阅读 OpenAI《Harness Engineering》与 Anthropic《Effective harnesses for long-running agents》《Harness design for long-running application development》有感,原文链接放最后了.
引言:一个反直觉的悖论
2025 年 8 月,OpenAI 一个三人团队向空仓库提交了第一行代码。五个月后,这个仓库膨胀到一百万行,1,500 个 PR,数百名日活用户。团队扩大到七人,人均日处理 PR 数不降反升。
而人类工程师写下的代码行数是:零。
几乎同时,Anthropic Labs 让 Claude 用 6 小时独立构建了一个 2D 复古游戏引擎,4 小时构建了一个数字音频工作站(DAW)。在多轮迭代中,它还设计出了荷兰艺术博物馆的高质量官网------那种在第 10 轮迭代时突然抛弃常规布局、改用 CSS 3D 透视渲染展厅空间的"创造性跳跃"。
这两个实验的主角不是 GPT-5 也不是 Claude Opus 4.5。主角是一套被称为 Harness 的运行制度。
但这里有一个悖论:模型能力明明在指数级增长,为什么反而更需要"缰绳"?如果马跑得越来越快,缰绳不应该越来越松吗?
答案是:大模型的原生缺陷不是能力不足,而是"组织自己"的能力不足。 就像一位天才工匠被扔进一个没有时间概念、没有记忆、不能回头的房间。他能做出精美的零件,但做不出一架飞机。
Harness Engineering 的本质 ------ 为什么大模型时代急需它
从 Prompt Engineering 到 Harness Engineering 的范式跃迁
大模型应用的发展经历了三个阶段:
| 阶段 | 核心关注点 | 代表实践 | 局限 |
|---|---|---|---|
| Prompt Engineering | 单次输入的魔法咒语 | Few-shot、CoT、ToT | 无法处理长周期、多步骤任务 |
| Context Engineering | 如何高效填充上下文窗口 | RAG、压缩、分层检索 | 只解决 "输入什么",不解决 "如何运转" |
| Harness Engineering | 设计智能体的运行环境与制度体系 | 多 Agent 协作、状态外化、反馈回路 | 需要系统性架构思维 |
Harness(缰绳) 这个词的隐喻极其精准:它不是马匹本身(模型能力),也不是骑手(人类意图),而是 连接二者、传递力量、施加约束、确保方向的整套装备系统。在大模型语境下,Harness 是:
一套包含工具接口、沙箱环境、架构约束、自动化测试、反馈循环及监控仪表盘的完整运行环境与制度体系,旨在引导和约束 AI 智能体,使其能够自主、可靠地完成复杂长周期任务,而无需人类实时干预。
大模型的原生缺陷:为什么必须需要 Harness
没有 Harness 的前端模型,即使强如 Opus 4.5,在面对 "构建一个 claude.ai 克隆" 这样的高级指令时,也会表现出四种系统性失败模式:
- 一次性冲刺(One-shotting):试图在一个上下文窗口内完成所有工作,导致中途耗尽上下文,留下半成品和未记录的状态。
- 过早宣布完成(Premature Completion):看到局部进展就认为任务完成,忽略后续功能。
- 上下文焦虑(Context Anxiety) :当接近上下文限制时,模型会主动 "收尾",草率结束尚未完成的工作。这是 Anthropic 发现的一个关键现象------仅靠上下文压缩(Compaction)无法解决,因为压缩会传递模糊指令,而模型对上下文边界的 "恐惧" 会改变其行为模式。
- 自我评估过度自信(Overconfidence):模型评估自己的产出时倾向于高估质量,尤其在主观任务(如 UI 设计)上。
这些缺陷的根源在于大模型的底层机制:
- 上下文窗口是有限且离散的 :Transformer 的注意力机制在超长序列上呈二次方复杂度,即使窗口扩展到 200k,有效注意力(Effective Attention) 依然集中在局部。模型在窗口末端的推理质量显著下降。
- 状态内置于参数,而非显式记忆:模型没有真正的长期记忆,所有 "记忆" 都是上下文中的 token。一旦会话结束,状态即丢失。
- 自回归生成的不可逆性:模型生成 token 的过程是单向的,无法像人类一样 "先思考再动手",容易陷入局部最优。
Harness Engineering 正是为了系统性解决这些原生缺陷而生。
OpenAI 与 Anthropic 的 Harness 实践
业务背景与技术路线对比
两篇文章表面上是技术实践,我觉得底层是更像是两种工程世界观的碰撞。
OpenAI:制度工程师
OpenAI 的 Codex 团队构建的是产品级 Harness------一套需要持续演进五个月的工业化制度。
他们的核心信念是:"人类掌舵,智能体执行。" 工程师不写代码,而是设计环境、意图和反馈回路。随着代码吞吐量增加,人类 QA 成为瓶颈,因此他们将审核工作 Agent 化,形成了所谓的 "Ralph Wiggum 循环"(源自《辛普森一家》中那个总是说"我什么都没做"的角色------讽刺的是,人类在这个循环中确实越来越不需要做什么)。
关键设计:
-
代码仓库即记录系统(System of Record)。所有知识必须版本化、可机械检查。专职 linter 验证文档链接有效性、新鲜度、结构合规性。甚至有一个"doc-gardening"智能体定期扫描过时文档并发起修复 PR。
-
渐进式披露(Progressive Disclosure) 。
AGENTS.md只有约 100 行,是"地图"而非"说明书"。它指向docs/目录中的深层文档------设计文档、执行计划、产品规范、技术债务追踪器。 -
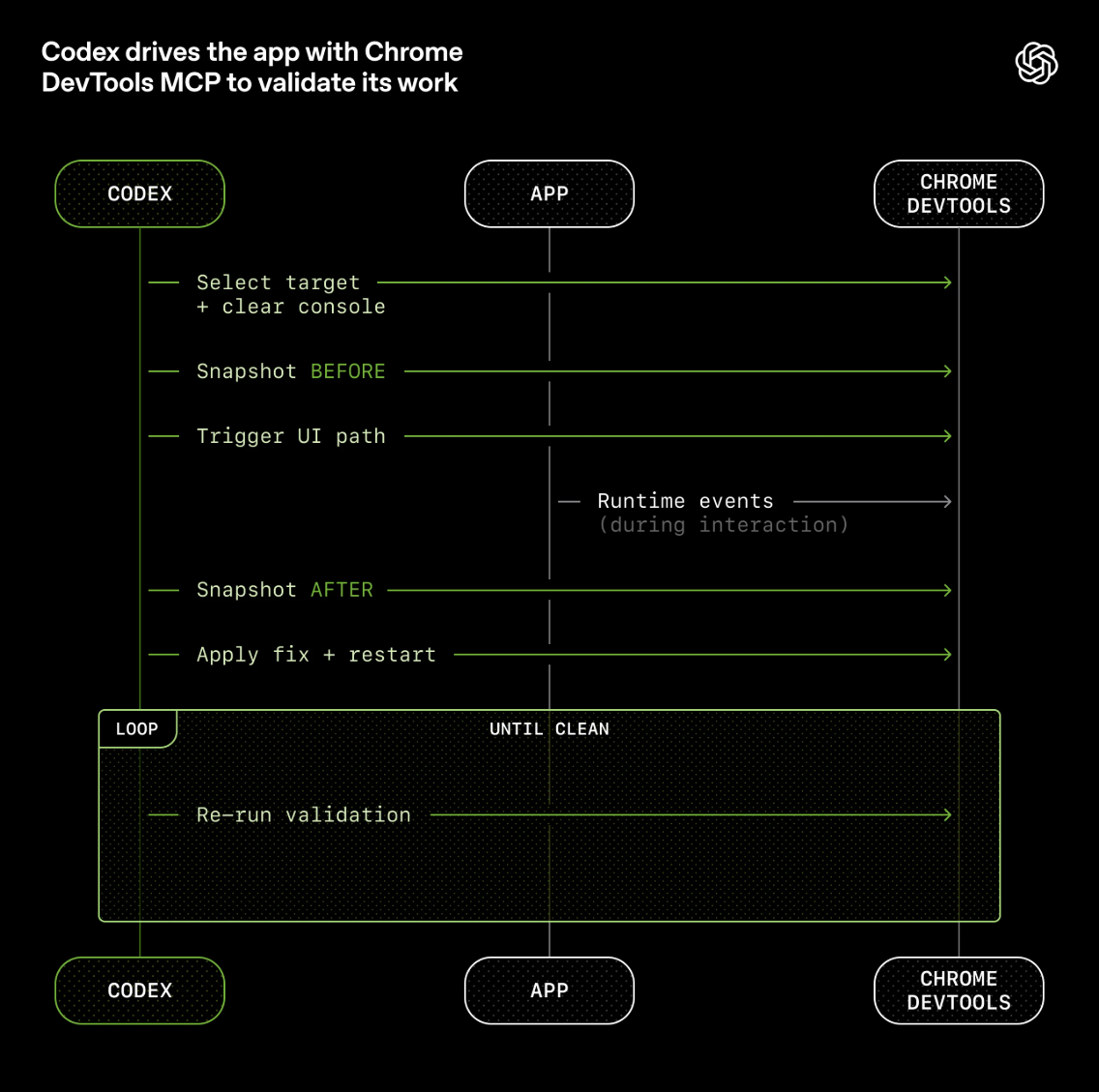
可观测性即感官延伸。Chrome DevTools MCP 让 Codex 能选择目标、清除控制台、捕获 DOM 快照、触发 UI 路径、截图对比。验证循环是
指标的可观测性则是通过:日志查询(LogQL)和指标查询(PromQL)直接暴露给 Agent。这样前后端都是可观测的
Anthropic:对抗训练师
Anthropic Labs 构建的是项目级 Harness ------针对单次 4-6 小时的长周期任务,强调对抗性优化。
他们的核心信念是:"每个新 session 都是一位失忆的新工程师,靠交接文档恢复状态。"
关键设计:
- 三 Agent 架构(Planner + Generator + Evaluator)。受 GAN 启发,Generator 和 Evaluator 形成对抗式优化闭环。Planner 将高级目标分解为 JSON 格式的 Feature List。
- Sprint Contract 机制。Generator 和 Evaluator 在每次编码前先协商"完成的定义"(Definition of Done)。Generator 提议构建内容和验证方式,Evaluator 审查以确保 Generator 在构建正确的东西。这种"先签合同再干活"的机制解决了过度乐观问题。
- Context Reset 而非 Compaction 。对于长任务,主动结束 session,通过 Handoff Artifact(
claude-progress.txt、feature-list.json、init.sh)启动新 session。Reset 不是放弃记忆,而是将记忆外化到更可靠的存储------文件系统。
一个关键的差异:模型进化如何淘汰 Harness 组件
Anthropic 在实验中发现了一个反常识现象:Harness 的组件不是越复杂越好,而且模型的进化会不断让某些组件"失效"。
Opus 4.5 表现出强烈的 Context Anxiety,因此必须依赖 Sprint 分解和 Context Reset。但 Opus 4.6 发布时,其官方改进包括"更谨慎地规划、更长时间地维持 Agent 任务、在更大代码库中更可靠地运行、更好的代码审查和调试能力"。于是 Anthropic 做了一个实验:移除 Sprint 结构。
结果令人惊讶:4.6 可以在没有 Sprint 分解的情况下连续运行超过两小时保持连贯。Evaluator 仍然有价值,但只在超出模型原生能力边界的任务上。对于模型已经能可靠完成的任务,Evaluator 变成了不必要的开销。
这揭示了一个深层原则:Harness 中的每个组件都编码了一个关于"模型不能做什么"的假设。这些假设会随模型进化而失效,因此 Harness 必须持续被"压力测试"和简化。
| 维度 | OpenAI(Codex 团队) | Anthropic(Labs 团队) |
|---|---|---|
| 业务目标 | 从零构建内部 SaaS 产品(百万级代码库) | 长周期自主软件工程(前端设计 + 全栈应用) |
| Harness 哲学 | 制度性(Governance):CI、linter、doc-gardening | 对抗性(Adversarial):Generator-Evaluator 博弈 |
| 状态管理 | 仓库即真相源,渐进式披露 | 文件系统外化(JSON + progress.txt + init.sh) |
| 测试策略 | Chrome DevTools MCP + LogQL/PromQL | Playwright MCP + 结构化评分 |
| 评估机制 | Agent 自审 + 交叉审查 + 人类可选审核 | 独立 Evaluator,四维度评分(Design/Originality/Craft/Functionality) |
| 成本特征 | 持续投入,追求吞吐量 | 单次高成本(200 vs 9),追求质量跃迁 |
共性提炼:优秀 Harness 的五大黄金法则
尽管路线不同,两篇文章在底层设计上高度一致:
法则一:状态必须外化到文件系统
OpenAI 将 docs/ 目录作为知识库的唯一真相源,Anthropic 将 claude-progress.txt、feature-list.json 和 init.sh 作为跨 session 的 "交接文档"。核心共识:上下文窗口不是存储,文件系统才是。 这类似于解决内存泄漏的思路------不优化内存,而是重启进程并从磁盘恢复状态。
法则二:渐进式披露优于百科全书式灌输
OpenAI 的 AGENTS.md 只有 100 行,是 "地图" 而非 "说明书";Anthropic 的 Feature List 是 JSON 结构化数据,每次只加载当前任务所需信息。两团队都发现:给 Agent 一张地图,比给一本 1000 页的说明书更有效。 过多的指导会挤占任务上下文,导致模型进行错误的局部模式匹配。
法则三:分离 "做事" 与 "评判"
OpenAI 让 Codex 在提交 PR 前进行自我审查,并引入其他 Agent 进行交叉审查;Anthropic 明确将 Generator 与 Evaluator 分离,并指出:"让独立的 Evaluator 保持怀疑态度,远比让 Generator 自我批评更容易实现(far more tractable)。" 这本质上是在 Harness 层面实现了 关注点分离(Separation of Concerns)。
法则四:可观测性必须对 Agent 可读
OpenAI 将 Chrome DevTools Protocol、日志查询(LogQL)、指标查询(PromQL)直接暴露给 Codex;Anthropic 让 Evaluator 通过 Playwright MCP 与实时页面交互。两者的共同洞见:如果人类需要看截图才能判断 UI 好坏,Agent 也需要同样的感知通道。 可观测性不是给人类看的仪表盘,而是 Agent 的感官延伸。
法则五:增量推进是长周期任务的唯一可行策略
OpenAI 采用 "深度优先" 的模块化解构;Anthropic 强制 "每次只做 1 个 feature"。两者都拒绝了 "大爆炸式" 开发,因为 上下文窗口的离散性决定了复杂任务必须被切分为可在单个窗口内完成的原子单元。
2.3 差异分析:产品级 Harness vs 项目级 Harness
OpenAI 的 Harness 是为 持续演进的产品 设计的:需要处理 1500 个 PR、维护技术债务、进行文档园艺(doc-gardening)、支持多人(多 Agent)协作。其 Harness 强调 制度性------CI 验证、 linter、知识库新鲜度检查。
Anthropic 的 Harness 是为 单次长周期项目 设计的:6 小时构建游戏引擎、4 小时构建 DAW。其 Harness 强调 对抗性------Generator-Evaluator 的迭代循环、上下文重置的干净启动。
这种差异决定了 Harness 设计的两个方向:产品 Harness 需要治理(Governance),项目 Harness 需要对抗(Adversarial)。
第三章:多 Agent 协作机制深度拆解
3.1 Anthropic 的三 Agent 架构:Planner-Generator-Evaluator
Anthropic 在前端设计和全栈开发中采用了受 GAN 启发的三 Agent 架构:
plain
复制
plain
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Planner │────→│ Generator │←────│ Evaluator │
│ (规划器) │ │ (生成器) │ │ (评估器) │
└─────────────┘ └─────────────┘ └─────────────┘
│ ↑ │
└───────────────────┴───────────────────┘
(迭代循环,5-15 轮)- Planner:将高级目标("构建 claude.ai 克隆")分解为可执行的 Feature List(JSON 格式),确定优先级和依赖关系。
- Generator:每次 session 只处理一个 feature,编写代码并进行端到端测试。
- Evaluator :使用 Playwright MCP 与实时页面交互,从 Design Quality、Originality、Craft、Functionality 四个维度进行评分,提供详细批评反馈。
关键设计细节:
- Evaluator 被专门校准为 "skeptical"(怀疑论者),通过 few-shot 示例训练其给出严苛评价。
- 每轮迭代产生渐进式优化的输出,单次运行可迭代 5-15 轮,持续长达 4 小时。
- Evaluator 的反馈直接驱动 Generator 的下一轮改进,形成 对抗式优化闭环。
3.2 OpenAI 的 Agent 审查网络:Ralph Wiggum 循环
OpenAI 的 Harness 更侧重于 代码生产的工业化流程:
plain
复制
plain
人类工程师描述任务
↓
Codex (Generator)
↓
打开 Pull Request
↓
┌─────────────────┐
│ 本地自审 Agent │
│ 云端审查 Agent │
│ 交叉审查 Agent │
└─────────────────┘
↓
反馈循环直到通过
↓
可选人类审核
↓
合并OpenAI 将这个循环称为 "Ralph Wiggum 循环" (源自《辛普森一家》)。其核心洞见是:随着代码吞吐量增加,人类 QA 成为瓶颈,因此必须将审核工作 Agent 化。 最终,该团队几乎将所有审核工作调整为 "Agent 审 Agent" 的模式。
3.3 单 Agent 多角色 vs 多 Agent 分离
Anthropic 在脚注中澄清了一个重要设计选择:其 Initializer Agent 和 Coding Agent 实际上是同一个 Agent,只是使用了不同的初始 user prompt。系统提示词、工具集和整体 Harness 完全相同。
这揭示了一个深层架构决策:
| 模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 单 Agent 多角色(Anthropic 早期) | 实现简单,无需角色间通信协议 | 角色混淆,评估偏差难以消除 | 任务边界清晰、评估客观的场景 |
| 多 Agent 分离(Anthropic 后期/OpenAI) | 评估更客观,可并行,可专业化 | 需要定义 Agent 间通信格式和状态传递 | 主观评估、长周期、高质量要求 |
Anthropic 从前端设计(主观)到全栈开发(客观)的演进中,逐渐从单 Agent 多角色转向多 Agent 分离,尤其是在 Evaluator 独立化上。OpenAI 则从一开始就是多 Agent 协作,因为产品级代码审查天然需要多视角。
实战启示:如果你的任务包含主观判断(UI 设计、文案质量),必须将 Evaluator 独立出来;如果任务以客观正确性为主(API 实现、算法逻辑),单 Agent 多角色即可满足。
测试与编码模块的设计细节
可观测性即代码:OpenAI 的 "感官延伸" 设计
OpenAI 的 Harness 将可观测性从 "人类仪表盘" 重新定义为 "Agent 感官系统":
Chrome DevTools MCP 接入:
- Codex 可以通过 CDP 选择目标、清除控制台、捕获 DOM 快照、触发 UI 路径、截图对比。
- 验证循环:
Snapshot BEFORE → Trigger UI → Runtime Events → Snapshot AFTER → Apply Fix → Re-run Validation → Loop Until Clean。
可观测性堆栈:
- 每个 git worktree 启动独立应用实例 + 临时可观测性堆栈。
- Codex 使用 LogQL 查询日志,PromQL 查询指标。
- 任务完成后,整个环境(包括日志和指标)被销毁,保持干净。
这使得提示词如 "确保服务启动在 800ms 内完成" 或 "这四个关键用户旅程中的任何跨度都不得超过两秒" 变得可执行------Agent 可以直接查询验证。
端到端测试即真理:Anthropic 的浏览器自动化
Anthropic 明确拒绝了 curl 级别的浅层测试,坚持使用 Playwright/Puppeteer 级别的浏览器自动化:
"Claude was able to identify and fix bugs that weren't obvious from the code alone."
其测试流程是 Generator 编码 → 启动应用 → Evaluator 用 Playwright MCP 导航 → 截图/交互验证 → 评分反馈。这种测试不是 "检查 API 是否 200 OK",而是 "检查按钮点击后模态框是否正确动画弹出"。
关键设计 :测试必须产生 结构化评分(JSON),而非开放式文本。Anthropic 的前端评估四维度(Design Quality / Originality / Craft / Functionality)每个都有明确的评分标准和 few-shot 校准示例。
反馈回路的形式化
两篇文章共同定义了 Harness 中反馈回路的三种形式:
| 反馈类型 | 触发时机 | 形式 | 作用 |
|---|---|---|---|
| 即时反馈 | 单轮工具调用后 | 工具返回结果(成功/失败/输出) | 修正当前行动 |
| 会话内反馈 | 单 session 内多轮迭代 | Evaluator 评分 + 批评 | 优化当前 feature |
| 跨会话反馈 | 新 session 启动时 | Handoff Artifact(progress.txt / git log / feature list) | 恢复状态,确定下一步 |
第五章:核心架构图景 ------ 一个优秀 Harness 的六层模型
基于对 OpenAI 和 Anthropic 实践的拆解,我总结出一个优秀 Harness 应具备的 六层架构模型。这个模型不是理论设想,而是对两家前沿团队实践的抽象与整合。
plain
┌─────────────────────────────────────────────────────────────┐
│ Layer 6: 意图与治理层 (Intent & Governance) │
│ - 人类指令解析、伦理约束、安全策略、成本预算 │
├─────────────────────────────────────────────────────────────┤
│ Layer 5: 知识库与渐进披露层 (Knowledge & Progressive Disclosure)│
│ - AGENTS.md (地图)、docs/ (真相源)、Feature List、Design Docs │
├─────────────────────────────────────────────────────────────┤
│ Layer 4: 评估与反馈层 (Evaluation & Feedback) │
│ - Evaluator Agent、评分标准、测试套件、审查规则 │
├─────────────────────────────────────────────────────────────┤
│ Layer 3: Agent 执行层 (Agent Runtime) │
│ - Generator Agent、Planner Agent、工具调用循环、上下文管理 │
├─────────────────────────────────────────────────────────────┤
│ Layer 2: 任务分解与状态管理层 (Task & State Management) │
│ - Feature List JSON、Progress Log、Handoff Artifact、Git 状态 │
├─────────────────────────────────────────────────────────────┤
│ Layer 1: 工具与沙箱层 (Tools & Sandbox) │
│ - MCP 工具集、浏览器自动化、可观测性查询、文件系统、代码执行环境 │
└─────────────────────────────────────────────────────────────┘工具与沙箱层 ------ Agent 的四肢与环境
这是 Harness 的基础设施。OpenAI 提供了 Chrome DevTools MCP、本地脚本、gh CLI、可观测性查询工具;Anthropic 提供了 Playwright MCP、代码执行工具、文件读写工具。
设计原则:
- 工具必须对 Agent 可读:如果工具输出是人类可读的日志,Agent 也必须能直接读取。避免 "人类看 Grafana,Agent 看文本摘要" 的双轨制。
- 沙箱必须可丢弃:每个 session 应在隔离环境中运行,任务完成后销毁,确保状态不污染。
- 工具调用必须可追踪:所有工具调用记录到结构化日志,供后续审计和调试。
任务分解与状态管理层 ------ 跨 session 的记忆系统
这是 Harness 最核心的创新层。状态外化是这个层的核心设计模式。
关键数据结构:
json
// feature-list.json (Anthropic 模式)
{
"features": [
{
"id": "auth-login",
"description": "Implement OAuth2 login flow",
"priority": 1,
"dependencies": ["db-schema"],
"passes": false,
"test_command": "npm run test:auth",
"notes": "Blocked by token refresh bug"
}
],
"metadata": {
"last_updated": "2026-05-21T14:32:00Z",
"session_count": 7
}
}
markdown
<!-- claude-progress.txt (Anthropic 模式) -->
## Session 7 Summary
- Completed: User profile page layout
- Blocked: Image upload (CORS issue)
- Next: Fix CORS then implement upload
- Git commit: a1b2c3d
bash
# init.sh (环境恢复脚本)
#!/bin/bash
git checkout main
git pull
npm install
npm run db:migrate
npm run dev &
echo "App ready at http://localhost:3000"设计原则:
- JSON 优于 Markdown:结构化数据更不易被模型意外修改。Anthropic 明确警告:"模型不太可能不适当地更改或覆盖 JSON 文件,相比之下 Markdown 文件风险更高。"
- 状态必须是自描述的:新 session 启动时,仅通过读取文件系统就能恢复全部上下文,无需外部记忆。
- Git 是状态的唯一真相源:每次 session 结束必须提交,提交信息包含进度摘要。
Agent 执行层 ------ 上下文调度与循环控制
这是 Harness 的 "大脑调度器"。
上下文管理三策略:
- Compaction(压缩):当上下文接近上限时,智能总结历史对话,保留关键决策和当前状态。
- Skill 渐进披露:不一次性加载所有工具和 MCP,而是根据当前任务动态加载相关 Skill(如 "前端调试 Skill"、"数据库迁移 Skill")。
- Context Reset(上下文重置) :当模型表现出 "上下文焦虑" 时,主动结束 session,通过 Handoff Artifact 启动新 session。这是 Anthropic 发现的关键策略------对于长任务,reset 比压缩更有效。
评估与反馈层 ------ 对抗式质量控制
这是 Harness 的 "免疫系统"。
Evaluator 设计要点:
- 独立性:Evaluator 必须是独立 Agent(或至少独立实例),与 Generator 不共享上下文。
- 怀疑论校准:通过 few-shot 示例训练 Evaluator 给出负面评价,避免 "好好先生" 偏差。
- 多维度评分:主观任务(如 UI)需要结构化评分维度;客观任务(如 API)需要断言式验证。
- 可执行性:Evaluator 的反馈必须能驱动 Generator 的具体改进行动,而非泛泛而谈。
知识库与渐进披露层 ------ Agent 的地图系统
OpenAI 的 AGENTS.md + docs/ 架构是这个层的最佳实践:
plain
AGENTS.md (≈100 行) ──→ 地图,指向深层文档
├── ARCHITECTURE.md ──→ 域和包分层的顶层地图
├── docs/
│ ├── design-docs/ ──→ 设计理念、核心信念
│ ├── exec-plans/ ──→ 活跃/已完成计划、技术债务
│ ├── product-specs/ ──→ 产品需求
│ └── references/ ──→ 外部技术参考(如 Nixpacks、uv)
├── DESIGN.md ──→ 设计系统
├── FRONTEND.md ──→ 前端规范
├── QUALITY_SCORE.md ──→ 质量评分与差距追踪
└── SECURITY.md ──→ 安全规范设计原则:
- AGENTS.md 是地图,不是百科全书:它只回答 "我在哪?我该去哪找什么?"
- 文档必须可机械检查:专职 linter 验证链接有效性、新鲜度、结构合规性。
- 知识必须版本化:所有文档与代码同仓库、同版本控制。
意图与治理层 ------ 人类的最终掌控
这是 Harness 的 "方向盘"。即使 Agent 自主运行,人类工程师仍通过以下机制保持掌控:
- 任务描述(Task Description):高级意图的自然语言表述。
- 约束规则(Constraints):如 "不手动写代码"、"所有变更必须通过 PR"、"禁止直接修改生产环境"。
- 预算与配额(Budget & Quota):API 调用成本上限、session 数量限制、时间盒(Time-boxing)。
- 安全策略(Security Policy):沙箱网络隔离、敏感操作人工确认、凭证代理(Credential Proxy)。
深度洞见 ------ Harness Engineering 的底层原理与未来
上下文焦虑的神经机制:为什么 Reset 比 Compaction 更有效
Anthropic 发现的 "Context Anxiety"(上下文焦虑) 是一个极具洞察力的现象。从 Transformer 的注意力机制分析,这一现象有其数学必然性:
Transformer 的注意力计算为 A tt e n t i o n (Q , K , V )= so f t ma x (d k Q K T )V 。当序列长度 L 接近上下文上限时:
- 注意力熵增 :so f t ma x 分布在超长序列上趋于平缓,每个 token 获得的注意力权重差异减小,导致 "注意力稀释"。
- 位置编码退化:即使是 RoPE 或 ALiBi 等外推编码,在接近训练长度极限时,相对位置感知能力也会下降。
- 元认知压力 :当模型在系统提示中感知到 "剩余 token 不足" 时(通过工具返回的上下文使用统计),会产生一种 隐性的优化压力------倾向于提前结束当前推理链,将 "完成" 作为优先目标而非 "正确"。
Compaction 的问题在于:它将历史对话压缩为摘要,但摘要的 信息损失 在复杂任务中是不可接受的。更关键的是,Compaction 保留了 "这是一个长对话" 的元信息,模型仍然感知到自己在处理一个历史沉重的会话。
Context Reset 的优雅之处在于 :它彻底切断了这种元认知压力。新 session 面对的是一个干净的注意力矩阵,没有任何历史负担。模型从 "交接文档" 中恢复状态,而非从压缩的上下文中继承焦虑。这类似于操作系统的 进程隔离------不修复内存泄漏,直接重启进程。
7.2 Harness 作为外部认知支架(External Cognitive Scaffolding)
从认知科学视角看,Harness 本质上是 将模型的认知过程外化为可操作的符号系统:
- Feature List 是模型的 外部工作记忆(External Working Memory),弥补了模型无法维护长期任务栈的缺陷。
- Progress Log 是模型的 元认知监控器(Metacognitive Monitor),使模型能够 "思考自己的思考过程"。
- Evaluator 是模型的 外部批判性思维(External Critical Thinking),解决了自回归模型无法自我修正的结构性问题。
- Git 是模型的 ** episodic memory**(情景记忆),提供了时间轴上的状态回溯能力。
这揭示了一个深层原理:大模型不是缺乏智能,而是缺乏 "智能的组织结构"。 Harness Engineering 不是让模型变得更聪明,而是为模型设计一个 外骨骼------让它能够承载超出其原生认知带宽的复杂任务。
7.3 从 Harness 到 Agent Operating System
OpenAI 和 Anthropic 的实践共同指向一个未来图景:Agent Operating System(Agent 操作系统)。
当前的 Harness 还是 "每个项目一套配置" 的手工业模式。未来的 Harness 将演化为操作系统级别的抽象:
| 当前 Harness | 未来 Agent OS |
|---|---|
| 项目级 init.sh | 系统级进程管理(fork/exec/session) |
| 手工编写的 AGENTS.md | 自动生成的 Agent 能力目录(类似 /proc) |
| 专用 Feature List | 通用任务调度器(类似内核调度器) |
| 单一 Evaluator | 多维度质量守护进程(类似系统守护进程) |
| 静态工具集 | 动态 MCP 加载与卸载(类似内核模块) |
这个 Agent OS 将具备:
- 进程隔离:每个 Agent session 是独立进程,通过 IPC(文件/消息队列)通信。
- 虚拟内存:文件系统作为 Agent 的 "虚拟内存",按需分页(渐进披露)加载上下文。
- 调度器:根据任务优先级、依赖关系和上下文压力动态调度 Agent。
- 安全边界:沙箱、凭证代理、权限系统构成 Ring 0/1/3 隔离。
结语:设计缰绳的人,驾驭未来
OpenAI 的五个月百万行代码实验和 Anthropic 的六小时游戏引擎构建,共同证明了一个结论:大模型的能力边界不是由参数规模决定的,而是由 Harness 的设计质量决定的。
在 Agent 优先的世界里,人类工程师的价值不再是代码产量,而是 系统设计能力、意图表达能力、反馈回路设计能力。优秀的 Harness 工程师像是一位经验丰富的驯马师------他不亲自奔跑,但深知如何让马匹在正确的方向上全速前进。
写好一个 Harness,意味着你要站在大模型底层原理(注意力、上下文、自回归)的认知高度上,为 Agent 设计一套 外化的认知架构。它必须让 Agent 在失忆后能迅速恢复状态,在自我膨胀时能被客观评估,在迷失方向时能被清晰的知识地图引导。
Harness Engineering 不是 Prompt Engineering 的升级版,它是 软件工程在 AI 时代的本体论升级------从 "人写代码" 到 "人设计系统,Agent 写代码"。
而我们现在,正处于这场升级的原点。
参考文章: