摘要
由于 WiFi 接入点(Access Point, AP)广泛存在,基于 WiFi 的室内定位受到了广泛关注。基于信号处理的方法能够达到分米级定位精度,但其性能受到 WiFi 系统有限空间分辨率的限制,尤其在强干扰的复杂环境中更为明显。相比之下,基于深度学习的方法即使在复杂环境中也取得了令人印象深刻的性能,但它们往往难以泛化到新环境。本文提出一种用于 WiFi 室内定位的域不变模型学习框架,使模型能够在不同环境中保持优异性能。核心洞察是从信号处理视角设计基于深度学习的 WiFi 定位系统。具体而言,我们让神经网络估计以 AP 为中心的极坐标,而不是拟合与环境强相关的 AP 坐标,从而获得域不变模型。为了释放神经网络回归高精度参数的潜力,本文设计了一个波束成形层,将信号处理知识融入神经网络。此外,本文提出一种多任务学习方案,以进一步提升定位精度。在多个数据集上的大量实验表明,本文方法的定位性能优于现有先进方法,并且在跨域条件下表现出优势。
关键词:信道状态信息;深度学习;室内定位;WiFi。
文章目录
-
- 摘要
- [I. 引言](#I. 引言)
- [II. 相关工作](#II. 相关工作)
-
- [A. 基于信号处理的方法](#A. 基于信号处理的方法)
- [B. 基于深度学习的方法](#B. 基于深度学习的方法)
- [III. 基础知识](#III. 基础知识)
-
- [A. 信道状态信息](#A. 信道状态信息)
- [B. 波束成形](#B. 波束成形)
- [IV. 方法设计](#IV. 方法设计)
-
- [A. 问题分析](#A. 问题分析)
- [B. 通过波束成形层释放神经网络潜力](#B. 通过波束成形层释放神经网络潜力)
- [C. 深度神经网络设计](#C. 深度神经网络设计)
- [D. 定位](#D. 定位)
- [V. 实现](#V. 实现)
-
- [A. 实验设置](#A. 实验设置)
- [B. 基线方法](#B. 基线方法)
- [VI. 评估](#VI. 评估)
-
- [A. 简单场景](#A. 简单场景)
- [B. 复杂场景](#B. 复杂场景)
- [C. 泛化能力](#C. 泛化能力)
- [D. 消融研究](#D. 消融研究)
- [E. 其他考虑](#E. 其他考虑)
- [VII. 大规模实验](#VII. 大规模实验)
- [VIII. 结论](#VIII. 结论)
- 参考文献
I. 引言
室内定位在过去二十年中一直是一个活跃研究方向 1,具有安全监控 2、室内导航 3、零售商业 4 等多种实际应用。由于 WiFi AP 普遍存在 5, 6,基于 WiFi 的系统 7, 8 相比基于雷达的系统 9, 10 更受关注。近年来,WiFi 定位系统的本质是利用客户端与 AP 之间的信道状态信息(Channel State Information, CSI)进行定位 11。
一种直接方案是先通过各种信号处理算法从 CSI 中估计到达角(Angle of Arrival, AoA)和飞行时间(Time of Flight, ToF),再基于 AP 坐标进行三角定位 12-15。基于信号处理的方法依赖域不变的数学模型,因此可以部署在任意环境中。然而,商用 WiFi 设备的空间分辨率有限,限制了这些算法的性能,进而限制了定位性能 16。更糟的是,在强干扰复杂环境中,这些方法的性能会显著下降 17。
另一类方法是利用深度神经网络直接估计客户端坐标。基于深度学习的方法从大量数据中提取不同位置处 CSI 的特征,并用这些数据调整神经网络参数。通过这种方法建立的模型相较基于信号处理的方法表现出更好的性能,尤其是在强干扰复杂环境中 17。但现有深度学习方法容易过拟合训练域中的特征,部署到新域时会出现严重性能退化。
本文结合信号处理的跨域能力和深度学习对高精度参数估计的拟合能力,以实现可靠的高精度定位。所提方法的关键洞察包括两点。
第一,现有基于深度学习的方法会将与环境强相关的 AP 坐标拟合到网络参数中。由于室内环境复杂,不同场景中的 AP 坐标通常不同,如 Fig. 1 所示,这使训练得到的模型高度依赖环境。不同于已有工作,本文提出将以 AP 为中心的极坐标作为网络输出。我们的观察是:尽管环境发生变化,AP 与客户端之间的相对空间关系仍保持一致,而以 AP 为中心的极坐标能够封装这种特性。
第二,极坐标回归精度可以通过将信号处理知识纳入深度学习来增强。具体而言,我们观察到波束成形的基本原理与全连接层的前向传播在本质上相同。基于这一观察,可以用全连接层实现波束成形,从而进一步释放神经网络在高精度参数估计中的潜力。
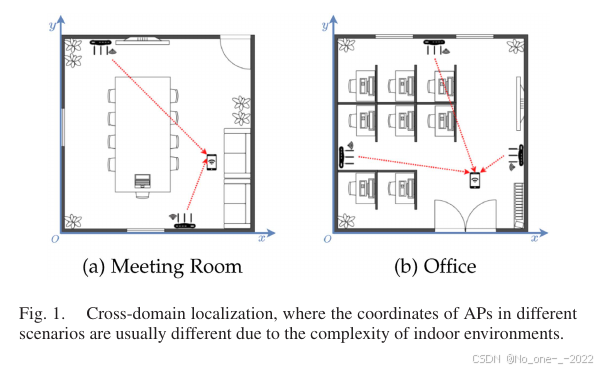
Fig. 1. 跨域定位。由于室内环境复杂,不同场景中的 AP 坐标通常不同。
为进一步提升定位性能,本文提出一种用于定位的多任务学习方案。该方案使模型能够同时学习笛卡尔坐标和极坐标特征,从而获得高精度定位能力和良好泛化能力。
本文主要贡献如下。
- 提出通过波束成形层释放神经网络进行高精度极坐标估计的潜力。通过这种方式,本文结合了信号处理和深度神经网络的优势,用于学习域不变模型。
- 提出一种用于定位的多任务学习方案,使神经网络能够同时学习同一位置处信号的不同表示,进一步提高定位精度。
- 在多个室内环境和多个数据集上进行了大量实验。结果表明,本文方法显著优于先进的信号处理方法,并且相较先进的深度学习方法保持了更好的跨域鲁棒性。相关数据集将向研究社区发布,以推动 WiFi 室内定位研究。
本文其余部分安排如下。第二节讨论相关工作,第三节介绍基础知识,第四节给出方法设计,第五节和第六节分别给出实验设置和实验结果,第七节展示大规模环境中的性能,第八节总结全文。
II. 相关工作
A. 基于信号处理的方法
商用 WiFi 设备通常配备多个天线,并能够以子载波级粒度获得物理信道测量 18,因此可以使用多种信号处理算法提取 AoA 和 ToF 信息。
基于 ToF 的方法。 ToF 方法需要较大带宽才能获得较高 ToF 分辨率 16。受 WiFi 设备带宽限制,ToneTrack 14 通过信道切换获得较大的虚拟带宽,Chronos 19 通过跳频获得精确 ToF 估计。然而,这些方法可能中断正常数据通信,不适合实际 WiFi 定位。SiFi 20 基于 MIMO 的频率锁定天线设计提出观察:只有一个时延畸变值能使所有天线的直达路径 ToF 相交于同一点。借助这一观察,SiFi 在不影响数据通信的情况下实现了 0.93 m 的中位定位精度。不过,它需要从 WiFi 设备中拉出天线以满足理论模型,这同样不实用。P2PLocate 21 从反向散射中分离出鲁棒 CSI,估计细粒度多普勒偏移和粗粒度 ToF,并将二者结合实现单天线收发设备定位。22 对 Android 12 支持的单边测距协议进行了广泛测试,并确认其测距结果不如 Fine Time Measurement(FTM)测距协议准确,同时提出了一系列改进方法。WiPeep 23 提出非协作 WiFi 定位概念并研究其隐私影响:WiPeep 连续移动一个 AP,并注入伪造数据包以诱导客户端响应,再结合响应包中的 ToF 信息和 AP 运动轨迹真值建立优化方程,最终求解客户端位置。
基于 AoA 的方法。 ArrayTrack 12 使用传统 MUSIC 算法和 8 根天线实现高精度定位,但依赖无法直接部署在商用 WiFi 设备上的特定硬件。Ubicarse 24 和 LTEye 25 使用合成孔径思想获得更大的阵列孔径,从而提高商用 WiFi 设备上的 AoA 估计精度,但这要求持有设备的人执行特定圆周运动,在许多场景中并不实用。SpotFi 13 将空间平滑 MUSIC 算法应用于商用 AP,以联合估计 AoA 和 ToF。空间平滑能避免相干信号导致的性能退化,但也会牺牲阵列孔径并限制空间分辨率 26。RoArray 27 将 AoA 估计转化为稀疏恢复问题,在低信噪比场景中也能获得尖锐的 AoA 谱;但超参数选择不当会漏检弱目标,计算复杂度也过高,难以实时定位。UbiLocate 28 使用 Nelder-Mead 搜索获得更精确的 AoA 估计,并结合纳秒级精度的 ToF 测量缓解非视距(NLoS)场景性能退化。Co-Loc 16 引入非参数度量来量化 AoA 估计精度,并利用多个 AP 的 AoA 会相交于一点这一事实进一步改善 AoA 估计。NLoc 29 首次利用广泛存在的多径反射,在没有直达路径且无需预训练或指纹采集时实现目标定位。AutoLoc 30 基于 RF 振荡器频率锁定后不确定初始相位保持常量这一洞察,提出无需校准不确定初始相位的定位方法。MultiLoc 31 融合毫米波与 WiFi,实现高精度和高可靠定位,并首次使用商用设备达到 0.18 m 的中位误差。32 使用高速 RF 多路复用器和子包切换,以低成本、高精度方式估计 AoA,无需多路复用器与接收机同步,缓解了部署大规模阵元相控阵的限制。
B. 基于深度学习的方法
基于深度学习的方法使用神经网络提取每个位置的特征;训练完成后,模型可根据输入预测位置。深度学习方法的核心在于精心设计的输入特征和网络架构。
输入特征。 为在复杂环境和非理想硬件系统中获得鲁棒特征,输入特征应对小尺度衰落、系统变化和硬件损伤保持鲁棒 33。CiFi 34 利用 CSI 相位差估计 AoA,并将其组成图像作为深度卷积神经网络 35 的输入。36 和 37 将 CSI 转换到 AoA-ToF 域,使网络能够基于其中丰富的多径信息区分不同位置。38 从 CSI 中提取 8 类信息作为增强特征,并通过数据构造算法形成输入特征。DLoc 17 将多个 AP 的 CSI 通过二维快速傅里叶变换(2D-FFT)转换为反映客户端位置的位置热力图,再组合这些热力图形成图像张量作为输入,并将客户端的笛卡尔坐标标签转换为带高斯峰值的图像。LiPhi++ 39 利用可移动激光测距扫描仪的感知能力自动标注 WiFi 扫描,从而避免人工干预数据采集。
网络架构。 DeepFi 40 使用一组受限玻尔兹曼机的贪婪学习算法逐层训练深度神经网络。41 基于长短期记忆网络(LSTM)探索利用 CSI 特征时间相关性进行定位的可能性。38 引入双注意力机制深度神经网络和双向 LSTM,并采用注意力机制提取 CSI 特征。42 提出注意力增强残差 CNN,以同时利用 CSI 中的局部信息和全局上下文。DLoc 17 借鉴图像翻译网络结构处理输入和输出图像,并引入一致性解码器消除 ToF 偏移。WePos 43 将自然语言处理中的预训练技术用于购物中心 AP 的 RSSI 数据预训练,再结合伪标签获取算法微调预训练模型,实现低成本、高精度的区域级室内定位。MetaLoc 将模型无关元学习(MAML)用于指纹定位,使模型能基于元参数快速适应新环境,从而降低人工成本。iToLoc 44 基于域对抗神经网络和协同训练半监督学习框架,大幅缓解 RSSI 定位中的信号变化、设备异构和数据库退化问题。MTLoc 45 利用多目标域自适应网络学习源域和目标域中的时间不变、时间特定与位置感知特征,实现指纹数据库自动更新。Penetrative AI 46 甚至不再设计和训练网络,而是使用预训练大语言模型处理传感器信息并获得位置信息。
综上,基于信号处理的方法具有较强跨域能力,但其定位性能受限于商用 WiFi 设备的空间分辨率,并在强干扰环境中严重退化。基于深度学习的方法虽然能在特定环境中获得高精度定位性能,但缺乏泛化能力。为克服这两类方法的限制,本文使用神经网络回归以 AP 为中心的极坐标,以融合信号处理的跨域能力和深度学习的拟合能力。
III. 基础知识
A. 信道状态信息
假设发射端有 1 根天线,接收端配备由 M M M 根天线组成的均匀线阵(ULA),且相邻天线间距为半波长。对于这种单输入多输出(SIMO)系统,发射端在 K K K 个子载波上传输一组 OFDM 信号。发射信号 s \mathbf{s} s 可写为
注:
- 本文假设的是单发多收 WiFi 架构:待定位客户端/发射端可以只有 1 根天线,而 AP/接收端需要多天线 ULA,以便从 CSI 的天线维度估计 AoA 并支撑后续波束成形层。
- "多天线"和"多个 AP"是两个层次:每个 AP 内部的多天线用于提取角度和距离信息,多个 AP 则在最终定位阶段提供多视角融合。
s = s 1 , s 2 , ... , s K T . (1) \mathbf{s}=s_1,s_2,\\ldots,s_K^T. \tag{1} s=s1,s2,...,sKT.(1)
其中 ( ⋅ ) T (\cdot)^T (⋅)T 表示转置。
当发射信号经无线信道 H \mathbf{H} H 传播后,接收信号 r \mathbf{r} r 可写为
r = H s + w , (2) \mathbf{r}=\mathbf{H}\mathbf{s}+\mathbf{w}, \tag{2} r=Hs+w,(2)
其中 w = ω 1 , ω 2 , ... , ω M T \mathbf{w}=\\omega_1,\\omega_2,\\ldots,\\omega_M^T w=ω1,ω2,...,ωMT 是频域中的 M M M 维白高斯噪声。
在 WiFi 通信和无线感知中,可以通过 WiFi 网络接口控制器(NIC)获取信道 H \mathbf{H} H,这也被称为 CSI 47。CSI 描述无线信号传播过程,因此包含传播空间的几何信息。当信号 s \mathbf{s} s 经过具有 P P P 条不同路径的多径信道到达接收机时,可从以下几个方面刻画 CSI。
到达角 θ p \theta_p θp。 信号到达每根天线时的相位偏移由天线间距和入射角决定。第 m m m 根接收天线相对于第一根天线的相位偏移,作为第 p p p 条路径 AoA θ p \theta_p θp 的函数,可写为
ϕ ( θ p ) m = e − j 2 π f k ( m − 1 ) l sin θ p c , (3) \\boldsymbol{\\phi}(\\theta_p)_m = e^{-j2\pi f_k\frac{(m-1)l\sin\theta_p}{c}}, \tag{3} ϕ(θp)m=e−j2πfkc(m−1)lsinθp,(3)
其中 f k f_k fk 为信号子载波频率, l l l 为天线阵列阵元间距, c c c 为光速。整个阵列的相位偏移向量为
ϕ ( θ p ) = \[ ϕ ( θ p ) 1 , ϕ ( θ p ) 2 , ... , ϕ ( θ p ) M ] T . (4) \boldsymbol{\phi}(\theta_p) = \left\[\\boldsymbol{\\phi}(\\theta_p)_1,\\boldsymbol{\\phi}(\\theta_p)_2,\ldots,\\boldsymbol{\\phi}(\\theta_p)_M\right]^T. \tag{4} ϕ(θp)=\[ϕ(θp)1,ϕ(θp)2,...,ϕ(θp)M]T.(4)
飞行时间 τ p \tau_p τp。 每条路径的信号会经历不同传播时间,该时间取决于路径长度。在频域中,第 k k k 个子载波相对于第一个子载波的相位偏移,作为第 p p p 条路径 ToF τ p \tau_p τp 的函数,可表示为
ψ ( τ p ) k = e − j 2 π ( k − 1 ) Δ f τ p , (5) \\boldsymbol{\\psi}(\\tau_p)_k = e^{-j2\pi(k-1)\Delta f\tau_p}, \tag{5} ψ(τp)k=e−j2π(k−1)Δfτp,(5)
其中 Δ f \Delta f Δf 是相邻子载波之间的频率间隔。整个子载波维度的相位偏移向量为
ψ ( τ p ) = \[ ψ ( τ p ) 1 , ψ ( τ p ) 2 , ... , ψ ( τ p ) K ] T . (6) \boldsymbol{\psi}(\tau_p) = \left\[\\boldsymbol{\\psi}(\\tau_p)_1,\\boldsymbol{\\psi}(\\tau_p)_2,\ldots,\\boldsymbol{\\psi}(\\tau_p)_K\right]^T. \tag{6} ψ(τp)=\[ψ(τp)1,ψ(τp)2,...,ψ(τp)K]T.(6)
复衰减 γ p \gamma_p γp。 每条路径 p p p 的信号都会经历衰减 γ p \gamma_p γp。
给定上述参数,无线信道 H \mathbf{H} H 可表示为
H = ∑ p = 1 P ϕ ( θ p ) ψ T ( τ p ) γ p . (7) \mathbf{H} = \sum_{p=1}^{P}\boldsymbol{\phi}(\theta_p)\boldsymbol{\psi}^T(\tau_p)\gamma_p. \tag{7} H=p=1∑Pϕ(θp)ψT(τp)γp.(7)
B. 波束成形
为提取定位所需信息,CSI 通常通过波束成形转换为频谱 48, 49。由于信号传播会在天线维度和子载波维度引入相位偏移,这种偏移可由 CSI 表征。利用 CSI 的相位偏移信息即可提取位置信息。接收机测量到的 CSI 为 H ^ ∈ C M × K \widehat{\mathbf{H}}\in\mathbb{C}^{M\times K} H ∈CM×K,可表示为
H ^ = h 1 , 1 h 1 , 2 ⋯ h 1 , K h 2 , 1 h 2 , 2 ⋯ h 2 , K ⋮ ⋮ ⋱ ⋮ h M , 1 h M , 2 ⋯ h M , K . (8) \widehat{\mathbf{H}} = \begin{bmatrix} h_{1,1} & h_{1,2} & \cdots & h_{1,K}\\ h_{2,1} & h_{2,2} & \cdots & h_{2,K}\\ \vdots & \vdots & \ddots & \vdots\\ h_{M,1} & h_{M,2} & \cdots & h_{M,K} \end{bmatrix}. \tag{8} H = h1,1h2,1⋮hM,1h1,2h2,2⋮hM,2⋯⋯⋱⋯h1,Kh2,K⋮hM,K .(8)
其中 h m , k h_{m,k} hm,k 表示第 m m m 根天线和第 k k k 个子载波对应的测量 CSI。通过补偿不同天线和频率上的相位偏移,来自 AoA θ \theta θ 和 ToF τ \tau τ 的信号会相干叠加,而来自其他位置的信号会被抑制。用于相位补偿的相位偏移可表示为
Φ m , k ( θ , τ ) = exp ( − j 2 π ( ( k − 1 ) Δ f τ + f k ( m − 1 ) l sin θ c ) ) . (9) \Phi_{m,k}(\theta,\tau) = \exp\left( -j2\pi \left( (k-1)\Delta f\tau +f_k\frac{(m-1)l\sin\theta}{c} \right) \right). \tag{9} Φm,k(θ,τ)=exp(−j2π((k−1)Δfτ+fkc(m−1)lsinθ)).(9)
对于具有 M M M 根天线和 K K K 个子载波的系统,相位偏移向量可写为
Φ ( θ , τ ) = Φ 1 , 1 ( θ , τ ) , ... , Φ M , 1 ( θ , τ ) , ... , Φ M , K ( θ , τ ) T . (10) \boldsymbol{\Phi}(\theta,\tau) = \\Phi_{1,1}(\\theta,\\tau),\\ldots,\\Phi_{M,1}(\\theta,\\tau),\\ldots,\\Phi_{M,K}(\\theta,\\tau)^T. \tag{10} Φ(θ,τ)=Φ1,1(θ,τ),...,ΦM,1(θ,τ),...,ΦM,K(θ,τ)T.(10)
通过为空间候选 AoA-ToF 值定义网格,可提取这些 AoA-ToF 对应的信号:
p = A H vec ( H ^ ) , (11) \mathbf{p}=\mathbf{A}^H\operatorname{vec}\left(\widehat{\mathbf{H}}\right), \tag{11} p=AHvec(H ),(11)
其中 vec ( ⋅ ) \operatorname{vec}(\cdot) vec(⋅) 表示向量化操作, ( ⋅ ) H (\cdot)^H (⋅)H 表示 Hermitian 转置, A \mathbf{A} A 定义为
A = Φ ( θ 1 , τ 1 ) , Φ ( θ 2 , τ 1 ) , ... , Φ ( θ g A , τ 1 ) , ... , Φ ( θ g A , τ g T ) . (12) \mathbf{A} = \\boldsymbol{\\Phi}(\\theta_1,\\tau_1), \\boldsymbol{\\Phi}(\\theta_2,\\tau_1), \\ldots, \\boldsymbol{\\Phi}(\\theta_{g_A},\\tau_1), \\ldots, \\boldsymbol{\\Phi}(\\theta_{g_A},\\tau_{g_T}). \tag{12} A=Φ(θ1,τ1),Φ(θ2,τ1),...,Φ(θgA,τ1),...,Φ(θgA,τgT).(12)
其中 g A g_A gA 和 g T g_T gT 分别表示候选 AoA 和 ToF 的数量。最后, p \mathbf{p} p 可重塑为尺寸为 g A × g T g_A\times g_T gA×gT 的矩阵,即 AoA-ToF 频谱。
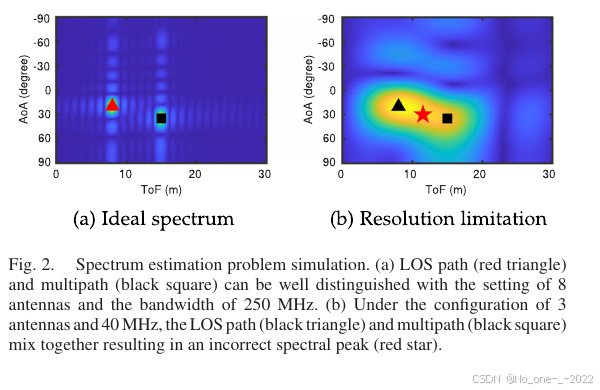
Fig. 2. 频谱估计问题仿真。
(a) 在 8 根天线、250 MHz 带宽设置下,LOS 路径和多径可被较好区分。
(b) 在 3 根天线、40 MHz 设置下,LOS 路径和多径混合,产生错误谱峰。
IV. 方法设计
A. 问题分析
1. 基于信号处理的方法。 假设不存在复杂多径且系统分辨率充足,则可以得到如 Fig. 2(a) 所示的理想频谱,其中视距(LOS)路径和多径可以被轻松区分。但实际情况并不理想。如果客户端到 AP 的直达路径与环境反射路径之间未分离到足够距离,则两条路径的信号会相互干扰 17。这种干扰可能导致叠加形成的新谱峰能量被增强、削弱甚至消失。Fig. 2(b) 展示了干扰效应导致新生成谱峰(红色星形)能量增强的一个例子。
从 AP 测得 CSI 中获得 AoA 和 ToF 后,基于信号处理的方法通过三角定位确定客户端位置。此时 AP 坐标已知,该过程可表示为
c = f l o c ( f s p e c ( x ) , κ ) = f l o c ( θ , τ , κ ) , (13) \mathbf{c} = f_{\mathrm{loc}}(f_{\mathrm{spec}}(\mathbf{x}),\boldsymbol{\kappa}) = f_{\mathrm{loc}}(\boldsymbol{\theta},\boldsymbol{\tau},\boldsymbol{\kappa}), \tag{13} c=floc(fspec(x),κ)=floc(θ,τ,κ),(13)
其中 c \mathbf{c} c 表示客户端坐标, x \mathbf{x} x 表示 AP 的 CSI, θ \boldsymbol{\theta} θ 表示 AoA, τ \boldsymbol{\tau} τ 表示 ToF, κ \boldsymbol{\kappa} κ 表示 AP 坐标, f l o c f_{\mathrm{loc}} floc 表示定位函数, f s p e c f_{\mathrm{spec}} fspec 表示空间频谱估计函数。
可以看到,当 WiFi 系统空间分辨率不足时,基于信号处理的方法性能会下降。在强干扰复杂环境中,这种现象会进一步恶化 17。不过,其数学模型在不同环境中保持不变,因此可部署到任意环境。
2. 基于深度学习的方法。 现有基于深度学习的方法利用神经网络强大的拟合能力对环境建模。模型训练完成后,可根据给定输入进行位置预测。尽管这些研究并不直接将 AP 坐标输入网络,但本质上仍使用神经网络拟合式 (13)。因此,AP 坐标会成为网络函数中的隐式参数。最终,这些方法的过程可表示为
c = f Θ ( x , κ ) , (14) \mathbf{c}=f_{\boldsymbol{\Theta}}(\mathbf{x},\boldsymbol{\kappa}), \tag{14} c=fΘ(x,κ),(14)
其中 f Θ f_{\boldsymbol{\Theta}} fΘ 表示带可训练参数 Θ \boldsymbol{\Theta} Θ 的神经网络。
由于室内环境复杂且多样,不同环境中的 AP 部署通常不同。同时,在单一环境中训练得到的模型已经拟合了 AP 坐标,因此训练模型与训练环境之间存在强相关。这意味着训练好的模型很难直接迁移到其他环境。
3. 本文洞察。 鉴于两类技术路线各有优缺点,本文选择结合信号处理的跨域能力和深度学习的拟合能力,以实现可靠的高精度定位。基于信号处理的方法能够直接部署到不同环境,是因为其数学模型在不同环境中保持不变,而这种特性由以 AP 为中心的极坐标估计保证,如 Fig. 3 所示。
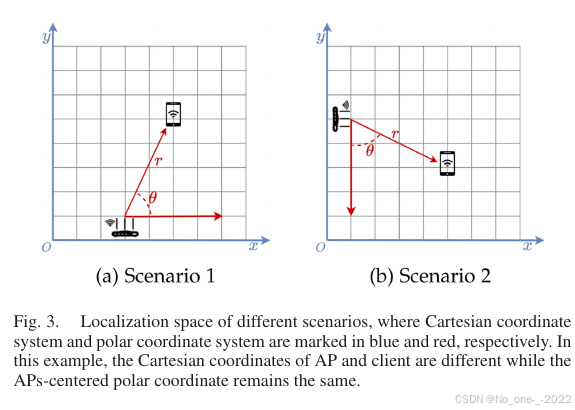
Fig. 3. 不同场景中的定位空间。蓝色和红色分别标记笛卡尔坐标系和极坐标系。在该示例中,AP 和客户端的笛卡尔坐标不同,但以 AP 为中心的极坐标保持不变。
基于这一观察,本文让神经网络估计以 AP 为中心的极坐标。这样,网络可以专注于拟合与环境弱相关的极坐标位置特征,从而增强模型跨域能力。获得极坐标后,再基于信号处理框架执行定位。该过程可表示为
c = f l o c ( f Θ ( x ) , κ ) = f l o c ( θ , τ , κ ) . (15) \mathbf{c} = f_{\mathrm{loc}}(f_{\boldsymbol{\Theta}}(\mathbf{x}),\boldsymbol{\kappa}) = f_{\mathrm{loc}}(\boldsymbol{\theta},\boldsymbol{\tau},\boldsymbol{\kappa}). \tag{15} c=floc(fΘ(x),κ)=floc(θ,τ,κ).(15)
基于这一洞察,可以利用神经网络强大的拟合能力,同时避免深度学习模型过拟合到单一环境。
注:
- 本文缓解换场景泛化问题的关键,是把网络主要要学习的目标从"全局绝对坐标"改成"相对 AP 的几何量"。普通深度学习定位容易学习到
CSI 模式 → 某个训练房间中的全局坐标 ( c x , c y ) , \text{CSI 模式}\rightarrow\text{某个训练房间中的全局坐标 }(c_x,c_y), CSI 模式→某个训练房间中的全局坐标 (cx,cy),
这会把 AP 位置、房间坐标系和场景布局隐式写进网络参数里;换到新房间或新 AP 布局后,这种映射就容易失效。
- 本文改为让网络估计以第 j j j 个 AP 为中心的极坐标:
( θ j , d j ) = f Θ ( x j ) , (\theta_j,d_j)=f_{\boldsymbol{\Theta}}(\mathbf{x}_j), (θj,dj)=fΘ(xj),
其中 x j \mathbf{x}_j xj 是第 j j j 个 AP 测得的 CSI, θ j \theta_j θj 是 AoA, d j d_j dj 是目标到该 AP 的距离。这个映射描述的是"无线信号特征到相对角度/距离"的关系,比直接输出全局 ( c x , c y ) (c_x,c_y) (cx,cy) 更接近无线传播的物理规律。
- 换到新场景后,网络仍然先输出相对 AP 的 ( θ j , d j ) (\theta_j,d_j) (θj,dj);随后再利用新场景中已知的 AP 坐标 κ j = ( x A P , j , y A P , j ) \boldsymbol{\kappa}j=(x{\mathrm{AP},j},y_{\mathrm{AP},j}) κj=(xAP,j,yAP,j) 把相对位置恢复成全局坐标:
目标全局坐标 = AP 全局坐标 + 由 ( θ j , d j ) 给出的相对位移 . \text{目标全局坐标} = \text{AP 全局坐标} + \text{由 }(\theta_j,d_j)\text{ 给出的相对位移}. 目标全局坐标=AP 全局坐标+由 (θj,dj) 给出的相对位移.
因此,场景相关的信息主要放在显式给定的 AP 坐标 κ \boldsymbol{\kappa} κ 中,而不是让神经网络把某个训练场景的 AP 坐标记在参数里。
- 波束成形层进一步帮助泛化:它把原始 CSI 转换成 AoA-ToF/角度-距离相关的空间频谱,使网络学习的中间表示更接近信号处理中的域不变物理量,而不是纯粹拟合某个房间里的 CSI 纹理。
- 多任务学习中的笛卡尔坐标分支主要用于补充训练场景内的定位精度;真正做跨域测试时,论文明确更依赖极坐标输出,因为全局笛卡尔坐标和训练环境、AP 布局强相关。
- 另外,本文在网络输入处解耦不同 AP 的 CSI:每个 AP 先独立给出相对定位结果,最后再做多 AP 概率融合。这比把多个 AP 的 CSI 固定拼接成一个输入更不依赖特定 AP 组合和布局。
- 因而本文的泛化机制可以概括为:学习较稳定的相对几何关系 → \rightarrow → 用目标场景的 AP 坐标恢复全局位置 → \rightarrow → 通过多 AP 融合提高稳健性。它不是完全消除跨域误差,多径、遮挡、硬件差异和相位校准误差仍会导致性能下降,但相比直接学习全局坐标的方法,跨场景退化更小。
B. 通过波束成形层释放神经网络潜力
当使用神经网络处理 CSI 时,一个直接方法是把 CSI 的天线数和子载波数看作图像的长和宽,把 CSI 的实部和虚部看作图像的不同通道 50, 51。但这种方法无法利用 WiFi 定位知识,会使定位网络不必要地复杂化 17。相比之下,DLoc 首先使用 2D-FFT 将 CSI 转换为空间频谱,并将空间频谱幅度转换为二维笛卡尔坐标热力图,再将其作为神经网络输入。这使 DLoc 能将 WiFi 定位知识纳入模型,把定位问题转化为图像翻译问题,并借助多种先进深度学习模型实现高精度定位。然而,DLoc 仅依赖空间频谱幅度,天然存在信息损失。
为此,本文精心设计了波束成形层,这是一种基于神经网络实现波束成形计算的方法。核心洞察是:波束成形与全连接层前向传播的数学本质相同。
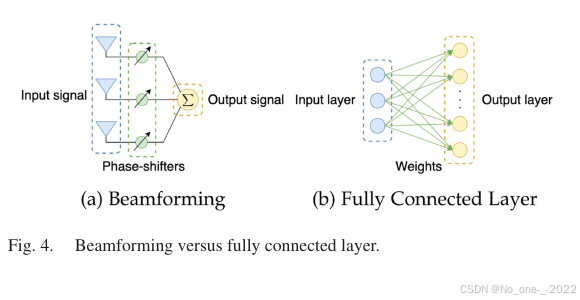
Fig. 4. 波束成形与全连接层的对应关系。
Fig. 4 给出了波束成形和全连接层的核心结构。具体而言,波束成形中的输入信号、输出信号和不同移相器的取值,分别对应全连接层中的输入节点、不同输出节点和不同权重。在波束成形中,通过不同移相器值补偿输入信号相位来获得空间频谱。类似地,波束成形过程也可看作输入节点与全连接层不同权重之间的矩阵乘法。因此,从这个角度看,全连接层的前向传播与波束成形相同。
在全连接层中,每个输入神经元通过加权连接与下一层每个神经元相连,可由权重矩阵表示。输出可通过输入向量与权重矩阵相乘再加上偏置向量得到:
o = W i + b , (16) \mathbf{o}=\mathbf{W}\mathbf{i}+\mathbf{b}, \tag{16} o=Wi+b,(16)
其中 o \mathbf{o} o 表示输出向量, W \mathbf{W} W 为权重矩阵, i \mathbf{i} i 为输入向量, b \mathbf{b} b 为偏置向量。
注意,式 (11) 和式 (16) 的主要计算核心都是矩阵乘法。当全连接层偏置项设为零时,可以使用全连接层执行式 (11) 中的计算:
p = W vec ( H ^ ) , (17) \mathbf{p}=\mathbf{W}\operatorname{vec}\left(\widehat{\mathbf{H}}\right), \tag{17} p=Wvec(H ),(17)
其中 W \mathbf{W} W 是用于替代式 (11) 中 A H \mathbf{A}^H AH 的权重矩阵, p \mathbf{p} p 表示向量化空间频谱, H ^ \widehat{\mathbf{H}} H 为测量 CSI。
神经网络擅长处理实值。当用神经网络处理复值 CSI 时,需要相应修改网络结构。复数常见表示为矩形形式 a + b i a+bi a+bi,其中 a a a 为实部, b b b 为虚部, i i i 为虚数单位。两个复数相乘为
( a 1 + b 1 i ) ( a 2 + b 2 i ) = ( a 1 a 2 − b 1 b 2 ) + ( a 1 b 2 + b 1 a 2 ) i . (18) (a_1+b_1i)(a_2+b_2i) = (a_1a_2-b_1b_2)+(a_1b_2+b_1a_2)i. \tag{18} (a1+b1i)(a2+b2i)=(a1a2−b1b2)+(a1b2+b1a2)i.(18)
当计算涉及复值矩阵时,对应公式为
( W 1 a + W 1 b i ) ( W 2 a + W 2 b i ) = ( W 1 a W 2 a − W 1 b W 2 b ) + ( W 1 a W 2 b + W 1 b W 2 a ) i . (19) (\mathbf{W}_1^a+\mathbf{W}_1^bi)(\mathbf{W}_2^a+\mathbf{W}_2^bi) = (\mathbf{W}_1^a\mathbf{W}_2^a-\mathbf{W}_1^b\mathbf{W}_2^b) +(\mathbf{W}_1^a\mathbf{W}_2^b+\mathbf{W}_1^b\mathbf{W}_2^a)i. \tag{19} (W1a+W1bi)(W2a+W2bi)=(W1aW2a−W1bW2b)+(W1aW2b+W1bW2a)i.(19)
当使用神经网络执行同样操作时,可以使用两个无偏置全连接层分别表示复值矩阵的实部和虚部,并执行式 (19) 的计算。进一步地,为利用波束成形知识,本文使用波束成形相位偏移矩阵初始化全连接层权重矩阵。通过上述方法实现的计算过程称为波束成形层。借助波束成形层,可以直接输入 CSI,而无需详细特征工程;同时利用深度学习进展与波束成形知识,进一步释放定位神经网络的潜力。
注:
- "波束成形层"从计算形式看,本质上是用无偏置全连接层执行矩阵乘法来模拟传统波束成形;它的特殊之处不在于发明了新的非线性网络层,而在于用波束成形的相位偏移矩阵初始化权重,把 AoA/ToF 相关的物理先验放进网络。
- 因此更准确的理解是:它是一个带信号处理先验初始化的 FC 层。如果训练时权重完全自由更新,这种物理含义会变弱;论文后面的随机初始化与波束成形初始化消融,主要就是用来证明这个初始化先验确实带来了性能收益。
C. 深度神经网络设计
多任务学习。 多任务学习旨在通过共享表示学习多个目标,提高神经网络的学习效率和预测精度 52,并已广泛用于计算机视觉 53 和自然语言处理 54 等领域。本文在基于深度学习的定位设置中探索多任务学习。
回顾近期深度学习定位工作,一种常见做法是使用笛卡尔坐标约束神经网络获得与绝对位置相关的特征。这些方法允许网络学习与环境强相关的特征,因此可获得极高定位精度 17, 33。然而,一旦 AP 位置发生变化,这样得到的模型无法输出与输入特征对应的正确位置。相比之下,我们观察到以 AP 为中心的极坐标与 AP 位置无关。一旦神经网络建立了数据与以 AP 为中心的极坐标之间的映射关系,无论 AP 位置如何变化,模型都可以基于对应输入数据输出正确的相对位置。这意味着以 AP 为中心的极坐标可以约束网络学习与相对位置相关的特征。因此,笛卡尔坐标和极坐标表示同一位置的不同信息。为约束网络同时学习两类坐标的不同特征,本文将客户端的以 AP 为中心的极坐标回归和笛卡尔坐标回归作为网络的两个分支。借助多任务学习思想,可得到兼具高精度定位和优异跨域能力的模型。
网络架构。 本文将位置参数估计任务建模为多标签回归。模型输入为 CSI 的实部和虚部,标签为极坐标和笛卡尔坐标。给定输入 CSI,首先使用波束成形层得到空间频谱。随后将空间频谱视为图像,并将其实部、虚部和幅度作为图像的三个通道。本文选择已被广泛验证且成为深度学习基石的 ResNet 55 作为特征提取网络。具体而言,使用 1 个卷积层和 4 个 ResNet BasicBlock 进行特征提取,最后使用若干全连接层,通过两个分支回归位置参数的均值和方差。
注:
- 这里的神经网络输入不是 RSSI,也不是目标坐标,而是每个 AP 在接收客户端数据包时测得的复数 CSI 矩阵 H ^ ∈ C M × K \widehat{\mathbf{H}}\in\mathbb{C}^{M\times K} H ∈CM×K;其中 M M M 表示 AP 接收天线数, K K K 表示 OFDM 子载波数,矩阵元素 h m , k h_{m,k} hm,k 对应第 m m m 根天线、第 k k k 个子载波上的信道测量。
- 由于 CSI 是复数,而常规神经网络更适合处理实值数据,论文将 CSI 拆成实部和虚部输入网络;这一步保留了幅度和相位信息,而相位差正是估计 AoA 和 ToF/距离的重要依据。
- CSI 进入网络后先经过波束成形层。这个层不是普通的特征拼接层,而是用类似全连接层的矩阵运算模拟传统波束成形,把原始 CSI 转换为 AoA-ToF/角度-距离相关的空间频谱。
- 波束成形层输出的空间频谱仍不是最终坐标;后续 ResNet 把该频谱当作图像处理,并使用频谱的实部、虚部和幅度构成三通道输入,从中提取定位特征。
- 训练标签包含两类位置表示:一类是以 AP 为中心的极坐标标签,即 AoA 角度 θ j \theta_j θj 和距离 d j d_j dj;另一类是全局笛卡尔坐标标签,即目标位置 ( c x , c y ) (c_x,c_y) (cx,cy)。最终网络通过两个分支同时回归这些位置参数的均值和方差。
- 因此本文的数据流可以理解为:AP 采集 CSI → \rightarrow → 拆成实部/虚部输入波束成形层 → \rightarrow → 得到空间频谱三通道图 → \rightarrow → ResNet 提取特征 → \rightarrow → 输出极坐标和笛卡尔坐标的估计及其不确定性。
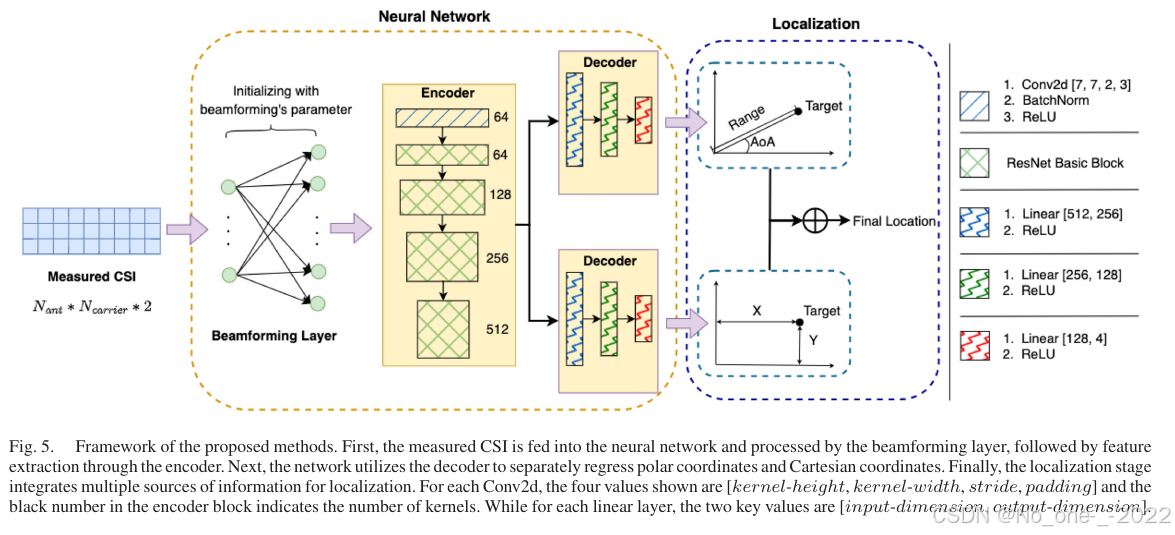
Fig. 5. 所提方法框架。测量 CSI 首先输入神经网络并由波束成形层处理,随后由编码器提取特征;解码器分别回归极坐标和笛卡尔坐标;最后定位阶段融合多源信息完成定位。
通过这种数据驱动方法,可以利用神经网络建立环境的隐式表示,并将真实世界观测到的真值数据纳入训练,以提取环境对 CSI 的影响。使用训练好的神经网络,可通过 CSI 的相位和幅度获得高精度 AoA 和距离。
置信度估计。 测试时,不同 AP 提供准确位置信息的置信度不同,原因包括接收信噪比差异以及 AP 是否被遮挡。已有信号处理和深度学习工作采用多种方法量化不同 AP 的置信度 33, 56-59。本文遵循概率论思想,采用概率方法 33 进行多 AP 定位。对于回归任务,让神经网络最后一层输出两个值,一个表示均值,另一个表示方差 60。将输入数据视为来自预测均值和方差的高斯分布样本,使用负对数似然(NLL)准则训练神经网络:
NLL ( y j , x ) = log σ j 2 ( x ) 2 + ( y j − μ j ( x ) ) 2 2 σ j 2 ( x ) + c o n s t a n t . (20) \operatorname{NLL}(y_j,\mathbf{x}) = \frac{\log\sigma_j^2(\mathbf{x})}{2} + \frac{(y_j-\mu_j(\mathbf{x}))^2}{2\sigma_j^2(\mathbf{x})} +\mathrm{constant}. \tag{20} NLL(yj,x)=2logσj2(x)+2σj2(x)(yj−μj(x))2+constant.(20)
其中 y j y_j yj 表示第 j j j 个 AP 的实值标签,常数项为偏置参数, μ j ( x ) \mu_j(\mathbf{x}) μj(x) 和 σ j 2 ( x ) \sigma_j^2(\mathbf{x}) σj2(x) 分别表示神经网络对第 j j j 个 AP 的预测均值和方差。直观而言,方差越大,对应的定位相关信息越不可靠。获得每个 AP 的方差后,第 j j j 个 AP 的置信度可由下式计算:
Confidence j = 1 σ j 2 . (21) \operatorname{Confidence}_j=\frac{1}{\sigma_j^2}. \tag{21} Confidencej=σj21.(21)
损失函数。 神经网络端到端训练,最终损失项 L \mathcal{L} L 由极坐标损失和笛卡尔坐标损失组合而成:
L = NLL ( θ j , x ) + λ 1 NLL ( d j , x ) + λ 2 NLL ( c x , x ) + NLL ( c y , x ) 2 . (22) \mathcal{L} = \operatorname{NLL}(\theta_j,\mathbf{x}) +\lambda_1\operatorname{NLL}(d_j,\mathbf{x}) +\lambda_2 \frac{\operatorname{NLL}(c_x,\mathbf{x})+\operatorname{NLL}(c_y,\mathbf{x})}{2}. \tag{22} L=NLL(θj,x)+λ1NLL(dj,x)+λ22NLL(cx,x)+NLL(cy,x).(22)
其中 θ j \theta_j θj 和 d j d_j dj 分别表示第 j j j 个 AP 的 AoA 和距离真值, c x c_x cx 和 c y c_y cy 是二维笛卡尔坐标, λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 是权重因子,用于调节不同任务损失在最终损失中的比例。
注:
- 这里没有直接使用普通 MSE,而是把每个待回归的位置量 y j y_j yj 建模为带均值和方差的高斯变量:
y j ∼ N ( μ j ( x ) , σ j 2 ( x ) ) . y_j \sim \mathcal{N}\left(\mu_j(\mathbf{x}),\sigma_j^2(\mathbf{x})\right). yj∼N(μj(x),σj2(x)).
网络最后一层因此不是只输出一个数,而是对每个位置量同时输出预测均值 μ j ( x ) \mu_j(\mathbf{x}) μj(x) 和预测方差 σ j 2 ( x ) \sigma_j^2(\mathbf{x}) σj2(x);前者是估计值,后者表示该估计的不确定性。
- 单个回归量的负对数似然损失为:
NLL ( y j , x ) = log σ j 2 ( x ) 2 + ( y j − μ j ( x ) ) 2 2 σ j 2 ( x ) + c o n s t a n t . \operatorname{NLL}(y_j,\mathbf{x}) = \frac{\log\sigma_j^2(\mathbf{x})}{2} + \frac{(y_j-\mu_j(\mathbf{x}))^2}{2\sigma_j^2(\mathbf{x})} + \mathrm{constant}. NLL(yj,x)=2logσj2(x)+2σj2(x)(yj−μj(x))2+constant.
其中第二项衡量预测误差,第一项惩罚过大的方差;因此网络不能简单地把方差预测得很大来掩盖误差。
- 总损失由三类任务组成:
L = NLL ( θ j , x ) ⏟ AoA 角度损失 + λ 1 NLL ( d j , x ) ⏟ 距离损失 + λ 2 NLL ( c x , x ) + NLL ( c y , x ) 2 ⏟ 全局笛卡尔坐标损失 . \mathcal{L} = \underbrace{\operatorname{NLL}(\theta_j,\mathbf{x})}{\text{AoA 角度损失}} + \lambda_1 \underbrace{\operatorname{NLL}(d_j,\mathbf{x})}{\text{距离损失}} + \lambda_2 \underbrace{ \frac{\operatorname{NLL}(c_x,\mathbf{x})+\operatorname{NLL}(c_y,\mathbf{x})}{2} }_{\text{全局笛卡尔坐标损失}}. L=AoA 角度损失 NLL(θj,x)+λ1距离损失 NLL(dj,x)+λ2全局笛卡尔坐标损失 2NLL(cx,x)+NLL(cy,x).
其中 θ j \theta_j θj 和 d j d_j dj 是目标相对第 j j j 个 AP 的极坐标标签, c x , c y c_x,c_y cx,cy 是目标在全局场景坐标系下的真实坐标。
- 论文公式写的是第 j j j 个 AP 的单样本形式;实际训练时,可以理解为对 batch 中所有样本、所有可用 AP 对应的这些损失求和或求平均,再用 Adam 做端到端优化。
- 预测方差 σ j 2 \sigma_j^2 σj2 有两重作用:训练时参与 NLL,帮助模型学习"不确定性";测试/融合时又可转成置信度 Confidence j = 1 / σ j 2 \operatorname{Confidence}_j=1/\sigma_j^2 Confidencej=1/σj2,让更可靠的 AP 或分支在 final location 中占更大权重。
D. 定位
如前所述,极坐标和笛卡尔坐标可以相互转换。为统一 J J J 个 AP 的估计坐标,本文基于定位几何模型将每个 AP 的极坐标转换为笛卡尔坐标:
c x , i n d i r e c t j = c x j + d j sin ( θ j + π 2 sgn ( v x j ) ) , c y , i n d i r e c t j = c y j + d j cos ( θ j + π 2 sgn ( v y j ) ) . (23) \begin{aligned} c_{x,\mathrm{indirect}}^j &= c_x^j+d_j\sin\left(\theta_j+\frac{\pi}{2}\operatorname{sgn}(v_x^j)\right),\\ c_{y,\mathrm{indirect}}^j &= c_y^j+d_j\cos\left(\theta_j+\frac{\pi}{2}\operatorname{sgn}(v_y^j)\right). \end{aligned} \tag{23} cx,indirectjcy,indirectj=cxj+djsin(θj+2πsgn(vxj)),=cyj+djcos(θj+2πsgn(vyj)).(23)
其中 c x , i n d i r e c t j c_{x,\mathrm{indirect}}^j cx,indirectj 和 c y , i n d i r e c t j c_{y,\mathrm{indirect}}^j cy,indirectj 分别为第 j j j 个 AP 的极坐标转换得到的横坐标和纵坐标均值; c x j c_x^j cxj 和 c y j c_y^j cyj 表示第 j j j 个 AP 的横坐标和纵坐标; d j d_j dj 和 θ j \theta_j θj 分别为第 j j j 个 AP 的距离和角度估计均值; v x j v_x^j vxj 和 v y j v_y^j vyj 用于确定符号函数 sgn ( ⋅ ) \operatorname{sgn}(\cdot) sgn(⋅) 的取值。
随后,使用误差传播理论 61 将第 j j j 个 AP 的极坐标方差转换为笛卡尔坐标方差:
σ c x , i n d i r e c t j 2 = ( ∂ c x , i n d i r e c t j ∂ d j ) 2 σ d j 2 + ( ∂ c x , i n d i r e c t j ∂ θ j ) 2 σ θ j 2 , σ c y , i n d i r e c t j 2 = ( ∂ c y , i n d i r e c t j ∂ d j ) 2 σ d j 2 + ( ∂ c y , i n d i r e c t j ∂ θ j ) 2 σ θ j 2 . (24) \begin{aligned} \sigma_{c_{x,\mathrm{indirect}}^j}^2 &= \left(\frac{\partial c_{x,\mathrm{indirect}}^j}{\partial d_j}\right)^2\sigma_{d_j}^2 + \left(\frac{\partial c_{x,\mathrm{indirect}}^j}{\partial \theta_j}\right)^2\sigma_{\theta_j}^2,\\ \sigma_{c_{y,\mathrm{indirect}}^j}^2 &= \left(\frac{\partial c_{y,\mathrm{indirect}}^j}{\partial d_j}\right)^2\sigma_{d_j}^2 + \left(\frac{\partial c_{y,\mathrm{indirect}}^j}{\partial \theta_j}\right)^2\sigma_{\theta_j}^2. \end{aligned} \tag{24} σcx,indirectj2σcy,indirectj2=(∂dj∂cx,indirectj)2σdj2+(∂θj∂cx,indirectj)2σθj2,=(∂dj∂cy,indirectj)2σdj2+(∂θj∂cy,indirectj)2σθj2.(24)
最后,使用 J J J 个 AP 的直接回归笛卡尔坐标、由极坐标间接转换得到的笛卡尔坐标以及相应方差进行概率融合,得到客户端笛卡尔坐标:
c c l i e n t = Fuse ( { c d i r e c t j , σ d i r e c t j } j = 1 J , { c i n d i r e c t j , σ i n d i r e c t j } j = 1 J ) , (25) \mathbf{c}{\mathrm{client}} = \operatorname{Fuse}\left( \{\mathbf{c}{\mathrm{direct}}^j,\boldsymbol{\sigma}{\mathrm{direct}}^j\}{j=1}^{J}, \{\mathbf{c}{\mathrm{indirect}}^j,\boldsymbol{\sigma}{\mathrm{indirect}}^j\}_{j=1}^{J} \right), \tag{25} cclient=Fuse({cdirectj,σdirectj}j=1J,{cindirectj,σindirectj}j=1J),(25)
其中融合权重与方差成反比,即方差越小的估计在最终定位结果中权重越大。所提方法整体框架如 Fig. 5 所示。
V. 实现
A. 实验设置
1. 数据集。 为评估本文方法性能,论文在三个不同数据集上进行了大量实验。DLoc 数据集将同步定位与建图(SLAM)引入深度学习定位中,以实现自动且高精度的数据采集。与以往单点数据采集相比,该数据集能更全面地评估定位方法性能。DLoc 数据集包含两个场景:一个是简单 LOS 场景,另一个是高多径和 NLOS 场景。为评估模型在单一场景随时间变化的泛化能力,每个场景还包含不同设置。需要注意的是,DLoc 数据集有两个局限:1)机器人移动速度为 15 cm/s,过慢;2)没有人体移动干扰。因此,DLoc 数据集不够贴近真实世界。
鉴于此,作者构建了一个基于超宽带(UWB)和 WiFi 的手持设备数据集,其二维笛卡尔坐标真值由 UWB 提供 62。此外,作者还开发了一套 Camera-WiFi 数据采集系统,其中数据真值由基于相机数据的计算机视觉算法获得。该系统在房间周围布置 12 个摄像头,并在房间四面墙的近水平中心位置放置 4 个高度为 1.2 m 的 WiFi AP。数据采集前对摄像头进行标定,并通过 NTP 协议与 AP 同步。每个 AP 是一台配备商用 Intel 5300 WiFi NIC 的迷你电脑,该 NIC 具有由三根天线组成的 ULA,天线间距为 2.6 cm,接近 5.3 GHz 频段半波长。迷你电脑使用 CSI tool 47 从 NIC 物理层测量每个数据包的 CSI,带宽为 40 MHz,信道为 60。另一台配置相同的迷你电脑作为待定位客户端并持续发送数据包。所有 AP 的 WiFi NIC 都工作在监听模式并持续监听 5 GHz 无线信道。构建这两个数据集时,志愿者手持发射机的方式如 Fig. 7 所示。
注:
- 本文定位的对象是会主动发送 WiFi 数据包的客户端/发射端设备,而不是房间里的普通静态物体。AP 通过接收该设备发出的信号来获取 CSI,再估计这个客户端的位置。
- 实验中的待定位目标可以由人手持,也可以由机器人携带;如果一个设备静止放在桌面上并持续发包,本文方法定位的是这个静止的 WiFi 设备。
- 桌子、椅子、墙面、反射板等普通静态物体在本文中主要作为环境反射体存在,它们会改变多径传播并影响 CSI,但不是网络直接输出位置的目标。
- 因此本文属于主动 WiFi 设备定位,而不是被动静态物体检测;对于完全不发射 WiFi 信号的普通物体,本文方法不能直接给出其坐标。

Fig. 6. UWB-WiFi 数据集不同场景布局。AP 用橙色标记,反射体用蓝色标记。
Fig. 7. 发射机手持示意图。
2. 训练与测试细节。 本文使用 PyTorch 63 实现模型,激活函数设为 ReLU,dropout 比例设为 0.2。训练 epoch 为 25,batch size 为 256。模型使用 Adam 优化器训练,学习率为 0.01,并采用衰减因子 0.99 的指数衰减调整学习率。权重因子 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 均设为 2。训练集与测试集比例为 8:2,并选择最后一个模型作为最终模型。
3. 相位校准。 对于 SpotFi 13 和 BreathTrack 64 中提到的 AP 相位校准,作者预先测量每个 AP 天线之间所有可能的相位差 65。设备重启后,将发射机带到 AP 前方移动并采集数据。随后,使用预先获得的相位差校准重启后的 AP,并运行波束成形算法估计 AoA。作者选择使 AoA 估计误差最小的相位差作为该次 AP 启动的相位差。这比手动连接同轴电缆校准更高效。
B. 基线方法
本文将所提方法与以下先进室内定位方法进行比较。
Co-Loc 16 引入非参数稀疏恢复度量来量化 AoA 精度,并通过观察用户客户端和多个 AP 之间的 AoA 会相交于一点来进一步提高 AoA 和定位精度。
DLoc 17 将深度学习定位定义为图像翻译问题,并借鉴现有神经网络架构来实现高定位精度。
SpotFi 13 使用空间平滑 MUSIC 算法从 CSI 中联合估计 AoA 和 ToF 信息,并结合多个 AP 的 AoA 确定客户端位置。
在评估整体性能后,本文进一步分析单个参数估计精度,即 AoA 和距离。具体而言,将 AoA 估计精度与波束成形、SpotFi 和 Co-Loc 估计结果比较;将距离估计精度与 CUPID 66 比较。由于 DLoc 数据集和本文数据集的数据格式不同,部分方法进行了修改,并尽力复现其工作。

Table I. 场景分类。
VI. 评估
为全面比较本文方法和先进定位方法的性能,论文将测试场景划分为简单场景和复杂场景。简单场景选择 DLoc 数据集中的 Atkison Hall,以及 UWB-WiFi 数据集中的 Conference 和 Lounge。这些场景中不存在大尺度反射体,对应常规测试定位方法的良好条件。复杂场景选择 DLoc 数据集中的 Jacobs Hall 和 UWB-WiFi 数据集中的 Office。这些场景中存在多个会导致复杂多径传播的反射体,更接近实际 WiFi 定位系统部署中的挑战。各场景详细描述见 Table I。
测试深度学习方法的泛化性能非常重要,因为能否有效泛化到未见数据是其实际部署的关键因素。评估泛化性能可以检验模型处理真实应用中可能遇到的变化、噪声和不同场景的能力。本文从域和布局两个方面测试泛化能力。随后,通过消融实验深入分析本文方法的有效性。最后,本文还进行了一些与计算开销等因素相关的实验。
A. 简单场景
1. 定位精度。 为验证已有工作复现的正确性,并比较不同方法的基础性能,论文选择数据集中的简单场景进行实验。Atikson Hall 部署 3 个 AP,环境非常简单且具有 LOS 条件;Conference 部署 4 个 AP,人体行走路径较简单;Lounge 可供人体移动的空间更大,部署 4 个 AP,并包含多张桌子和周围椅子。定位结果如 Fig. 8 所示。
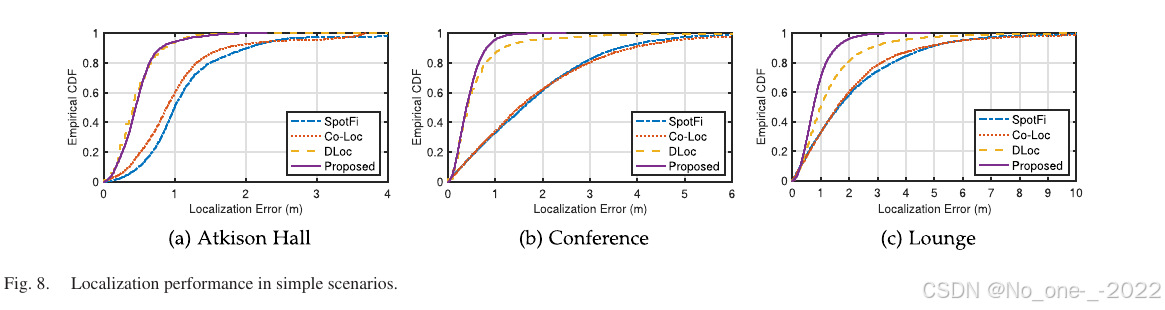
Fig. 8. 简单场景中的定位性能。
在 Atkison Hall 中,本文方法中位误差为 0.44 m,90 分位误差为 0.80 m。DLoc 中位误差为 0.41 m,90 分位误差为 0.85 m。本文方法的中位误差略差于 DLoc,但 90 分位误差略优于 DLoc。另一方面,SpotFi 和 Co-Loc 的中位误差分别为 0.99 m 和 0.88 m,90 分位误差分别为 2.02 m 和 1.71 m。可以观察到,基于深度学习的方法显著优于基于信号处理的方法,而基于信号处理的方法并未达到同等定位精度,只勉强达到分米级精度。这首先是因为深度学习方法对环境具有强拟合能力;其次,随机移动机器人和人体采集的数据不带偏置,可能来自空间中任意位置,从而落入阵列边界角度,导致未考虑该情况的方法出现较大 AoA 估计误差并降低定位性能 57。
在 Conference 场景中,本文方法保持了与 Atkison Hall 中相近的性能,中位误差为 0.38 m,90 分位误差为 0.81 m。DLoc 的中位误差仍为 0.41 m,但 90 分位误差增至 1.17 m。两种测试场景的主要区别在于设备是否由人体手持。DLoc 将不同 AP 的信息组合后输入网络训练,而任意 AP 的 CSI 都会受到人体运动影响,导致测试阶段的组合特征与网络学习到的特征之间存在差异,从而降低定位性能。本文方法在网络输入处解耦 AP 信息,并在定位阶段只基于不同 AP 的单独定位结果进行定位,降低了不同 AP 信息之间的相互影响,因此提升了定位精度。由于 WiFi 设备空间分辨率有限,且缺乏对人体扰动的建模,SpotFi 和 Co-Loc 出现更严重的性能退化,其中位误差分别为 1.58 m 和 1.49 m,90 分位误差分别为 3.60 m 和 3.89 m。
在空间更大的 Lounge 中,本文方法中位误差和 90 分位误差分别增至 0.73 m 和 1.53 m。DLoc 中位误差增至 1 m,而 90 分位误差降至 2.74 m。SpotFi 和 Co-Loc 性能进一步下降,中位误差分别为 1.63 m 和 1.58 m,90 分位误差分别为 4.73 m 和 4.54 m。Lounge 扩大的开放区域增加了随机行走路径的复杂性,进一步放大了人体运动对 CSI 的影响,提高了神经网络拟合函数的复杂度。因此,深度学习方法性能下降。同时,信号处理方法误差继续增大,进一步说明人体扰动对这些方法性能有显著影响。
2. 参数估计精度。 这些场景下的参数估计结果如 Fig. 9 所示。结果显示,本文方法的参数估计性能明显优于其他方法,这是高精度定位的基础。
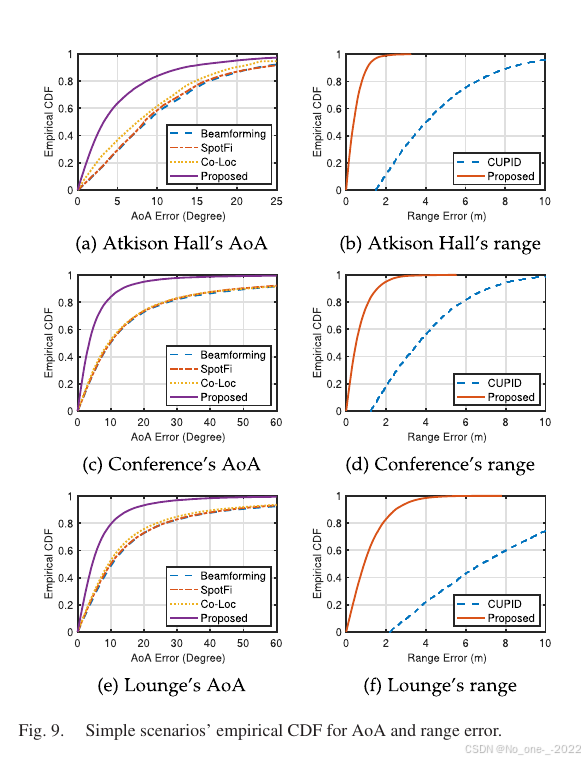
Fig. 9. 简单场景中 AoA 和距离误差的经验 CDF。
对于 AoA 估计,本文方法在不同场景中的中位误差保持在 3 ∘ 3^\circ 3∘ 到 4 ∘ 4^\circ 4∘,90 分位误差保持在 10 ∘ 10^\circ 10∘ 到 16 ∘ 16^\circ 16∘。波束成形、SpotFi 和 Co-Loc 的表现相近,中位误差为 5 ∘ 5^\circ 5∘ 到 10 ∘ 10^\circ 10∘,与本文方法差距不大;但它们的 90 分位误差较大,为 20 ∘ 20^\circ 20∘ 到 51 ∘ 51^\circ 51∘。对基于多 AP 联合 AoA 的定位而言,单个 AoA 测量中的大误差即可导致最终定位结果出现显著误差,这正是这些基于 AoA 的方法在复杂场景中表现较差的原因。
对于距离估计,本文方法在不同场景中的中位误差保持在 0.38 m 到 0.90 m,90 分位误差保持在 1.05 m 到 2.48 m。如 Fig. 11 所示,CUPID 性能较差,难以满足实际室内位置服务需求。
本文方法通过波束成形层释放神经网络潜力,实现高精度参数估计。这使其在不同场景中始终获得优于其他方法的定位性能。
B. 复杂场景
真实环境并不总像简单场景那样理想,可能存在复杂多径传播、大型反射面以及影响数据质量的其他因素。为此,论文设计复杂场景测试多种方法在挑战条件下的性能。定位结果如 Fig. 10 所示。
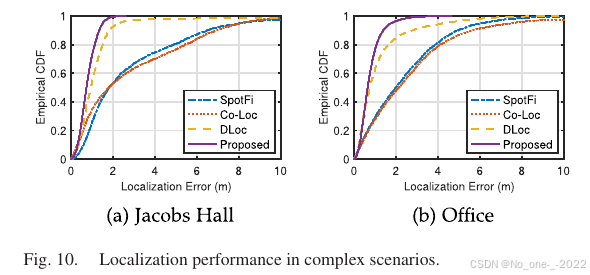
Fig. 10. 复杂场景中的定位性能。
在 Jacobs Hall 中,存在两块等离子屏幕,并且一个 AP 被墙体阻挡。本文方法中位误差为 0.73 m,而 DLoc、SpotFi 和 Co-Loc 分别为 0.94 m、1.82 m 和 1.81 m。本文方法 90 分位误差为 1.34 m,而 DLoc、SpotFi 和 Co-Loc 分别为 1.81 m、6.48 m 和 6.96 m。在该场景中,DLoc 性能略差于本文方法;而信号处理方法表现较差,说明它们无法处理具有大量反射面的复杂场景。
Office 场景引入人体扰动,减少了一个反射面,并包含多个杂乱工位。本文方法中位误差为 0.64 m,90 分位误差为 1.40 m。DLoc 中位误差降至 0.76 m,但 90 分位误差较 Jacobs Hall 增至 2.79 m,进一步说明人体扰动会增加 DLoc 的尾部误差。SpotFi 和 Co-Loc 的中位误差分别为 1.99 m 和 2.14 m,90 分位误差分别为 4.95 m 和 5.63 m。与 Jacobs Hall 测试结果相比,它们的尾部误差下降。作者认为这是因为反射数量减少,使传统信号处理方法更容易从 CSI 中获得 LOS 路径 AoA,从而缓解定位性能退化。
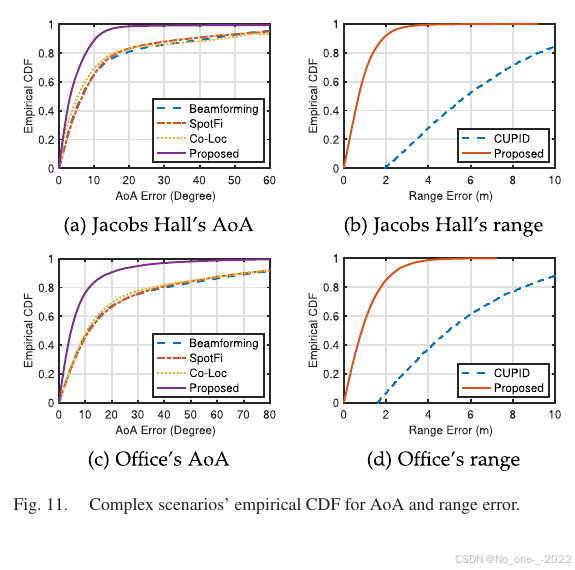
Fig. 11. 复杂场景中 AoA 和距离误差的经验 CDF。
对于复杂场景中的 AoA 估计,在 Jacobs Hall 中,本文方法中位误差为 3.2 ∘ 3.2^\circ 3.2∘,90 分位误差为 10.4 ∘ 10.4^\circ 10.4∘。Co-Loc 在 Jacobs Hall 中的中位误差为 5.4 ∘ 5.4^\circ 5.4∘,90 分位误差为 46.2 ∘ 46.2^\circ 46.2∘;SpotFi 和波束成形的中位误差分别为 6.7 ∘ 6.7^\circ 6.7∘ 和 6.5 ∘ 6.5^\circ 6.5∘,90 分位误差分别为 36.7 ∘ 36.7^\circ 36.7∘ 和 42.6 ∘ 42.6^\circ 42.6∘。当测试场景变为 Office 时,本文方法性能略有下降,中位误差为 4.6 ∘ 4.6^\circ 4.6∘,90 分位误差为 19.3 ∘ 19.3^\circ 19.3∘。然而,Co-Loc、SpotFi 和波束成形性能显著下降:其中位误差分别增加 5.3 ∘ 5.3^\circ 5.3∘、 4.8 ∘ 4.8^\circ 4.8∘ 和 4.6 ∘ 4.6^\circ 4.6∘,90 分位误差分别增加 25.1 ∘ 25.1^\circ 25.1∘、 33.8 ∘ 33.8^\circ 33.8∘ 和 31.1 ∘ 31.1^\circ 31.1∘。
对于距离估计,本文方法在 Jacobs Hall 中中位误差为 0.70 m,90 分位误差为 1.86 m;在 Office 中中位误差为 0.86 m,90 分位误差为 2.36 m。
C. 泛化能力
本文从两个不同视角测试基于深度学习定位方法的泛化性能:域泛化和布局泛化。这两个视角覆盖了不同泛化维度,能够全面评估方法在各种域和布局中准确、一致运行的能力。通过考察深度学习方法在这些多样场景中的性能,可以了解其适应性、鲁棒性以及真实应用适用性。
1. 域泛化。 训练深度学习模型通常需要大量数据和计算资源。如果一个域中训练的深度学习模型可以直接泛化到其他域,将大幅节省人力和计算资源。为测试这一能力,论文在单个场景中训练模型,并在其他场景中测试,以评估深度学习方法的跨域性能。
如前所述,神经网络输出的笛卡尔坐标高度依赖训练环境。因此,论文仅使用本文神经网络输出的极坐标测试跨域性能。结果如 Table III 所示。无论训练和测试场景如何,本文方法都表现出基本的分米级定位能力,尽管与源场景相比性能有所下降。另一方面,DLoc 的定位误差显著增加。在最佳情况下,本文方法的中位误差和 90% 尾部误差分别增加 69% 和 73%;相比之下,DLoc 的中位误差和 90% 尾部误差分别增加 195% 和 150%。造成这种差异的根本原因是 DLoc 的输入和输出都是笛卡尔坐标下的位置热力图,而这些热力图嵌入了 AP 的位置;AP 位置在不同环境中很可能变化,因此位置热力图会成为与源场景强相关的特征。本文通过将极坐标中的角度和距离信息作为输出,使网络能够学习可跨域泛化的特征。
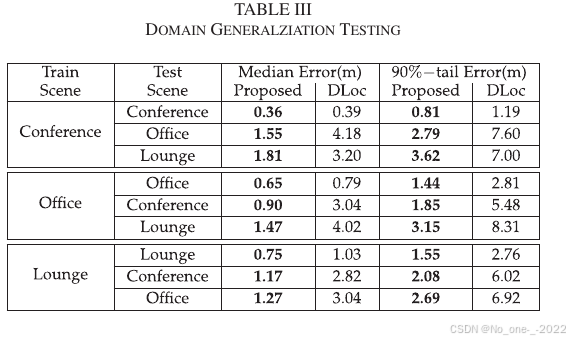
Table III. 域泛化测试。
2. 布局泛化。 深度学习定位方法部署后,日常活动会改变环境,使部署场景和训练场景不一致。由于模型无法实时更新,测试深度学习定位方法对同一场景内不同布置的泛化能力十分重要。本文将这种能力称为布局泛化。
为评估该能力,作者在一个场景内设置 7 种不同布局,并使用前述 Camera-WiFi 系统采集训练和测试数据。其中,第一个布局为空场景,第二到第七个布局依次引入不同家具和实验设备。训练数据集包含 21,600 个样本,每个测试场景数据集包含 5,400 个样本。最终测试结果如 Table II 所示。
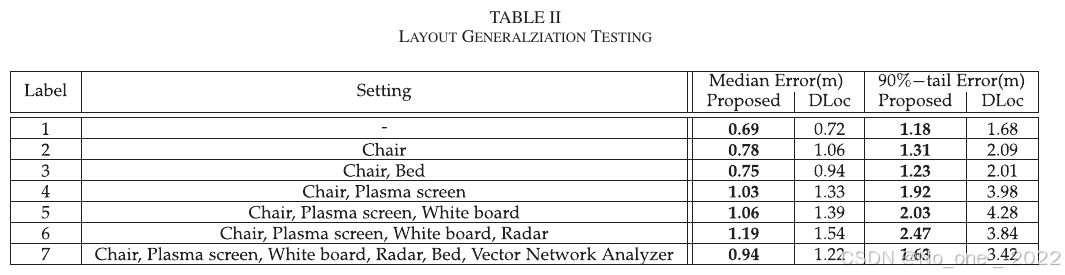
Table II. 布局泛化测试。
测试结果表明,本文方法始终优于 DLoc。这里有两点值得注意。第一,随着环境复杂度增加,两种方法的定位误差都会增加,但并非严格正相关。第二,在场景 4 的测试结果中,引入大型反射面(等离子屏幕)会导致两种方法的中位误差和 90 分位误差均增加,说明反射面对深度学习方法具有显著影响。
D. 消融研究
本文进行了一系列受控实验,以评估不同组成部分或因素对所提方法性能的影响。消融实验在简单场景和复杂场景的数据上均进行了全面测试。
1. 波束成形层消融。 为确认波束成形层有效性,论文进行了两个实验。一个是移除网络中的波束成形层,直接输入通过波束成形获得的 CSI 复频谱;另一个是使用 50 提出的卷积层替代波束成形层。结果见 Table IV。
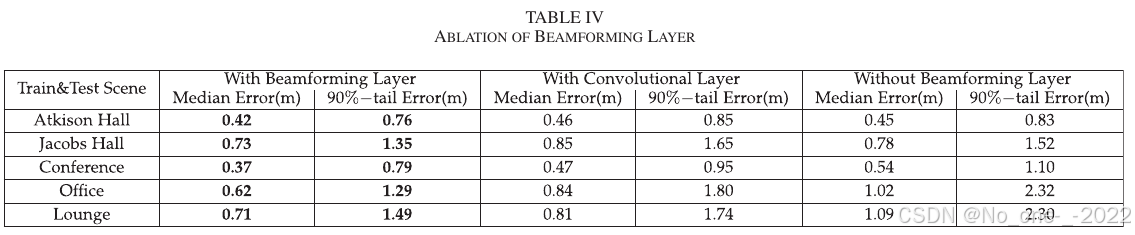
Table IV. 波束成形层消融。
相比卷积层,波束成形层使中位误差降低 9% 到 26%,使 90 分位误差降低 10% 到 28%。相比直接输入复频谱,波束成形层使中位误差降低 6% 到 39%,使 90 分位误差降低 8% 到 44%。结果表明,波束成形层有效提升了定位精度。
2. 波束成形初始化消融。 前文中,本文使用波束成形相位偏移矩阵初始化波束成形层权重矩阵。为验证波束成形知识的有效性,论文比较了随机初始化波束成形层和使用波束成形相位偏移矩阵初始化的结果。Table V 显示,波束成形初始化提升了模型性能。具体而言,波束成形初始化使中位误差降低 9% 到 14%,使 90 分位误差降低 5% 到 26%。
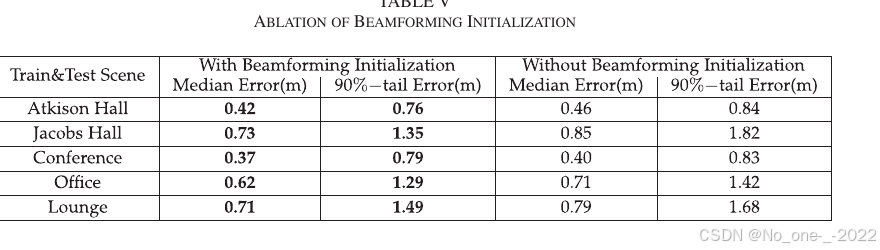
Table V. 波束成形初始化消融。
3. 多任务学习消融。 为测试多任务学习有效性,论文对所提网络进行修改,构造两个变体:一个变体回归极坐标,另一个变体直接回归笛卡尔坐标。这两个网络分别称为 AoA-Range 分支网络和 X-Y 分支网络。测试结果见 Table VI。
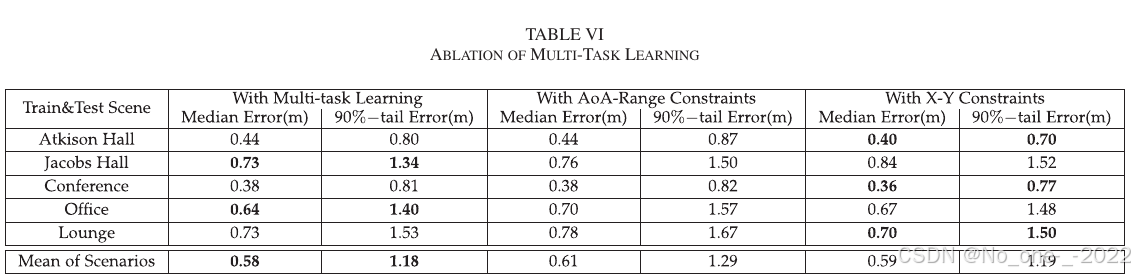
Table VI. 多任务学习消融。
一个直观观察是,使用多任务学习的网络性能并不总是最好。在一些情况下,直接回归笛卡尔坐标的网络表现更好。但这是因为神经网络过拟合了环境,从而缺乏域泛化能力。本文目标是通过多任务学习同时实现高定位精度和域泛化能力,并有效结合二者。相比与特定场景紧密耦合的笛卡尔坐标直接回归网络,多任务学习网络的精度在某些场景中略有下降,但这是可接受的。
E. 其他考虑
1. 将模型迁移到新域。 在 VI-C 节中,论文已经展示了本文方法的域泛化能力。这里进一步展示:只使用新环境中的少量数据微调模型,即可进一步提升定位精度。
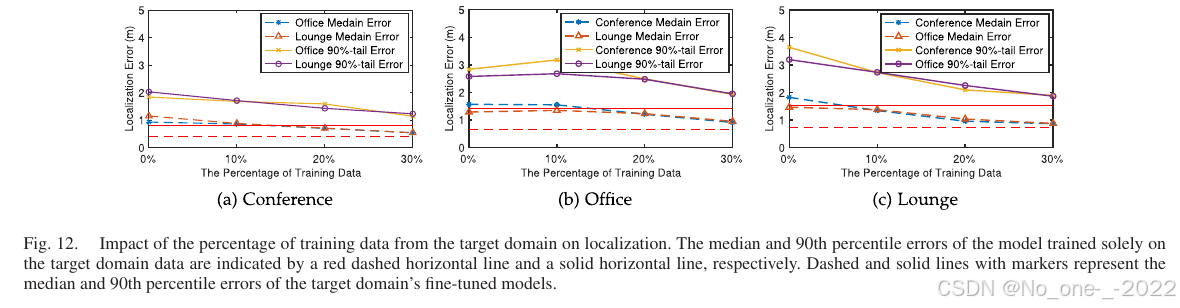
Fig. 12. 目标域训练数据比例对定位的影响。红色虚线和红色实线分别表示仅使用目标域数据训练的模型的中位误差和 90 分位误差;带标记的虚线和实线表示目标域微调模型的中位误差和 90 分位误差。
从 Fig. 12 可以观察到,随着训练数据量增加,微调模型的中位误差和 90 分位误差整体呈下降趋势。当训练数据占 10% 时,在大多数场景下,中位误差和 90 分位误差分别降低 1% 到 26% 和 9% 到 25%,但也存在误差增加 3% 到 12% 的情况。当训练数据占 20% 时,中位误差降低 5% 到 47%,90 分位误差降低 4% 到 42%。当训练数据占 30% 时,中位误差和 90 分位误差分别保持在 1 m 和 2 m 以内。然而,与仅在目标域训练的模型相比,中位误差和 90 分位误差仍分别存在 0.15 m 到 0.3 m、0.36 m 到 0.54 m 的差距。这只是初步验证,作者认为还有更有效的方法可将具有域不变特征的模型迁移到新环境。
2. AP 数量影响。 在实际环境中,并不总能使用多个 AP 的信息,因此研究 AP 数量对本文方法定位精度的影响具有意义。论文基于 Camera-WiFi 系统采集的数据进行实验,结果见 Table VII。
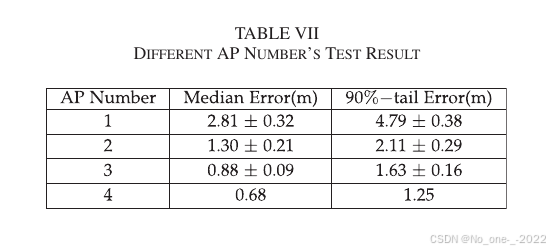
Table VII. 不同 AP 数量的测试结果。
结果表明,随着 AP 数量增加,定位精度提高。这是因为 AP 数量增加使可用信息更多,并降低了数据噪声对定位结果的负面影响。
注:
- 从 Table VII 看,本文方法使用 1 个多天线 AP 也可以定位,但误差较大;AP 数量从 1 增加到 4 时,中位误差约从 2.81 m 降到 0.68 m。
- 因此实际部署时,1 个 AP 可用但不稳,3 到 4 个具备 CSI 采集和多天线接收能力的 AP 会更适合获得较可靠的定位效果。
3. 计算开销。 部署系统需要满足实际实时处理需求。这里,论文将本文方法与 DLoc 进行比较。本文模型大小约为 DLoc 的三分之一,更加轻量。推理时间计算使用单块 NVIDIA V100 GPU。在相同数据下,评估 18,000 个数据点,并用总推理时间的平均值获得每个数据点的推理时间。如 Table VIII 所示,本文方法推理时间短于 DLoc。
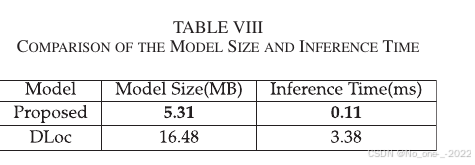
Table VIII. 模型大小与推理时间比较。
VII. 大规模实验
为进一步研究本文方法性能,论文在更大场景中进行了实验。实验场景描述见 Table IX,布局如 Fig. 13 所示。
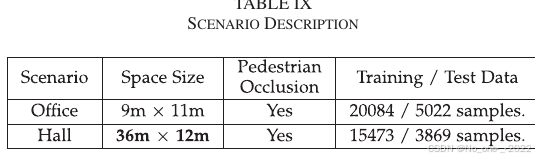
Table IX. 场景描述。

Fig. 13. Hall 场景布局。
论文分别在小规模和大规模环境中训练模型,并在大规模和小规模环境中测试。结果如 Fig. 14 所示。可以看到,无论是从小规模场景迁移到大规模场景,还是从大规模场景迁移到小规模场景,所提算法都始终优于现有 DLoc 和 SpotFi。
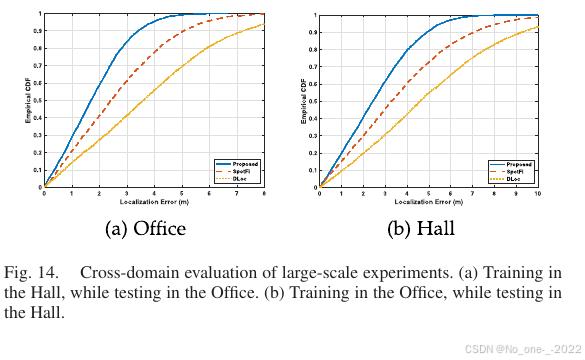
Fig. 14. 大规模实验中的跨域评估。
(a) 在 Hall 训练,在 Office 测试;(b) 在 Office 训练,在 Hall 测试。
VIII. 结论
本文研究了基于信号处理的定位方法的局限性,以及现有基于深度学习的方法缺乏跨域能力的问题。通过从信号处理视角设计基于深度学习的定位方法,所提方法显著优于基于信号处理的先进方法。与现有深度学习方法相比,本文将定位 90 分位误差最高降低 49%,在跨域条件下表现出更优性能。此外,本文向研究社区发布数据集以支持后续研究。本文工作推动了 WiFi 定位研究的发展,并展示了将信号处理与深度学习技术结合以提升室内定位精度和泛化能力的潜力。
参考文献
参考文献条目较长,本文保留正文中的原始引用编号;完整参考文献请见源 PDF 的 References 部分。