写在前面:文章初稿写于今年年初。今天回头看,当时还以为赶上了AI末班车------现在连尾灯都看不见了。AI圈的造词速度,比我掉头发还快。
群里随手一刷,MCP、A2A还没弄明白,这周又冒出一堆新词。就像你刚把Vue3的Composition API摸熟,群里已经开始聊Vapor Mode了。
所以,送你一张"三代工程化跃迁"地图,把满屏飞舞的AI名词------LLM、RAG、MCP、Agent、Harness、Skill、A2A、蒸馏、CoT......
一、🗺️ 三代工程化跃迁:一张总览图看懂所有名词
AI应用开发两年间,经历了三代核心能力的跃迁。所有你听说过的名词,都能在这张图里找到位置。
| 世代 | 核心能力 | 代表名词 | 解决什么问题 |
|---|---|---|---|
| 第一代 | 提示词工程 | Prompt、System Prompt、CoT、Few-shot、Zero-shot、JSON Mode | 教会AI怎么听懂人话 |
| 第二代 | 上下文工程 | RAG、Memory、Vector DB、Embedding、Function Calling、MCP、A2A、Skill、Agent、OpenClaw | 教会AI怎么查资料干活 |
| 第三代 | Harness(质检)工程 | Eval Harness、Benchmark、MMLU、HumanEval、GSM8K、A/B Test、Regression Test | 教会团队怎么知道AI没瞎说 |
一句话记住:从"怎么问",到"喂什么",再到"怎么验"。
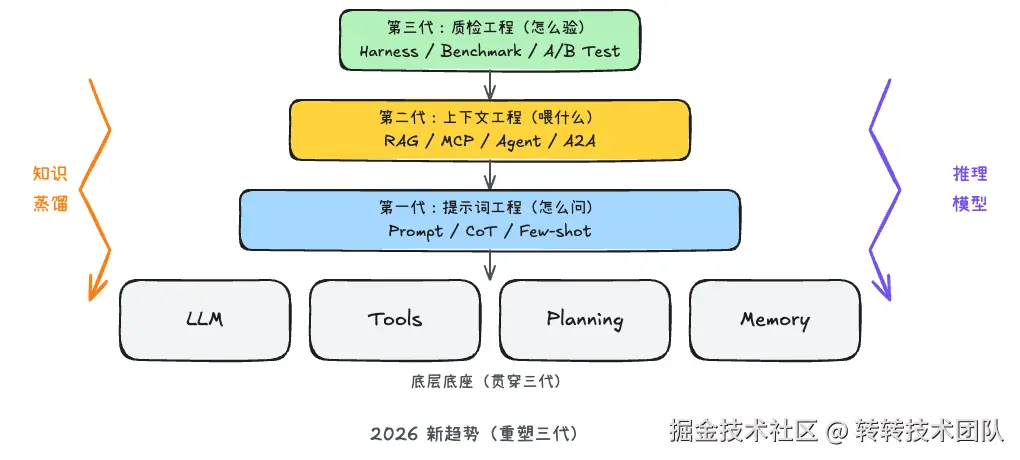
二、🔧 底座层:四大基础模块
如果你看到RAG、Agent这些词就头大,先别慌。无论哪一代工程化,底层都是这四个模块的排列组合。搞懂它们,任何新名词都能秒懂。
| 模块 | 人话解释 | 类比 |
|---|---|---|
| LLM | 大脑,负责理解、推理、生成 | 公司里最聪明的员工 |
| Memory | 记事本,存对话、存知识、存状态 | 行政的档案柜 |
| Tools | 手和脚,连接外部世界查资料、调API | 员工的电脑和电话 |
| Planning | 项目经理,拆解任务、调度执行顺序 | 秘书的待办清单 |
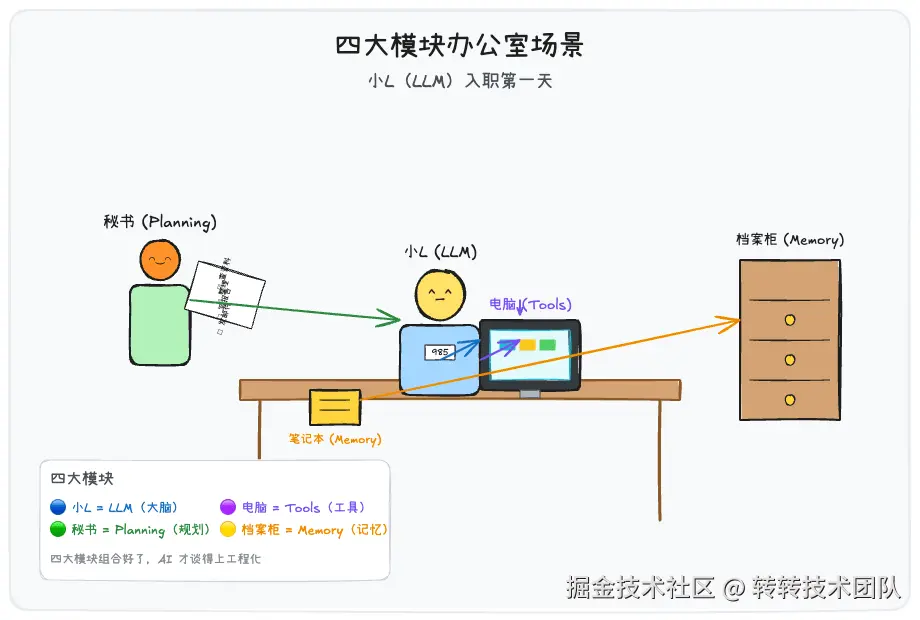
四个名词一次记住:LLM(大语言模型)、Memory(记忆系统)、Tools(工具系统)、Planning(规划系统)。
一个比方看懂四大模块:
想象你招聘了一个AI员工"小L":
- 小L(LLM):985毕业,但入职后知识不再更新,还不能"科学上网"------就像你招了个只会Vue2的同事,React18都没听过。
- 笔记本(Memory):把对话和资料记下来,下次带着------帮他作弊出"记忆力"。
- 电脑(Tools):配了能上网、查库、发邮件的电脑,他终于不是只会背书的做题家了。
- 秘书(Planning):把高层意图拆解成:查资料→整理→写报告→发邮件。
四大模块组合好了,才谈得上工程化。缺一个,AI就是残废。
三、🎯 第一代:提示词工程(Prompt Engineering)
如果你还在纠结Prompt怎么写,恭喜你,你处在第一代。
核心目标:让模型听懂你的话,输出你想要的结果。
Prompt(提示词)
你给模型输入的那段文字。模型靠它猜你想要什么。Prompt写得好不好,直接决定输出质量。
System Prompt(系统提示词)
隐藏在后台的"顶层设计",定义模型的角色和行为边界。例如:"你是一位资深前端架构师,回答要简洁,带代码示例。"用户看不到,但每轮对话都生效。
CoT(Chain of Thought,思维链)
在Prompt里加一句"请一步一步思考",让模型把推理过程显式写出来,而不是直接跳结论。数学题和逻辑题的救命稻草。
Few-shot(少样本提示)
在提问前,先给模型看几个"问题→答案"的示例,让它模仿风格和格式。例如贴3段你写的代码,让它按同样风格续写。
Zero-shot(零样本提示)
不给任何示例,直接提问。模型靠预训练知识硬答。简单问题够用,复杂问题容易跑偏。
JSON Mode(结构化输出)
强制模型以JSON格式返回结果,方便程序解析。(部分平台也支持XML等结构化格式)如果没有它,模型可能返回一段自然语言"好的,结果如下......",你的代码就像接到一个没写接口文档的后端------只能靠正则硬扒。开启JSON Mode,直接锁定输出结构,告别靠运气。
第一代现状:这些技术已是基础门槛,2023年值钱,现在白菜价。不会写Prompt就像不会用Chrome控制台------能干活,但别说自己会前端。
但 Prompt 写得再好,模型也不知道你公司的内部文档长什么样,读不了你的数据库,更发不了邮件。于是工程师们开始想办法:怎么让模型开口前,先看到最相关的资料?
这就是第二代------上下文工程。
四、🔌 第二代:上下文工程(Context Engineering)
如果你已经会写Prompt,但模型答不上公司内部的业务问题,该升级了。
核心目标:在模型回答前,把最有价值的信息精准地塞进它的上下文窗口。
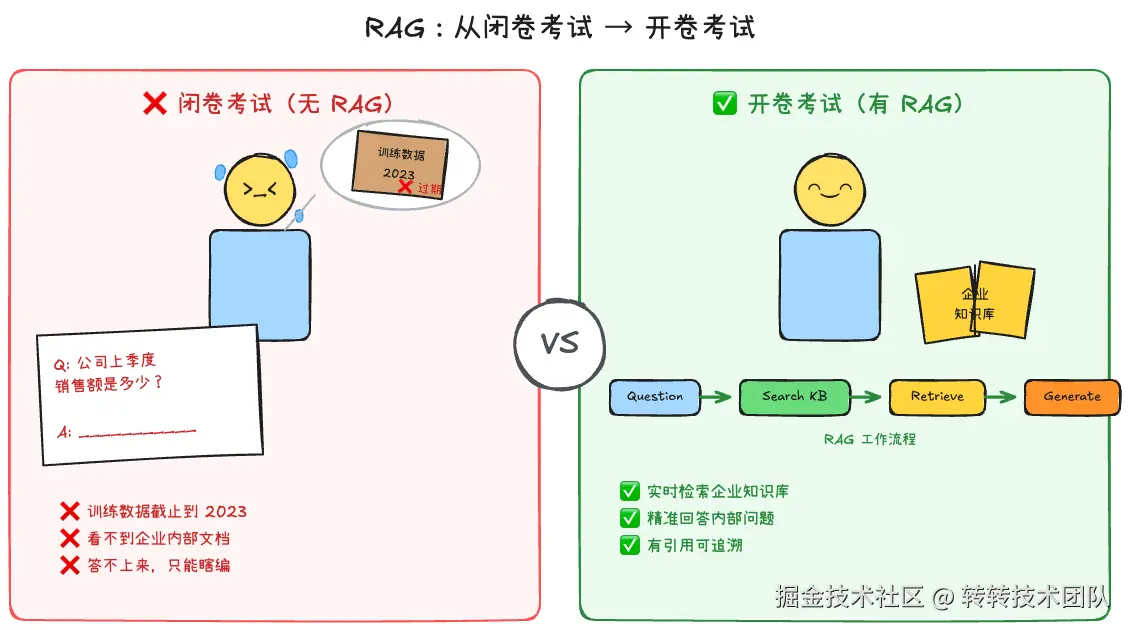
纯本地部署的模型知识有截止日期,看不见你的企业文档,读不了你的数据库。(虽然部分产品已接入实时搜索,但企业内部数据仍然触达不到。)第二代工程化解决的就是:怎么在模型开口前,帮它"开卷考试"。
RAG(Retrieval-Augmented Generation,检索增强生成)
本质:给模型外挂一个资料库。用户提问时,系统先从知识库检索相关资料,塞进Prompt里,再让模型生成回答。
涉及名词:
- Vector DB(向量数据库):把文档切成碎片,转成数学向量存储。检索时通过"找相似的向量"定位相关内容。代表:Chroma、Pinecone、Milvus、pgvector。
- Embedding(嵌入):把文字、图片转成向量的技术。"语义相似"在向量空间里表现为"距离相近"。
- Memory(记忆系统):广义上包含RAG的检索记忆,也包含对话历史、用户画像、长期知识库。
Function Calling(函数调用)
本质:给模型一双手。模型判断需要外部数据时,输出结构化JSON指令,应用层执行后把结果塞回模型。
完整流程拆解:用户问:"今天北京天气怎么样?"
- 模型判断需要查天气 → 输出JSON:
{"tool": "get_weather", "city": "北京"} - 你的代码执行这个指令,调用天气API → 拿到结果:"8°C,晴天"
- 把结果塞回给模型
- 模型把数据变成人话:"北京今天8度,晴天,适合出门走走。"
MCP(Model Context Protocol,模型上下文协议)
本质:Function Calling的"USB-C标准化"。以前每个工具接入方式不同(N×M复杂度),MCP统一接口后变成N+M。服务方实现一次MCP Server,应用方接入MCP Client,即插即用。
代表MCP Server:GitHub(代码操作)、PostgreSQL(查库)、Notion(文档管理)、Puppeteer(浏览器自动化)、Filesystem(本地文件读写)。
A2A(Agent-to-Agent Protocol)
本质:MCP连接"AI和工具",A2A连接"AI和AI"。多Agent协作时的通信标准------前端Agent、后端Agent、测试Agent互相发现、发任务、传结果、同步状态。
你可以理解为:MCP是AI的插排,A2A是AI的微信群------一个管通电,一个管聊天。
Skill(技能)
针对特定任务预封装的指令集+工具调用逻辑。可以简单到一段优化过的System Prompt,也可以复杂到包含多步工具调用的微型工作流。
识别真假Skill:有实质性工具集成、有输入输出契约、可验证可组合 = 真Skill;纯文本回复不涉及外部交互 = 假Skill(只是Prompt模板)。
Agent(智能体)
具备自主规划能力、能调用工具执行复杂任务、并在执行中持续适应的AI系统。四大模块的完整组合:LLM做决策、Memory存状态、Tools动手、Planning拆解任务。
演进层级:工具增强型聊天 → 单任务Agent → 多Agent协作(A2A)→ 通用自主Agent。
OpenClaw
一个开源的Agent应用框架/平台,属于"应用层"的实现。你可以理解为"基于四大模块+上下文工程搭建出来的成品套件",帮你快速拼装Agent而不从零造轮子。
分类说明:OpenClaw 属于第二代技术的"应用层实现"------它本身不发明新原理,而是把上下文编排能力打包成开箱即用的框架。就像 React 属于前端工程化,而 Next.js 是 React 的应用层封装。
第二代现状:不会上下文工程,就像只会写SQL但不会做数据仓库------接不了大盘的活。
但上下文工程再花哨,也回答不了一个致命问题:"这 AI 到底靠不靠谱?"你改了 Prompt、换了模型、加了 RAG,自我感觉良好,一上线用户骂娘。没有评测,一切优化都是蒙眼射箭。
这就是第三代------Harness 工程。
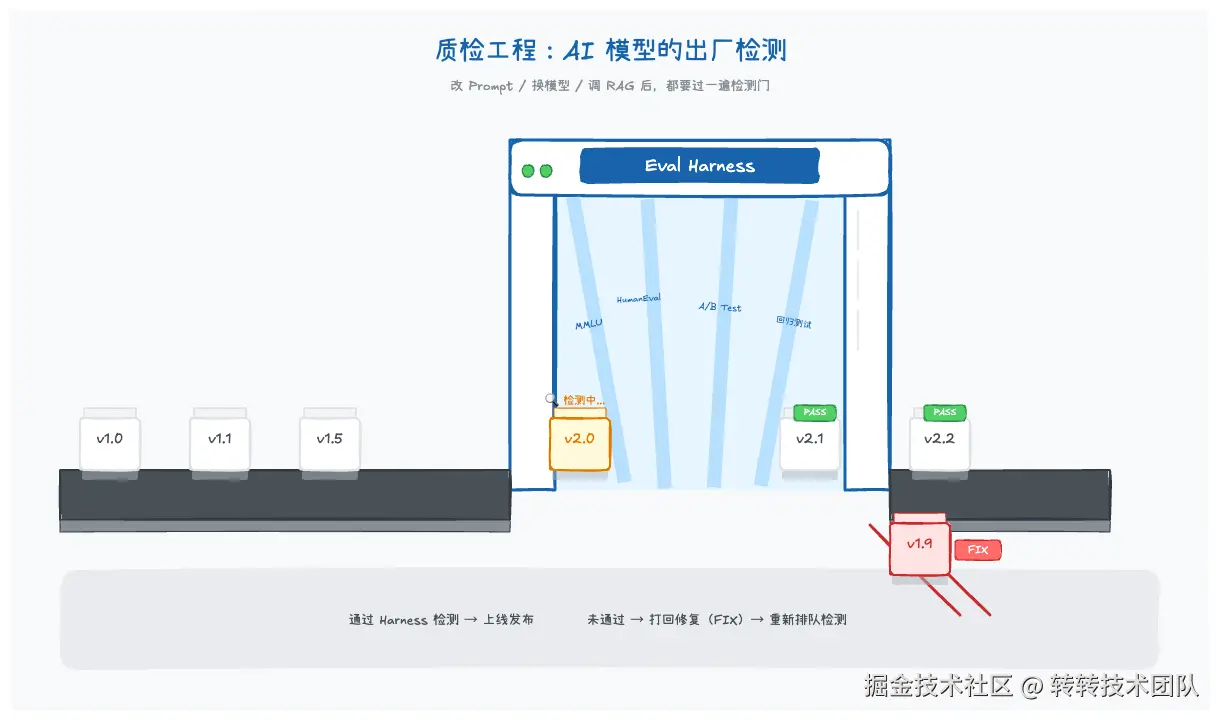
五、✅ 第三代:Harness(质检)工程
如果你上线前从不跑测试集,恭喜你,你是第三代的目标用户。
核心目标:建立标准化、可复现、自动化的评测体系,回答"这个AI系统到底行不行"。
前两代解决了"让AI能干活",第三代解决"让AI可靠地干活"。没有评测,一切优化都是蒙眼射箭------你改Prompt改得很爽,上线后用户骂得更爽。
Eval Harness(评测框架)
一套标准化的评测工具链,用统一的基准测试回答"模型/系统能力如何"。代表:EleutherAI 的 lm-evaluation-harness,或者各团队自研的 CI/CD 评测流水线。
现实案例:某团队每次换模型都手工问20个问题,感觉"差不多"。接入Harness后,发现新模型在长文本理解上比旧模型低了15个百分点------之前完全没测出来。
怎么做:把评测脚本写进代码库,和业务代码一起版本管理。模型换版本、Prompt改措辞、RAG换召回策略,一键跑全量测试。
Benchmark(基准测试)
行业公认的"考题库"。模型在这套题上得分高,不代表实际好用;但得分低,大概率有问题。就像 LeetCode 刷到 300 题不等于能写好业务代码,但一题不会肯定不行。
陷阱提醒:Benchmark刷分有技巧。有的模型专门针对MMLU做指令微调,考试高分,上业务还是一塌糊涂。所以Benchmark用来筛掉差的,不保证选到好的。
MMLU(Massive Multitask Language Understanding)
测模型在多学科知识上的广度,涵盖数学、历史、计算机、法律等 57 个科目。从高数到法律,57 门课一起考,偏科生直接露馅。堪称模型的"高考综合卷"。
补充知识:MMLU的每一道题是四选一。57个科目里,人文社科类模型普遍表现好,数理类普遍差。如果你要做数学相关的Agent,别只看MMLU总分,拆开看数学子项。
最新趋势:MMLU已经快被刷爆了,头部模型能做到90%以上。现在业界更关注MMLU-Pro(难度升级版)和MMLU-R(带推理过程标注的版本)。
HumanEval
测模型写代码的能力:给函数描述让模型补全代码,再跑测试看对不对。前端工程师选代码助手,必看这个指标。
延伸:HumanEval的问题是手写的,总共164道。后来出现了HumanEval+(增强测试用例)、MBPP(更多入门级编程题)、LiveCodeBench(持续更新的新题,防刷榜)。
真实场景:有的模型HumanEval刷到80%+,但写React组件时一直幻觉API。因为HumanEval测的是算法补全,不是工程代码生成。所以选代码助手时,还要看自己的业务场景测试集。
GSM8K
测数学应用题推理能力,难度覆盖小学到初中。推理模型和传统模型拉开差距的主战场就在这里。
为什么重要:小学数学题看起来很"简单",但需要多步推理。传统模型靠模式匹配容易错,推理模型(如o1、DeepSeek-R1)能显式写出步骤,正确率直接翻倍。
变种:GSM8K之后还有GSM-Hard(加大数字、加长步骤)、MATH(竞赛级数学)、AIME(美国数学邀请赛)。你要做数学辅导类产品,AIME才是真考场。
A/B Test
线上对比两个模型/策略的效果,看哪个在真实用户场景里表现更好。质检工程不只跑离线Benchmark,还要接线上实验。
实操建议:
- 流量切5%-10%给实验组
- 关注业务指标(采纳率、满意度、任务完成率),不看Benchmark分数
- 同时监控延迟、成本、安全拦截率
翻车案例:某团队离线测试显示新模型在客服场景准确率提升8%,上线A/B测试后用户满意度反而下降------因为新模型回复更快但更啰嗦,用户觉得烦。离线测试根本测不出"烦不烦"。
Regression Test(回归测试)
每次改 Prompt、换模型、调 RAG 策略之后,都跑一遍标准问题集,确保新改动没有搞崩以前好用的 case。
每次改 Prompt 不跑回归,就像你重构完组件不跑单元测试就上线------勇气可嘉,但别。
案例:某RAG产品做了个"优化",把召回从10条降到5条。离线测试显示准确率没掉,但上了生产发现用户问"去年第三季度的三个项目"时,第6条文档里正好有第三个项目------被截掉了。回归测试里如果有这个case,就能提前发现。
怎么做:
- 维护一个"金标准问题集",50-200个
- 每个问题标注正确答案/预期行为
- 每次改动后自动跑,对比新旧版本差异
- 差异超过阈值自动拦截发布
第三代现状:正在爆发,区分"业余玩家"和"专业团队"的分水岭。2026年不会质检工程的工程师,就像2023年不会写Prompt一样------还没上桌,牌局已经换了。
六、🕳️ 踩坑指南(一句话版)
| 坑 | 真相 | 正确姿势 |
|---|---|---|
| Function Calling和MCP竞争 | 不竞争,一个对内表达意图,一个对外标准化连接 | 内部用FC,对外接第三方服务用MCP |
| RAG万能 | 检索错误会"垃圾进垃圾出" | 检索层加重排序(Rerank),答案层加引用溯源 |
| 蒸馏模型万能 | 性价比方案,极端任务还是大模型稳 | 日常任务用小模型,极端任务fallback大模型 |
| Reasoning模型一定更好 | 响应慢,简单问题"想太多" | 简单问题上普通模型,硬核任务上推理模型 |
| Benchmark分数即一切 | 可能刷分,实际业务测试才是金标准 | Benchmark过线后,重点跑业务case和线上A/B |
| Skill能取代Agent | Skill是"预制菜",Agent是"完整厨房",层级不同 | Skill做原子能力,Agent做流程编排,组合使用 |
七、🎬 结语
所以你看,AI 新名词确实比我头发掉得还快。但只要你抓住这条主线------怎么问 (Prompt)、喂什么 (RAG/MCP/A2A)、怎么验(Harness)------任它新词满天飞,你自岿然不动。
下次群聊里又飞过什么 MCP、A2A、蒸馏、CoT......你先别慌,问三个问题就够了:
- 它帮我问得更好了?→ 第一代
- 它喂得更准了?→ 第二代
- 它验得更科学了?→ 第三代
对不上号的?大概率是营销词,可以安心跳过。
毕竟,只要你学得够慢,那就不用学了,因为他可能已经过时了,正如这篇文章一样。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~