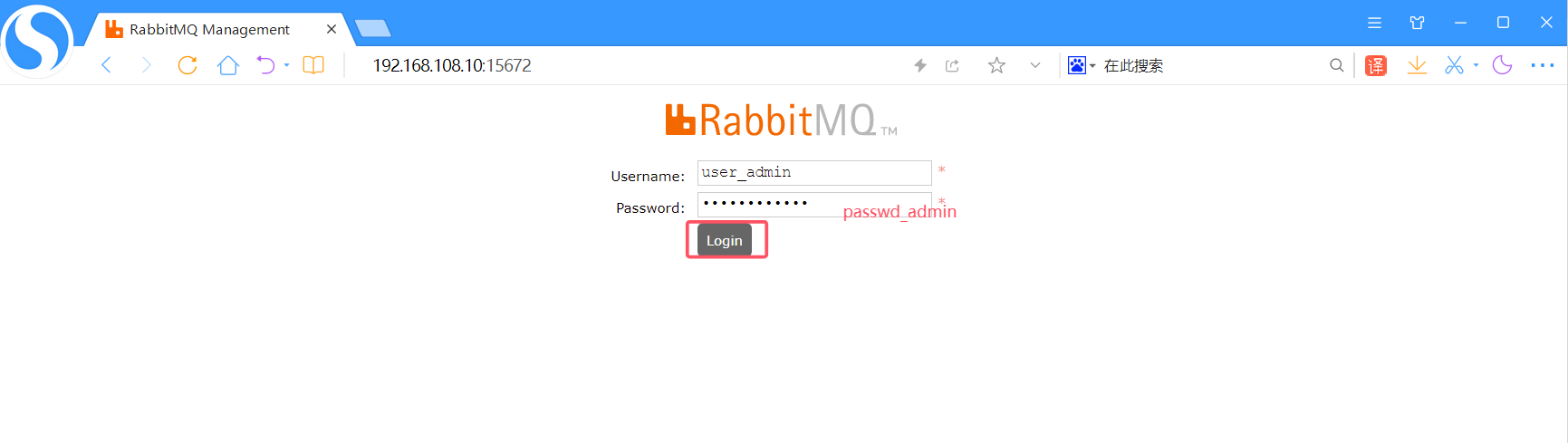
创建虚拟机过程
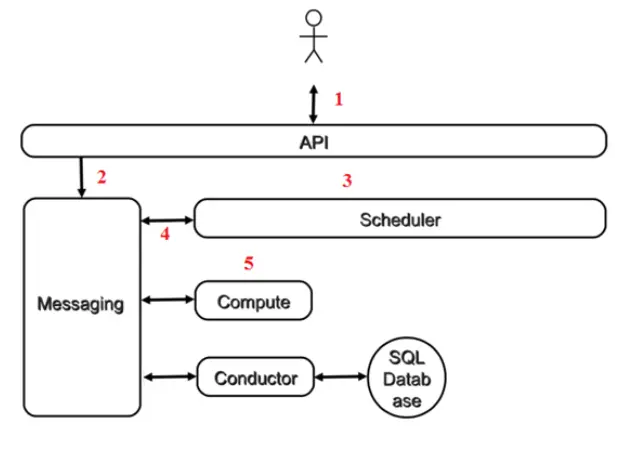
- 客户向 API(nova-api)发送请求:"帮我创建一个 Instance"
- API对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:"让 Scheduler 创建
一个 Instance" - Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若
干计算节点中选出节点 A。 - Scheduler 向 Messaging 发送了一条消息:"在计算节点 A 上创建这个 Instance"
- 计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然
后通过本节点的 Hypervisor Driver 创建 Instance。 - 在 Instance 创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向
Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。