1、下载源码,从地址:https://github.com/ggml-org/llama.cpp下载,如下图所示:
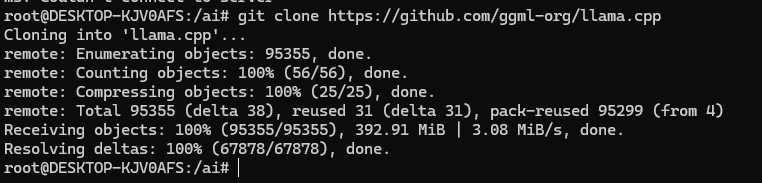
2、安装cuda,安装方法请看地址:https://blog.csdn.net/sunxiaoju/article/details/157170558?spm=1011.2415.3001.5331中的安装方法,安装好之后还需要安装:
bash
apt install nvidia-cuda-toolkit然后执行如下命令:
bash
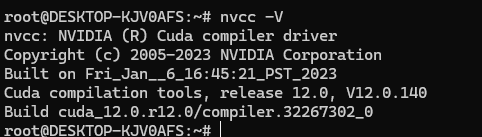
nvcc -V如下图所示:
3、安装如下工具:
bash
apt install -y build-essential cmake git wget
apt install libssl-dev4、然后进入到llama.cpp源码目录创建一个build文件夹如:
bash
mkdir build
cd build/
cmake .. -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build . --config Release -j$(nproc)
mkdir -p /usr/share/llama.cpp/bin
cp bin/* /usr/share/llama.cpp/bin/
vim ~/.bashrc
export PATH=$PATH:/usr/share/llama.cpp/bin编译过程中出现如下错误:
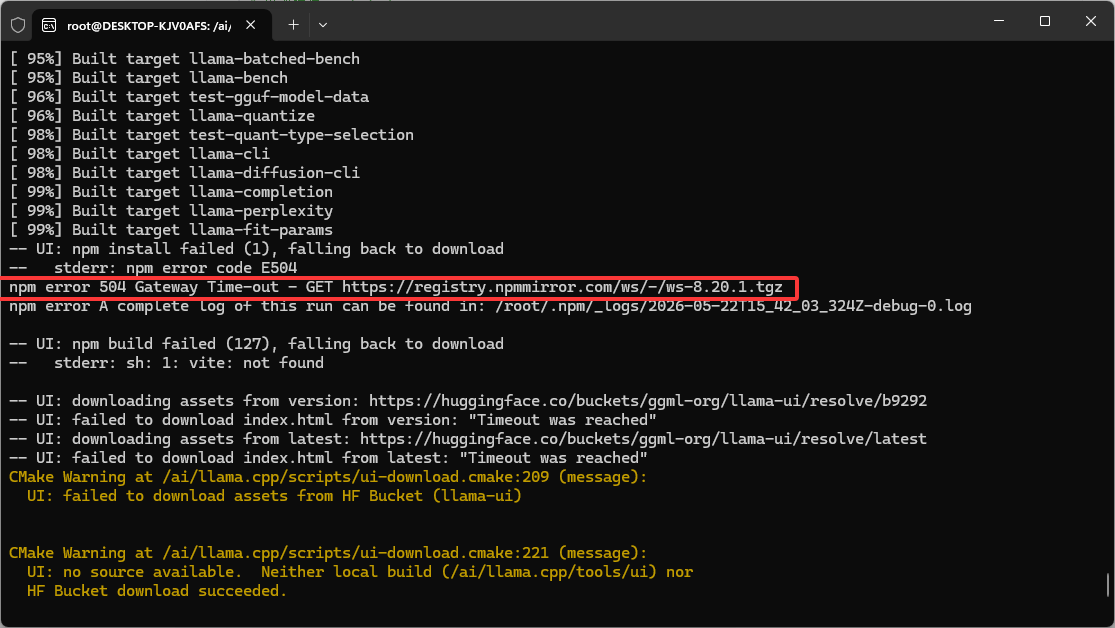
那就手动安装,通过如下命令安装:
bash
npm install -g ws@8.20.1 --verbose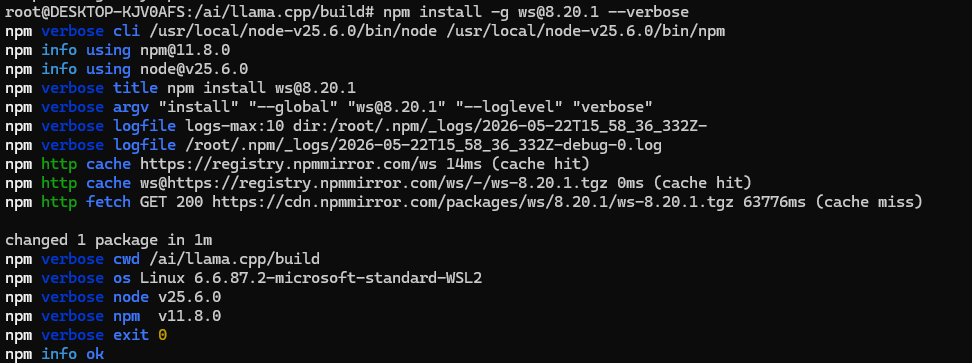
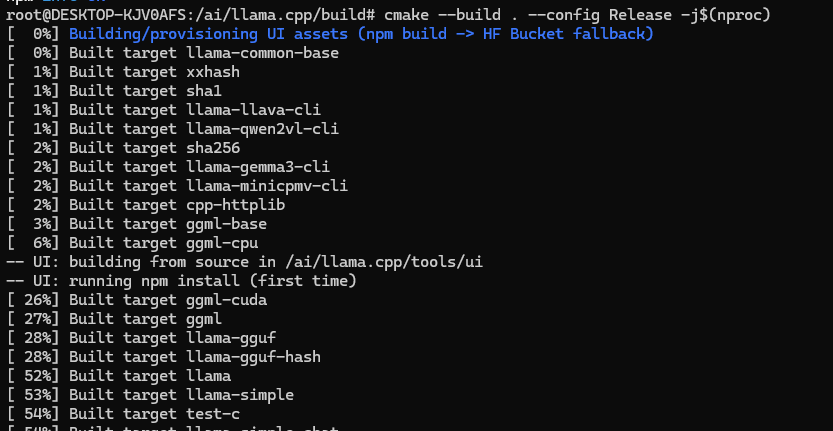
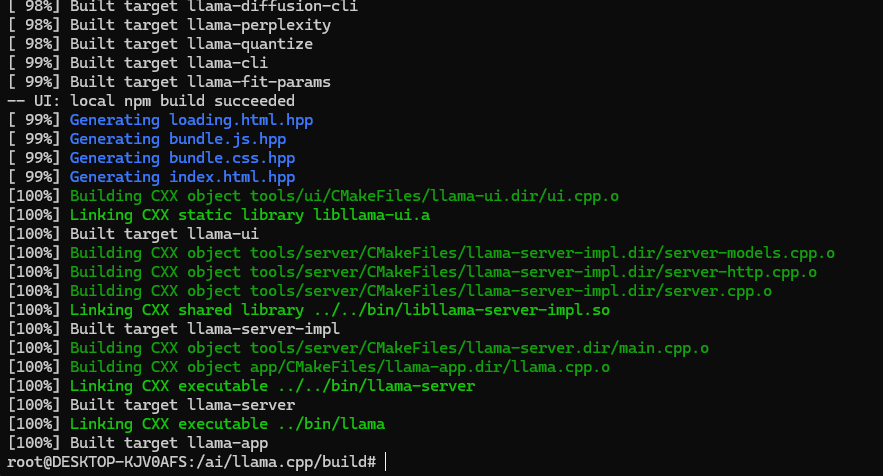
5、然后查看版本:
bash
./bin/llama-cli --version