本文作者:电商-商家增长团队
我们是电商-商家增长团队 ,在用 AI Coding 从 0 到 1 搭建 AI 短视频生成平台 的过程中,最初以 Vibe Coding 为主,初期效果很不错,但随着项目复杂度上升,问题接踵而至:AI 生成的代码缺乏自动化验证、复杂功能频繁返工、前后端接口需要手动对齐,开发效率大打折扣。
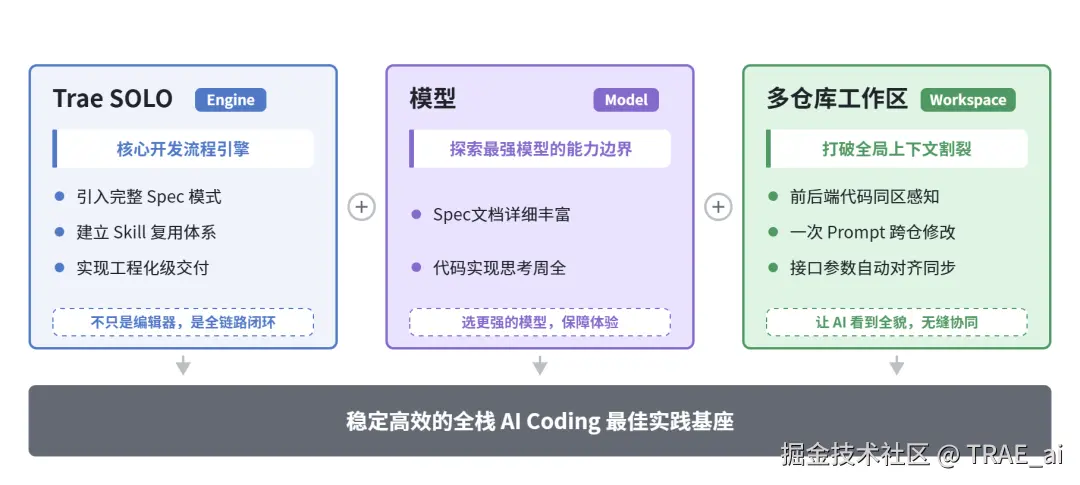
因此,我们开始系统地探索 AI Coding 的最佳实践工作流 ,经过数月的迭代打磨,沉淀出了一套 TRAE SOLO + 多仓库 Spec 模式 + 测试验证 Skill 的全栈开发实践。

实践成果:2 人 × 2 周,从 0 到 1 完成 AI 短视频生成平台的 MVP
已投放视频效果: 招商视频、PPT 讲解视频,并取得了正向收益


核心工具链一览

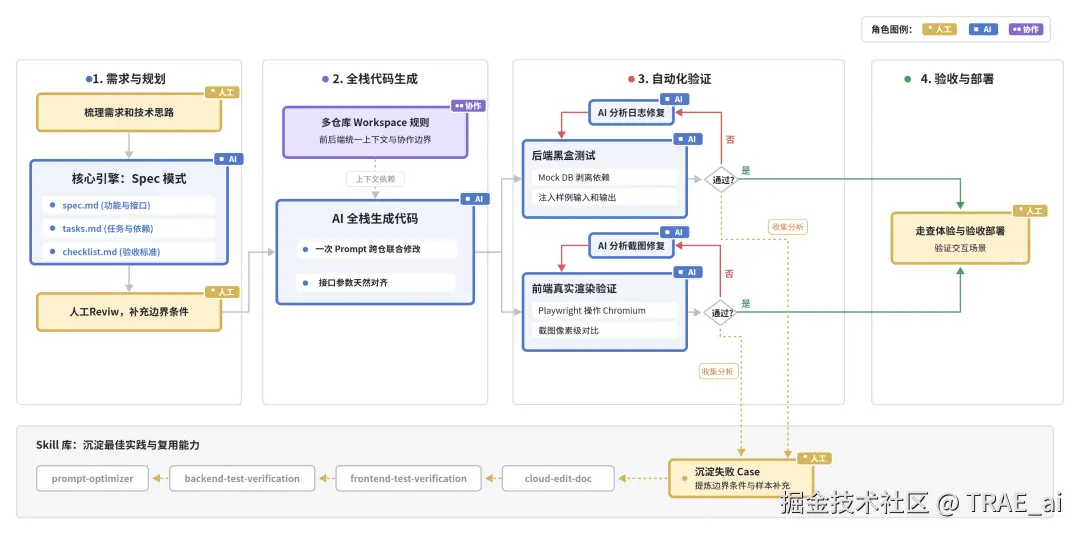
核心工作流:从接手需求→效果回收
3.1 Spec-First:需求即文档,告别 Vibe Coding**
心路历程
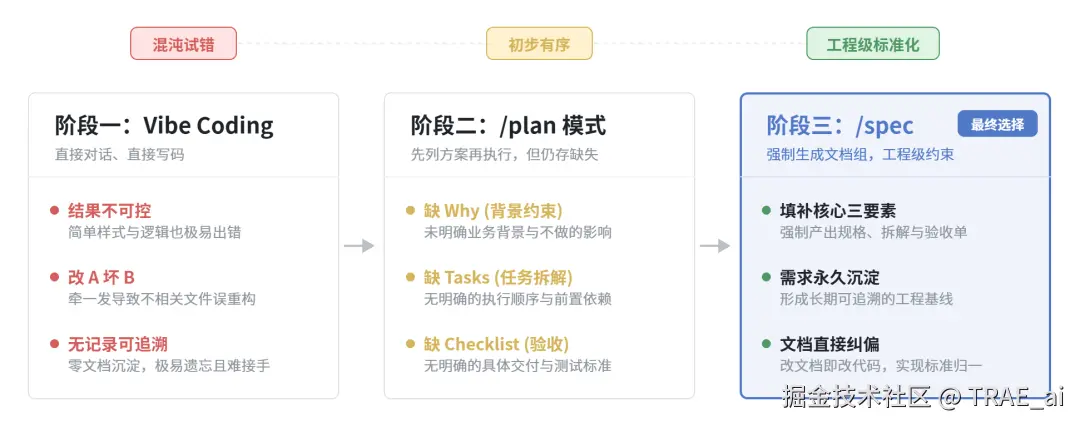
Spec 模式的三件套
在 TRAE 中使用 /spec 命令后,AI 会生成三份文档:
-
spec.md(需求规格):功能描述、技术方案、API 接口定义、前后端分工
-
tasks.md(任务拆解):按优先级排列的开发任务列表,含依赖关系
-
checklist.md(验收清单):每个任务的完成标准和测试要点
踩过的坑:大多数问题不是"实现错了",而是"Spec 没对齐"
实操效果: 一个"级联更新逻辑 + 批量修改音色 + 重组时间线"的需求,通过 /spec 生成完整方案后,3 小时完成 3 个小功能、500 行代码。后续修改即使不用 /spec,AI 也能自动定位到该需求,同步修改代码和 tasks.md。
3.2 前后端共享上下文:多仓库开发的正确姿势
Workspace:让一次 Prompt 全栈闭环
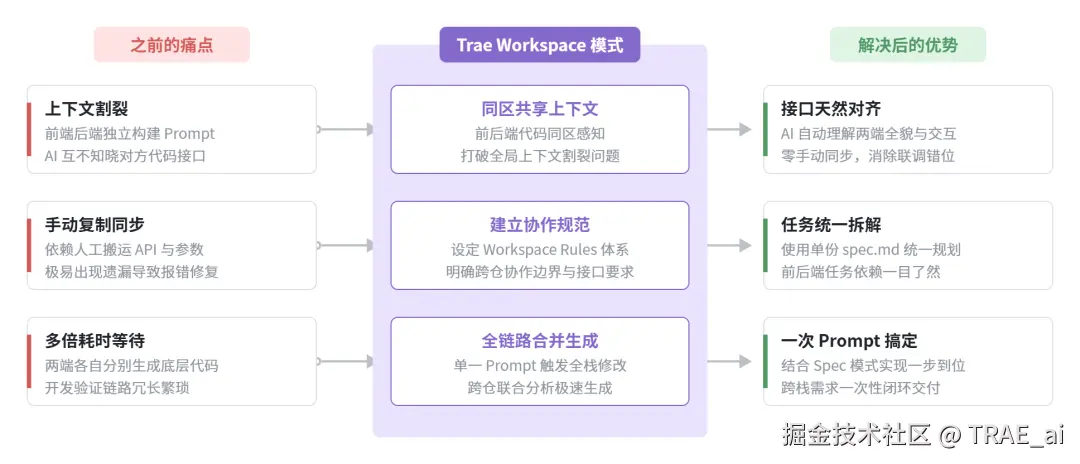
多仓库 Workspace 配置方法
- 通过 TRAE 新建一个窗口
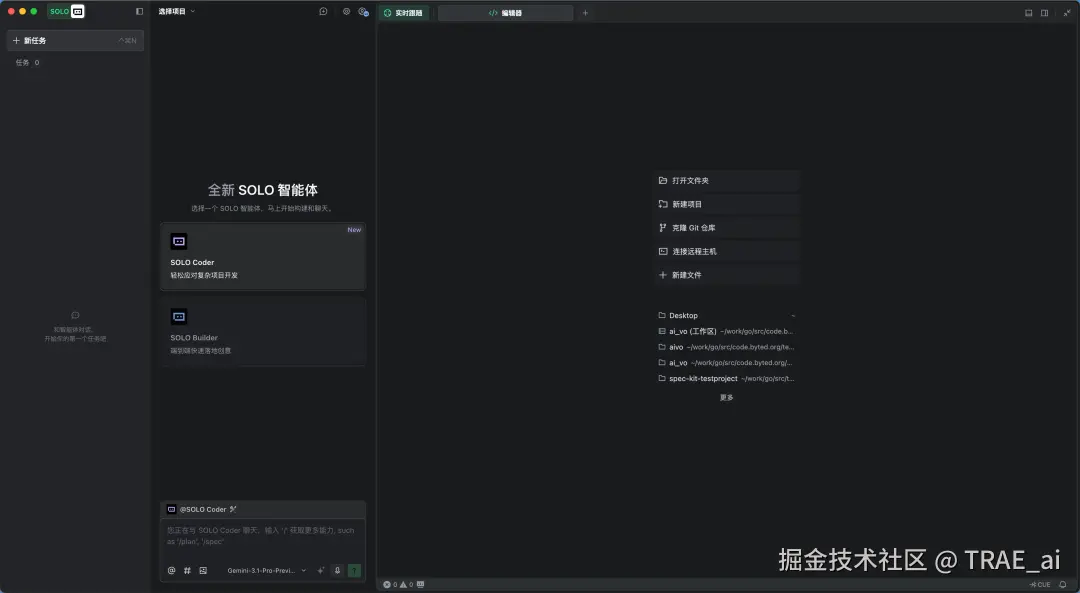
- 将多个代码仓库添加到工作区
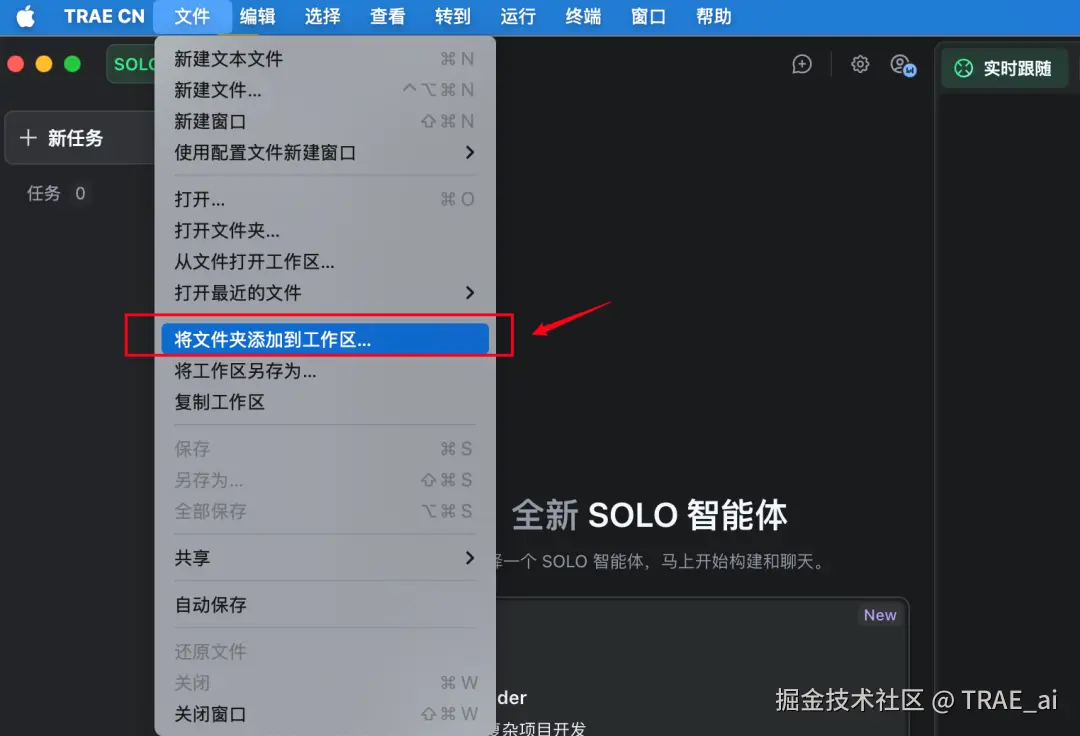
- 保存工作区,会生成一个配置文件,后续打开该配置文件即可
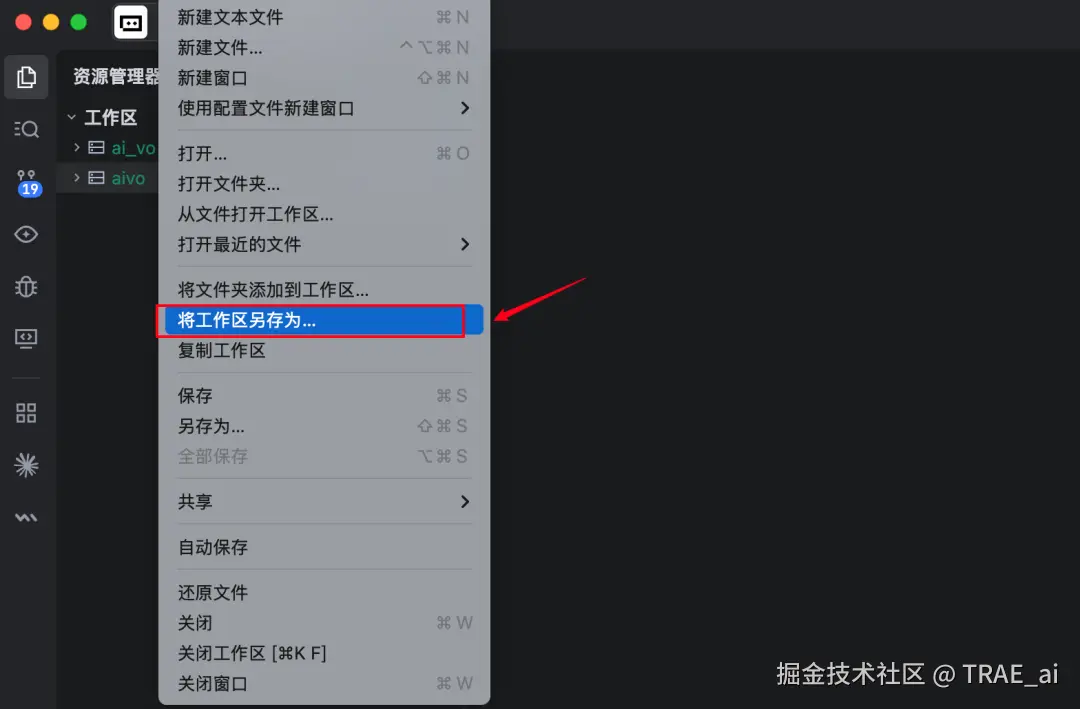
-
为每个代码仓库,设置工作区规则(跨项目协作规则)
-
一次 Prompt 并通过 Spec 模式执行,最终同时改动前后端
缺点:Spec 文档只会在其中一个仓库生成
经验复用
可复用的场景: 涉及多仓库的需求,且各个仓库之间有依赖关系
存在的难点:
-
代码较多的仓库,建议沉淀知识库,便于 AI 识别需求改动涉及的仓库与代码位置
-
TRAE 同时打开多个代码仓库,存在性能问题,可考虑使用内存较高的开发机
3.3 测试不是附加动作,是 AI Review 代码的核心抓手
后端测试验证:给定样例输入输出,像 LeetCode 一样
核心思路: 不要让 AI 猜"对不对",而是给它明确的输入和期望输出,让它自己跑、自己改
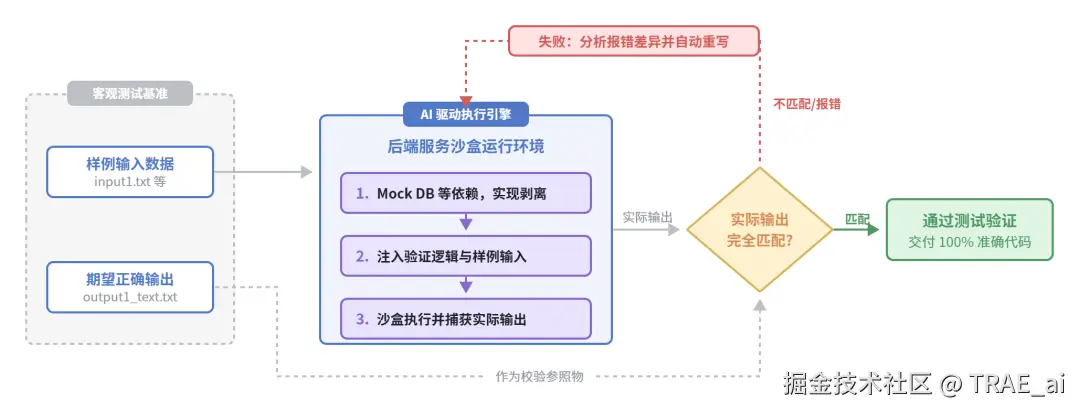
实操案例(解析文章内容):
-
/spec 定义功能:输入文章接口返回的富文本 → 输出纯文本 + 图片列表,不涉及 DB 的纯解析功能
-
提供样例文件:input1.txt → output1_text.txt + output1_image.txt
-
定义通过标准:文本正确率 > 95%,图片召回率 > 95%
-
AI 自动运行测试 → 发现错误 → 修复代码,循环直至通过
关键细节: 一开始只给了样例输入没给样例输出,AI 凭感觉实现,效果不稳定。补充明确的样例输出后,准确率从不稳定直接提升到 100%
前端测试验证:写能够真实执行的测试用例
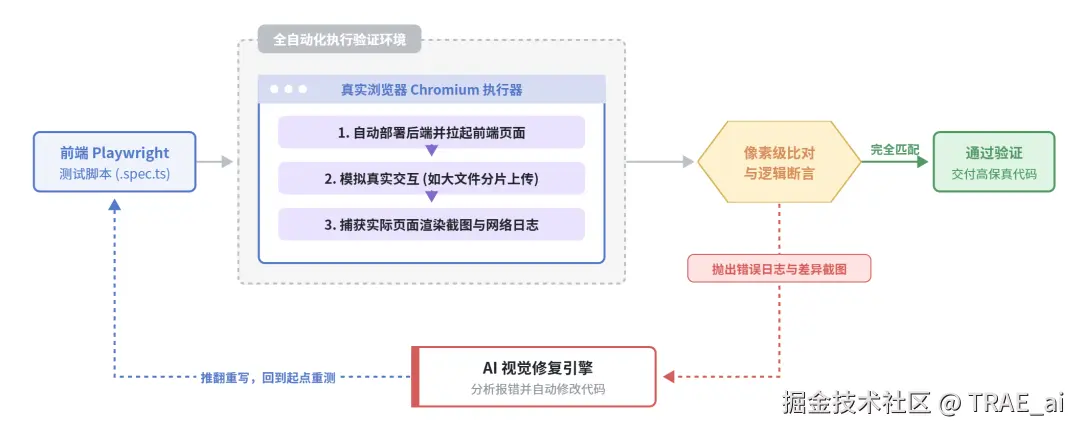
正确的做法:
-
编写调用 Playwright** 的测试脚本(.spec.ts / .js)
-
AI 自动部署后端 → 启动前端 → 运行测试脚本
-
测试脚本在真实浏览器中操作页面、调用后端接口
-
根据测试结果自动修复,直至通过
实际案例 (大文件分片上传):AI 自动执行测试脚本 → 打开页面 → 进入道具管理 → 上传 50MB 视频 → 观察分片请求(每片 5MB)→ 验证最终 URL 返回。全程自动化,无需人工介入。
实战遇到的问题
-
后端的测试验证 Skill 执行的比较好,前端的测试验证 Skill 仅仅写了个 markdown 文件,并没有真正执行
-
重新描述前端的测试步骤
结果:AI 写了测试文件,但需要让我自己运行。
-
给定视频位置,最终成功。将上述经验进行总结,循环迭代 Skill
-
其他卡点
a. TRAE 会跳出来让我人工确认是否执行 rm、kill 等操作
b. 代码编写+测试:需要 1 - 1.5 小时,中间可以干别的事(比如写下一个需求的 Prompt)
经验复用
-
一些明确、长期执行的逻辑,写具体测试用例调用playwright,比接入 Playwright 的MCP、CUA稳定的多
-
适合CUA、接入 Playwright 的 MCP 场景:一次性场景
-
过往的测试有大量重复的工作,如创建 n 个测试任务计划。现在可能的解法:沉淀创建测试任务计划的Skill(PRD-> 接口入参,调接口)
3.4 Skill 迭代:从一次性 Prompt 到可复用能力
Skill 迭代的正循环引擎
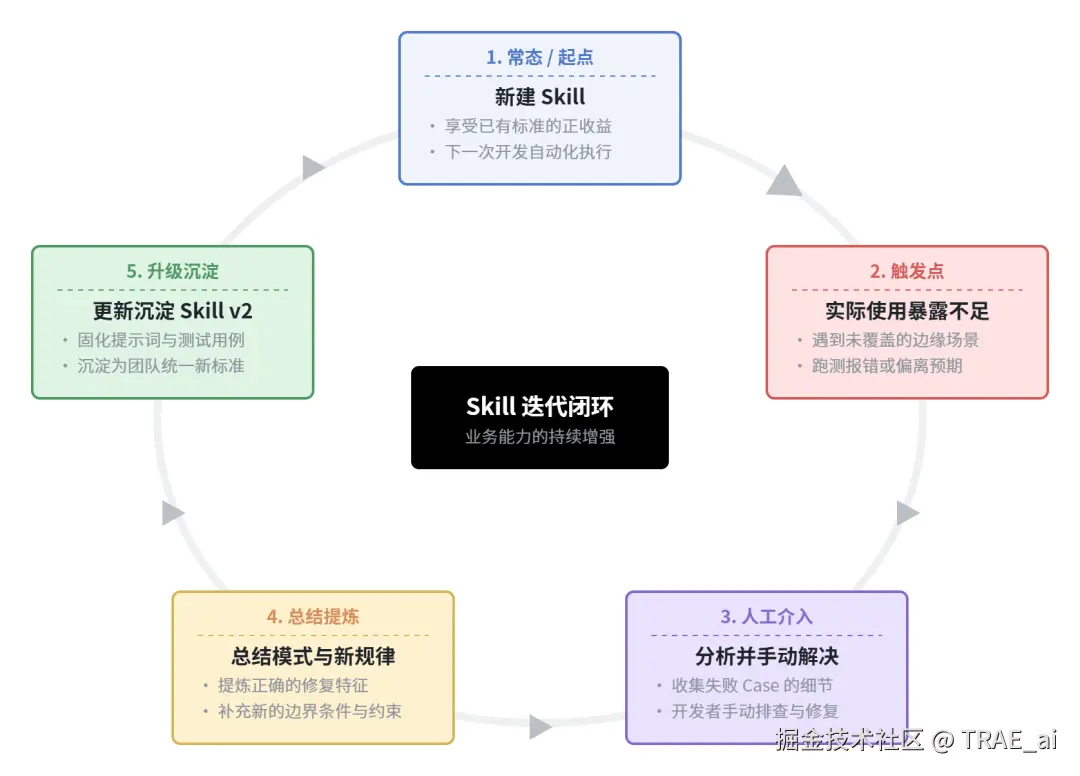
核心经验: Skill 不是一次写好的,而是通过 失败 Case 反馈 不断迭代优化。每次失败都是改进 Skill 的机会。

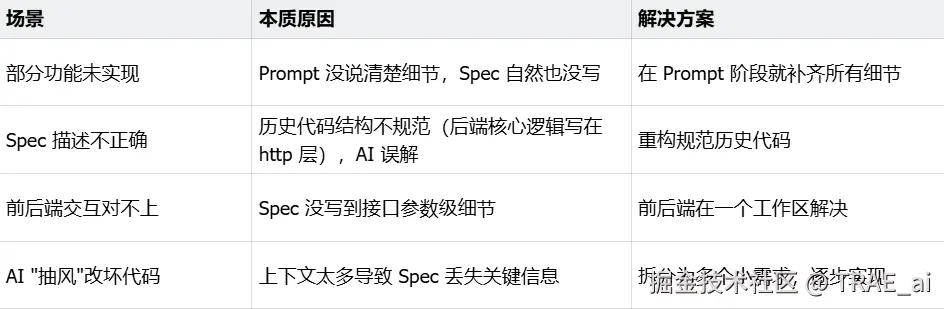
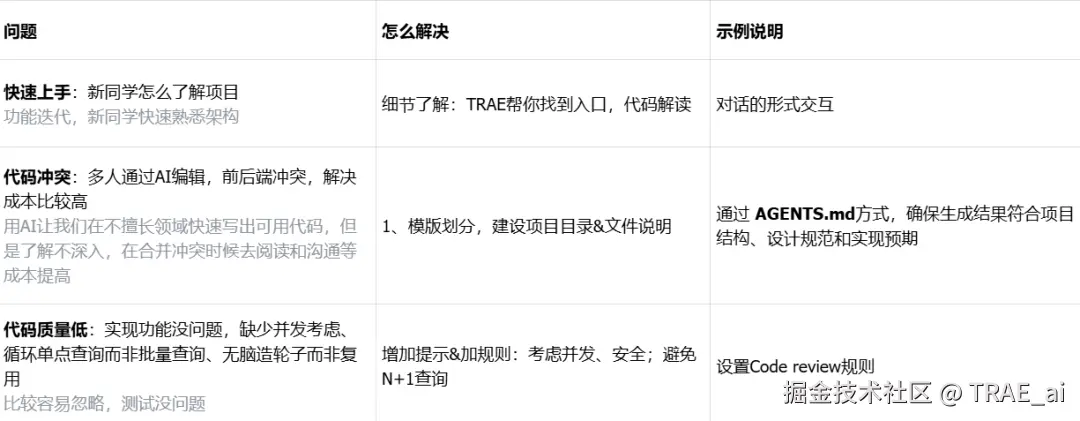
常见问题汇总

AI Coding 深水区:挑战与突破方向
前面介绍的工作流在 AI 短视频生成 项目(从 0 到 1 的项目)取得了显著成效,但在实践过程中,我们也深刻感受到 AI Coding 进入深水区后面临的一系列挑战。
接下来将坦诚地剖析这些难点,并探讨可能的解法。
5.1 当前工作流的适用性分析
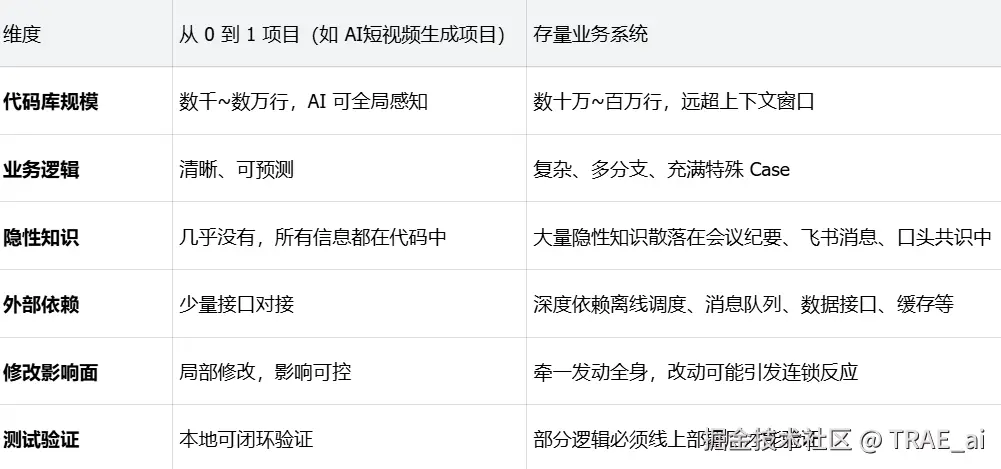
为什么这套工作流在 AI 短视频生成项目上效果好?
AI短视频生成项目是一个从 0 到 1 的全新项目,它天然具备以下有利条件:
-
没有历史包袱: 代码库干净,没有历史遗留的特殊逻辑,AI 不会被误导
-
业务逻辑相对清晰: AI 短视频生成的核心链路明确,需要编写的代码基本在 AI 模型的知识范围内(前端组件、后端 CRUD + 任务调度)
-
团队规模小,协作简单: 2 - 3人团队,沟通成本低,代码冲突少
为什么不一定适用于存量业务场景?
对于大部分团队来说,面对的往往是已经运行多年的存量业务系统,这些系统与 AI 短视频生成项目 存在显著差异:
5.2 深水区的五大核心挑战

5.3 清醒的认知:AI Coding 不是万能的
在探索 AI Coding 深水区的过程中,我们形成了几个清醒的认知:
-
AI Coding 的 ROI 与项目特征强相关: 新项目 > 存量项目,逻辑清晰的模块 > 业务复杂的模块
-
人的判断力始终是核心: AI 负责执行;人负责关键决策,牵引AI往正确的方向迭代。Prompt 的质量、Spec 的审核、架构的把控,这些依赖人的经验和判断力
-
沉淀比使用更重要: 每一次实践的知识沉淀(Skill、文档),都是在为团队构建长期的 AI 协作能力

总结
6.1 核心方法论
整套工作流的核心逻辑可以归纳为:
-
需求先行: 先用 /spec 对齐需求,再让 AI 写代码
-
全局感知: 前后端同一工作区,让 AI 看到全貌
-
测试驱动:** 用自动化测试验证代替人工 Review
-
持续沉淀: 将重复操作固化为 Skill,不断迭代
6.2 给不同角色的建议
角色
后端开发
建议
优先沉淀后端测试验证 Skill,给定明确的输入输出样例
角色
前端开发
建议
编写 Playwright 测试用例,比接入 MCP/CUA 效果更好
角色
QA
建议
将测试场景结构化,沉淀为可复用的测试 Skill
角色
全栈开发
建议
多仓库工作区 + Spec 模式是标配
AI Coding 的最佳实践不会有终点,但每一次迭代都在让下一次更高效。