第一章 概述
基本概念
- what is 计算机系统结构
程序员必须掌握的计算机属性
系统设计
定量原理
- Amdahl定律:
S=1(1−P)+PN S = \frac{1}{(1-P)+\frac{P}{N}} S=(1−P)+NP1
其中,P为能并行的部分比例,N为部件加速比 - cpu性能公式:
cpu执行一个程序所需要的cpu时间 = 所需时钟周期数 * 时钟周期时间
所需时钟周期数 = IC * CPI
CPU Time=Instruction Count×CPI×Clock Cycle Time CPU\ Time = Instruction\ Count \times CPI \times Clock\ Cycle\ Time CPU Time=Instruction Count×CPI×Clock Cycle Time - 局部性原理
- 经常性事件为重点
系统性能评测
- 执行时间(单个程序) & 吞吐率(单位时间)
用户cpu时间:程序耗费
系统cpu时间:程序运行期间系统耗费
系统结构发展
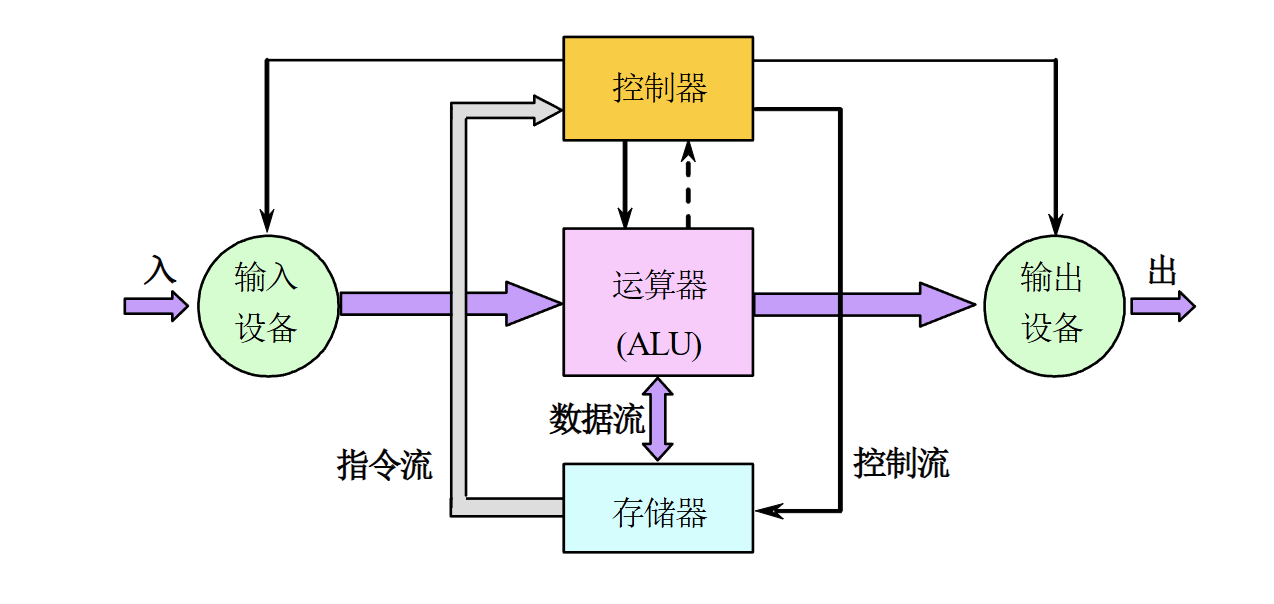
冯诺依曼体系
提高并行性的技术途径
- 时间重叠
- 资源重复
- 资源共享
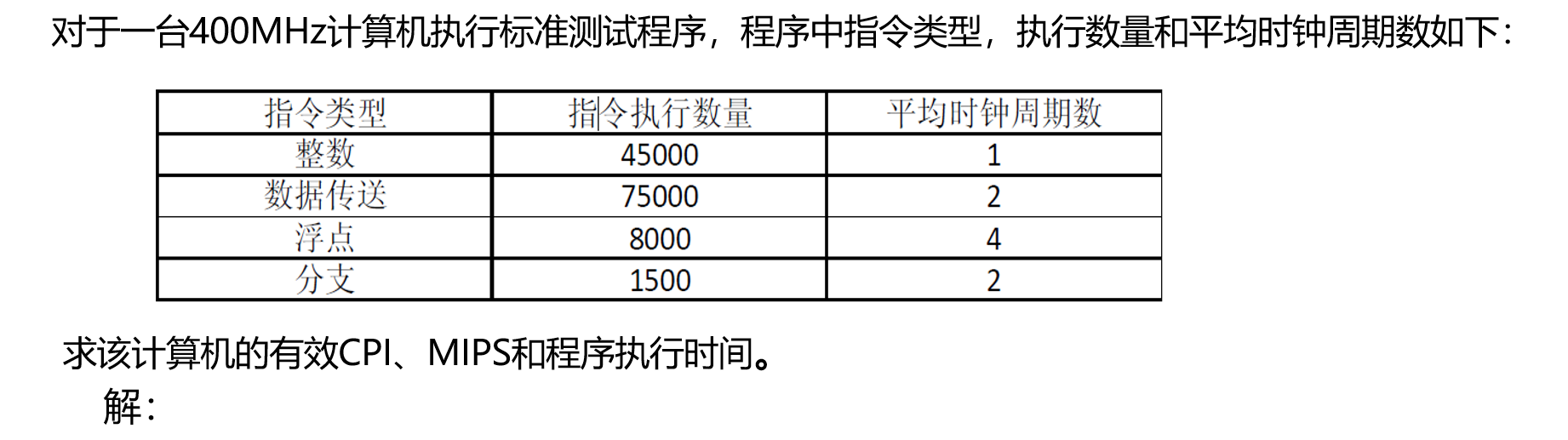
例题

第三章 流水线
基本概念
- 流水线作业原则:尽可能早的开始工作
- 流水线技术:一个重复的过程分解为若干个子过程,每个子过程由专门的功能部件实现,以达到子过程之间并行节省时间的效果。每个子过程及功能部件称为流水线的极或段。
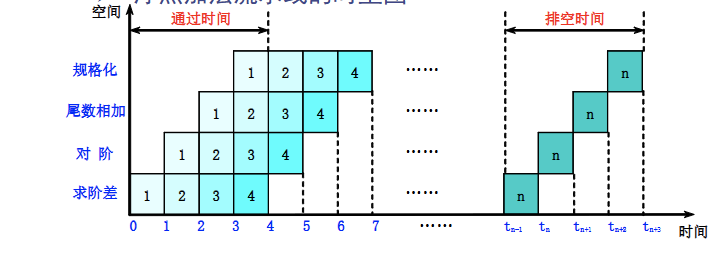
- 时空图:纵轴表示指令(段),横轴表示时钟周期。
- 流水线的种类
处理机 & 系统、单 & 多功能、静 & 动态、线性 & 非线性
性能指标
- 吞吐率:
TP=nTk TP=\frac{n}{T_k} TP=Tkn
TP为吞吐率,n为任务数,Tk为总时间数
对于各段时间相等的流水线:
Tk=(k+n−1)Δt T_k=(k+n-1)\Delta t Tk=(k+n−1)Δt
k为流水线段数。
我们可以观察到,当n趋于无穷时:
TPmax=1Δt TP_{max}=\frac{1}{\Delta t} TPmax=Δt1
对于各段时间不等的流水线:
TP=n∑i=1kΔti+(n−1)max(Δt1,Δt2,⋯ ,Δtk) TP= \frac{n} { \sum_{i=1}^{k}\Delta t_i + (n-1)\max(\Delta t_1,\Delta t_2,\cdots,\Delta t_k) } TP=∑i=1kΔti+(n−1)max(Δt1,Δt2,⋯,Δtk)n
以瓶颈段所耗费时间为节拍。
TPmax=1max{Δti} TP_{max}=\frac{1}{\max\{\Delta t_i\}} TPmax=max{Δti}1
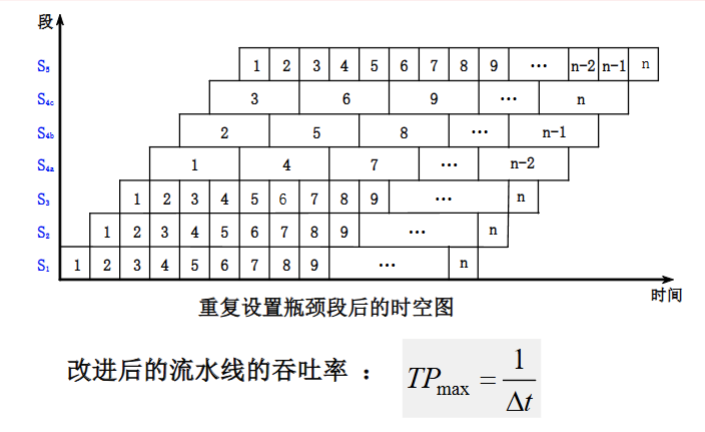
解决办法:细分瓶颈段,需要额外加;重复瓶颈段,增设硬件
- 流水线的加速比
S=TsTk S=\frac{T_s}{T_k} S=TkTs
Ts为不使用流水线的总时间,Tk为使用流水线的总时间。
各段时间相等:
S=TsTk=nkΔt(n+k−1)Δt S=\frac{T_s}{T_k}=\frac{nk\Delta t}{(n+k-1)\Delta t} S=TkTs=(n+k−1)ΔtnkΔt
各段时间不等:
S=TsTk=n∑i=1kΔti∑i=1kΔti+(n−1)max(Δt1,Δt2,⋯ ,Δtk) S=\frac{T_s}{T_k}=\frac{n\sum_{i=1}^{k}\Delta t_i} { \sum_{i=1}^{k}\Delta t_i + (n-1)\max(\Delta t_1,\Delta t_2,\cdots,\Delta t_k) } S=TkTs=∑i=1kΔti+(n−1)max(Δt1,Δt2,⋯,Δtk)n∑i=1kΔti
- 流水线的效率:
E=流水线实际工作时空区流水线总时空区 E= \frac{ 流水线实际工作时空区 }{ 流水线总时空区 } E=流水线总时空区流水线实际工作时空区
各段相等:
E=nk+n−1 E= \frac{n}{k+n-1} E=k+n−1n
n为任务数,k为流水线段数
各段不等:
E=n∑i=1kΔtik∑i=1kΔti+(n−1)max(Δti) E= \frac{ n\sum_{i=1}^{k}\Delta t_i }{ k\left \\sum_{i=1}\^{k}\\Delta t_i + (n-1)\\max(\\Delta t_i) \\right } E=k∑i=1kΔti+(n−1)max(Δti)n∑i=1kΔti
例题:
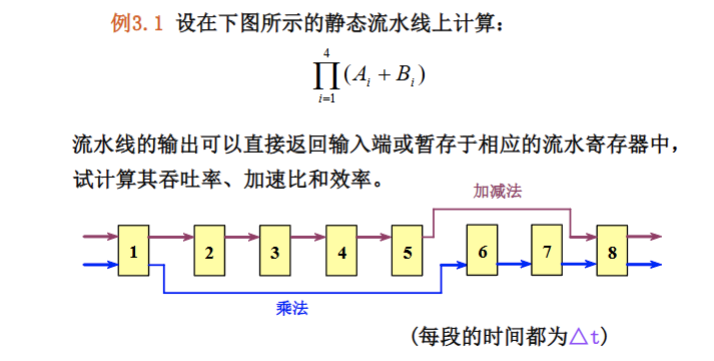
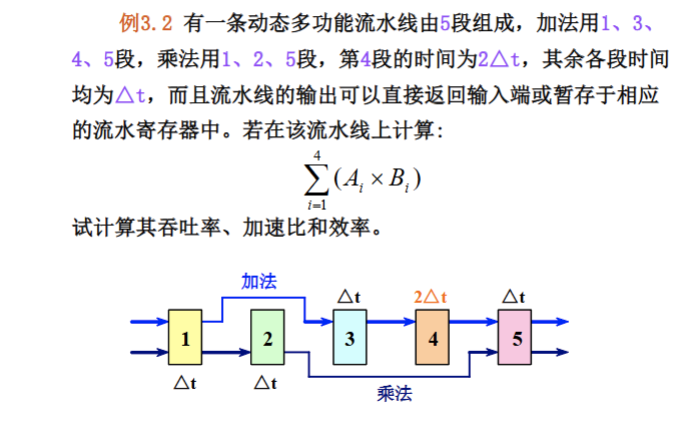
注意题目中说明是静态还是动态流水线。
非线性流水线调度
问题:非线性流水线存在反馈回路,一个任务可能需要回过头来用前面的段,这就可能造成和后面的冲突,需要找到最优调度,既不发生冲突,又充分利用。
单功能
启动距离:两个任务输入的时间间隔
禁用启动距离:会引起冲突的不可用时间间隔
预约表:一个任务从开始到结束,在哪些时钟周期用哪些功能段的总结表
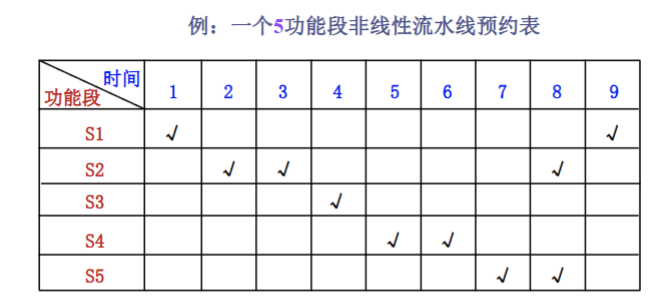
禁止表:每个段的禁用启动距离的集合。如上图所示,S1 = 9 - 1 = 8, S2 = 3-2,8-3,8-2 = 1,5,6; ... 最后得到的集合F = {1,5,6,8}
冲突向量C:从最高位到最低位,位数由最大禁止启动距离决定。对于上面的F,C0 = 10110001。新的任务流入后,设隔了j个时钟周期输入,新的冲突向量SHR(j)C0 或 C0.
如:隔两个时钟,C = 10110001,C' = 00101100,C' 或 C = 10111101,这就是新的冲突向量
对于新的冲突向量,根据其可用的时间间隔,求出后续的冲突向量;最后画出状态转移图。
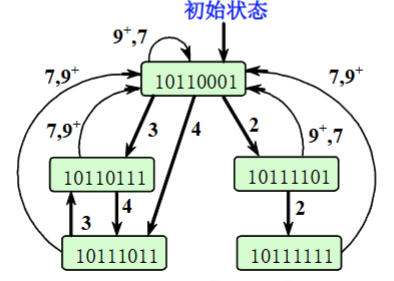
上图中,9+表示超过9的时间间隔,复位
根据图我们可以找出最优调度方案:从起点出发,找出若干形成闭环的路线(不要求回到起点),其中平均启动间隔最小的是(3,4)
3+42=3.5 \frac{3+4}{2}=3.5 23+4=3.5
流水线相关与冲突
经典5段流水线----RISC流水线
- 执行过程:
- IF:取指令------从PC取地址,寻址放入IR,PC + 4
- ID:指令IR译码,用IR中的寄存器地址访问寄存器组,读操作数
- EX:执行计算周期
- MEM:存储器访问,处理load(上周期计算出的有效地址)、store指令(指定数据写入有效地址指向的存储器单元,完成 )分支指令:如果分支成功,把转移目标地址送入PC。(分支指令也在此阶段全部完成)
- WB:write back,写回寄存器组
- 流水线实现:
- 每一个周期作为一个流水段
- 在以上的实现方案中,分支指令和store指令需要4个周期,其它指令需要5个周期
相关与流水线冲突
- 相关:指令之间存在依赖关系。
- 数据相关:j使用i的结果,或j与k相关,k与i相关,则j与i相关(具有传递性)
- 名相关:两条指令使用相同的名(指令访问的存储器单元的名称),但没有数据流动。解决办法:换名字
- 控制相关:由分支跳转造成。
- 冲突:下一条指令不能再指定的时钟周期进行,卡住了
- 结构冲突:硬件资源不满足,不够用。可以通过插入暂停周期或设置独立的指令和硬件
- 数据冲突:需要用前面指令的结果,只能等。包括写后读、写后写、读后写,后面的指令提前执行引起冲突。解决办法:定向:计算出的结果不放寄存器,直接给其他指令需要的地方,即不需要写回
- 控制冲突:提前取分支指令,可能失败导致前面白干。解决办法:等,但太慢;分支预测,让CPU预测分支跳转的方向:猜对,不停;猜错,清空。
例题(待做)

第五章 指令级并行
背景
前面讲了cpu运行时可能遇到的各种问题,那么怎样让多条指令一起干活,别等、别闲、别浪费?
概念
- 开发指令集并行的方法:基于软件的静态、和基于硬件的动态
- CPI流水线 = CPI理想 + 结构冲突停顿 + 数据冲突停顿 + 控制冲突停顿。要想快,就要减少三种停顿
指令的动态调度
基本思想
区别于编译期间代码调度和优化的静态调度(一旦指令受阻,后面的指令都停顿,动态调度再程序的执行过程中进行优化,即谁准备好谁执行。这样可能会导致乱序执行,从而引发一些顺序执行不会引发的问题
ID阶段拆成两段
引入 IS 和 RO,分别检测结构冲突和数据冲突。没有结构冲突就会立即占用资源,等待数据准备好。
调度算法
- 记分牌算法
目标:没有结构冲突时,尽可能早执行没有数据冲突的指令
四个阶段:

- Tomasulo算法
原理:相比于记分牌算法,该算法通过寄存器换名消除WAR和WAW冲突,即:Tomasulo = 动态调度 + 寄存器换名,消除假相关
动态分支预测技术
概念: 程序运行时根据分支过去的表现预测将来的行为
看什么:预测的准确性和分支开销(正确和不正确两种情况)。决定分支开销的因素有:流水线结构、预测方法、预测错误的恢复策略
目的:尽快找到分支目标地址
关键问题:如何记录分支历史信息、如何根据这些信息预测去向
BHT 分支历史表
- 原理:记录分支指令最近一次或几次的执行情况。
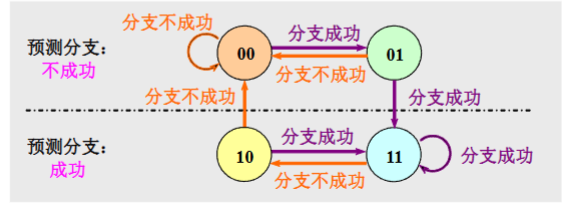
BTB 分支目标缓冲器
- 目标:分支开销为0
- 方法:分支目标缓冲。分支成功的分支指令的地址和分支目标地址都放到缓冲区保存起来
多指令流出技术
- 目标:一个周期发出多条指令,使CPI小于1
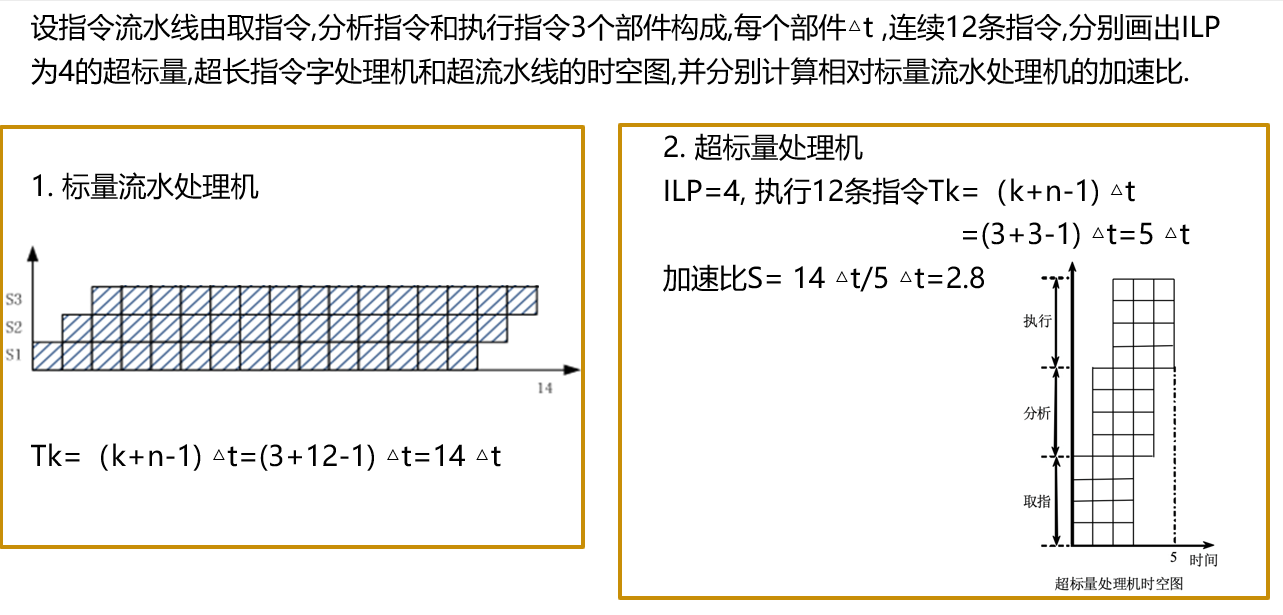
- 处理机分类:1. 超标量:每拍发几条不固定,由硬件情况决定;2. 超长指令字,每拍发固定数量的一包指令,把能并行执行的多条指令组装成很长的一条指令3.超流水线处理机:将每个流水段细分,使n跳指令每隔1/n个时钟周期流出一条指令。
例题



第七章 存储系统
基本概念
指标:容量大、速度快、价格低
问题:这三个指标往往难以同时实现
解决办法:多种存储器技术,构成多级存储层次结构。要综合考虑时间局部性 和空间局部性 ,靠近CPU的存储器小而快,远离CPU的存储器大而慢
性能参数:
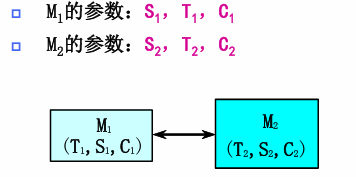
存储容量S:最远离CPU的存储器容量
S=S2 S = S_2 S=S2
每位价格C:
C=S1C1+S2C2S1+S2 C = \frac{S_1 C_1 + S_2 C_2}{S_1 + S_2} C=S1+S2S1C1+S2C2
命中率H:CPU访问存储系统时,在M1中找到信息的概率
H=N1N1+N2 H = \frac{N_1}{N_1 + N_2} H=N1+N2N1
平均访问时间TA:
TA=HT1+(1−H)(T1+TM)=T1+(1−H)TM=T1+FTM T_A = H T_1 + (1 - H)(T_1 + T_M) = T_1 + (1 - H)T_M = T_1 + F T_M TA=HT1+(1−H)(T1+TM)=T1+(1−H)TM=T1+FTM
其中,Tm为不命中开销,此处Tm = T2 + Tb(传送一个数据块所需时间)
三级存储系统
构成:Cache + 主存 + 辅存
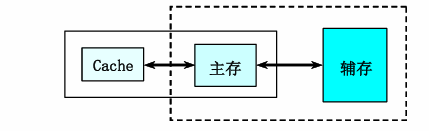
可以看成由"Cache---主存"层次和"主存---辅存"层次构成的系统。"Cache-主存"层次:弥补主存速度的不足 ;"主存-辅存"层次: 弥补主存容量的不足
核心问题:
映象(块调入放哪一级结构)、查找(块处于高层存储器)、替换(发生不命中)、写策略(写访问进行哪些操作)
Cache 基本知识
原理
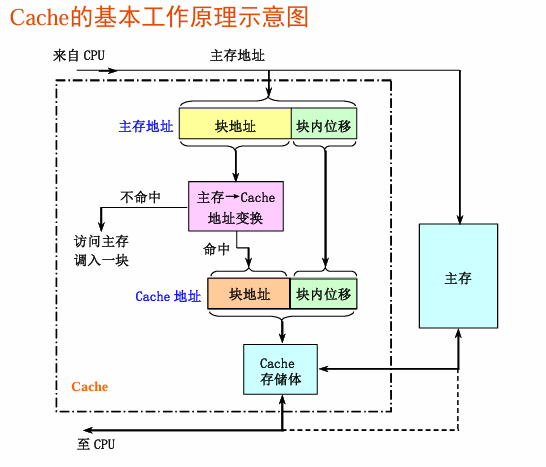
流程:CPU申请数据(主存哪个块里的哪个数据)------ 先看看Cache里有没有(cache根据主存块号,算出可能放在cache的哪里了)------ 有就直接用,没有就调------ 数据交付给CPU
这里的核心问题:1。主存里的数据和Cache的映像规则是怎么样的? 2. CPU访问Cache时,如何确定Cache中是否有所要访问的块?如何确定其位置?
映像规则
- 全相联:主存中的任一块可以被放置到Cache中的任意一个位置
- 直接映像:主存中的每一块只能被放置到Cache中唯一的一个位置
- 组相联:主存中的每一块可以被放置到Cache中唯一的一个组中的任何一个位置。n路组相联:每组n个块
查找算法(CPU访问cache)
- 查找目录表:cache存储主存地址的标识tag(因为每个主存块能唯一地由其标识来确定)。CPU先找到目标数据所在的组,再逐一比较tag。优化:并行查找:同一组里的所有块同时查找
cache工作过程
从查找之后的事情讲起:
- 读取命中:cache直接返回给CPU
- 读取不命中:cache向主存请求,把整个块送回来,cache存进去再返回给CPU。如果cache存满了,就要进行替换算法,之后讨论。
- 写直达:改cache时主存也一起改,一致性好但是慢。
- 写回法:先只改cache,等对应块被替换再写回主存。
写的时候有一个问题:要改的地方不在cache怎么办? ------直接写入主存
替换策略:
- 随机法
- FIFO
- LRU 实现方法:堆栈法:队头最先被使用,需要替换时队尾的出;比较对法:两两比较谁更新
cache性能分析
- 不命中率
- 平均访存时间 = 命中时间 + 不命中率 * 不命中开销
- CPU时间=(CPU执行周期数+存储器停顿周期数)×时钟周期时间 CPU时间 = (CPU执行周期数 + 存储器停顿周期数) \times 时钟周期时间 CPU时间=(CPU执行周期数+存储器停顿周期数)×时钟周期时间
存储器停顿周期数=访存次数×不命中率×不命中开销="读"的次数×读不命中率×读不命中开销+"写"的次数×写不命中率×写不命中开销 存储器停顿周期数 = 访存次数 \times 不命中率 \times 不命中开销 = "读"的次数×读不命中率×读不 命中开销+"写"的次数×写不命中率×写不命中开销 存储器停顿周期数=访存次数×不命中率×不命中开销="读"的次数×读不命中率×读不命中开销+"写"的次数×写不命中率×写不命中开销
实际CPI=CPIexecution+每条指令平均访存次数×不命中率×不命中开销 实际CPI =CPI_{execution} + 每条指令平均访存次数 \times 不命中率 \times 不命中开销 实际CPI=CPIexecution+每条指令平均访存次数×不命中率×不命中开销
CPU时间=IC×实际CPI×时钟周期时间 CPU时间=IC \times 实际CPI \times 时钟周期时间 CPU时间=IC×实际CPI×时钟周期时间
例题:

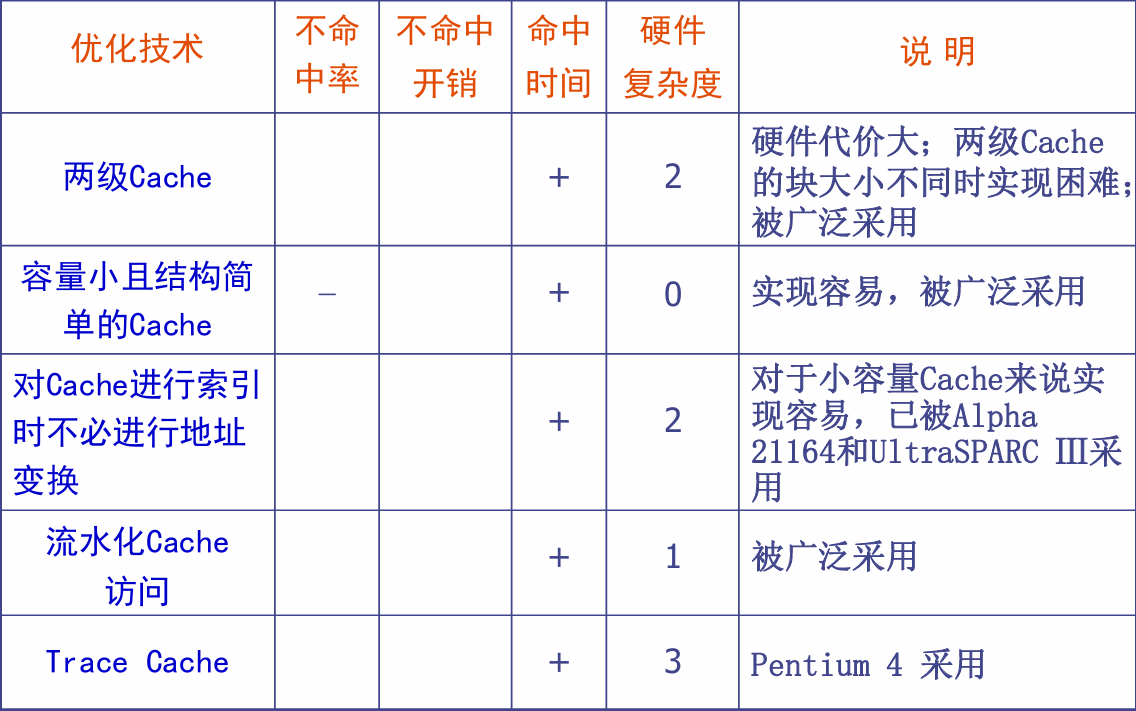
改进cache性能
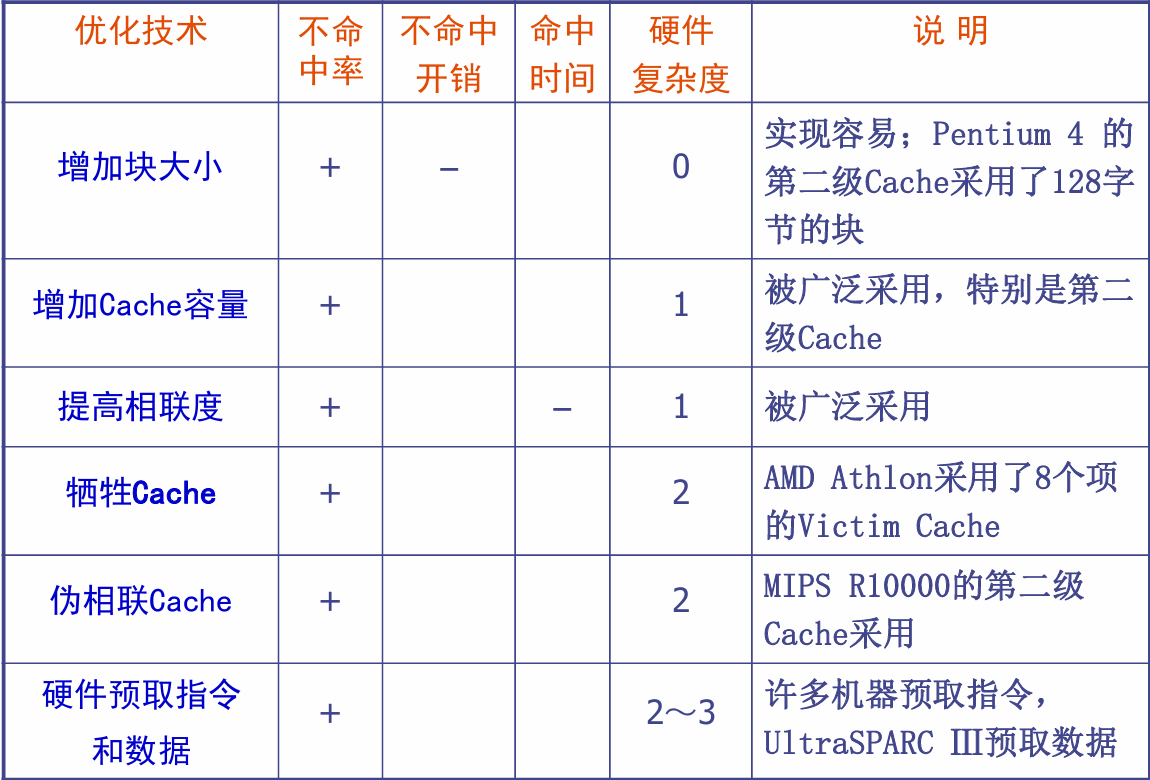
- 降低不命中率
- 减少不命中开销
- 减少cache命中时间
降低Cache不命中率
- 不命中种类:强制性不命中(首次访问块)、容量不命中(程序执行所需块不能全部调入cache)、冲突不命中(组相联太多块被映射到同一组)
- 解决办法:
硬件优化 :增加块大小、增加cache容量、提高相联度(会增加命中时间)、编译器控制预取
软件优化 :编译器优化(数组合并、循环融合、内外循环交换)
特殊结构优化:牺牲cache(在cache和下级存储器之间设一个小cache,存放被调出去的块备用)
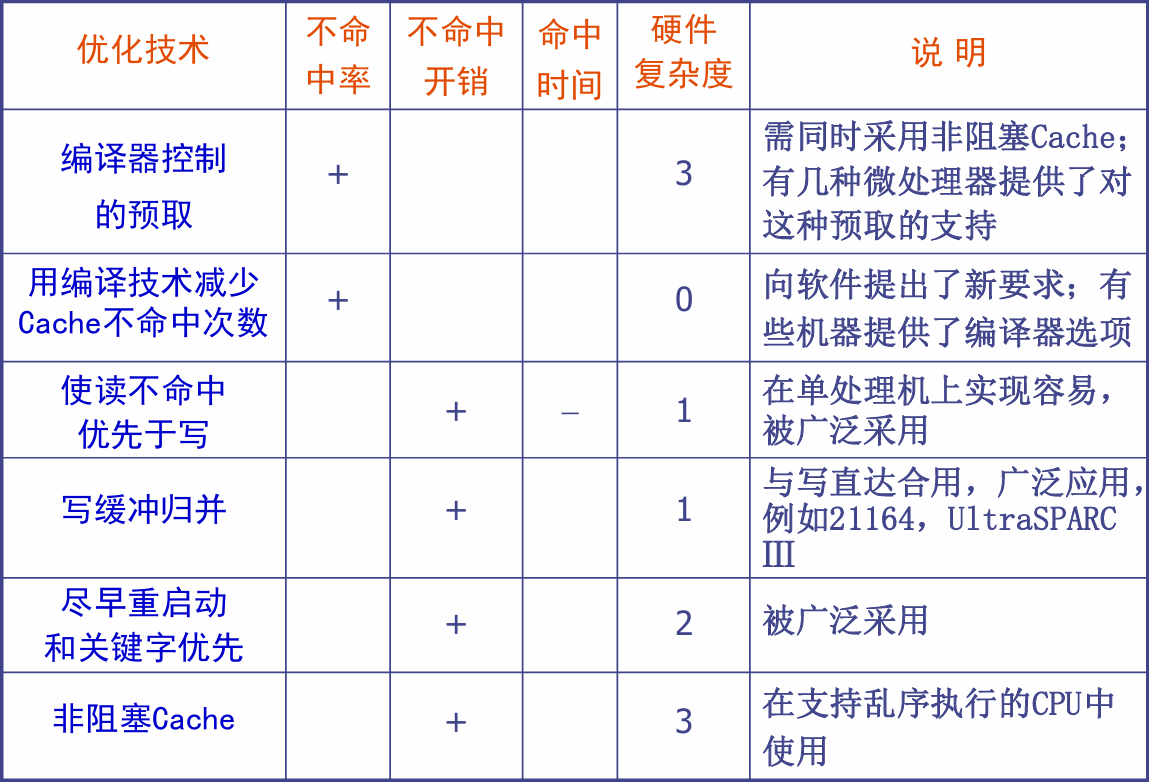
减少cache不命中开销
目的:让miss的代价变小,想办法让去主存拿数据更快
采用两级cache
第一级小而快,第二级容量大
- 性能分析
平均访存时间=命中时间+不命中率×不命中开销=命中时间L1+不命中率L1×(命中时间L2+不命中率L2×不命中开销L2) 平均访存时间= 命中时间 + 不命中率 \times 不命中开销 = 命中时间_{L1}+不命中率_{L1}× (命中时间_{L2}+不命中率_{L2}×不命中开销_{L2}) 平均访存时间=命中时间+不命中率×不命中开销=命中时间L1+不命中率L1×(命中时间L2+不命中率L2×不命中开销L2)
- 局部miss & 全局miss
局部不命中率=该级Cache的不命中次数/到达该级Cache的访问次数 局部不命中率=该级Cache的不命中次数 / 到达该 级Cache的访问次数 局部不命中率=该级Cache的不命中次数/到达该级Cache的访问次数
全局不命中率=该级Cache的不命中次数/CPU发出的访存的总次数=不命中率L1∗不命中率L2 全局不命中率=该级Cache的不命中次数 / CPU发 出的访存的总次数 = 不命中率L1 * 不命中率 L2 全局不命中率=该级Cache的不命中次数/CPU发出的访存的总次数=不命中率L1∗不命中率L2
例题:


写缓冲合并
将多次小写合并成一个大写一起写回主存,需要用到一个写缓冲器。
请求字处理
访问主存调块时,尽快把需要的块中的那个数据优先发送给CPU。
非阻塞cache技术
即使不命中也不等待,继续执行后面的指令
减少不命中时间
采用容量小结构简单的cache、虚拟cache等方法
总结:
7.6 并行主存系统
目标:访问主存后怎么加速。想到并行主存系统。
核心思想:多个存储体同时工作
核心做法:提高带宽
- 单体多字存储器
- 多体交叉存储器(两种编址方式:高位交叉和低位交叉)
7.7 虚拟存储器
目标:主存容量优先,虚存扩容
例题:7.12
第八章 IO系统
I/O系统的性能
系统响应时间 = I/O系统的响应时间 + CPU的处理时间,不能让I/O成为系统响应时间的瓶颈
参数:连接特性、容量、响应时间、吞吐率
I/O系统的可靠性、可用性和可信性
可靠性看"能连续干多久不坏";
可用性看"坏了修好以后,总体有多少时间能用";
可信性看"这个系统让不让人放心"。课件中用 MTTF 表示平均无故障时间,用 MTTR 表示平均修复时间。
廉价磁盘冗余阵列RAID
- 磁盘阵列:多个磁盘的组合替代一个大容量磁盘,多个磁盘并行工作、交叉存放、多个数据请求并行处理
- 条带化:一整块数据切成小条存放到多个磁盘
- 冗余:多存一些额外信息,以备损坏还原
- 奇偶校验:用其他盘的信息反推坏掉的数据,P=A⊕B⊕CP = A \oplus B \oplus CP=A⊕B⊕C,若A坏了 ,A=P⊕B⊕CA = P \oplus B \oplus CA=P⊕B⊕C
由此要解决的两个问题:如何计算冗余信息 ? 如何把冗余信息分布到磁盘阵列的各盘?
RAID分级及特性
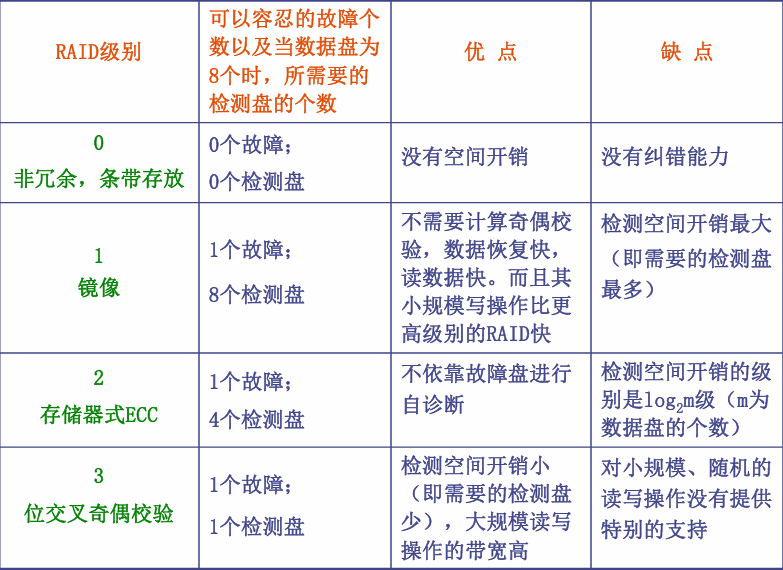
1 RAID0
内容:
磁盘1:A E I M
磁盘2:B F J N
磁盘3:C G K O
磁盘4:D H L P
特点: 速度快、空间利用率高,无校验盘
缺点:无容错、坏一个盘全完
- 适合追求速度、不太怕数据丢的场景
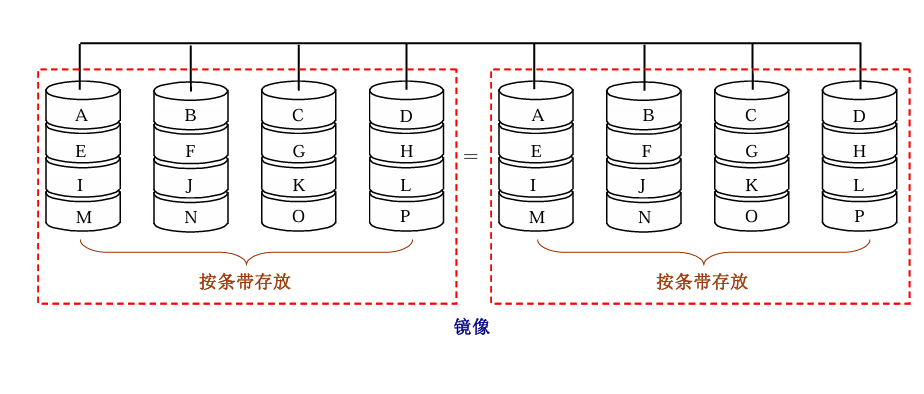
2 RAID1:镜像磁盘
内容 :所有磁盘数据提供冗余备份,每一块磁盘配一块镜像盘
磁盘1:A B C D
磁盘2:A B C D
磁盘3:E F G H
磁盘4:E F G H
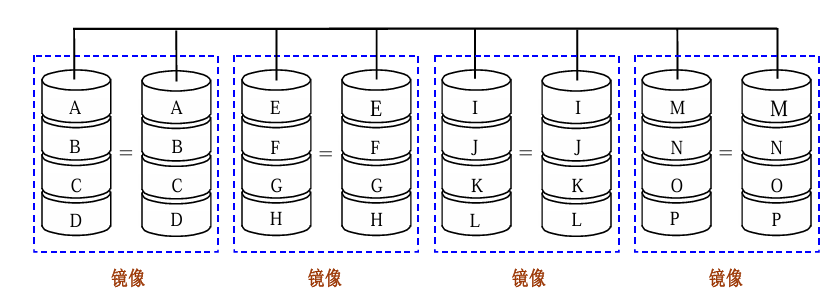
优点:读取快、恢复快
3 RAID2 :位交叉存放、汉明码纠错校验盘
内容 :4个数据盘、3个校验盘
数据部分:
磁盘1 磁盘2 磁盘3 磁盘4
A0 A1 A2 A3
B0 B1 B2 B3
C0 C1 C2 C3
校验部分:
校验盘1 校验盘2 校验盘3
ECC/Ax ECC/Ay ECC/Az
ECC/Bx ECC/By ECC/Bz
ECC/Cx ECC/Cy ECC/Cz
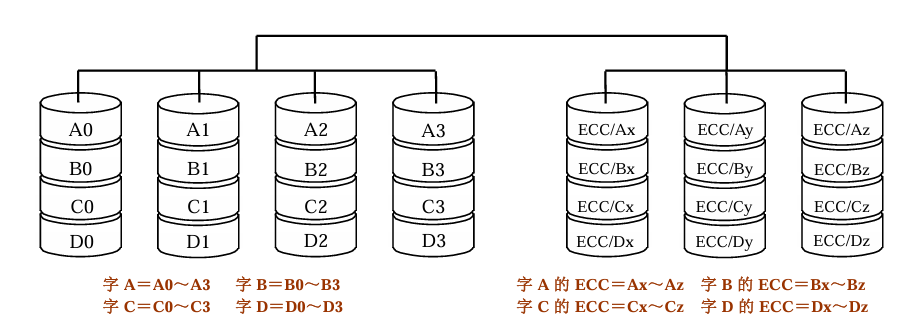
特点: 每个数据盘存放所有数据字的一位;冗余盘是用来存放汉明码的,其个数为log2m级
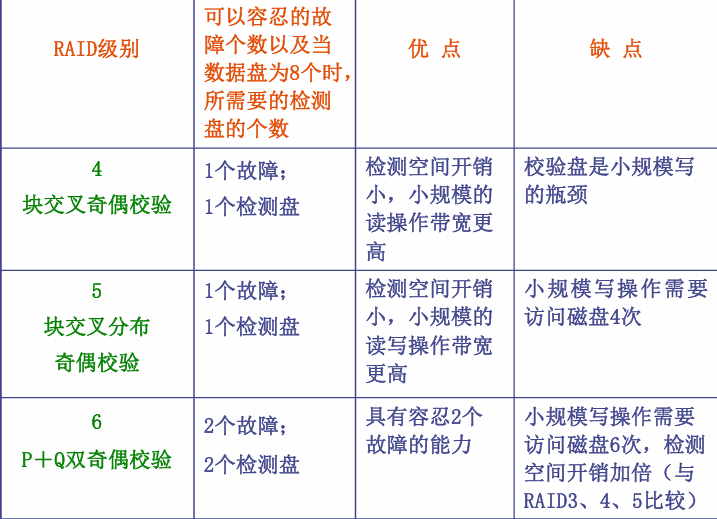
4 RAID 3 位交叉奇偶校验磁盘阵列
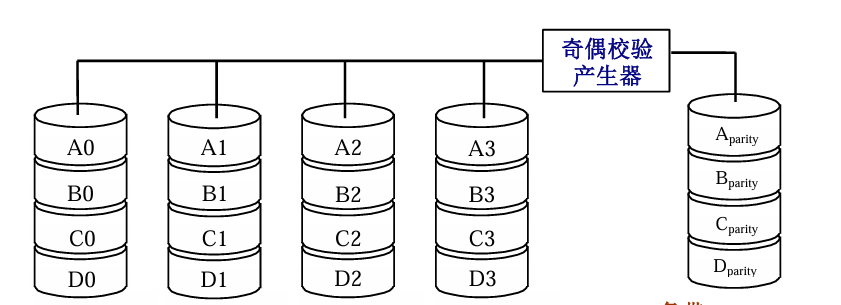
特点:写数据时为每行数据形成奇偶校验位并写入校验盘(位交叉);读数据时若发生异常异或计算其他盘正确信息;缺陷:只能恢复1块坏盘
5 RAID 4:块交叉奇偶校验磁盘阵列
相比于RAID 3,条带更大,以块为单位进行交叉存放,这样子读取的时候不用多块盘参与,一般小规模数据请求只要读一块。因此,适合多个小规模访问请求。
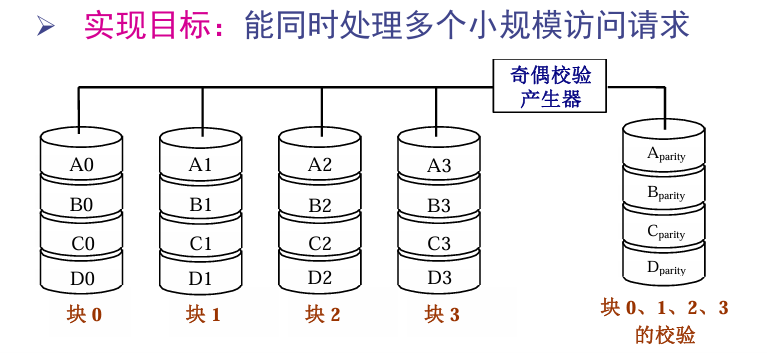
6 RAID 5 块交叉分布奇偶校验磁盘阵列
无专用冗余盘
7 RAID 6 P+Q双校验磁盘阵列
容忍两个盘出错
8 RAID 1 0
先进行镜像,再进行条带存放
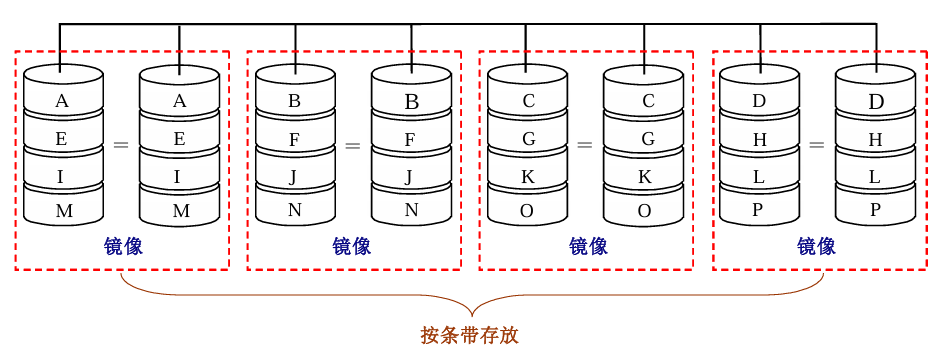
9 RAID 0 1
先进行条带,再进行镜像存放
习题补充
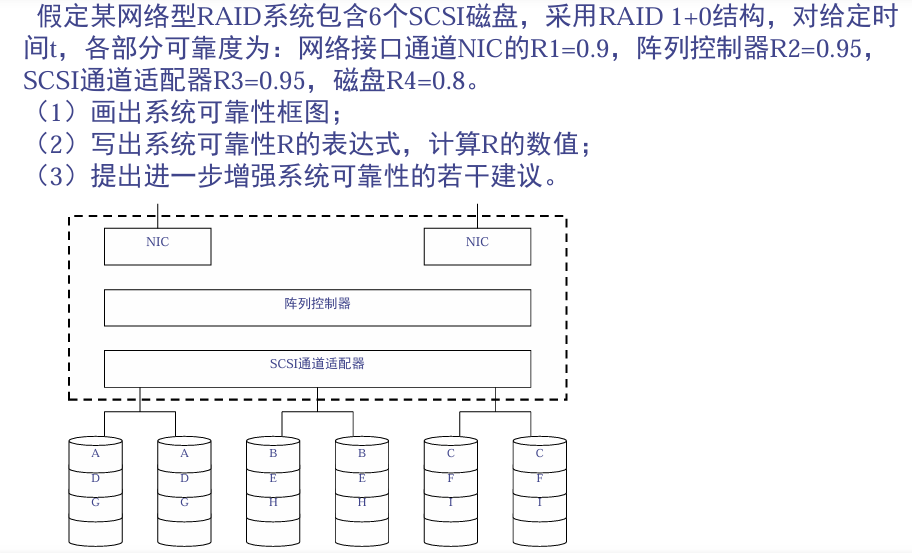
可靠性框图画法:
必须同时正常-> 串联;任意一个正常-> 并联
可靠度表达式计算:
串联:可靠度相乘;并联:1 - 全部失效的概率
R=1−(1−R1)2×R2×R3×1−(1−R4)23R = 1 - (1 - R_1)\^2 \times R_2 \times R_3 \times 1 - (1 - R_4)\^2^3R=1−(1−R1)2×R2×R3×1−(1−R4)23
建议:
-
增加阵列控制器冗余
因为现在只有一个阵列控制器,坏了系统就坏。
-
增加 SCSI 通道适配器冗余
因为现在 SCSI 通道适配器也是单点故障。
-
提高磁盘可靠度
选用 MTTF 更高的磁盘。
-
增加热备份盘
某个磁盘坏了以后可以快速替换,减少 MTTR。
-
采用 RAID6 或更多冗余结构
RAID 1+0 已经有一定容错能力,但可以进一步提升容错能力。
-
加强电源、风扇等辅助部件冗余
防止非磁盘部件成为系统故障点。
第九章 互联网络
基本概念
互连网络就是计算机部件之间的"交通路网",它的目标是在尽量小的延迟、成本、能耗约束下,传输尽可能多的数据,避免成为系统瓶颈。
- 三要素:网络元件、互连结构、控制方式
- 主要操作:置换(多个输入连到多个输出)、广播(一对所有)、选播(一对多)
- 结构参数:网络规模、结点度、结点距离、网络直径(网络直径(即任意两个节点之间的最长路径长度))、等分宽度
- 性能指标:时延 + 带宽
互连函数
输入端编号 x 经过某种规则后,连接到输出端编号 f(x)。
常见互连函数:
- 恒等函数 I(x) = x
- 交换函数Cube_k,把二进制编号的一位取反。Cube0取反第0位。用于构造超立方体网络。
- 均匀洗牌函数σ:把二进制编号循环左移一位。σ(x2 x1 x0) = x1 x0 x2
- 逆均匀洗牌函数σ⁻¹:循环右移一位。σ⁻¹(x2 x1 x0) = x0 x2 x1
- 蝶式函数β:二进制编号最高位和最低位互换。β(x2 x1 x0) = x0 x1 x2
- 反位序函数 ρ:反位序函数是把所有位的顺序全部倒过来。ρ(x2 x1 x0) = x0 x1 x2
- 移数函数:整体编号加或减一个数,然后对N取模。α(x) = (x ± k) mod N
- PM2I函数:PM2I 就是编号加上或减去 2 的 i 次方 ,再绕圈取模。
PM2+i(x) = x + 2^i mod N
PM2-i(x) = x - 2^i mod N
例题:

注意:与目标连接没说作为源还是终点,需要双面考虑。
动态互连网络
总线网络
总线网络由一组导线和插座构成,每一次总线只能用于一个源到一个或多个目的之间的数据传送
交叉开关网络
交叉点开关能在源和目的之间形成动态连接,同时实现多个源---目的对偶之间的无阻塞连接;一个 n×n 的交叉开关网络可以无阻塞地实现 n! 种置换。像一个"电话交换台",输入和输出之间有很多交叉点开关,哪个输入要连哪个输出,就把对应的交叉点接通。
多级互连网络MIN
使用多级开关,使数据在一次通过网络的过程中可以实现更多置换。不像交叉开关那样一步直达,而是分成好几级中转站。数据从第一级开关进去,一级一级走,最后到输出端。
Omega网络(多级混洗---交换网络)
- 构成:靠一层一层的 2×2 开关 来决定数据往哪里走。一条数据要从输入端走到输出端,中间要经过好几道"关卡"。每道关卡前,先把线路"洗牌"一下;然后遇到一个小开关,小开关决定它是直走还是交叉走。
- 核心:洗牌线路 + 2×2开关 + 洗牌线路 + 2×2开关 + ......
- 硬件组成:
N个输入,N个输出
级数 = log₂N
每级开关数 = N/2
总开关数 = Nlog₂N / 2 - 2 * 2开关详解:两个状态:0表示直连(不交换输入输出)、1表示交换(上下交换)
- 在 Omega 网络里,被"混洗"的不是最开始那排输入端本身,而是"级与级之间的连线/数据通道编号"。即:
某一级开关的输出端
↓
经过固定的混洗连线
↓
接到下一级开关的输入端
例子:8 x 8 Omega网络
0: 000 → 000 = 0
1: 001 → 010 = 2
2: 010 → 100 = 4
3: 011 → 110 = 6
4: 100 → 001 = 1
5: 101 → 011 = 3
6: 110 → 101 = 5
7: 111 → 111 = 7
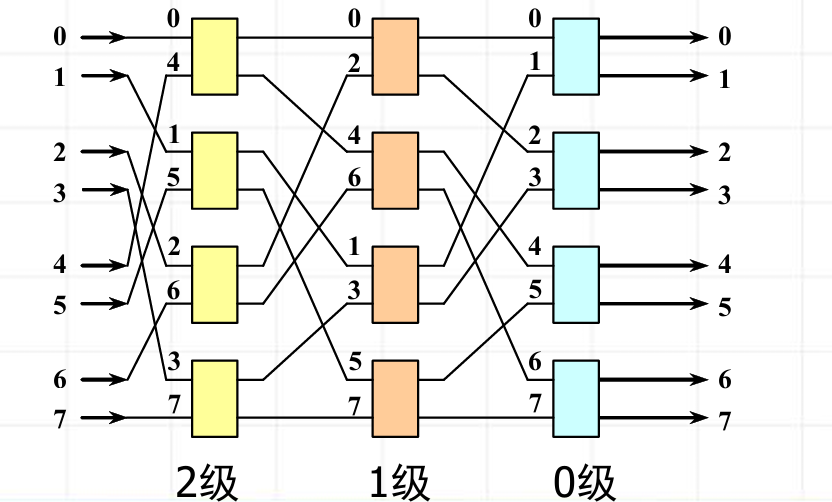
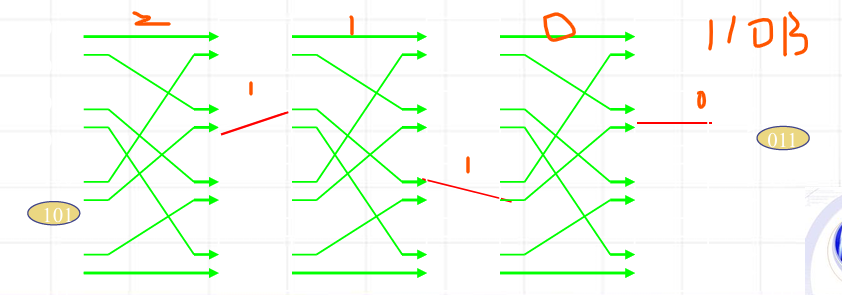
- 寻径算法:
根据给定的输入/输出对应关系,确定各开关的状态。
操作::将任一个输入地址与它要到达的输出地址作异或运算,其结果的biti位控制数据到达的第i级开关,"0"表示"直连","1"表示"交换"。
例如给定传输101B→011B,二者异或结果为110B,于是从101B号输入端开始,把它遇到的第2级开关置为"交换",第1级开关置为"交换",第0级开关置为"直连"。如下图红线所示
网格直径:k维网络的网格直径,每一维差最大,k(n-1)
第十章
习题:
